
基于Unet 的多任务医学图像语义分割模型*
2022-10-20 01:09沈旭东楼平吴湘莲朱立妙雷英栋
电子器件 2022年3期
沈旭东 ,楼平* ,吴湘莲 ,朱立妙 ,雷英栋
(1.嘉兴职业技术学院智能制造学院,浙江 嘉兴 314036;2.同济大学浙江学院机械与汽车系,浙江 嘉兴 314051)
气胸是指气体进入胸膜腔,造成积气状态,气胸对于人类的生命是很大的危险,一般判断正确率仅在50%,其中通常的方法是通过X 光片进行诊断,但是X 光片须有经验丰富的医生才能判断。当前随着深度学习技术[1]的不断发展,通过深度学习模型就可以很快地识别出是否患有气胸疾病,并且能够判断出病灶的位置,而且通过网络模型预测病人是否患有气胸也将很大程度上减轻医生的负担,可以提供有效的辅助手段。
在使用传统Unet 模型[2-3]进行语义分割的过程中,遇到的第一个问题是,正样本召回率低,如图1 所示,X 光片有气胸病灶,但是通过语义分割模型预测的过程,没有识别出来;第二个问题是,能否在原有的基础上,设计更好的网络结构,进一步提高语义分割的精度。第一个问题原因在于Unet 是针对点对点的像素级别的语义分割模型,不能从全局的角度进行有无病灶的判断,因此对于小的病灶,单纯地使用Unet网络进行分割,无法得到很好的预测结果,本文在经典Unet 网络的基础上做了改进,引入“分类”和“分割”多任务策略进行学习,通过对不同的图像在全局上进行有无病灶二分类学习,再对每个图像上的单个像素进行语义分割,将两者的损失函数进行融合,通过这种方法可以提高正样本预测的准确率。对于第二个问题,传统的解决方式是增加网络的体积,但是调大神经元的数量来设计更深层次的网络结构,将会导致占用非常大的硬件资源,而且也会使得训练变得非常困难[4],本文在网络结构的改进上,采用Resnet34[5-6]作为编码框架,设计了空间通道压缩与激发(Spatial-Channel Sequeeze & Excitation,SCSE)模块进行修正,提高训练预测的精度。
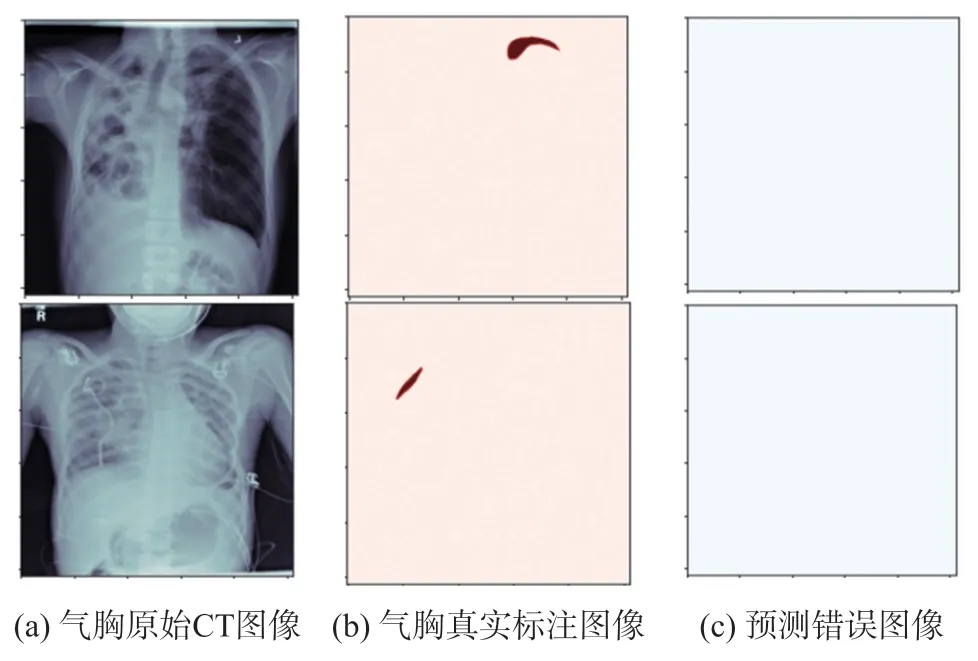
图1 气胸CT 图像预测错误
1 网络模型结构设计
1.1 总体设计
本文设计了一种针对气胸CT 图像的端到端语义分割模型,采用编码、解码的网络结构,在设计二分类网络和语义分割网络时,其中编码阶段的基础特征提取网络是很重要的一部分,由于获取海量气胸CT 图像的难度比较大,本文采用以Resnet34 为框架的带预训练参数的Unet 模型作为特征提取网络,因为它通过在网络中增加残差网络的方法,解决了网络深度到一定程度,误差升高,效果变差,梯度消失现象明显[7],使得网络反向传播求最小损失难以实现的问题。在编码阶段,引入SCSE 模块结构,得到图像二分类损失,解码时融合编码阶段各层特征信息,进行上采样,对上采样的各层特征信息再进行融合,得到语义分割图像,再对图像二分类和图像语义分割两者的损失函数进行融合,调整权重关系,得到全局损失函数,再进行优化,最终得到预测图像。具体结构如图2 所示。
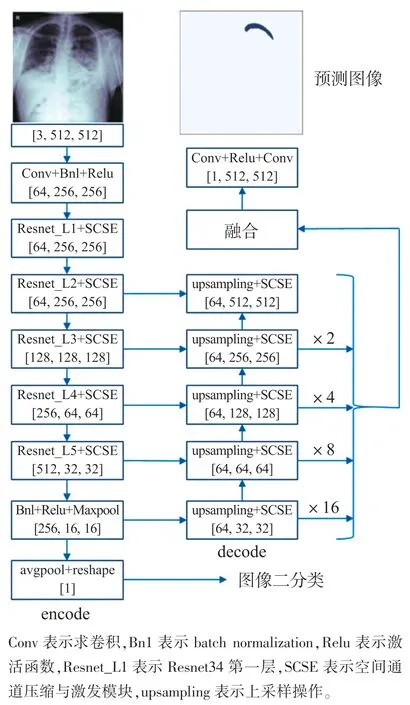
图2 网络模型结构设计
1.2 SCSE 模块设计
假设输入图像X∈ℝH×W×C,通过编码模块Resnet34 和解码模块上采样生成输出特征图U∈ℝH×W×C′,H和W表示图像的空间高度和宽度,C和C′表示输入和输出的通道数量,通过卷积和非线性变换操作后,U中包含了X中空间和通道信息,我们在每次编码或解码操作后,引入SCSE 模块,将U修正为U′,SCSE 模块实现方式如图3 所示,主要有空间压缩模块和通道压缩模块两部分组成。
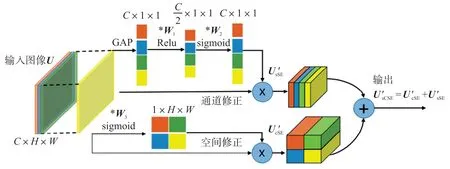
图3 SCSE 模块结构图
空间压缩模块设计如下,假设输入特征图U=[u1,u2,…uC],其中ui∈ℝH×W代表每个通道的特征图,通过全局平均池化[8-9](global average pooling,GAP)操作,得到向量z∈ℝ1×1×C,对于第k个通道特征图变换如式(1):
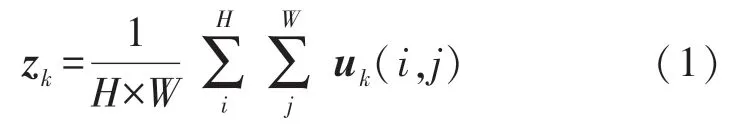
该变换在z中引入了全局空间特征信息,再通过z′=W1(δ(W2z)),得到z′,其中W1∈,W2∈为两个全连接网络,δ(·)为ReLU[10]操作。再通过sigmoid 变换,得到归一化修正系数σ(z′)∈[0,1],最终通过修正系数乘以输入特征图U,得到,如式(2):

通过该模块,不重要的通道内信息会减小,被抑制,而重要通道内的信息几乎保持不变,变相得到增强。
通过上述空间压缩信息,从而获得衡量通道重要性的指标,我们也可以通过压缩通道信息,获取衡量空间位置重要性的指标。同样对于输入特征图U=[u1,u2,…uC],通过转换得到
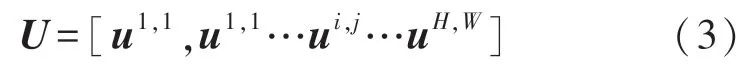
式中:ui,j∈ℝ1×1×C代表对应的空间位置(i,j),通过q=Wsq*U卷积操作实现空间挤压操作,再通过sigmoid变换,得到归一化修正系数σ(q)∈[0,1],最终通过修正系数乘以输入特征图U,得到,如式(4):
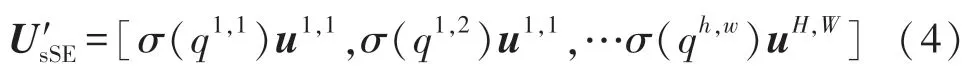
通过相加得到两者的融合信息,最后得到对空间信息和通道信息重要性都做了权重处理的输出。如式(5):

1.3 多任务学习策略
在对气胸CT 图像进行语义分割时,为了减少噪声干扰,当分割得到的图像像素点求和小于一定数量时,预测该图像为无病灶特征,因此相当于用语义分割算法做了二分类操作,但是语义分割模型以及损失函数只考虑了单个像素点的分类,没有考虑整张图片所有像素点求和的整体分类[11-12],因此在优化的过程中只是针对局部进行优化,没有考虑到对整体进行优化,针对这个问题,本文引入了多任务学习策略,直接使分类和语义分割两个网络共用同一个网络结构,提取特征图,而不是分别使用两个独立的网络,结构如图4 所示,在保证整个网络结构不变的情况下,设置多个任务“分类”和“分割”,对于二分类,本文引入逻辑斯特损失函数loss1,对于分割任务,本文引入交叉熵损失函数loss2,在训练时,首先通过单独的两个损失函数分别计算分类和分割两个输出的损失,再计算这两个损失的加权和作为网络的损失,最终得到融合的损失函数loss=a×loss1+b×loss2,其中a、b为两者的权重值。
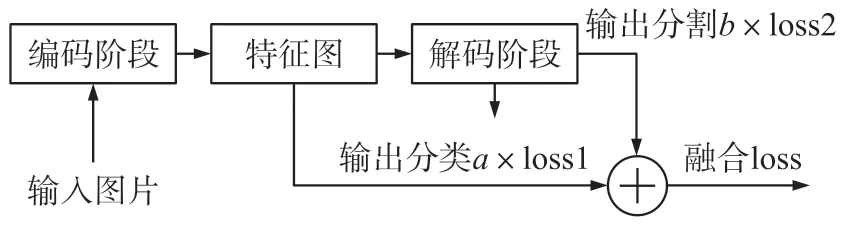
图4 多任务学习结构图
2 实验和分析方法
2.1 数据集及处理方法
本文所用数据集包含了原始图像及标注的分割图像,标注的分割图像由RLE(Run Length Encoding)编码,整个数据集包含12 047 张原始图像及标注好的分割图像,如图5 所示,尺寸为1 024×1 024 pixel,将所有图像分为训练集数据和验证集数据,其中训练集占90%,验证集占10%。由于GPU 容量的限制,将原始1 024×1 024 pixel 图像重新整形为512×512 pixel,为了进一步扩大数据集的容量和提高网络模型的泛化能力,将图片进行随机水平翻转、垂直翻转、旋转、亮度变换,高斯模糊,透视变化等操作,随机比例为50%。
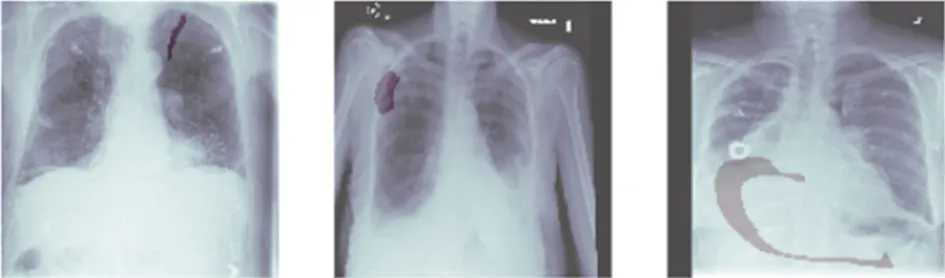
图5 带标注的数据集
2.2 评价指标
评价指标用于衡量网络模型的好坏,可以说明模型的性能,辨别模型的结果。本文所采用的模型使用Dice 作为评价指标[13],Dice 系数是一种集合相似度度量指标,通常用于计算两个样本的相似度,取值范围为[0,1],分割结果最好时值为1,最差时值为0,在该模型中,用于检测预测病灶和真实病灶的相似度,如式(6):

2.3 训练相关细节
本文在设计相关实验时,采用pytorch 框架进行设计,实验所用图形工作站配置为:4 核CPU,内存16G,GeForceGTX1080Ti GPU,显存16G,操作系统Ubuntu 16.04,网络模型配置如下:优化器采用随机梯度下降,momentum=0.9,weight_decay=0.0001,LearningRate=0.002,由于单张图片为512×512 pixel,图片较大,批处理大小设置为4,为了增加批处理大小,本文采用梯度累加实现“显存扩大”,进行N次前向后反向更新一次参数,相当于扩大了N倍的batchsize,即每次获取1 个批处理的数据,通过梯度下降法,计算梯度,梯度不清空,不断累加,累加一定次数后,根据累加的梯度更新网络参数,然后清空梯度,进行下一次循环。一定条件下,batchsize 越大训练效果越好,梯度累加则实现了批处理量的变相扩大,本文设置累加次数为4 倍,相当于将批处理大小设置为16。
2.4 实验结果及分析
(1)多任务学习策略对比分析
本文在多任务学习策略中,采用对“分类”和“分割”两种损失函数进行加权平均的方式,根据多任务损失函数loss=a×loss1+b×loss2,a、b为两者的权重值,对a、b两者取不同的值进行对比分析,实验结果如表1 所示,a、b实际为气胸图像良恶性判别和语义分割的损失权重之比,在训练时,有可能出现某一任务的偏重明显大于其他任务的情况,这样可能使有些任务的训练效果较差,所以在这里加入损失权重,来对每个任务的比重进行调节,以防止某个任务的训练效果较差。针对不同的权重系数,采用Unet+Resnet34+SCSE 网络模型进行对比分析,实验表明对于该任务,分类loss 权重a=0.1,语义分割loss 权重b=0.9 时预测效果最好。
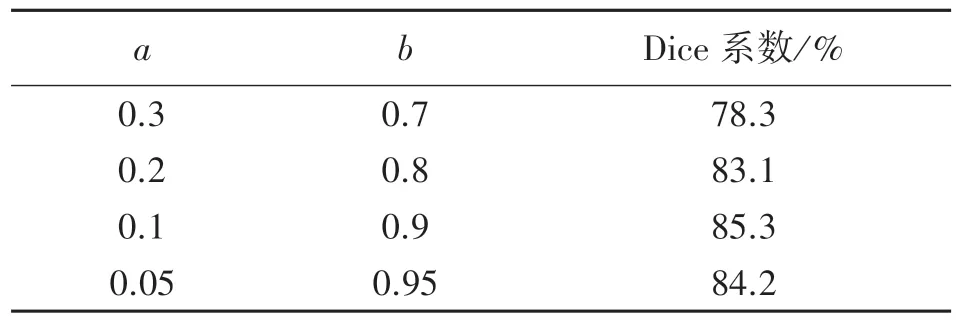
表1 不同权重系数预测对比结果分析
(2)不同网络模型对比分析
不同网络模型对比分析结果如表2 所示,本文设计的模型在预测气胸CT 图像时,其中Dice 相似系数得分达到85.3%,成绩与目前最好“五折交叉验证训练模型”接近,但简化了模型结构和训练复杂度,实验表明采用Resnet34 作为编码框架,引入SCSE 模块将比单Unet 网络提高约4%,采用二分类和语义分割双任务进行预测比单任务进行预测在预测精度上也提高1.2%。由此可以分析,引入SCSE模块对图像特征信息进行修正,从空间和通道两个方向获取图像的全局信息,比传统的Unet+Resnet34模型对于特征的获取更加有效,损失函数采用“分类”和“分割”融合的多任务策略对气胸医学图像进行语义分割,可以更好地优化训练过程,避免了只是针对局部优化,没有考虑到对整体进行优化的缺点。
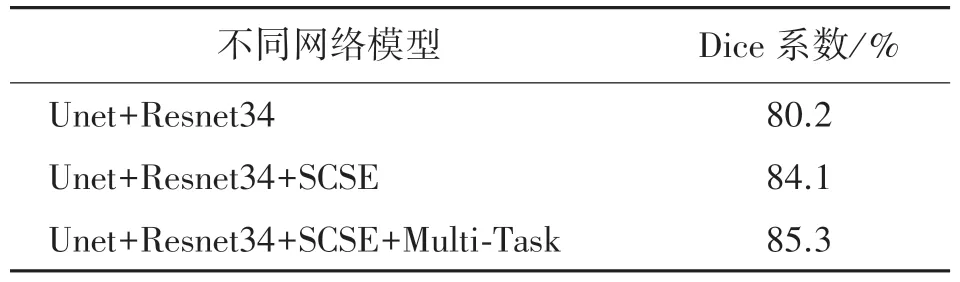
表2 不同网络模型对比结果分析
(3)预测效果
根据训练得到的最优网络模型Unet+Resnet34+SCSE+Multi-Task 组合,对实际医学图像进行分割,以3 个病人为例进行预测,预测效果如图6 所示。
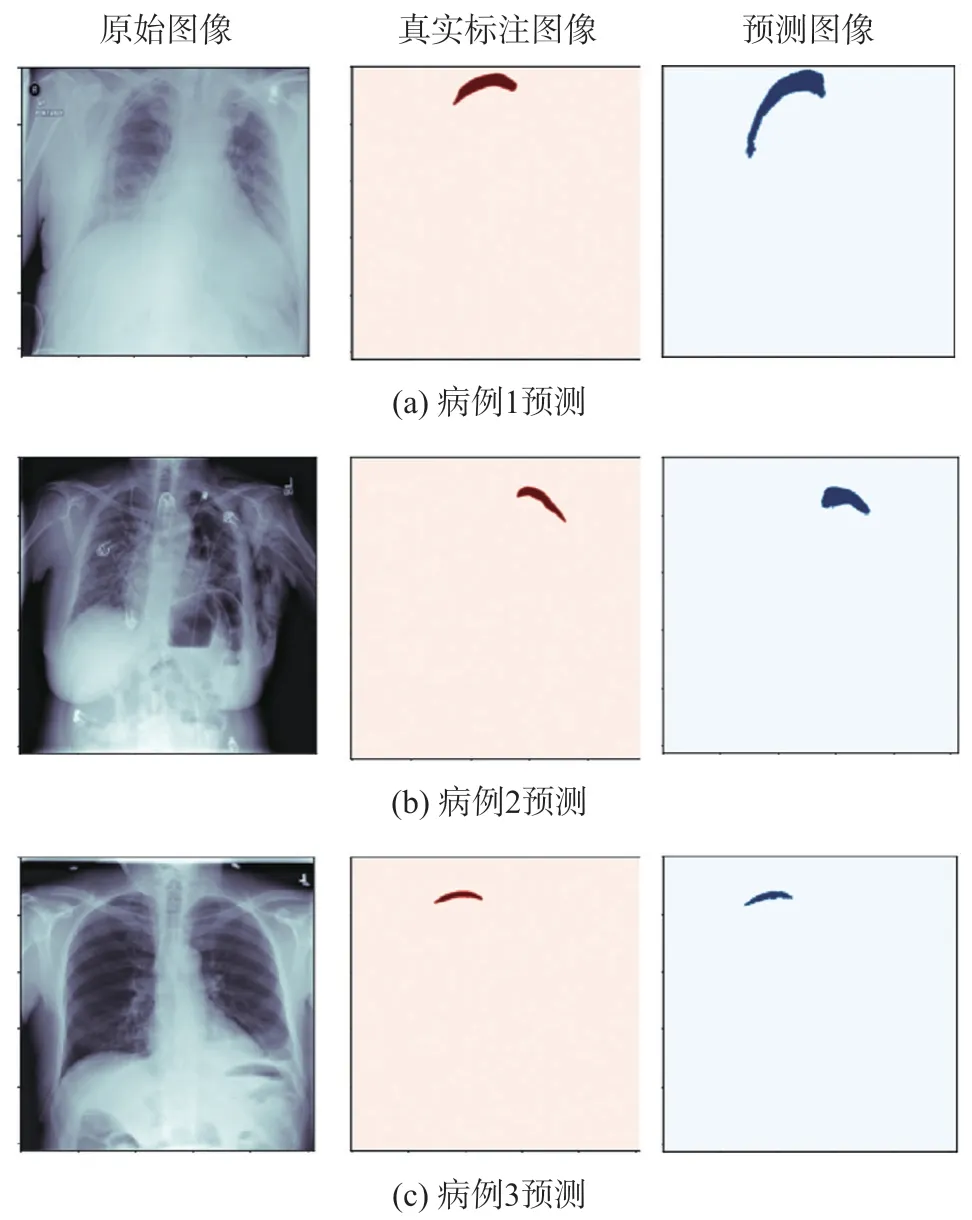
图6 实验预测效果
3 结束语
深度学习模型是医学图像检测领域非常强大的工具,使用语义分割预测气胸CT 图像病灶位置对医生判别疾病将起到很好的辅助作用,本文设计的语义分割模型采用Resnet34 作为框架,解决了网络深度到一定程度,梯度消失的问题;引入SCSE 模块,从空间和通道两个方向获取图像的信息,提高了语义分割的精度;损失函数采用“分类”和“分割”多任务策略进行学习,从局部像素点和全局图像的分类上进行融合,进一步提高了语义分割的精度。
猜你喜欢
应用心理学(2022年5期)2022-11-05
北京航空航天大学学报(2022年8期)2022-08-31
北京大学学报(自然科学版)(2022年1期)2022-02-21
现代信息科技(2021年21期)2021-05-07
学习与科普(2019年4期)2019-09-10
中国保健营养(2019年4期)2019-09-10
人人健康(2019年11期)2019-01-19
中国新技术新产品(2016年23期)2016-12-26
长江学术(2015年1期)2015-02-27
祝您健康(1992年5期)1992-12-28
