
基于关键词结构编码的涉案微博评价对象抽取模型
2022-10-13 08:41王静赟余正涛
数据采集与处理 2022年5期
王静赟,余正涛,相 艳,陈 龙
(1.昆明理工大学信息工程与自动化学院,昆明 650500;2.昆明理工大学云南省人工智能重点实验室,昆明 650500)
引 言
微博等社交媒体的蓬勃发展让人们获得更丰富、更及时的信息,同时每天也会产生大量评论。其中,与案件相关的评论在网络上迅速传播,所产生的舆论会干扰有关机构的工作。为此,获取涉案微博评论的评价对象,对于后续进行案件相关评论的细粒度情感分析,掌握案件舆论走向具有重要的作用。
涉案微博评价对象抽取的目的是从微博用户的评论文本中识别出被评价的对象,例如,在“这次事故女司机是无辜的”这一评论中,需要识别出评价对象“女司机”。针对评价对象抽取任务,目前的方法主要分为基于规则[1-4]、基于传统机器学习[5-8]和基于深度学习的方法[9-17]。基于规则的抽取方法是利用关联规则、频繁词项和句法依存关系进行评价对象的抽取,但是这些方法严重依赖于人工定义的规则,需要消耗大量的时间精力,可移植性差。基于传统机器学习的方法通常将该任务看作一个序列标注任务,利用支持向量机、句法关系和条件随机场(Conditional random field,CRF)等进行评价对象的抽取,也依赖于手工特征。基于深度学习的模型可以自动地学习特征,通过注意力机制等获取句子中与评价对象更相关的信息,在评价对象抽取任务上表现出优异的性能。
涉案微博评价对象抽取任务具有特定的领域性。针对某个案件,网友的评论通常都会围绕微博正文中所提及的案件发生的人物、地点等关键词展开。换句话说,正文中出现的案件关键词构成了用户评论的评价对象。如表1所示,在“奔驰女司机维权案”这个案件中,评论中出现的“女司机”“奔驰店”“女车主”“奔驰”等评价对象在对应的正文中都被提及。显然,微博正文中与案件相关的关键词信息对于涉案微博评价对象抽取任务是有效的。

表1 微博正文及其对应的评论示例Table 1 Example of microblog text and corresponding comments
因此,可以利用微博正文中的案件关键词信息作为引导,帮助模型识别用户评论中的评价对象。然而,案件关键词之间是独立的,不存在序列依赖关系。因此,借助Lin等[18]提出的结构编码思想,本文将关键词组合表示为多个语义片段,从而综合利用多个关键词的信息指导评价对象的抽取。具体来说,首先使用结构编码机制对案件关键词进行编码表征,然后通过交互注意力机制融合评论句子表征和案件关键词表征,最后送入CRF,进行评价对象的抽取。
本文的主要贡献如下:
(1)结合涉案微博数据的特点,提出了利用微博正文中的关键词信息指导评论中的评价对象抽取。
(2)提出利用结构编码机制对微博正文关键词进行编码,从而能综合利用多个关键词信息,构建涉案微博评价对象抽取模型。
(3)在人工标注的“奔驰女司机维权案”和“重庆公交车坠江案”涉案微博数据集上进行实验,证明了模型的有效性。
1 相关工作
现有的评价对象抽取的模型主要分为基于规则、基于传统机器学习和基于深度学习的抽取模型。
(1)基于规则的抽取方法是利用人工定义的规则和句法依存关系抽取评价对象词项。例如,Hu等[1]提出利用关联规则抽取评价对象,并抽取出句子中与评价对象相距最近的表达意见的形容词;Zhuang等[2]采用WordNet和人工构建的词表寻找评价对象和观点词,然后使用依存解析的方法提取有效的评价对象-观点对;Blair-Goldensohn等[3]提出利用句子中出现的频繁词项抽取评价对象;Qiu等[4]提出了一种使用依存树学习句法关系的独特方法。然而,这些方法严重依赖于预定义的规则和外部资源。
(2)基于传统机器学习的抽取方法一般是将其定义为一个序列标注任务。例如,Kessler等[5]提出使用支持向量机对情感表达的潜在评价对象进行排序,通过解析句子的依存关系抽取评价对象词项;Jin等[6]提出构建一个由词和词性组成的词集,根据这个词集对评论进行标注,然后送入隐马尔可夫模型训练,抽取评价对象词项;Jakob等[7]提出使用通用句法关系作为枢纽来减少领域间的差异,用于跨领域的评价对象抽取;Shu等[8]提出了一种终身学习的方法能让传统的CRF从之前领域的抽取任务中获取知识,从而利用获取的知识在当前的任务中更好地执行抽取任务。然而,上述方法对大量的手工特征有很强的依赖性,难以处理特征缺失的情况。
(3)基于深度学习的抽取方法可以自动学习特征,在该任务上表现出了强大性能。例如,Li等[10]利用神经记忆交互建立评价对象和观点词之间的联系,并同时考虑了局部和全局的记忆进行评价对象抽取。为了更加关注句子中重要的词,Li等[11]提出将之前时刻的评价对象预测的信息结合到当前时刻的评价对象中,生成有历史信息的评价对象。Wang等[12]提出耦合多层注意力模型,挖掘评价对象之间间接的关联,从而得到更精准的评价对象信息。Ma等[13]设计了门控单元网络,将对应的单词表示纳入解码器,使用位置感知注意力,更加关注目标单词的相邻单词。He等[14]和Luo等[15]提出使用注意力机制的自动编码器进行评价对象抽取,并在各个数据集上取得了较好的性能。近期,Tulkens等[16]提出了一种新的注意力机制,可以从句子中获取更多相关信息。为了解决缺少大量标注数据的问题,Li等[17]提出一种新的数据增强方法,将数据增强看作一个条件增强任务,生成句子的同时对齐原始的标签序列,同时能够保留原始的评价对象不变,进行评价对象抽取。由于字符级信息对于中文文本的序列标注任务较为重要,所以Li等[9]提出使用字符级信息提升评价对象抽取模型的性能。
从上述研究工作来看,基于深度学习的模型对于评价对象抽取任务是有效的,但是对于涉案微博这类特定数据而言,有其自身的领域特性。因此,本文提出基于关键词结构编码的涉案微博评价对象抽取方法。
2 本文方法
本文提出的评价对象抽取模型使用B(begin)、I(inside)和O(other)进行字符级别的标签标注。其中,B代表评价对象的起始位置,I代表评价对象内部,O代表不是评价对象。数据标注示例如表2所示。

表2 数据标注示例Table 2 Data annotation example
本文模型的基本结构分为评论编码层、关键词编码层、信息融合层和评价对象抽取层4部分,如图1所示。其中,评论编码层将微博评论句的字符嵌入和词嵌入送入BiLSTM进行编码,并将得到的编码表示进行拼接,输入双层高速网络[19];关键词编码层将案件关键词嵌入送入BiLSTM编码,然后通过结构编码机制进一步提取结构编码表征;信息融合层通过交互注意力机制将评论句子表征和案件关键词结构表征进行融合;评价对象抽取层将最终的特征表示送入CRF,抽取评价对象词项。

图1 涉案微博的评价对象抽取示意图Fig.1 Schematic diagram of evaluation object extraction of the case-involved microblog
2.1 评论编码层
由于涉案微博评论的主观性和表达方式的自由性,其评价对象可能会出现多字少字的情况,造成分词结果不准确。因此本文按照字符粒度对评论数据集进行标注,并且同时使用字符嵌入和词嵌入作为评论的初始表示。给定一个微博评论句子,字符序列和词序列按照字符长度进行对齐。即对于每个字符,都为其分配包含该字符的词。字符向量序列和词向量序列分别表示为和,其中t表示句子中字符的总个数表示句子中第j个位置的字符表示第j个位置的字符对应的词。将词嵌入和字符嵌入分别输入Bi LSTM进行编码,并将编码得到的隐表示Hc∈R2d×t和Hw∈R2d×t进行拼接得到表示Hcw∈R4d×t,具体如下

式中:⊕表示拼接操作;d表示嵌入维度。
然后将其输入双层高速网络[19],以此平衡字符向量和词向量的贡献比,得到具有上下文语义特征的评论多层次向量表示K∈R2d×t。
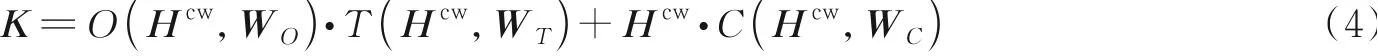
式中:O表示非线性函数;T表示转换门;C表示携带门;WO、WT和WC为权重矩阵。
2.2 关键词编码层
本文使用TextRank分别从两个案件的微博正文中抽取案件关键词。给定一个评论句对应的一组案件关键词,其词向量序列表示为U={u1,u2,…,uf},其中f表示关键词的总个数。将其送入BiLSTM,得到具有上下文语义特征的案件关键词向量表示L∈R2d×f。

本文使用结构编码操作将具有上下文语义特征的案件关键词的向量表示L∈R2d×f转化为结构化表示H∈R2d×r,具体如下

式中:A∈Rr×f为权重矩阵;W1和W2为可训练的参数;r为超参数,表示L∈R2d×f转换为结构化表示的结构数量。
因为权重矩阵A∈Rr×f容易面临过度平滑的问题,即权重矩阵中的值趋于相似。为了让权重矩阵中的值更加具有区分性,本文引入了惩罚项。具体而言,受Lin等[18]的启发,本文使用惩罚项Z作为损失函数中的一部分来保证H中结构化表示的多样性。

式中:I表示单位矩阵为矩阵的Frobenius范数。
2.3 信息融合层
将具有上下文语义特征的评论多层次向量表示K={k1,k2,…,kt}∈R2d×t与关键词编码层得到的结构化表示H={h1,h2,…,hr}∈R2d×r做交互注意力,由此得到的关键词表征M∈R2d×t用来表示评论句,具体操作如下。
如图2所示的交互注意力机制,对结构化表示H={h1,h2,…,hr}∈R2d×r中的每一个特征表示进行加权求和,由此得到信息交互的关键词表征。

图2 交互注意力机制Fig.2 Cross attention mechanism

式中注意力权重αj,i用相应 的匹配分 数sj,i通过softmax函 数计算得 到,sj,i通过特征 向量kj和hi的双线性乘积计算得到

式中W和b为可训练的参数。
将上述融合之后的信息M∈R2d×t与评论句子字符嵌入通过Bi-LSTM得到的隐表示Hc∈R2d×t进行点乘,再和评论句子词嵌入通过BiLSTM得到的隐表示Hw∈R2d×t进行简单拼接,得到最终的表征G∈R2d×t。
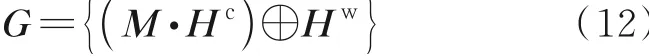
式中“·”表示按位相乘。该表征既融合了关键词信息,又保留了原有的评论句字符级信息和词级信息在时序上的上下文依赖关系。
2.4 评价对象抽取层
将G={g1,g2,…,gt}通过一个线性层后,得到表示G',其中G'i,j是序列中第i个字符的标签j的得分。设输入序列为x={x1,x2,…,xt},标签序列为y={y1,y2,…,yt},标签预测的分数为

式中:Q为转移分数矩阵;Qi,j表示从标签i转移到标签j的分数。对所有可能的标签序列的得分应用softmax函数,从而得到给定输入x的条件下标签序列y的概率P(y|x)。本文使用负对数似然函数作为损失函数,最后通过维特比算法得到条件概率最大的输出序列。

式中Zi表示第i个训练实例的惩罚项,见式(8)。
3 实验与分析
3.1 实验数据集
本文构建了两个涉案微博数据集,并对其评价对象进行人工标注,分别为“奔驰女司机维权案”与“重庆公交车坠江案”,具体如表3所示。

表3 涉案微博评价对象抽取数据集Table 3 Data sets of cased-involved Microblog evaluation objects
考虑到涉案微博评论数据的复杂性,本文对其进行了如下预处理:首先,去掉涉案微博评论数据集中重复的数据;其次,删除评论中出现的超链接广告,同时删除其中类似“@+用户名”的噪声数据;然后,如果评论中出现某些标点符号连续重复,比如“。。。”“!!!”等,使用首位标点符号将其替换,同时删除评论中出现的表情符号;最后,为了确保涉案微博评论的完整性,删除其中字符数少于7的评论。
3.2 评价指标
本文的评价指标使用的是精确率(P)、召回率(R)、F1值,计算公式分别为

式中:TP表示正例被正确判定为正例;FP表示负例被错误判定为正例;FN表示正例被错误判定为负例。
3.3 模型参数设置
本文实验所使用的预训练词向量①https://github.com/LeeSureman/Flat-Lattice-Transformer是基于CTB 6.0(Chinese Treebank 6.0)语料库训练得到,字符嵌入②https://github.com/LeeSureman/Flat-Lattice-Transformer是基于大规模标准分词后的中文语料库Gigaword训练得到,嵌入维度均为50。通过实验比较,选择关键词个数为20。
实验使用随机梯度下降算法(SGD)优化参数,dropout的大小设置为0.4,学习率设置为0.012,L2设置为1e-8。
3.4 基准模型对比实验
为了验证本文模型的有效性,分别与CRF、LSTM-CRF、BiLSTM-CRF、BiLSTM-CNN-CRF、Seq2Seq4ATE和BERT-CRF六个基准模型进行了对比实验。基准模型介绍如下。
(1)CRF[8]:该方法是解决序列标注问题用得最多的方法之一,通过学习观察序列来预测标签序列。
(2)LSTM-CRF[20]:该方法也是序列标注问题中常用的方法,使用LSTM解决了远距离依赖问题。
(3)BiLSTM-CRF[20]:该模型使用BiLSTM从两个方向编码信息,来更好地捕获上下文信息,同时使用CRF向最终的预测标签添加约束。
(4)BiLSTM-CNN-CRF[21]:该模型结合了BiLSTM和CRF的优势,同时又融合了CNN抽取局部特征,进行评价对象抽取。
(5)Seq2Seq4ATE[13]:该模型使用门控单元控制编码器和解码器产生的隐状态,并通过位置感知注意关注目标词的相邻词。
(6)BERT-CRF[22]:该方法将评论句输入预训练BERT模型,得到的表示送入CRF,抽取评价对象词项。
为了保证比较的公平性,本文实验将上述模型的学习率、dropout、批次等参数设置为与本文模型一致,LSTM的隐层向量大小设置为100,CNN卷积核的尺寸设置为(2,3,4)。BERT-CRF实验中使用的BERT预训练语言模型为Google发布的BERT-Base(Chinese)模型。实验分别在两个数据集上进行,表4给出了对比实验的结果。通过表4可以看出,相较其他模型而言,基于传统机器学习的CRF模型的性能都是最低的,在两个数据集上的F1值分别只有56.14%和45.81%,这是由于CRF模型需要定义大量的特征函数,根据自定义的语言特征模板进行评价对象抽取,并没有抽取相应的语义特征。与CRF模型相比,LSTM-CRF、BiLSTM-CRF和BiLSTM-CNNCRF模 型 利用LSTM对 评论信息进行了抽取,因此性能获得了提升。其中,BiLSTMCRF模 型 相 较LSTM-CRF模型性能提升明显,这是由于BiLSTM是从前后两个方向编码信息,能够更好地捕获双向语义依赖关系,可以提取到某些很重要词的完整特征,而单向的LSTM只能捕获到单向的词序列信息。融合了CNN模型之后,F1值又有所提升,说明CNN可以很好地捕获局部特征。与基于有CRF解码器的模型相比,Seq2Seq4ATE模型在性能上有进一步的提升,这是由于门控单元可以在解码当前词的标签时自动集成来自编码器和解码器隐藏状态的信息,同时位置感知模块可以迫使解码器在对标签进行解码时更加注意当前单词的邻近词。在基准模型中,基于预训练BERT的BERT-CRF模型的P、R、F1值都是最高的,这是由于BERT包含了很多预训练语料中蕴含的外部知识和语义信息。在两个数据集上,本文模型的P、R、F1值对比所有基准模型均有所提高,验证了本文模型抽取涉案微博评论的评价对象的有效性。

表4 基准模型对比实验结果Table 4 Comparison of experimental results of baseline models %
3.5 消融实验
为了验证本文模型中结构编码机制和案件关键词信息的有效性,针对“奔驰女司机维权案”数据集进行了消融实验。
第1个消融模型是“(-)案件关键词”,表示去掉模型中的关键词编码层和信息融合层,仅仅是对微博评论句子进行编码,将得到的多层次向量表示K送入CRF抽取评价对象词项。
第2个消融模型是“(-)结构编码”,表示去掉结构编码机制,仅仅将具有上下文语义特征的案件关键词的向量表示L与评论句子的多层次向量表示K做交互注意力,后续操作与主模型保持一致。两个消融模型的实验结果如表5所示。通过表5的实验结果可以看出,当没有融入案件关键词时,模型的P、R、F1值均大幅下降,说明案件关键词的融入可以很好地指导模型学习涉案微博领域的特征,进而抽取评价对象词项。当没有使用结构编码机制时,模型的F1值降低了1.34%,P值降低了3.79%,R值反而升高了0.67%,可以看出结构编码机制以牺牲一部分召回率换取了评价对象抽取精确率大的提升,说明结构编码机制可以有效帮助模型综合利用各个案件关键词的信息,对模型的指导作用更准确。

表5 消融实验结果对比Table 5 Comparison of ablation experiment results %
3.6 案件关键词数量的影响
本文针对两个数据集分别采用不同数量的案件关键词进行了实验,实验结果如图3所示。通过图3的实验结果可以看出,当案件关键词数量采用20和30时,性能相对较好。特别是当关键词数个数为20时,模型在两个数据集上的F1值都是最高的。说明当关键词数量过少时,其信息量不足,无法充分指导模型学习涉案微博领域的特征,而当关键词数量过多时,可能会引入噪声数据,让模型学习到错误的信息,导致模型性能下降。

图3 设置不同关键词数量的F1值对比Fig.3 Comparison of F1 values of different numbers of keywords
3.7 案件关键词质量的影响
为了探究案件关键词质量对模型的影响,本文分别采用TextRank和TF-IDF两种关键词提取方法进行了实验。由于上述实验结果证明,抽取20个关键词融入模型的效果最好,所以从“奔驰女司机维权案”数据集的正文中利用两种方法分别抽取20个关键词,抽取结果如表6所示。通过表6可以看出,TextRank抽取到的关键词信息与正文中所提及的案件核心要素更相关,而TF-IDF会抽取到一些高频的噪声词,比如“热议、称有”等。

表6 不同工具抽取到的案件关键词Table 6 Case keywords extracted by different tools
将表6得到的不同质量的关键词融入模型进行实验,实验结果如表7所示。表7的实验结果证明了使用TextRank抽取关键词的效果要优于TF-IDF。原因可能是通过TF-IDF抽取到的关键词包含很多与评价对象无关的噪声词,这些词并不构成网友评论的评价对象,影响了模型的性能。

表7 不同质量关键词的实验结果对比Table 7 Comparison of experimental results of different quality keywords %
4 结束语
本文提出了一种基于关键词结构编码的涉案微博评价对象抽取方法。该方法通过结构编码机制综合利用微博正文的案件关键词信息,并通过交互注意力机制将其融入评论句子表示,来指导评价对象的抽取。在两个数据集上的实验结果证明了本文所提方法在涉案微博评价对象抽取方面的有效性。所提出的结构编码机制使模型能够更准确地抽取评价对象词项,且使用TextRank抽取一定数量的关键词融入模型能够得到最好的性能。未来的研究工作考虑融入其他涉案领域外部知识来改善评价对象抽取的结果。
猜你喜欢
小学生学习指导(中年级)(2021年12期)2021-12-30
廉政瞭望·下半月(2021年5期)2021-07-20
汉字汉语研究(2020年2期)2020-08-13
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
疯狂英语·新读写(2018年3期)2018-11-29
意林(2018年3期)2018-03-02
