
基于目标时空上下文融合的视频异常检测算法
2022-10-16 12:27古平邱嘉涛罗长江张志鹏
计算机工程 2022年10期
古平,邱嘉涛,罗长江,张志鹏
(重庆大学 计算机学院,重庆 400044)
0 概述
视频监控系统被广泛应用于公共场所,在维护社会治安稳定方面发挥重要作用。视频异常检测是指通过算法检测视频中不符合预期或常理的行为,旨在发现并定位可能威胁公共安全的异常行为[1]。视频异常检测主要存在两个难点[2]:一方面,异常事件有很强的场景依赖性,不同场景对异常行为的定义不同,部分场景下的正常事件在其他场景下会变成异常,如人在人行道行走时为正常,但随意穿过马路则为异常;另一方面,异常事件具有稀缺性、多样性、不可穷举性等特点。因此,视频异常检测大多采用半监督或无监督方法,利用只包含正常样本的训练集训练模型,然后对测试集进行检测。
异常事件的主体往往是视频中的行人、车辆等目标,现有的异常检测方法大多将视频帧分割成若干区间处理或是直接将视频帧输入模型,不能很好地关注发生异常的对象,易受背景干扰。在检测时,现有算法大多只考虑了时间上下文提取,忽视了空间上下文信息,而对于连续视频数据中的目标,时空上下文信息对异常检测有很大意义。时间上下文信息代表了目标的运动状态,空间上下文信息代表了检测目标和周围目标的关系。例如,在测试集视频帧中,若同时出现了行人和汽车,而在训练集中未出现过这种情况,则认为出现了异常目标。
为充分利用目标的时空上下文信息,准确检测异常目标,本文提出一种融合目标时空上下文的视频异常检测算法。通过特征图金字塔网络(Feature Pyramid Network,FPN)对目标进行提取以避免背景干扰,针对同一视频帧中的多个目标构建空间上下文,并将目标外观和运动特征重新编码。利用时空双流网络分别重构目标的外观和运动特征,两个子网络采用相同的结构,均包含自编码器和上下文编码记忆模块,并将重构误差作为异常分数。在此基础上,利用异常检测模块融合两个子网络的输出,得到最终的异常检测结果。
1 相关研究
现有的视频异常检测算法可分为传统机器学习方法和深度学习方法两类。传统机器学习方法一般包括特征提取和异常判别两步,提取的手工特征有光流直方图[3]、纹理[4]、3D 梯度[5]等,常用的判别方法有聚类判别[6]、重构判别[7]、生成概率判别[8]等。然而,基于手工特征的方法往往不能准确描述复杂的目标和行为,导致视频异常识别效果不理想。
近十年来,基于深度学习的视频异常检测研究取得了较大进展。对于时空信息的提取,目前主要有双流网络、3D 卷积和长短期记忆(Long Short-Term Memory,LSTM)网络等方法。SIMONYAN等[9]构建了时空双流网络,对视频图像和光流分别训练两个CNN模型,最终对判别结果进行合并。FAN等[10]将双流网络用于视频异常识别,利用RGB 帧和动态流分别表示外观异常和动作异常,利用高斯混合模型进行异常判别。3D 卷积也是一种常用方法,目前已有C3D、I3D、S3D 等多种3D 卷积模型[11]。NOGAS等[12]利用3D 卷积自编码器(AutoEncoder,AE)计算视频时空块的重构误差进行异常判别,该网络结构简单,具有较高的效率,但识别结果还不够理想。此外,LSTM 网络和循环神经网络(Recurrent Neural Network,RNN)也被用于对连续的视频帧进行建模,如CHONG等[13]先采用LSTM提取视频特征,再利用自编码器对特征重构从而判别异常,但该网络结构比较复杂,训练花费大。
目前常用的基于深度学习的视频异常检测网络有VAE、MemAE、GAN 等。WANG等[14]提出了一种串联VAE 的结构,通过第1 个VAE 网络过滤明显正常的样本,再通过第2个VAE网络进行异常检测。SABOKROU等[15]将CAE和GAN结合,利用GAN的判别器提升CAE的重构能力。然而,由于自编码器有较强的泛化能力,因此异常样本也可能获得较低的重构误差。为了增大异常样本的重构误差,研究者将MemAE 用于视频异常检测。GONG等[16]在AE 中加入Memory 模块,降低了模型的泛化能力,使异常样本有更大的重构误差。PARK等[17]在MemAE 的基础上添加特征分离损失,学习得到正常视频帧的多个模式,同时使用U-Net 代替编码器实现了重构和预测。然而,此类方法大多将视频帧分割成若干区间处理或是直接将视频帧输入模型,不能很好地关注发生异常的对象,易受背景干扰。IONESCU等[18]将视频异常检测视为分类问题,通过目标检测分离视频帧中的目标,然后利用K-means 算法和SVM 对目标分类,当目标不属于任何一类时,即作为异常对象被检出。但该方法将提取的目标视为单独的个体,忽略了目标与空间周围目标的关系,难以发现上下文相关的异常。
2 融合目标时空上下文的视频异常检测
本文提出一种基于目标时空上下文融合的视频异常检测算法,如图1 所示,整体检测网络由目标检测模块、时间信息网络、空间信息网络和异常检测模块组成,时空两个子网络结构相同,均由编码器、上下文编码记忆模块和解码器组成。对于视频数据集,先对各视频帧进行目标检测,得到所有目标的矩形边界框,再计算光流,在视频帧和光流图的对应位置提取目标,分别输入2 个子网络,通过空间信息网络提取外观特征,通过时间信息网络提取运动特征。在对目标进行编码、提取上下文和重构后,计算重构误差作为异常分数,利用异常检测模块融合两个子网络的输出,给出异常评价结果。

图1 基于目标时空上下文融合的异常检测网络Fig.1 Video anomaly detection network based on target spatio-temporal context fusion
2.1 目标检测
本文通过FPN[19]进行目标检测,FPN 同时融合了底层的细节信息和高层的语义信息,能够准确检测小目标,同时兼顾精度和速度。对于视频数据集X,首先分帧得到连续的视频帧X1,X2,…,XN,依次输入FPN,得到视频中所有目标的矩形边界框,再计算相邻两帧的光流图,如式(1)所示:

其中:光流图Yt由视频帧Xt-1和Xt计算得到。然后,分别在RGB帧Xt和光流图Yt上对应位置裁剪得到视频帧内的所有目标,对于每一帧Xt,经过目标检测后得到目标RGB帧和目标光流图,缩放到大小为64×64 的矩阵,以帧为单位,将上述目标分别输入空间和时间信息网络。
2.2 空间信息网络
空间信息网络的作用是提取目标对象的外观特征,经过空间上下文编码后再进行解码重构,以此判断视频帧在空间域是否存在异常目标。
2.2.1 空间自编码器
空间自编码器包含编码器和解码器两个部分。编码器将输入的RGB 帧编码为特征向量,输入为单个目标的RGB帧,输出为目标的外观特征,编码器包含4 个卷积层和3 个最大池化层,使用ReLU 激活函数,其输出的特征输入上下文编码记忆模块进行重新编码。解码器将重新编码后的特征重构,用于计算异常分数,解码器的输入为经过重新编码的特征′,输出为重构后的目标。解码器包含4 个卷积层和3 个上采样层,使用最近邻插值法进行上采样。上述过程可表示为:

其中:θe、θd表示编码器和解码器的参数;E表示编码器;D表示解码器。
2.2.2 上下文编码记忆模块
通过目标提取,可使检测网络只关注可能发生异常的目标,免受背景图像的干扰,但同时也去除了目标的空间上下文信息,即同一帧中多个目标之间的关系,如操场上车辆与行人的共现关系。为此,本文在自编码器中嵌入上下文编码记忆模块MemAE,利用空间上下文关系对目标特征进行编码并辅助目标重构,从而增大异常目标的重构误差。上下文编码记忆模块输入为编码后的目标外观特征,每次输入一帧中所有目标的特征,用于计算该帧的空间上下文,并对这n个目标的特征重新编码。首先将输入的特征图展开后得到C维的特征向量。由于出现在同一帧的不同目标之间存在关联,每帧视频可以得到n个目标,因此将它们叠加后得到一个大小为C的特征向量,作为这一视频帧的空间上下文信息,如式(4)所示:

其中:zt表示视频帧的空间上下文信息;表示目标的特征;n为一帧中的目标数,若一帧中的目标不足n个,则通过随机重复将目标添加至n个。
视频异常检测采用无监督训练方式,训练集数据全部为正常样本,其中每一帧的空间上下文信息即代表一种正常的模式,所以,来自于训练集的正常模式是对测试集进行异常检测的关键。由于自编码器具有较强的泛化能力,使得部分异常上下文信息也能较好地用于重构,因此本文在上下文编码后添加一个内存记忆模块MemAE[16],用于学习能最强表征所有正常上下文信息的有限个原型特征并保存在内存项中,该模块结构如图2 所示。内存块M是一个大小为N×C的矩阵,M∈RN×C,存储了N个内存项,每个内存项为mj,维度为C,在训练过程中更新和读取内存项,在测试过程中仅读取内存项。

图2 MemAE 模块Fig.2 MemAE module
内存记忆模块的输入为代表空间上下文信息的特征向量zt,输出由权重向量和内存项相乘得到。对于特征zt的读取操作,先进行寻址,分别计算zt和每一个内存项mj的余弦相似度,再使用Softmax 函数计算得到权重向量wt,如式(5)所示,其中d(.,.)代表余弦相似度,如式(6)所示:
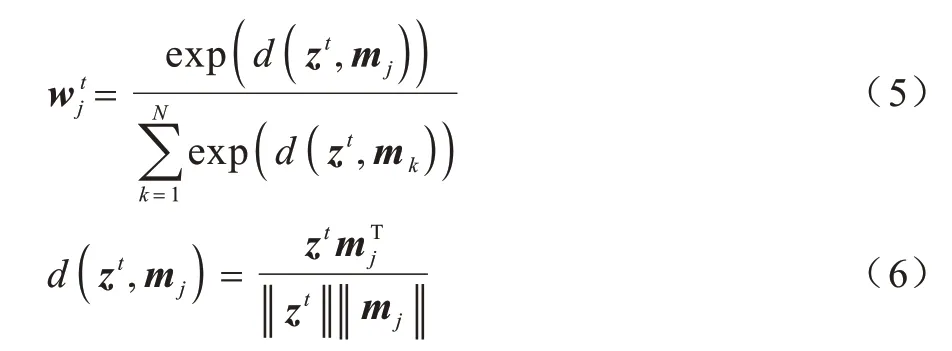
异常上下文信息也可能由一些正常特征组合得到,为了限制异常上下文信息的重构,本文对权重向量wt的每一项进行硬收缩,确保其稀疏性,如式(7)所示:

其中:λ为稀疏阈值,权重低于阈值时变为0,通过硬压缩促使模型使用更少的内存项来重构输入特征;是内存项mj的权重,对于特征zt,其与内存项mj的相似度越高,权重越大。读取操作可表示为:

其中:为特征zt对应的权重矩阵;M为内存项。
对于式(3)中计算得到的上下文信息zt,通过读取内存得到,再与每个目标的特征拼接,得到2×C维的特征向量:

2.2.3 损失函数
本文将时间信息网络和空间信息网络分开训练,空间信息网络的损失函数由外观特征损失和熵损失两部分组成。首先最小化每个目标的重构误差作为外观特征损失,采用均方差损失函数,如式(10)所示:

在内存记忆模块中,为了使编码得到的空间上下文特征zt与内存中最相似的一项相似度尽可能高,本文添加了熵损失函数,如式(11)所示:

其中:为式(7)中的内存寻址权重。平衡这两个损失函数,得到总损失函数,如式(12)所示:

其中:λrecon和λent分别代表重构损失和熵损失的权重。
2.3 时间信息网络
本文用光流代表目标的运动信息。光流具有表观特征不变性,不仅能够代表目标的运动特征,同时消除了颜色和光线强弱对异常检测的干扰,很好地弥补了RGB 帧的不足[20]。时间信息网络的输入为每一帧目标光流图,输出为它们的重构图时间信息网络结构与空间信息网络相同,损失函数由光流特征损失和熵损失组成,如式(13)所示:

2.4 异常检测



最后,将相邻10 帧视频异常分数取均值,进行分数平滑处理。
3 实验
3.1 数据集
本文实验使用USCD 和Avenue 数据集。UCSD[21]行人数据集包含ped1 和ped2 两个子集,本文使用ped2 子集,其中训练集包含16 个视频,共2 550 帧,测试集包含11 个视频,共2 010 帧,每帧大小为240×360 像素,异常行为包括自行车、汽车、滑板。Avenue[22]数据集的训练集包含16个视频,共15 328帧,其中测试集包含21 个视频,共15 324 帧,每帧大小为360×640 像素,异常事件包括跑步、错误行走方向、骑自行车等。
3.2 参数设置与评价指标
本文采用在coco 数据上预训练的ResNet50fpn目标检测网络提取目标,对于训练集和测试集,检测阈值分别设置为0.5 和0.4,以降低网络的泛化能力,扩大重构损失,目标个数n分别设置为18 和24 个,利用TVL1 算法提取光流,将所有视频帧转化为灰度图片,截取的目标调整为64×64 像素。自编码器采用Adam 优化器优化,对于空间信息网络和时间信息网络分别设置0.001 和0.000 1 的学习率,批尺寸为64,超参数λrecon=1.0,λent=0.000 2。本文采用受试者操作特征曲线(Receiver Operating Characteristic,ROC)的曲线下面积(Area Under Curve,AUC)作为评价指标,AUC 越高代表异常检测效果越好。
3.3 实验结果与分析
3.3.1 FPN 检测阈值的影响
FPN 的检测阈值决定了能提取多少目标,阈值过低可能会导致漏检,阈值过高可能会将背景误判为目标。因此,本文在UCSD-ped2 数据集上通过实验分析FPN 不同阈值对异常检测效果(AUC)的影响,实验结果见表1,从中可以看出,对训练集和测试集的检测阈值分别设置为0.5 和0.4 取得了最好的效果;对于训练集,设置较高的检测阈值可以得到更少的目标,降低网络的泛化能力,增大重构误差;对于测试集,设置较低的检测阈值会漏掉部分异常目标,影响检测效果。

表1 FPN 检测阈值对异常检测效果的影响Table 1 Inference of FPN detection threshold on anomaly detection effect
3.3.2 与其他算法的对比
将本文算法与现有视频异常检测算法在帧级AUC 上进行对比,实验结果见表2,从中可以看出,本文算法在UCSD-ped2 数据集上取得了最好的结果,与同样采用目标检测的算法FPN-AE-SVM[18]相比提高了1.5 个百分点,与采用内存记忆模块的算法Mem-AE[16]和P w/MemAE[17]相比也有较大提升,因为UCSD-ped2 数据集中每帧有较多目标,异常事件为少数自行车和汽车、滑板,融合空间上下文信息能很好地学习正常模式,检出异常目标。同时,本文算法在Avenue 数据集上也取得了较好的结果。

表2 不同视频异常检测算法性能对比Table 2 Performance comparison of different video abnormal detection algorithms %
图3 展示了在UCSD-ped2 测试集视频片段上的本文算法得到的异常分数和真实标签,其中95 帧之前为正常人行道视频(左图),之后为异常视频(右图),异常事件是人行道上的自行车,从中可以看出,当异常目标出现后,异常分数有明显的提升,算法准确定位了异常目标。

图3 UCSD-ped2 数据集上的异常分数Fig.3 Abnormal scores in UCSD-ped2 dataset
3.4 消融实验
为验证双流网络和上下文编码记忆模块的作用,在UCSD-ped2 数据集上设计对比实验,实验结果如表3 所示,从中可以看出:基于光流特征的时间信息网络效果优于空间信息网络;时空双流网络充分利用了视频中的时间和空间信息,相比于只用空间流和只用时间流网络分别提升了5.1 和0.3 个百分点;在添加上下文编码记忆模块后,3 种网络的帧级AUC 都得到了进一步提升,双流网络的AUC 上升了1 个百分点,证明了上下文编码记忆模块能够有效提升视频异常检测效果。

表3 消融实验结果Table 3 Ablation experimental results %
4 结束语
本文提出一种基于目标时空上下文融合的视频异常检测算法,通过FPN 提取目标以减少背景干扰,利用视频帧中的多个目标构建空间上下文,并对目标外观和运动特征重新编码,充分利用目标的时空上下文信息。在USCD-ped2 和Avenue 数据集上的实验结果验证了所提算法的有效性。由于目标提取过程中会产生一定的漏检,造成异常目标误判,因此后续将会选择性能更优的目标检测算法,同时针对目标之间的联系进一步优化空间上下文的构建方法。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
当代陕西(2022年4期)2022-04-19
摄影世界(2022年1期)2022-01-21
锻压装备与制造技术(2021年5期)2021-11-13
科学技术创新(2021年5期)2021-03-17
中国生殖健康(2020年7期)2020-12-10
——编码器
演艺科技(2020年7期)2020-08-13
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
商周刊(2017年6期)2017-08-22
