
一种噪声鲁棒的人脸融合攻击检测方法
2022-10-14 02:01张超曹秀莲蔡鹃张乐冰
网络安全技术与应用 2022年9期
◆张超 曹秀莲 蔡鹃 张乐冰
(1.国家计算机网络网络应急技术处理协调中心湖南分中心 湖南 410000;2.怀化学院 湖南 418000)
随着人脸识别技术的迅速发展,人脸识别系统广泛应用于日常生活中,如自动边界控制系统可以通过自动读旅行证件(eMRTD)轻松验证用户的身份[1-2]。然而,最近出现了一种新的针对人脸识别系统的欺骗攻击——人脸融合欺骗攻击[3]。攻击的方式如下:首先,由两幅或多幅真实人脸图像生成一幅与融合参与者外观相似的融合人脸图像,然后将融合人脸图像作为身份模板注册到人脸识别系统中,使其能与所有融合参与者匹配,如图1 所示。这意味着,“罪犯份子”可以用自己的照片与其“协助者”的照片生成一张人脸融合图像,以“协助者”的身份申请合法的eMRTD 或护照。

图1 融合人脸示意图
近年来,已有不少学者对人脸融合攻击下商用人脸识别系统的安全漏洞进行研究。文献[3-10]提出了一系列融合人脸检测方法,然而,上述融合人脸检测方法主要面向可控环境,对非受控场景的应用缺乏足够的泛化能力,在不同图像质量应用环境下的稳定性与鲁棒性较差。为此,本文提出了一种抗噪声的融合人脸检测方案,它采用端到端卷积神经网络结构,利用卷积自动编码网络生成去噪人脸图像,并通过融合人脸鉴别网络对去噪人脸图像进行人脸融合攻击检测,提高了融合人脸检测算法的鲁棒性。
1 相关工作
目前,人脸融合欺骗攻击取证的相关研究尚处于起步阶段,有关人脸融合攻击的研究主要集中在人脸识别系统对人脸融合攻击的脆弱性和融合人脸检测方法两个方面。
1.1 人脸识别系统的脆弱性研究
Ferrera 等人最早对人脸融合攻击进行了研究[3],通过使用软件生成与多人相似的融合人脸图像,使其与人脸识别系统中的多人相匹配。然而,该文中的融合人脸图像采用手动方式生成,不适合大批量的生成融合人脸图像来验证人脸识别系统的脆弱性。随后,Andrey 等人提出了一种自动融合人脸生成技术[5],利用该技术可以快速、自动、大批量的生成融合人脸图像,不仅肉眼无法区分其真伪,并且几乎可以完美欺骗商用人脸识别系统Luxand FaceSDK 6.1。同时,Robertson等人研究了伪造身份证件的潜在方法[7],他们认为在实际应用场景中完全可以通过融合人脸图像来伪造身份。文献[8,9]中提出了一些评价指标来评估生物识别系统在人脸欺骗攻击下的安全性。此外,Wandzik 等人研究了基于深度学习的人脸识别系统面对人脸融合攻击时系统的脆弱性[10],证明了人脸融合攻击可以轻易地欺骗这些基于深度学习的人脸识别系统,极大的威胁了基于深度学习的人脸识别系统的安全性。因此,针对融合人脸攻击的检测逐渐成为生物识别系统安全领域的一个研究热点。
1.2 融合人脸检测方法研究
现有融合人脸检测方法按照是否使用辅助图像可分为盲检测和非盲检测两类方法。目前大多数人脸融合欺骗攻击检测方法 都属于盲检测方法。
(1)融合人脸盲检测方法
人脸融合欺骗攻击的盲检测方法主要侧重于捕捉融合人脸图像与真实人脸图像之间的差异,适用于在线电子护照申请或人脸识别系统注册时对人脸融合欺骗攻击进行检测。考虑到融合人脸图像和真人脸图像之间的纹理差异,Raghavendra 等人最早提出了一种融合人脸自动检测方法[6],该方法利用二值统计图像特征(BSIF)来表示融合人脸图像和真实人脸图像之间的纹理差异。由于融合人脸图像通常是由真实人脸的JPEG 图像生成的,并以JPEG 格式存储,这会导致融合人脸图像质量的下降和“JPEG 伪影”效应。因此,Andrey 等人[5]和Hildebrandt 等人[11]分别提出了基于JPEG图像质量特征的融合人脸检测算法,通过从量化的DCT 系数中提取Benford 特征检测融合人脸图像。Kraetzer 等人[12]使用八个关键点/边缘算子来表示人脸图像经过融合后的图像退化效果。类似的,T.Neubert[13]提出了一种基于JPEG图像的连续压缩退化的融合人脸检测算法。
Raghavendra 等人[14]提出了一种基于AlexNet 和VGG 网络的深度卷积神经网络,实现对数字/打印-扫描融合人脸图像的检测。随后,C.Seibold 等人[15]分别考察了AlexNet、VGG 和GoogleNet 三种典型网络,并证明预训练的VGG19 网络[16]比其他两种网络在融合人脸的检测中能够取得更好的效果。
此外,受到图像来源取证思想的启发[17-18],文献[19]提出了一种基于传感器模式噪声统计量化特征的融合人脸检测算法。与此同时,L.Debiasi 等人[20]使用传感器模式噪声频谱直方图的统计特征进行了融合人脸检测。
(2)融合人脸非盲检测方法
Ferrara 等人[21]使用人脸识别系统获得的辅助图像和生物特征护照中显示的面部(融合)图像,采用融合人脸生成逆运算的方式实现对人脸融合攻击协助者的面部图像恢复。文献[22]中提出了一种基于对抗生成网络的人脸融合攻击协助者溯源的方法,较好地实现了人脸融合攻击协助者的面部图像重建。
基于以上分析,可以发现尽管融合人脸攻击检测的研究虽然取得了一定的进展,形成了一些检测体系,但总体来说仍处于起步阶段,距离商业化、实用化的阶段甚至为司法机构提供可靠的法律证据还有很大的差距,仍然存在许多问题亟须解决。而且现有的融合人脸攻击检测方法多是在可控环境下进行测试的,对非受控场景的应用缺乏足够的泛化能力,在不同图像质量的应用环境下缺乏较好的稳定性与鲁棒性。因此,在实际应用中如何提高融合人脸检测方法抵抗噪声的干扰是提高人脸识别系统稳定性的重要问题。为此,本文提出了一种噪声鲁棒的融合人脸检测方法。
2 基于深度学习噪声鲁棒的人脸融合攻击检测方法
为了抑制噪声对融合人脸检测的影响,提高检测方法对各类噪声的鲁棒性,本文方法增加了去躁过程,首先对噪声人脸图像进行自适应去噪,然后再对去噪后的人脸图像进行融合人脸检测,其体系结构如图2 所示,由自适应去噪网络和融合人脸鉴别网络两个部分组成。
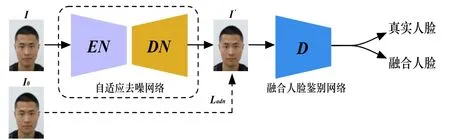
图2 噪声鲁棒融合人脸检测框架
其中,自适应去噪网络由编码网络EN 和解码网络DN 两部分组成。
2.1 自适应去噪网络
本文提出的噪声鲁棒融合检测框架包含了一个自适应去噪网络,采用噪声鲁棒无监督学习技术。自适应去噪网络由编码网络EN 和解码网络DN 两部分组成。编码网络EN 和解码网络DN 的结构分别如表1、表2 中所示。

表1 编码网络结构

表2 解码网络结构
给定含噪的人脸图像I,编码网络EN 用于提取I的身份特征,解码网络DN 用于生成无噪的人脸图像。为了有效地抑制I中的噪声,在训练阶段提供I 的辅助图像(无噪声)I0。从而使生成的无噪声面部图像尽可能接近辅助图像I0。这里,采用损失,自适应去噪网络的损失定义为:
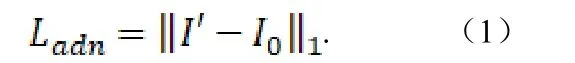
自适应去噪网络生成的去噪面部图像如图3 所示,通过采用自动编码器结构,自适应去噪网络可以有效地去除人脸图像中的噪声并生成去噪后的人脸图像。

图3 自适应去噪图像的示意图
2.2 融合人脸鉴别网络
对噪声人脸图像进行自适应去噪后,采用融合人脸鉴别网络进行融合人脸检测。本文方法采用了分类效果较好的VGG19[16]网络,卷积层使用3×3 卷积核,包括一个前置层和一个后继层。同时,将网络最后一个完全连接层上的输出转换为1×2 大小的向量,以区分图像是真实图像还是融合人脸图像。

3 实验结果分析
3.1 实验设置
由于目前尚无公开的融合人脸数据库,本文创建了一个含噪声的融合人脸数据库。为确保数据集中的训练集、验证集和测试集中受试者的不相关性,本文在训练集、验证集和测试集中独立生成了大量的融合人脸图像。每个子集均按照文献[5]中提出的框架自动生成两种类型的融合人脸图像(整体融合图像和拼接融合图像),并在此基础上生成了四类含噪人脸图像(密度0.01 的椒盐噪声、密度0-0.3 的均匀噪声、标准差0.01 高斯噪声和均值0.15 标准差0.08 的瑞利噪声)如图4 所示。

图4 四类含噪融合人脸示意图(左半脸为无噪声人脸,右半脸为含噪人脸)
最终创建的融合人脸数据库中共包含了9004 幅含噪真实人脸图像、6864 幅含噪整体融合人脸图像和7312 幅含噪拼接融合人脸图像,详细信息如表3 所示。
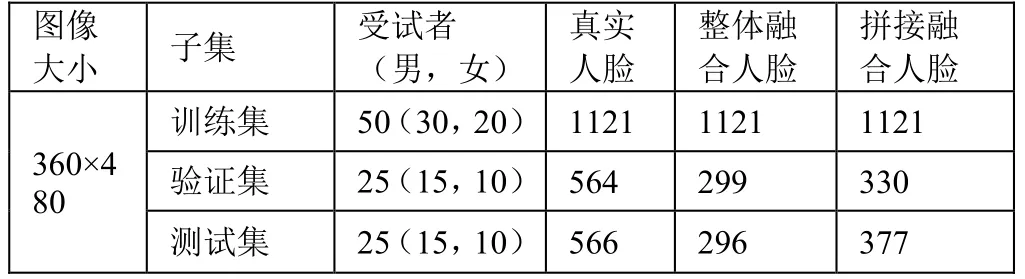
表3 含噪声融合人脸数据库概况(在各类噪声情况下)
在实验中,我们选择ISO/IEC 度量标准[23],即真实呈现分类错误率(BPCER)和攻击呈现分类错误率(APCER),以评估检测性能,并以平均分类错误率(ACER)来衡量对含噪融合人脸方法在测试集中的总体检测性能。
3.2 不同类型噪声下的检测性能比较
通过将本文方法与当前一些典型的融合人脸检测方法进行比较,如基于纹理特征的方法[6]、基于JPEG 压缩特征的方法[12-13]、基于SPN的方法[19-20]和基于深度学习的方法[15],实验结果证明了本文方法的良好性能。
相关融合人脸检测方法在四种噪声下的性能如表4-表7 所示。显然,在不同噪声干扰下,本文提出的方法均可以获得更好的ACER。在不同噪声干扰(高斯噪声、均匀噪声、椒盐噪声和瑞利噪声)和不同类型的融合人脸融合(整体融合和拼接融合)下,本文方法的ACER通常比其他方法低50%。例如,在高斯噪声、拼接融合等情况下,本文提出的方法的ACER 为11.08%。它比次优结果方法[15]的错误率低了53.52%。
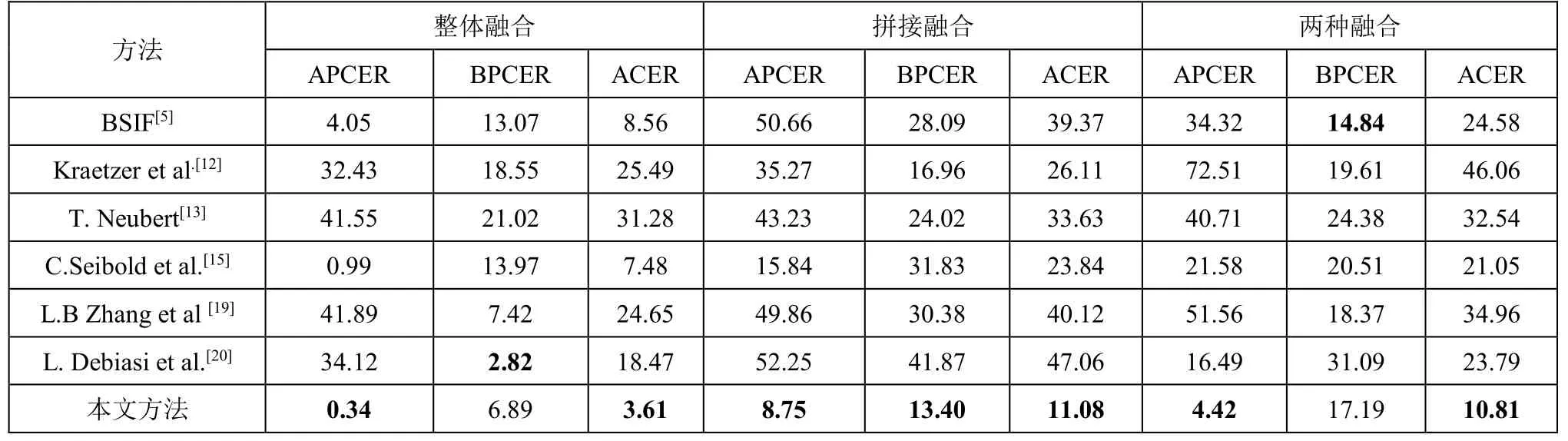
表4 高斯噪声下各检测方法性能比较 (%)

表5 均匀噪声下各检测方法性能比较 (%)
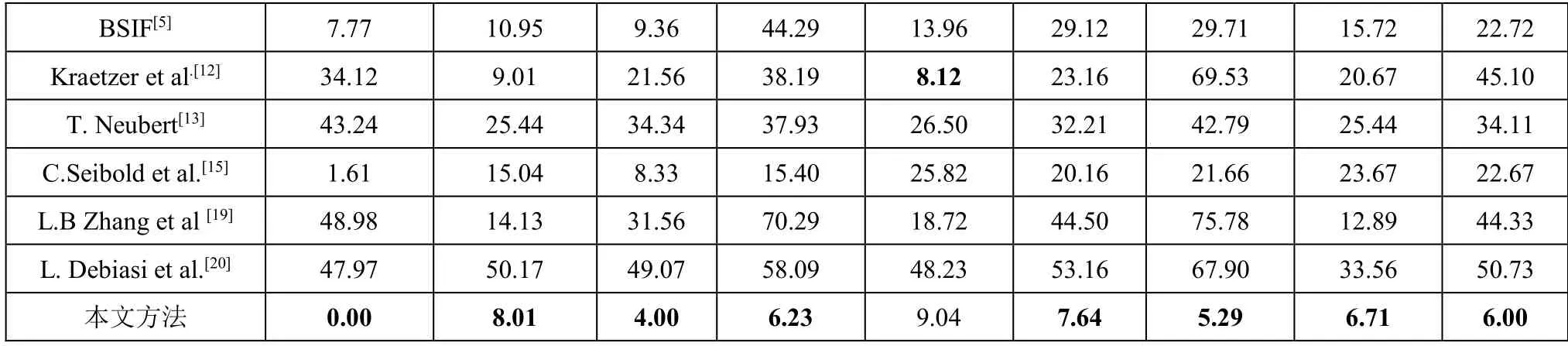
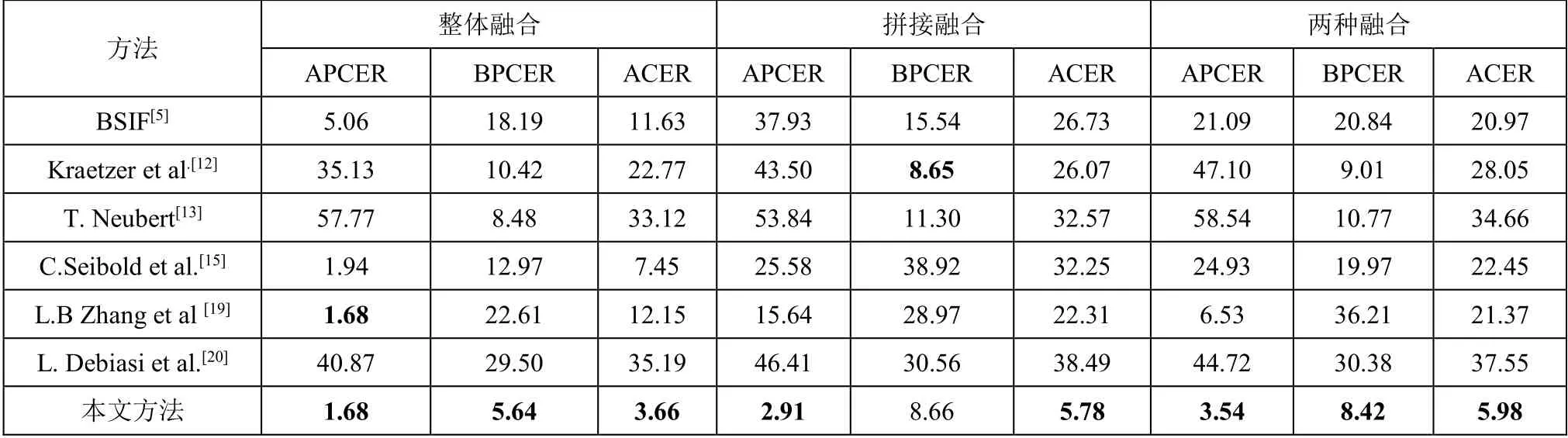
表6 椒盐噪声下各检测方法性能比较 (%)

表7 瑞利噪声下各检测方法性能比较 (%)
图5—8 显示了四种类型噪声下不同融合人脸检测方法检测误差折衷(DET)曲线,结果同样表明本文提出的方法具有最佳检测性能。
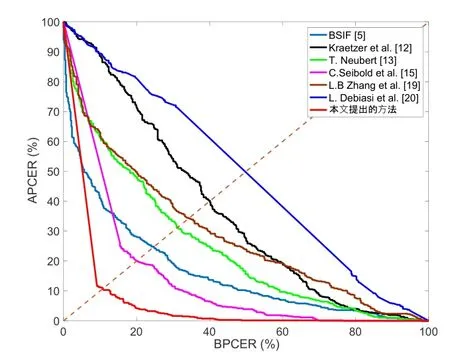
图5 高斯噪声下不同检测方法的DET 曲线

图6 均匀噪声下不同检测方法的DET 曲线

图7 椒盐噪声下不同检测方法的DET 曲线
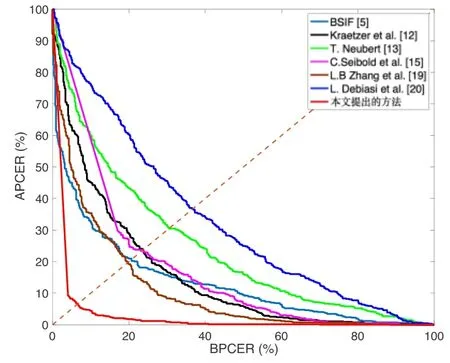
图8 瑞利噪声下不同检测方法的DET 曲线
此外,在实际检测环境中,未知类型的噪声可能会影响融合人脸检测方法的性能。因此,单类噪声测试可能无法准确反映实际情况。为了测试该方案的泛化能力,本文还进行了跨噪声评估。它在一类含噪人脸图像上进行训练,在另一类含噪人脸图像上进行测试。在跨噪声下的拼接融合攻击检测的结果如表8 所示。

表8 四类噪声下的跨噪声检测ACER 性能比较(%)
由表8 可以看出,本文提出的方法在跨噪声检测中效果最佳。例如,以含高斯噪声的人脸图像作为训练集,使用含椒盐噪声、均匀噪声和瑞利噪声的人脸图像作为测试数据集时,本文所提出的方法的ACER 分别为8.42%、8.81%和9.64%。这比其他的次优方法的结果错误率分别降低了71.97%、62.27%,67.96%。
值得注意的是,某些方法的ACER 为50%,是由于这些方法的APCER/BPCER 为100%,而对应的BPCER/APCER 为0%。意味着在这些方法中,所有测试人脸图像(真实人脸图像和变形人脸图像)都被错误分类为真实人脸图像(或变形人脸图像),即这些方法在跨类型噪声情况下是无效的。
实验结果和分析表明,本文提出的检测方案较传统的基于纹理特征的方法[6]、基于JPEG 压缩特征的方法[12-13]、基于SPN 的方法[19-20]和基于深度学习的方法[15]能显著降低各类噪声对融合人脸检测的影响,提高了检测的鲁棒性。
4 结论与展望
本文提出了一种新的噪声鲁棒的融合人脸检测方法,采用端到端卷积神经网络结构,由自适应去噪网络和融合鉴别网络组成,可以有效地抑制噪声对人脸融合攻击检测的影响。实验结果表明,与现有方法相比,本文提出的融合人脸检测方案对噪声具有较强的鲁棒性。今后我们将致力于更复杂的自适应去噪网络的研究,使其能抵御多种噪声的干扰,并进一步研究含打印/扫描噪声的人脸融合攻击检测方法。
猜你喜欢
作文中学版(2022年1期)2022-04-14
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
数学年刊A辑(中文版)(2020年3期)2020-10-27
学生天地(2020年31期)2020-06-01
电子制作(2019年14期)2019-08-20
动漫星空(2018年9期)2018-10-26
中学生数理化·八年级物理人教版(2017年9期)2017-12-20
电子制作(2017年1期)2017-05-17
噪声与振动控制(2015年4期)2015-01-01
