
基于光滑化方法的分段线性删失分位数回归模型估计
2022-10-18 05:47王小刚陈姜猛
江西师范大学学报(自然科学版) 2022年3期
王小刚,陈姜猛
(北方民族大学数学与信息科学学院,宁夏 银川 750021)
0 引言
相较于传统的回归模型,分位数回归模型能够根据不同分位数得到不同的估计结果,既能衡量在平均意义下的估计结果,又能反映在极端情况下的估计效果,具有灵活性和稳健性以及单调同变性等优点,从而它受到越来越多学者的关注.在管理、金融和医学等领域的研究中,由于研究提前结束、研究对象无法继续参与实验(如研究对象工作变迁、意外身亡等事件不能继续研究)会导致无法获取个体准确的生存时间,即数据存在删失,所以直接使用分位数回归会损失有用的信息,使得模型估计效果产生偏差.文献[1-2]提出了基于删失数据的分位数回归模型估计方法,得到有效的估计;Peng Liming等[3]使用与删失数据相关联的鞅结构,估计了删失分位数回归模型的参数;Wang Huixia Judy等[4]在假设生存时间和删失变量条件独立的条件下,提出用局部加权分位数回归方法估计删失分位数回归模型参数;Tang Yanlin等[5]为了自动地估计和检测分位数之间的共性,提出了一种新的带有2种分位数惩罚变量的删失分位数回归算法;张倩倩等[6]对存在删失的医疗费用建立了分位数回归模型,提出了简单加权估计和模拟退火算法,并验证了模型具有稳健性;李忠桂等[7]基于EL法和SEL法对右删失数据构造了更高精度的检验统计量;孙桂萍等[8]对长度偏差右删失数据剩余寿命分位数模型提出了参数估计,推导了估计的相合性和渐近正态性;张立文等[9]研究了删失分位数回归模型的变点检验问题;王江峰等[10]研究了在删失指标随机缺失下的非参数删失回归模型,构造了回归函数的复合分位数回归估计,得到估计的大样本性质.
在实际应用中,删失数据会受到诸如新政策实施、新技术变革、经济金融危机、全球新冠肺炎疫情等重大事件冲击,可能会呈现出非线性的结构特征和趋势,若不考虑变点的存在性则会产生有偏的估计.在此种情况下,由于分段线性删失分位数回归模型既能解释模型的非线性结构特征,又能保持删失分位数回归模型原有优点,所以该模型就成为研究的热点,也是使用较为广泛的模型.
在分段线性删失分位数回归模型中,困难之处在于需要对未知的变点位置进行估计.常用的变点位置估计方法可以分为2类.一类方法是2步法,即事先给定某个变点初值,将模型按照变点的位置分成前后2个部分,利用已知方法分别估计参数,然后通过最优化目标函数得到变点估计.如常用的格点搜索法[11-13],该方法的优点在于不需要对模型分布做假设,具有一定的灵活性,然而其缺点在于变点估计的精度与运算效率成反向变动关系,且变点估计较难给出符合实际意义的解释,因此常用来做变点位置的初步估计.另一类方法是同时估计方法,即通过某种方法将变点参数转化为模型参数,再利用已有方法得到模型参数及变点位置的估计.如常用的线性化技术[14-15],线性化技术简便易行,但难以推导大样本性质,且变点估计效果依赖于迭代快慢与质量,常会遇到变点收敛速率过慢状况.线性化方法的缺陷可以通过光滑化的核函数方法加以弥补[16-18],光滑化的核函数方法的思想是将目标函数在变点处展开,利用光滑的核函数替代在目标函数中的不可导项,从而得到变点位置和模型系数的估计.光滑化的核函数方法估计更加有效,收敛速度更快,且能够得到估计的大样本性质,因此光滑化的核函数方法被广泛应用于变点的位置估计研究.
本文首先给出了分段线性删失分位数回归模型及估计方法,推导估计量的大样本性质,然后通过数值模拟验证了在分段线性删失分位数回归模型中的变点位置及模型系数估计效果,并将该方法对线性化技术进行了比较.利用药物滥用数据进行的实证分析发现了存在的变点,并给出了合理解释.
1 分段线性分位数模型及其估计
1.1 模型定义与估计
给定观察值(xi,yi,δi),考虑删失分位数回归模型如下:
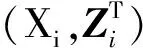
假设未知的变点位置为ψ,分段线性删失分位数回归模型定义如下:
(1)
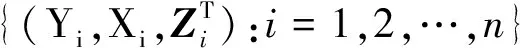
(2)
其中ρτ(k)=k(τ-I(k<0))是检验函数.由于变点ψ的存在导致目标函数(2)不可导,因此,借鉴文献[17-18]的方法采用光滑的核函数K((X-ψ)/h)代替示性函数I(X>ψ),h(>0)表示窗宽,将核函数K((X-ψ)/h)代入目标函数(2),得到新的目标函数:
(3)
最小化目标函数(3)可得到模型参数ξ=(β0,β1,β2,β3,γT)T和变点ψ的估计.为了寻求目标函数(3)的最优化解,将非线性项β2(Xi-ψ)K((Xi-ψ)/h)在给定初值ψ*处进行泰勒展开,即
β2(Xi-ψ)K((Xi-ψ)/h)≈β2Ui+β3Vi,
其中Ui=(Xi-ψ*)K((Xi-ψ*)/h),β3=β2(ψ-ψ*),Vi=-{K((Xi-ψ*)/h)+(Xi-ψ*)K′((Xi-ψ*)/h)/h}.
将Ui、Vi代入目标函数(3),有
(4)
通过最小化目标函数(4)即可更新参数ξ=(β0,β1,β2,β3,γ)T,估计算法如下.
算法1基于光滑化方法的分段线性删失分位数模型估计.
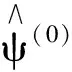
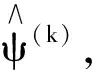
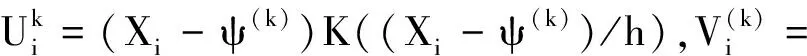
h)/h}.
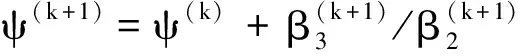
Step4重复步骤2和步骤3直到收敛,收敛条件为

参数估计依赖窗宽的选择,本文通过最小化交叉验证函数选择最优窗宽,即
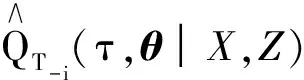
1.2 渐近性质
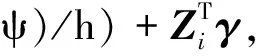
(5)
定义
q(ωi,θ)=∂max{Ci,g(ωi,θ)}/∂θ=diag(I(g(ωi,
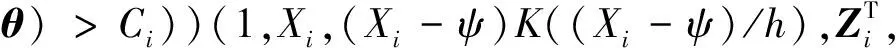
h)/h)T,
其中θ0为真值,ρ′τ(k)=τ-I(k<0)表示ρτ的1阶导数.极小化目标函数(5)等价于求解方程
为了证明其渐近性,给出如下正则性条件.
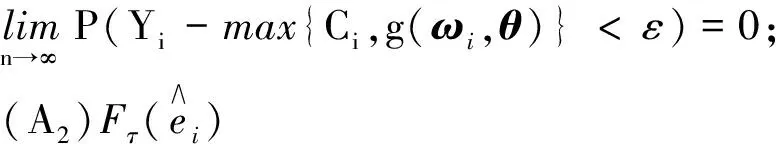
(A3)Xi的密度函数Pi(x)在有界紧集合[M1,M2]上连续;
(A4)E(‖Zi‖3)<∞,其中‖·‖表示Euclidean
范数;
(A5)存在2个正定矩阵C0和D0,分别满足
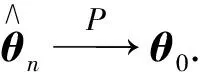
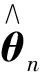
容易得到∀δ>0,∃N,当n>N时,有
P(Yi-max{Ci,g(ωi,θ)}<ε)<δ,
用核函数K((X-ψ)/h)代替示性函数I(X>ψ),有I(Xi>ψ)=K((Xi-ψ)/h)+o(h),h→0.
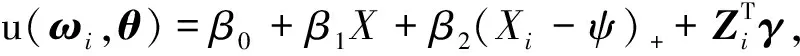
可得
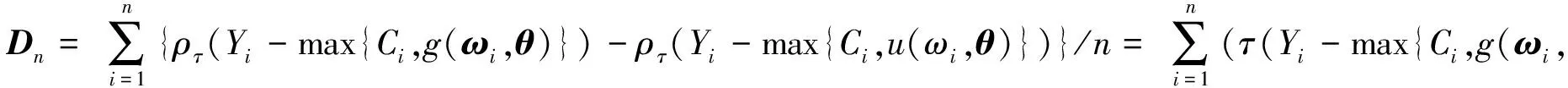
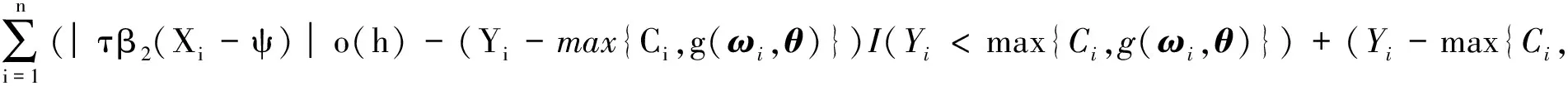
由正则性假设(A1)知有
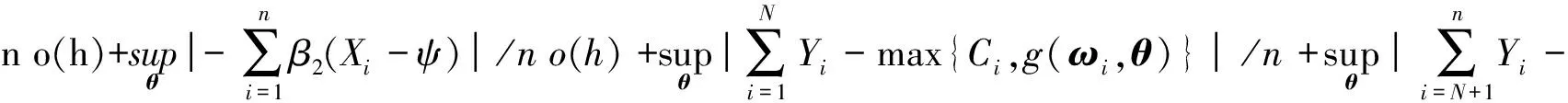
对于有限的N和任意小的δ,当n→∞时,上述不等式右边4项都收敛于0,即
结合Li Chenxi等[12]证明的一致性,得到ln,τ(θ)的连续性.引理1得证.
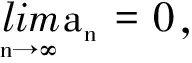
其中
vi(θ,θ0)=ρ′τ(Yi-max{Ci,g(ωi,θ)})q(ωi,θ)-ρ′τ(Yi-max{Ci,g(ωi,θ0)})q(ωi,θ0).
证引理2的证明与文献[19]中的引理4.6的证明相似.为证明引理2,需验证文献[19]中引理4.6的条件(B1)、(B3)和(B5)满足即可.条件(B1)显然成立.
对于条件(B3),有
‖vi(θ,θ0(τ))‖≤‖ρ′τ(Yi-max{Ci,g(ωi,θ)})(q(ωi,θ)-q(ωi,θ0))‖+‖(ρ′τ(Yi-max{Ci,g(ωi,θ)})-ρ′τ(Yi-max{Ci,g(ωi,θ0)}))q(ωi,θ0)‖=‖I1i‖+‖I2i‖,
其中
‖I1i‖=‖ρ′τ(Yi-max{Ci,g(ωi,θ)})(q(ωi,θ)-q(ωi,θ0))‖=‖ρ′τ(Yi-max{Ci,g(ωi,θ)})q′(ωi,θ0)(θ-θ0)‖=op(1),
所以有E(‖I1i‖2|ωi)=op(1).同时,
‖I2i‖=‖(ρ′τ(Y-max{Ci,g(ωi,θ)})-ρ′τ(Yi-max{Ci,g(ωi,θ0)}))q(ωi,θ0)‖=‖(I(Yi≤max{Ci,
g(ωi,θ)})-I(Yi≤max{Ci,g(ωi,θ0)}))q(ωi,θ0)‖≤‖q(ωi,θ0)‖I(max{Ci,g1(ωi,θ,θ0)}≤Yi≤max{Ci,g2(ωi,θ,θ0)}),
这里的g1(ωi,θ,θ0)和g2(ωi,θ,θ0)分别为
g1(ωi,θ,θ0)=min{max{Ci,g(ωi,θ)},max{Ci,g(ωi,θ0)}},
g2(ωi,θ,θ0)=max{max{Ci,g(ωi,θ)},max{Ci,g(ωi,θ0)}}.
又由于g1(ωi,θ,θ0)≤g2(ωi,θ,θ0),有
‖max{Ci,g(ωi,θ)}-max{Ci,g(ωi,θ0)}‖=‖qT(ωi,θ0)(θ-θ0)+Rn‖≤‖q(ωi,θ0)(θ-θ0)‖≤an‖q(ωi,θ0)‖,
即
E(‖I2i‖2|ωi)≤‖q(ωi,θ0)‖2E(I(g1(ωi,θ,θ0)≤Yi≤g2(ωi,θ,θ0)))≤‖q(ωi,θ0)‖2·fτ,ωi(ξi)‖max{Ci,g(ωi,θ)}-max{Ci,g(ωi,θ0)}‖≤anfτ,ωi(ξi)‖q(ωi,θ0)‖3,
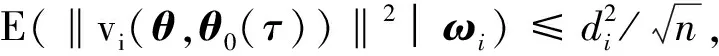
即条件(B3)满足.
下面验证条件(B5).对于任意的常数C,令
有
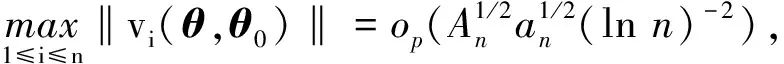
定理1在正则条件(A1)~(A5)下,有
其中协方差阵中的C0和D0的估计分别为
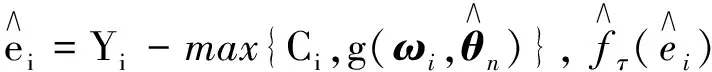
Δn是平滑参数,借鉴文献[21]的方法选择如下:
其中φ(·)和Φ(·)分别表示标准正态分布的密度函数和分布函数.
证在引理1和引理2的条件下,可得
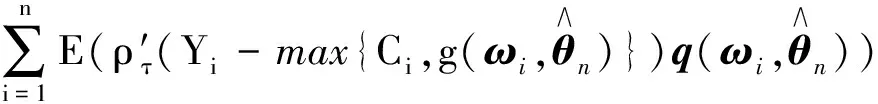
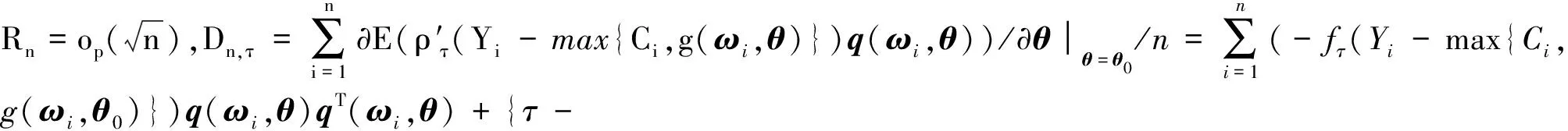
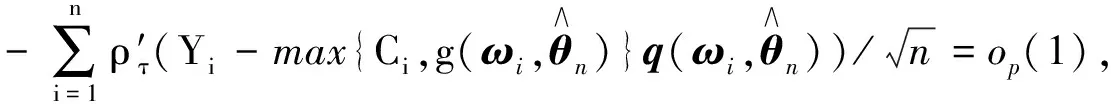
因此有
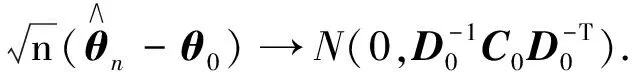
2 蒙特卡罗模拟
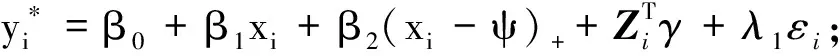
Y=max{C,T},δ=I(T≥C),QT(τ,θ|X,Z)=β0+β1X+β2(X-ψ)++ZTγ.
在固定删失和随机删失下、在不同分位数下的同方差和异方差数值模拟结果分别如表1和表2所示.表1和表2的上部分和下部分分别为在样本量n=200和n=500下估计量的评价指标,即偏差(Bs)、标准差(SD) 、标准误(ES) 、95%的覆盖率(CP) 和置信区间长度(AW).
从表1可以看出:在固定删失情况下,当分位数为0.5且同方差时,模型估计的Bs和SD都很小,且ES和SD非常接近,这说明估计效果是有效的,AW较小,且CP都接近于95%.从横向来看,在0.5分位数下,异方差的参数估计Bs和SD均较小,ES和SD很接近,这说明即使在异方差情况下模型估计效果也较好.另外,异方差的置信区间长度AW和覆盖率CP的估计结果要比在同方差情况下的估计结果更差.当分位数为0.3和0.7时,模型估计的Bs、SD要比在分位数为0.5时的估计结果更差,ES和SD的接近程度较好,AW与CP的效果与在分位数为0.5时的效果差异不大,这说明估计结果具有稳健性.
当样本量从200增长到500时,可以发现无论是估计的Bs、SD、ES还是AW都呈现减小趋势,但CP呈现增大趋势,这也验证了定理1的结果.同样,ES与SD非常接近,CP更接近于95%,这也验证了估计具有可靠性.
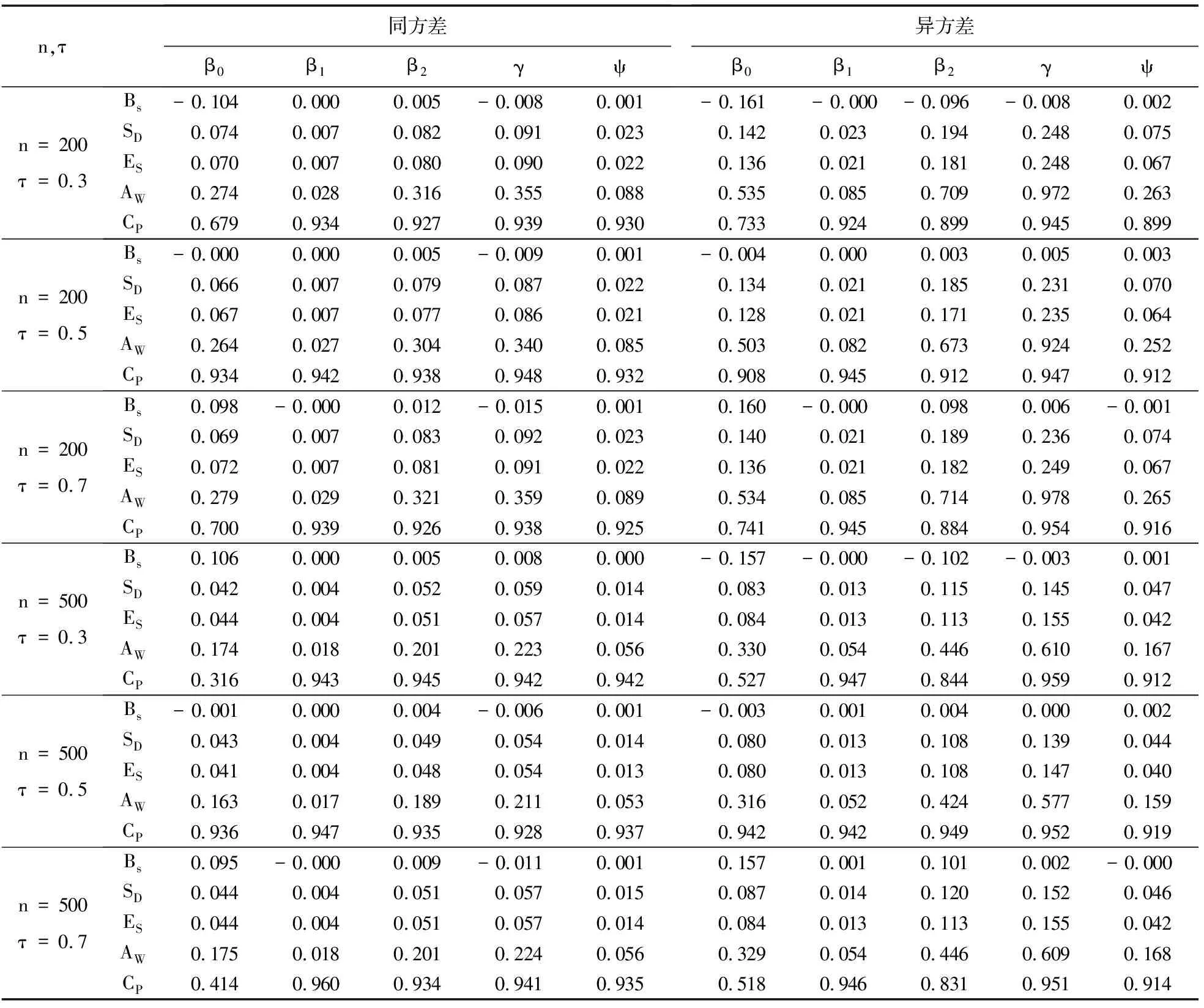
表1 在固定删失下的模拟结果
在随机删失下的模拟结果如表2所示.从表2可以看出:在同方差、相同样本容量、相同分位数情况下,固定删失的估计效果要比随机删失的估计效果更好.Bs、SD、ES之间的关系以及AW和CP之间的特征与表1中所得的结论相同.
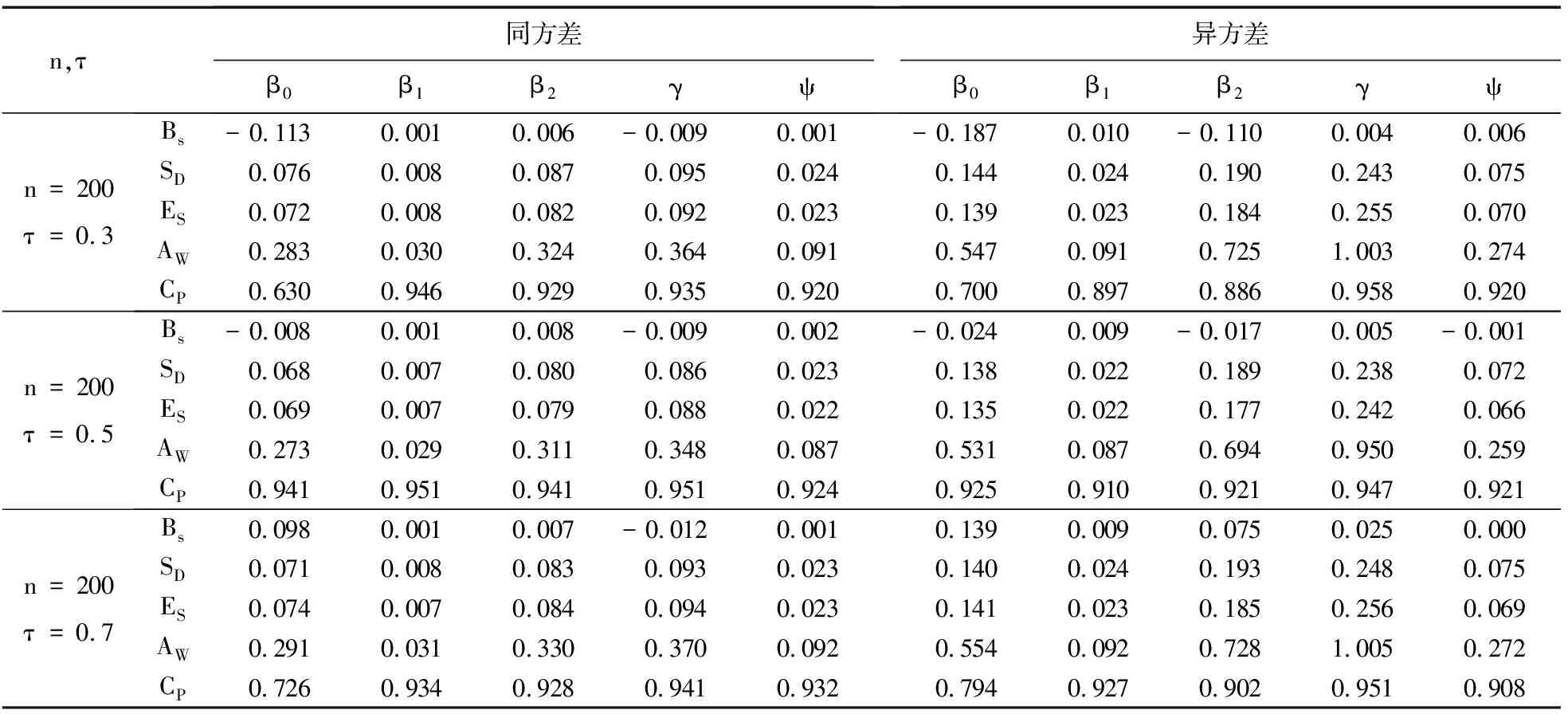
表2 在随机删失下的模拟结果
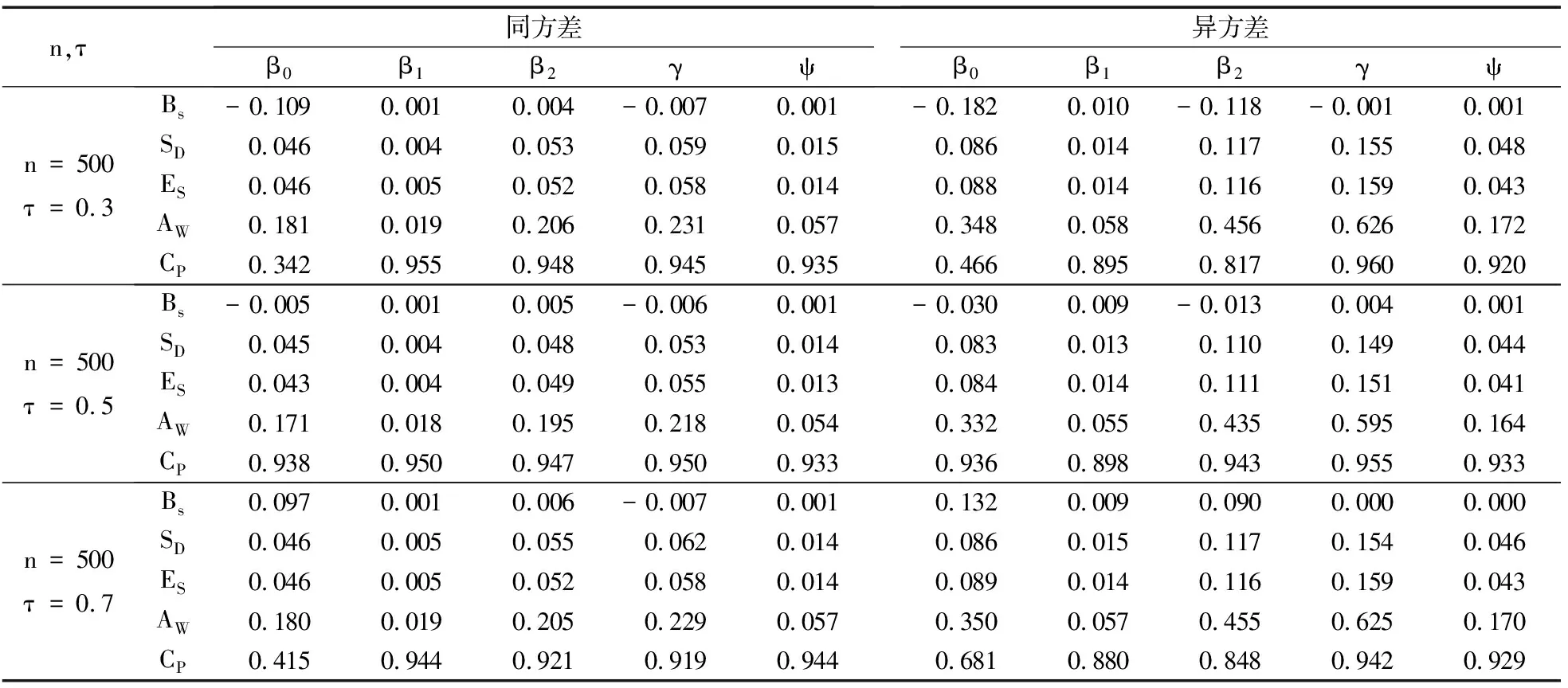
表2(续)
总体上,在其他情况不变的条件下,同方差下的估计效果要优于异方差下的估计效果,更大的样本容量的估计效果更好,这验证了参数估计满足相合性,固定删失的估计效果优于随机删失的估计效果,0.5的分位数的估计效果优于其他分位数的估计效果.蒙特卡罗模拟结果表明本文的光滑化方法具有有效性和稳健性.
为对比光滑化方法的可行性,对本文方法和线性化技术得到的模拟结果进行比较.当样本容量为1 000且分位数为0.5时的模拟结果如表3和表4所示.
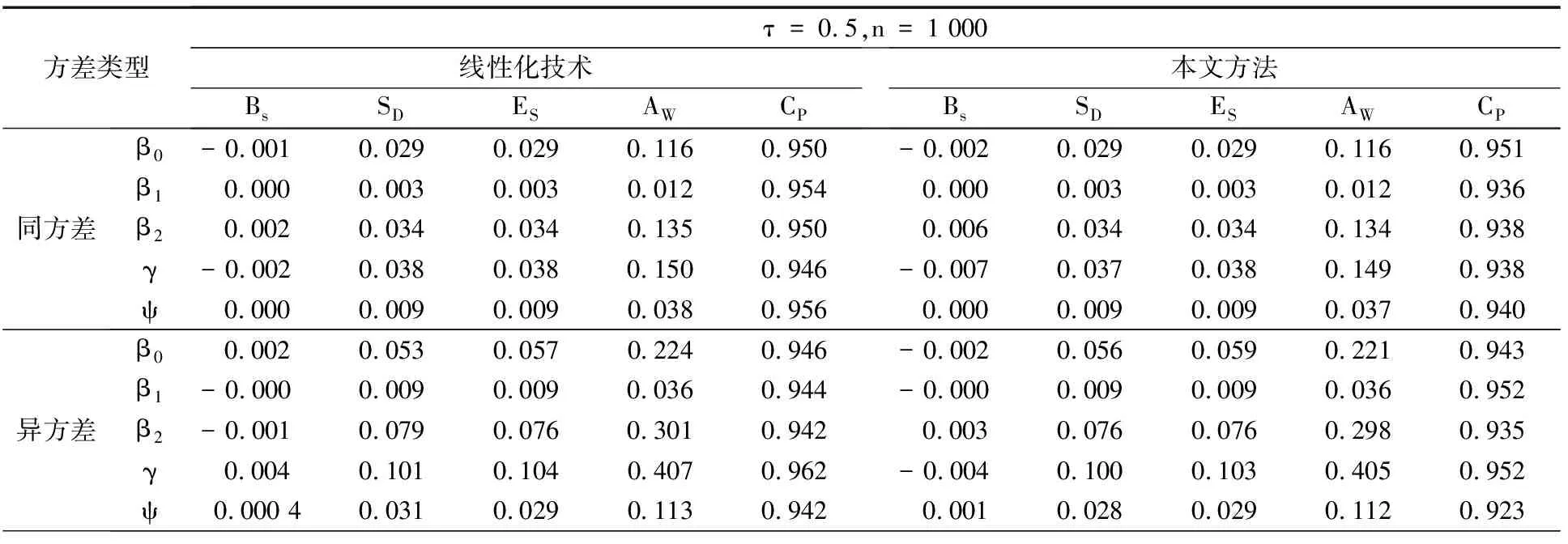
表3 在固定删失下线性化技术与本文方法的模拟结果对比
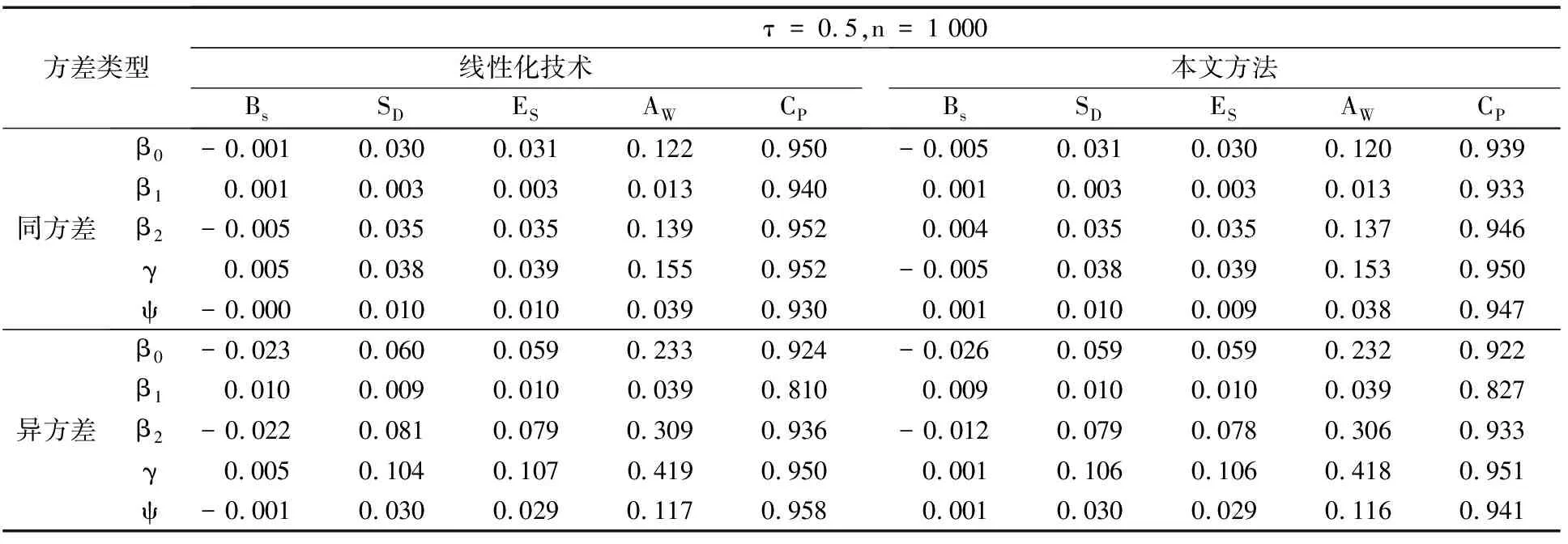
表4 在随机删失下线性化技术与本文方法的模拟结果对比
从表3和表4中可以看出所有的Bs都非常小,因此2种方法的估计是渐近一致的.2种方法的ES与SD非常接近,这表明估计具有相合性.此外,2种方法的CP均接近95%.但在相同显著性水平下,本文方法在同方差情况下略好于线性化技术,在异方差情况下优于线性化技术,本文方法估计的AW比线性化技术估计的AW更小,因此,本文方法在估计变点位置及模型参数的有效性上要优于线性化技术,且本文方法的收敛速率较高,而线性化技术在模拟时可能会存在不收敛情形.
3 实证分析
在医学领域中,药物的滥用会给个人、家庭及社会带来巨大的危害性.若不采取有效的预防措施和控制,则与之有关的疾病将会很快在全球泛滥成灾,所有国家都将处于这种危险之中,因此研究药物滥用复发时间的影响因素和变化趋势有着重要的实际意义,也有利于对药物滥用复发时间的控制和采取有效的预防措施.但是在对药物滥用复发治疗时,由于病人的药物没有复发而研究结束了或在研究结束前有病人提前结束治疗,所以导致数据存在删失.另外,考虑到模型会受到药物复发治疗的影响因素以及药物复发的反应快慢的冲击而产生变点,因此可通过用含变点的分段线性删失分位数回归模型研究药物滥用复发时间的影响因素,并利用本文方法进行估计.
文献[22]给出了关于UIS药物治疗的研究数据,原始数据的样本容量为628,包含575个无缺失的数据.响应变量为复发时间间隔,协变量为随机化治疗ZT,ZT=1表示接受了180 d的治疗,ZT=0表示接受了90 d的治疗,ZA为登记年龄,ZB为抑郁评分(取值为0~54),ZV为最近静脉用药史,ZV=1表示用药,ZV=0表示没有用药,ZN表示既往药物治疗次数(取值0~40),由于ZN在一定情况下会受到治疗效应解释的影响,所以将ZN分成ZN1和ZN22个指标,ZR表示种族,ZR=0为白人,ZR=1表示非白人,ZS表示治疗地点,ZS=0表示治疗点A,ZS=1表示治疗点B,XF表示治疗时间,用治疗天数TL定义,XF=TL/90为短治疗,XF=TL/180为长治疗.在研究结束前有病人提前结束治疗,因此数据存在删失.选取协变量ZN1、ZN2、ZV、ZT、XF[23]构建分段线性删失分位数回归模型.
从药物复发时间间隔(取对数)和XF的散点图(见图1)可以看出:XF值在0.5前后复发时间间隔呈现不同特点.在0.5之前复发时间间隔较大,但在0.5之后逐渐变小,呈现出非线性特征,这表明模型可能存在变点.因此建立分段线性删失分位数回归来分析药物滥用复发时间的治疗数据,模型如下:
Yi=max(Ci,Ti),δi=I(Ti≥Ci),i=1,2,…,575,
QTi(τ|Xi,Zi)=β0+β1XFi+β2(XFi-ψ)++γ1ZN1i+γ2ZN2i+γ3ZVi+γ4ZTi,
其中Yi为药物复发时间间隔,δi为删失指标,θ=(β0,β1,β2,γ1,γ2,γ3,γ4,ψ)T为未知参数.在分位数τ=0.3、0.5、0.7时利用本文方法估计了变点位置及模型参数,模型估计结果如表5所示.
由表5可知:在0.5的分位数下,所有参数估计的P值都小于0.05,通过了显著性检验.变点系数β不为0表示存在变点,变点位置为0.498.其他协变量的系数都为正,这表示其他协变量与复发时间间隔正相关.在0.3分位数下的估计与在0.5分位数下的估计相同,变点位置为0.485,与在0.5分位数下的情况相似.在0.7的分位数下,随机化治疗ZT没通过显著性检验,其他协变量都通过了检验,且也存在变点,变点位置为0.814.在不同分位数下的分段线性删失回归模型的估计都表明:复发时间间隔与治疗时间之间存在变点,前一半治疗时间(在0.5的分位数时为0.498)与后一半治疗时间的治疗效果有显著差异,即前一半治疗时间的复发时间间隔更长.
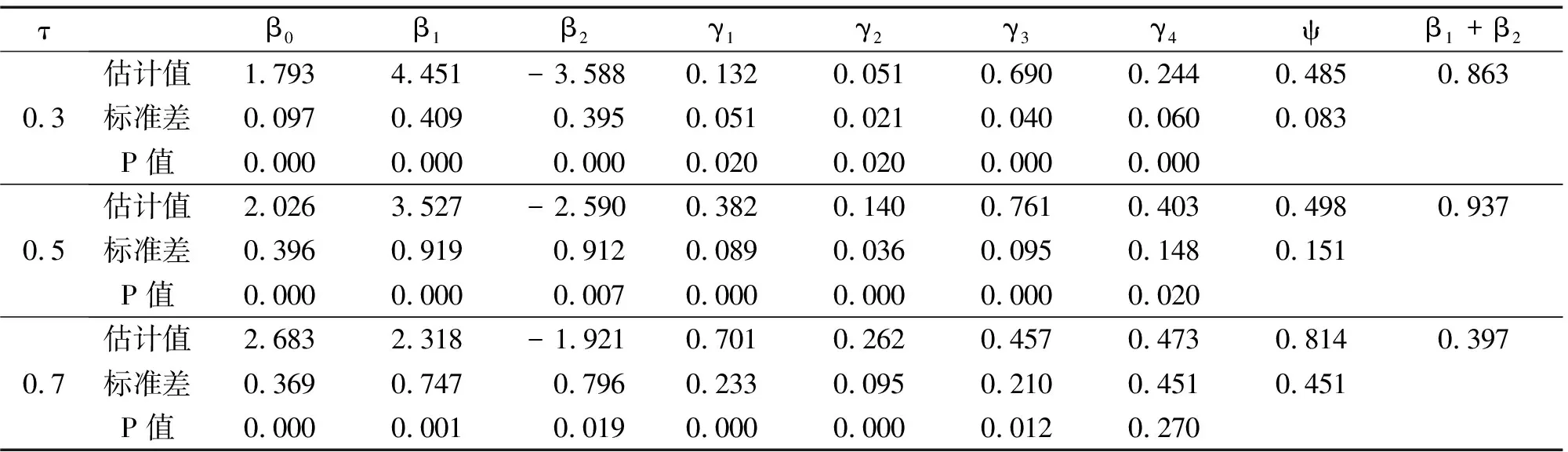
表5 估计结果
为更清晰地得到复发时间间隔与治疗时间之间的变化特征,在复发时间和XF散点图上画出不同分位数下的折线图(见图1).
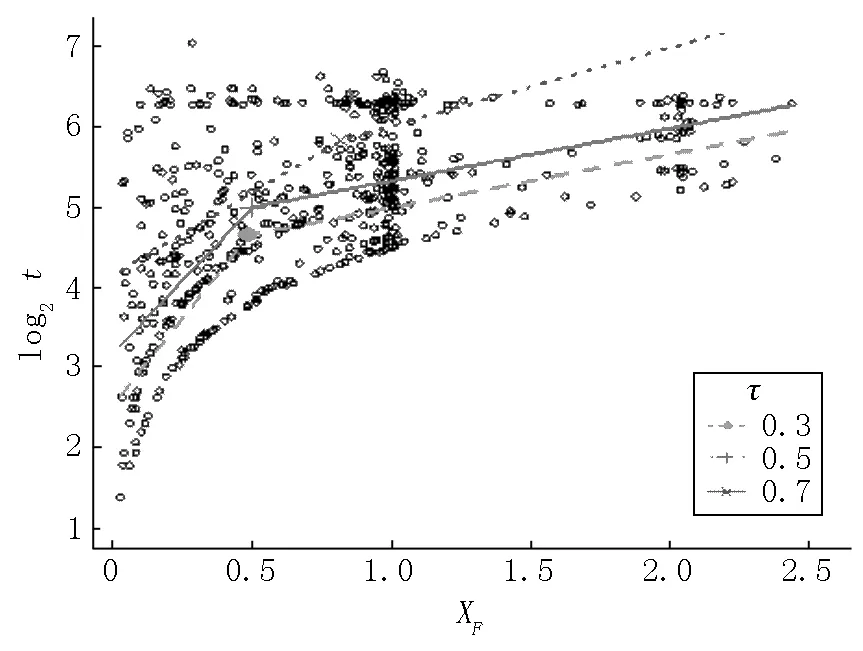
图1 药物复发时间间隔与治疗时间散点图
从图1可以看出:当分位数为0.3和0.5时,治疗时间在0.5附近(估计值分别为0.485和0.498)有显著差异.当分位数为0.7时,治疗时间在0.814处存在变点.变点前的复发时间间隔随着治疗时间的增加而增加,变点后的复发时间间隔明显比变点前的复发时间更小,也就是说,在前半段治疗时间里复发时间间隔更长,即变点之前的治疗比变点之后的治疗更有效.
4 结论
本文基于光滑化的核函数方法研究了分段线性删失分位数回归模型变点位置及模型系数的估计问题,利用核函数替代在目标函数中的非光滑项,通过迭代算法得到变点位置和模型系数估计,推导了估计量的渐近性质.蒙特卡罗模拟结果验证了估计效果的有效性和稳健性,同时利用该方法与线性化技术进行了比较,发现在置信区间较小的情况下,该方法的估计效果更好.针对药物滥用的数据实证分析表明:复发时间间隔与治疗时间存在正向影响,复发时间在0.5的分位数下存在变点,变点位置为0.498,即前一半时间的治疗比后一半时间的治疗更加有效.在0.3和0.7的分位数下也发现变点,且变点前后的治疗效果与在0.5分位数时的治疗效果相近.
猜你喜欢
山西教育·招考(2021年8期)2021-12-17
语数外学习·高中版上旬(2020年5期)2020-09-10
学苑创造·B版(2019年8期)2019-08-09
学校教育研究(2019年24期)2019-02-07
初中生世界·九年级(2017年10期)2017-11-08
新高考·高三数学(2017年4期)2017-07-10
理科考试研究·高中(2016年10期)2017-01-17
中学生数理化·八年级数学人教版(2016年5期)2016-08-23
中学生数理化·八年级数学人教版(2016年5期)2016-08-23
中学生数理化·八年级数学人教版(2016年5期)2016-08-23
