
深度学习在图像分类中的应用综述
2022-10-14 08:53金玮孟晓曼武益超
现代信息科技 2022年16期
金玮,孟晓曼,武益超
(华北水利水电大学,河南 郑州 450046)
0 引 言
图像分类技术最早是在20世纪40年代提出的,那时候的技术能力不足,计算机设备不够完善,所以图像分类技术在那个时候没有得到快速发展。随着计算机的快速发展和计算能力的不断提高,深度学习逐渐走入人们的视野,尤其是深度学习中的卷积神经网络,在图像领域掀起一波热潮。卷积神经网络是深度学习(Deep Learning)的重要算法之一,本文通过深度学习中的卷积神经网络对图像分类展开分析和介绍。随着科学技术的不断更迭,卷积神经网络的发展速度迅猛,应用的领域也不断扩大,比如图像识别、自然语言处理、语义分割等领域。能够解决当时遇到的CPU处理能力不足问题,但也只能分析一些小规模的数据,存在着对复杂图片处理不到位等诸多问题。对网络模型采取一层一层的训练是由Hinton研究团队于2006年提出的,在此之后,卷积神经网络在图像处理领域得到了广泛的应用,并且推动了机器学习任务准确率的提高,目前它已经成为一种强大且通用的深度学习模型。随着互联网技术的快速发展,有越来越多的图像信息存储在网上。在这种情况下,如何利用计算机对这些图像进行智能分类和识别,让其更好地服务于人类就显得尤为重要。
一些描述卷积神经网络模型的综述,介绍了卷积神经网络的基本结构以及神经网络的一些经典网络模型,讲述了这些模型的优缺点以及演进过程。综合比较那些热门的卷积神经网络模型之间的异同点,对一些所存在的过拟合问题、计算精度问题进行分析说明。最后,对基于卷积神经网络的图像分类进行总结,并对该领域的未来工作进行展望。
1 深度学习
1.1 深度学习的发展
从时间的角度来看,深度学习经历了两次低谷期,第一次低估是1943的MCP人工神经元模型,当时是希望能够借助计算机来模拟人的神经元反应过程。第一次将MCP用于机器学习的是1958年Rosenblatt发明的感知器算法。它的缺点是只能处理线性分类问题。打破非线性禁锢的是Hinton于1986年发明的适用于多层感知器的BP算法,并且采用Sigmoid算法进行非线性映射,把深度学习从第一次低谷中拉了出来,有效地解决了非线性相关的分类问题。但是之后有人提出BP算法存在梯度消失问题。在此之后决策树方法、线性SVM、KernelSVM、随机森林等被提出,深度学习迎来了第二春。
深度学习可以根据数据是否具有标签划分为监督学习和非监督学习。监督学习的方法有:循环神经网络、卷积神经网络、深层堆叠网络等。非监督学习的方法有:生成对抗网络、深度信念网络、玻尔兹曼机、自动编码器(AutoEncode)等。它们的应用场景各有不同,包括语音分析、文字分析、时间序列分析、图像分析领域等。此外,受限玻尔兹曼机(RBM)一般在实际工作中不单独使用。
1.2 深度学习的应用领域
随着深度学习的快速发展,深度学习的算法模型也在不断改进,并且运用到各种领域。例如:无人驾驶汽车、安保方面的人脸识别、图像中的物体分类、交通场景识别以及医学领域的图像识别,等等。深度学习在无人驾驶领域主要用于图像处理、感知周围环境、检测车辆、行人、交通标志等目标;在安防监控中,人脸识别有重大意义,比如公共场所(地铁站、车站、街道等)的人脸识别。公共场所的人脸识别可以帮助公安抓捕嫌犯;在医学领域可以做到医疗看护,尤其是在长期的辅助生活中,人脸识别可以帮助护士密切关注患者或监控行动不便老人的活动,以免发生意外事故。深度学习已在诸多领域中得到成功应用,但依然会有更多的高精度算法被陆续提出,未来深度学习会有更广阔的发展空间。如图1所示为深度学习在自动驾驶中的应用。
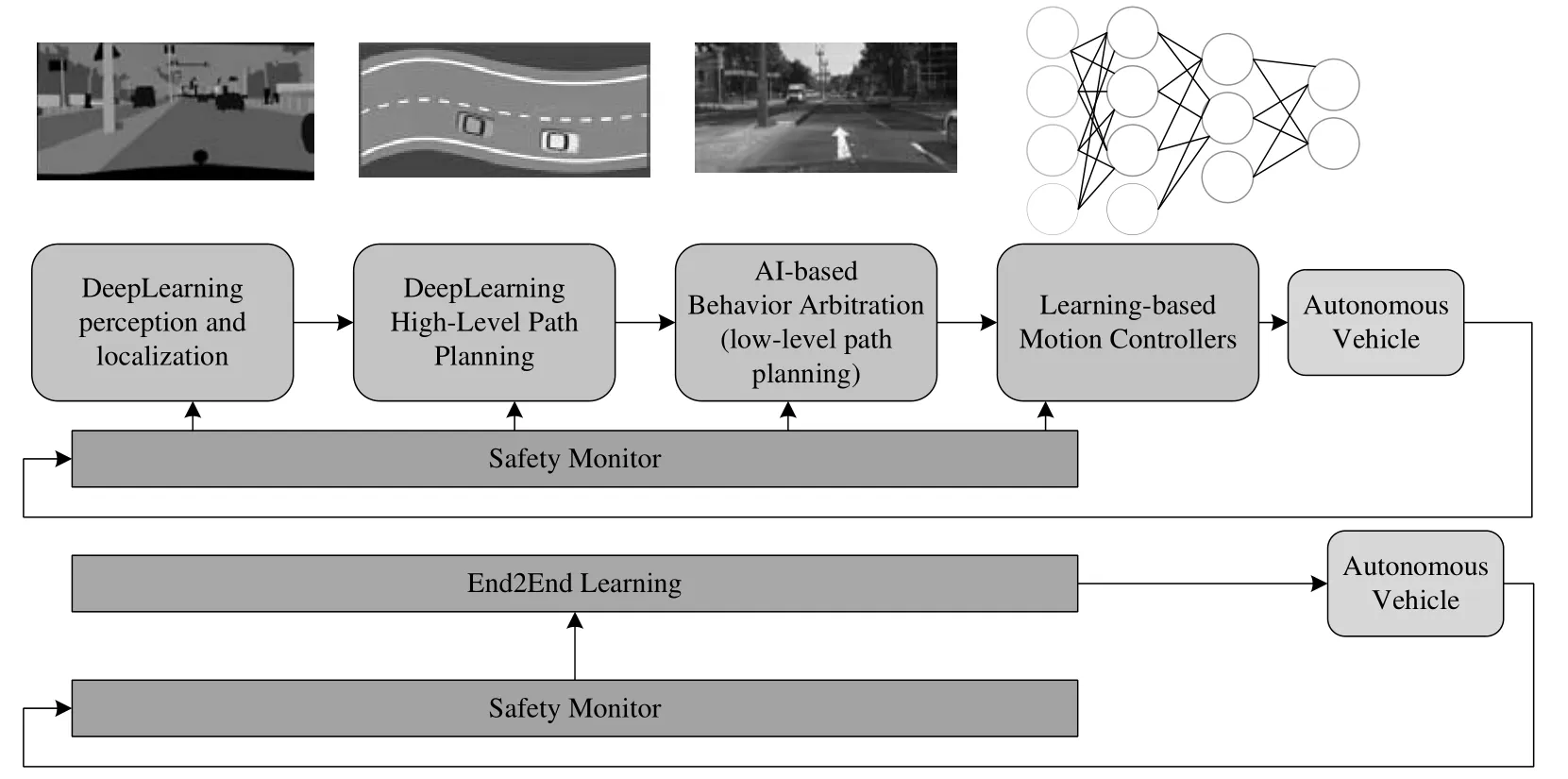
图1 基于深度学习的自动驾驶
2 卷积神经网络
卷积神经网络具备的网络层次比较多,包括输入层、卷积层、池化层、全连接层等。
卷积层在整个网络中的作用是对输入数据进行特征提取,卷积层内的任何一个神经元都与上一层中位置接近的神经元形成一对多的连接关系,并且卷积核的大小是决定区域大小的关键,这也被称为“感受野”(receptive field)。此外,卷积层还有一个重要特点就是采用了参数共享机制,对于不同的区域,我们都共享同一个卷积核,这个机制可以大大减少网络参数的数量。减少参数数量会使模型的训练更有效,从而避免过拟合问题。
池化层在整个网络中的作用是逐步减小数据的空间大小,目的是减少网络中的参数数量以及降低计算复杂度,以便很好地控制过拟合。其中池化的方式也有很多,如最大池化、平均池化等。因为图片具有平移不变性的特征,所以池化层的作用会更加有效,通过不断的下采样操作图片不会损失本身具有的特征。我们可以将图片缩小到合适的尺寸,这样能够极大地降低卷积运算时间,减少最后在全连接层的参数,进而提升了计算的效率。
全连接层在整个网络中的作用是连接之前的卷积层、池化层等进行的多种操作的特征,最后把输出的值分配给一个分类器。简单来说就是通过特征提取实现分类。在实际的应用当中,全连接层也可由卷积操作实现。全连接层的长度、神经元数、激活函数是全连接层对模型影响的三个参数。
3 图像分类的网络模型
Krizhevsky等提出了由5个卷积层和3个全连接层组成的Alex Net网络结构,采用Re Lu激活函数解决之前Le-Net使用的Sigmoid函数在深层网络中出现的梯度弥漫问题;同时,为了减少过拟合问题,提出了Dropout方法,还可在一定程度上减少训练任务量。如表1所示,他们在ILSVRC-2012竞赛中top-5错误率为15.4%,并且取得了当时的冠军。这一成果成为当时学术界的一大焦点,此后卷积神经网络会向网络的更深层次或网络结构改进的方向出发。当然,这个网络会具有一定的局限性,也就是受限于GPU的可用内存量以及我们愿意接受的训练时间长度。
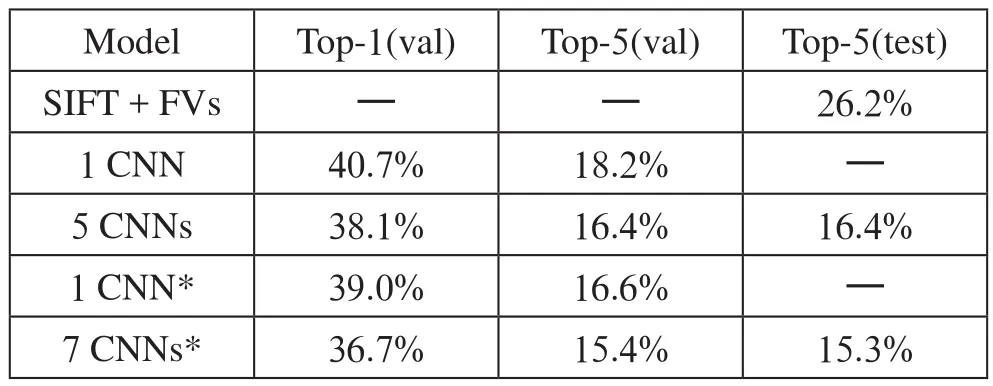
表1 ILSVRC大赛的错误率比较
Simonyan等提出了VGG网络,使用的是较小的卷积核(3×3)并采用堆叠的方式,这样可以减少参数的数量,他们没有违背Le Cun等人提出的经典卷积神经网络架构,只是对其进行了一些改进即增加了深度,并且证实了加深网络结构可以提高分类的精度和性能。可以通过尺度抖动增强训练集的方式来获取多尺度图像的统计信息。这个模型在ILSVRC 2014中获得了第二名的成绩,逊色之处是这样的网络模型使用的参数过多,会导致训练速度较慢,建议之后在这个问题上多加改进,但网络的最佳深度限制到16~19层。
GoogLeNet是由Christian Szegedy等人在ILSVRC 2014中提出的一种新型网络模型,引入一个新的模块(也就是如图2所示的Inception-V1模块)。利用这个模块增加网络结构的深度,进而提高效率和准确率,指出1×1卷积的关键作用:主要用于降维,抵消计算瓶颈,否则我们的网络规模将受到限制,在增加网络深度的前提下还可以增加网络的宽度,并且保持性能不会有损失。如果提升了网络的模型,参数就会增多,容易出现过拟合问题,应用起来会有一定的难度。
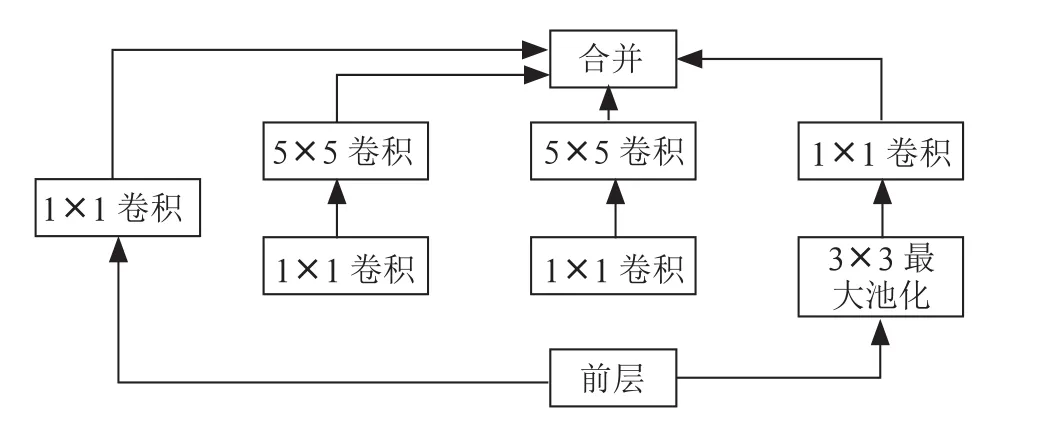
图2 Inception-v1模块结构
之后谷歌团队相继提出了Inception-V2、Inception-V3、Inception-V4等模块,减少一定的参数量;提高了网络训练速度;缓解了梯度弥漫问题。
Kaiming He等提出了Res Net更深层次的网络模型,在ILSVRC2015中斩获第一名,他们提出了利用残差学习框架对网络的一些训练进行简化,证实这些残差网络更容易优化,而且在大幅度增加深度的同时还可以保持有效的精度。他们的残差网高达152层,而且复杂度还低于VGG网络,在图像分类领域中取得了较好的成果。因为梯度消失的问题会成为一些障碍,所以Res Net采用残差模块来解决退化问题。如图3所示,他们构思了一个体系结构也就是添加一个身份映射,把最初的底层映射表示为(),结合堆叠的非线性层的另一个映射可转换为()+,得到一个恒等式:()=()+。
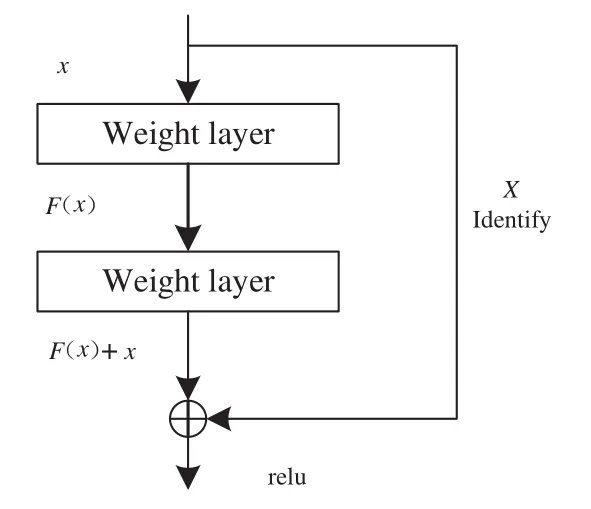
图3 残差学习模块
Zhang等提出了DenseNet的网络模型,它以前馈方式将每一层连接起来,与之前的卷积网络不同的是,在DenseNet中,会有(+1) /2个连接,每一层的输入都来自之前所有层的输出。其中DenseNet的特点有:减轻了梯度消失、加强了feature传递、鼓励了特征重用、减少了参数数量。DenseNet能够改善整个网络的信息流和梯度,这样使得它们更容易训练。DenseNet因为其紧凑的内部表示以及减少的特征冗余,对于特征转移这方面还没有突破。基于CNN图像分类模型的ImageNet数据集错误率对比如表2所示。
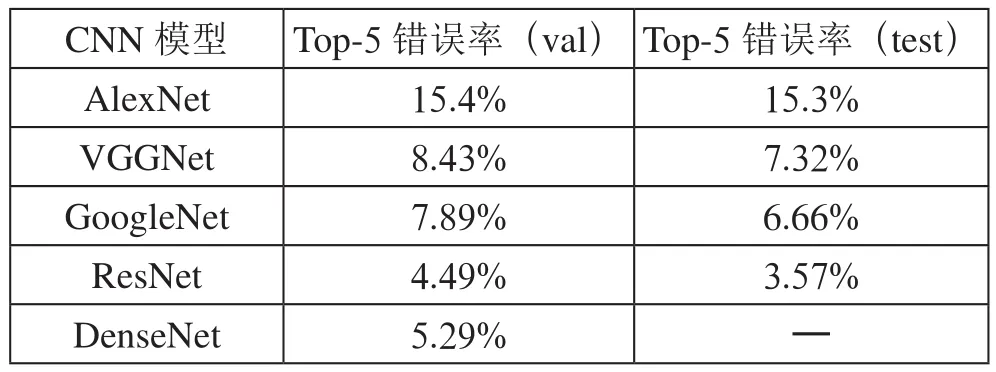
表2 基于CNN图像分类模型的ImageNet数据集错误率对比
4 结 论
回顾了卷积神经网络在图像分类领域中所取得的一些优异成绩,同时也点明了其在图像分类识别中仍然存在一些问题。通过本文的综述,提出一些可能会对图像分类领域的学者有所帮助的方法,抑或为他们指明一些方向。
卷积神经网络模型在应用方面对计算机硬件的要求非常高,对于较大规模的数据集其计算能力可能会受到影响,所以可以尝试基于小样本数据集进行迁移学习。如何正确使用小样本数据,其中的方法值得我们做进一步的研究。
目前卷积神经网络在图像分类领域中使用的大都是监督式学习,耗费大量的人力和物力,而对于半监督学习以及非监督学习的图像分类算法还不太完善,不过可以弥补一些监督学习的不足之处,如何把卷积神经网络更好地应用于该领域值得诸多学者们做进一步的深入探究。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
中国教育信息化·高教职教(2022年4期)2022-05-13
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
计算技术与自动化(2022年1期)2022-04-15
煤气与热力(2022年2期)2022-03-09
上海师范大学学报·自然科学版(2019年5期)2019-12-13
福建基础教育研究(2019年6期)2019-05-28
软件(2017年6期)2017-09-23
中国新通信(2017年9期)2017-05-27
