
融合边缘检测的3D点云语义分割方法研究
2022-10-13 03:28伏娜娜胡志锋郑书展
重庆工商大学学报(自然科学版) 2022年5期
陈 玲, 许 钢, 伏娜娜, 胡志锋, 郑书展
(安徽工程大学 检测技术与节能装置安徽省重点实验室,安徽 芜湖 241000)
0 引 言
随着3D采集技术的不断发展与完善,3D数据运用于各个不同的领域中。点云作为一种常用的3D数据表达形式,能够在空间里将原始的几何信息完整地保留下来,不会产生离散化。作为理解和分析3D场景基础的点云语义分割[1],更是未来研究的热点。点云语义分割是区分点云中的每个点,将点云划分为一块块具有特定语义信息的区域,在计算机视觉中具有重要研究意义。
随着卷积神经网络、深度学习的快速发展,也推动了点云语义分割技术不断前进,在不同领域中应用范围广泛,比如在无人驾驶、室外建筑物识别[2]和室内机器人定位等领域。近年来,为了解决3D点云不规则且无序性等问题,许多学者利用深度学习[3]的方法将其转换为可用于卷积神经网络处理的规则结构。在此基础上Qi等[4]提出了PointNet利用多层感知机学习逐点数据提取全局特征,再使用MLP对每个点进行分类,但该方法对局部特征的感知较差。为此Lian等[5]提出了一种高密度的PointNet++,它能够在不同尺度上提取局部特征;柴玉晶等[6]引入了图注意力机制增强局部特征的感知能力来更好地学习点云的空间分布;Huang等[7]提出了条件随机场的方法,认为可在语义分割后期改进物体边缘的分割效果;Ye等[8]提出了递归神经网络(RNN)进行端到端学习,更好地捕获点云中的上下文特征并将其合并。但这些方法在融合全局特征和局部特征时会丢失点云丰富的几何特征和空间密度分布。
为了更好地融合全局特征与局部特征,TAKIKAWA等[9]设计了一个双流CNN结构,将形状流与经典流并行处理,这种结构可以在物体边缘产生更清晰的预测,并且对小物体和瘦物体有更好的性能。但这种方法现用于2D图像中且未对分割出的物体边界进行语义信息的提取。综上所述,在现有的方法中,物体边缘的分割精度仍有待加强且未能将全局信息及局部信息进行有效融合。为此,本文提出了一种融合语义边缘检测的三维点云语义分割算法。在文献[10]的基础上引入了注意力机制对点云的边缘信息能够有效提取,减少感知歧义,生成精确的语义边缘。同时设计了一个融合模块,将语义边缘检测网络得到的边缘特征和语义分割网络得到的区域特征进行有效融合并对其进行优化。融合后的网络改善了语义分割结果中分割目标不明确、边缘不清晰等缺点,同时对小物体也有更好的分割性能。
1 相关工作
1.1 2D语义边缘检测
目前,在二维图像中,一些工作利用基于CNN的方法进行边缘提取与分类。CASENet[11]利用全局嵌套边缘检测(HED)网络[12]增加类别感知的语义信息,将低层和高层特征与多标签损失函数相结合进行监督学习。在后续工作中,SEAL网络[13]通过减少标注过程中不可避免的不对齐导致的训练标签噪声来优化CASENet。为解决固定权重融合的局限性,提出一种动态特征融合(DFF)模型[14],根据特定的输入为每个位置推断出合适的多层次特征融合权重,从而有助于产生更准确的边缘预测。
与现有工作不同,本文为了对3D点云进行有效的语义边缘检测,从2D语义边缘检测中借鉴了提取增强特征的思想,对3D点云中的对象进行物体边界的提取,从而更好地识别三维物体。
1.2 融合边缘检测的语义分割
对于二维图像,将边缘检测任务和语义分割任务进行联合学习,对提升语义分割学习速率、预测精度是一个可取的做法。在Gated-SCNN中,利用了分割和边缘预测任务之间的对偶性,将边界信息融入分割CNN中来辅助分割,并引入了双重损失来细化语义分割和边缘预测。DecoupleSegNets[15]则是通过对不同监督下的主体和边缘进行解耦,再与相应的两个正交部分损失函数将其合并完成最终分割任务。以上两个网络都是利用二值边缘检测联合语义分割来提升性能。而RPCNet[16]是将语义边缘检测与语义分割任务进行联合学习,识别属于目标边界的像素类别,以提高边缘分割的正确性。
利用类别感知的3D边缘检测方法与3D点云语义分割方法进行联合学习,两者的耦合性会更加一致。此外,与以前的工作不同,它将分割和边缘检测之间的交互限制在特征和网络结构的共享上,同时利用了语义分割的全局特征和语义边缘检测的边缘特征之间的密切关系。
2 网络结构设计
2.1 网络整体结构
如图1所示,该架构是融合语义边缘检测的语义分割网络整体结构,由两个主流网络构成。首先通过一个共同的特征编码器对点云进行特征提取与编码,保留完整且相同的点云空间信息,然后经过不同的解码结构分别得到不同的特征信息。语义分割解码模块得到的是语义全局特征,语义边缘检测解码模块得到的具有语义信息的边缘特征,为了更好地融合全局特征与边缘特征,采用融合算法来处理特征合并,以达到最终理想的语义分割结果。
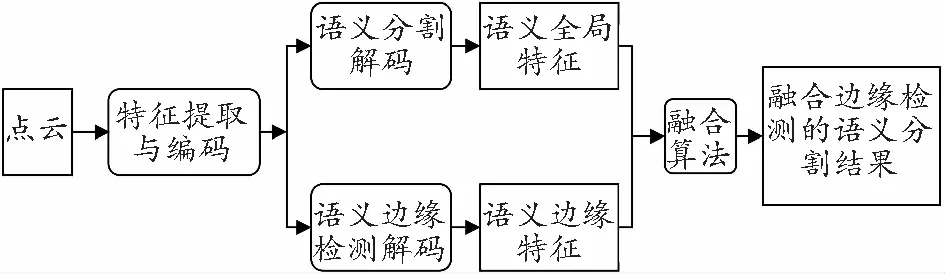
图1 语义分割网络整体框架Fig.1 The overall framework of semantic segmentation network
2.2 语义分割网络
2.2.1 特征提取
为了减少信息的损失,采用直接对点云进行卷积处理的方法,不使用点云的其他中间表示形式。该网络采用基于核的方法KPConv(Kernel Point Convo-lution)[17]建立骨干网络,克服了之前卷积方法的局限性。KPConv分为可变卷积核和不变卷积核,文中采用的是不变卷积核,它具有良好的收敛性能。
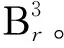
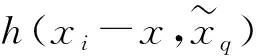
对于落在球内的点xi,对应于它们特征fi,通过上一步的方法获得新的特征,最后将特征累加作为点x的特征,即:
以上就是对点云进行特征提取的过程。
2.2.2 编码器与解码器
语义分割网络由编码器—解码器构成,如图2所示,编码器内表示的是特征提取与编码部分,语义分割解码器内表示的是解码部分。
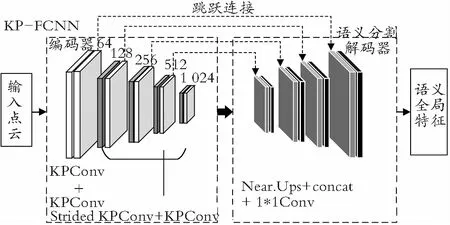
图2 语义分割网络模块Fig.2 Network module of semantic segmentation
如图2所示的KP-FCNN是一个全连接的卷积神经网络,其中编码部分被设计为基于ResNet[18]网络结构,其中包含五层卷积网络,每一层卷积网络中都由两个卷积模块构成,除了第一层由两个相同的KPConv卷积块构成,其他每一层都由KPConv和Strided KPConv卷积块构成。
如图3所示,KPConv卷积块代替了每一层中BN(Batch Normalization)和Leaky ReLu Activation的作用,其中BN层主要对点云的分布进行归一化,使用更大的学习速率使得梯度传播能够更稳定地进行,增加网络的泛化能力。ReLu激活函数的作用是在使用梯度下降法时,会使收敛速度更快。与一般的网络结构不同,该网络已经有了网格采样,因此在每一层新的位置上不需要池化层进行下采样[19]操作,在网络结构中使用KPConv卷积提取小区域的局部特征向量并且称为“跨步KPConv”,类比图像中的跨步卷积。编码器阶段主要对点云进行不同尺度的特征提取。
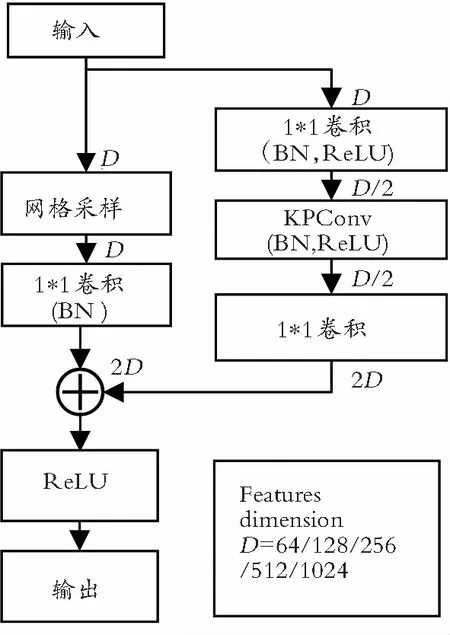
图3 核点网络层Fig.3 KPConv network layer
解码部分使用了最邻近上采样来获得最终的逐点特征。编码层和解码层之间的特征使用跳跃连接来传递,以上特征被并联到上采样部分通过一维卷积来处理。由以上所述的网络结构得到了具有语义信息的全局特征,也就是初步语义分割结果。
2.3 语义边缘检测网络
语义边缘检测网络如图4所示,编码器内是与语义分割网络相同的编码结构对点云的特征进行提取,语义边缘检测解码器内表示的是对提取的特征增强,捕获目标的边缘信息并对其添加语义信息。
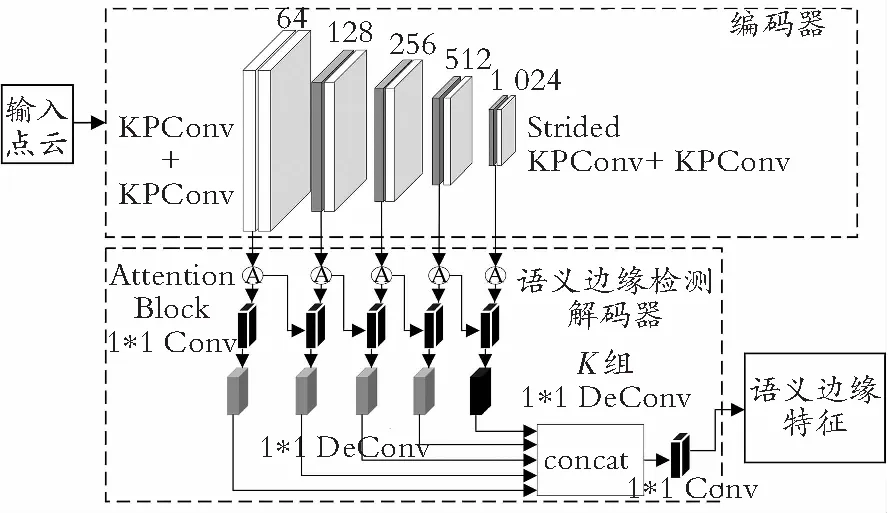
图4 语义边缘检测网络模块Fig.4 Network module of semantic edge detection
语义边缘检测解码器的输入与语义分割解码器的输入均来自前一级编码器所使用的五层卷积网络,该网络去除了所有的连接层得到了全卷积网络,去除了第五层的池化操作,避免了高层信息的丢失,增加了感受野,对特征边缘及小物体进行更好地定位。
为了对提取的不同尺度特征进行增强处理,语义边缘检测解码加入了注意力机制[20]模块(Attention Block)。如图4所示,在每一层后加入了注意力机制模块,且将每一层经过注意力机制模块提取后的特征加入后一层卷积块中,多种不同尺度的特征进行提取融合。如图5所示的注意力机制模块,将输入的点云数量设为N,特征维度为C,通道数为D。在该模块内,通过卷积层、全连接层和softmax得到各点之间的权重概率分布,然后对各点特征进行加权处理,得到带不同点的注意力新特征。
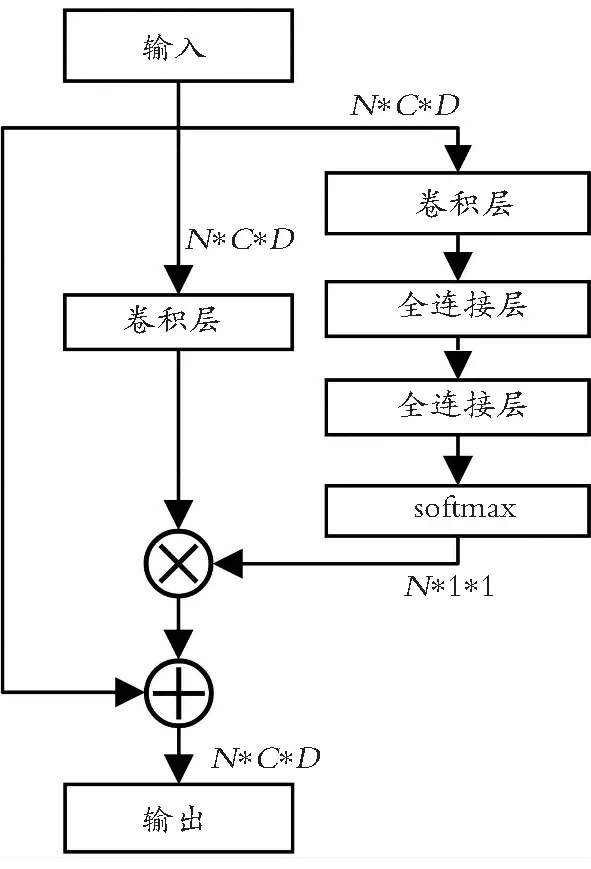
图5 注意力机制模块Fig.5 Attention block
H(x)=Wi(x)*Ti(x)+x

在增强特征提取操作后加上一个Deconv layer用于放大特征信息。为了使边缘轮廓加入语义信息,在以上基本网络的第五层加入了一个分类模块,该分类模块采用一个双线性上采样(由K组反卷积层去完成)以产生K个激活边缘结果(其中K表示语义类别),每个结果的大小都与输入点云相同。每一层经过反卷积操作得到的输出结果进行concat融合,随后使用一个1×1 Conv layer进行特征融合,得出输出点云大小与输入点云大小相同的结果。由以上网络结构得到了具有语义信息的边缘轮廓特征结果。
2.4 融合结构
融合结构如图6所示,将语义分割网络得到的全局特征结果与语义边缘检测网络得到的边缘特征结果进行融合,将融合后的结果进行分割细化得到最终语义分割结果。
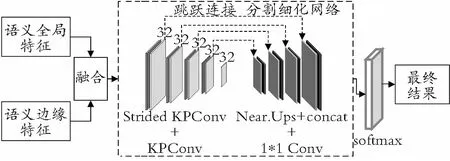
图6 融合模块Fig.6 Fusion module
在进行两路特征融合时,采用加权融合[21]的方式利用两路信息,其中语义全局特征为A,语义边缘特征为B,融合后的特征M可表示为
M=W(A+B)⊗A+(1-W(A+B))⊗B
其中,W表示为全局特征映射的权值,两路特征映射的权值之和为1。
为了更好地融合全局和边缘特征,构建了一个分割细化网络。该网络如图6中分割细化网络所示,在编码结构中有五层卷积网络,除第五层以外,每一层都由KPConv卷积块和Strided KPConv卷积块构成,其中各层的通道数的大小为32。解码部分同样使用了最邻近上采样来获得最终的全局特征。使用跳转连接在编码和解码中间层之间传递特征并用concat函数进行融合,将局部特征与全局特征同时考虑,所有特征被并联到上采样部分通过一个1×1卷积进行处理。
Softmax用于多分类过程中,首先将所有预测的结果转化为非负数,然后对转换后的结果进行归一化处理,最后预测边界的点将具有较大的激活值。采用softmax函数进行分类处理,得到最终的语义分割结果。
3 损失函数设计
本文模型是将语义边缘检测及语义分割进行联合学习,故使用了双重语义损失函数,使网络具有更好的语义边界结果。

其中,β是K类点云中非边缘点的百分比,以解释样本数的偏度。该损失函数用来监督边缘信息的提取,强迫边缘检测部分只学习边缘信息。
针对语义分割网络中损失函数的选取,采用了一个标准的多类别交叉熵损失函数。假设输入的一组点云P,具有语义类别K,其损失函数定义如下:

4 实验设计与结果分析
4.1 实验数据集及评价指标
S3DIS数据集包括三个不同建筑中的5个大型室内区域,每个区域的面积约为1 900、450、1 700、870和1 100 m2(总共6 020 m2)。这些区域在以下方面表现出不同的建筑风格和外观属性,主要包括办公区域、教育和展览空间,以及会议室、个人办公室、卫生间、开放空间、大堂、楼梯和走廊,同时包含了13类室内场景对象。
采用的评价指标平均交并比(Mean Intersection Over Union,MIOU)为语义分割的标准度量其值为fMIOU表示。计算两个集合的交集和并集之比,在语义分割的问题中,这两个集合为真实值(Ground Truth)和预测值(Predicted Segmentation)。这个比例可以变形为正真数(Intersection)比真正、假负、假正(并集)之和。在每个类上计算IOU(Intersection Over Union),之后平均。
4.2 网络参数设置及实验方法
本文的算法实验系统为Linux16.04,使用的GPU是NVIDIA GTX 1080Ti,运算平台为CUDA-Toolkit 9.0,深度学习框架为Pytorch,版本号为1.1.0。在模型训练过程中,使用一个具有动量的梯度下降优化器,以0.95的动量和0.01的初始学习速率,去最小化逐点交叉熵损失。学习速率呈指数下降。将weight_decay设置为0.000 1,batch size设置为4。
该网络采用的骨干网络是基于KPConv的算法框架,除了对基本网络参数的设置,还要对其他参数进行一些设置。由于三维场景点云数量巨大,所选取的数据集是室内场景,在随机采样时采样半径为2 m的球体,并用高斯噪声[22-23]、随机缩放和随机旋转来增强。输入的点云被下采样,设置网格大小为4 cm。在训练过程中,设置网络最多需要120个epoch才能收敛,对于分割任务可以生成输入球形领域的任意个数,若一个epoch为500次优化,相当于网络可以看到2 000个领域球。
4.3 实验结果与分析
4.3.1 S3DIS数据集区域5测试结果
图7-图10是S3DIS数据集区域5的语义分割可视化结果,选取了3个场景对语义分割结果进行了对比,并与原始场景和Ground Truth语义分割结果进行了对照。

图7 原始点云数据Fig.7 Cloud data of original points

图8 真实值Fig.8 True values

图9 Rigid KPConvFig.9 Rigid KPConv

图10 本文算法Fig.10 Algorithms used in this paper
将Rigid KPConv算法实验结果与本文算法实验结果对比,能够清晰看到门、墙以及杂物的分割更为精准,同时也减少了误分割、分割不准确等问题。例如图7(a)中,算法对门的分割更为清楚,有明显的轮廓;图7(b)中,算法对墙上的壁画和周围物体的边界有着较为良好的分割性能;图7(c)中,算法对墙、门以及书架有了更为清晰的认知能力,同时对小物体也有较好的分割性能。
表1是算法在S3DIS数据集区域5内测试的结果。实验结果表明与Rigid KPConv算法相比,本文算法在对柱状物体、门、窗户等物体有较为良好的分割结果。例如在表1中柱状物体的fMIOU提高了6%,门的fMIOU提高了11%,对窗户的fMIOU提高了23%,有着较为良好的分割性能。但仍对椅子、书架这类物体分割性能有稍许欠缺,可能与物体的复杂性有关。
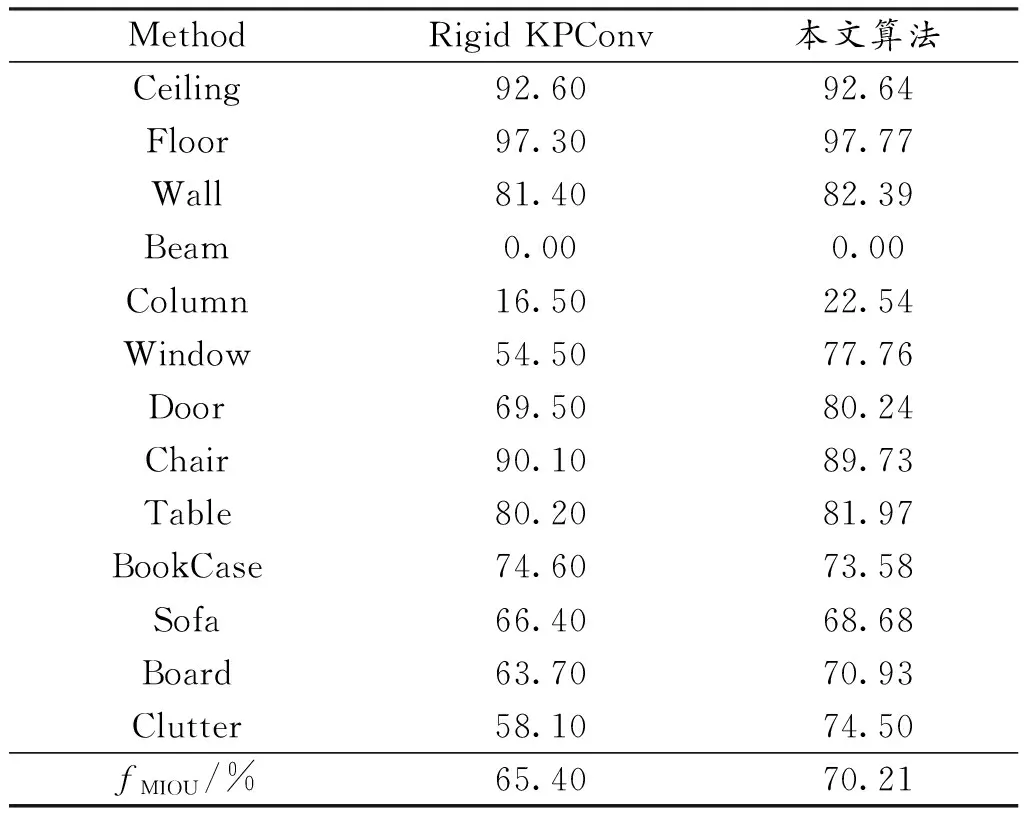
表1 S3DIS数据集区域5上语义分割的详细MIOU分数Table 1 Detailed MIOU scores of semantic segmentation in region 5 of S3DIS dataset
由图7、表1可知融合了语义边缘检测的语义分割网络具有更好的分割性能,对物体的边缘信息能够更好地完善。在S3DIS数据集区域5上的实验结果表明,本文算法较卷积核不变的KPConv算法在语义分割结果精度上提高了4.81%。
4.3.2 消融实验
为了进一步分析网络中各因素带来的影响,通过消融实验研究加入不同模块对测试结果的影响。实验在数据集S3DIS区域5内进行。
如表2所示,测试结果中只考虑语义分割模块得到的初步语义分割结果分割精度为64.43%,在本文中语义分割网络采用的是与基于KPConv算法相同的网络架构,得到的分割精度与Rigid KPConv算法得出的分割精度仍有差距。对于加入语义边缘检测任务中来看,在没有引入注意力机制网络的情况下,产生了具有语义信息的边缘轮廓与语义分割模块得到的结果融合细化,输出的最终语义分割结果的分割精度为68.90%,fMIOU提高了4.47%;在引入注意力机制网络后增强了特征信息的同时抑制了非边缘的语义信息的产生,改进了语义边缘检测的性能,得到最终语义分割实验结果的分割精度为70.21%,fMIOU提高了1.31%,总体提高了5.78%。这表明了语义边缘检测模块及注意力机制网络对语义分割精度的提高是有效的。
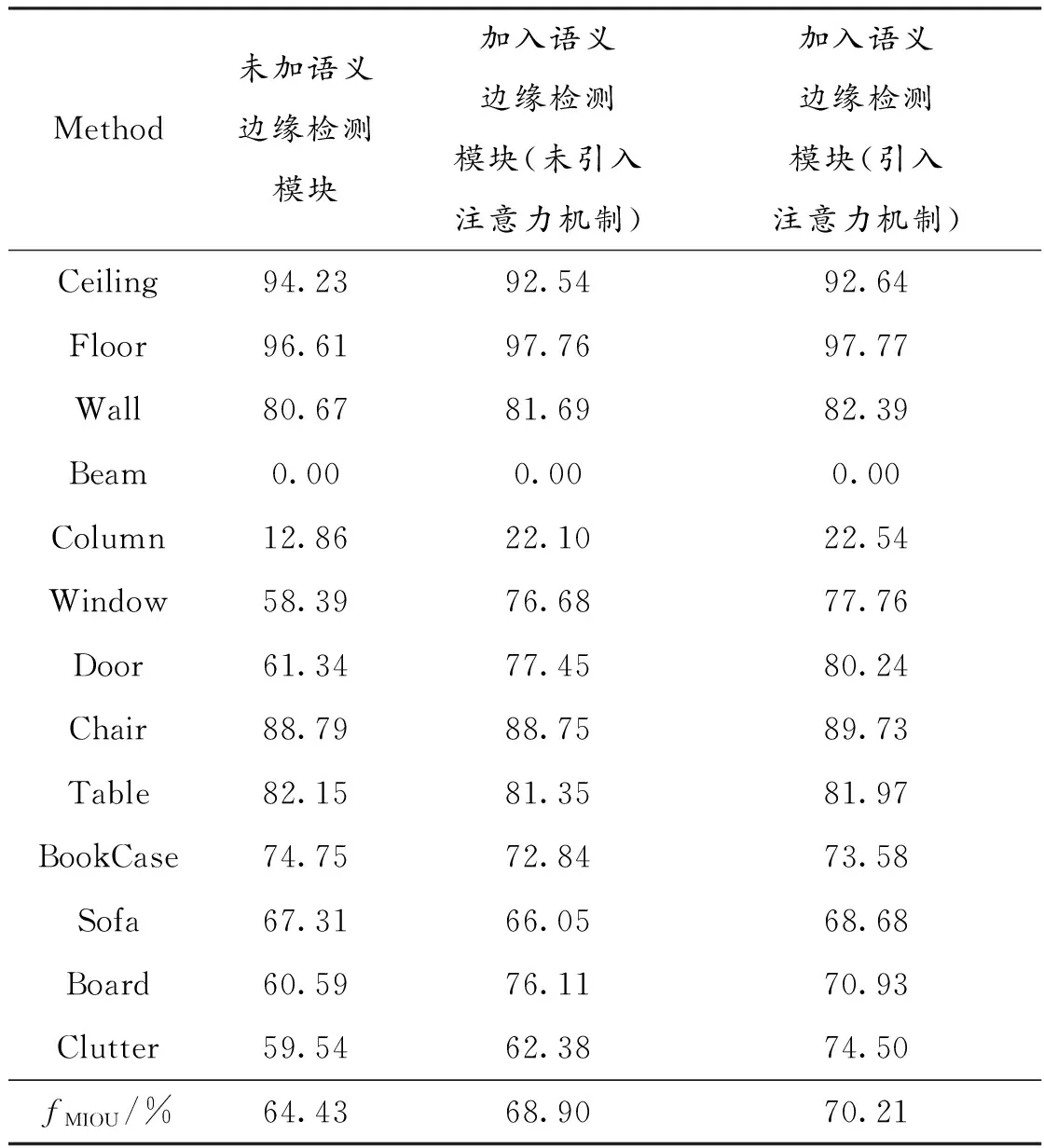
表2 不同模块的有效性对比Table 2 Comparison of effectiveness of different modules
5 结束语
提出将语义分割网络及语义边缘检测网络进行联合学习,是一种双流FCN结构。语义分割网络是对点云数据进行初步提取区域内的全局语义特征信息。在语义边缘检测网络中引入了注意力机制,对点云数据中物体的边缘进行特征提取增强,抑制了非边缘信息的产生,给边缘信息赋予了丰富的语义特征信息。然后将两路网络得到的语义特征信息进行融合处理,同时对融合结果进行输出细化。此外,使用了双重语义损失函数,使网络产生更好的语义边界,以此得出最终的语义分割结果。实验结果表明,融合了语义边缘检测的语义分割网络对物体的边界分割效果更加清晰明确,改善了边缘信息模糊的问题,提高了总体分割的精度。在数据集S3DIS上验证了该网络的有效性,能够得到较为理想的分割效果。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
开放教育研究(2020年2期)2020-03-31
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
通信产业报(2016年44期)2017-03-13
中国社会历史评论(2016年2期)2016-06-27
现代语文(2016年21期)2016-05-25
长江学术(2016年4期)2016-03-11
雕塑(1999年2期)1999-06-28
