
基于决策树的中小微企业信贷风险数据分析
2022-10-14 03:47:08卢林军董浩垠
大众科技 2022年9期
卢林军 卢 畅 董浩垠
基于决策树的中小微企业信贷风险数据分析
卢林军1卢 畅1董浩垠2
(1.桂林电子科技大学计算机与信息安全学院,广西 桂林 541004;2.桂林电子科技大学建筑与交通工程学院,广西 桂林 541004)
银行通常需评价中小微企业情况才提供贷款,并且可以为声誉较高和信用风险较低的公司给予特殊利率优惠。文章通过信誉量化、决策树等数学模型,运用模糊层次分析法、spearman相关系数分析法以及剪枝处理等方法,设计银行对中小微企业信贷的策略。对有信贷记录的中小微企业,运用模糊层次分析法,建立信誉量化模型,取得了各个企业信贷额度占银行总信贷额度的比例,银行可根据实际额度按比例给中小微企业贷款。对没有信贷记录的中小微企业,使用决策树模型,预测企业的信誉评级和违规情况,使得无信贷记录的企业能够得到一个相对精准的信用评价。此外,还对决策树模型进行剪枝处理,提高模型的准确率和泛化性能。针对公开数据集进行测试,得到相关决策,模型具有较强的适应性,也可推广至其他领域。
中小微企业;信誉量化;决策树;模糊层次分析;相关系数分析
引言
生活中,由于中小微型企业的规模小和缺乏抵押资产,基于信贷政策、发票交易信息和产业链上下游影响力,银行为保持稳定的供求关系,会向实力强的企业提供贷款,并且可以为声誉较高和信用风险较低的公司给予特殊利率优惠。在相关的研究[1-15]中,银行会首先根据企业实力和信誉评估中小企业的信用风险,然后根据信用风险等因素,判断是否放贷,采用信用限额、利率和期限等借贷方式,对中小微型企业给予借贷。
(1)利用spearman相关性分析法[16]对四项指标与企业信誉进行相关性检验,得到指标相关性良好,验证了系数选择的合理性。
(2)根据没有信誉评级的企业数据,在经过指标提取后,建决策树[17]模型,该模型在样本小的条件下,能很好的完成信誉评级的分类效果。同时,考虑到决策树模型自身会产生过拟合的缺点,对决策树模型进行了剪枝处理,提高模型泛化性能。
1 中小微企业信贷风险管理问题假设
现实中有很多因素影响着银行的信贷策略,为了使得本文的研究能够顺利进行,需要对问题进行一些假设。在满足银行对中小企业信贷管理的条件并考虑了实际因素之后,提出了如下基本的合理假设。
(1)假设中小微企业进行与销项全部有发票记录,不存在发票遗漏的现象。
(2)假设本文选择的公开数据中提到的企业,全都符合中小微企业的标准,不存在皮套公司。
(3)假设中小微企业处于经营正常的状态,不存在企业被列入到异常经营的范围。
(4)假设本文没有考虑到的影响因素,对本文提出的模型影响忽略不计。
(5)假设中小微企业的借贷,都没有政府以及国家的优惠政策减免。
(6)假设银行的资金流动正常,拥有充足的现金可以放贷。
(7)假设银行具有承受烂账、坏账的能力,不存在容易倒闭的情况。
(8)假设本文使用的公开数据集中的企业,都在中小微企业中具有代表性。
(9)假设本文使用的公开数据中的数据均为真实且可靠的。
2 中小微企业信贷风险管理分析
2.1 与企业信誉相关因素选取与分析
为了探究讨论企业信誉,建立评价模型解决问题,本文从数据集中123家有信贷记录的企业中,选取5项指标与信誉评级进行相关性分析。
(1)信誉评级。
企业信誉评级反映了企业信用度的高低等级类别,它是根据企业从资产、负债和盈利等方面对企业信誉、地位等方面,对企业信用度进行划分。本文把企业信誉评级分为A等评级,B等评级,C等评级,D等评级,一共四个等级。其中A等评级企业信誉最高,D等评级企业信誉最低。
(2)上一年是否违约。
银行成为企业获取融资的重要手段,银行是企业信贷的主要资金来源者和风险承担者,企业信贷违约不断积聚的风险会波及到银行信贷资产,也会打破银行的稳定经营。本文使用的123家有信贷记录的企业信贷数据中,所有的企业都有信贷是否违约记录。在此之前的信贷中,有违约记录的企业,信誉度较低,信贷风险高。
(3)企业年利润比。
企业年利润比反映了企业盈亏情况,企业盈亏情况又反映出了企业是否具有偿还银行贷款的能力。根据公开数据集,本文对数据集中企业用公式(1)计算盈利情况。

b为该企业一年中销项发票的价税合计总和,即企业收入;b为企业一年中进项发票中的非负价税合计总和,即企业支出;为企业年利润比;收入除以支出得到的结果,即为企业年利润比。
(4)销项发票中负价发票个数。
销项发票为企业销售产品时为购货方开具的发票,负价发票为交易活动中,企业已入账记税后,购买方因故发生退货并退款。在交易过程中购买方退货并退款,一般情况下认为与产品的质量有关。负价发票个数过多,说明企业产品质量出现重大问题。产品质量有问题会直接降低了潜在投资者购买企业产品的意愿,增加了企业获利的成本和难度。只有过硬的产品质量才能让企业获得赢得市场,获得更好的效益,实现企业的可持续发展,拥有良好的信誉条件。
(5)负价发票对应的金额数目。
一个企业如果销售发票中,负价发票过多会导致企业收入降低,还贷能力也逐渐下降,使得企业未能及时还款,企业在银行就有了违约记录,企业将承受较高的罚息,增加企业财务成本,形成恶性循环。
2.2 相关性分析校验
相关性分析是指对两个或多个具备相关性的变量元素进行分析,从而衡量两个变量因素的相关密切程度[18]。为了校验上述4项指标与企业信誉的相关性,本文选取信誉评级作为标准,分别对上一年是否违约、企业年利润比、销项发票中负价发票个数以及负价发票对应的金额进行相关性分析[7]。对于检验各指标的相关性,本文选择spearman方法。当spearman相关系数接近0时,说明关系不相关;当spearman相关系数大于0.3时,表示有相关关系;两个变量的相关性越强,spearman相关系数绝对值越大;反之,两个变量的相关性越弱,spearman相关系数绝对值越小[19]。分别计算企业一年中发票中负价发票的个数n、企业一年中负价发票对应金额数目m、企业年利润比P、上一年是否违约v与信誉评级g的spearman相关系数。相关系数结果如表1所示。
表1 相关系数符号说明
指标含义相关系数 ni企业一年中发票中负价发票的个数Ei的企业对应的编号0.356 mi企业一年中发票中负价发票对应金额数目0.361 Pi企业年利润比0.464 vi上一年是否违约0.695
从表1可以得出上述四个指标与信誉评级的相关系数。可以看到每个系数与信誉评级相关系数均大于0.3,验证了系数选择的合理性。
2.3 信誉量化模型的建立
已知与信誉相关因素分别有:信誉评级、上一年是否违约、企业年利润比、销项发票中负价发票个数和负数发票对应的金额。运用模糊层次分析法模型[20],加入约束条件,输入数据,进行求解。
求解步骤如下:
Step1:本文先对五项指标:信誉评级、上一年是否违约、企业年利润比、销项发票中负价发票个数和负数发票对应的金额数目,进行单独分析并排名,将排名作为企业在该项的得分。
Step2:将五项得分相加作为该企业的最终信誉,并对最终信誉进行排名。
Step3:对排名进行归一化处理作为该企业的信贷额度占银行信贷额度的系数。基于以上思路,本文建立数学模型公式(2),公式(3),完成信贷数据的信誉量化过程。
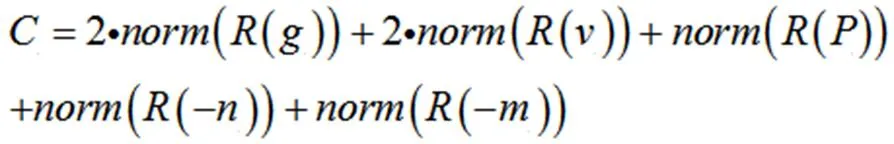
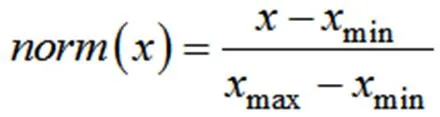
表示企业代号为E的企业对应的编号;C为该企业的信誉量化数值;表示企业信誉排序后的排名;g为该企业的信誉评级,A取4,B取3,C取2,D取1;v为上一年是否违约,未违规取2,违规取1;P为企业年利润比详细定义见公式(1);n为该企业一年中发票中负价发票的个数;m为该企业一年中发票中负价发票对应金额。
本文基于企业信誉评级、上一年是否违约、企业年利润比、销项发票中负价发票个数和负数发票对应的金额,共5点指标,运用模糊层次分析法,最终对123家有信贷记录的企业排序进行分析,本文在进行排名时,相同分数的企业取排名相同的名次,而不是去取对排名进行顺延的排名的名次。这样可以使得相同分数的企业差异鉴定但导致了不同项的排名的最值可能相差较大,因此,本文对每个排名进行了归一化处理,处理得到的结果排名,即为函数()详见公式(3)。最后对企业的信誉量化数值C进行排序,得到123个有信贷记录的企业量化后信誉的排名(C)。对信誉排名除以排名总和,得到每个企业对应的系数,作为该企业的信贷额度占银行信贷额度的系数,其中第i个企业的银行信贷额度系数计算方式如公式(4)所示。

k为第个企业最终得到的银行信贷额度系数;()为对进行求和。第个企业最终被分配的信贷额度为M,其计算方式如公式(5)所示。
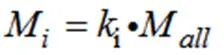
3 有信贷记录的中小微企业信贷策略
为了排除实验干扰数据的影响,本文在处理数据时,进项发票数据与销项发票数据中所含有的作废发票,都将不做处理。在进价发票信息中,部分企业发票所含有的信息过少,进行计算时会产生干扰数据,从而影响到计算结果,故本文将其认为干扰数据。在处理进价发票信息时,由于进价发票信息中的负价发票与购买方相关性低,故不作为计算数据,仅将正价发票数据作为该企业支出金额。
将信誉评级、上一年是否违约、企业年利润、销项发票中负价发票个数和负数发票对应的金额数目,分别按照上述所建立的数学模型,进行处理后,计算出第个企业的信誉量化数值C和企业信贷额度系数k,以及每个企业对应的信贷额度M。每个企业可贷款额度对应的百分比k计算结果如图1所示。

图1 企业可贷款百分比示意图
图1中展示了信贷额度大小排名中,排名前35家中小微型企业,各家企业占银行总信贷额度的百分比;其余88家中小微型企业,占银行总信贷额度的百分比。表2展示了123家有信贷记录企业的信贷风险量化分析后的部分结果,得到的排名靠前的部分企业信贷评级和是否违规的信息。
表2 部分企业信誉风险的信息
企业代号E15E16E64E31E58E89E31E7… 信誉评级AAAAAAAA… 是否违规否否否否否否否否…
从表2中可以看出,拥有信贷额度高的公司均对应较高的信誉评价等级,且在之前的信贷交易中没有出现违约现象。此现象也可说明本文建立的数学模型,具有较好的准确性。本文假设银行放贷总额度为100万,根据公式(5)的计算方式可以得出每一家企业的信贷额度,部分企业对应的信贷额度M如表3所示。
表3 部分有信贷记录企业的信贷额度
企业代号E15E16E64E31E58E89E31… 信贷额度19960197601956019360191601896018750…
4 尚未有信贷记录企业的信贷方案
4.1 决策树模型建立
本文的数据中有302家公司均无信贷记录,在提出的模型公式(4)和公式(5)中缺少信誉评级和上一年是否违约两项。本文使用决策树模型对123家有信贷记录的企业数据进行训练,使得决策树模型可以分别对302家无信贷记录的企业数据的信誉评级进行分类以及预测该企业是否会违约。
通过决策树模型获取信誉评级g和企业是否会违约v。在预测过程中,先选用企业盈利比P、企业每月负发票数平均值n和企业每月负发票对应金额平均值m作为输入值将企业是否违规作为输出值。由于模型预测该项准确率高达90%,故接下来本文将是否违规的预测值作为输入与企业盈利比P、企业每月负发票数平均值n、企业每月负发票对应金额平均m一起输入决策树模型进行分类训练。最终得到企业的信誉评级。
4.2 决策树模型的优化
由于302家无信贷记录企业所给数据较多,并且部分数据具有干扰性,本文对决策树模型进行了剪枝处理,减小模型过拟合的概率提高模型泛化性。剪枝处理属于决策树优化中的精调部分。因为在使用决策树模型的过程中,将不断重复节点分化过程,尽可能使得被训练样本正确分类,这使得决策树模型把训练集本身特性,当作数据具有的一般的性质,从而导致拟合过度。在实际操作过程中通过模拟不同的剪枝深度,计算不同剪枝深度下决策树模型在验证集上的准确率。绘制预测准确度如图2所示。
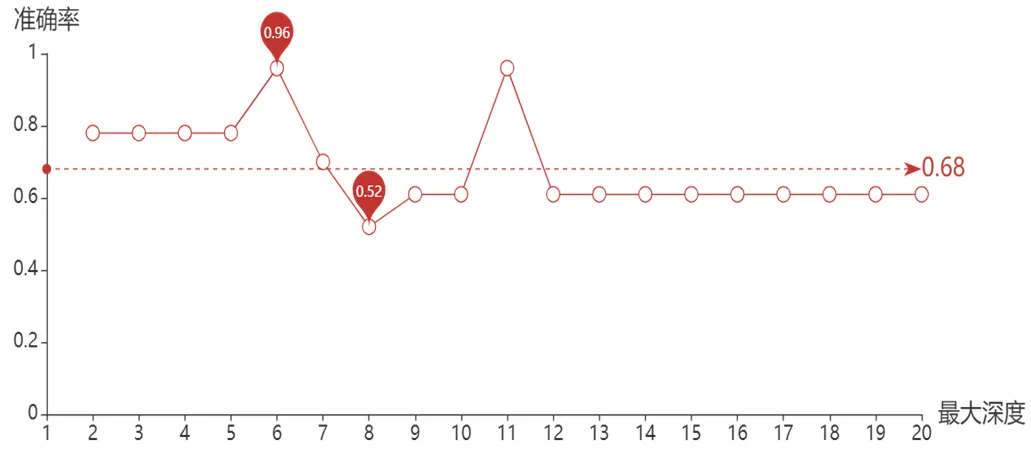
图2 决策树深度对于模型准确率
从图2中可以得到,当剪枝数为6时在验证集上准确率最高,为96%。在生成的决策树中,剪枝之前的结果冗余且繁杂,剪枝后决策树模型更加间接且具有预测更高的准确性,可以满足对信誉评级预测的需求,使得尚未有信贷记录的中小微企业能够获得一个相对精确的信誉评级。
4.3 预测信誉评级与违规情况
将302家无信贷记录企业的数据,输入经过剪枝处理决策树模型,可预测出每一家企业的信誉评级和是否违约情况。部分企业的预测结果如表4所示。
表4 部分企业指标预测效果
企业代号E125E126E127E128E129E130E131… 信誉评级BAACAAA… 是否违规否否否是否否否…
4.4 信誉量化值计算
将预测得到的信誉评级、上一年是否违约。以及附件中企业年利润、销项发票中负价发票个数和负数发票对应的金额分别按照上述建模方式进行处理后计算出企业的信誉量化数值C和企业可贷款百分比k以及每个企业对应的信贷额度M。M计算结果如图3所示。
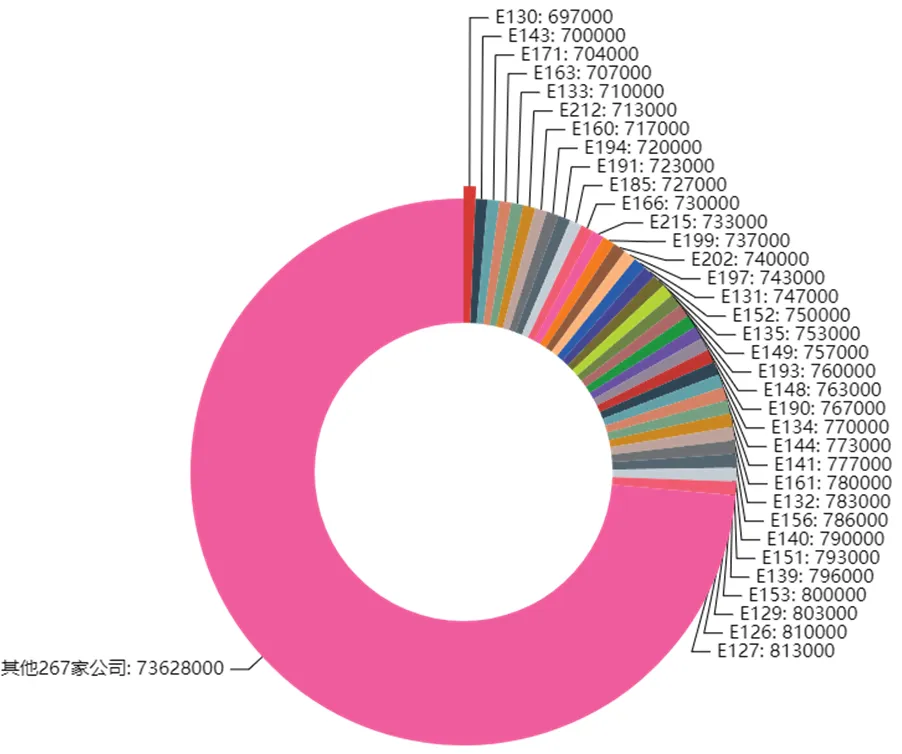
图3 302家无信贷记录企业可贷金额
本文在提取出评估指标的基础上,利用123家有信贷记录的企业数据构建出决策树,从而预测出302家无信贷记录企业中每一家企业的信誉评级和违规情况,构建出有信贷记录的数据集,采用原来的评估方式,计算出每一家公司获得银行贷款的占比,由于预测的过程中可能与真实有出入,将月均收入作为企业可贷金额合理性的一个评估,表5为前5个企业对应的月均收入,信贷评级和是否违规的信息。
表5 可贷款额度前5的企业基本信息
企业代号E127E126E129E153E139 月均收入18640K11857K8179K7095K5459K 信誉评级AAACA 是否违规否否否否否
从表5中可以看出,信贷额度高的公司均对应较高的信誉评价和较高的评价等级,同时在之前的信贷交易中没有出现违规违约现象,也具有较高的月均收入。此现象也可说明模型具有较好的准确性。部分企业对应的信贷额度M如表6所示。假设贷款申请额度为1亿元,下表为部分302家无信贷记录企业根据计算出的信贷额度比例所得的具体信贷额度。
表6 部分302家无信贷记录企业的信贷额度
企业代号E127E126E128E129E153E139 信贷额度813000810000806000803000800000796000
5 结论
本文建立的模型,综合考虑了影响中小微企业信贷风险的多方面因素及其限制,建立的最优模型能与实际生活贴近,可用于多种问题的量化分析,优化资源的配置。建立的数学模型,既忽略了对问题实质影响的部分因素,又体现了问题的主要矛盾,使得模型简单易求解。模型的评价体系、评价体系指标、评价体系方法,可推广到其它的公共服务系统的评价中,简化计算复杂度。模型仍然存在一些不足,本文模型是建立在相对理想的状态下,然而现实的企业信贷的信贷风险还有信息不对称风险、经营风险、道德风险等因素的制约,在现实中应用此模型可能会存在一定偏差。
对银行不同的实际问题,本文建立的数学模型都能给出很好的解决方式,说明模型具有较强的适应性。本文的模型不仅仅只在银行信贷决策方面起作用,而且也能解决商品销售等方面问题,广泛应用于实际生活中的多个领域。
[1] Vieira J, Barboza F, Sobreiro V A, et al. Machine learning models for credit analysis improvements: Predicting low income families' default[J]. Applied Soft Computing, 2019, 83: 105640.
[2] Murjad M D, Rustam Z. Fuzzy support vector machines based on adaptive particle swarm optimization for credit risk analysis[J]. Journal of Physics: Conference Series, 2018, 1108(1): 012052.
[3] 侯明. 疫情下中小微企业信贷扶持政策存在的问题和对策[D]. 长春: 吉林大学,2021.
[4] 孔翼尧. 小微企业信贷管理中的问题与对策分析[J]. 时代金融,2021(19): 81-83.
[5] 蒋伟. 浅析中小企业信贷问题[J]. 时代金融,2014(12): 99-100.
[6] 曲蕾. 小微企业信贷管理中的问题与对策分析[J]. 商讯,2020(36): 117-118.
[7] 费洪波. 银行小微企业信贷业务的问题及对策研究[D]. 成都: 西南财经大学,2019.
[8] 王黎,李烨峰. 信贷资源配置视角下中小企业融资问题研究[J]. 智库时代,2018(51): 34,47.
[9] 王朵朵. 徽商银行B分行小微企业信贷风险管理研究[D]. 蚌埠: 安徽财经大学,2021.
[10] 陈璐璐. 工商银行JA分行小微企业信贷风险管理研究[D]. 长春: 吉林大学,2021.
[11] 赵岚,李俊叶. 基于Logistic回归的企业信贷违约概率模型研究[J]. 科学技术创新,2021(23): 4-5.
[12] 东雨晨. 浅析中小企业信贷融资困境及对策[J]. 商场现代化,2021(19): 58-60.
[13] 翁瑜. 小微企业信贷风险定价的研究[D]. 杭州: 浙江大学,2021.
[14] 王宇晴. “互联网+”视角下小微企业信贷问题研究[J]. 中小企业管理与科技(下旬刊),2021(11): 134-136.
[15] 赵苓伶,陈瑾,李笑莹,等. 基于K-Means聚类分析的中小微企业信贷策略分析[J]. 高师理科学刊,2021,41(9): 14-20.
[16] 谢文华. Spearman相关系数的变量筛选方法[D]. 北京: 北京工业大学,2015.
[17] 张棪,曹健. 面向大数据分析的决策树算法[J]. 计算机科学,2016,43(S1): 374-379,383.
[18] 吴朋民,陈挺,王小梅. Altmetrics与引文指标相关性研究[J]. 数据分析与知识发现,2018,2(6): 58-69.
[19] 由庆斌,韦博,汤珊红. 基于补充计量学的论文影响力评价模型构建[J]. 图书情报工作,2014,58(22): 5-11.
[20] 司守奎,孙玺菁. 数学建模算法与应用[M]. 北京: 国防工业出版社,2015(4): 375-379.
Analysis of Credit Risk Data of Small and Medium-Sized Enterprises Based on Decision Tree
Banks usually need to evaluate the situation of small and medium-sized enterprises before providing loans, and can give special interest rates to companies with high reputations and low credit risk. Through credit quantification, decision tree, and other mathematical models, using fuzzy analytic hierarchy process, spearman correlation coefficient analysis, pruning and other methods, design the bank's credit strategy for small and medium-sized enterprises. For small and medium-sized enterprises with credit records, fuzzy analytic hierarchy process is used to establish a quantitative model of reputation, and the proportion of each enterprise's credit line in the bank's total credit line is obtained. The bank can lend loans to small, medium-sized and micro enterprises in proportion to the actual amount. For mall and medium-sized enterprises without credit records, the decision tree model is used to predict the credit rating and violations of the enterprises, so that enterprises without credit records can obtain a relatively accurate credit record. In addition, the decision tree model is pruned to improve the accuracy and generalization performance of the model. Testing against public data sets to obtain relevant decisions, the model has strong adaptability and can also be extended to other fields.
small and medium-sized enterprises; reputation quantification; decision tree; fuzzy analytic hierarchy process; correlation coefficient analysis
F832.4; TP181
A
1008-1151(2022)09-0005-05
2022-04-29
广西大学生创新创业训练计划立项项目(202010595168、202110595025)。
卢林军(2000-),男,桂林电子科技大学计算机与信息安全学院学生,研究方向为机器学习、深度学习、计算机视觉。
猜你喜欢
公民与法治(2022年12期)2023-01-07 09:16:26
计算机应用文摘·触控(2022年8期)2022-05-25 13:27:53
投资与理财(2019年8期)2019-12-01 11:56:38
华人时刊(2019年13期)2019-11-26 00:54:42
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
华人时刊(2016年19期)2016-04-05 07:56:08
股市动态分析(2015年19期)2015-09-10 04:19:36
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
