
基于双端知识图的图注意推荐模型
2022-10-17 11:03陈平华熊建斌申建芳
计算机工程与应用 2022年20期
孙 伟,陈平华,熊建斌,申建芳
1.广东工业大学 计算机学院,广州 510006
2.广东技术师范大学 自动化学院,广州 510665
随着在线信息量复杂性和动态性的不断增长,推荐系统已成为克服信息过载的有效方法。为了提高推荐的准确率以及给推荐结果带来可解释性[1],研究学者已经开始在推荐系统中利用知识图谱(knowledge graphs,KG)作为辅助信息,考虑用户对实体的个性化偏好[2]进行推荐。将KG纳入推荐有以下三个方面优点:(1)KG中项目之间丰富的语义相关性有助于探索潜在的联系,提高推荐的准确性;(2)KG中各种类型的关系有助于合理地扩展用户兴趣,并增加推荐项目的多样性;(3)KG连接用户历史上喜欢的一个推荐项目,为推荐系统带来可解释性。传统的处理推荐问题往往从矩阵的角度考虑,矩阵里面每一行代表用户,每一列代表物品,每个点代表用户对物品的操作,将推荐问题转化为通过矩阵里面现有的点来填充那些未知的位置。图视角成为解决推荐问题的新方法,把用户和物品看作图上的节点,用户对物品的操作建立边,从而得到一个二部图,在二部图的基础上添加更多的节点和边,形成更为复杂的图,辅助二部图的计算,最终把推荐问题转化为在图上寻找高效的链接模式。近年来,图神经网络(graph neural network,GNN)因其强大的建模能力引起广泛关注,具有从图的领域对数据进行特征提取和表示的优势,与传统的图学习方法[3](随机游走和图嵌入)相比,表现得更好。对于用户-项目二部图,GNN迭代地从交互项中传播信息并更新用户向量(项目也是如此),并且增强用户/项目的表示。此外,利用GNN来学习具有图形结构边信息的压缩表示[4],然后将所学辅助信息的嵌入与来自交互项数据的嵌入集成在一起,从而提高推荐的整体性能。
1 相关工作
1.1 基于知识图谱的推荐算法
基于嵌入方法的推荐。基于嵌入的应用知识图谱在推荐系统的方法主要是通过图嵌入的方式对实体和关系进行表征[5-6],进而扩充原有物品和用户表示的语义信息。这类方法目的是将实体和关系映射到连续的向量空间中,获得低维稠密表示。Zhang等[7]使用TransR的方法在知识图谱中学习物品相关实体的结构化知识,得到物品的结构化语义嵌入表示,从而对推荐系统中原有基于协同过滤中每个物品的隐向量进行扩充。文献[8]使用TransE生成图谱中的实体和物品的表征,并进一步使用键值对记忆网络[9],基于用户历史交互数据中关联的实体得到用户的细粒度动态特征[10],从而有效地提升推荐效果。Wang等[11]则使用TransR得到的用户历史交互数据中关联的实体表征,并利用自注意力机制学习它们的加权和,进而更有效地获得用户的特征。但是,这些基于知识图谱的嵌入方法更适用于图内相关应用,主要优化目标是知识图谱补全或边预测任务,而不是推荐任务。
基于路径方法的推荐。基于路径的应用知识图谱在推荐系统的方法主要是挖掘基于图谱用户、物品之间多种连接关系[12]。由于知识图谱可以和推荐系统中的用户-物品交互数据构成一个异质信息网络,因此可以在推荐系统中引入传统的对异质信息网络[13]进行挖掘的元路径方法。在文献[14]中,作者使用卷积神经网络对每种不同元路径采样得到从用户到物品路径进行嵌入的表征[15],进而构造基于元路径的用户偏好特征,并结合NeuMF的算法构建推荐系统。在文献[16]中,作者使用元图的方式替代元路径对异质信息网络进行特征提取,元图相比元路径可以描绘异质信息网络中更复杂的特征信息。但是,这类算法严重依赖元路径或元图,需要领域知识和人工来处理,因此不适合端到端训练,当场景或图谱发生改变时,需要重新构造。
1.2 基于GNN方法的双端推荐
推荐系统中大多数数据本质上都是图结构,利用它在捕获节点之间的相关性以及对图形数据表示方面强大的能力,并且对知识图谱进行建模[2],使其优化目标与推荐系统一致,从而提升推荐效果。KGCN模型[17]的每层网络通过对异质图中每个实体采样得到其部分邻居节点,利用邻居节点上一层的状态更新该实体所在层的表征,通过多层KGCN的迭代进而得到对应物品的表征,最后利用目标函数预测用户与物品的交互行为[18]。KGAT模型[19]将用户节点视为知识图谱中的一种实体,该模型将用户-项目图与知识图谱看作为一个图,采用图注意机制学习每个节点的嵌入时,利用实体之间的关系递归传播其邻居的嵌入,并且邻居的重要性通过注意力机制来区分。RippleNet模型[11]从异质信息网络图中抽取与用户节点相连的多跳实体节点,融合利用这些实体节点的嵌入表征更新用户的表征,从而利用用户和物品表征的点积去预测推荐结果。王等人提出一种基于知识图谱的双端邻居聚合推荐算法,但该算法在物品端只是将用户邻居信息进行简单聚合,没有过多考虑项目方面的特性。
总体而言,目前利用GNN捕获KG中的信息并进一步应用于推荐中仅仅是从项目端进行建模[17],无法从用户的角度进行考察。上述现有的很多文章都在推荐系统中引入外部知识来提升推荐系统的效果,但没有过多考虑项目方面的特性,不能非常精确学习商品表示,即某些用户对同一作者的书籍感兴趣,而其他用户则对某一本书体裁感兴趣,在现实世界中,每个用户对给定的项目都有不同的看法视图,而在实体视图中,项目表示由知识图谱中连接到它的实体来定义。本文的研究基于双端知识图的图注意推荐(DGAR),为了丰富用户和实体之间的交互,提出用户实体交互模块来增强项目表示,当从知识图谱中对给定项目附近收集信息时,从用户角度使用面向用户的关系注意力模块表征每个实体之间关系和信息的重要性,利用给定用户、项目和关系的信息,确定该项目连接到哪个邻居更重要,并且对每个节点固定大小的邻域进行重要性采样,使得实验的成本在可预测范围。为了提高面向用户信息的质量,丰富包含用户点击信息的KG实体构建用户表示,使用一种偏好传播技术来探索用户在偏好集中的潜在兴趣,对高阶实体相关性进行建模并捕获用户的潜在兴趣,以此通过KG增强的用户表示来增强用户的导向信息。
2 基于双端知识图的图注意推荐模型
2.1 问题定义
在推荐方案中,用户和项目设置为U={u1,u2,…}、V={v1,v2,…}以及用户项目交互矩阵按照用户隐式反馈定义为Y={yuv|u∈U,v∈V},如果观察到用户项目之间有交互,设置yuv=1,否则就为0。此外,为了增强推荐的性能,利用知识图谱的信息,知识图谱由实体-关系-实体这样的三元组{(h,r,t)|h,t∈ε,r∈R}构成。三元组(h,r,t)描述关系r从头实体h到尾实体t,并且ε和R设置为知识图谱中的实体和关系集,此外,项目v∈V也连接着知识图谱中的一个或多个实体e,N(v)表示v附近的邻居实体。给定交互矩阵Y和知识图谱G,试图预测用户u是否对商品v有潜在兴趣。最终目的是学习一个预测函数ŷuv=F(u,v;Θ,G),其中yuv是用户u与项目v互动的概率,而Θ代表函数F的模型参数。
本文总体模型框架图如图1所示。

图1 模型框架图Fig.1 Model frame figure
2.2 项目表征计算
为了进一步提高面向用户的性能,本文通过用户-实体交互来增强项目表示,从用户的角度收集知识图谱中实体的信息,把用户-实体交互操作分为面向用户的关系注意力和面向用户的实体投影。具体流程如图2所示。

图2 用户-实体交互(包含面向用户的关系注意力和面向用户的实体投影)Fig.2 User-entity interaction
2.2.1 面向用户的关系注意力
从知识图谱中给定项目的附近收集信息时,以用户特定的方式对项目周围的每个关系进行评分,通过这个机制利用给定用户、项目和关系的信息来确定连接到该项目的哪个邻居更重要。例如,一些用户可能认为电影《钢铁侠》由它的主要演员小罗伯特·唐而出名,其他人也可能认为电影《少年派的奇幻漂流》是因为它的导演是李安而出名。每个实体邻域的权重由得分由πurv,e决定,u表示不同的用户,rv,e表示从实体v到邻居实体e的关系r(评分方法在公式(2)中给出)。通过聚合相邻实体嵌入的权重,得到面向用户给定实体邻域的最终信息

为了计算实体邻域得分πurv,e,首先将关系r∈Rs,项目表示v∈Rs以及用户嵌入u∈Rs进行串联操作,然后将它们转换为最终的面向用户的得分πurv,e:

其中,Wr∈R3s和br∈R是可训练的参数,最后对面向用户的得分πurv,e进行归一化操作:

2.2.2 面向用户的实体投影
为了进一步增强用户-实体交互,本文提出面向用户的实体投影模块,对于不同的用户,知识图谱中实体应该具有不同的信息来表征它的属性。例如,在电影推荐中,用户对演员威尔·史密斯的印象会因人而异,通过电影《阿拉丁》,有人会把他当作喜剧演员,而由于电影《坏男孩》会被人认为他是动作演员。因此,面向用户的实体投影看作是增加用户-实体交互的前一层,经过这一层的训练,再通过面向用户的关系注意模块以特定于用户的方式聚合邻域信息。实体投影机制通过将每个实体e投影到用户视图u上来优化实体的嵌入,其中,投影函数可以是线性或者是非线性:

We和be是训练参数,σ是非线性激活函数。
最后一步是将实体表示v及其邻域表示聚合到单个向量中:
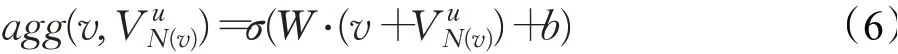
通过单层项目聚合,实体的最终表示由它自身以及直接邻居决定,将其称为一阶实体表示,并将其从一层扩展到多层,以更广泛和更深入的方式探索用户的潜在兴趣。过程如下:将每个实体的初始表示(0阶表示)传播到其邻居会导致1阶实体表示,然后继续重复这个过程,即由1阶获得2阶表示,到最后一个实体的h阶表示是其本身及其邻居的初始表示的结合,以上步骤在算法1中进行了详细的描述。H表示接收场的最大深度或者聚合迭代的次数,对于给定的用户项目对(u,v)(第1行),首先以迭代方式逐层计算v的接收场M(第10~17行),然后,将重复聚合H次(第5行):在迭代过程中,计算每个实体的邻域表示(第7行),然后将其与自己的表示聚合获得用于下一次迭代的表示(第8行),由此形成H阶实体的表示形式(第9行)。
算法1项目表征

2.3 用户表征计算
为了提高面向用户的信息的质量,丰富根据包含用户点击信息的KG实体构建的用户表示。例如,如果用户观看了《我,机器人》,由此会发现这部电影是由威尔·史密斯扮演,威尔·史密斯也在《黑衣人》和《追求幸福》中扮演角色。从KG获取用户偏好信息依赖于KG中的所有相关实体,实体之间的联系有助于人们找到潜在的用户兴趣。用户偏好的提取也适合所提出的面向用户的模块,在用户的心目中,一个著名演员的图标不仅由他们看过的电影来定义,而且由用户可能感兴趣的KG中的电影来定义。在上面所举的例子中,如果用户对威尔·史密斯有潜在的兴趣,这些模块将会很快集中在他演的其他电影身上。总之,相关KG的实体对用户表示进行了建模,并通过KG增强了用户表示,增强面向用户的信息,整个过程如算法2和图3所示。

图3 传播用户偏好集生成用户最终表示Fig.3 Propagate user preference sets to generate user final representation
算法2用户表征

定义1给定交互矩阵Y和知识图谱G,将用户u的k跳相关实体集定义为:

定义2用户u的k跳偏好集定义为从开始的知识图谱三元组:
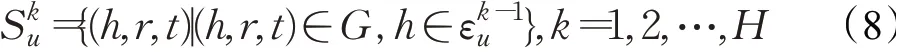
2.3.1 计算与项目嵌入的相关概率
给定项目v的嵌入向量和用户u的偏好集S1u,S1u中的每个三元组(hi,ri,ti)通过比较项目v与该三元组中的头实体hi和关系ri来分配相关概率:
陶小西说温衡的手机一直关机,他已经在火车站等了四天了,连夜晚也不敢走开,他还刻意穿了扎眼的橘红色羽绒服,只是为了让她一眼就能在人群里看见他。

其中,Ri和hi是关系和头实体的嵌入向量,相关概率pi可以视为项目v和实体hi在关系空间Ri中的相似度,并且不同的关系空间计算得到的相似度不一样。例如,《阿甘正传》和《弃儿》在考虑导演或明星时非常相似,但如果从体裁或作家的角度来衡量,彼此的共同点就少了。
2.3.2 计算输入向量


2.4 学习算法
算法3中给出了上述训练步骤的正式描述,对于给定的用户项目对(u,v),首先生成用户表示u和项目表示vu,用于计算点击率如下:

为了优化这个模型,在训练过程中采用负采样,目标函数如下:
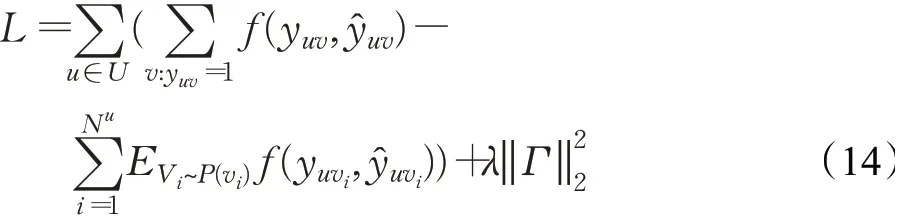
其中,f是交叉熵损失函数,p是负采样分布,并且p服从均匀分布,Nu是用户u的负采样数量,Nu=||{v:yuv=1},第二项是正则化优化。
算法3

在现实世界的知识图谱中,N(e)的大小在所有实体上都可能存在很大的差异,另外,随着跳数的增加,可能会增长得太快。为了使每个批次的计算模式保持固定和高效,对每个实体进行重要性采样,而不是使用其全部邻居,好处在于:第一,邻居节点个数可控,内存占用及计算耗时可控;第二,聚合邻居节点的过程中可以根据邻居节点的重要性聚合。具体来说,将实体v的邻域计算表示为,为每个实体v均匀采样一组固定大小的邻居S(v),其中S(v)={e|e~N(v)},而N(v)直接表示这些实体连接到v,其中|S(v)|=Kn和Kn是项目邻域的抽样规模,可以修改。在跃点p,对用户首选项集进行采样,以维护固定数量的相关实体,其中是固定的邻居样本大小,可以修改。在模型中,S(v)也称为实体v的单层接收场,因为v的最终表示对这些位置敏感,图4给出了实体的两层接收场的示例说明,其中K设置为2。
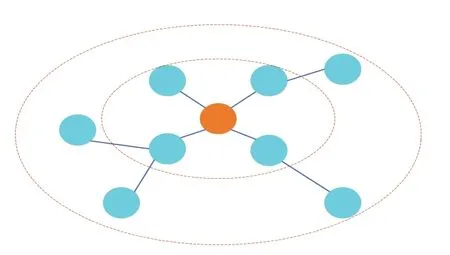
图4 知识图谱中给定实体的两层接收场Fig.4 Two layers of receptive fields for given entity in knowledge graph
3 实验结果与分析
3.1 数据集
本文主要使用MovieLens-20M、Book-Crossing、Last.FM三个数据集进行实验,将本文所提出的模型与针对这些数据集的模型进行比较,并且使用Microsoft Satori7为每个数据集构造知识图谱,从整个KG中选择一个三元组的子集,并把它的置信度设置为大于0.9。为简单起见,排除具有多个匹配或没有匹配实体的项目,然后,将商品id与所有三元组的头部实体匹配,并从子KG中选择所有匹配良好的三元组,见表1所示。
3.2 评价指标
本文将在两个实验场景评估所提出的方法:(1)在点击率(CTR)预测中,应用经过训练的模型来预测测试集中的每个互动,本文将使用AUC和ACC来评估点击率预测。(2)在前K项推荐中,使用训练好的模型为测试集中的每个用户选择K个预测点击概率最高的项目,然后选择Precision@K评估推荐的集合,所有可训练的参数均通过Adam算法进行优化。
3.3 实验结果分析
表2是按点击率预测得出的结果,通过用户-项目对作为输入,最后预测用户使用该项的可能性,在这里采用二进制分类问题中广泛使用的AUC和ACC来评估点击率预测的性能。对于top-N推荐,首先为每个用户选择N个预测点击率最高的项,然后选择Precision@N来评估推荐的集合,图5验证在ML-1M和LFM-1b这两个数据集中,本文所提出的模型产生最好的性能,另外一个数据集由于论文排版空间的原因在这里就不展示。
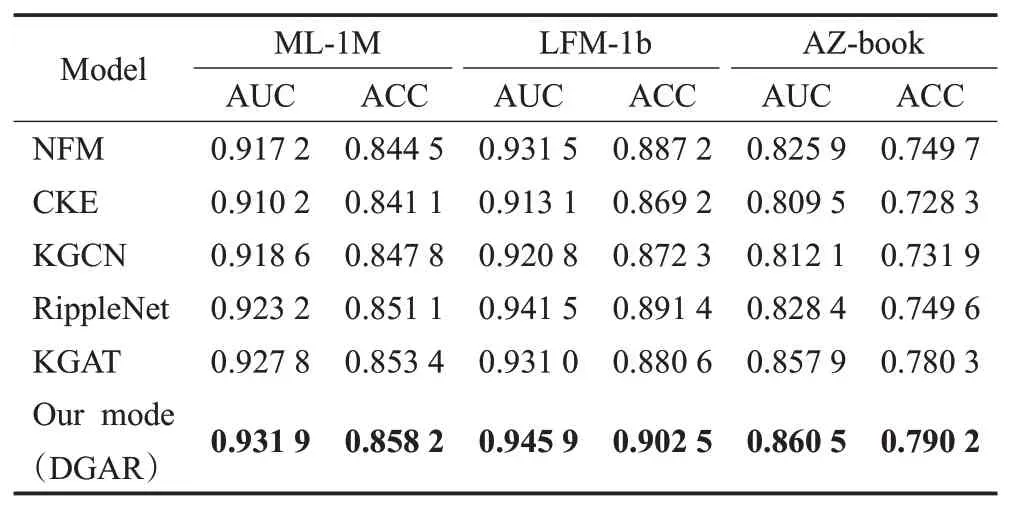
表2 不同算法在所有数据集中进行AUC和ACC的性能比Table 2 Performance ratio of AUC and ACC for different algorithms on all datasets

图5 在top-N推荐中的Precision@N结果Fig.5 Precision@N results in top-N recommendation
通过表2可以看出,DGAR在所有数据集上产生了最佳性能,并且在top-N推荐中也具有出色的性能,如图5所示。
两种基线RippleNet和KGAT优于基于协同过滤的方法NFM,表明KG有助于推荐。尽管RippleNet和KGAT取得出色的性能,但是因为RippleNet既没有将用户点击历史记录项并入用户表示,也没有引入高阶连通性,且KGAT不混合图卷积网络层信息,也不会在收集KG信息时考虑用户偏好。
KGCN没有充分利用用户点击项信息,DGAR通过用户点击项和相关实体来丰富用户表示,然后对附近的实体进行加权并强调最重要的实体。
3.4 参数分析
表3说明,将Km设置为较大值时,除了AZ-book以外,本文所提出的模型性能都会得到提高,当Km设置为32时,本文所提出的模型可以在AZ-book上获得最佳性能,主要在于这个数据集里与用户互动的项目数量比较少,也就说,当用户互动的项目很少时,Km很小仍然允许本文模型找到足够的信息来代表用户。邻居节点的影响也在表3所示,将其设置为16或32时,可以获得最佳性能,当Kn太大时会导致噪音。

表3 不同偏好集Km和邻居节点采样Kn的AUCTable 3 AUC of different preference set Km and neighbor nodes sampling Kn
更改嵌入大小时的结果显示在表4中,增大嵌入尺寸s最初可以提高性能,因为较大的s包含更多有关用户和实体的有用信息,而将s设置得太大则会导致过拟合。

表4 具有不同嵌入大小s的AUC结果。Table 4 AUC of results with different embedding s
表5说明将H从1更改为4来研究模型的接收场深度的影响,结果表明模型相对于K对H更为敏感。当H=3或4时,模型将会处于崩溃边缘,较大的H会给模型带来太大的噪声,依据实验结果,H等于1或者2时足以满足实际情况。

表5 具有不同接收深度H的AUC结果Table 5 AUC of results with different depth of receptive field H
4 结束语
本文提出一种基于双端知识图的图注意网络推荐模型,通过从用户端和项目端对现有的基于图卷积的推荐模型进行改进,考虑用户和实体的一些信息,提出的DGAR模型在知识图谱中收集个性化的知识信息来增强项目表示,并且通过知识图谱实体集传播用户兴趣,从知识图谱中捕获用户偏好信息,找到用户的潜在兴趣最终得到用户的表示,通过实验证明本文模型的优越性。未来研究中可以考虑社交网络或项目上下文这样的结构信息,将DGAR推广到相关应用中。
猜你喜欢
军事文摘(2022年16期)2022-08-24
舰船科学技术(2022年11期)2022-07-15
计算机系统应用(2021年11期)2022-01-06
当代陕西(2019年5期)2019-03-21
新城乡(2018年6期)2018-07-09
21世纪商业评论(2018年3期)2018-03-02
小天使·二年级语数英综合(2017年3期)2017-04-01
小天使·一年级语数英综合(2015年8期)2015-07-06
读者·校园版(2015年13期)2015-07-01
现代出版(2014年6期)2014-03-20
