
基于智能磨矿介质及CNN 和优化SVM 模型的球磨机负荷识别方法
2022-10-14 09:36徐怀兵邹文杰赵建军张志军
工程科学学报 2022年11期
徐怀兵,王 廷,邹文杰✉,赵建军,陶 乐,张志军
1) 北京科技大学土木与资源工程学院,北京 100083
2) 矿冶过程自动控制技术国家重点实验室,北京 102628
3) 中国矿业大学(北京)化学与环境工程学院,北京 100083
球磨机广泛应用于矿山、玻璃、陶瓷、水泥、化工等工业领域,在选矿厂中使用球磨机粉磨矿石以实现脉石和有用矿物间的单体解离,为后续选别作业提供质量和流量合格的原料,磨矿产品质量直接关系着整个选矿厂的经济和技术指标.在磨矿过程中,真正用于破碎物料的能量仅占总能耗的10%~20%,且在生产过程中球磨机长期处于欠负荷状态运行,甚至时有空磨、涨肚等现象发生,以上问题直接导致球磨作业的高耗低效[1-2].因此,科学、准确地预测磨机内部负荷是保障磨机在最佳负荷状态运行的重要基础,对磨矿过程节能降耗、提质提产具有重要意义.
目前,国外学者通过研究磨机运转过程中产生的振动信号、振声信号、电机电流、扭矩变化来预估磨机负荷状态,这些方法经过优化已形成系列产品,如Millsense、Sensomag、MillVis、StarCS 和LoadIQ 等检测仪表,在大型自磨机及艾萨磨机获得一定的工业应用[3-4].然而,决定磨机内部负荷状态的转速、填充率、磨矿浓度、料球比、介质级配等参数之间耦合作用复杂且时变性较强,给料量、入料粒度分布、磨矿浓度、加球量、球配比等内部负荷参数无法在线检测和显性描述,使得各种检测方法各有优缺点.以振动法为例,电压频率发生变化、衬板和钢球磨损或者磨机转速的微小波动等会使物料负荷控制点产生漂移,从而降低振动检测信号的可靠性,且振动法难于检测出介质充填率及磨矿浓度[5-6],目前还没有相关的补偿措施来优化这一问题.上述所检测的外部响应信号难以实时准确的反映磨机内部的负荷情况,给磨机综合运行状态的控制和优化带来较大难度.
磨机内部的物料运动状态一直是领域内关注的焦点,磨矿过程中钢球介质的运动特征信号可通过嵌入了传感器的磨矿介质来获取.Dunn 和Martin[7]使用嵌入加速度传感器的检测球检测磨机内部钢球的最大冲击力,但因采样频率过低以及钢材杨氏模量值设置为不合理的103GPa,导致其测量数据与Hertzian 理论难以有效对应.Rolf 和Vongluekiet[8]在φ0.8 m×0.4 m 规格的实验室磨机用检测球探寻了钢球的冲击能量分布情况,试验结果表明,在转速率为75%时冲击频率最高,与离散元模拟验证结果基本一致.Gao 和Thelen[9]设计了一款带有压电传感器的直径40 mm 的检测球,通过磨矿介质充填率条件实验发现冲击频率随转速率升高从每分钟30 次大幅降低至每分钟7 次.Martin 等[10-11],Yin 等[12-13]设计出一种带有加速度传感器的检测球来获取磨矿介质的加速度、角速度等运动参数,但是该方法使用的球体未与普通磨矿钢球在重心、密度、体积上保持相同,难以模拟真实钢球介质的运动状态.
综上,磨矿介质内部嵌入传感器后可模拟普通钢球以获得其在磨机内部的运动特征信息,已有研究并未实现嵌入传感器的模拟钢球与实际磨矿钢球在尺寸、重心、密度以及介质表面粗糙度上的一致性,而且缺乏对所测数据识别磨机负荷模型的深入研究.本研究设计了一款内嵌加速度传感器且与钢球介质物理性质相一致的智能磨矿介质用于识别磨机负荷,通过设计磨矿条件试验以获取不同负荷状态下智能介质的运动信息数据,对数据进行降噪及特征值提取预处理后,在一维数据和二维图源下分别使用优化的支持向量机(SVM)和卷积神经网络方法(CNN)进行分类识别,最终实现负荷状态分类与预测,为实现球磨机负荷检测与在线评估提供重要解决方案与技术保障,也为磨矿机理研究提供一种新方法.
1 基于智能磨矿介质的磨机负荷试验设计
本文设计的智能磨矿介质保持与普通钢球介质的重心、密度和表面粗糙度等物理特征上的一致性,并充分考虑智能磨矿介质的耐磨性、抗冲击性及密封性,其主要由传感器封装体、2 个配重钨块以及不锈钢外壳构成,印制电路板PCB 上主要集成CJMCU-375 型加速度传感器、TF 卡、STM32F103型微处理器、USR-C322 型无线传输模块,PCB 与电池模块由盖板经螺丝和凹槽镶嵌组装为传感器封装体,2 个配重钨块于球壳内部两端对称布置,两个半球壳嵌合后连接,智能磨矿介质直径70 mm,平均密度为7850 kg·m-3将智能磨矿介质混入石英砂、普通钢球共磨处理以实现与磨矿介质表面的粗糙度相一致.
由于钢球磨介在运转的磨机内部存在滑移、抛落、旋转、死区停滞等运动情况,故智能磨矿介质选用三轴加速度传感器实时记录各方向的三轴加速度数据,采样频率为1 kHz,其检测到的信号经单片机微处理器进行压缩、调制、滤波等预处理后,由无线传输模块发送至计算机进行处理分析.此外,还设计了用于离线使用的TF 数据存储模块,因为无线传输模块处于智能磨矿介质外壳和磨机外壁双层金属屏蔽下,出现了较严重的传输不稳定以及数据丢包现象,所以本文中智能磨矿介质所获取的试验数据均通过离线的TF 数据存储模块记录.根据上述因素选择各模块型号和进行相应通信电路设计.智能磨矿介质的结构组成及检测模块设计在文献[14]中有详细介绍.
本文的试验系统由实验室球磨机、智能磨矿介质(数据采集端)、上位机(数据处理端)构成.首先使用智能磨矿介质采集球磨机在不同充填率条件下的欠负荷、正常负荷、过负荷三种行为状态下的加速度数据,然后微处理器将加速度信号进行预处理后传输至上位机进行后续的分析与处理,最终利用SVM 以及神经网络对球磨机负荷状态进行分类与识别.图1 为球磨机负荷状态识别总体方案.

图1 球磨机负荷状态识别总体方案Fig.1 Overall scheme of ball mill load status identification
本文采用SM500×500 小型球磨机开展干式磨矿试验,球磨机转速率设定为80%.试验样品为广元某矿山的岩沥青矿石,平均密度为2300 kg·m-3.根据文献[15]确定磨矿钢球的级配为30 mm∶40 mm∶50 mm∶70 mm=30∶20∶30∶20,根据式(1)计算10%~50%五种充填率条件所需钢球数量.每种充填率条件进行一组磨矿试验,分别加入矿石6 kg,磨矿时间为10 min,取矿样后继续磨50 min,每组试验重复三次.使用式(2)合成智能磨矿介质经试验采集到磨机不同负荷状态下的三轴加速度数据.定义磨矿效果系数为每组负荷试验归一化后的-200 目产率和电耗之比,将其作为评价磨矿效率的指标[14],结果如表1 所示.
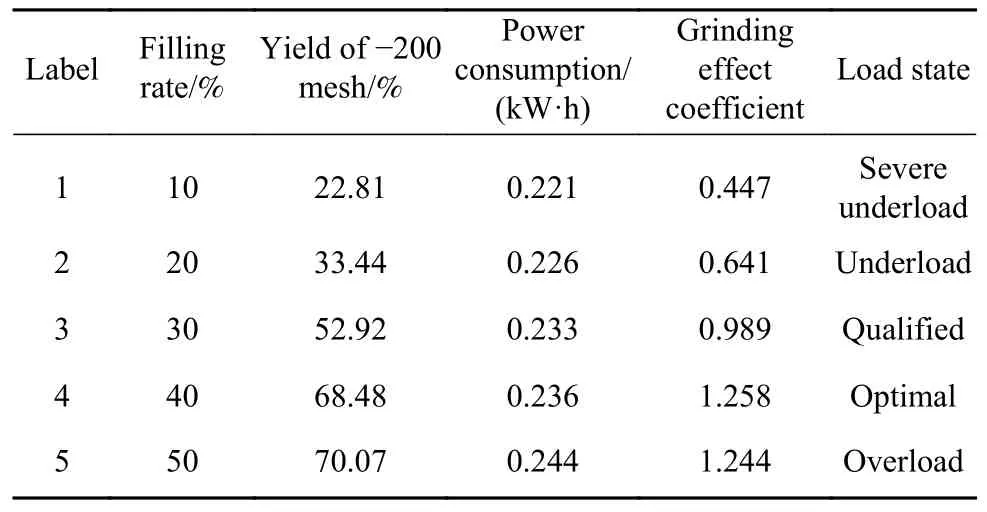
表1 5 种负荷状态参数划分结果Table 1 Five kinds of load state parameter division results
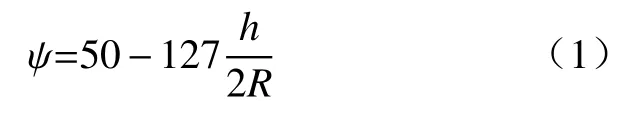
式中:ψ为球磨机的充填率;h为磨机中心到磨矿介质上表面的高度;R为球磨机内半径.

式中:a为三条坐标轴上合成的加速度;sx,sy和sz分别为三条轴上的传感器输出信号;0.049 为传感器的灵敏度系数.
2 优化SVM 模型识别磨机负荷状态
在小样本数据的分类检测领域中,常用的分类器有支持向量机(SVM)、极限学习机(ELM)、随机森林(RF)和人工神经网络(ANN)等.其中,SVM 所需样本数量少,鲁棒性较好,应用范围最广,但由于SVM 涉及二次规划问题,求解时效性不太理想.因此,优化SVM 模型成为了当前的一个改进方向,据文献报道,优化后的粒子群优化法(PSO-SVM)和遗传算法(GA-SVM)效果均显著提高[16].图2 为本文基于优化SVM 分类模型的磨机负荷状态识别流程.

图2 基于优化SVM 分类模型的磨机负荷状态识别流程Fig.2 Recognition process of mill load status based on the improved support vector machine classification model
2.1 SVM 基本原理
SVM 以统计学上的结构风险化最小原理为计算原则,着重研究在有限样本情况下的统计规律,因而对小样本数据分类有一定的优势,泛化能力较强.SVM 的基本思想是根据线性回归方程构建一个超平面作为决策面,使得各类待分数据间隔最大化,并将分类问题转化为一个带约束的线性规划方程.相关原理[17]如式(3):
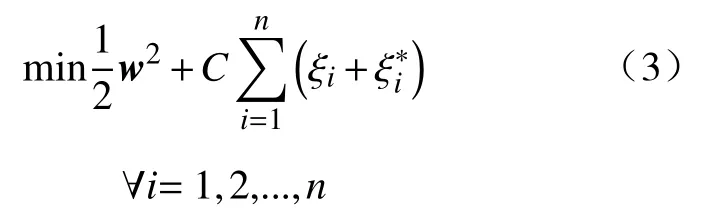
上式的约束条件为:(wφ(xi)+b)-yi≤ε+ξi,yi-(wφ(xi)+b)≤ε+ξi*.
式中:w为方向向量;n为样本数;b为超平面参数;C为惩罚因子;ξ 为松弛变量;yi为分类标签;φ(xi)是向量xi在高维空间中的映射;ε为不敏感系数.
由式(3)可知,影响决策曲面间隔的主要参数为惩罚因子C和松弛变量ξ,这两个参数的引入将凸优化问题最小化.然而在常规的SVM 实际应用中,往往引入核函数k(xi,xj)将数据映射到高维空间建立最优分离超平面对数据进行非线性划分,SVM 中常用的核函数如表2 所示,表中d为多项式核函数的最高项次数;g为核函数参数,默认值为(k为类别数).

表2 SVM 常用核函数Table 2 Commonly used kernel functions of the support vector machine
由表2 可知,C和g是决定核函数性能的关键参数,然而C和g的选取具有较强的主观随意性,多靠经验和反复试验选取,在一定程度上影响了分类模型的泛化能力及分类准确率[17].因此,有必要探索对C和g进行自动寻优的算法.
网格搜索法(GS-SVM)、遗传算法(GA-SVM)、粒子群优化法(PSO-SVM)是目前支持向量机研究中常用的三种参数自寻优模型,本文使用此三种模型对预处理后的智能磨矿介质加速度信号进行训练与分类.各模型的原理可分别简述如下.
GS-SVM 是指定参数值的一种穷举搜索方法,可将所有估计核函数的参数组合进行遍历.在对C和g的随机组合进行参数自动寻优时,通过粗略调节较大步长,在其结果范围内进行精细搜索,过程中使用交叉验证法来缩短程序运行时间,改变寻优步长,基于平均误差最小原则,选出最优参数组合.
GA-SVM 是一种模拟生物交叉变异形成的全局概率搜索寻优模型,将随机组合的C和g进行二进制编码,设置种群规模、迭代次数等参数,而后计算适应度函数,进行交叉与变异操作生成“新染色体”,确定最优解后再进行解码.算法的具体优化原理见文献[18].
PSO-SVM 模型基于种群中粒子进化过程中的合作与竞争关系来寻找最优粒子,首先,设定初始随机粒子的速度及位置,然后经过不断迭代、更新来寻找每一轮的个体极值与全局极值,在到达一定的迭代次数后可获得已搜索空间内的最优解[19].粒子位置迭代及速度更新如式(4):
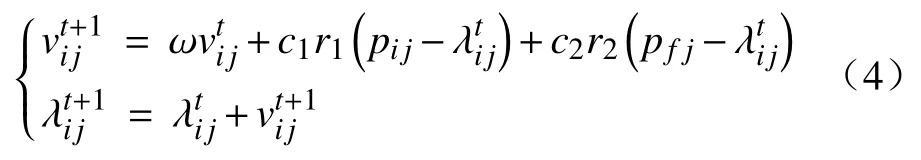
2.2 加速度信号预处理
智能磨矿介质采集到的各负荷状态下的源数据经过微处理器进行了滤波操作,有效进行了异常值的剔除,但在磨机内部恶劣的检测环境下,智能磨矿介质获取到的试验加速度信号具有明显的非线性、非平稳的特点,容易因零点漂移而产生线性趋势项,本文使用最小二乘法去除趋势项[20],抑制零点漂移.图3 为40%充填率条件下智能磨矿介质获取的加速度信号及经最小二乘法初步去趋势处理后的结果.
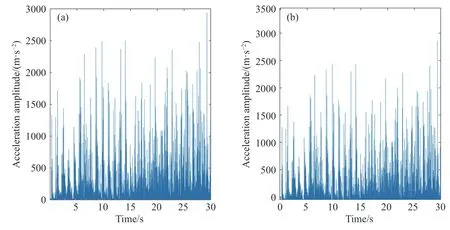
图3 正常负荷工况信号波形.(a)源信号;(b)去趋势结果Fig.3 Signal waveform under normal load conditions: (a) original signal;(b) detrended results
由图3 可知,智能磨矿介质经磨矿试验所获取到的特征加速度信号由于磨机位置偏离、筒体振动、空气噪声反射、传感器自身偏移以及结构性能弱化等问题使得加速度信号存在多种成分,大量有价值的特征信号淹没于噪声中.因此,有必要研究加速度信号的去噪方案,刻画信号细节特征,为后续的特征提取及分类识别提供基础.本文使用互补集合经验模态分解算法(CEEMD)和相关系数法联合去噪[21-22],限于篇幅,具体方法及信号重构后效果参见前期文献[14].重构后的欠负荷、正常负荷、过负荷三种典型工况下的加速度信号对比重构前的加速度信号波形图,低频噪声被有效滤除.根据表1 的负荷状态划分结果,选取欠负荷、正常负荷(最佳负荷)、过负荷三种典型工况下的5 组随机样本数据,并计算相应信号重构前后的样本熵值,其结果列于表3.
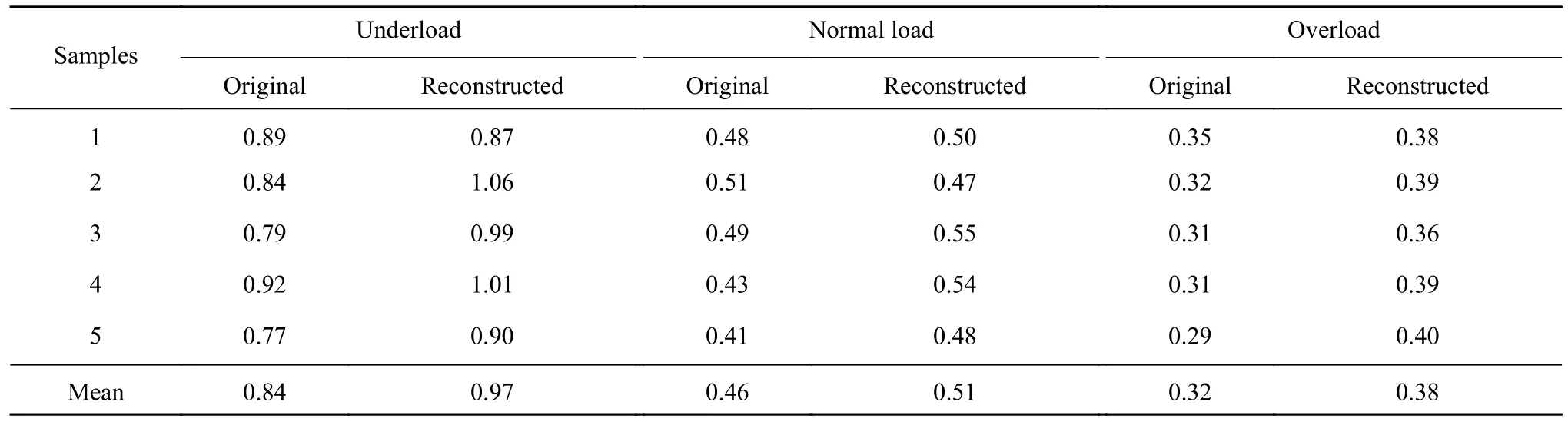
表3 三种典型工况下的样本熵值Table 3 Sample entropy values under three typical working conditions
去噪效果评价可由表3 中的样本熵结果表征,重构后的三种负荷状态下的平均样本熵值均有一定的增加,如欠负荷状态下的值由0.84 提升至0.97,表明CEEMD 联合相关系数法对加速度信号去噪的效果较好.
2.3 特征向量提取
2.3.1 时域特征参数
重构后的负荷特征加速度信号仍然具有非线性、非平稳的特点,在工程应用中常通过提取时域特征参数来分析此类信号.时域特征参数可以分为有量纲参数和量纲一参数两类,有量纲参数具有物理意义,如均值、标准差、均方根误差等数值的变化较为敏感,但在环境改变的情况下,表现又不够稳定.量纲一参数通常为有量纲参数的比值,无实际的物理意义,其对磨机负载以及转速的变化不敏感,能够更直观反映出球磨机运行时的内部状态信息,如峭度、偏度、裕度和脉冲因子等.综上所述,本文联合平均值、标准差、峭度、峰峰值和偏度五个有量纲和量纲一时域参数来描述负荷加速度信号的基本特征,相关参数的计算方式见文献[23].
2.3.2 样本熵
近似熵可以度量时间序列的复杂度,而且仅需要少量数据便可得出计算结果.然而,近似熵在计算时会因不断比对固有的自身数据而产生偏差.样本熵为解决此问题应运而生,其定义见式(5).观察可知,样本熵值与m、l有关,但样本熵具有一致性,序列的自相似性越高,熵值就越小,序列表现复杂,则熵值就大.因此,熵值增大与减小的趋势并不受m、l的影响,样本熵相较近似熵并不包含自身数据段的比较,提高了计算精度、节约了计算时间[24].

式中:Bm(l)为现有序列中两数据元素差值最大的距离个数与总序列中距离总数(N-m)的比值;N为数据长度;l为相似容限;m为维数.
由表3 可知,三种典型工况下重构的样本熵值相较源信号均有一定程度的增加,说明CEEMD 联合相关系数法重构的信号有效消除了一些低频噪声,使得源信号经重构后序列自身差异性增加,特征更加明显,更易与其他负荷状态区分.另外,不同负荷状态下的样本熵值差异较为明显,而相同负荷状态下的样本熵值在平均值上下波动,表现较为稳定.结合样本熵值与三种负荷状态下的加速度信号图进一步分析,欠负荷工况下的样本熵值最大,其原因可能是欠负荷状态下磨机筒体内的矿料和钢球较少,钢球在下落过程中能与筒壁、钢球、矿料相互碰撞,而且提升高度会随着不断变化的钢球排列方式而改变,因此,欠负荷状态下的加速度信号复杂度最高,相应的熵值也就最大.在过负荷状态下,磨机筒体内的钢球和矿料都比较多,钢球的排列方式相对固定,智能磨矿介质主要在肾形区蠕动,产生的磨矿作用较弱,因此采集到的加速度数据随机性较小,复杂度较低,相应的熵值也就最小.在正常负荷状态与过负荷状态下的样本熵值差别不大,可能会出现部分交叉重叠的问题,因此将样本熵结合以上时域特征参数作为特征向量来区分磨机负荷状态,部分待训练特征向量列于表4.
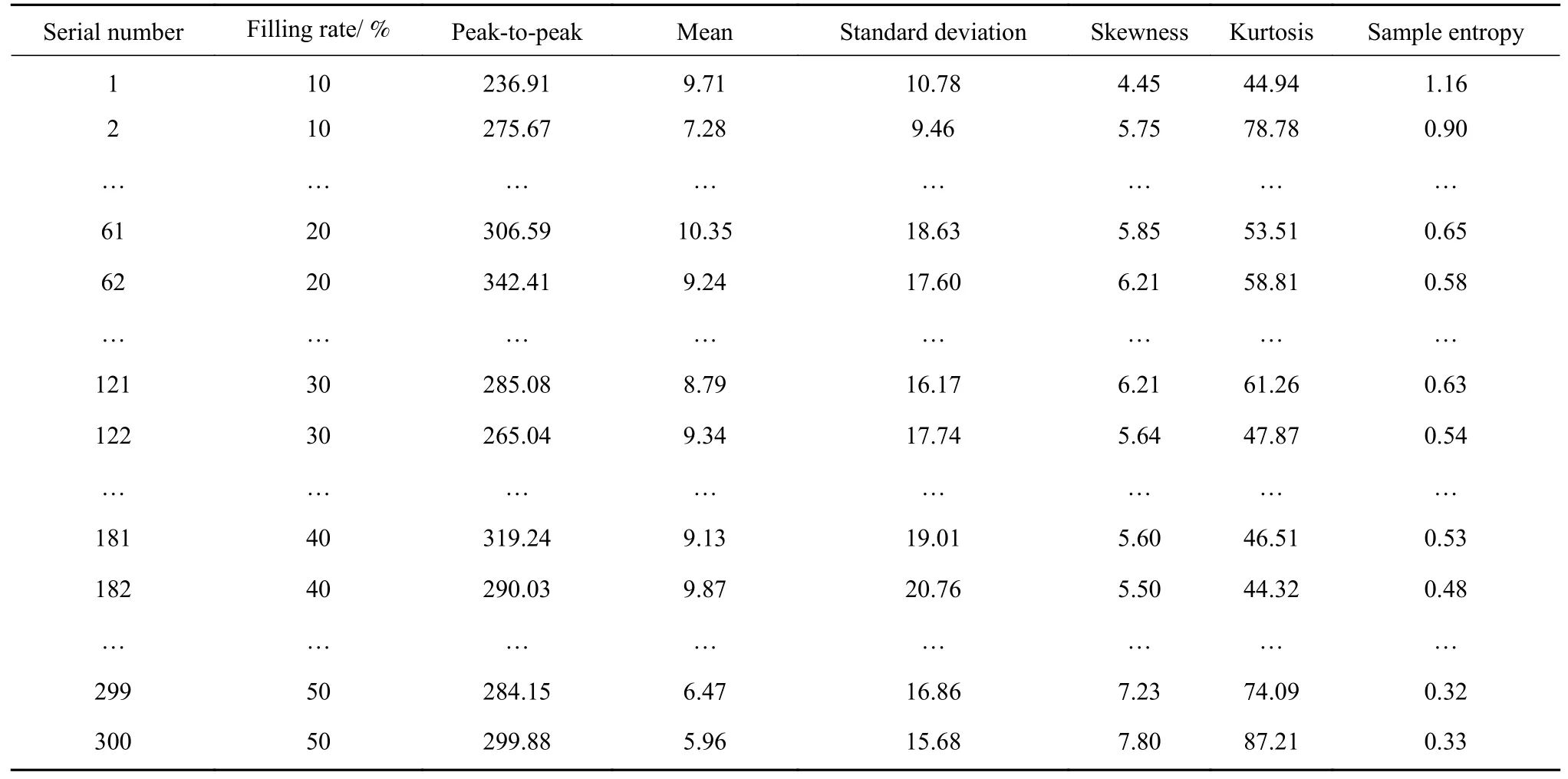
表4 不同负荷状态下的部分待训练特征向量Table 4 Feature vectors to be trained under different load conditions
2.4 优化后的SVM 模型识别结果
笔者用于负荷样本处理的笔记本电脑配置为处理器i5-6200U,RAM 为4 G.使用Matlab R2020a软件将表4 中的300 组特征向量输入三种分类器(GS-SVM、GA-SVM、PSO-SVM)分别进行训练与测试.首先使用mapminmax 函数对待分类数据集进行归一化处理,然后依据文献[25]设定各分类器参数,将数据集划分80%用于训练,剩余20%用于验证,将表1 中的5 种磨机负荷状态分别记录为标签1~5,得出三种模型下的负荷状态分类结果及最佳C和g值,列于表5 中,绘制如图4 的分类结果图.
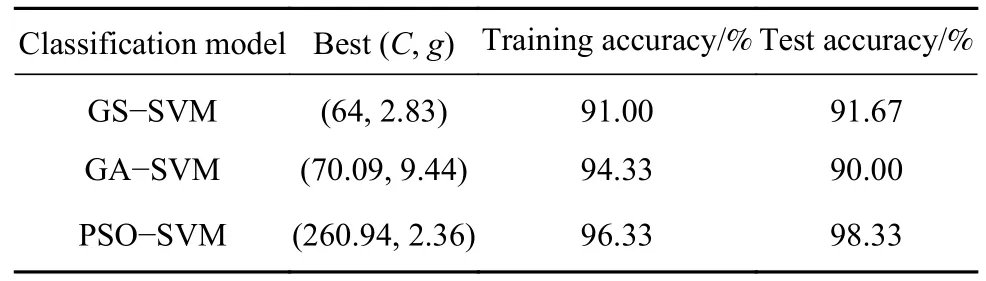
表5 三种优化SVM 模型对磨机负荷状态的识别结果Table 5 Recognition results of the three improved support vector machine models on the load state of the mill
由图4 中的GS-SVM、GA-SVM、PSO-SVM三种模型的识别结果可知,PSO-SVM 的分类识别准确率高于GS-SVM 和GA-SVM,达到98.33%,三种分类识别模型的误判主要出现于充填率30%和40%的工况中,如前所述,两者在磨矿效率系数、时域特征参数、样本熵数值上差异较小,导致其分类识别困难.
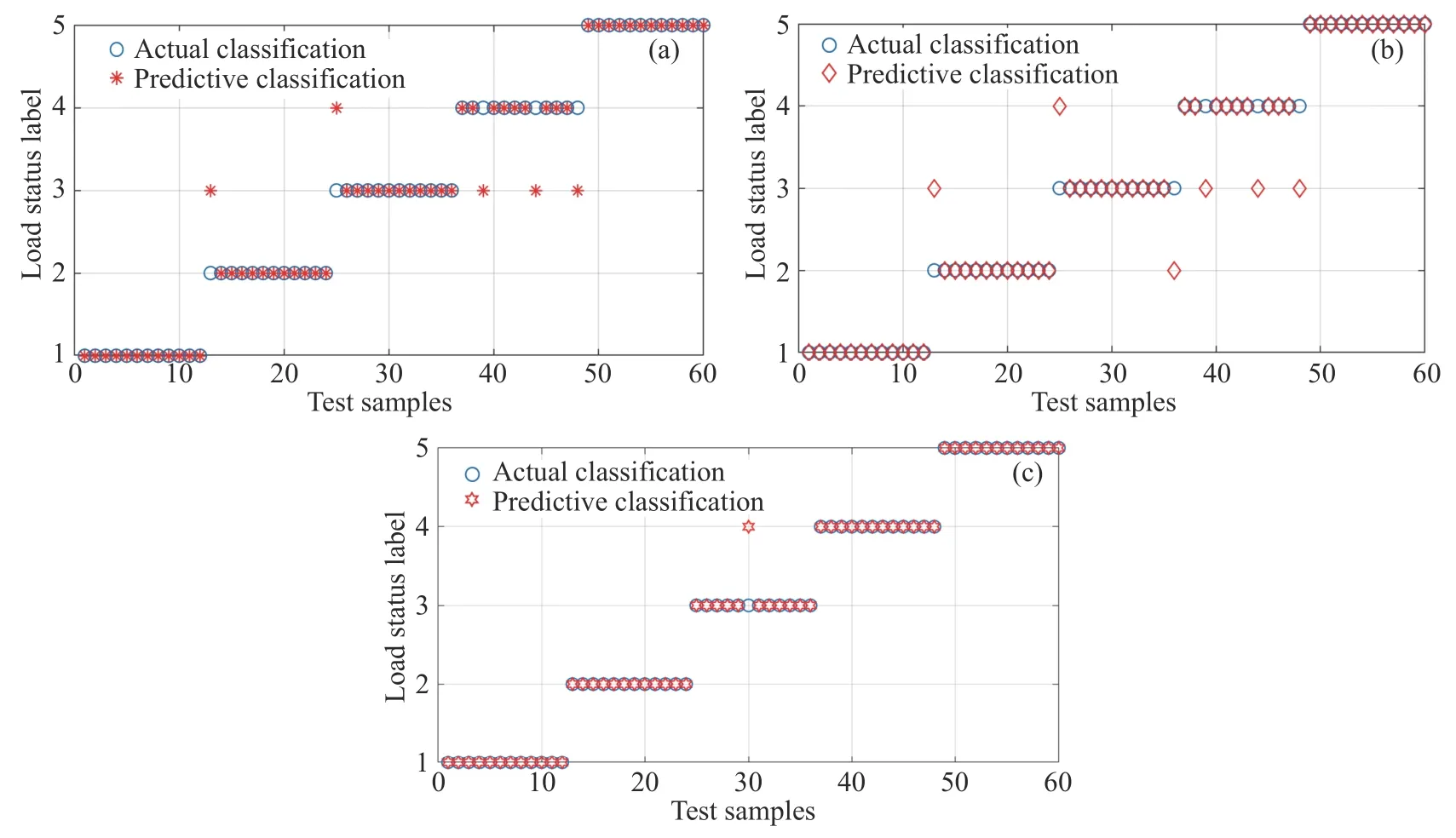
图4 三种优化的SVM 模型的负荷状态分类识别结果.(a)GS-SVM 分类结果;(b)GA-SVM 分类结果;(c)PSO-SVM 分类结果Fig.4 Results of load status classification and recognition of the three improved support vector machine methods: (a) results of GS-SVM classification model;(b) results of GA-SVM classification model;(c) results of PSO-SVM classification model
为验证PSO-SVM 分类模型的优越性,引入小样本数据分类中常用的KELM 和RF 两种分类模型对磨机负荷样本进行分类识别对比验证.五种分类模型的识别准确率结果和程序运行时间如图5.
由图5 可知,相比GS-SVM、GA-SVM、KELM和RF,PSO-SVM 的识别准确率依然最高,在对SVM 分类器的核参数进行自动寻优时运行时间却最长,耗费40.59 s.RF 和KELM 虽识别准确率不够理想,但程序运行时间最短为4.55 s.因此,还需要不断的优化PSO 自身算法,在不影响性能的前提下,尽可能缩短PSO-SVM 模型的运行时间.

图5 不同分类模型下的负荷状态识别准确率及运行时间Fig.5 Results of load status recognition under different classification models
3 CNN 模型识别球磨机负荷状态
卷积神经网络(CNN)常用于深度学习中,近几年深度学习网络因强大的自学习能力被广泛应用于工件探伤和生命健康等领域,例如,CNN 能根据不同工况下的振动信号差异来判断轴承的健康情况,可为球磨机负荷状态的分类识别提供借鉴意义[26-27].CNN 为一种前馈神经网络,无需对智能磨矿介质采集到的加速度信号进行繁琐的预处理,即可自适应提取目标特征.其结构主要由卷积层、池化层(下采样)、激活函数(Softmax)、Dropout(避免过拟合)及全连接层组成.卷积神经网络的一般结构如图6 所示.卷积层主要依靠卷积核(主要元素:权重系数、偏差)在待识别区域做卷积运算,通过激励函数(ReLu)进行非线性变换和池化操作来达到降低输入数据维度的目的,连续提取深层特征,经过每轮迭代训练后,Softmax 激活函数跟标签做对比并优化后再次进入卷积和池化操作,当达到设定的迭代次数后,结束训练并保存当前网络的权重.
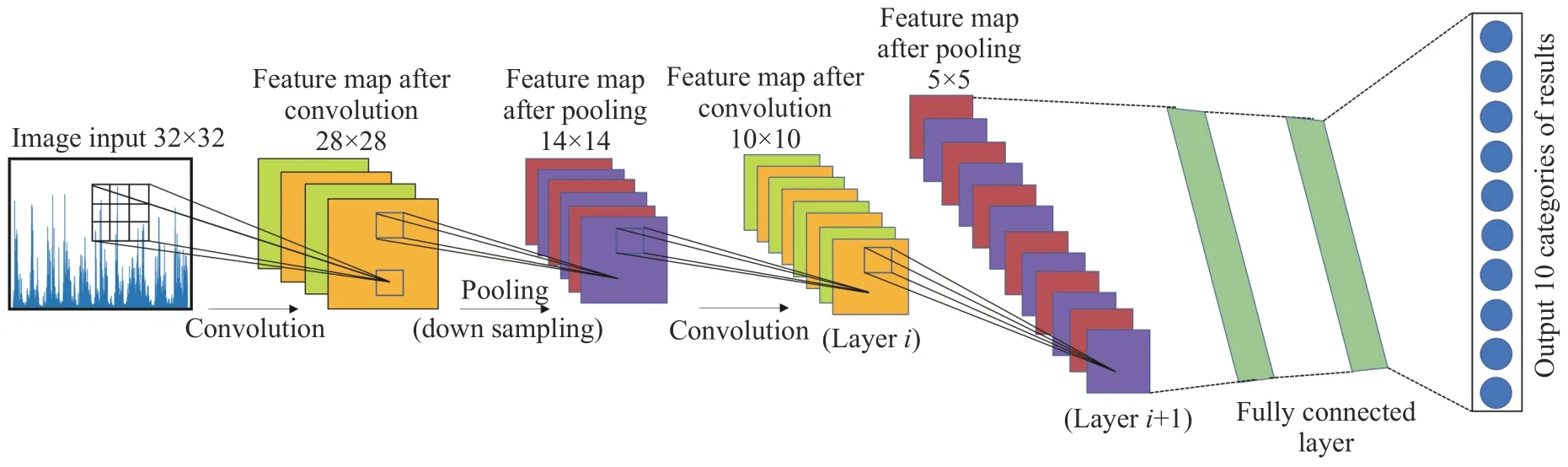
图6 卷积神经网络基础结构图Fig.6 Basic structure diagram of the convolutional neural network
3.1 CNN 分类模型框架
在CNN 训练网络模型中,常用的网络结构有Lenet5,Alexnet,ResNet,Inception,VGG 等.LeNet5网络结构相对简单,在拟合数据上有欠缺,而ResNet具有残差结构,较VGG19 网络结构复杂一些,导致其在训练过程中容易过拟合[28].此外,VGG 网络在Alexnet 的基础上使用多个3×3 小卷积核级联代替Lenet5 中的大卷积核来增加网络深度,有效提升了CNN 的分类效果,在当前的研究中应用广泛.本文将搭建基于VGG19 网络结构的CNN训练模型,获取15 组磨矿试验的各一小时磨矿数据,无须进行去趋势及降噪等预处理操作,每10 s输出相应时序信号并全部转换为224×224×3 尺寸的RGB 图片.将获取到的900 幅图片按照80%用于训练,20%用于验证的划分方式,输入到基于VGG19 结构的CNN 训练网络模型中进行为期30 轮,每轮迭代72 次的训练.本文所使用VGG19结构的具体网络参数见图7,从数据集中随机选取40 幅图片进行展示,见图8.

图7 本文VGG19 结构的网络参数Fig.7 Network parameters of the VGG19 structure in this study
图8 部分待分类随机数据集Fig.8 Part of the random data set to be classified
3.2 CNN 分类模型识别结果
图9 展示了CNN 网络模型对磨机负荷样本进行训练与测试过程中的分类识别准确度与损失函数结果,可知在前10 轮迭代训练中,其训练与测试集的分类准确度呈震荡的上升趋势,后趋于平稳.经30 轮共2160 次迭代训练后,因为VGG19 独特的结构和优秀的性能,使得验证集识别准确率高达98.89%.损失函数为反映预测分类模型与实际数据间的差异程度指标,CNN 进行前向传播阶段,依次调用每一层的Forward 函数,得到逐层的输出,最后一层与目标函数比较得到损失函数.在迭代训练后期,损失函数接近于零,表明本文所构建的VGG19 网络模型在真实标签上的分类概率高,训练收敛的效果较好.
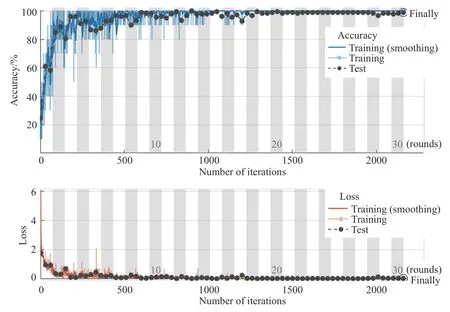
图9 CNN 训练磨机负荷样本结果Fig.9 Results of the convolutional neural network training mill load sample
4 结论
本文采用基于CNN 和优化SVM 的GA-SVM、GS-SVM、PSO-SVM 等分类方法对不同磨矿负荷试验中智能磨矿介质采集到的加速度信号数据进行分类识别.研究主要得出以下结论:
(1) 内嵌三轴加速度传感器模块的智能磨矿介质可有效模仿普通磨矿钢球,采集到的各负荷状态下的加速度信号数据具有一定的区分度.
(2) 采用CEEMD 和相关系数法对加速度源信号去噪具有较好的效果,更好地刻画了信号细节特征.
(3) GA-SVM、GS-SVM、PSO-SVM 对一维数据进行识别,整体识别率较高,特别是PSO-SVM的分类识别准确率可达98.33%.然而,特征参数在输入SVM 分类模型之前需要冗长的提取过程,耗时耗力,此方法仅在数据量较少时有优势.
(4) 使用CNN 对二维图像识别时,无需对源信号进行去趋势和去噪等预处理,即可自适应提取反映区分磨机负荷状态的特征,磨机负荷分类准确率高达98.89%.虽前期需要大量时间训练网络模型,但后期可做到实时识别,具有较高的应用推广性.
猜你喜欢
金属矿山(2022年9期)2022-10-24
金属矿山(2022年9期)2022-10-24
航天制造技术(2022年3期)2022-07-15
广西大学学报(自然科学版)(2022年2期)2022-07-06
兵工学报(2022年1期)2022-03-14
建材发展导向(2021年6期)2021-06-09
建材发展导向(2020年16期)2020-09-25
劳动保护(2018年4期)2018-04-27
科学与财富(2017年27期)2017-10-17
科技资讯(2017年20期)2017-08-22
