
基于ZYNQ平台的图像处理算法IP验证系统研究
2022-10-24 01:20尹飞皓尚建华
计算机技术与发展 2022年10期
尹飞皓,尚建华
(东华大学 信息科学与技术学院,上海 201620)
0 引 言
随着机器视觉和电子技术的发展,视频图像处理技术得到了迅速的发展并已广泛应用于各个领域[1-2]。传统的ARM、单片机技术由于其主频较低、计算能力较差,较难实现高速、实时的图像处理。针对时性要求较高的应用环境[3-4],FPGA凭借其独特的流水线计算结构[5]、完全可控的Block Ram以及内部集成的丰富的DSP资源[6],可较好实现图像的实时处理;其次,FPGA的可重构性使其可以灵活地实现算法升级和更新,具有更好的可维护性,因此,FPGA已逐渐成为当前实时图像处理的首选[7]。
目前,市场上已有的硬件算法验证平台普遍以FPGA/ZYNQ为控制手段,主要通过开发摄像头实现。然而,这些实现方案存在一定的缺陷,一些图像处理算法(如白平衡处理)会因不同的实现方式而对不同图像数据产生明显的差异。而基于摄像头进行开发,必须选取实际场景以使摄像头进行数据采集并提供给算法端使用。其次,摄像头采集图像的帧数与像素往往在通信协议配置时被限定,因而无法满足需要灵活配置图像帧数和像素的验证场景。并且,基于VGA/HDMI图像输出的传统方案也存在一定的局限性。
针对上述问题,该文基于Xilinx公司的ARM+FPGA结构的ZYNQ芯片[8],在ARM端搭建LwIP协议栈,实现与上位机通信;其次,实现视频配置的下发和视频数据的互传,基于AMBA AXI4协架构自定义多个存储器直接访问(Direct Memory Access,DMA)的IP,并灵活地结合高性能接口和加速器一致性接口(Accelerator Coherency Port,ACP)的使用,实现ARM与FPGA的大数据交互和视频无撕裂显示;最后,针对显示环境的不同需求,设计了上位机回收视频和HDMI兼容多分辨率的显示。
1 系统架构
系统的设计方案如图1所示。在ZYNQ-7000 SOC的可编程逻辑(Programmable Logic,PL)端实现多个DMA主机模块和HDMI控制器模块,DMA主机模块通过AXI-ACP和AXI-HP接口实现FPGA端和ARM端的数据通信,并在DMA读写模块间插入预读取模式的异步先入先出对列(FIFO),进而为待验证算法IP提供接口[9]。在PS端主要实现网络通信模块与DMA从机模块,网络通信模块采用LwIP的Socket模式实现TCP通信,DMA从机模块通过GP接口的AXI-LITE模式实现视频配置数据的寄存器地址映射。
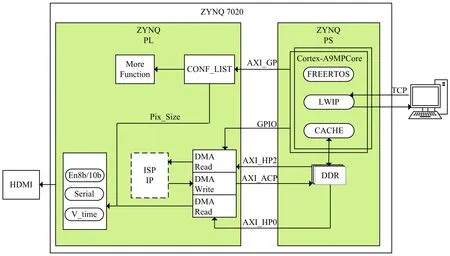
图1 系统总体设计架构
2 软件设计
为了高效接收上位机下发的数据,并根据解析到的数据进行对应的地址分配以及向PL端下发所需指令,系统在PS端对ARM部署FreeRTOS_10_Xilinx操作系统以实现任务的调度,并搭建LwIP协议栈建立TCP通信。LwIP协议栈是瑞典计算机科学院的Adam Dunkels开发的一个轻量型开源TCP/IP协议栈,其占用的RAM/ROM极少,但能实现TCP协议的主要功能[10]。其次,在Vivado SDK中提供了LwIP RAW/Socket API两种接口。RAW模式具有更好的性能,占用内存低,但实现难度较大且不宜移植;Socket模式的内存开销略大,但其易用性和移植性更好。由于ZYNQ-7020芯片的资源较为丰富,因此,在满足系统网络带宽要求的前提下,该文选用Socket模式进行开发。
2.1 数据内部的交互设计
在建立TCP通信后,ARM端接收由上位机下发的数据包。为保证视频数据的高效传输和视频流的数据同步,需节约不必要的数据搬运时耗并保证内存的一致性。若采用传统的内存拷贝和搬运的方式进行视频传输,将会降低数据的传输效率,导致视频卡顿,因此,在收到数据后,利用Zero-Copy技术直接指向数据缓冲源地址DDR3 0X2000000进行数据缓冲,进而减少了数据从LwIP TCP缓冲区到目标缓冲区的数据复制时间[10]。
在从PL端或PS端访问DDR时,二者的访问方式不同。PL端可以直接访问DDR;PS端访问DDR时,首先将一批数据缓存于Cache中以提高交互效率,因此,当Cache中的数据发生变换时,DDR中的数据无法立刻随之改变。当PL端修改DDR中的数据时,ARM无法获取DDR中已被修改的数据信息,依旧会从Cache中读取原来未被改变的那部分数据,此时将出现内存不一致的问题。为了保存内存的一致性,通常会通过Xil_DCacheDisable关闭Cache功能,以使ARM绕过Cache而直接访问DDR,但这又会导致ARM性能的大幅降低。针对上述问题,可以利用Xil_DCacheFlushRange方法将Cache中的缓存图像数据不断刷新写入DDR中,在保证ARM性能的同时,有效实现内存的一致性。
2.2 嵌入式软件的执行流程
在Vivado SDK中选择freertos_tcp_perf_server模板进行网络通信模块的服务器端开发。首先在模板头文件中设置缓冲区尺寸和监听端口号并使能数据传输任务;然后利用模板中的lwip_sendto()和lwip_recvfrom()函数进行TCP的收发[11],这组收发函数无需建立连接即可使用,在调用函数时会自动建立Socket连接,如果建立失败则会返回错误;使能传输任务之后,在传输任务中初始化套接字,当ARM端接收到上位机下发的数据,内存进行处理并根据包头判断下发数据的属性,判断数据属于配置数据还是属于图像数据,配置包的结构如图2所示。
如果数据为配置数据,则根据配置包的内容,通过AXI-LITE将图像尺寸等信息映射到对应的寄存器地址中,并发送640×512图像尺寸的配置包,再借助集成逻辑分析器(ILA)获取conf_list模块的输出,可以验证是否得到正确的配置数据。
如果是图像包头且读回的上位机标志为0,则将数据包头后的图像数据不断写入内存并做地址偏移处理,并通过EMIO GPIO向DMA读模块的中断发送初始化脉冲,再依次将DDR中的图像数据读出;当收到两帧图像数据后,再向上位机发送8字节BB以请求新的一帧图像,同时清空缓冲数据。如果读回的上位机标志为1,则将处理后的图像数据回传到上位机。软件主体控制流程如图2所示。
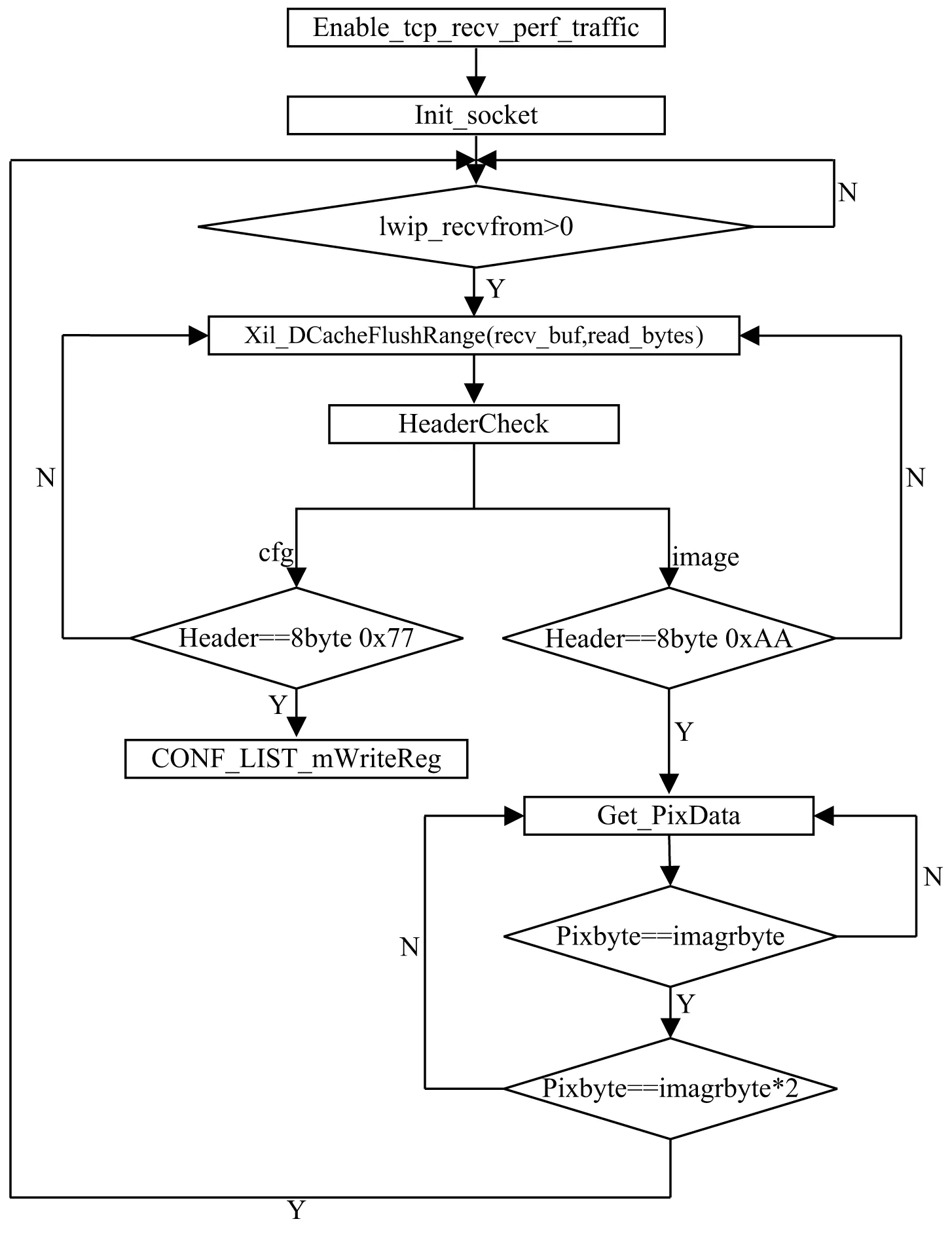
图2 软件控制流程
3 硬件逻辑设计
3.1 DMA读写模块的设计
PL侧与PS侧的良好通信是视频图像传输质量和传输效率的重要保证。在ZYNQ SOC中,主要通过AXI-HP、AXI-GP和AXI-ACP三种AXI总线接口实现ARM端和FPGA端的数据交互[12]。
AXI协议是ARM公司提出的一种高性能、低延时、稳定的片内总线协议。该协议基于猝发和信号握手机制进行数据传输,其拥有读/写地址通道、读/写数据通道、写响应通道五个独立的传输通道。由于视频数据传输带宽宽且需要访问DDR中的地址,因此,在该系统中,通过HP接口和ACP接口的AXI4-MEMORY-MAP模式完成视频数据的DMA读写,结构如图3所示。首先由AXI-LITE配置的各寄存器获得每帧图像的宽和高信息,然后由乘法器计算出一帧图像的总像素值,并以此控制猝发传输的地址。
系统中的三次DMA的猝发长度均设置为256,AXI总线的位宽设置为64 bit,AXI时钟设为200 MHz,进而获得较大的数据传输带宽。由于ZYNQ中DDR的一位地址可以储存8 bit数据,因此,每启动一次猝发,地址将会增加2 048位。在RGB888格式中,一个像素点为24 bit,且DDR中的三个地址位可储存一个像元数据。因此,完成一帧完整图像的读写,地址位的增量为三倍的像元数据量减去一次突发的地址增量。
图3所示DMA读写模块中,各模块的功能如下。
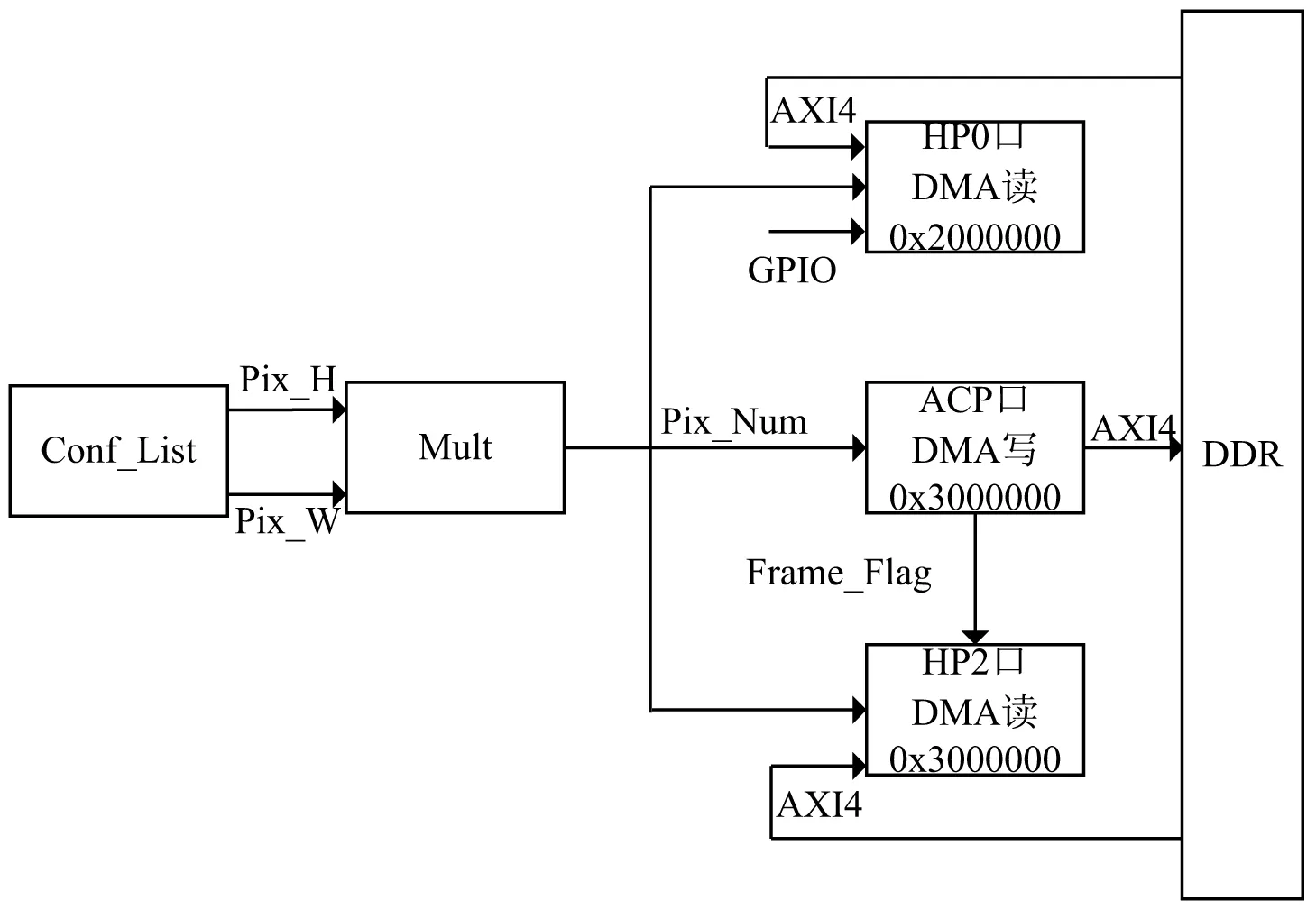
图3 DMA读写模块
HP0口DMA读模块的主要功能是从DDR的0X2000000地址中读出ARM端从上位机接收到的图像数据。每当ARM端接收到一帧图像数据,则通过EMIO GPIO向该模块发出一次读启动脉冲并将该模块使能。然后,通过异步预读取模式的FIFO把读出的图像数据进行缓存,并提供给DMA写模块或图像算法模块,其中,FIFO的写时钟为AXI时钟,FIFO的读时钟为图像处理模块时钟。
ACP口DMA写模块的主要功能是将处理后的图像数据重新写入DDR中。ACP接口是ZYNQ PS端上的加速器一致性接口,是一个兼容AXI3的64位从机接口,可以与SCU(Snoop Control Unit)连接并为PL侧提供异步缓存能力,实现PL侧直接访问PS侧。ACP接口与Cache刷新函数配合使用还可解决Cache一致性的问题,有效保证ARM的性能[13]。
HP2口DMA读模块的主要功能是读取DDR中存储的处理后的图像数据,并通过异步预读取模式的FIFO将该图像数据传输给HDMI控制模块,其中,写FIFO的时钟为AXI时钟,读FIFO的时钟为HDMI控制模块的时钟。为了保证视频流畅并防止FIFO被写满,当FIFO中缓存图像数据不足一行且读通道非忙时,AXI读数据的有效信号设为高电平;当读数据和读数据响应同时有效时,写FIFO的使能信号设为高电平,且FIFO深度设置为2 048,以大于一行像素量的最大值。
3.2 HDMI控制器的设计
HDMI控制器的结构如图4所示,根据HDMI1.4设计规范,通过VGA时序转换可得到三组八位RGB数据[14-15],然后借助8b/10b模块获得直流平衡性更好、转换电平更密集的10 bit编码组,并将10 bit并行数据串行化处理,最后通过OBUFDS原语将串行数据转换为差分信号,实现系统终端的显示。由主机和从机构成的两个OSERDESE2原语在将10 bit并行数据串行化处理时[16],为了避免普通IO口因过高的时钟频率而发生严重的时钟抖动,OSERDESE2原语选择双沿传输模式,且串行化时钟的频率为并行数据时钟的五倍。
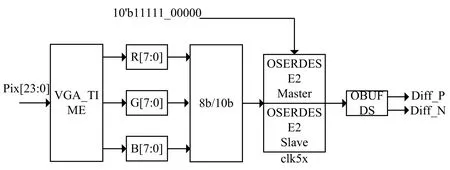
图4 HDMI控制器结构
较传统设计方案而言,该系统实现了HDMI兼容分辨率的无撕裂显示。根据配置数据包的图像尺寸,HDMI模块可实现1 280×1 024分辨率的图像显示并向下兼容多种分辨率的显示。由于系统中的ARM端与FPGA端存在图像数据多次交互的过程,因此,图像数据需同步处理,以保证图像帧同步,避免出现图像显示撕裂的情况。
系统采用如图5所示的双帧缓存设计时序,通过双帧缓存图像数据的类乒乓操作方式解决图像撕裂问题。每次进行DMA写操作时,首先在DDR中缓存两帧图像数据;当第零帧数据写入到DDR中时将Frame_Flag拉高,当第一帧数据写入DDR时将Frame_Flag拉低;然后,将Frame_Flag信号传递到DMA读模块,在DMA写模块写第零帧数据时读出第一帧数据,在DMA写模块写第一帧数据时读出第零帧数据。通过上述双帧缓存操作,可有效避免同时读写同一帧图像数据所造成的数据不同步问题。
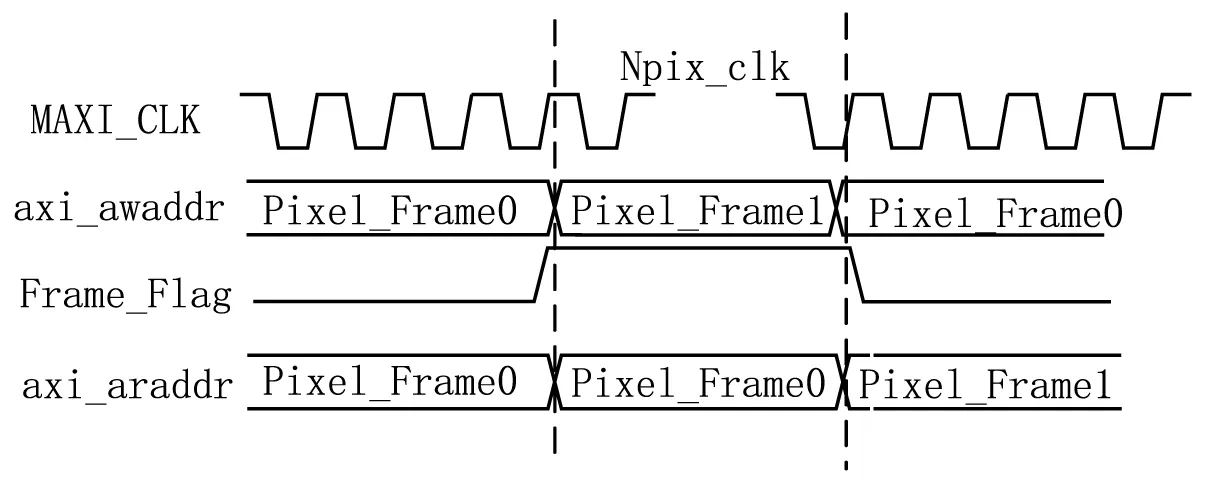
图5 双帧缓存时序关系
4 系统测试与结果分析
自动白平衡算法(Automatic White Balance,AWB)是图像传感器预处理图像的一种常用图像色彩处理方法,其目的是通过还原白色目标的颜色,进而准确还原其他物体的色彩[17]。常用的AWB算法有灰度世界法(Gray World Method,GWM)、完美反射法(Perfect Reflector Method,PRM)、灰度世界和完美反射正交组合算法(Quadratic Combining GWM&PRM,QCGP)等。其中,GWM和PRM算法具有较好的实时性且易于硬件实现,因而被广泛应用[18];QCGP算法计算量极大,因此实时性受到一定限制;GWM算法是在获取图像中RGB三色通道的均值以及所有像素色彩的均值后,通过计算以使三个均值趋于一致;PRM算法则是将图像中亮度最高的点作为“白色”参考,然后进行白平衡处理。
本次测试中,分别使用GWM和PRM两个算法对系统性能进行测试。原始图像如图6(a)所示,图像偏绿。经过GWM算法矫正后,图像更符合真实的人眼视觉效果(图6(b)),而经过PRM算法处理后的图像已经失真(图6(c))。同时,也可利用RTL电路实现GWM和PRM图像处理算法,处理效果与软件算法处理的效果相同(图6(d)(e)),且具有很好的实时性。GWM和PRM两种算法的用时情况如表1所示。
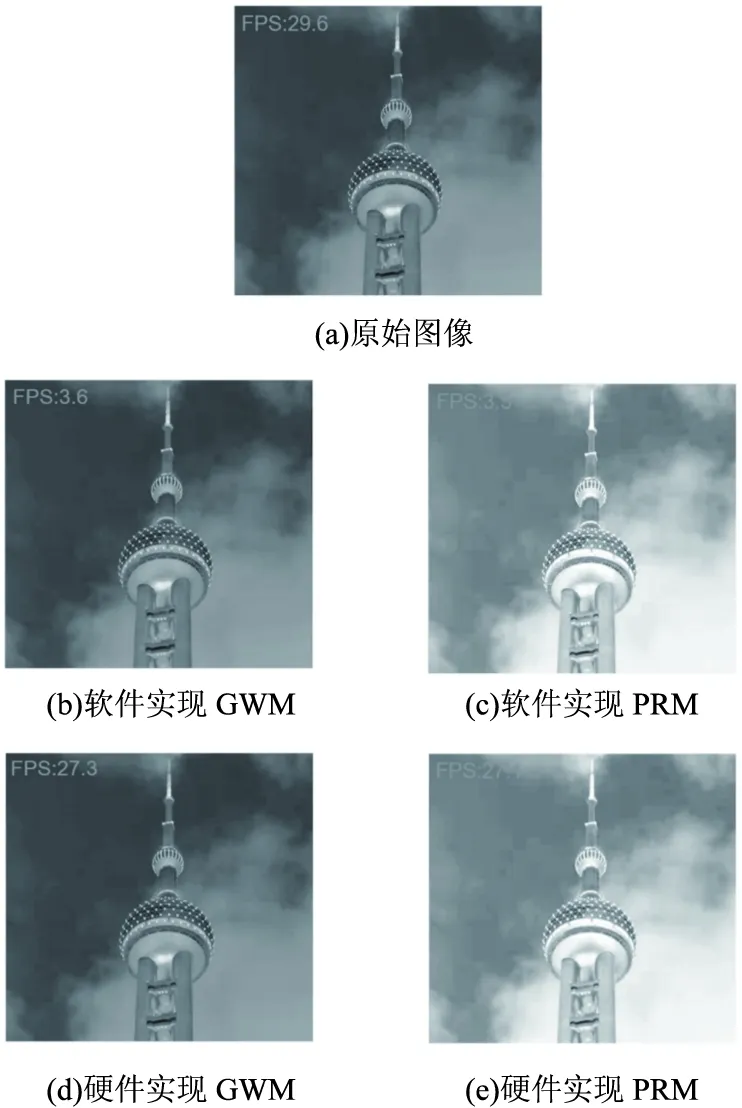
图6 系统测试结果
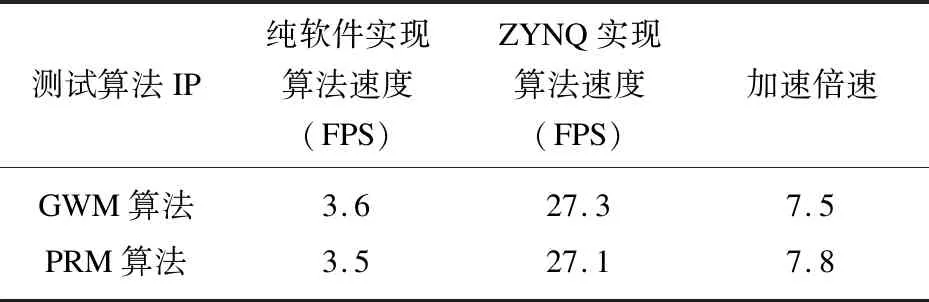
表1 不同平台的算法实现速度
经过测试,系统平均传输速率可达400 Mbps以上,能够达到实时图像传输和处理的要求。另外,系统硬件逻辑资源占用率低于20%且保留了丰富的BRAM和DPS资源,能够为后续复杂图像算法IP的验证提供充足的扩展空间。
5 结束语
针对当前硬件图像算法验证平台的缺陷,以ZYNQ为主控芯片设计了一款灵活高效的图像算法IP验证系统,并提供了完整的图像传输和显示方案,通过软硬协同的方式充分发挥了ARM+FPGA架构的优势。借助GWM和PRM两种算法对系统性能进行了测试,测试结果表明,GWM和PRM算法在FPGA中具有很好的实时性,可以实现400 Mbps以上的视频传输速率,能够较好地支持图像算法IP的验证,有效降低外设成本。
猜你喜欢
建材发展导向(2021年18期)2021-11-05
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
家庭影院技术(2020年12期)2021-01-18
小学生学习指导(低年级)(2020年10期)2020-11-09
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
数学大王·低年级(2018年9期)2018-10-24
数学大王·中高年级(2017年2期)2017-02-08
学苑创造·A版(2016年4期)2016-04-16
