
情报学论文创新性评价研究
——LDА和SVM融合方法的应用
2022-10-17 07:31曹树金曹茹烨
图书情报知识 2022年4期
曹树金 曹茹烨
(中山大学信息管理学院,广州,510006)
1 引言
创新是持续发展的原动力,是科学研究的核心和本质。2016年5月,习近平总书记在全国科技创新大会、两院院士大会、中国科协第九次全国代表大会上提出,要改革科技评价制度,建立以科技创新质量、贡献、绩效为导向的分类评价体系,正确评价科技创新成果的科学价值、技术价值、经济价值、社会价值、文化价值[1]。学术论文是基础科学研究的主要成果形式之一,其学术价值主要由创新性及创新度来衡量[2]。在知识爆炸的时代,科研论文产出数量持续攀升,给期刊、科研机构以及研究者的工作带来了挑战。对于期刊而言,从大量投稿中选取创新价值高的学术论文,是推动期刊本身乃至整个学科发展的基本要求。对科研机构和研究者来说,快速识别创新论文、准确获取创新观点是把握领域研究前沿和选择研究课题的迫切需求。然而,创新本身是复杂多样的,难以界定和测度。同行评议作为最常用的学术评价手段,在对论文创新性的判断中发挥着一定作用,但评审人的认知偏差、思维惯性等因素会影响创新性评审的结果[3]。现有研究开始探索基于内容[4-5]的学术论文创新性评价方法。研究主题是论文的中心思想,是对内容的高度凝练,同时也是体现论文创新性的重要特征之一[6]。
论文主题创新是对特定集合中研究主题进行比较和分析而得出的结论,发表时间是需要考虑的关键因素之一[7]。Savov等认为如果一篇论文的研究主题在未来几年成为了研究热点,但在其发表以前并不流行,那么该论文具有创新性[8]。然而,对于特定领域的科学研究而言,未来研究热点是未知的,但过去各个时期和现阶段的流行主题是已知的。基于此,本文拟从主题演化视角出发,以情报学期刊论文为例,利用LDА主题模型结合SVM机器学习的方法,分析论文是在其主题成为流行之前还是之后发表的,依此来判断论文的主题创新性。因为论文创新是一个相对的概念,所以这里的创新性是指论文发表时的主题创新性。本研究的意义在于:一方面,不局限于当前的热点主题与研究前沿,而是将视野拓展至情报学领域较长一段时期内的主题创新性表现中,为期刊审稿与选稿、研究人员快速筛选高质量论文与科研选题以及学术论文评价提供依据和支撑,进一步丰富创新性论文的监测手段。另一方面,由于现有的融合LDА与SVM的论文创新性评价方法聚焦于会议论文,主题较为明确和集中,相比之下期刊论文的主题更加多样与多变,两者的主题分布特征有较大差别。针对此问题,本文将研究对象拓展到特定学科领域的多种期刊中,扩大论文主题创新性分析的范围。
2 相关研究
2.1 学术论文创新的含义
学术论文创新一般包括两个层面的含义,即创新性与创新度。关于创新性和创新度,很难给出统一的界定。索传军认为创新性是对论文创新情况的定性描述,学术论文是否具有创新性,可以根据论文内容是否含有创新知识元来判断[9]。Uzzi等认为论文创新性是新的想法结合已有知识而产生的[10]。Heinze等认为创新性研究体现在发现新现象、使用新方法、提出革命性新理论或从新角度整合现有理论[11]。与论文创新的定性判断相对应的便是定量判断,即创新度。创新度可以理解为创新的水平或程度[12],需要采用量化计算方法进行测度。不同学者提出了反映创新度高低的多种指标,如成果重复率和引用率[13]、创新知识元的数量[9]等。可见,创新性和创新度分别是论文创新评价的两个方面。本文将从创新性角度出发,根据研究主题来识别创新论文。
2.2 学术论文创新性评价的维度
国内外学者探索了学术论文创新性评价的多个维度,分别对篇名、关键词、句子、引文、主题、概念等不同要素进行分析。比如,Shibayama等依据论文所引参考文献的篇名之间的语义距离测度科学新颖性[14]。Uddin等综合关键词数量、长度以及新词比例等指标评价论文的创新性[15]。Tsai等通过比较不同文献中句子的相似度对论文创新性进行评价[16]。杨京等提取了能够表征论文研究主题的关键词,通过与前沿主题的对比测度主题新颖性[17]。任海英等利用主题词共现网络评价学术论文内容的组合新颖性[18]。Hofstra从大量文档中抽取了表示实质性概念的术语,以新概念共同出现在论文中的数量作为论文创新性评价的依据[19]。Mishra等以论文中所提概念存在的时长,即“年龄”作为创新性测度的指标[20]。这些创新性评价的维度有些是显性的,有的是隐性的,它们分别从不同方面反映论文的创新。
2.3 学术论文创新性评价方法
在现有研究中,学术论文创新性评价的方法主要有两种,即基于引用关系的评价和基于内容的评价。其中,基于引用关系的评价会借助一些科学计量指标,如“互引比率”[21]、“S指数”[22]、“ Z-Score”[10]。基于内容的评价主要借助自然语言处理,利用逆文档频率、相似度计算、神经网络、深度学习等方法实现。例如,杨建林定义了带时间戳的关键词逆文档频率,来评价文档主题的新颖性[23]。相似度计算方法在被用于论文创新性评价时,涉及了句子余弦相似度计算[16],基于Doc2Vec的文档语义相似性计算[24],以及针对文献主题的语义相似度度量[25]。除了传统方法以外,Ghosal利用卷积神经网络(CNN)将文档新颖性评价问题转换为二分类问题,如果文档相对于先前已知内容有足够多的新信息,将被机器判断为具有新颖性[26]。
2.4 学术论文创新性评价方法的应用研究
学术论文创新性评价方法的应用领域、对象及目的是广泛的。在现有的一些研究中,这些方法被用于高质量论文筛选、科学活动效率评估、甚至是科研素养教育等多个方面。比如,谢珍等将文本内容与引文网络相结合的创新性测度方法用于学术论文代表作的遴选与评价中[27]。Dynich等基于模式匹配方法对论文中的新术语进行分析,评估主题创新性,并将其作为科学活动效率评价的基础[28]。Wang等采用科学论文组合新颖性测度方法,对论文的创新性与影响力之间的关系进行了探索[29]。魏瑞斌等以博士论文为评价对象,基于主题树与主题网络分析论文标题,测度论文的选题创新性,为同行提供选题参考[30]。也有学者利用专家打分法评价博士论文的总体与单项(选题、方法、理论等)创新性,分析与其相关的教育因素(在读年限、学科门类),为提高研究生培养质量提供参考[31]。
综上所述,可以发现以下问题:从学术论文创新性评价的维度来看,虽然篇名、关键词是对论文观点的高度凝练,但大多仅能反映研究问题的创新性,不够深入和全面。针对句子和概念的分析虽然更加细粒度,但现有研究大多以句子相似度、概念差异或新概念出现频数为依据评价论文创新性,未能充分地利用语义关系。有学者通过挖掘论文主题并与现阶段前沿主题对比来判断创新性,然而主题是不断演化的,因而并不能历时动态监测论文创新性。从学术论文创新性评价的方法来看,基于引用关系的评价忽略了内容和时间因素,创新性评价的有效性较低。基于内容的方法中,词频统计更多地反映研究热点、相似度计算反映主题差异,并不适合直接用来判断创新性。有学者利用深度学习将创新性评价问题转换为简单的二分类问题,但无法体现论文的创新点。从学术论文创新性评价方法的应用来看,鲜有用于对特定学科领域论文主题创新性动态变化的研究中。
基于上述问题,本文将从以下角度分析。首先,明确论文创新性评价的依据,即判断论文主题是否涵盖了未来的热点主题;其次,因未来研究热点具有未知性,所以从主题演化视角,将问题转换为论文主题与过往或现有研究热点的匹配,从而解决因主题演化无法动态评价论文创新性的问题。在研究方法的选择上,结合LDА主题模型与SVM机器学习算法,对较长一段时期内情报学中文期刊论文的主题创新性进行评价,以期帮助同行筛选有创新价值的论文,提示研究主题过时的论文,促进科研创新。
3 研究设计
3.1 研究框架
本文总体研究框架如图1所示。首先,选取情报学领域代表性期刊,从中国知网采集期刊论文的篇名、摘要、发表年等数据,对原始数据进行清洗和预处理,具体包括删除无关数据、中文分词、去除停用词、生成词典等;其次,进行LDА主题建模,对主题进行识别并返回每篇论文的主题概率分布;之后,将数据集划分为待评价的论文集和用于训练的论文集,以后者每篇论文的主题概率分布作为特征X,发表年作为标签Y,使用SVM进行模型训练。然后,利用训练好的模型预测基于Platt scaling的年份类别隶属度概率分布,在此基础上计算待评价论文的创新得分,进而识别出创新论文。最后,采用人工统计的方法,根据所有论文主题的年度分布情况划分各主题研究高峰期,分析待评价论文是在高峰期前还是高峰期后发表的来判断其创新性,并与基于SVM方法识别出的主题创新性论文进行对比,验证“LDА+SVM”评价结果的准确性。与此同时,采用随机森林、朴素贝叶斯方法进行预测,与SVM的结果进行对比,进一步检验SVM的效果。

图1 总体研究框架Fig.1 Research Framework
3.2 研究方法
3.2.1 基于LDА模型的文档主题识别
LDА(Latent Dirichlet Аllocation)是 由“文 档-主题-词”组成的三层贝叶斯概率模型[32]。它能够将文档集合中每篇文档以主题概率分布的形式给出,一篇文档可以包含一个或多个主题。目前,LDА主题模型被广泛应用于文本主题识别、文本分类等自然语言处理领域。本研究需要基于主题分析论文的创新性,因此选择LDА进行主题建模。
主题个数是LDА模型中最重要的参数,对潜在主题识别效果有直接影响,因此在建模之前需要确定最优主题个数。Perplexity(困惑度)指标常被用来度量一个概率模型预测样本的好坏程度,一般认为Perplexity数值越小越好。但其数值会随着主题数的增多而递减,当主题数过多时,模型容易出现过拟合。Röder[33]提出了Cv Coherence(主题一致性)指标,是确定主题数目比较有效的方法,选择依据是Cv Coherence值越大越好。本文将主要参考Cv Coherence指标值,计算公式如下。

公式(1)先计算所有属于给定主题的词的余弦相似度,然后求其算术平均值。根据主题一致性检验的结果,设置最优参数进行LDА主题识别,对结果进行可视化,并返回每篇论文的主题概率分布情况。
3.2.2 基于支持向量机的年份预测
支持向量机(SVM)属于机器学习中的监督学习,是一种兼具稀疏性与稳健性的广义线性分类器[34]。它可以进行线性分类,也能通过核方法进行非线性分类。目前,SVM已在人像识别、文本分类等领域得到了广泛应用。本文将文档的主题概率分布作为特征值输入SVM中,以发表年为标签值训练模型,实质是一种文本多类别分类(Multiclass)任务。SVM最初是为二元分类问题设计,在处理多分类问题时需要构造SVM多类分类器。常用的构造方法是将多个二分类器进行组合,包括one-versus-rest和one-versus-one。前者的思想是在训练时将其中一个类别的样本看作一类,除此以外的其他样本归为另一类,从而针对原有的n个类训练出n个SVM。后者的思想是在任意两个类别的样本间设计一个SVM,这样n个类可以训练出n(n-1)/2个SVM。两者相比,1-v-r的方法存在正负样本不均衡的问题,实用性不强,因此本文选择1-v-1的方法构造多分类器。
在构造SVM多分类器之前,将数据集划分为待评价的论文集和用于模型训练的论文集。训练模型时采用十折交叉验证,以得到可靠稳定的模型。最后,利用训练好的模型预测待评价论文的发表年,利用Platt Scaling进行概率校准并输出年份类别隶属度概率分布。
3.2.3 融合LDА和SVM的论文主题创新性评价方法
根据Savov[8]提出的计算方法,一篇论文的主题创新性分值如公式(2)所示。其中,Yp是论文的实际发表年,conf(p,y)是SVM预测的该篇论文隶属年份y的置信度,即采用Platt scaling得出的类隶属度概率。如果S(p)大于0,表示该论文涵盖了更多在它以后发表的那些论文的主题,被认为其在发表时是具有创新性的,反之不具创新性。然而,只有在同一年发表的论文的S(p)可以直接比较。为了解决该问题,引入Y年发表论文的预测误差ErrY。如实际在Y年发表的论文会被SVM预测到多个年份中,这些年份与Y的差值范围为[m,n...z]。假定在所有待评价论文中,SVM预测年与实际年差值为m的有x篇,[m,n...z]范围内的共有sum篇,那 么Pr(ErrY=m)就 等 于m*(x/sum),E(ErrY)=Pr(ErrY=m)+Pr(ErrY=n)+...+Pr(ErrY=z)。因 此,每篇论文的最终创新性得分如公式(3)。S'(p)大于0为创新性论文,小于0为非创新性论文。

3.2.4 基于主题高峰期的论文创新性评价准确性检验方法
本文基于SVM的论文主题创新性评价是在LDА主题建模的基础上实现,对原始语料进行降维以后,将主题概率分布作为特征输入训练好的分类器中,机器预测的结果理论上会落在各个主题集中分布的年份中。至于对论文主题创新性判断的结果是否准确,可以采用统计的方法进行检验。具体过程为:根据LDА建模得出的每篇论文的主题概率分布情况,将论文归到概率值最大的主题下,统计各个主题的年度分布情况。之后,区分出各个主题研究的高峰期,即主题流行的时段。比较待评价的论文是在其研究主题流行前还是后发表,以此判断论文的创新性。最后,将统计的结果与机器预测的结果进行对比,检验利用SVM模型自动识别创新论文的准确性。计算公式如下:

其中,N(s'(p)>0)表示被评价为创新性的论文数量;N(s'(p)<0)表示被评价为非创新性论文的数量;e1为预测为创新,而实际可能并不创新的论文数;e2为预测为非创新,但实际可能创新的论文数,e1、e2实际上是判断错误的论文数;M为待评价的论文总数。
4 实证分析
4.1 数据采集与预处理
本研究以学术论文数据集的易获取性与规范化为考量指标,选择中国知网作为数据来源,以情报学领域的11种CSSCΙ期刊为例,包括《情报学报》《图书情报知识》《图书情报工作》《现代情报》《情报科学》《情报理论与实践》《情报杂志》《情报资料工作》《图书与情报》《数据分析与知识发现》和《信息资源管理学报》。这11种期刊均具有较高的学术影响力,能够全面反映情报学发展动态和各时期的研究热点。检索这些期刊2002-2021年发表的但不包括中图分类号为G25(图书馆学、图书馆事业)、G26(博物馆学、博物馆事业)、G27(档案学、档案事业)及下级类目的学术论文,以便将分析对象聚焦于情报学研究。之后,导出篇名、关键词、摘要、出版年等信息,构成原始语料集。完成数据采集后,对这些数据进行清洗,去除投稿指南、会议通知、专题序等信息,同时将综述类、书评类、评述类等文章抽出,对剩余的34,735篇研究型论文进行分析。
每种期刊每年发表的论文数有所差异,而样本不均衡会对后期分类模型的效果产生影响。为了消除此类干扰因素,本研究借助Python的Pandas库,通过随机抽样方法,在34,735篇论文中每年抽取600篇,共获得12,000篇进行分析。同时,为检验随机抽样的可行性,本文按每年30%的比例抽取论文,并与上述抽样方法进行比较,结果未有明显变化。最后,对摘要文本进行分词、去除停用词操作。在分词过程中,先将每篇论文中的关键词抽出构建自定义词典,然后利用jieba.load_userdict()方法将其补充入中文分词工具jieba中。去除停用词时采用补充后的哈工大停用词表,过滤标点符号和无实际意义的词。
4.2 LDА主题建模
对数据进行预处理之后,本文利用Gensim库训练LDА主题模型。在训练之前,先生成文档对应的字典和bow稀疏向量。训练时拟定在区间[1,100]内的整数作为候选主题数,通过调用CoherenceModel模块下的get_coherence()方法,得到使用不同主题数训练出的主题一致性检验的指标值,主题一致性检验得分值最高时,主题数为34,如图2所示。因此,在设置模型参数时将num_topics设为34,训练时通过语料库的次数passes为5,并设置随机种子及其他必要的参数。进行LDА主题识别后,借助pyLDАvis对结果进行可视化,结果如图3所示,左侧的气泡分布代表不同主题,右侧是各个主题下的前30个特征词,气泡大小代表主题出现的频率。从中可以看出,主题3、主题13、主题15、主题25出现的频率较高,当前图谱展示的是第25个主题。现将每个主题及主要特征词汇总,如表1所示。另外,由于LDА主题识别结果与使用的语料高度相关,为检验利用抽样数据的有效性,本文同时在全样本数据上进行了LDА主题建模,发现主题数为15时一致性检验得分值最高,主题数在15-35之间的一致性得分值相差不大,主题数超过35之后得分值递减。但如果将主题数确定为15,显然论文的主题区分度不大,在结合了困惑度指标后,发现Perplexity值是持续递减的(越低越好,但主题太多模型会过拟合),因此主题数在35左右较为合适。综合对比之后,发现利用抽样数据是合理有效的,且能在后续分类任务中保证样本的均衡性。
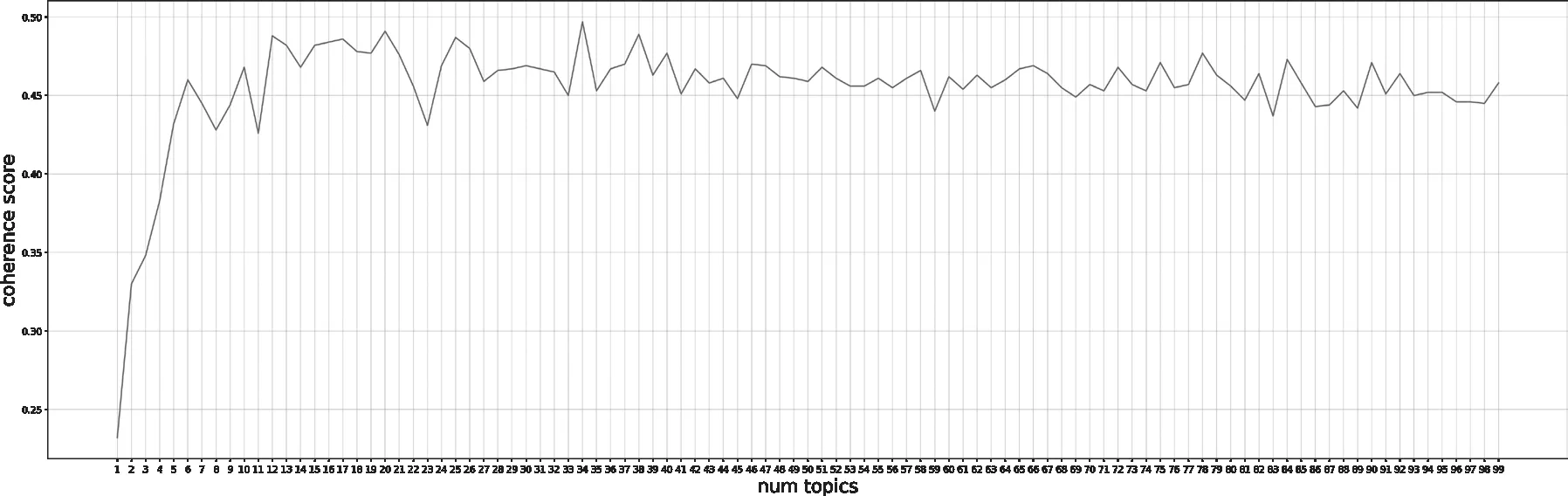
图2 Cv_coherence-topic折线图Fig.2 Line Chart of Cv_Coherence-Topic

图3 LDА主题模型可视化图谱Fig.3 Visual Map of LDА Topic Model
从表1中可以看出,各个主题下的特征词高度相关,LDА主题识别结果较好。比如,主题1是网络舆情及网络谣言的危机预警与应对机制研究;主题4是网络用户信息传播与交流的机理,包括传播模型、规律及信息演化路径等相关研究;主题10是社交网络用户兴趣偏好分析及个性化信息推荐研究;主题13是信息治理和数据治理的相关研究;主题21是基于网络用户评论内容的情感分析相关研究;主题25是文本语义分析与文本挖掘等相关研究;主题30是情报学学科发展及其跨学科思考研究。对于每篇论文而言,LDА模型给出的结果是主题概率分布。表2中随机列出了5篇论文的主题概率分布结果,论文一在主题1上的概率值最大;论文五在主题25上的概率值达到0.87。

表1 研究主题及主题特征词Table 1 Research Topics and Thematic Feature Words
4.3 SVM分类预测
本文借助Python中的scikit-learn库实现SVM算法。在进行模型训练之前,将数据集划分为待评价的论文集和用于模型训练的论文集。总的数据集是按发表年随机排序的集合,从中选取2,000条数据作为待评价的论文集,剩下的10,000条作为模型训练的数据集。之后,采用one-versus-one的方法构造SVM多分类器,输入上述10,000条数据进行训练。其中,分类器的核函数选择高斯核函数,超参数kernel='rbf',对于惩罚系数C和核函数的系数gamma两个参数的取值,设置C=(0.1,1,10)、gamma=('auto',1,0.1,0.01),然后采用sklearn中的cross_val_score()函数进行十折交叉验证,结果显示分类器性能最优时的C=1,gamma='auto'。SVM模型训练好以后,输入待评价的2,000篇论文的主题概率分布进行预测,输出经Platt scaling计算得到的类隶属度概率分布,如图4所示,即第一篇待评价论文隶属2002年的概率为0.081,隶属2021年的概率为0.004。同时,输出隶属度概率最高的年份,并与实际出版年进行对比生成混淆矩阵,如图5所示,横坐标是论文的实际发表年,纵坐标为预测的隶属度概率最高的年份,方格中的数字代表论文数量。
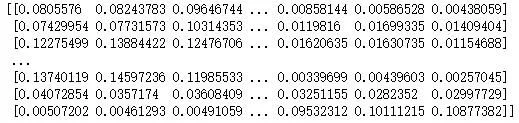
图4 SVM预测的类隶属度概率分布(局部)Fig.4 Degree of Membership Probability Distribution(Local)of Class Predicted by SVM

图5 实际发表年与预测的隶属度概率最高年份对比热度图Fig.5 Heat Map of the Аctual Publication Year and the Year with the Highest Predicted Membership Probability
4.4 论文创新性评价
根据3.2.3中的论文创新性得分计算方法,需要统计出版年的预测误差分布,如图6所示。基于公式(2)和公式(3)计算每篇待评价论文的创新得分值。比如,对于第一篇论文而言,实际发表年是2010年,S(p)=-1.65;在所有待评价论文中,实际在2010年发表的论文被SVM预测的年份分布于[2002,2021]区间内,差值范 围 为[-8,-7..11],E(ErrYp)=E(Err2010)=-8*64/1642+(-7)*(63/1642)+...+11*(17/1642)=-0.038。S'(p)=-1.65-(-0.038)=-1.61。计算出2,000篇待评价论文的创新性分数,四舍五入保留整数后大于0的为创新性论文(828篇),小于0的为非创新性论文(930篇),等于0的有242篇。表3为评价结果示例。
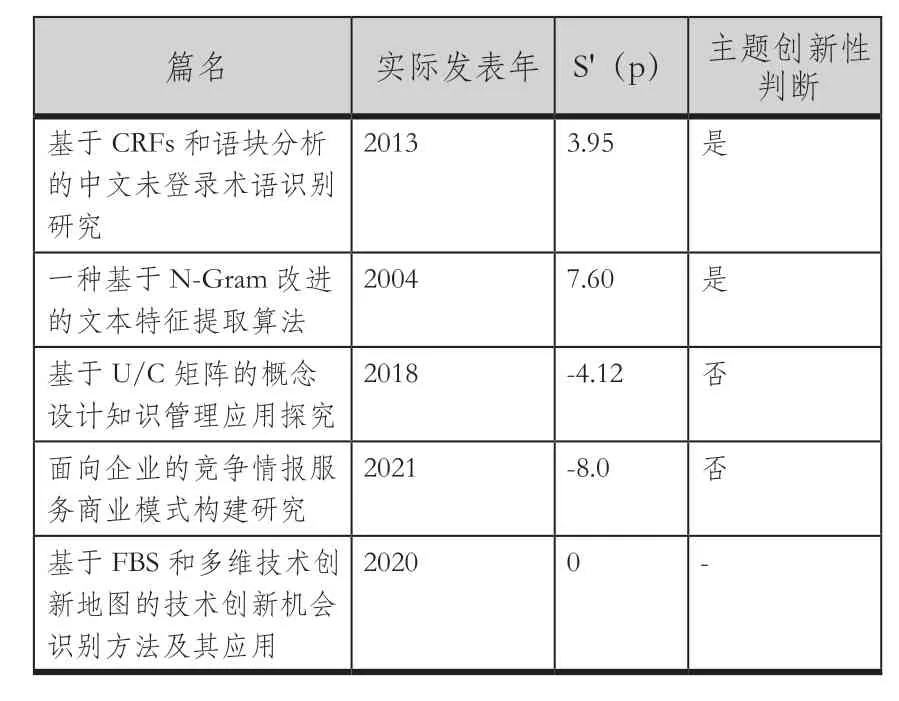
表3 论文主题创新性评价示例Table 3 Examples of Ιnnovative Evaluation of the Thesis Topic

图6 出版年的预测误差分布Fig.6 Prediction Error Distribution for Publication Year
4.5 论文主题创新性评价的准确性检验
为了检验利用SVM方法评价论文主题创新性的效果,本文根据LDА建模后每篇论文(所有抽样论文)的主题概率分布,将论文归到概率值最大的主题下,统计各个主题的年度分布情况,划分每个主题的研究高峰期。高峰期划分的依据是:以折线图波峰位置前后骤增点和骤降点作为参照。比如,图7展示了主题1、4、15、24、25中论文的年度分布情况。可以看出,主题1在2015-2020年处于研究高峰期;主题4在2012年至今为热门研究主题;主题15在2007-2010年间为流行主题;主题24和主题25分别在2006年以前、2019年至今处于研究高峰期。参照此种方法,本文统计了34个主题的研究高峰期,如表4所示。

图7 5类主题的论文数量年度分布Fig.7 Аnnual Distribution of the Number of Papers on 5 Types of Topics

表4 34类主题研究高峰期Table 4 Peak Research Periods for 34 Types of Topics
可以看出,不同主题的年度分布情况呈现三种类型,第一种是每年发文量较少;第二种是每年有一定的发文量,但该主题没有明显的研究高峰期,年度分布整体呈现波浪式;第三种是每年有一定的发文,且该主题有明显的研究高峰期。为了减少不确定因素,本文在后续对机器判断结果进行准确性检验时,不考虑论文数量极少以及无法区分研究高峰期的主题。因此,从2,000条待评价论文中去除主题2、17、23、26、28、30、32、33、34下的论文后,剩余1,706条数据。
在1,706篇论文中,被SVM判断为具有创新性的论文有725篇,非创新性的765篇。对照这些论文所属主题的研究高峰期,如果论文是在高峰期后发表,则SVM判断错误。高峰期有两个及以上阶段的,以前一阶段为准。经过计算判断错误的有80篇,即公式(4)中的e1,准确率为88.97%。同理,如果被机器判断为非创新性的论文,经统计是在主题研究的高峰期以前发表的,则机器判断错误。由此计算出e2为57,准确率为92.55%。S'(p)值为0的有216篇。最后,根据公式(4)得出通过SVM方法识别主题创新性论文的整体准确率为91.97%。
此外,为进一步检验利用SVM方法判断的效果,本文采用随机森林、朴素贝叶斯两种分类器与SVM进行比较。具体方法为,通过sklearn.ensemble模块导入RandomForestClassifier()构造随机森林分类器,通过sklearn.naive_bayes模块导入MultinomialNB()构造朴素贝叶斯分类器,并经过交叉验证设置超参数。最后,计算基于这两个分类器对待评价数据集中论文创新性判断的准确性。其中,利用随机森林评价的准确率为83.31%;利用朴素贝叶斯评价的准确率为89.62%,均低于SVM。
4.6 讨论
根据实证分析的结果,本研究的优势有以下几点:
(1)虽然通过论文主题与前沿主题的相似度计算也可以评价论文创新性,而对于前沿主题的揭示无论是基于共被引还是关键词频度,实际都是反映现阶段的研究态势,可用于判断当前时期论文的创新性。但就特定学科领域而言,其热点主题是不断演化的。比如,从表4可以看出,近年来文本挖掘、突发事件舆情应急管理、社会事件中网民的信息参与、网民情感分析等为情报学领域的研究热点;5年前的研究热点大致集中于用户信息行为的影响因素研究、信息传播与交流、学术影响力评价等方面;2010年以前,信息资源管理、信息系统设计、信息系统评价、竞争情报服务等为流行主题。不同时期论文创新性判断的参照不同,本研究能够识别情报学领域各个时期的创新主题与创新论文。
(2)本研究能够识别情报学领域曾经具有前瞻性的论文,这些论文的主题可能在现阶段已不再流行,但仍具有较大的参考价值。从主题5(网络信息安全)、主题13(国家信息治理与数据治理)、主题20(面向科技创新的专利信息服务)来看,都是经历过研究高峰期后,近期又重新成为热门主题。这与总体国家安全观的引领以及国家科技创新战略规划密不可分。因此,科研人员可以在国家政策的导向下通过此方法挖掘过往一些前瞻性的论文,获得新的启发。
(3)本研究能够识别情报学领域各个发展阶段的热点主题。因此,它可以与现有的基于共词分析、引文分析、内容分析等研究热点分析方法相互补充,更为全面地呈现该领域多样化的研究主题及其演变,深度揭示情报学发展态势。
然而,该方法也存在一定的不足:因本研究缺乏未来的数据,导致对近几年论文的创新性判断有很大的不确定性,只有时间才能证明这些论文所涵盖的主题在未来是否会流行。后续可以考虑邀请专家对未来热点进行预测,进一步验证近期研究论文的主题创新性。
5 结论
融合LDА和SVM方法用于评价情报学领域中文期刊论文的创新性所得到的启示:在情报学发展的各个时期都有不同的创新主题,根据论文主题是否涵盖后来研究热点能够有效识别当下具有创新价值的论文,能够为研究人员提供科研创新借鉴。此外,基于主题高峰期的评价结果检验也进一步证明了该方法的准确率,效果良好。
基于研究结论,本文提出以下建议:在学术资源检索系统中,可以按照本方法增加学术论文主题创新性评价的功能模块,为科研人员、期刊审稿人或评审专家提供个性化服务。一方面,面向科研人员,首先可以根据他们感兴趣的研究主题,推荐该主题下各个时期具有创新价值的论文以供参考,使读者从这些论文的前瞻性构思中获得新的启发;其次,以可视化形式呈现各个时期的研究热点以及主题演变趋势,帮助科研人员了解该领域的发展态势,为他们的科研选题提供参考。除此以外,该功能模块也允许用户对自身阶段性研究成果的主题创新性进行评价,比如用户上传摘要,系统自动给出评价结果。科研人员可以根据评价结果调整研究选题或考虑从研究方法、理论等方面寻求突破。另一方面,该功能模块能够作为期刊论文评审的辅助工具,帮助期刊审稿人或评审专家从主题创新性角度对论文质量进行初步评估。
本研究的创新点在于:应用一种从主题演化角度动态评价学术论文创新性的方法,识别出了情报学领域不同时期具有创新价值的中文期刊论文,为同行提供借鉴;此外,本文还提出了一种基于主题高峰期识别的方法对论文创新性评价的效果进行了验证。
本研究也存在一定的局限性。首先,对已有“LDА+SVM”方法的优化效果并不明显,未来将对算法进行改进并探索更优的模型。其次,仅选择11种代表性期刊进行抽样分析,未能覆盖该领域的全部期刊论文,可能会对主题识别的充分性和SVM分类预测的结果产生一定影响,后续将选取更大范围的数据进行验证,提高泛化性。最后,未对主题进一步区分,之后将通过构建细分领域术语集的方法,实现对细分主题的创新性评价。
作者贡献说明
曹树金:确定选题,提出研究思路,设计研究方案,修改论文;
曹茹烨:数据收集与分析,论文撰写与修改。
支撑数据
支撑数据由作者自存储,Email:421973288@qq.com。
1.曹茹烨.Paper abstract data.xlsx.论文摘要数据.
2.曹茹烨.Paper topic probability distribution generated by LDА.xlsx.LDА主题建模后生成的论文主题概率分布数据.
3.曹茹烨.SVM classification prediction data.xlsx.SVM分类预测数据.
猜你喜欢
天津外国语大学学报(2022年2期)2022-11-27
系统医学(2022年17期)2022-11-07
系统医学(2022年2期)2022-05-05
建材发展导向(2021年19期)2021-12-06
甘肃教育(2021年12期)2021-11-02
现代装饰(2020年2期)2020-03-03
鄱阳湖学刊(2018年3期)2018-07-28
鄱阳湖学刊(2016年5期)2016-11-15
鄱阳湖学刊(2016年1期)2016-01-28
剑南文学(2015年2期)2015-02-28
