
基于表情识别技术的学生课堂状态检测
2022-10-14 00:55杨春金王建霞
河北工业科技 2022年5期
苏 悦,杨春金,王建霞
(1.河北科技大学信息科学与工程学院,河北石家庄 050018;2.河北太行机械工业有限公司,河北石家庄 052160)
随着人工智能的快速发展和不断完善,在线学习已成为各类教育教学的新常态[1]。特别是2019年新型冠状病毒疾病爆发后,各大高校线下教学率大幅度下降。线上教学模式不断地走进学生们的日常生活中。与传统的线下课堂教育模式相比,线上教学拥有更加丰富的学习资源,学生可以在课后重温课上视频进行复习[2]。然而,对于教师来说,在线教学是一个单向的教学过程,这种教学形式导致师生之间缺乏交流,情感缺失现象严重[3]。若学生长期一人面对屏幕,缺乏与教师之间的互动,情绪低落,学习效率低下,学习则易出现效果差等问题[4]。
学生在课堂上对知识点的掌握与学习时的面部表情具有关联性[5],国内外研究者将表情识别技术应用到学生课堂状态监测[6-9],通过学生面部表情数据,判断学生上课状态。MONKARESI 等[10]采用 Kinect 人脸跟踪器和心率检测方法检测学习者参与教育活动的情况,发现面部表情识别的准确性高于心率检测;ZALETELJ等[11]使用由Kinect One传感器获得的2D和3D数据来构建学生面部和身体属性的特征集,机器学习算法用于训练分类器,估算单个学生随时间变化的注意力水平。然而目前将面部表情识别应用于真实复杂场景中的智能教育领域,识别和分析学生在课堂上的面部表情的模型效果并不是非常理想。针对以上问题,本文在人脸表情识别技术研究的基础上设计实现在线学习表情识别系统,提出基于mini_Xception[12]架构添加通道注意力机制[13]的卷积神经网络[14](CNN)模型,提高网络模型的质量。对图像进行灰度化、数据增强[15]等处理以增加训练数据,然后将图像输入到该网络中进行训练。实验表明,该网络模型可以提高人脸识别的准确性和增强表情识别效果,并能分析学生在课堂上的参与度和状态。
在线学习表情识别系统实现了对学生表情的分析与反馈,为教师提供学生线上课堂期间的情感数据,推出学生上课的几种状态(积极、消极、中性)。其不仅可以监测学生学习状态以及有效掌握教学节奏,还可以追踪特定学生的学习状态并进行状态评估,依据评估结果及时调整学习状态,也方便教师有针对性地调整上课节奏、课堂内容以及课后知识补充内容,及时改进教学内容和方法。
1 系统架构设计
1.1 在线学习系统模型
在线学习系统是结合了在线学习与表情识别技术的情感分析模型,通过摄像头获取学生人脸图像,使用人脸表情识别技术进行人脸表情分类,结合事先设定好的“情绪-状态”分类,判定学生的学习状态,反馈给教师。在线学习系统设计的框架如图1 a)所示。

图1 在线学习系统整体实现架构
在线学习系统模型由学习模块、教学模块及情感识别模块组成,学习模块供学生使用,学生首先完成注册,然后使用注册的账号登录,便可按照课程安排进行学习;同样在教学模块中,教师首先需要进行注册,其次登录自己的账户,然后根据教学计划安排课程,进行线上授课;这2个模块面向教师和学生,功能简单易懂,方便上手。在线学习系统中的核心是情感识别模块,该模块首先通过摄像头定时截取学生人脸图像进行表情识别,得到学生在线学习时的学习状态,反馈给教师,教师通过反馈来掌握学生的课堂情况。设计该模型的主要目的是帮助教师通过学生的学习状态改进教学内容和方法,来提高学生的学习兴趣和热情。
图1 b)为图1 a)下半部分学生学习系统情感分析的模块图,也是整个系统的核心技术。其中,数据采集模块用于获取学生知识学习序列,人脸检测模块和表情识别模块用于情感识别,分析反馈模块用于反馈学生上课状态。该框架描述了学生登录系统后获取学生学习时的表情信息并进行识别反馈的基本技术要点。
1.2 情感识别模块流程
情感识别模块的核心是表情识别,它的基本流程如图2所示。过程为1)通过摄像头获取学生面部数据;2)对图像进行预处理;3)检测定位图像中的人脸,若未检测到人脸,则返回第1步,若检测到人脸,则进入第4步;4)进行人脸表情特征提取和表情分类;5)输出表情识别结果。
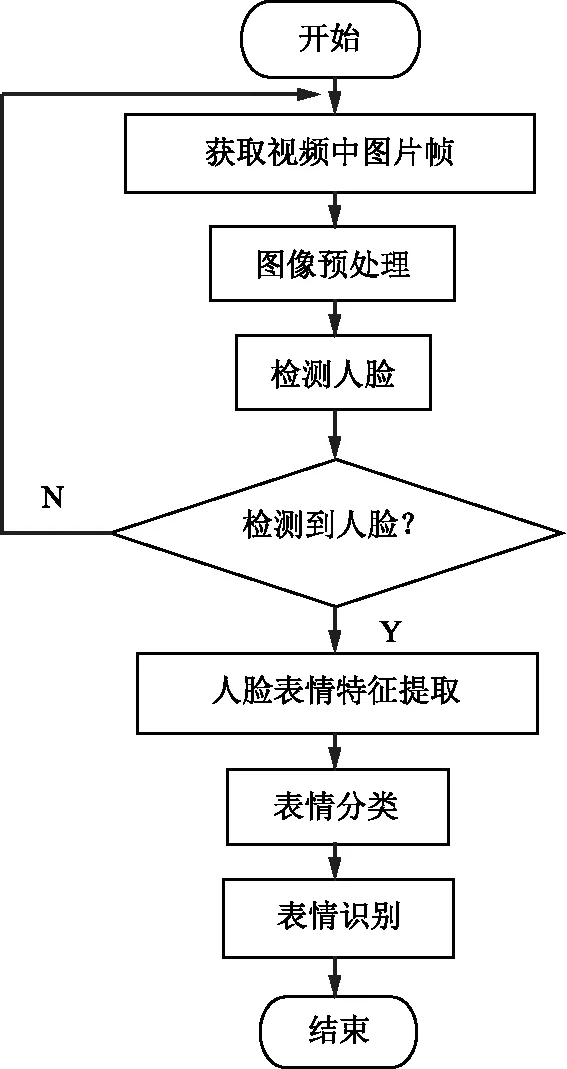
图2 情感识别模块的流程图
2 表情识别及其技术
人的面部表情是衡量人类情绪状态的一种非常直观的维度和外在表达方式,也是人际关系中一种非常重要的沟通方式[16]。1971年EKMAN等[17]建立了FACS,提出了“高兴、厌恶、生气、恐惧、吃惊、悲伤”6种基本表情。在之后的表情识别实验中,大多数人使用这6种基本表情,或者在这6种基本表情中添加一个中性表情作为研究基础。本文中,表情识别的内容主要包含以下几项:人脸图像采集、图像预处理、人脸检测和基于深度学习的网络模型的表情特征提取,基本流程图如图3所示。
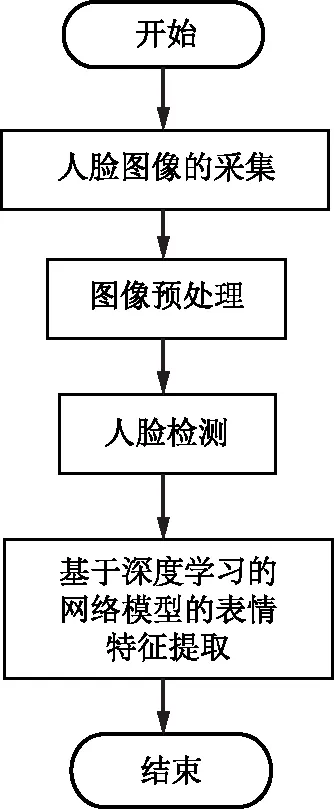
图3 人脸表情识别的流程图
2.1 人脸图像采集
当学生进入课程时,系统摄像头会自动打开,实时获取学生在课堂上的表情数据,设定固定时间,每隔几帧截取一张图像进行检测与识别。
2.2 图像预处理
在原始图像采集过程中受拍摄角度、光照强度的影响,以及传输过程中噪声或设备本身的影响,原始图像的质量会下降。直接进行原始图像检测并进行特征提取可能会导致差异偏大。因此,需要对原始图像进行初步处理,减少设备的计算量,处理过程中主要进行图像灰度化操作,将三通道彩色图转换成单通道灰度图,灰度图的转化公式如式(1)所示。
Gray(x,y)=Red(x,y)×0.299+Green(x,y)×
0.587+Blue(x,y)×0.114,
(1)
式中(x,y)为图像像素点的坐标。
2.3 人脸检测
人脸的检测方法有许多,例如使用dlib,OpenCV的Haar 级联人脸检测器[18]或多任务卷积神经网络(MTCNN)[19]等方法检测人脸。OpenCV的检测方法对光线不好、侧面的人脸可能检测不到;基于dlib的检测方法检测力度不够;因此两种方法都不适合在线学生人脸检测。MTCNN检测方法对光线不好、角度偏差大和人脸表情变化明显的图片检测效果更好,并且内存的消耗小,相对于前2种方法,更适合在线进行学生人脸检测。MTCNN是由P-Net,R-Net,O-Net构成。
1)MTCNN使用到的损失函数
人脸识别采用交叉熵损失函数,回归框和关键点采用L2损失函数,如式(2)—式(4)所示。
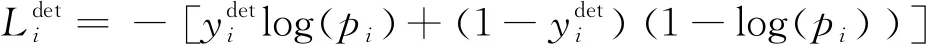
(2)
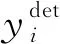
(3)

(4)
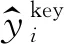
最终训练的损失函数综合了人脸识别、回归框、关键点的损失函数加权表示,如式(5)所示。
(5)

2)MTCNN检测人脸效果
当摄像头打开时,MTCNN实时检测人脸数据并绘制人脸框。图4显示了不同角度的人脸检测结果。

图4 MTCNN不同角度检测人脸效果图
2.4 基于深度学习的网络模型的表情特征提取
表情特征提取是表情识别过程中的核心步骤,对正确实现表情识别分类有着非常大的作用,确保表情特征提取的精确度可以提高表情识别的准确度,为获取学生在线学习状态提供依据。表情识别特征提取通常采用深度学习模型。
1)ResNet-18模型
ResNet[20]架构是用于图像识别的CNN模型之一,该架构已被广泛应用于各种特征提取,在ResNet网络被提出之前,传统的卷积神经网络是由一系列卷积层和低采样层叠加而成。然而,当叠加到某个网络深度时,会出现2类问题:①梯度消失或梯度爆炸。②退化问题。在ResNet的论文中,通过数据预处理和使用BN(批量归一化)层,可以解决第1类问题;在网络中添加残差结构,搭建的网络结构能够突破1 000层,同时使用批量归一化加速训练,可以解决第2类问题。本文首先采用ResNet-18网络进行训练数据和测试数据。
2)mini_Xception架构模型
mini_Xception是以Xception[21]架构为基础的,图5为该网络架构的结构图,含有4个残差深度可分离卷积,且去除了全连接层,批标准化及ReLU激活函数添加到每个卷积之后,在预测模块中使用全局平均池和soft-max激活函数,且模型参数比传统的CNN少几十倍。在实验中mini_Xception网络的训练速度和效果均比ResNet-18网络要好。

图5 mini_Xception网络架构
3)改进的mini_Xception架构模型
注意力机制是聚焦于局部信息的机制。通道注意力机制原理是通过建模每个特征通道的重要程度,然后针对不同的任务增强或抑制不同的通道。其结构如图6所示,关键操作是squeeze和excitation,在输入SE注意力机制之前(左侧空白图),特征图的每个通道的权重是一样的,通过SENet之后(右侧彩色图),不同颜色代表不同的权重,使每个特征通道的重要性变得不一样,让神经网络重点关注权重值大一些的通道。

图6 通道注意力机制结构图
为提高mini_Xception网络的特征提取和表达能力,本文提出在mini_Xception网络的基础上添加通道注意力机制,得到一种改进的网络训练模型。通道注意力机制添加到mini_Xception网络架构中的示意图如图7所示。

图7 添加通道注意力机制的mini_Xception网络架构
用这个网络模型在Fer2013[22],CK+[23]上进行训练,得到的效果均比原版的mini_Xception网络要好。通过以上几个网络模型实验的对比,最终采用改进的mini_Xception网络模型训练数据和测试数据。
3 实验与结果分析
3.1 实验环境
开发环境:PyCharm;学习框架:Tensorflow;操作系统:Windows 10(64位);程序语言:Python 3.7;实验中优化器为Adam,epoch设为 200,batch_size 为 32。
3.2 数据集采集与预处理
本实验数据集采用Fer2013与CK+。
1)Fer2013数据集将含有大量非正脸图片的灰度图数据集分为训练集(80%)、测试集(10%)、验证集(10%),图片大小为48×48,每张图片都带有标签,标签分为7种表情。图8为Fer2013数据集表情示例图。

图8 Fer2013数据集表情示例图
2)CK+数据集是从动态视频中提取出表情图片组成的数据集,每一个图片对应一个标签,标签有7种。图9 为CK+数据集表情示例图。

图9 CK+数据集表情示例图
本文通过对CK+数据集进行预处理,剪裁出人脸区域的同时删除冗余信息,生成48×48大小的灰度图。CK+数据集中可直接用于表情识别的图片数量较少,在训练过程中很容易出现过拟合,因此,在实验当中,对此数据集采用拉伸、平移、调节亮度等8种不同的方法进行数据增强,相比原始数据集扩大了9倍。
3.3 实验结果
本实验数据集采用Fer2013和CK+,在ResNet-18,mini_ Xception上进行训练和测试,得到了表1所示的识别准确率,从表1中可以看出mini_Xception上的识别准确率比ResNet-18提高了将近7%和3%,表明在本实验中mini_Xception的识别准确率要比ResNet-18好。

表1 不同数据集在不同网络模型上的准确率
本实验在mini_Xception的基础上,又做了一些改进的对比实验,在mini_Xception上添加通道注意力机制(channel attention mechanism),并在数据集Fer2013,CK+上进行训练和测试。实验结果如表2和表3所示,改进的网络模型在数据集Fer2013和CK+上的识别准确率均有一定的提高,且相比于文献[24—27]效果更好。

表2 mini_Xception与改进的mini_Xception上的准确率

表3 本文改进的网络模型与其他文献网络模型实验结果准确率对比
最后,将训练好的模型导入表情识别系统进行表情识别。表情识别系统应用到在线教学模式进行授课时,摄像头定时捕获学生面部图像进行识别,如图10和图11所示,可以准确定位到人脸并准确识别学生的表情,再将可视化数据反馈给教师,教师根据可视化信息等了解学生的学习状态和情况,进而调整教学节奏,调动学生上课的积极性,提高教学质量。

图10 人脸表情识别的部分效果图

图11 表情数据状态数据可视化图
图10为学生上课过程中,摄像头实时截取学生面部表情,将图像导入表情识别网络模型识别输出的表情结果。图11为上课过程中识别的所有表情和状态的汇总饼状图,由此可观察学生表情及状态的占比情况,其中左侧饼状图为表情饼状图,展示“高兴、厌恶、生气、恐惧、吃惊、悲伤、中性”7种表情所占百分比,右侧饼状图为在7种表情的基础上提出的“积极、消极、中性”3种学习状态的饼状图,“高兴、吃惊”表示学生的积极状态,“厌恶、生气、恐惧、悲伤”表示学生的消极状态,“中性”表示学生的中间状态。
4 结 语
人工智能与在线教育相结合的智慧学习是当代新型智能教育模式,也是教育信息化的趋势。为解决在线教育导致的学生情感信息缺失问题,提出了能够反馈学生情感状态和学习状态的模型,并详细描述了其原理及流程。通过在课堂上采集学生学习时的表情数据构建了学生面部表情识别数据集,采用添加通道注意力机制的mini_Xception网络模型对学生面部表情进行分类,再将分类结果与ResNet-18网络、原始mini_Xception以及多个已有文献[24—27]的分类结果进行比较,经过多次对比实验表明,本系统采用的方法获得了较高的准确率。应用表情识别技术,实时监测学生表情,为教师提供可视化的课堂数据,使教师能够了解学生课堂状态,及时调整教学内容和方法,增强学生上课积极性,提高在线学习的教学质量。
本方法虽然能够很好地识别人脸表情,但是在遮挡、侧面以及光线不足等情况下,表情识别效果被影响的问题仍未得到很好解决,为了解决这些因素的影响,未来的表情识别研究重点可以放在如何消除眼镜框遮挡、脸部遮挡、侧面人脸和光线不足等的影响上,以便于表情识别技术可以在更复杂的环境中使用[28]。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
小学生作文(低年级适用)(2019年5期)2019-07-26
动漫星空(2018年9期)2018-10-26
读友·少年文学(清雅版)(2018年12期)2018-04-04
山东青年(2016年3期)2016-02-28
奇闻怪事(2014年5期)2014-05-13
汽车与新动力(2012年1期)2012-03-25
