
面向跨模态行人重识别的单模态自监督信息挖掘
2022-10-21 01:55吴岸聪林城梽郑伟诗
中国图象图形学报 2022年10期
吴岸聪,林城梽,郑伟诗
中山大学计算机学院,广州 510006
0 引 言
随着城市监控系统的完善,对监控视频进行智能分析的需求越发迫切。行人重识别作为智能监控视频分析的基础技术受到越来越多的关注。其任务是跨无交叠视域的摄像头进行行人图像的匹配。由于不同摄像头下采集的行人图像受到光照、分辨率、遮挡和背景变化等影响,这些场景因素导致的数据分布偏移是行人重识别的难点。随着深度学习的迅速发展,基于有监督学习与弱监督学习的算法,行人重识别模型在公开标准数据集上已经能达到很高的性能。
然而,现有的研究大部分集中在基于可见光图像的行人重识别。对于可见光图像无法适用的应用场景,如在跨白天和夜晚或跨室外与室内的情况下,行人图像的外观会受到显著光照变化的影响。在正常光照场景下通常使用可见光图像。而在低照度场景中由于采集的可见光图像质量退化严重,其中包含的信息不具有判别性,难以从中提取特征进行匹配。在这种情况下监控摄像头通常会切换为采集近红外图像,克服光照不足的影响。可见光图像包含红(R)、绿(G)、蓝(B)3个通道,而红外图像包含单个通道。由于成像原理不同,可见光图像与红外图像属于不同模态的数据,存在显著的视觉差异(如图1左侧),使得现有针对可见光行人图像的方法难以适用。为克服显著光照变化的影响,有必要研究“可见光—红外”跨模态行人重识别问题。
目前,“可见光—红外”跨模态行人重识别的研究主要围绕设计能有效消除模态鸿沟的跨模态匹配算法开展,但是性能仍然不理想。除了不同模态数据的显著视觉差异导致的模态鸿沟外,数据难以标注也是一个限制模型性能的重要问题。目前公开的多模态行人数据集的训练集身份总数均不超过500,对于训练深度学习模型仍然不够。如图1左侧,由于在红外图像中缺失可见光图像的颜色信息,视觉模糊度高使人工观察也很难分辨行人图像是否属于同一个人,导致人工标注跨模态的样本比一般情况下标注同模态的样本耗时更长以及成本更高。
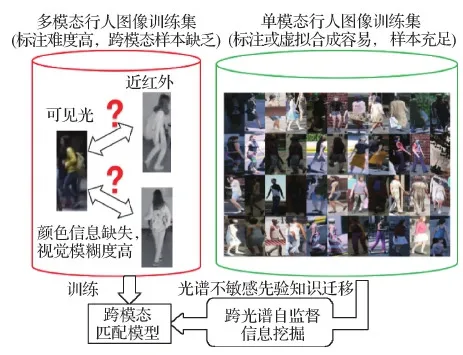
图1 基于单模态数据辅助的跨模态行人重识别示意图
在有标注的多模态数据量有限的情况下,从其他领域迁移对跨模态匹配有帮助的先验知识是其中一种重要的解决思路。如图1,本文提出使用单模态可见光行人图像作为辅助,从中挖掘对光谱范围不敏感的特征,并把这种先验知识迁移到基于有限的有标注多模态训练数据学习的跨模态匹配模型中,以提高其判别能力。单模态数据的标注相比跨模态数据的标注更加容易,用于辅助的可见光行人图像的获取可以选择用人工标注,也可以选择更容易获得标签的3维合成虚拟行人数据。
面向跨模态行人重识别的任务,针对模态鸿沟与有标注训练数据有限的问题,本文从单模态自监督信息挖掘的角度开展研究,利用额外的单模态可见光图像作为辅助挖掘对光谱范围不敏感的特征,通过预训练模型初始化与下游任务微调把先验知识迁移到跨模态匹配模型中,提高多模态数据有限情况下的判别性能。本文的创新点如下:
1)提出一种随机单通道掩膜的数据增强方法来提取通道共享的特征,使模型对成像光谱变化不敏感;
2)提出一种基于三通道与单通道双模型互学习的预训练与微调方法,从三通道与单通道的关系中挖掘自监督信息引导模型学习鲁棒的跨模态匹配特征。
1 国内外研究现状与相关工作
1)基于可见光图像的行人重识别。近年来,行人重识别研究(罗浩 等,2019)快速发展,技术日趋成熟。现有的行人重识别方法研究主要集中在可见光图像和视频的理解上。行人重识别技术经历了从手工特征设计(Liao等,2015)到距离度量学习(Zheng等,2013)和端到端深度学习(Ahmed等,2015)的快速发展。大多数现有的行人重识别研究都从可见光图像中提取视觉表观特征,然后学习计算相似度进行匹配。其难点在于姿态变化与遮挡(史维东 等,2020)、多分辨率(沈庆 等,2020)等方面。
虽然有监督学习(Sun等,2018;Ye等,2022)、弱监督学习(Meng等,2021)和无监督学习(Ge等,2020;Zheng等,2021b;Wei等,2018;Yu等,2020)的方法都已经可以在基于可见光图像的行人重识别研究中取得很好的性能,但这些方法仍然未能解决开放环境中的行人重识别问题,如光照变化强烈的跨模态行人重识别场景(Wu等,2017)、换衣行人重识别场景(Yang等,2021)、细粒度行人重识场景(Yin等,2020)、跨分辨率行人重识别场景(Zheng等,2022)以及基于群体验证的场景(Zheng等,2016)等。
2)跨模态行人重识别。为解决不同场景光照变化强烈的问题,“可见光—红外”跨模态行人重识别(陈丹 等,2020)的研究主要围绕能有效消除模态鸿沟的跨模态匹配算法开展,但是性能仍然不理想。Wu等人(2017)首次开展跨模态行人重识别的研究,并公开了首个包含可见光图像与红外图像的多模态行人重识别数据集。之后,跨模态行人重识别的研究逐渐开始发展。Ye等人(2018)提出基于双流网络的方法HCML(hierarchical cross-modality metric learning),利用双流网络消除模态差异以及通过度量学习得到更稳定的跨模态匹配。在模态鸿沟消除方法的设计上,还发展了一些代表性的方法,包括基于图像和特征联合对齐的D2RL(dual-level discrepancy reduction learning)(Wang等,2019b)、基于生成对抗学习的cmGAN(cross-modality generative adversarial network)(Dai等,2018)与AlignGAN(aligned genereative adversarial network)(Wang等,2019a)、基于跨模态相似度保持的CMSP(cross-modality similarity preservation)(Wu等,2020)、基于第3模态生成的XIV-ReID(x-infrared-visible re-identification)(Li等,2020)和MMG(middle modality generator)(Zhang等,2021b)、基于多模态图像混合的CMM(class-aware modality mix)(Ling等,2020)、基于协同注意力机制的CoAL(co-attentive lifting)(Wei等,2020)、基于模态“特有—共享”特征迁移的cm-SSFT(cross-modality shared-specific feature transfer)(Lu等,2020)、基于模态和模式联合对齐的(joint modality and pattern alignment network,MPANet)(Wu等,2021)、基于模态混淆学习网络的方法(modality confusion learning network,MCLNet)(Hao等,2021)、基于融合模态联合学习的方法(syncretic modality collaborative learning,SMCL)(Wei等,2021)、基于密集关键点配对的方法(learning by aligning,LBA)(Park等,2021)和基于多特征空间联合优化的方法(multi-feature space joint optimization,mSO)(Gao等,2021)等。针对可见光图像与红外图像的模型设计开始引入自动机器学习的思想,发展了基于特征搜索的NFS(neural feature search)方法(Chen等,2021)与基于架构搜索的CM-NAS(cross-modality neural architecture search)方法(Fu等,2021)。Tian等人(2021)基于信息瓶颈理论,提出变分自蒸馏的方法避免互信息的显式估计。
基于通道增强联合学习的CAJL(channel-augmented joint learning)方法(Ye等,2021)与跨光谱图像生成方法(Fan等,2020)都是与本文研究高度相关的方法。它们通过分离可见光图像的RGB通道分别做数据增强来使数据更接红外图像的模态。一方面,在单通道图像特征提取上,它们对不同通道学习共享的卷积核,而本文使用的随机单通道掩膜相当于在卷积网络第1层学习通道特有的卷积核,通过识别通道特有的纹理更好地提取通道共享的外观形状特征。另一方面,本文进一步通过互学习探索了从单模态数据得到的三通道图像与单通道图像的关系来挖掘自监督信息用于跨模态匹配。除了消除模态鸿沟的研究思路,有小部分研究从单模态数据中迁移先验知识来帮助跨模态匹配的学习。Liang等人(2021)提出一种跨模态自训练方法,利用单模态预训练的模型通过跨模态伪标签学习无监督地提高跨模态匹配的性能。与现有相关方法对比,本文从单模态自监督信息挖掘的新角度,学习有利于跨模态匹配的先验知识,克服模态鸿沟的问题。
3)互学习。深度互学习(Zhang等,2018)是与本文密切相关的方法。其主要思想是训练多个模型,使其互为教师模型和学生模型,通过知识蒸馏(Hinton等,2015)互相迁移学习到的知识从而提高模型的判别能力。互学习的思想在行人重识别的研究领域也受到关注。例如,在单模态无监督行人重识别方法MMT(mutual mean-teaching)(Ge等,2020)和跨模态有监督行人重识别方法MPANet(Wu等,2021)中也使用了互学习。MMT用互学习探索当前模型与平均模型之间的关系,来获取更可靠的伪标签用于单模态无监督学习。MPANet用互学习拉近不同模态的输出消除模态鸿沟。本文通过把单模态数据变换为三通道与单通道两个视角,并通过它们之间的互学习挖掘有助于跨模态匹配的自监督信息,不受限于以往方法训练过程中对多模态数据同时存在的要求。
2 单模态跨光谱自监督信息挖掘
2.1 问题与符号定义


本文目标是在辅助的可见光图像数据集DRGB-A上进行预训练,挖掘对光谱范围变化具有稳定性的特征。然后在真实的多模态行人数据集DRGB和DIR上进行微调时,把预训练模型中的先验知识通过初始化参数迁移到跨模态行人匹配的下游任务上,提高模型的判别性能。
2.2 随机单通道掩膜数据增强
跨模态行人重识别问题中的模态鸿沟是由可见光图像和红外图像的成像原理不同导致的。可见光的红、绿、蓝通道与红外光的通道上的灰度值表示对物体反射不同波长光线的强度。可见光图像中的3个通道共同反映了可见光的颜色信息。在使用单模态可见光图像进行行人特征学习的时候,三通道共同反映的颜色信息是重要的判别性特征。然而,由于光谱范围不同,这对红外图像却无法适用。本文模型可以学习到跨光谱不变的特征。
可见光图像示例如图2(RGB图像)所示。分离的红、绿、蓝3个通道无法反映三通道图像丰富的颜色信息。当进行不同通道图像的对比时,比如第1个通道和第3个通道,发现行人的上下身衣服灰度值均发生了变化。如果要对不同通道的图像进行身份匹配,也就是跨光谱的匹配,学习的特征需要包含更加丰富的行人形状等细粒度信息。由于可见光图像与红外图像的匹配同样是一种跨光谱的匹配,假设对红、绿、蓝通道跨光谱匹配具有判别性的特征,在红外图像上也具有适用性。假设从不同通道的图像中提取共享的外观形状特征需要识别不同的纹理。在神经网络浅层使用通道特有的卷积核。

图2 随机单通道掩膜数据增强示意图
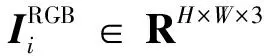
(1)

由于被随机掩膜提取的输入通道之外的两个输入通道为0,使用随机单通道掩膜相当于使卷积神经网络的第1层学习R、G、B通道特有的卷积核(Wu等,2017),通过在网络浅层识别通道特有的纹理更好地提取通道共享的外观形状特征。
2.3 三通道与单通道双模型互学习
2.3.1 基于单模态可见光图像的双模型预训练

(2)


LID-sin=Lcls-sin+Ltri-sin
(3)
判别损失函数LID-sin由交叉熵分类损失Lcls-sin和软间隔三元组损失Ltri-sin(Hermans等,2017)两部分组成。
(1)交叉熵分类损失Lcls-sin表示为
(4)

(2)软间隔三元组损失Ltri-sin表示为

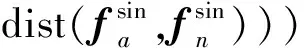
(5)
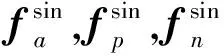
对于三通道特征提取模型MRGB,学习的目标函数LID-RGB可类比单通道特征提取模型Msin的目标函数LID-sin进行构建。
2)三通道与单通道模型互学习。三通道特征提取模型MRGB是从RGB图像学习得到的。对于与行人身份相关的判别性信息,从RGB图像中既可以提取如色度、饱和度等与颜色相关的特征,也可以提取形状、纹理等与颜色无关的特征。虽然两种特征都包含可以区分行人的信息,但模型会趋向于学习与颜色相关的特征,可以为下游任务中可见光图像的模态内匹配提供先验知识。
单通道特征提取模型Msin是从经过随机单通道掩膜数据增强后的单通道数据中学习得到的。由于模型输入的单通道数据中的信息是三通道RGB图像的子集,在缺失了不同通道组合的情况下,难以提取到色度、饱和度等与颜色相关的特征。模型会更趋向于学习形状、纹理等与颜色无关的特征。这种特征具有对光谱范围变化不敏感的特点,可以为下游任务中红外图像的模态内匹配和可见光与红外图像之间的跨模态匹配提供先验知识。
为了直观地理解三通道模型与单通道模型学习到的特征,按照上述介绍的训练方法,在UnrealPerson(Zhang等,2021a)数据集上训练了以ResNet-50(He等,2016)为骨干模型的MRGB和Msin。然后,在DukeMTMC(Duke multi-target multi-camera)(Ristani等,2016)数据集的RGB图像上进行测试。随机选择训练集中的一幅RGB图像,分别根据两个模型提取的特征的欧氏距离检索训练集中最相似的图像,得到排序列表如图3所示。在排序列表中,为显示更多不同身份的行人,同一个身份的行人图像只保留最靠前的一幅。可以观察到,对于同一幅查询图像,三通道模型检索到的图像衣着颜色与查询图像高度相似,其中也包含与查询图像中的男性行人外观形状不同的女性行人(如图3(a)红框中的第3幅和第6幅图中的女性发型与男性短发形状不同,第7幅图中的女性腿型比男性腿型细);单通道模型检索到的图像则都是与查询图像中的男性行人外观形状接近的其他男性行人,但衣着颜色则未必相近(如图3(b)红框中的第5、7、9幅图都是与查询图像的行人体型相近的短发男性,但衣服颜色不同)。观察结果与上述三通道模型和单通道模型提取特征的特点相符。

图3 三通道模型与单通道模型检索排序列表对比
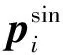


(6)

结合判别损失函数和互学习损失函数得到预训练的总体损失函数
Lpre=LID-sin+LID-RGB+wmuLmu
(7)
式中,wmu是控制互学习损失Lmu影响的权重参数。
在三通道模型与单通道模型之间进行互学习,一方面可以促进单通道模型对在缺乏颜色信息情况下容易忽略的特征的提取,另一方面可以促进三通道模型对光谱范围不敏感特征的提取。
由于单通道数据和三通道数据是从同一个数据变换得到的两个不同视角的输入,单通道模型和三通道模型的互学习可以看做是从三通道和单通道的关系中挖掘有利于跨模态匹配的自监督信息。只需作为辅助数据的单模态可见光图像,即可为下游的跨模态匹配任务提供先验知识。三通道与单通道模型互学习的示意图如图4所示。
2.3.2 基于多模态数据的双模型微调
在基于互学习的双模型预训练后,三通道模型MRGB和单通道模型Msin学习到两种不同的先验知识。虽然在互学习中两个模型的知识会相互补充,但由于输入数据的不同,两个模型仍分别侧重颜色相关特征与光谱范围不敏感特征的提取。为更有效地在下游任务中利用两种先验知识帮助有监督学习,避免预训练与微调的学习目标之间产生差异,使用与双模型预训练相同的框架(如图4所示),在多模态数据上进行双模型微调。
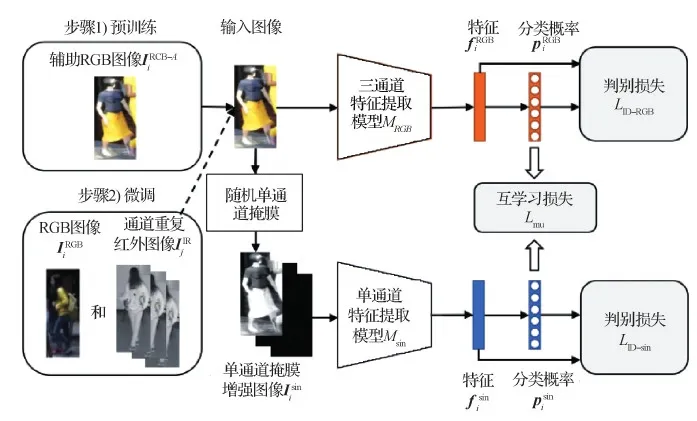
图4 三通道与单通道双模型互学习示意图
微调训练的目标函数Lfine参照式(7)中的Lpre构造。与预训练的区别在于输入训练数据的不同。微调过程除了使用可见光图像,还增加了通过上述预处理转换成三通道的红外图像。
在基于多模态数据的双模型微调中,三通道模型与单通道模型的互学习起到的作用与预训练过程类似,从可见光图像的三通道数据与单通道数据之间挖掘得到的自监督信息可提供先验知识作为正则化,提高跨模态匹配特征的判别性。
2.3.3 模型推断
在完成基于三通道与单通道模型互学习的预训练与微调之后,测试阶段由于有两个不同的模型,采用不同的推断方式。
1)三通道模型推断。对于可见光图像,直接输入三通道模型提取特征。对于红外图像,把单通道复制为三通道输入三通道模型提取特征。
2)单通道模型推断。由于单通道模型训练时的输入是应用了不同通道掩膜的图像,为保持训练和测试输入的一致性,在推断之前需要对测试图像进行预处理。对于可见光图像,参照1.2节分别使用掩膜mR、mG和mB得到3幅只包含单通道信息的图像,分别输入单通道模型进行特征提取。对于红外图像,首先把单通道复制为三通道,然后采用与可见光图像相同的方式进行掩膜处理与特征提取。最后,把提取的3个特征取平均得到融合的特征。单通道模型特征提取过程如图5所示。
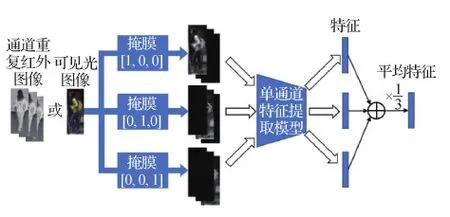
图5 单通道模型特征提取示意图
3)双模型融合推断。在计算资源允许的情况下,可以通过特征串联的方式,融合两个模型的输出作为特征。
在提取特征后,通过度量查询图像和图库图像的特征欧氏距离进行检索。
3 实 验
本文在SYSU-MM01(Wu等,2020)、RGBNT201(Zheng等,2021a)和RegDB(Nguyen等,2017)这3个多模态数据集上测试提出的基于单模态跨光谱自监督信息挖掘的预训练与微调方法,与当前先进的方法进行对比,并进行了消融实验、使用不同超参数与预训练数据集的实验。
3.1 实验设置
1)数据集。图6展示了3个数据集的一些示例图像。

图6 实验中各个数据集的样本示例
SYSU-MM01数据集由6个摄像头拍摄,其中4个是正常光照环境下的可见光摄像头,2个是黑暗环境下的近红外摄像头。拍摄的场景包括2个室内场景与3个室外场景。不同场景下的图像有光照、背景等场景变化。行人身份总数为491个,可见光图像数量为30 071幅,近红外图像数量为15 792幅。
RGBNT201数据集由4个摄像头拍摄,其中每个摄像头拍摄了同步的可见光图像、近红外图像与热成像图像。场景变化包括有天气、光照等。行人身份总数为201个,可见光图像、近红外图像与热成像图像的数量均为4 787幅。
RegDB数据集包含了一个可见光摄像头和一个热成像摄像头拍摄的412个身份的行人的8 240幅图像。对于每个身份,有10幅可见光图像和10幅热成像图像。
在提出方法的预训练过程中,需要辅助的有标注可见光行人图像数据集。在默认的实验设置下,采用3维合成的虚拟数据集UnrealPerson(Zhang等,2021a)作为辅助数据集。UnrealPerson是3维合成的大规模数据集,包含了3 000个身份的120 000幅行人图像,无需人工进行标注。使用虚拟数据进行预训练可避免使用真实数据的隐私问题。
2)测试协议。在SYSU-MM01数据集上,遵循Wu等人(2020)对训练集和测试集中查询图像和图库图像的划分。“全搜索”表示在全部摄像头的数据组成的图库图像中的搜索实验;“室内搜索”表示在室内摄像头的数据组成的图库图像中的搜索实验,难度比“全搜索”稍低。
在RGBNT201数据集上,遵循了数据集提出者Zheng等人(2021a)的测试协议。训练集身份数为141,测试集身份数为30。由于RGBNT201上有3种模态的图像,跨模态匹配分为4种情况:“可见光—近红外”表示把近红外图像作为图库图像,把可见光图像作为查询图像;“可见光—热成像”表示把热成像图像作为图库图像,把可见光图像作为查询图像;“近红外—可见光”和“热成像—可见光”是将上述两种情况的图库图像和查询图像种类交换。
对于RegDB数据集,遵循了现有方法HCML(Ye等,2018)中使用的测试协议。一半的身份用于训练,其他身份用于测试。跨模态匹配的方式有两种:“热成像—可见光”表示把热成像图像作为查询图像,把可见光图像作为图库图像,“可见光—热成像”表示把可见光图像作为查询图像,把热成像图像作为图库图像。
实验的性能指标是通过度量查询图像和图库图像之间的相似度获得的排序列表计算得到的累积匹配特性CMC(cumulative match characteristic)、Rank-k正确率和平均精度均值(mean average precision,mAP),参照Zheng等人(2015)在Market-1501数据集上的计算方法。
3)实现细节。(1)基础模型。在实现中采用了ResNet-50(He等,2016)作为骨干模型,把输入图像的尺寸调整为384×128像素,然后在输出的特征图上分割水平条带提取特征,具体参照MGN(multiple granularity network)(Wang等,2018)的模型设计。分类器层参照circle损失(Sun等,2020)的实现方式,其中circle head的间隔参数设为0.35,特征的尺度设为64。然后使用平滑参数为0.1的标签平滑操作,得到最后的分类概率。提出方法中的单通道模型和三通道模型均基于此模型实现。
(2)训练策略。由于模型参数用ImageNet预训练的参数初始化,输入数据的预处理先使用ImageNet的均值和标准差进行图像的归一化。然后应用随机水平翻转、随机裁剪、随机擦除和颜色抖动的数据增强策略。数据增强策略的参数参照He等人(2020)提出的FastReID中的策略设置。在颜色抖动策略中设置亮度变化范围为[0.8, 1.2],对比度变化范围为[0.85, 1.15]。训练过程分为预训练和微调两个步骤。在预训练过程中,默认使用单模态可见光图像数据集UnrealPerson。在微调过程中,使用需要测试的目标数据库的训练集数据。在梯度下降的的迭代过程中,使用ADAM(adaptive moment estimation)优化器(Kingma和Ba,2015)。预训练步骤分双模型单独训练和双模型互学习两个阶段。第1阶段的迭代总数为15 000次,前2 000次迭代使用warmup策略使学习率从3.5×10-6增加到3.5×10-4,之后的7 000次迭代保持学习率不变,最后6 000次迭代使用Cosine学习率下降策略。第2阶段的训练设置与第1阶段相同,区别在于加入了互学习损失Lmu,其权重wmu设置为0.1。微调步骤也参照预训练步骤分两阶段进行,区别在于每阶段迭代总次数变为8 000次,去除了预训练步骤中保持学习率不变的7 000次迭代。
(3)测试过程。默认使用三通道模型进行推断。在展示的实验结果中,“三通道模型”“单通道模型”和“双模型融合”均表示提出的方法。
4)对比方法。在SYSU-MM01与RegDB数据集上,对比了当前具有代表性的、先进的跨模态行人重识别方法,包括基于非对称建模的Zero-Padding(Wu等,2017)、基于图像和特征联合对齐的D2RL(Wang等,2019b)、基于生成对抗学习的AlignGAN(Wang等,2019a)、基于跨模态相似度保持的CMSP(Wu等,2020)、基于第3模态生成的XIV-ReID(Li等,2020)、基于多模态图像混合的CMM+CML(Ling等,2020)、基于协同注意力机制的CoAL(Wei等,2020)、基于模态“特有—共享”特征迁移的cm-SSFT(Lu等,2020)、基于密集关键点配对的方法LBA(Park等,2021)、基于神经网络架构搜索的方法CM-NAS(Fu等,2021)、基于通道增强联合学习的CAJL(Ye等,2021)和基于模态和模式联合对齐的MPANet(Wu等,2021)。在RGBNT201数据集上,由于目前已经公开测试过的方法较少,只有TSLFN+HC(hetero-center loss)(Zhu等,2020)和DDAG(dynamic dual-attentive aggregation)(Ye等,2020)有公开报告的结果。其中,CAJL是一种单通道数据增强方法。MPANet应用了多模态的互学习,是当前在SYSU-MM01数据集上性能最高的方法。对于具有代表性的先进方法LBA、CM-NAS、CAJL和MPANet,基于作者公布的代码以UnrealPerson数据集预训练的参数作为初始化进行实验,以保证与提本文方法使用相同的训练数据进行公平的对比。在实验结果中表示为“方法名(unreal)”。其中,CM-NAS由于只在SYSU-MM01和RegDB两个数据集上提供了模型架构且没有公开架构搜索的代码,不进行在RGBNT201数据集上的实验。CM-NAS的所有实验结果都是基于作者公开代码实现得到的。
3.2 实验结果对比与分析
1)消融实验。为说明方法各个部分的有效性,在SYSU-MM01上进行了如表1所示的消融实验。展示的结果是全搜索设置下的性能。所有实验都默认在ImageNet预训练参数的基础上使用UnrealPerson作为进一步预训练的数据集,除了实验0只使用 ImageNet预训练的参数。实验1是使用单个模型在可见光数据上进行预训练和在多模态数据上微调的基础模型。在实验2—实验11,预训练互学习和微调互学习两列中的内容表示是否有使用互学习的训练策略。“无”表示只使用单个模型进行训练。“有”表示使用了“互学习类型”一列中的策略进行双模型互学习。在预训练有两个模型的情况下,微调使用的单个模型选择三通道模型。在互学习类型中,“A—B”中的A和B表示互学习的两个模型输入的数据类型。“三通道—单通道掩膜”是本文方法。为说明随机单通道掩膜的作用,对比了3种引导模型学习颜色无关信息的数据增强方法,分别是使用灰度图作为输入、使用RGB三通道随机打乱的图像作为输入(表示为“乱序通道”)以及使用跨光谱图像生成方法(Fan等,2020)得到的单通道R、G、B和灰度图像作为输入(表示为“跨光谱图像”)。

表1 在SYSU-MM01数据集上的消融实验性能
结果表明:对比实验1的基础模型,在实验6和实验11中提出的预训练互学习和微调互学习两个步骤都能带来显著的性能提升。对比实验2和实验6还有实验7和实验11,结果表明“三通道—单通道掩膜”的互学习比“三通道—三通道”的互学习更有效,说明从三通道和单通道的关系中能学习到的对光谱范围不敏感的特征,对跨模态匹配更有帮助。对比实验3—实验6还有实验8—实验11,结果表明使用随机单通道掩膜比使用灰度图、随机打乱通道顺序和跨光谱图像更有助于挖掘跨光谱不变的自监督信息。实验5和实验10中跨光谱图像与提出的随机单通道掩膜一样使用了分离的单通道R、G、B图像,但性能不如本文方法。由于随机单通道掩膜方法进一步考虑了网络第1层通道特有卷积核的建模,通过在网络浅层识别通道特有的纹理更有效地提取通道共享的外观形状特征。对比实验0和实验1,说明了UnrealPerson虚拟数据的预训练对于行人重识别任务的有效性。
2)与当前先进方法的对比。在SYSU-MM01、RGBNT201和RegDB这3个数据集上与当前先进方法的对比结果分别如表2—表4所示。

表2 在SYSU-MM01数据集上的跨模态匹配性能对比
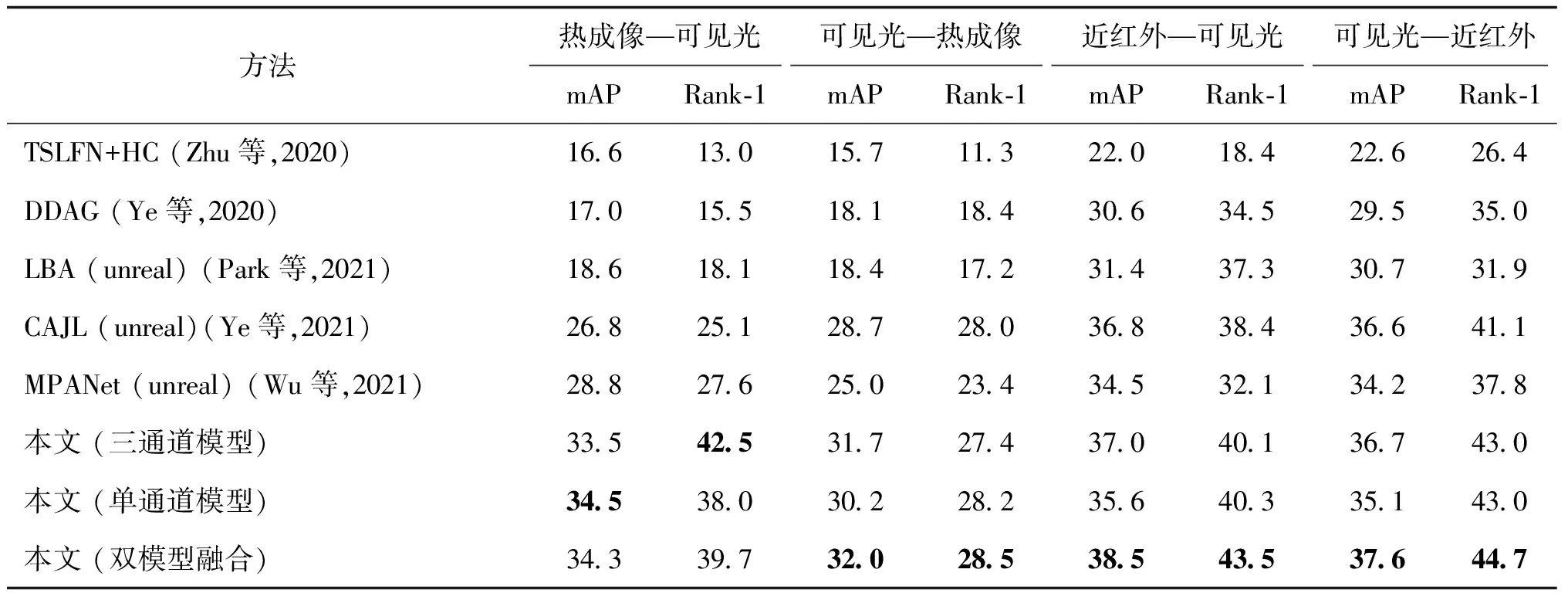
表3 在RGBNT201数据集上的跨模态匹配性能对比
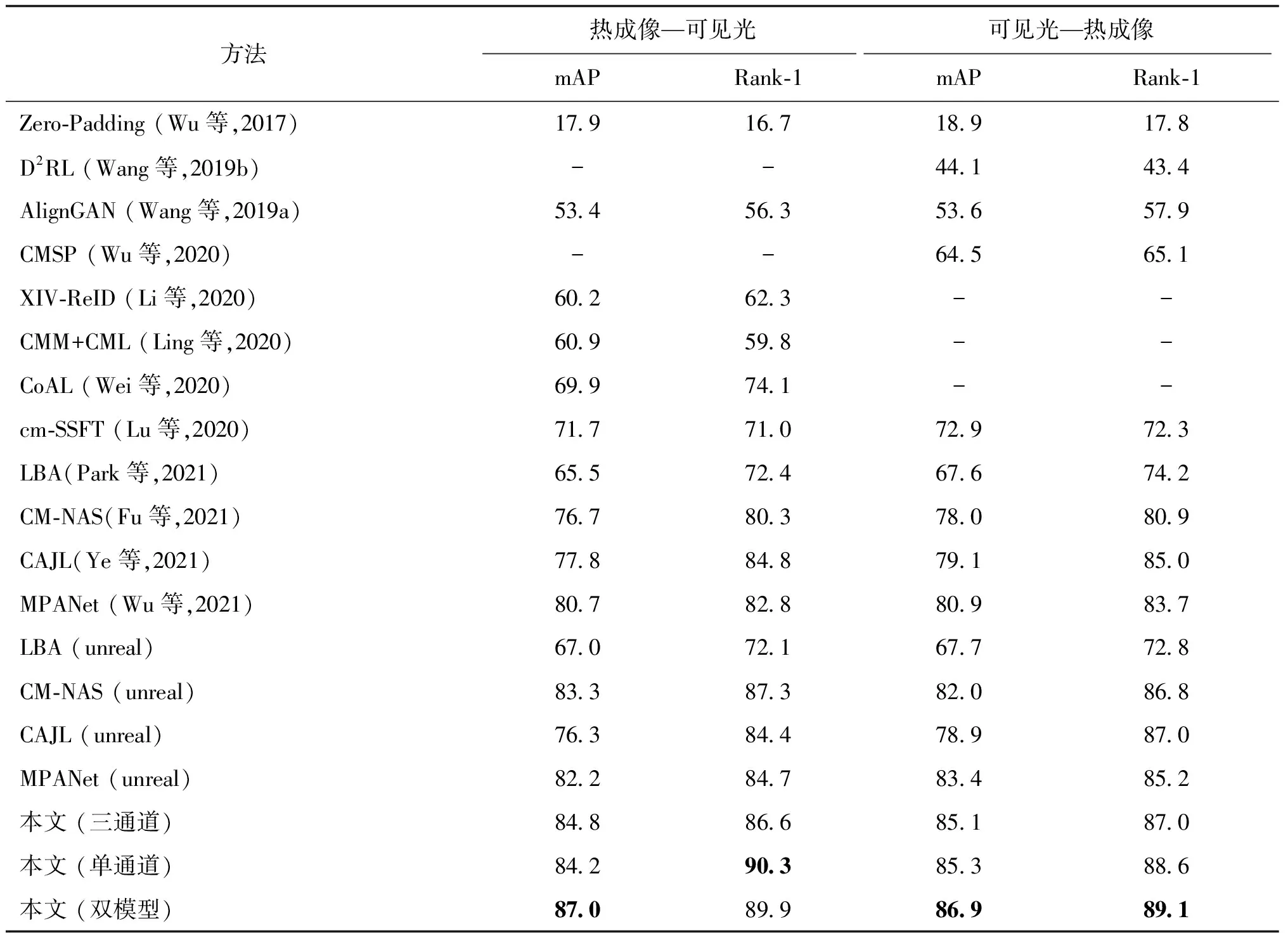
表4 在RegDB数据集上的跨模态匹配性能对比
从实验结果可得,在SYSU-MM01上,在本文方法使用三通道模型或者单通道模型单独进行测试时,取得与MPANet(unreal)相当的性能。在使用双模型融合的情况下,mAP和Rank-1的准确率取得最优的效果。在RGBNT201和RegDB数据集上,单独使用本文方法中的三通道模态或者单通道模型对比性能排第2的方法均有提升。在RGBNT201上,在热成像图像和可见光图像的匹配实验中,Rank-1准确率和mAP有接近5%的提升。对于LBA(unreal)、CM-NAS(unreal)、CAJL(unreal)和MPANet(unreal)这几种先进的方法,相比使用ImageNet预训练的结果,使用UnrealPerson进行预训练的结果在SYSU-MM01上提升不明显,在RegDB上稍有提升,但都不如使用本文双模型互学习方法。对比方法的预训练方法是使用单模态RGB图像直接训练单个模型,倾向于学习颜色相关的判别性先验知识,对跨模态匹配帮助不大。而提出的双模型互学习方法可在预训练与微调阶段都从单通道模型迁移跨光谱不变的判别性知识到三通道模型中,更有利于模型提高跨模态匹配的判别性能。
与SYSU-MM01相比,本文方法在RGBNT201和RegDB数据集上的提升更明显。在数据集的规模上,RGBNT201的训练身份数比SYSU-MM01和RegDB都少,RegDB的训练样本数比SYSU-MM01少。不同数据集上性能提升的差别说明,在目标域越缺乏监督信息的情况下,提出的自监督信息挖掘方法提供的先验知识对下游任务的提升越大。
双模型融合在大部分情况下都能相比三通道模型和单通道模型有一定的性能提升,说明两个模型在互学习后提取的特征仍具有互补性。在少数情况下,比如在RGBNT201上“热成像—可见光”设置下的结果,互学习有可能使双模型的知识比较完全地进行互相迁移,导致双模型互补性变弱,但是双模型融合的结果仍与最优的单模型结果相当。在计算资源允许的情况下,使用双模型提取特征进行融合以获得更好的效果。
3)预训练模型对现有方法的提升作用。为验证提出的预训练方法的通用性,基于在单模态的虚拟行人数据集UnrealPerson(Zhang等,2021a)上进行三通道与单通道双模型互学习得到的三通道模型参数作为初始化,使用具有代表性的先进方法LBA、CM-NAS、CAJL和MPANet进行学习(表示为“方法名(unreal + 提出的预训练)”),并与使用UnrealPerson直接训练单个模型作为初始化的实验(表示为“方法名(unreal)”)进行对比。
在SYSU-MM01数据集全搜索设置、RGBNT201数据集的“热成像—可见光”设置以及RegDB数据集的“热成像—可见光”设置下得到的实验结果如表5所示。使用提出的双模型预训练方法(表示为“(unreal + 提出的预训练)”)的性能高于使用一般的单模型预训练方法(表示为“(unreal)”),表明了三通道与单通道双模型预训练的有效性。三通道模型在SYSU-MM01数据集上取得与对比方法相当的性能,而在样本数更加受限的RGBNT201数据集和RegDB数据集上能取得更优的性能。
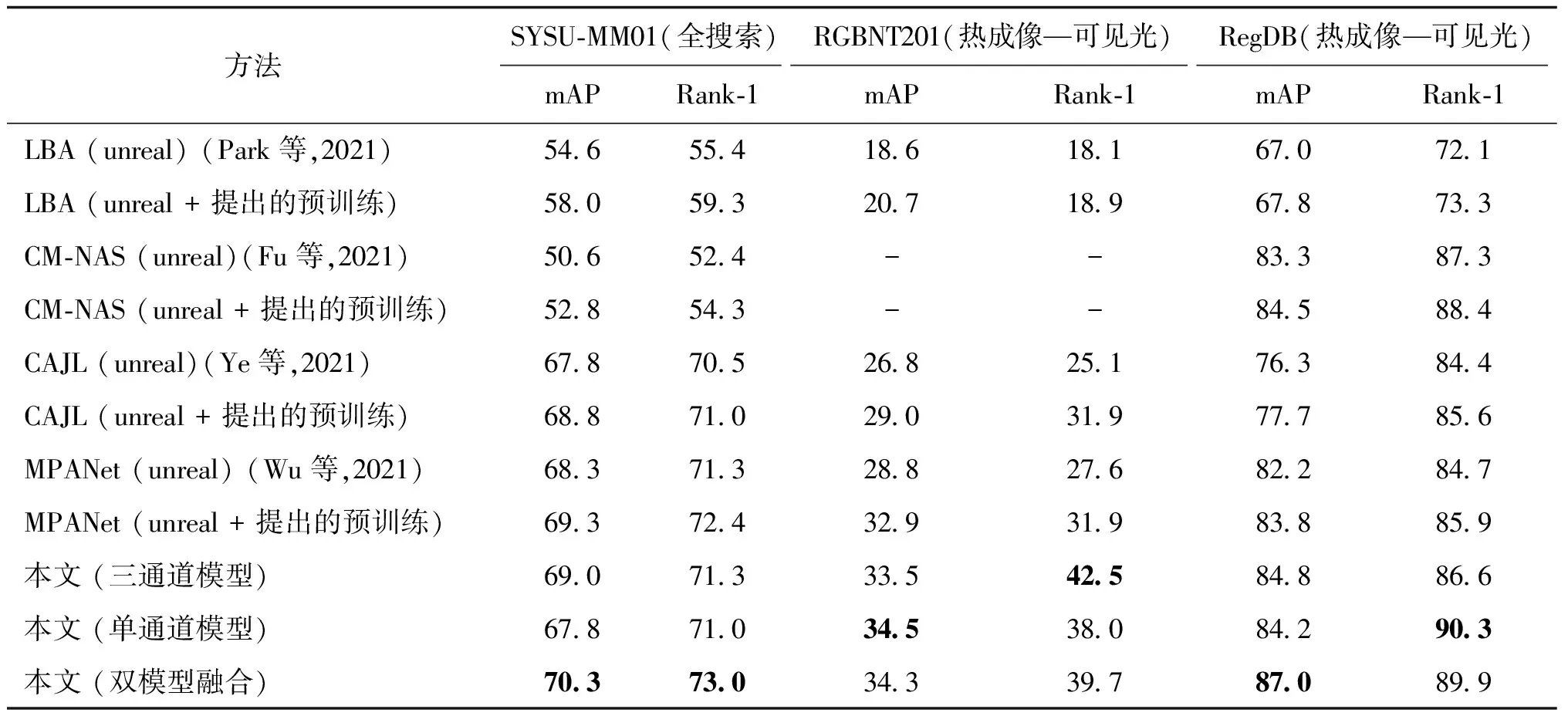
表5 把本文提出的预训练应用到其他现有方法的性能

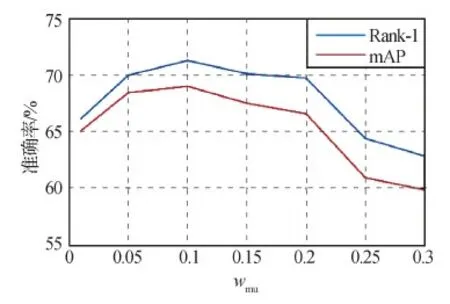
图7 互学习损失权重wmu的影响

表6 不同预训练数据集在SYSU-MM01的性能对比
基于ResNet-50默认架构的实验访问链接https://github.com/wuancong/cjig_supplementary/blob/main/附录.pdf。
4 结 论
本文研究“可见光—红外”跨模态行人重识别,适用于跨正常光照与低照度场景进行行人匹配的情况。造成跨模态行人重识别性能不理想的难点主要是图像视觉差异导致的模态鸿沟以及标注数据缺乏。为解决这些问题,本文研究如何利用易于获得的有标注可见光图像作为辅助,挖掘单模态自监督信息来提供跨模态匹配的先验知识。主要创新点有两方面:1)提出一种随机单通道掩膜的数据增强方法,促使模型学习对光谱范围不敏感的特征;2)提出一种三通道与单通道双模型互学习的方法,从三通道数据与单通道数据的关系中挖掘跨光谱自监督信息,使这种先验知识在预训练和微调过程中在双模型之间互相迁移和补充,提高跨模态匹配模型的判别能力。在 “可见光—红外”多模态行人数据集SYSU-MM01、RGBNT201和RegDB上进行的跨模态行人重识别对比实验表明,本文方法能有效地利用单模态可见光图像辅助数据挖掘对光谱范围变化不敏感的自监督信息以帮助跨模态匹配,达到当前最优的性能。
提出的互学习方法需要在训练阶段使用双模型同时进行训练,虽然测试过程可以只使用单模型,但是训练过程中的开销比一般情况下的单模型训练大一倍。进一步的工作可以考虑在互学习的框架中研究共享参数、模型压缩和知识蒸馏等新方法实现计算开销的减少。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
汽车工程师(2021年12期)2022-01-17
意林(2021年5期)2021-04-18
扬子江(2019年1期)2019-03-08
成长·读写月刊(2018年8期)2018-08-30
电子技术与软件工程(2017年23期)2018-01-17
中国科技纵横(2017年15期)2017-09-09
小天使·一年级语数英综合(2017年6期)2017-06-07
科技传播(2017年2期)2017-04-06
科技资讯(2015年8期)2015-07-02
