
基于改进DeepLabv3+网络的风机叶片分割算法研究
2022-10-20 10:21李宁张彦辉尚英强周弋高金秋
电子技术应用 2022年9期
李宁,张彦辉,尚英强,周弋,高金秋
(国网北京电力公司电缆分公司,北京 100010)
0 引言
近些年来,随着国家对风电政策支持力度的不断加大,风电产业获得了长足的发展,我国已经成为世界上最大的风电产业大国。随着大量风电机组的出保,风电运维管理问题也受到业内人士的广泛关注。由于风电场环境较复杂,风力发电机组叶片全天候在高空运行,容易出现缺陷影响叶片寿命,严重的甚至造成停机事故。因此,对风机叶片进行定期检查具有重要意义。
随着无人机技术、人工智能及无损检测技术的发展,基于无人机平台采集高清风机叶片图像,通过计算机视觉技术自动识别缺陷的自动巡检技术已成为风电机组定期巡检的新模式。由于无人机航拍采集的叶片图像背景为大地,背景复杂,干扰因素较多,利用图像分割技术实现对风机叶片区域的分割,实现背景的去除,能够排除环境干扰,有效提高缺陷识别的准确率。传统的图像分割方法根据图像的颜色、空间结构和纹理信息等特征进行处理分析,如:基于阈值的图像分割方法、基于边缘的图像分割方法、基于区域的图像分割方法、基于特定理论的分割方法等[1-4]。传统的图像分割方法在分割精度和分割效率上难以达到实际应用的要求,需要通过人工设计的特征与其他方法的结合实现,具有很大的局限性[5-6]。而深度学习能够从数据中有效地自主学习特征,具有很强的自学习能力。随着2015 年全卷积网络FCN[7]的提出,利用深度学习进行语义分割逐渐发展起来。
DeepLab 是深度学习语义分割领域影响较大的一支,其中DeepLabv3+[8]是DeepLab 语义分割系列网络的最新作,其前作有DeepLabv1[9]、DeepLabv2[10]、DeepLabv3[11],在DeepLabv3+中通过Encoder-Decoder 结构进行多尺度信息的融合,其骨干网络使用了ResNet-101 和Xception 模型,提高了语义分割的健壮性和运行速率。DeepLabv3+提出了采用扩张卷积代替池化层来产生密集的预测的策略,在Pascal VOC 和Cityscape 数据集取得了不错的成绩,但其编码输出的特征图相较于输入图像分辨率减小了16 倍,有很多的细节信息被丢失,导致现有算法在物体边缘和细节部分分割效果不佳[12-13]。
由于无人机采集的风机叶片图像具有背景复杂和叶片占比差异较大的问题,本文以DeepLabv3+网络为基础,在DeepLabv3+网络的基础上改进了空间金字塔结构(Atrous Spatial Pyramid Pooling,ASPP)和Decoder 模块。DSAPP 通过级联多个空洞卷积层,使用密集连接的方式将每个空洞卷积层的输出传递给后续的空洞卷积层,获得了更大范围的感受野。在Decoder 阶段添加多层特征融合,以恢复在降采样过程中丢失的细节信息和低级特征。
1 图像采集及基础网络简介
1.1 图像采集
本文所用的图像是选择抗风性能较强的六旋翼无人机搭载可见光相机通过自主规划航线,沿着叶片的4个面(迎风面、背风面、前缘、后缘)飞行采集的。相机距离叶片的距离约为6 m,约每隔2 m 采集一张图像。每幅图像的尺寸为5 280×3 956,为了降低分割难度,提升分割效率,本文将图像中出现的机头及塔筒部分也视为叶片处理。
1.2 DeepLabv3+网络结构简介
DeepLabv3+属于Encoder-Decoder模型,Encoder -Decoder 结构常用于自然语言处理中,在分割任务中就是将图片通过卷积得到小尺寸的特征图再通过上采样将尺寸还原的过程。DeepLabv3+网络是以DeepLabv3 模型为基础,利用其作为编码模块输出特征图,并添加解码模块实现语义分割。编码器部分首先利用不同通道的可分离卷积层提取图像特征,再通过ASPP 模块中不同扩张率的空洞卷积捕获到该特征空间信息,并通过1×1 卷积进行通道压缩。在解码器部分,首先对提取到的多尺度特征信息进行4 倍双线性插值上采样,再与基础网络中提取到的原始特征进行结合,然后利用3×3 卷积对合并后总的特征信息做简单特征融合,最后对特征采用4 倍双线性插值上采样得到分割结果。图1 展示了DeepLabv3+的基本结构。
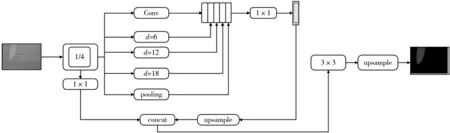
图1 DeepLabv3+的网络结构
2 基于改进DeepLabv3+网络的叶片分割方法
DeepLabv3+网络通过Encoder-Decoder 结构实现像素的有效分割,但ASPP 选择的扩张率6、12、18 可以获取的感受野有限,且Decoder 阶段引入Encoder 的低层特征图进行特征融合,丢失了部分中高层特征,在物体边缘处的语义分割效果不够理想。针对DeepLabv3+网络的不足,本文从两个方面进行改进,通过建立DASPP 模块获取更大的感受野和更密集的采样点,将Encoder 阶段的多层特征图拼接到Decoder 阶段,通过特征融合增加网络的细节信息。整体网络结构如图2 所示。
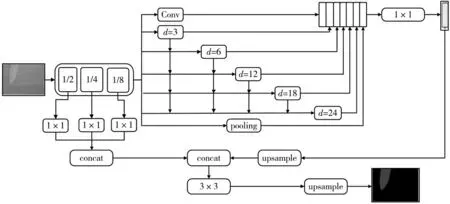
图2 改进DeepLabv3+的网络结构
2.1 DASPP 模块
DeepLabv3+采用ASPP 模型进行级联的空洞卷积,通过叠加不同扩张率的空洞卷积特征,使得输出的特征映射级联到一起逐步获得更多的感受野尺寸。ASPP 模块使用空洞卷积解决分辨率和感受野的矛盾,在不增加卷积核参数量的前提下获得较大的感受野尺寸,编码高级的语义信息。空洞卷积的主要作用就是在保持分辨率的条件下增大感受野,一维的空洞卷积如下:

其中,y[i]表示输出信号,x[i]表示输入信号,d 表示扩张率,w[k]表示卷积核的第k 个参数,K 是卷积核大小,* 表示卷积。空洞卷积相当于在卷积核两个连续值中间插入了d-1 个0,使得卷积时的感受范围增大。ASPP 通过并联3 个不同扩张率的空洞卷积层处理同一输入特征,并将结果融合在一起,此时输出的特征是输入的多尺度采样特征,如式(2)所示:

其中,Hk,d(x)用来表示一个空洞卷积,y 表示融合特征。DeepLabv3+采用的ASPP 模块将3 个不同扩张率(6、12、18)的卷积层进行连接,增加了卷积核的感受野,例如一个扩张率为d,卷积核大小为K,通过空洞卷积后的感受野尺度可以表示为:

ASPP 模块的3 个空洞卷积层分别产生的感受野范围如式(4)所示:
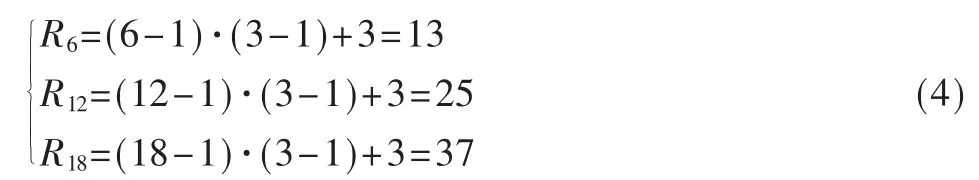
语义分割任务需要像素的高级特征表示,对于高分辨率的叶片图像需要网络具有更大的感受野。ASPP 为了获取足够大的感受野,需要足够大的扩张率,但随着扩张率增加,会使得像素采样率比传统卷积更加稀疏,造成更多的细节信息丢失,因此原有的ASPP 模块对扩张卷积的效果产生衰减,空洞卷积会变得越来越无效并逐渐失去模型能力。在风机桨叶分割中,存在不同尺度的风机叶片,叶片占幅比过大和过小的情况均存在,这更加需要捕获不同尺度的叶片感受野。因此本文设计了DASPP 模块来解决风机桨叶分割中的感受野问题,通过级联多个空洞卷积层,使用密集连接的方式将每个空洞卷积层的输出输送给后续的空洞卷积层。在DSAPP 模块中,空洞卷积层充分利用了合理的扩张率,通过一系列的特征连接编码不同尺度的中间特征,因此DASPP 模块的输出特征覆盖了多尺度范围的信息,同时也避免了使用过大扩张率的卷积导致的细节特征丢失问题。为避免因空洞卷积密集连接出现的特征通道数激增问题,本文使用了1×1 卷积进行通道压缩,用于降低参数,限制计算量。
DASPP 结合了空洞卷积层串联和并联的优点,可以产生具有更多尺度的特征表示,多尺度特征融合与增大感受野交替进行。空洞卷积层通过级联的方式组织到了一起,扩张率逐层增加,每层空洞卷积层的输出都会与其输入及其他层的输出进行组合,最终产生具有更多更大尺度的感受野。本文设计的DASPP 模块使用5 个不同扩张率(3、6、12、18、24)的空洞卷积层进行级联,并与另外两层特征层进行组合后共同编码,生成更密集的特征金字塔。DASPP 模块级联的空洞卷积如式(5)所示:
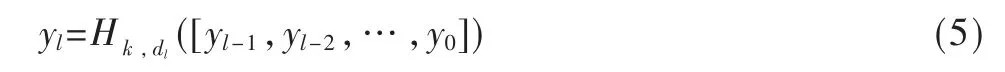
其中,dl表示第l层的扩张率;yl-1,yl-2,…,y0表示对前面所有层的输出进行组合之后生成的特征。级联两个空洞卷积层可以产生更大的感受野,假设两个空洞卷积的感受野尺寸分别为K1、K2,级联后的感受野为:

可以看到DSAPP 使用密集连接集成几个不同扩张率的卷积层特征,相当于集成多个尺度和感受野的卷积核特征,由于存在串联和并联结构,扩张率层层递增,后面的层使用前面的层的特征,进行信息的共享,像素的使用更加密集,小的扩张率使得像素采集更加密集,大的扩张率使得感受野更大。ASPP 与DASPP 的感受野对比如下:
ASPP 的最大与最小感受野:
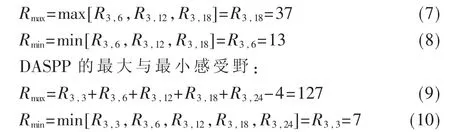
因此,本文提出的DASPP 模块对于高像素中的小目标和大目标分割提供了充分的上下文信息,能够产生更好的分割细节。
2.2 Decoder 模块
DeepLabv3+网络通过Decoder 模块来重构物体的边界信息,首先对提取到的多尺度特征信息进行4 倍双线性插值上采样,再与基础网络特征提取部分提取的原始特征进行结合,然后利用3×3 卷积对合并后的特征信息做简单的特征融合,最后对特征采用4 倍双线性插值上采样得到分割结果,避免了原始结构中直接对编码器输出进行16 倍的上采样操作,具有更好的细节信息。但DeepLabv3+网络的Encoder 阶段仍然采用了一个4 倍的上采样,大尺度的上采样会对边缘分割产生不利影响,且只与基础网络的低层特征进行了融合,丢失了部分信息会造成分割结果的损失。因此在Decoder 阶段添加多层特征融合,以恢复在降采样过程中丢失的细节信息和低级特征。优化后的Decoder 模块融合基础网络的多层特征图,编码器输出特征进行4 倍上采样后与将基础网络提取的1/2、1/4 和1/8 大小的特征图进行充分的特征融合,减少上采样过程的信息丢失问题,获得更好的分割效果。
本文在Decoder 模块采用了1×1 卷积和深度可分离卷积,1×1 卷积将基础网络提取的特征图进行通道压缩,保持特征所占的比重均衡,利于模型学习。将编码和解码的特征进行融合后,再经过一个3×3 的深度可分离卷积,将每个通道独立进行卷积计算,逐点卷积将得到的多个特征图在深度上加权组合,能够实现对空间信息和深度信息的去耦合,有效提高分割精度。优化后的网络模型通过端到端的学习和训练,能够在叶片边缘等细节部分有更好的表现。
3 实验及结果分析
3.1 数据集准备
本实验采用的数据集来自无人机采集的风机可见光图像数据集,共918 张,包括风机不同角度不同距离的可见光图像。利用开源图像标注工具VIA 对可见光图像的风机叶片轮廓区域进行精准标注,得到包含标注信息的JSON 文件。对标注文件进行解析,区分像素点是在叶片外还是叶片内,对不同对象赋予不同的数值,把背景像素设为0,叶片像素设为1,保存为与原图名称一样的单通道mask 标签图,用于网络的训练。
图像增广技术通过对训练图像做一系列的随机改变,来产生相似但又不同的训练样本,扩大数据集的规模,降低模型对某些属性的依赖,从而提高模型的泛化能力[14]。在分割任务中需要对原图和mask 标签图同步增广,选择数据增广工具Augmentor 实现。将可见光原图与mask 图进行旋转、水平翻转、噪声、裁剪、颜色空间变换等操作对应变换,使得数据集更加丰富和多样性,颜色空间变换效果如图3 所示。最终形成训练集图像2 000张,验证集图像400 张,测试集图像200 张。

图3 颜色空间变换效果图
3.2 模型训练
本文实验基于Ubuntu16.04 操作系统,GPU 为GeForce RTX2080Ti,CPU 为Inter Core i9-9900,使用TensorFlow 深度学习框架来训练和测试模型。
本文在基础网络部分使用ResNet-101 作为预训练模型,使用Adam 优化算法迭代的更新网络权重,使用poly 学习策略,设置初始化学习率为0.007,power 设置为0.9,训练尺寸设置为1 025×1 025,batch size 为2,迭代次数为3 万次,每训练一个epoch 在验证集上测试一次。
3.3 模型评价
本文使用像素平均交并比(Mean Intersection over Union,MIoU)和像素精度(Pixel Accuracy,PA)作为分割效果评价指标。语义分割属于像素级别的分类任务,预测的结果存在真正(True Positive,TP)、假正(False Positive,FP)、假负(False Negative,FN)和真负(True Negative,TN)4 种情况。
MIoU 为语义分割的标准度量,其计算两个集合的交并比。这个比例可以变形为TP 比上TP、FP、FN 之和。在语义分割的问题中,这两个集合为真实值(Ground Truth)和预测值(Predicted Segmentation)。计算公式如下:
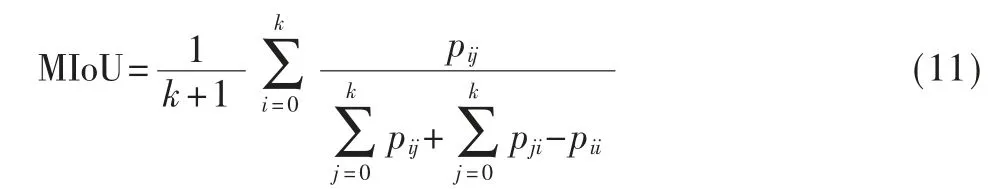
其中,i 表示真实值,j 表示预测值,pij表示将i 预测为j,k+1 是类别个数。等价于:

MIoU 一般都是基于类进行计算的,将每一类的IoU计算之后累加,再进行平均,得到的就是基于全局的评价[15]。理想情况下比例为1。
PA 即标记正确的像素占总像素的比例,公式如下:

通过图4 和图5 可以发现,通过训练,模型的MIoU达到了99.234%,像素精度达到了0.997,已经达到相当高的精度,完全符合使用要求。
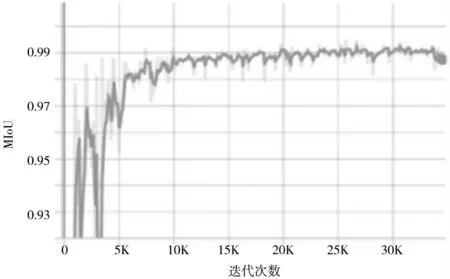
图4 MIoU 曲线
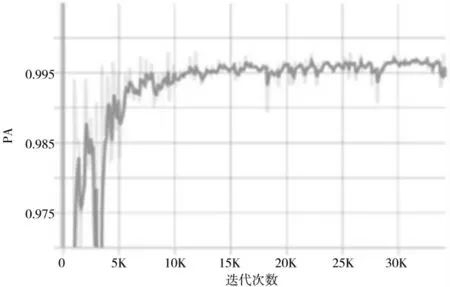
图5 PA 曲线
3.4 实验结果与分析
为验证网络改进对分割结果产生的影响,本文进行了对比实验,本文算法与DeepLabv3+网络的风机桨叶分割结果如图6 所示,第1 列为风机叶片图像,第2 列为标签图像,第3 列为DeepLabv3+网络分割结果,第4 列为本文算法分割结果。

图6 分割结果对比
由图6 可以看出,相较于原DeepLabv3+网络分割效果,本文算法在添加了多尺度感受野和特征融合后,在叶片的边缘和细节方面具有更好的分割效果。
通过对比测试,利用本文算法与DeepLabv3+网络对风机桨叶分割得到了多组实验结果,如表1 所示,经过优化后的网络达到了最高的MIoU 和PA值。

表1 测试结果对比
实验结果表明,本文采取的两种改进方法均对分割结果有不同程度的提升,与直接采用DeepLabv3+网络进行风机叶片分割相比,本文设计的网络在MIoU 上提升了9.3%,在PA 上提升了3.9%,验证了本文所提方法的有效性。
4 结论
针对无人机采集的风机叶片图像的质量及DeepLabv3+算法对物体边缘和细节部分分割效果不佳的现状,本文提出了一种基于改进DeepLabv3+网络的风机叶片分割算法。使用密集连接的DASPP 来获取多尺度的感受野信息,同时改进Decoder 模块,进行多尺度特征图融合,减少上采样过程的信息丢失问题。本文提出的算法像素准确率达到了99.68%,平均交并比达到了99.13%,相比改进之前分别提高了3.9%与9.3%。通过大量测试,本文算法在背景复杂、占幅比悬殊的图像上叶片边缘和细节上都具有较好的分割表现,但是如何有效地分割纯净的风机叶片去除风机机头及塔筒,需要进一步深入研究。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
机电信息(2022年9期)2022-05-07
中国水运(2022年4期)2022-04-27
计算技术与自动化(2022年1期)2022-04-15
科学24小时(2020年6期)2020-07-18
上海师范大学学报·自然科学版(2019年5期)2019-12-13
中国化工贸易·中旬刊(2018年6期)2018-10-21
价值工程(2017年28期)2018-01-23
故事作文·高年级(2017年2期)2017-03-01
