
基于一维卷积神经网络的气体识别方法研究*
2022-10-20 01:09鹏徐永凯杨佳康陆
电子器件 2022年3期
李 鹏徐永凯杨佳康陆 一
(1.南京信息工程大学,江苏省气象探测与信息处理重点实验室,江苏 南京 210044;2.南京信息工程大学,江苏省大气环境与装备技术协同创新中心,江苏 南京 210044;3.南京信息工程大学滨江学院,江苏 无锡 214105)
随着我国工业的迅猛发展,在日常生产生活中,由危险化学气体泄漏而引发的灾难性事件时有发生,这对人们的生命财产造成极大威胁,也引起社会的广泛关注及相关部门的高度重视。这些泄漏气体一般不是某种单一气体,以混合气体居多,因此如何快速、准确地识别混合气体中的组分是一项重要研究工作。而人工嗅觉的智能检测应用极为广泛,在气味识别、环境监测、食品质量监管[1]、医疗卫生[2]及公众安全[3]等领域发挥着重要的作用。因此,可以利用人工嗅觉对工业生产及日常生活中泄漏的混合气体进行识别与分类。
人工嗅觉(Artificial Olfaction,AO)模仿生物的嗅觉系统,一般采用气敏传感器阵列与模式识别算法相结合的手段对被检气体进行定性分析,从而达到对混合气体进行识别与分类的目的。金属氧化物半导体(metal oxide semiconductor,MOS)气敏传感器具有成本低、反应速度快、使用寿命长等优点,因此常被用来构建传感器阵列。但MOS 气敏传感器具有交叉敏感性[4],即一种类型的气敏传感器可同时对多种气体发生反应,这对人工嗅觉的分类效果影响很大。若通过改进金属材料来改善气敏传感器的性能较为困难,且研发周期较长、成本高,而从气敏传感器阵列与人工智能算法相结合的角度更容易实现[5]。通过气敏传感器阵列与相关算法相结合,可实现对混合气体定性分析的目的,从而为后续气体浓度的定量分析提供重要支撑。
近年来,为了提高人工嗅觉的检测准确度与精度,许永辉[6]、谭光韬[7]、陶孟琪[8]、Zhang L[9]、Yoo Y[10]、Sunny[11]等均做了很多努力。以上各类方法的大致过程是通过人工设计特征提取函数对传感器响应值进行相关特征提取,如响应稳态值、响应基值、响应时间、响应恢复时间等,然而此类传统方法中人工特征提取函数的设计过程较为复杂,分类准确度很大程度上取决于特征提取函数设计效果的好坏,且特征提取函数不能根据响应信号进行自适应调整,而卷积神经网络具备自适应特征提取能力,因此可以应用在气体分类上。而气敏传感器的输出信号为一维时间序列,因此本文基于一维卷积神经网络(One-Dimensional Convolutional Neural Network,1D-CNN)进行改进,实现对被测混合气体的识别与分类。
1 卷积神经网络算法
卷积神经网络(CNN)在二维信号处理方面应用最早,尤其在图像处理方面的应用,如最早的手写字识别[12]、图像检索[13]、人脸识别[14]等,随着技术的发展,研究人员开始尝试将CNN 用来处理三维信号如行为识别[15]、医学诊断[16]等与一维信号如语义识别[17]、文本识别[18]、心电识别[19]等,均表现出良好的应用效果。本文采用一维卷积神经网络对混合气体进行识别,与传统方法的不同之处在于不需要人工设计特征提取函数对信号进行特征提取,可以节省不少时间。因为特征提取函数设计往往较为复杂,对每一特征提取就需要设计一次函数,复杂程度高、难度大,且提取效果也并不是每次都能尽如人意,而卷积神经网络可自动、全面地对原始数据进行特征提取与学习,比较适合完成对混合气体进行分类的任务。
1.1 一维卷积神经网络基本原理
本文所提出的1D-CNN 主要包括输入层、隐含层、全局平均池化层、输出层,如图1 所示为一维卷积神经网络的结构图,整个网络有四个隐含层,其中每个隐含层包括两个卷积层、一个池化层与激活函数(tanh 函数)。卷积层用来提取传感器阵列原始信号的特征,可以改善MOS 传感器的选择性;而池化层可以保留显著特征、降低特征的维度,从而减小数据运算量与复杂程度。原始相应信号通过输入层输送至神经网络,经过各隐含层的特征提取、池化降维等操作,最后通过softmax 函数对响应信号进行分类。
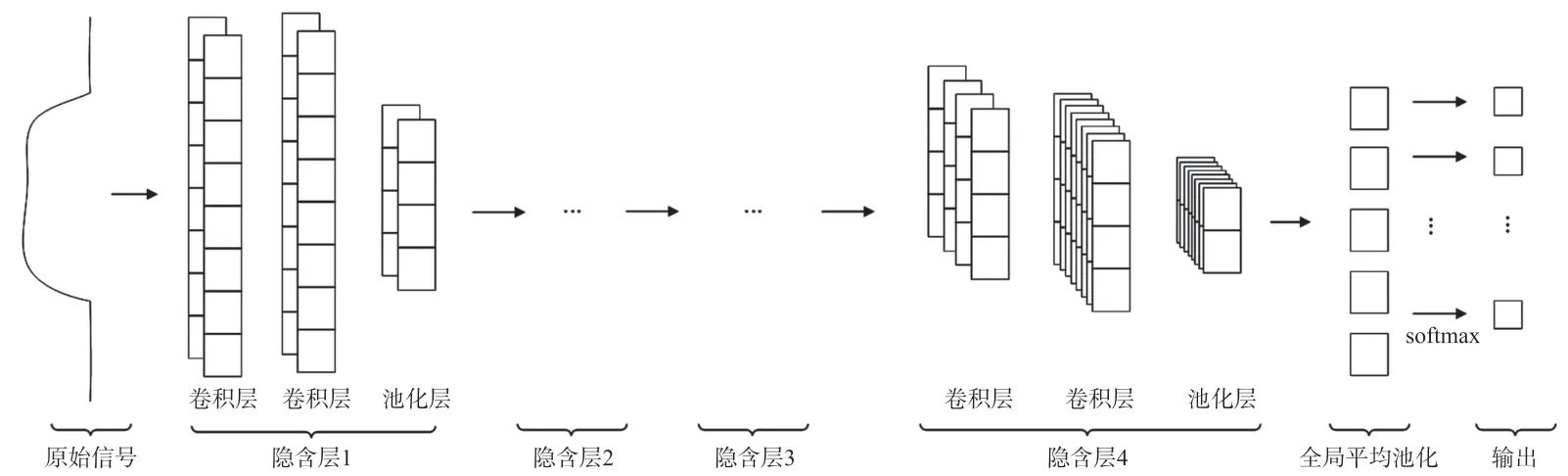
图1 一维卷积神经网络结构图
1.2 特征提取与分类
一维卷积神经网络[20-21]主要通过卷积运算提取输入数据的特征,可有效降低原始数据对后续操作的噪声干扰,从而提高分类结果的准确率,其输出特征图作为下一层输入。常见二维卷积提取的特征既与水平方向相关[22],又与垂直方向相关,而此处一维卷积提取的特征仅与水平方向相关,且气敏传感器输出的响应信号是一维时间序列,而非二维图像的像素点,因此非常适合用一维卷积运算对输出的响应信号进行特征提取。一维卷积运算的示意图如图2 所示,其表达式如(1)所示,xj代表输出,表示第j层卷积层的第i个一维卷积核的输出。
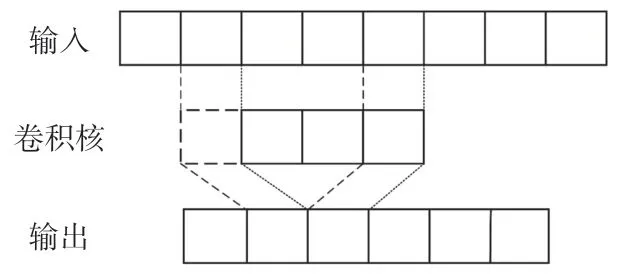
图2 一维卷积运算示意图
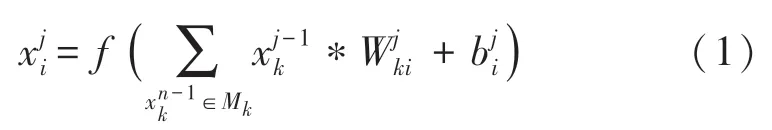
式中:M为输入数据集,为卷积核,*为卷积符号,b为偏置项,f为激活函数。在本文中,四个隐含层的卷积核大小分别为1×16×8、1×4×16、1×4×256、1×2×512,其中8、16、256、512 分别为卷积核的数量。
本文特征提取部分采用每个隐含层两个卷积层加一个池化层的结构,可以进一步提取数据的相关特征,同时池化采用最大池化,以去除冗余信息、减小数据的尺寸,而不改变数据的维度,也不涉及权重与参数更新,这样可以有效减轻神经网络的结构负担与运算量。最大池化的表达式如(2)所示,这里池化步长为2。

一般卷积神经网络的结构会在网络最后的池化层后加两个全连接层(Fully Connected Layer,FC)[23],全连接层的作用是将上一层得到的特征图延展为向量,再对向量进行卷积,以降低其维度,但这将大大增加模型复杂度、降低训练速度,容易导致过拟合现象的出现,而全局平均池化(Golbal Average Pooling,GAP)则可改善这一不利因素。因气敏传感器的输出响应信号在时间域上是连续、相关的,对其进行GAP 操作可以保证采样特征的连续性,并可有效去除冗余信息,提高运算效率,减少过拟合出现的概率。同时,在全局平均池化层后加入Dropout 层,可减少中间特征的数量、提高运算效率,增强模型的泛化能力,预防过拟合现象的出现。
如果分类标签采用独热编码的话,混合气体分类的数目会随着混合气体种类呈现指数型的增加,例如如果某种混合气体含有m种成分,则会产生2m个标签,这样标签维度将会变得很大,为有效降低标签维度,本文采用将独热编码转换成多标签分类方法,如表1 所示,“0”代表没有这种气体,“1”代表有这种气体,多标签分类可将独热编码的(0,0,0)转换成0 表示,可有效解决独热编码标签尺寸大的问题。
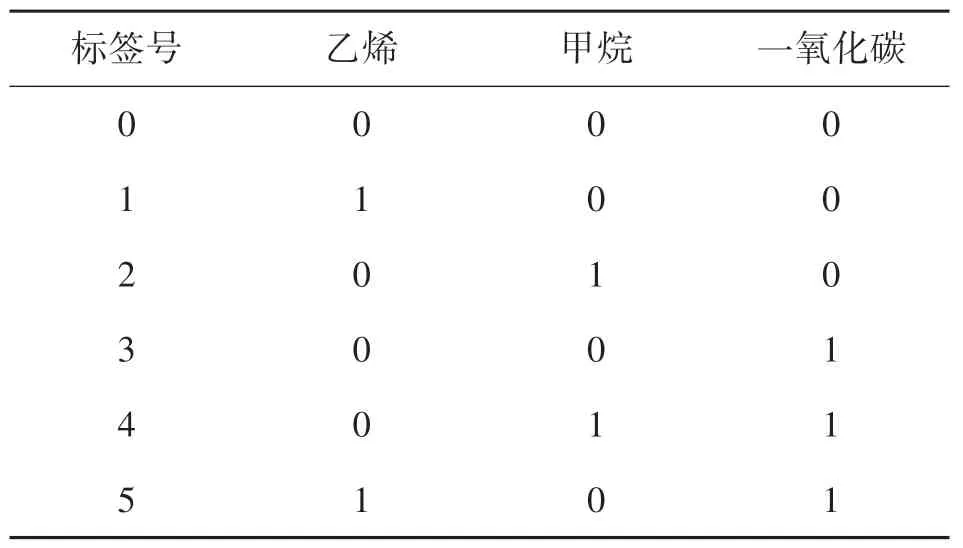
表1 混合气体标签
最后再通过softmax 函数对输入数据进行分类并利用分类交叉熵函数计算损失。softmax 函数常用来解决多分类问题,其表达式如式(3)所示。

式中:xk为第k个节点的输出值。softmax 函数首先对输入信号进行指数变换,这样可以将多分类的数值转换为[0,1]且和为1 的概率分布,而得到数值可看作该输入的处理结果而被分为某一类的近似概率,并将其划分为对应概率最大的标签类。
最后对其进行预测分类与损失计算如式(4)、式(5)所示。

式中:ypre为对目标气体的预测,yprei为预测正确的概率,WT为权重,b为偏置,yi为真实标签,n为分类标签数,最终将交叉熵函数作为训练的损失函数,损失函数输出值越小,则说明模型训练越好。如果预测值与真实值越接近,交叉熵函数输出值就越接近0,而若预测值与真实值误差较大,在反向传播训练过程中,各种参数调整幅度也会随之变大,从而使模型更快地收敛。
2 实验数据的获取
实验数据的获取需要搭建数据采集系统,这里针对甲烷(CH4)、一氧化碳(CO)、乙烯(C2H4)及两种混合气体进行采集数据,整个数据采集系统的框图如3 所示。
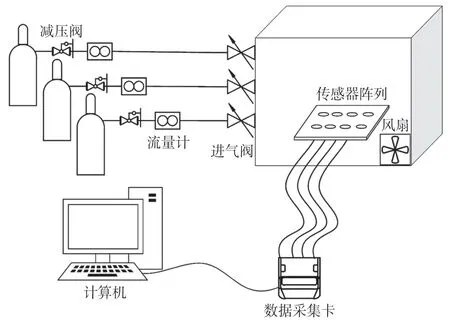
图3 数据采集系统
整个数据采集系统主要由气瓶、气敏传感器阵列、数据采集卡及计算机等组成。其中三个气瓶分别存有甲烷、一氧化碳和乙烯,可根据需求配制不同浓度的单一气体或混合气体。配置浓度计算公式如式(6)所示。

式中:Q为需要输送至配气箱内的气体体积,单位为mL,C为所需配置气体浓度ppm(parts per million,百万分比),V为配气箱的有效容积,单位为mL,此处V=27 cm×27 cm×28 cm=20 412 cm3,则V的取值为20 412 mL,这里高压气瓶里的气体经减压阀降至0.1 MPa 再经流量计输送至配气箱内,所以可以忽略压强的影响。如需配置100×10-6的CO,根据式(6)可计算出Q=100×10-6×20 412 mL=2.041 2 mL,即需向配气箱内输送2.041 2 mL 的CO 气体即可。传感器阵列由四种不同型号的传感器组成:分别为费加罗公司TGS2600、TGS2610、TGS2611 和TGS2620,表2 列出了不同传感器可与发生反应的气体。当目标气体进入MOS 气敏传感器,与其内部半导体元件发生反应时,半导体元件会发生还原反应,释放热量,使得元件温度升高,电阻发生变化,可以利用这一特性,将气体组分和浓度转换成电信号进行输出。

表2 传感器阵列选型
实验配气采用静态配气法,首先每次配气前先用纯净氮气清洗实验箱3 min,待输出响应值基本稳定后根据式(6)进行不同浓度的气体配置,输入气体体积通过流量计瞬时流量和时间相乘可以得出。同时用数据采集卡记录气体与传感器阵列反应的输出响应信号,此处数据采集卡的采样频率设置为10 Hz,每次采样时长为5 min,采集不同浓度甲烷、一氧化碳、乙烯及两种混合气体,其中三种单一气体取值为0~500×10-6,间隔为100×10-6,如表3 所示;混合气体浓度分布如表4、表5 所示。
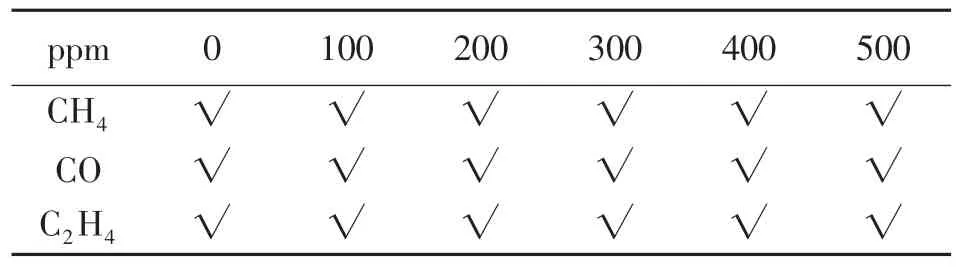
表3 单一气体浓度
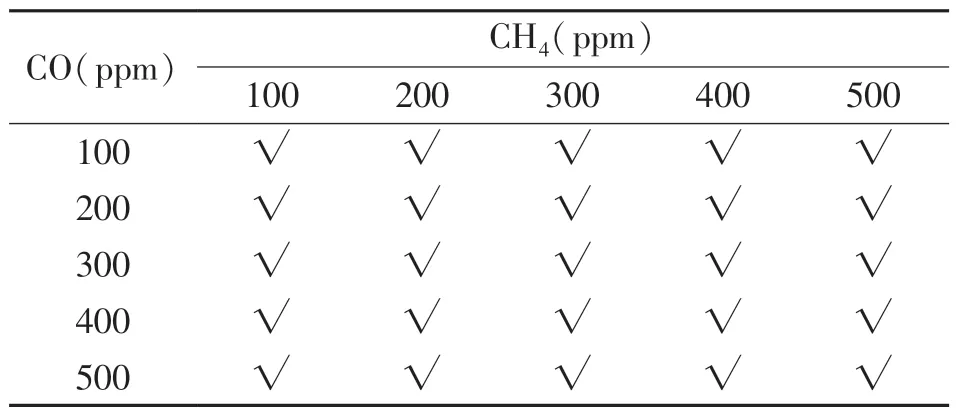
表4 甲烷、一氧化碳混合气体浓度
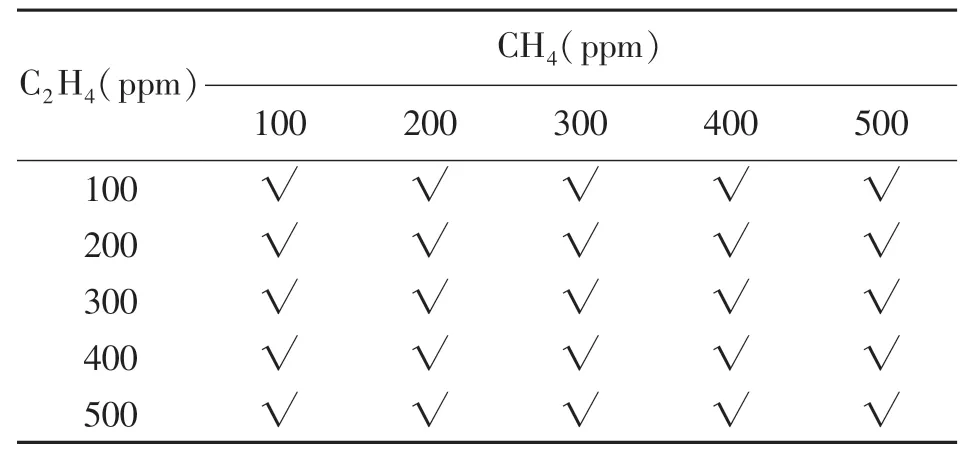
表5 乙烯、一氧化碳混合气体浓度
每组数据采集60 次,共计获得4080 条数据,训练样本与测试样本的数据量比例为7∶3。
3 气体检测方法流程
图4 所示为整个气体识别算法流程图,整个过程主要分为两个阶段:训练阶段和测试阶段。首先通过气敏传感器阵列与目标气体发生反应采集相关数据,在训练阶段,对采集到的数据贴上标签,并随机打乱排列顺序;通过隐含层的卷积运算与池化操作对响应信号进行特征提取与降维处理,并通过反向传播更新权重,保存最优模型参数。测试阶段,通过前期训练好的模型,对输入数据进行分类,得出识别结果。
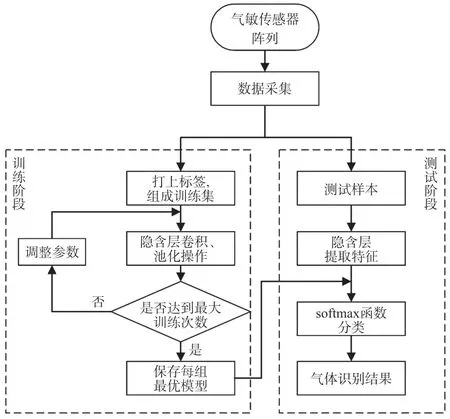
图4 气体识别算法流程
4 实验结果与对比
实验选取甲烷、一氧化碳、乙烯及两种混合气体的实验数据作为训练样本,采用改进一维卷积神经网络对其进行识别与分类。除了选用改进前的1D-CNN算法比较外,还与其他传统算法如支持向量机(Support Vector Machine,SVM)、主成分分析法(Principal Component Analysis,PCA)、K 最近邻(K-Nearest Neighbor,KNN)做对比,因SVM、PCA、KNN 不能进行数据特征的自动提取,需人工设计特征提取函数。如图5 所示为四种传感器对浓度为200×10-6的CO 浓度响应曲线,可看出每种传感器的响应基值(传感器在空气中输出电压值)、响应建立时间(响应值从基值上升到最大响应值的90%所用时间)、响应恢复时间(响应值从最大响应值下降了90%所用时间)均有差异,可根据这些特点进行特征提取函数的设计。

图5 不同传感器对200×10-6 CO 的响应
如图6 所示,(a)、(b)为改进前1D-CNN 的训练准确率和损失率,可以看出训练结果收敛性较差一些,最佳准确率最终达到92%左右;(c)、(d)分别为改进后1D-CNN 的训练准确率和损失率,收敛性较好且最终训练识别准确率基本接近100%、损失率接近0,可以看出利用卷积神经网络自动提取的特征对数据进行分类,具有准确率高、损失小的优势。

图6 训练结果图
为进一步说明本文所提出的改进1D-CNN 算法在气体识别与分类方面的性能,表6 列出了不同方法在气体检测性能方面的比较,这里1D-CNN 与改进的1D-CNN 参数设置相同,batch size 为20,优化器Adam 学习率为0.000 35,dropout 设为0.35;CNN+SVM 中CNN 参数保持同上,SVM 惩罚系数C设为0.9,采用线性内核;长短期记忆网络(Long Short-Term Memory,LSTM)batch size 为20,步长设为2,隐层为256,学习率为0.001;极限学习机(Extreme Learning Machine,ELM)正则化系数的倒数C 设为10,学习率设为0.3,可以看出相较于未改进的1D-CNN 算法,改进后的1D-CNN 算法在分类准确率上有7.62%的提高,而相比于其他三种算法,它们的训练准确率在70%~80%之间,均没有改进后的1D-CNN 算法训练准确率高,因此改进后的1D-CNN 算法在准确率上占据优势。

表6 不同方法准确率
5 结论
针对金属氧化物半导体气敏传感器阵列在气体检测时选择性差的问题,本文通过搭建改进的1DCNN 网络结构和数据集进行模型的训练,实现了对甲烷、一氧化碳、乙烯及两种混合气体的识别与分类。实验结果表明1D-CNN 复杂特征提取能力优于传统算法,不再依赖人工特征提取,简化了特征提取过程,同时分类准确率也相应提升,也为后续气体组分的浓度估计提供了重要支撑。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
计算技术与自动化(2022年1期)2022-04-15
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
电机与控制学报(2018年9期)2018-05-14
软件(2017年6期)2017-09-23
