
一种基于模型压缩的行人重识别方法
2022-10-14 13:01关晓惠孙欣欣
浙江水利水电学院学报 2022年4期
关晓惠,孙欣欣
(浙江水利水电学院 信息工程学院,浙江 杭州310018)
行人重识别是机器学习领域的一个重要分支,主要利用计算机视觉技术,在跨监控设备的场景下识别和检索特定行人是否存在于视频画面,可应用于视频监控、智能安防等领域。随着深度学习在计算机视觉领域获得突破性进展,研究人员提出了各种基于深度学习的行人重识别方法,主要有基于表征学习的方法、基于度量学习的方法、基于局部特征的方法、基于视频序列的方法和基于GAN造图的方法等[1]。然而,在开放空间中,由于光线、摄像角度、遮挡和分辨率等因素,这些模型缺乏鲁棒性和适应性,无法保证稳定的识别精度。另一方面,现有算法的模型复杂度高,参数众多,计算量大,难以在资源受限的终端设备上部署[2]。为此,研究人员就深度神经网络压缩与加速开展了一系列的研究,主要方法有:参数剪枝、参数共享、低秩分解、核稀疏化及知识蒸馏等[3-4]。笔者探索一种优化组合策略进行模型压缩,在保证精度的情况下,降低模型的复杂度和计算量。
1 预备知识
笔者通过通道剪枝[5]、分组卷积[6]、非局部自注意力机制[7-8]等优化组合,寻求在速度与精度两方面都最佳的特征提取策略,具体流程如图1所示。
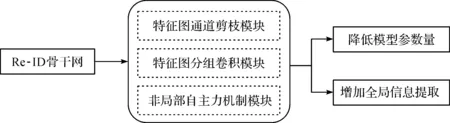
图1 方法总结流程图
1.1 通道剪枝
为了降低模型的复杂度,通常采用通道剪枝的方法对神经网络的宽度进行调节,添加BN层权重系数,剪掉多余的特征图通道,具体过程为包含特征通道选择和特征通道重组两个方面。通道剪枝示意图如图2所示。
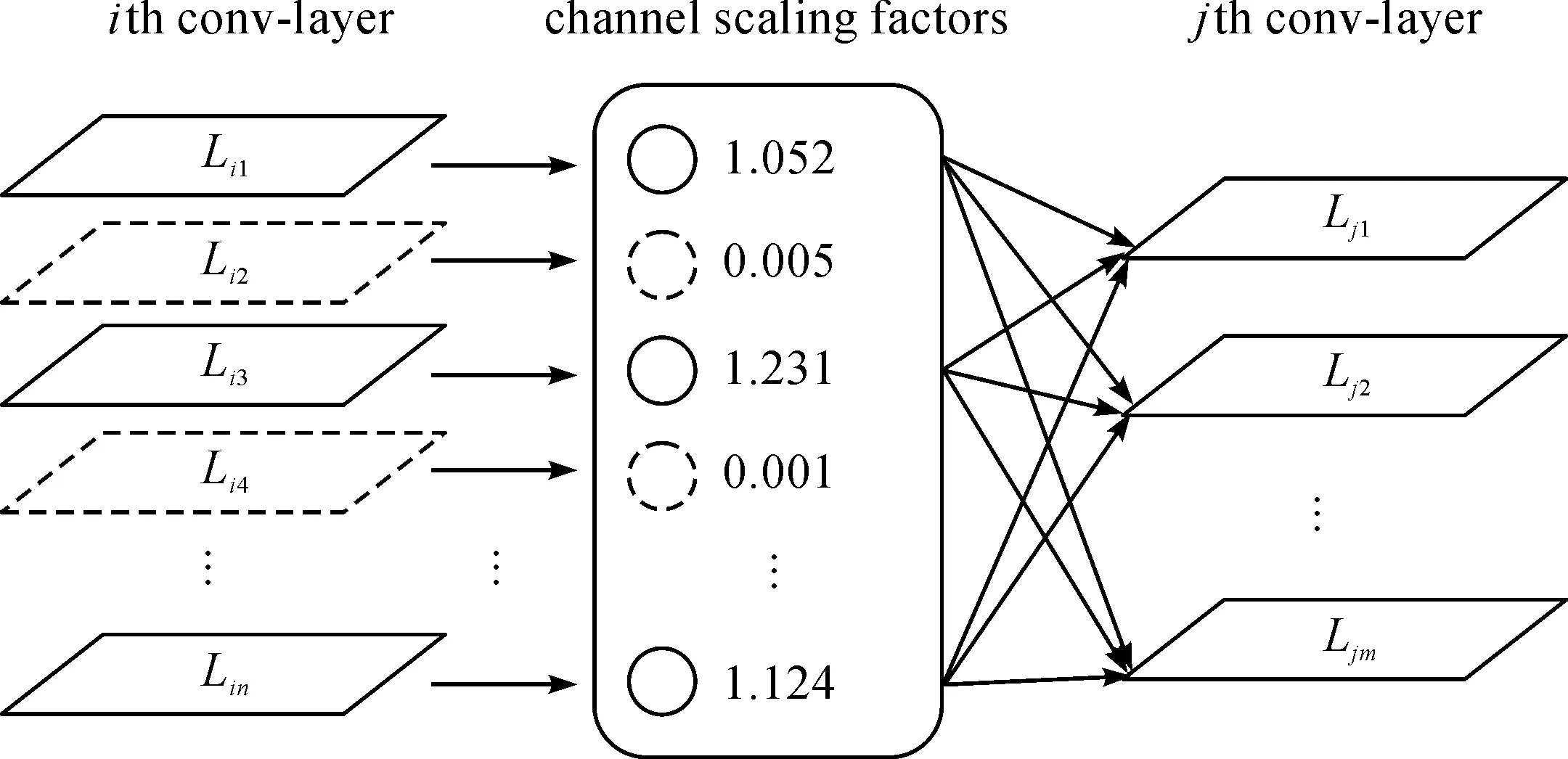
图2 模型通道剪枝示意图
通道剪枝数学描述形式为
(1)

(2)
s.t. |βi|0-c′≤0
通过调整惩罚系数λ,使βi中出现更多的0项,通过βi的结果完成特征通道选择。然后求解参数fi,使得剪枝后的特征图输出信息与原特征图输出信息尽可能接近,即最小化特征重组误差。
1.2 分组卷积
分组卷积是一种减少参数,提升网络特征抽取能力的重要手段。首先将输入特征图按通道数平均分组,然后分别对每一组进行常规卷积,最后按卷积通道维度合并所有特征图。
记输入特征图为c×h×w(h×w为特征图大小,c为输入通道数),卷积核大小为s×c×k×k(s为卷积输出通道,k×k为卷积核大小),卷积步长为1,填充为0,则输出特征图大小为s×h×w。在忽略神经元偏置的情况下,常规卷积的参数量为s×c×k×k,计算量为k×k×c×h×w×s。若将输入特征图按通道均分为G组(每组含c/G有个特征图),则每组对应的卷积核大小为(s/G)×(c/G)×k×k,然后将各组的输出特征图按通道数拼接,输出的特征图尺寸s为s×h×w,分组卷积的参数量为(s×c×k×k)/G,降低为原来的1/G,卷积计算量也为原来的1/G。
1.3 非局部自注意力机制
非局部自注意力机制通过扩大感受野的方式捕获更丰富的信息,数学表达式为
(3)
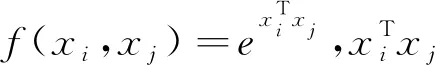
2 实验方法
2.1 模型框架
将通道剪枝、分组卷积和非局部自注意力机制分别记为V1,V2,V3,它们的集合Ω={V1,V2,V3},Ti为集合Ω的第i个子集;非线性函数G(xi)特征提取网络,xi为输入的特定人物图像,i为人物id,则pi=G(xi)为模型输出i号人物的概率,那么Re-ID的定义可表示为max(pi)。若固定xi的输入尺寸,则可表示Re-ID模型的复杂度(Params、Flops)为o{G(xi)},建立数学模型为
(4)
整个方法的框架如图3所示。
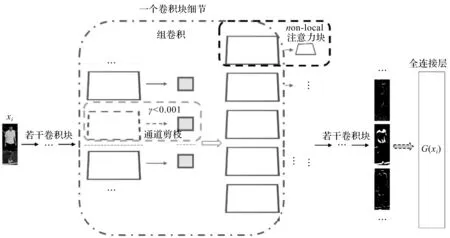
图3 方法框架示意图
2.2 损失函数
笔者所述模型的损失函数包括两部分,一部分采用分类问题的交叉熵损失函数L1;另一部分采用三元组损失函数L2。为了控制L1与L2对总体损失函数的影响,引入平衡因子,损失函数表示为
(5)

3 实验过程与结果
实验采用Market-1501数据集[9],共有1 501个行人类别(身份),32 668张行人图片,从中选取751个行人的12 936 张图像作为训练集,750个行人的19 732张图像作为测试集。为了证明优化压缩方法的有效性和通用性,以ResNet50和mobileNetV2作为基础网络结构,使用随机梯度下降优化算法学习网络权重,训练图像尺寸为256×128。训练时的批量大小设置为64,基础学习率为10-3,训练周期为200个epoch。训练时数据增强包括随机旋转、随机平移。训练开始前分别加载ResNet50和mobileNetV2的ImageNet预训练权重参数,当修改ResNet50和mobileNetV2网络结构时,将修改后的网络重新在ImageNet数据集上训练20~30个epoch。实验中用到的ResNet50和mobileNetV2模型的结构如表1和表2所示,其中:Conv代表卷积操作;stride为卷积的步长;FC为全连接层。

表1 ResNet50网络结构
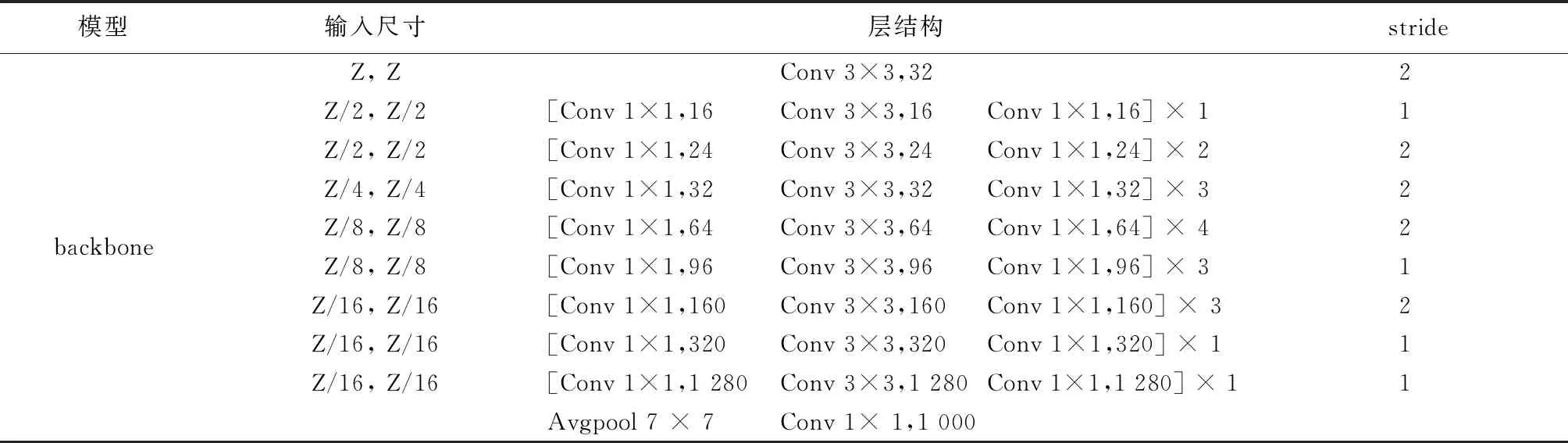
表2 mobileNetV2网络结构
实验使用的硬件平台:GPU为2080Ti*4,CPU为48核Inter(R) Xeon(R) 2.20GHz,软件版本为Ubuntu 16.04,Pytorch 1.5,Python 3.7。实验中用到的评价标准有累计匹配特征(CMC)和平均准确率均值(mAP)。评估模型大小和计算消耗的指标有参数量(Params)和网络一次前向传播所执行的浮点运算次数(Flops)。
3.1 通道剪枝实验
使用Market-1501数据集,在ResNet50和mobileNetV2[10]模型的基础上,按照剪枝率q=0.5训练模型,并和没有剪枝的模型参数进行对比,实验结果如表3所示。
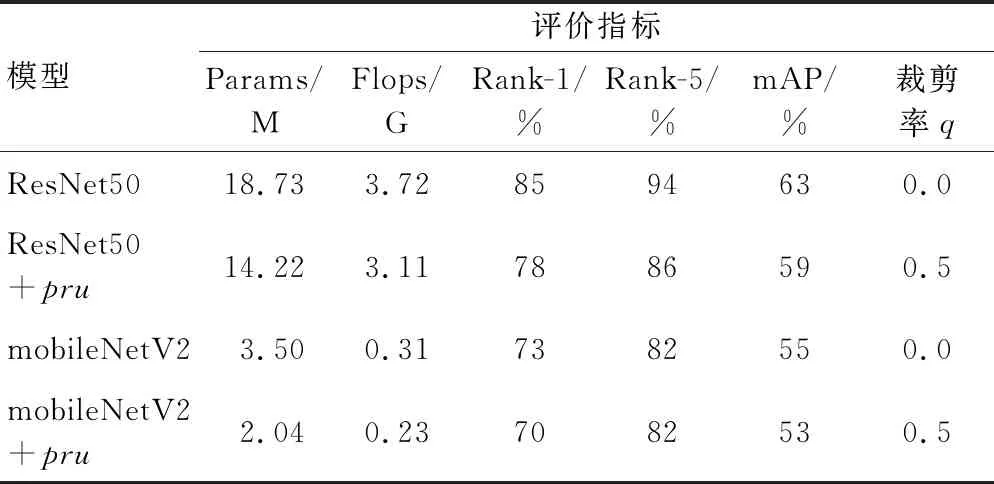
表3 通道剪枝压缩ResNet50和mobileNetV2的卷积通道
实验表明,裁剪率为0.5时,ResNet50模型的参数量下降24%,总浮点运算次数下降17%,在Market-1501数据集上微调10个样本周期后Rank-1达到78%,较之前下降8%,mAP为59%,较之前下降6%。mobileNetV2模型的网络参数量仅为2.04 M,下降42%,总浮点运算次数为0.23 G,下降26%,在Market-1501数据集上微调20个样本周期后Rank-1达到70%,下降了4%,mAP为53%,下降4%。
为了验证超参数q对模型性能的影响,本实验采用不同的模型剪枝率简化模型,从实验结果可知,模型性能会随着剪枝率q的增大而下降,当达到某一阈值后模型性能会急速下降(图4)。因此,调节压缩率q的大小虽然可实现对模型不同程度的压缩,但同时会带来模型精度的损失,尤其当q大于一定阈值后,模型精度损失极其严重。可见,仅通过非结构化剪枝无法得到最优的压缩模型。
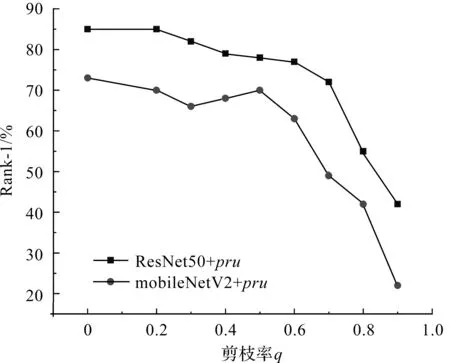
图4 剪枝率q对ResNet50和mobileNetV2在Market-1501数据集上的性能影响
3.2 分组卷积实验
上述通道剪枝压缩时,存在模型间断点问题。为了进一步压缩模型,同时避免模型出现间断点,使用分组卷积形式,将卷积在通道方向上分组,每组使用同一个卷积核。记输入层特征图大小为[B,G,H,W],将C个通道均分为g组,训练周期为200个epoch。研究表明分组卷积超参数G取32时ResNet50在ImageNet上的分类效果最佳,因此本实验默认此设置。分组卷积不但减少了运算量起到加速作用,还可以使卷积后的特征图包含更多的语义信息。分组卷积实验结果如表4所示。

表4 Market-1501数据集上使用组卷积操作改造ResNet50和mobileNetV2模型
由实验结果可知,使用分组卷积替换部分正常卷积可在性能指标Rank-1和mAP极小损失的情况下,极大地降低模型的参数量。
3.3 非局部自注意力实验
由于非局部自注意力机制可以弥补卷积操作缺乏全局信息处理能力的缺点,在ResNet50网络模型的四个层级的连接处分别插入非局部自注意力机制块,在mobileNetV2模型的第一个反残差块后加入非局部自注意力块。实验结果如表5所示。

表5 非局部自注意力non-local块插入对基准网络的影响,实验数据集为Market-1501
由实验结果可知,非局部自注意力模块可有效提升网络的性能。ResNet50在插入三个非局部注意力块后mAP提高了3%,mobileNetV2插入一个非局部注意力块后mAP提高了2%。但非局部自注意力模块也会给网络带来计算量和参数量的提升,其中ResNet50网络前向传播的Flops增加了20%,Params增加了15.3%,mobileNetV2则分别增加了24%和17%。可见性能的提升多伴随着计算消耗,因此如何找到模型性能与计算消耗的平衡是亟待解决的问题。
3.4 交叉实验
为了验证各优化方法组合的有效性,以ResNet50和mobileNetV2网络为基础为各种优化算法进行交叉组合,实验结果如表6所示。

表6 Pose-DTW模型优化前后性能测试
实验结果表明,通道剪枝技术、分组卷积和非局部自注意力机制的结合,可使得裁剪后的模型经过微调可以获得更优越的精度,同时明显降低模型的参数量、计算量。同时不同的优化方法是相对独立的,在应用中可以根据实际需求和应用平台选择速度和精度最平衡的优化组合策略。
4 结 语
针对现有行人重识别模型参数量多、计算消耗大的问题,笔者提出若干种模型压缩优化的策略,主要通过通道剪枝、自注意力、分组卷积等方法的组合优化,快速开发出符合实际使用场景的网络模型。笔者从理论和实验上说明不同的优化方法可以相互组合,使模型在计算消耗和精度损伤方面达到最佳平衡。此优化策略具有一定的通用性,不仅可用于ResNet50这种大体量模型,也可用于轻量级的网络,进一步压缩其存储消耗和计算消耗,同时提高模型精度。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
农业工程学报(2022年12期)2022-09-09
计算机应用(2022年5期)2022-06-21
山花(2022年5期)2022-05-12
计算机应用与软件(2021年11期)2021-11-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
散文诗(2020年1期)2020-07-20
天津诗人(2017年2期)2017-03-16
