
基于FPGA 的声纹识别系统设计
2022-10-22 03:37:08贾子龙潘士杰郭子昊唐进姚
电子器件 2022年4期
贾子龙潘士杰郭子昊唐 进姚 燕
(北京邮电大学自动化学院,北京 100876)
随着科技的发展,人工智能技术的广泛应用,智能语音系统已广泛融入到人们生活中,智能对话,通过语音控制设备完成指定的工作等应用随处可见。声音作为人与人之间最自然的交流媒介,其中包含着大量不同种类的信息。因此,语音学目前有三大主要的研究领域,包括声纹识别、语音识别和情感识别[1]。声纹识别是通过对一种或多种语音信号的特征进行分析进而实现对输入信号的识别,这种特性对于每个人来说都是独有的,就如同指纹一样,每个个体之间普遍具有差异性,主要取决于人体咽喉、鼻腔和口腔等器官的形状、尺寸和位置等因素以及人们对发声器官的操纵方式。目前针对声纹识别最常用的一些方法为模板匹配法、最近邻方法、神经元网络方法,VQ 聚类法等[2]。其基本原理大致均为通过提取说话人声音频谱,经处理后提取一些特征参数再与目标声纹的参数进行比对检测。声纹识别同样属于一类模式识别问题,伴随着人工智能的发展,也逐渐朝着深度学习的方向不断发展,基于深度学习的声纹识别,经过大量数据训练后得到的模型,其识别效果有着显著的提升。文献[3]提出了一种深度置信网络(Deep Belief Network,DBN)和深度神经网络(Deep Neural Network,DNN)的自适应通用模型,利用i-Vector 构建全局通用DBN 模型。徐志京等人[4]设计了一种加权全序列的卷积神经网络(Weighted Deep Fully Convolutional Neural Network,W-DFCNN),可以更好地适应高频梅尔倒谱小波系数(High Mel Frequency Cepstrum Wavelet Coefficient,HMFCWC)特征。李晋等人[5]提出了一种利用全变量空间,将语音数据进行线性降维后,对声纹模型向量i-vector 进行信道补偿的方法。
CNN 作为机器学习领域常用技术,广泛地应用在目标识别等方面,对于经常用于检测的模型,为了提高检测效果,往往都有巨大的参数量,也就需要庞大的算力支持[6-7]。CPU 为计算单元少,缓存单元多的结构,处理CNN 时速度较慢。GPU 虽然拥有大量的计算单元,可以有效加速CNN 计算,但其同时也有功耗高,成本高,不便携的缺点。利用软件实现声纹识别,虽然具有较高的灵活性和可操作性,具有更多的资源,可构建更为复杂的网络,但缺乏合适的硬件通路,使其在高效性及低功耗性上无法做到统一。
利用FPGA 根据对应算法设计加速网络结构,可以非常有效地加速CNN 的运算,能效高,延迟低。针对不同的网络结构可以设计对应的加速电路,可以很好地适应深度学习[8-11]。基于这些优点,越来越多的研究者开始关注于FPGA 的硬件加速。但是FPGA 硬件加速也存在一些限制,如常常一个完整的系统需要多个模块协同,均占用板卡资源,故板卡资源无法全部分配给CNN 运算,设计时要考虑对资源占用的优化;对于不同的网络,要实现最优需要设计不同的硬件电路。尽管如此,FPGA 在CNN 加速方面依然有着极大的实用价值。
声纹识别现在在很多领域都得到了广泛应用,常用于刑侦破案、罪犯跟踪、国防监听、个性化应用、证券交易、银行交易、公安取证、个人电脑声控解锁、汽车声控解锁、身份验证和识别等[12-14]。在本项目中,选择使用的是Xilinx 旗下的PYNQ-Z2 开发板,进行基于FPGA 加速的声纹识别技术的研究及实现。
1 系统总体设计
本研究基于Xilinx 的PYNQ-Z2 开发板,实现了具有声纹识别功能的控制系统,系统的硬件框图如图1 所示。

图1 硬件结构框图
系统首先对PYNQ-Z2 开发板进行初始化,读取经过语音数据集训练出的权重和偏置,初始化完成后开始工作。按下按键开始录音,通过麦克风采集48 kHz 采样率、24 bit、双通道语音信号。取其中一个通道的音频信息,提取梅尔频率倒谱系数(Mel Frequency Cepstral Coefficients,MFCC)参数,输入到Xilinx ZYNQ7020 作卷积和池化的并行运算,而后从ZYNQ7020 中输出得到标签和准确率。若输入音频的标签相符,即身份正确,将语音信号进行格式转换,转成API 输入要求的16 kHz 采样率、16 bit、单通道语音信号,并输入到百度API 中进行语音转文字操作,得到字符串形式命令。对命令字符串进行关键字检索,进而调用Arduino I/O 和MIC 执行命令。如果身份验证失败,输出音频“没有权限”。命令执行完成后或者身份错误时,重新跳转到按键开始处,等待下一次命令输入。
1.1 MFCC 特征提取
梅尔频率倒谱系数与梅尔标度(Mel scale)有着密不可分的关系。梅尔标度是基于人耳对于不同频段声音的敏感度不同的特性提出来的,在这个标度下,人耳对频率的感知度能成为线性关系。为此,出现了梅尔滤波器(Mel-filter banks),它的通带在低频处较窄且密,高频处较宽且疏,从而达到由低频到高频分辨率逐渐降低的效果,声音转换为梅尔频谱(Mel Bank Features),来模拟人耳对声音的感知。梅尔倒谱系数便是在梅尔频谱的基础上,做倒谱分析后的特征系数,通过它及其一阶、二阶动态系数,能够很好地表示声音的特征[15-16]。
MFCC 特征提取流程如图2 所示。

图2 MFCC 特征提取流程图
MFCC 的提取,一般可分为以下几个环节:(1)音频预处理;(2)离散傅里叶变换;(3)梅尔滤波;(4)动态特征系数的提取。
1.1.1 音频预处理
由于采集设备或人发声器官自身的原因可能会出现信号的混叠、高频失真的问题,对语音信号的质量会产生一定影响,因此在对音频信号进行分析前,必须对其进行预加重、分帧、加窗等预处理操作,从而尽可能保证后续的语音处理得到的信号更均匀、平滑,为MFCC 的提取提供优质的参数,提高语音处理质量。
预加重:语音信号的平均功率谱受声门激励和口鼻辐射的影响,高频端大约在800 Hz 以上,按6 dB/oct(倍频程)衰减,频率越高相应的成分越小,为此要在对语音信号x(n)进行分析与处理之前对其高频部分加以提升。预加重网络的输出y(n)和输入的语音信号x(n)的关系为:
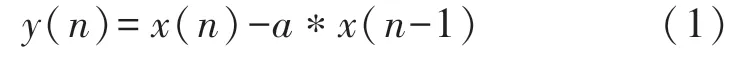
式中:a为预加重系数。
分帧:语音信号具有时变特性,而同时也具有短时平稳性,一般认为在10 ms~30 ms 的较短时间内,其特性基本保持不变,便可以看作一个准稳态过程。因此对任何语音信号来说,分析与处理必须建立在“短时”的基础上,即进行“短时分析”,将语音信号分成数个小段来分析其特征参数,其中每一段称为一“帧”,帧长取10 ms~30 ms。实际操作时,是将N个采样点集合成一帧,N的取值与信号的采样频率有关,对于MkHz 的采样率,一般让N/M落在10~30 内。为避免相邻两帧的变化过大,会让两相邻帧之间有一段重叠区域,此重叠区域包含了L个取样点,一般L的值约为N的1/2 或1/3。
加窗:分帧之后,需要紧接着进行加窗处理,加强两端的连续性,防止频谱的泄露。常用的有汉宁窗、汉明窗、矩形窗。本项目采用汉宁窗。

1.1.2 离散傅里叶变换
预处理好的信号,需要利用傅里叶变换将其转换为频域下的表征,以更好地观察信号的特性。

式中:xn为长为N的信号序列。
1.1.3 梅尔滤波
梅尔滤波需要先将信号从Hz 频率转变为梅尔频率,具体变换关系为
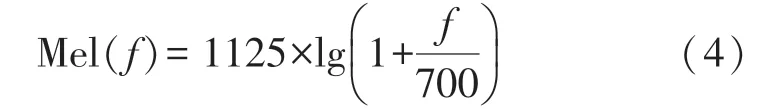
逆变换:

选取Hz 频率下的最低频率与最高频率,根据需求滤波器个数等间隔插入频率点,这些会是梅尔三角滤波器的对称中点,再将这些坐标转化为Hz频率下的表示,并寻求对应位置数组f,滤波器传递函数为:
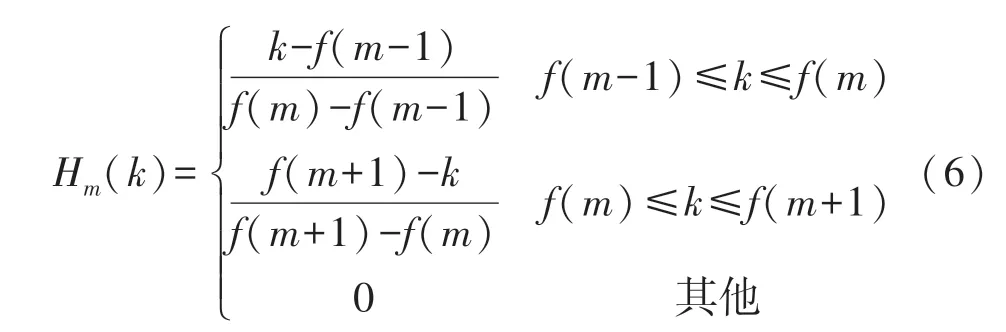
以此便能构建梅尔滤波器组。将预处理好的音频信号通过前一步设计的梅尔滤波器,就能够得到音频的MFCC。再注意将能量为0 的地方调整为eps,以便对数运算,而后作离散余弦变换
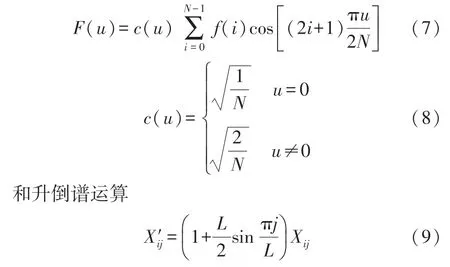
式中,L为升倒谱系数,得到的结果就是MFCC 的特征系数。
1.1.4 动态特征系数的提取
有了MFCC 的特征系数,还需要对其求一阶和二阶导数。原因是MFCC 系数只反映语音在静态情况下的特性,而动态特性亦是语音的另一大特征,只有动静结合,才能获得更好的识别性能。

至此,MFCC 及其一、二阶系数提取完毕,每一帧得到13×3 的数组,可用于后续神经网络输入,将每帧的特征系数平铺开来,视作一个矩阵,便能将其运用于卷积神经网络CNN,并利用FPGA 对其卷积和池化运算进行加速。
1.2 卷积神经网络分类模型
神经网络主要由卷积层和池化层组合形成,卷积层可以获取输入的特征,池化层会对卷积结果进行子采样以降低运算复杂度[17]。本文所建立的卷积神经网络分类模型结构如图3 所示,其中主要有4 个卷积层、3 个池化层、1 个全连接层。
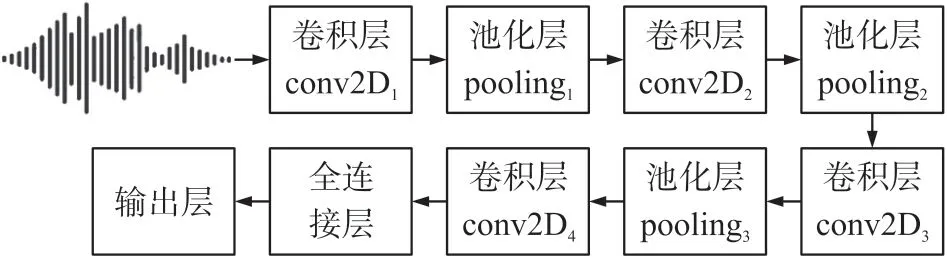
图3 CNN 网络结构图
表1 为神经网络各层的卷积核大小及输出特征的大小,每一层的卷积核大小均为3×3,卷积完成后利用核为2×2 的池化层进行降维,最终输出为一1×1 的结果。

表1 CNN 各层的卷积核大小及输出特征大小
1.3 格式转换
PYNQ 得到的是48 kHz 采样率、24 bit、双通道的输入音频信号,而语音转文字所用API 的输入要求是16 kHz 采样率、16 bit、单通道音频信号。利用soundfile 库优先将输入信号转化为16 bit,而后由wave 读取输入音频的时间序列,该序列采用二进制记录。双通道下,可视序列的奇数项为左声道,偶数项为右声道,简单筛去右声道即可,这样就能让双声道变单声道。而后48 kHz 采样率和16 kHz 采样率的联系在于,48 kHz 采样率下每隔3 个点是16 kHz采样率下的一个点,故要48 kHz 采样率转16 kHz采样率,只需对序列隔3 取1。又因为是双声道转单声道,就变成了对序列隔6 取1。之后再将序列保存为wav 文件,即可满足格式要求。
2 声纹识别基于FPGA 的实现
系统数据流如图4 所示,对于Zynq 芯片主要包含两大功能模块:PS(Processing System) 与PL(Programmable Logic)。其中PS 模块是一个基于ARM 处理器的处理系统,PL 模块是基于Xilinx 7 系列架构的可编程逻辑单元。

图4 系统数据流图
系统的工作流程为:系统先从外设中获取音频并将其存储在PS 存储单元中,经过处理器提取处理后驱动AXI-DMA 单元将数据输送到片上处理器,之后ARM 会控制CNN 硬件加速单元读取特征和权重来进行计算,并将结构送回片上存储器再经由AXI_DMA 送回到PS 的存储器中,再进一步处理输出。
2.1 基于FPGA 的MFCC 特征参数提取
实际所使用的PYNQ-Z2 开发板的环境是一个简易的32 位Linux 系统,而不幸的是,TensorFlow 对于32 位系统的支持仅仅停留在1.0 版本之前,而这阶段版本跨度变化巨大,从静态图网络变为了动态图网络,代码书写规范和要求也有很大改变。另一方面,开发板难以安装librosa 包,不能简单地依靠librosa 进行声音特征的提取,也要求构建一套音频特征采集的方案。
除此之外,还有一些其他常用的语音信号处理函数如pyaudio、pydub,开发板也不支持,因而无法使用,需要按照上述原理手写代码以实现对读取到的音频进行分切和梅尔频谱的提取,即对语音信号分别作预加重、分帧、加窗、快速傅里叶变换FFT、取绝对值、经过Mel 滤波器、取对数、离散余弦变换,最终取得MFCC 特征参数。而后再对其作一阶差分和二阶差分,获取其一阶参数和二阶参数。
经过上述几步获得的MFCC 参数组,是基于语音信号分帧后的每一帧语音信号,因此,理论上,对于每个人,每一帧的语音信号的MFCC 参数组是大致相同的。为了优化运算速率,同时保证一定的准确度,对MFCC 参数组作裁剪,只取连续80 帧的语音信号对应的MFCC 参数组。取20 帧~100 帧,可以在一定程度上避免最初的静音干扰。同时,为了方便后续的卷积和池化运算,筛掉最后3 个二阶特征参数,只取前36 个MFCC 特征参数。这样处理之后,得到一个80×36 的特征矩阵,以供后续处理。
本项目利用TensorFlow1.0 对代码进行重写后采用Adma 算法做训练,同样在得到声纹识别的模型后,录入音频并提取梅尔频谱,放入模型中比对。
以上便是在32 位FPGA 开发板上的实现方式,由于很多库函数不支持而无法使用,因此有不少方面需要单独写代码实现,但实现后经验证与在win10 环境下的效果基本一致。
2.2 基于FPGA 的卷积网络实现
由于卷积神经网络具有特有的计算模式,利用通常的方式实现很难满足其性能要求,为此,采用FPGA 加速的方式可以非常有效地提高CNN 的性能,主要目的为充分利用FPGA 平台所提供的计算资源以实现高效的循环展开及流水线化[18]。
2.2.1 卷积和池化ip 核的建立
如果直接基于python 作卷积运算,每次卷积将作j×k次循环乘法,时间复杂度较高。而FPGA 能进行多路并行运算,为了充分利用其并行运算优势。本研究通过HLS 生成conv 卷积IP 和pool 池化IP,重构base.bit 并将上述两个IP 核添加到base 中,之后依据输入输出地址重写python 函数。如此操作后,虽然能够正常生成bit,但是却无法进行正常的卷积和池化运算,判断原因为加入这两个IP 核后,片上资源利用率过高,或是引脚间冲突,故对电路进行一定裁剪,去掉没有使用而资源占比很大的video模块后,能正常生成bit,并且功能正常。对于一个神经网络,通常其运算量是非常大的,通常可以利用FPGA 硬件的并行化来设计一个运算通路,即使用硬件来对这个网络进行加速。
对于一个卷积神经网络,其进行的操作主要有三个,即卷积、池化和全连接运算。其中全连接运算还可以看成卷积运算的一种特殊形式。故而只需要设计两种通用数据通路即可实现该网络。这样做可以节省很多的资源并且具有更高的灵活性。
从图5 中可以看出,只需要实现两大通用模块,一块实现卷积及Relu 运算,另一块实现池化运算,通过CPU 可以对两大模块的工作参数及运算结果分别进行配置。

图5 数据通路设计图
其中卷积的核心为一三维的累加乘法,定义式如下

式中:Fo(co,y,x)表示输出特征中在(x,y)处的神经元,Fi(ci,y,x)表示输入特征中在(x,y)处的神经元。卷积核的大小为Ky×Kx,输入特征映射总数为c层。
对于池化操作,主要有三类:最小池化,最大池化和平均池化,分别作为三种模式,根据CPU 的指令来选择。该模块主体为三个大循环,分别为层数、宽度、高度,遍历每一个元素,之后按照模式要求取最大、最小或平均值。
在IP 核建立方面主要使用了高层次综合工具(HLS)来实现,其工作流程如图6 所示。本研究利用C++编写并实现了池化和卷积的IP 核,并利用Vivado 将其合并入板卡中,图7、图8 即为调整单元模块前后板卡资源使用情况。如图7 所示,加入两个IP 核后,线路复杂,资源将近占满,运行效率低且容易出错。其中无用的video 模块是造成这种情况的主要原因,可以看到,删去video 模块后,情况得到了很大改善,其资源使用情况如图8 所示。
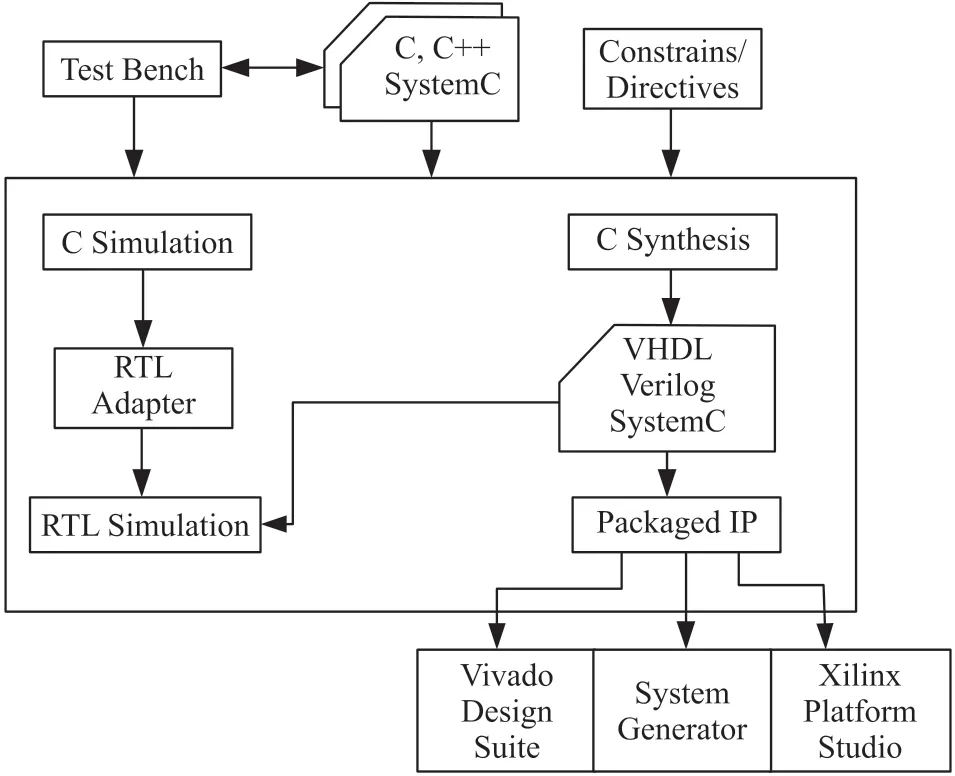
图6 HLS 总览

图7 重建修改前的资源使用情况

图8 重建修改后的资源使用情况
3 实验结果
本研究整合了声纹识别和语音识别,完成了一个比较完善的语音控制系统,能够完成语音输入、身份验证、命令识别、命令执行等一系列操作。为了展示成果,共寻找了20 人录制样本,分别经过CPU、GPU、FPGA 三个平台测试,如表2 及表3 所示,可以看出,CPU 耗时最长,GPU 最短,FPGA 远快于CPU,略慢于GPU。
初始化时长:

表2 初始化时长
正常工作时长:

表3 不同平台处理时间对比
本次实验成功实现了声纹识别在PYNQ-Z2 的片上运行并且利用FPGA 对卷积运算进行加速。识别样本数量20 人,输出范围为包括“未成功识别“在内的20+1 种结果,能够在较高正确率(3 人测试共100 次,成功识别次数为88 次)情况下识别出20人中的特定说话人,在遇见20 人以外的其他说话人时,也能够返回“未能识别”。未采用FPGA 硬件加速时,PYNQ-Z2 实现单词声纹识别需要耗时3 s 左右,然而加速之后,该时间明显降低不少,可以明显看到FPGA 对声纹识别速率的提升。
4 结束语
本文主要介绍了基于FPGA 实现声纹识别的一些关键技术,声纹识别作为一种生物特征识别技术,可以有效地解决语音方面的安全性问题,是将来身份验证、身份识别等方面的一种有效解决方案。梅尔倒谱系数可以有效地提取和描述出语音信号中的声纹特征,利用卷积神经网络结合FPGA 的并行运算优势可以有效地提高运算速度及识别准确率。同时,该设计仍然有很多可拓展之处
对于Windows+GPU 版,能够依赖成熟的音频特征提取库来获取梅尔倒谱,因此该过程在单次采样时几乎感受不到耗时。但是对FPGA 开发板而言,即使使用的是PYNQ-Z2,能够支持Linux 系统,但由于其32 位的限制,一些PC 端能使用的库功能无法正常调用。故针对音频特征,虽然依照了梅尔倒谱提取的数学原理对其进行功能复现,但是效果并不是很好,占用时间较长。关于这一点,可以如声纹识别一样,利用FPGA 做加速运算,同时可以对数学方法的代码实现进行优化,进而能减少时长占用。
猜你喜欢
时代汽车(2024年12期)2024-07-05 22:35:03
哈尔滨工业大学学报(2022年5期)2022-04-19 13:26:36
语言与文化论坛(2019年3期)2019-04-13 02:25:30
家庭影院技术(2018年11期)2019-01-21 02:20:52
电子制作(2018年19期)2018-11-14 02:37:08
电子技术与软件工程(2017年24期)2018-01-17 12:39:59
中国科技博览(2017年17期)2017-06-14 00:23:40
电子制作(2017年9期)2017-04-17 03:00:46
电脑知识与技术(2016年12期)2016-06-14 00:01:51
人间(2015年8期)2016-01-09 13:12:42
