
融合知识图卷积网络的双端邻居推荐算法
2022-10-24 01:38胡婷婷吴长旺
计算机技术与发展 2022年10期
胡婷婷,黄 刚,吴长旺
(南京邮电大学 计算机学院、软件学院、网络空间安全学院,江苏 南京 210023)
0 引 言
信息技术以及互联网环境的不断发展使得信息过载问题亟待解决,个性化推荐作为大数据时代的产物,发挥的作用越来越重要。为了帮助用户在海量数据中挑选出自己感兴趣的内容,提高用户体验,推荐系统[1]在电影[2]、广告[3]、新闻[4]等推荐场景中得到了广泛应用。虽然关于推荐系统的研究以及应用已取得极大的进展,但还是面临着诸多挑战,比如常见的数据稀疏性以及冷启动[5]问题。传统的推荐算法主要分为基于协同过滤[6]的推荐算法、基于内容的推荐算法以及混合推荐算法,这些算法更加侧重于挖掘用户与物品之间的静态相关性,但忽略了随着时间的推进而导致的用户兴趣的衰减以及偏好的动态变化。
随着技术的不断发展,互联网上越来越多的数据能够被感知获取,比如用户评论的文本、社交信息、图像以及项目属性,研究者通过加入这些辅助信息来提高推荐性能。知识图谱旨在描述真实世界中客观存在的各种实体及其关系,构成了一张巨大的语义网络图,将各种辅助信息融入推荐算法中,包含丰富的物品信息,便于缓解推荐的数据稀疏以及冷启动问题。同时知识图谱[7]具有以下特征:(1)精确性:知识图谱中物品之间丰富的语义相关信息有助于探索各物品之间的潜在联系从而提高推荐准确性;(2)多样性:知识图谱中各个类别的关系可以挖掘用户潜在兴趣,合理地发散推荐结果,提高推荐结果的多样性;(3)可解释性:知识图谱可以连接用户的历史点击记录和推荐记录,为推荐结果提供可解释性。虽然知识图谱有上述优点,但是知识图谱具有高维性以及异构性,如何高效地利用知识图谱进行推荐仍然是一个巨大的挑战。基于嵌入方法是一种可行的解决方案,通过将知识图谱中的实体或者关系映射到连续的低维向量空间中,得到实体或者关系的表征来扩充用户以及物品之间的语义信息。一些典型的知识图谱嵌入方法主要分为两类:基于翻译的模型,比如TransE[8]、TransR[9]、TransH[10]、TransD[11]等;语义匹配模型,如DistMult[12]、CompLex[13]等。但它们更适合知识图谱的补全等知识图内的应用,并不适用于推荐。为了更加充分利用知识图内的有效信息,提出了用图神经网络来挖掘知识图谱中的潜在特征,以此来提取用户与项目之间不同的特征关系。Wang等人提出了KGAT[14](Knowledge Graph Attention Network)方法,该方法将用户-物品二部图与知识图谱融合在一起,形成一种新的网络结构,并从该网络结构中递归邻居传播学习节点嵌入,并通过注意力机制区分各邻居嵌入的重要性。Wang等人提出了RippleNet[15]与KGCN[16]方法,其中RippleNet在知识图谱中以用户交互过的物品为中心,逐层向外进行扩散,实现用户特征的提取。KGCN旨在通过项目节点的邻居与项目节点的聚合得到项目的个性化特征。但是上述方法仅仅只能聚合一端邻居而无法有效确定目标物品与目标用户之间的关系。
基于上述研究,该文提出了一种融合知识图卷积网络与用户偏好的双端邻居推荐算法。在用户端及物品端同时进行特征向量的提取,从而进一步提升推荐的性能。此方法将知识图谱视作有权图,通过注意力机制将关系变为权重,此权重可以理解为该关系影响用户行为的偏好程度,之后从知识图谱的中心出发,迭代地向邻部扩张,之后通过邻居聚合或拼接聚合的方式得到物品的特征向量。其中对于用户特征的提取是通过用户偏好在知识图谱中的扩散过程实现,最后让用户兴趣传播与物品特征聚合交替进行,共享当前已知信息,从而优化推荐结果。
1 相关工作
1.1 KGCN模型
KGCN(KnowledgeGraph Convolutional Networks)模型是知识图谱与图神经网络结合的典型案例。其中心思想就是利用图神经网络的消息传递机制与基本推荐思想相结合进行训练,从而得到知识图谱结构的数据特征。如图1(a)所示,以目标物品为中心向外层进行扩散,向外扩散的过程可以视为在知识图谱中以目标物品作为起点进行广度优先遍历。因为每个扩散的路径只有关系存在不同,计算对应路径的权重时仅考虑关系对于用户的重要性,例如,一个用户可能看重电影的主演明星,而另一个用户可能更关注电影的类型。因此,路径的方向将不再重要,所以将知识图谱视为无向图。然后将扩散得到的节点再向内聚合,再将目标物品本身的嵌入向量与其周围的嵌入向量再进行一次消息聚合,以及走一次或者多次全连接层的操作得到物品的特征向量。KGCN[16]模型如图1(b)所示,整个模型以用户id以及物品id作为输入,第一次聚合选择遍历深度为1的实体,第二次聚合选择遍历深度为2的实体,在知识图谱上进行多层聚合得到物品特征向量,将其与嵌入向量表示的用户特征向量计算得到用户对物品的预测兴趣值。涉及的概念如下:
N(v)表示知识图谱中的实体v直接相连的实体集合。rei,ej表示知识图谱中实体ei与ej的关系向量。
(1)

(2)

(3)
(4)
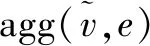

(5)
(6)
(7)
根据公式(1)~公式(5),如图1(a)所示,不断从外向内聚合,将节点的信息聚合到物品节点。最终形成物品节点的向量表示vu。
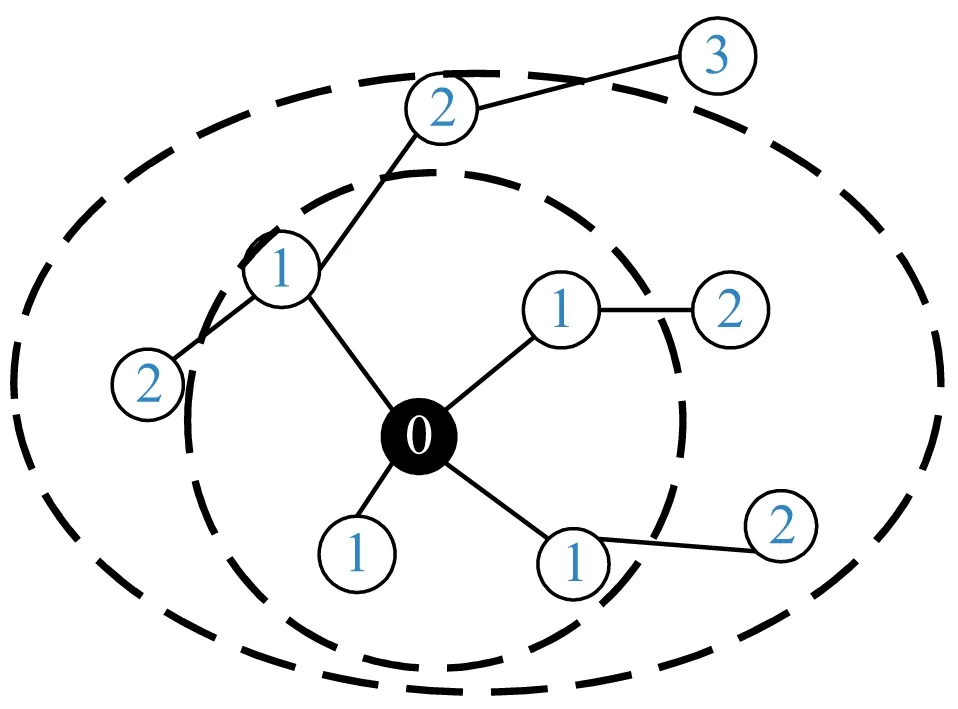
(a)知识图谱
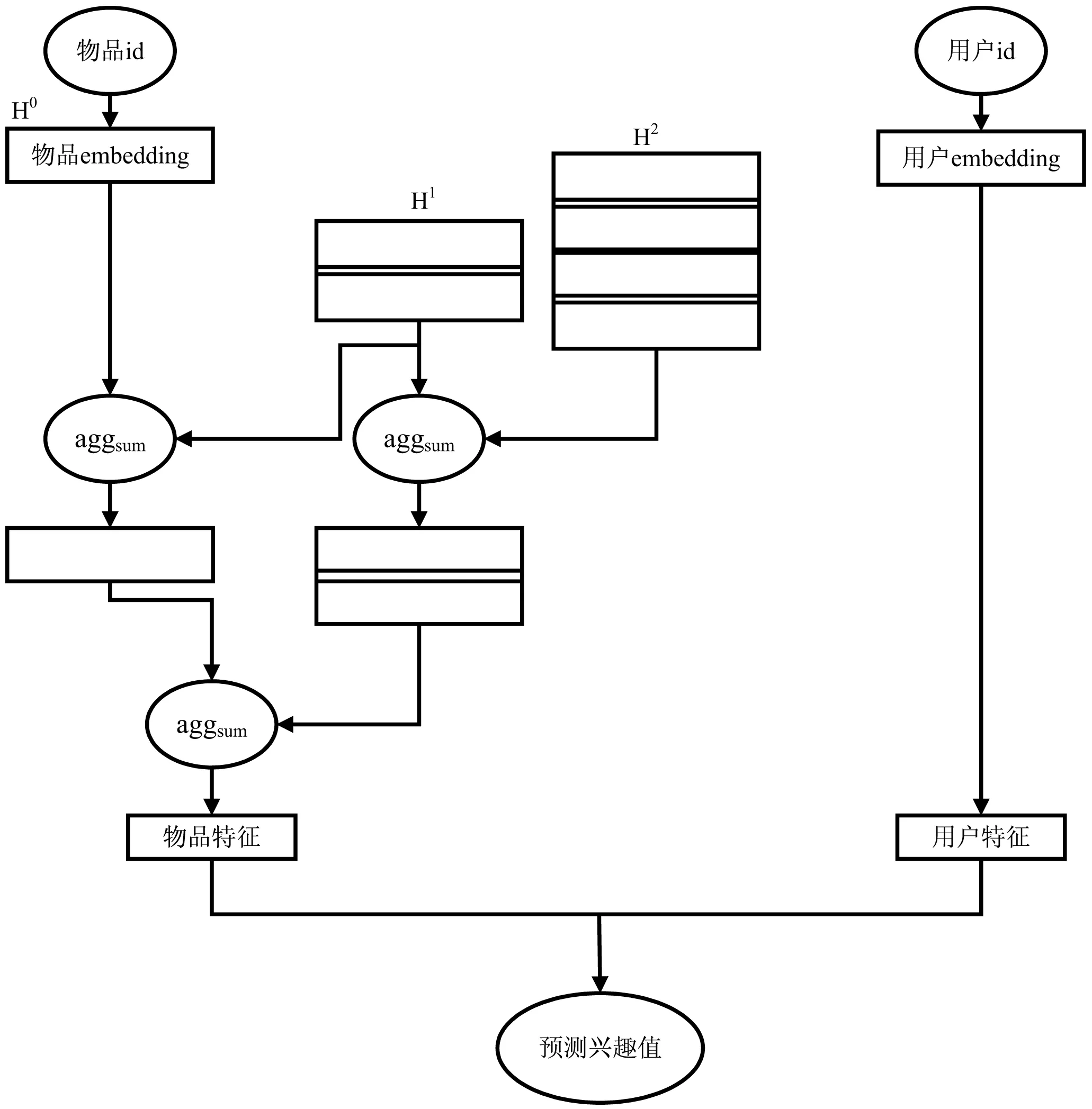
(b)KGCN模型
1.2 RippleNet模型
知识图谱中包含大量的实体间的相互关系,通过对知识图谱中复杂的联系进行研究,进而可得到用户潜在的兴趣与偏好。例如:某个用户已经观看过《长津湖》这部电影,他可能是主演吴京的粉丝,又或者他喜欢导演陈凯歌的风格,也可能是喜欢看战争片,然而吴京还出演过其他更多优秀的作品,导演陈凯歌也不只执导过这一部电影,战争片也包含其他优秀的作品。在知识图谱中与电影《长津湖》相关的实体,用户可能都感兴趣。而RippleNet[15]的核心思想就是根据用户的历史记录来挖掘用户对于知识图谱实体中的潜在高阶偏好。将用户点击过的实体作为“种子”,沿着知识图谱的边在知识图中进行扩散,此扩散是一个逐渐衰减的过程,类似于水中的涟漪,进而扩散得到的节点与用户兴趣有关,可用来加强用户兴趣的表征。如图2所示,整个模型以用户id以及物品id作为输入,首先在知识图谱上进行多层传播提取用户特征,再通过计算得到的用户特征向量与嵌入的物品向量得出用户对物品的预测兴趣值。

图2 RippleNet模型
模型通过输入用户u以及候选的物品v,得到用户u点击物品v的概率值。其中物品向量v随机初始化即可,而用户向量u的计算方式如下:
(8)

(9)

(10)

2 算法描述
2.1 总体框架
该算法通过融合知识图卷积以及用户偏好同时在物品端以及用户端进行交替特征提取,最后基于二者向量内积衡量用户对物品的评分。总体框架如图3所示。
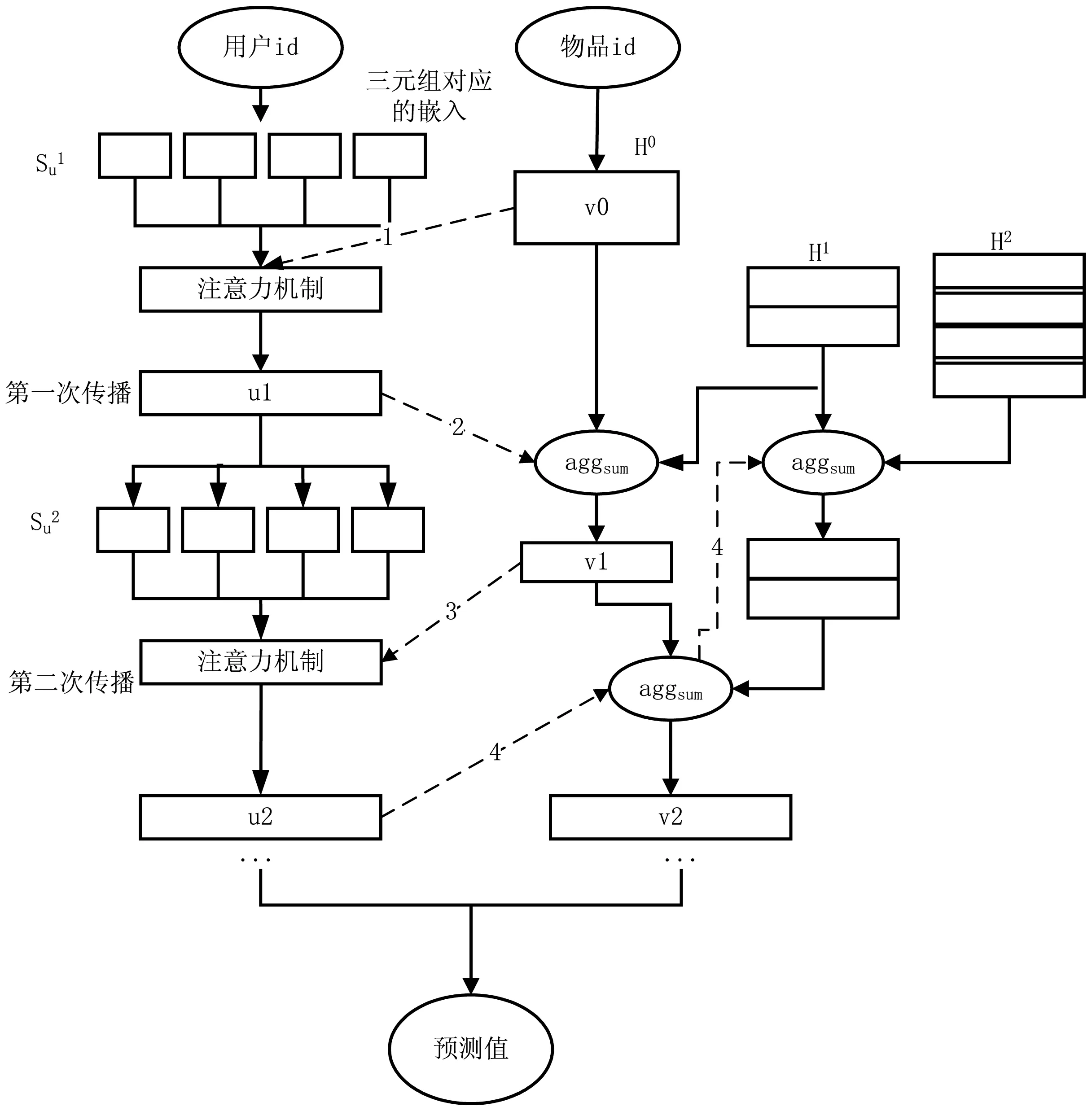
图3 模型框架
2.2 算法思想
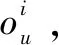
(11)
其中,超参数β用来控制在知识图谱中每一跳输出的权重,此池化操作可以用来区分每一跳对于用户偏好输出的重要性,因为:
(12)
当β为0时,表示最大池化;当β趋近于无穷时,表示平均池化。可以通过控制β的大小来调整在知识图谱中每一跳对于用户偏好的比重。
2.3 算法描述
该算法融合知识图卷积网络和用户偏好,通过在用户端以及物品端交替进行个性化特征的提取,算法流程如图4所示。
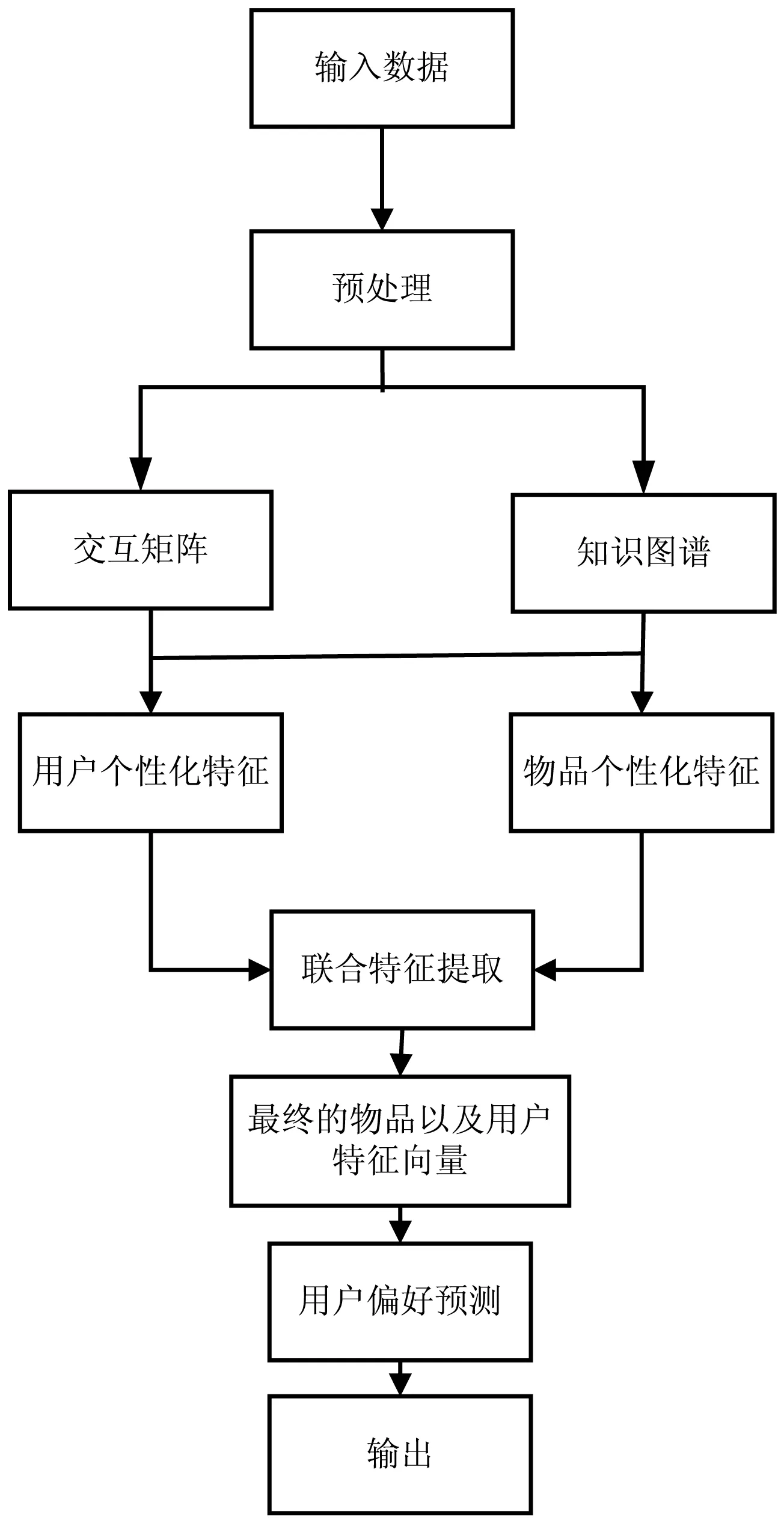
图4 算法流程
具体实现步骤为:
(1)获取输入数据并对输入数据进行预处理,以得到交互矩阵和知识图谱,交互矩阵中包括用户和用户的历史点击对象,知识图谱包括与历史点击对象对应的用户节点。
(2)在知识图谱上对用户节点的邻居信息进行融合,以得到用户个性化特征。
(3)知识图谱中包括物品节点的邻居信息,对物品节点的邻居信息进行聚合,以得到物品个性化特征。
(4)对用户个性化特征和物品个性化特征进行交替特征提取,分别得到用户特征向量和物品特征向量。
交替进行步骤2和步骤3,使得用户个性化特征的波形与物品个性化特征的波形可以进一步产生干涉效应,更深入地发掘用户的兴趣分布和物品特征的关系,得到用户特征向量和物品特征向量。
(5)对用户特征向量和物品特征向量进行内积运算,并通过预测函数来预测用户的偏好,具体的,可通过以下两种预测函数中的一种来预测用户的偏好。
3 实验结果与分析
3.1 实验数据集
为了更好地评估提出的算法,一个包含用户交互信息以及用户辅助信息的数据集是十分必要的。采集的数据集是MovieLens-1M以及Book-Crossing。MovieLens-1M数据集中包含6 040名用户对3 706部电影的100万条评分,其中每个用户评分过的电影条目数均大于20。Book-Crossing数据集来自Book-Crossing市场,包含100万个书籍评分信息,并且包含书籍辅助信息27万多条。对应于数据集的知识图谱数据是从KGCN[16]公开的预处理知识图谱获得,该知识图谱信息来自 Microsoft Satori,两个数据集经过预处理后的统计数据如表1所示。

表1 两个数据集的统计数据
3.2 实验设置与参数
为了验证提出的基于知识图谱的推荐模型的有效性,选取了一些目前最具有代表性的推荐模型进行比较:
MKR[17]:通过一个交叉压缩单元交替学习目标物品与知识图谱中实体的共同潜在语义表示来进行推荐,丰富物品端的表示。在实验中,迭代次数设为10。
KGCN[16]:用图卷积网络的方法在知识图谱中聚合物品的辅助信息,丰富物品端的表示,得到用户对物品的偏好概率。
RippleNet[15]:根据用户的历史记录,挖掘用户对于知识图谱实体中的潜在高阶偏好。
对于每个数据集,按照6∶2∶2 的比例随机构成训练集、验证集和测试集,每个实验重复3次,取平均性能值。在实验中,本模型相对于每个数据集的超参数对照如表2所示。

表2 超参数取值
其中,d表示嵌入维度;H-u以及K-u分别表示提取用户特征时在知识图谱上遍历的深度和邻居采样数;H-i以及K-i分别表示提取物品特征时在知识图谱上遍历的深度和邻居采样数;λ表示正则化的参数;batch表示梯度下降时每批的数据量;η表示训练速率。
3.3 评价指标
采用AUC和F1来评价模型的性能。其中F1为:
(13)
其中,precision为准确率,recall为召回率。F1是同时考虑了准确率与召回率的指标。AUC的物理意义为任取一对正例和负例,其中正例得分大于负例得分的概率,AUC越大,表明方法效果越好。AUC可通过对ROC曲线下各部分的面积求和而得,当测试集中正负样本数量相差很大时,ROC曲线仍然能保持不变,因此AUC可以有效地测试模型的效果。
3.4 结果及分析
将提出的模型与不同模型进行了对比,表3表示各模型在不同数据集下的AUC以及F1的指标结果。

表3 指标对比实验
从实验结果中可以看出,文中模型的实验结果是普遍优于基准实验的,在MovieLens-1M以及Book-Crossing两个数据集上性能都有所提升。其中MKR模型仅仅使用知识图谱嵌入的思想而未能充分利用知识图谱路径信息来进行推荐,因此难以达到最佳性能。RippleNet模型通过模拟用户偏好在知识图谱上进行广泛传播得到用户潜在兴趣,但未充分利用待推荐物品在知识图谱上的信息,从而导致物品特征的缺失。KGCN模型通过知识图卷积网络来提取物品的特征向量,但未充分利用用户的历史点击项目来挖掘潜在的用户偏好,导致用户特征的丢失。相比于以上模型,文中模型有效利用了待推荐项目的图谱信息,并根据用户的历史交互对象在知识图谱中的传播得到准确的用户兴趣表示,物品端与用户端的在知识图谱中交替进行,共享当前已知信息。实验结果表明文中模型有较好的推荐性能。
3.5 参数分析
在超参数调节实验中,研究各个超参数的取值对文中模型的推荐结果的影响:
(1)维度d的取值分别为2、4、8、16、32、64,在MovieLens-1M上对应的AUC取值如图5所示。根据实验发现,在MovieLens-1M数据集上维度取值为16最佳,根据折线图可以看出,当维度小于16时,推荐质量会随着维度的增长而提升,这是因为维度过小所容纳的信息也会相对较少。当维度大于16之后,推荐质量开始逐渐降低,这是因为在维度过大的时候,会引入更多的噪音,导致训练的时候易出现过拟合,求出的解不够泛化。

图5 维度d对推荐质量的影响
(2)用户特征提取以及物品特征提取时遍历的深度分别取值1、2、3、4时,在MovieLens-1M数据集上用户端以及物品端对应的AUC值如图6和图7所示。根据折线图可以看出,随着遍历深度的增加,推荐效果首先呈现上升的趋势,到一定点之后呈现下降趋势。这是因为在提取相应特征时,若遍历深度过低,会使得推荐算法无法充分利用知识图谱中的信息,影响推荐效果;若遍历深度过高,离目标物品较远的实体的引入会造成噪音效果,不利于推荐模型的表现,从而影响推荐质量。还可以看出,用户特征提取深度(H-u)以及物品特征提取深度(H-i)都取值为2可使推荐效果达到最高。

图6 遍历深度H-u对推荐质量的影响

图7 遍历深度H-i对推荐质量的影响
(3)对用户特征提取的实体采样数在取值为2、4、8、16、32、64以及物品特征提取的实体采样数在取值为2、4、8、16时,在MovieLens-1M数据集上用户端及物品端对应的AUC取值如图8和图9所示。由折线图可以看出实体采样数太小时,知识图谱中所能提供的有价值的信息无法被充分挖掘。而实体采样数过大时,则会引起更多噪音,从而降低推荐质量,不利于模型的表现。从实验数据可发现,在MovieLens-1M数据集上提取用户特征时的实体采样数K-u取值为16且提取物品特征时的实体采样数K-i取值为16时推荐质量达到最高。

图8 采样数K-u对推荐质量的影响
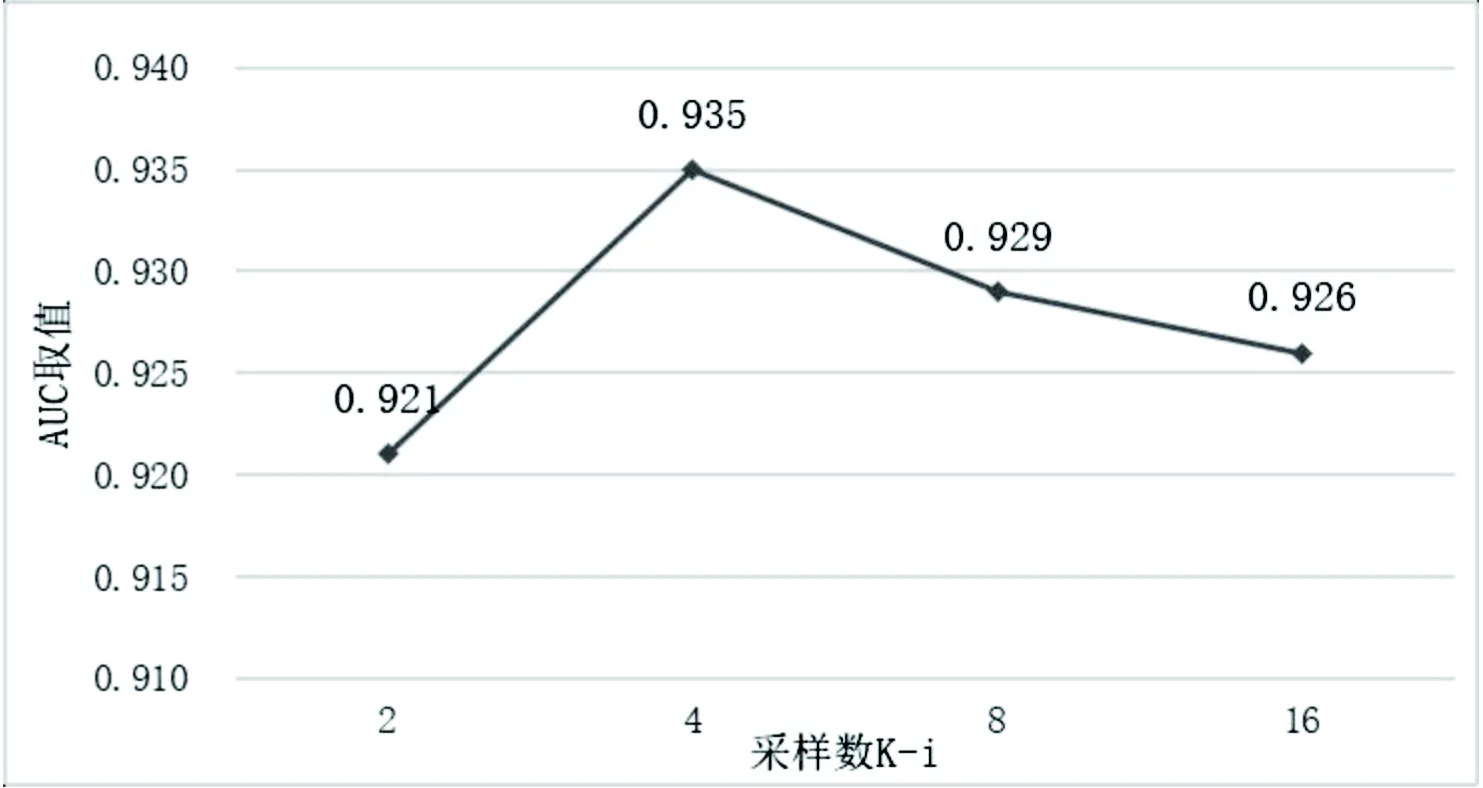
图9 采样数K-i对推荐质量的影响
4 结束语
提出了一种基于知识图卷积与用户偏好的双端邻居推荐算法。该算法将知识图谱作为辅助信息,利用知识图卷积网络模型提取出有个性化的物品特征向量,通过RippleNet模型在知识图谱传播捕获用户偏好信息,找到用户的潜在兴趣,最终得到用户的个性化向量表示。考虑到上述两个推荐模型结构相似,因此联合用户兴趣传播与物品特征聚合的过程,在知识图谱上交替进行用户端与物品端的特征提取。这种新的结构使两侧的特征提取过程统一,使得用户端与物品端的波形进一步产生干涉效应,更深入挖掘知识图谱中用户的兴趣分布与物品特征之间的关系,提高推荐效果。通过实验证明了该模型的优越性。未来研究中还可以挖掘知识图谱中每个实体的属性,类似于物品标签,可进一步提升推荐算法的质量。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
北京航空航天大学学报(2022年8期)2022-08-31
小学生学习指导(低年级)(2022年5期)2022-05-31
保定学院学报(2022年2期)2022-04-07
疯狂英语·初中天地(2021年11期)2021-02-16
少先队活动(2020年12期)2021-01-14
少年漫画(艺术创想)(2019年2期)2019-06-06
数学学习与研究(2018年15期)2018-11-12
新城乡(2018年6期)2018-07-09
领导科学论坛(2016年9期)2016-06-05
