
基于三部图的学习资源个性化推荐算法研究
2022-10-13 06:15闵磊
科技资讯 2022年20期
闵磊
(江汉大学图书馆 湖北武汉 430056)
随着文献资源数字化以及互联网技术的飞速发展,各类学习资源也逐渐从纸质走向电子,且规模也在以前所未有的速度增长。这些海量的数字化资源为广大师生在学习材料的获取方面提供便利,但过大的规模也容易使其陷入“信息爆炸”的迷惘之中[1]。
超大的资源规模,往往会使人们真正感兴趣的内容被淹没在数字的海洋中。那么如何采用一种智能的方法,准确且便捷地挖掘出用户真正感兴趣的资源,就成为了一项亟待解决的问题。这种根据用户的兴趣向其推荐资源的方法,就是个性化推荐技术。
目前,关于个性化推荐技术,学者已经提出了一些实用的算法。比较典型的算法包括基于内容的推荐算法、基于协同过滤机制的推荐算法[2],以及近年来受到较多关注的基于网络结构的推荐算法[3-4]等。其中,基于内容的推荐算法对资源的文本描述进行自然语言分析,提取特征属性,然后向用户推荐特征属性相近的资源[5],这类算法可以克服“冷启动”,但对资源要求较高,需要有足够的属性描述;基于协同过滤机制的算法,则利用不同用户对资源的历史选择信息,以协同的方式共同过滤出相近偏好的资源进行推荐,这类算法无需资源的描述信息,仅需要用户的历史选择数据,但存在“冷启动”问题[6]。基于网络结构的推荐算法,则将用户和资源视为二部图的两类节点,然后以物质或热量扩散的方式将信息进行扩散,最后以节点上信息的多少来确定推荐列表。
相较于其他算法,基于网络结构的推荐算法思想简洁有效性较强,是一类较有发展前景的技术。该文结合学习资源的标签信息,对基于二部图的网络推荐算法进行扩展,探讨了一种基于标签的三部图学习资源个性化推荐算法。
1 二部图个性化推荐机制
1.1 基于学习资源选择关系的二部图
对线上的学习活动而言,学习资源与学习者可以被抽象为两类性质不同的节点。学习者的学习过程,相应地可以被视为学习者所代表的节点与学习资源所代表节点的一次选择关系。这种众多成对出现的交互关系组合在一起,就构成了二部图网络。在二部图网络中,同类节点之间彼此互不相连,连边仅出现在不同类别的节点之间,连边的密集程度就蕴含了学习者对于学习资源的偏好程度。在二部图网络中,对学习者推荐其可能感兴趣的学习资源,就是依据已有的网络结构信息,对未相连的两类节点之间的可能连边进行预测。
如图1所示,左侧节点A、B、C代表学习者,他们处于学习者层;右侧节点D、E、F、G 代表学习资源,他们处于学习资源层;连边体现了学习者对于学习资源的偏好性即选择关系,也就体现着两层之间的关系。在图中,节点A和节点G之间原本不相连,也就是学习者A 尚未选择过学习资源G。如果能够通过已有的历史选择信息,预测出A节点和G节点之间可能存在连边,那么就可以向节点A(学习者A)推荐G节点(学习资源G),从而实现个性化推荐的目的。
1.2 基于二部图的信息扩散推荐机制
在由学习者与学习资源构成的二部图网络中,可以假设存在这样的事实:即某个学习资源之所以会被学习者选择,是因为其内在所蕴含的知识与这类学习者的兴趣特征相匹配,而学习者通常比较倾向于接受具有相似兴趣学习者的推荐。因此,具有相似兴趣学习者的历史选择,就可以根据一定的评估规则作为备选项推荐给相应的学习者。
基于上述假设,可以结合图1 对基于二部图的信息扩散推荐机制进行描述。假设图中的A 节点,代表我们希望向其推荐资源的学习者。初始时,对于与节点A相连接的所有节点(右侧的学习资源)都赋予一个单元的信息量,即D、E 节点上的信息量为1。然后这两个节点以连边为传播路径,向相邻节点(左侧代表学习者的节点)传播信息,这一过程为第一阶段传播,此阶段过后学习者节点上会累积一定量的信息。而这些学习者节点(排除A 节点)上信息量的多少,反映出了他们与A 学习者曾经选择过相同学习资源的度量,这在一定程度上可以体现他们与A 学习者兴趣的相似性。
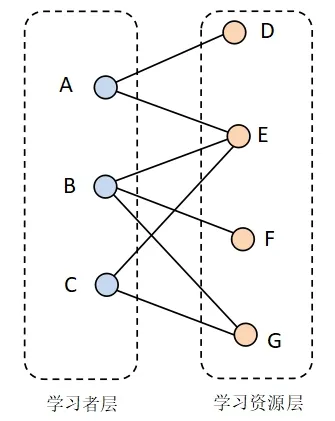
图1 二部图网络示意图
通常情况下,人们更倾向于接受与自己兴趣相似者的建议。因此,如果某些学习资源是其他相似兴趣学习者选择过但A 学习者尚未选择过的,那么将适合将其推荐给A。而这些学习者与A学习者的兴趣相似性,可以由第一传播阶段结束时他们所代表节点上的信息量多少来体现。因此,直接将这些节点上的信息,以相应的量额传播到代表学习资源的另一侧,就等效于将他们曾经选择过的学习资源赋予相应的推荐可性度。最后对右侧的学习资源节点,根据其所获取信息量的多少进行排序,然后排除掉学习者原本已选择过的节点,排序靠前的节点就可以作为可性度高的节点推荐给学习者A。
以图1为例,在整个二部图的信息扩散过程中,各阶段的数据描述如下。
在初始阶段:因为D和E节点与A节点相连接,所以D、E节点上的信息量被置为单位1。而F、G节点并未直接与A相连接,因此他们上的信息量为0。
在第一传播阶段:该阶段中,信息从右侧代表学习资源的节点传播到左侧代表学习者的节点,该过程结束时,A、B、C 这3 个节点上的信息量分别为4/3、1/3、1/3。
在第二传播阶段:该阶段中,信息从左侧代表学习者的节点传播到右侧代表学习资源的节点,该过程结束时,D、E、F、G 节点上信息量分别为2/3、17/18、1/9、5/18。排除掉学习者A 原本就已经选择过的资源D 和E,G 节点上的信息量最大,因此如果需要为学习者A推荐一个最合适的资源,那么就是G资源节点。
2 基于标签的三部图学习资源个性化推荐算法
2.1 融合学习资源标签的三部图
前述基于二部图网络的信息扩散推荐算法,可以较为有效地为学习者进行个性化学习资源推荐,并且思路简洁、过程简单、适合于高数据量并行计算。但与协同过滤算法类似,该算法在一定程度上存在“冷启动”问题。对于希望接收推荐的学习者,如果其选择过的资源没有或者较少地被其他学习者选择,则二部图推荐算法中的第二传播过程将会受到影响。特别是当被推荐者的历史选择资源为冷门资源时,这种情况更为突出。也就是说,如果二部图网络的连边较为稀疏,将可能会影响到推荐项目的有效性。
通过对二部图网络的推荐过程进行分析可知,为了能在一定程度上缓解网络稀疏所带来的问题,一种可行的方法是增加初始传播阶段结束时具备信息节点的数量,也就是增加被推荐者历史选择资源的影响面。假如该类节点数量较为丰富,那么通过第一阶段的信息传播,能够找到具有相似兴趣学习者的概率就较大,从而使最终涵盖的备选推荐资源就更为丰富。对该假设,最为关键的就是增加初始信息传播节点的数量。很明显,通过已有的选择关系(即连边)无法解决,因为缺少的就是这种连边信息。不过结合目前互联网上的数据特点,可以从“标签”信息着手。
与互联网上的其他资源类似,相当多的在线学习资源通常也具有一定的标签信息。例如:对某个关于勾股定理的学习材料,可能的标签就会有“勾股定理””或“几何”;对有关惯性的物理学科资源,可能的标签就会有“牛顿定理”或“惯性”。这些为资源打上的标签,可以理解为以一种简洁的方式对资源的类别或者属性进行的描述。而具有相似类别或属性的资源,也更可能会被标注上相似或者相同的标签。如果从标签信息进行扩展,那么即便对某个仅被选择过一次的学习资源,也能够通过其对应的标签扩展到其他资源。而这种扩展过程并不需要通过其他学习者的“选择过程”来协同地实现,这也就缓解了连边稀疏所带来的问题。
根据以上思想,可以将传统的二部图网络进行扩展,加入一个标签层形成一个三部图网络结构。如图2所示,从左向右分别是三部图网络的学习者层、学习资源层以及标签层。如果一个学习资源具备某个标签,则该资源节点就与标签层中对应的节点产生连边关系。由于标签是对学习资源地一种标注,因此标签节点仅与学习资源节点产生连接关系。在该网络中,标签层及其与学习资源层连边的作用,主要是对学习者选择过节点的覆盖面进行扩充。从本质上而言,这种通过“标签”对节点覆盖面的扩展,是一种间接的扩展,它虽然不能直接体现被推荐者的历史选择情况,但是却可以从侧面依据被推荐者的兴趣增大初始关注资源的范围。
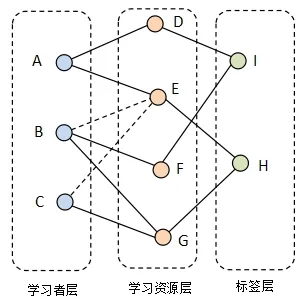
图2 三部图网络示意图
2.2 基于标签的三部图推荐算法
融合标签信息构建出三部图网络后,可以对二部图信息扩散推荐算法进行改进,形成基于标签的三部图推荐算法。对于该算法而言,左侧学习者节点与学习资源节点之间的信息传播过程与二部图推荐算法相同。其改进之处主要在于,在正式进行信息扩散前,加入了一个初始信息预分配过程。
在图2 的示例中,依然假设A 节点为希望向其推荐资源的学习者节点。并且,为了体现标签对资源的扩展作用,示例图中删除了E节点(代表学习者A曾经选择过的学习资源节点)与其他节点的连边,使网络变得更为稀疏(图2中删除的边用虚线表示)。
对改进后的算法,由于其对学习者节点与学习资源节点之间的信息传播过程未做本质改变,因此该文主要对初始信息预分配过程进行描述。
初始信息预分配过程包含两部分,具体叙述如下。
第一,为学习者A 节点所选择过的学习资源分配初始信息,也就是对于与A 节点相连的资源节点均赋予单位信息量1。在图示中即对D、E 节点赋予信息量1。
第二,通过标签信息对学习资源层中节点的信息量进行扩展,该过程本质上是在学习资源层与标签层之间加入了一个局部的信息扩散过程。对于第一部分中获得信息的节点,使其承载的信息,能够通过标签节点(该过程中标签节点作为中间过渡)传播到其他资源节点上去。
图2中,假设E 节点和G节点的标签相同(即他们都与标签层中的H节点相连接)、D节点和F节点的标签相同(即他们都与标签层中的I节点相连接)。以资源节点E上的单位信息量为初始信息,沿着标签连边进行扩散。此阶段结束后,节点G上的的信息量为1/2;同理,节点F上的信息量也为1/2。然后标签节点上的信息反向传播到学习资源节点上,此阶段中信息将会传播到其他相关节点上,即起到了初始信息扩展的目的。
完成初始信息预分配过程后,后续的信息传播过程就仅限定在学习者节点层与学习资源节点层之间,也就是与经典的二部图信息传播算法相同。完成整个传播过程后,学习资源节点上的信息量构成的向量为[3/2,3/2,3/8,5/8],排除掉A学习者已经选择的节点,剩余节点中信息量最大的是G 节点,即G 可以作为需要推荐的资源节点。
从示例中可以看出,D、E 节点并未与除A 节点之外的其他学习者节点相连。那么如果不加入标签层进行信息扩展,那么D、E 节点上的信息量将不可能传播到其他节点上去,也就无法实现推荐其他资源的目的。但通过“标签”三部图改进后的算法可以对信息传播的过程进行强化,进而增加最终可推荐资源节点的数量,这也体现了本算法在缓解稀疏网络所存在问题方面所起的作用。
2.3 影响算法有效性的因素及应对策略
上述基于三部图的个性化推荐算法,通过引入“标签”信息,将经典的二部图信息扩散推荐算法进行了改进。该算法的一个特点是对获得初始信息节点的广度进行了扩展,可以缓解常规推荐算法在稀疏网络上所存在的问题。因此,所扩展信息的合理性,在很大程度上决定了算法的有效性。
由算法的原理可知,标签信息是否准确直接决定了初始信息节点的选择是否准确。由于互联网的开放性,网络上学习资源的标签也一般由用户或资源浏览者自行标注,因此存在多样性以及标准不唯一的特点,这在很大程度上会影响该文算法的有效性。
为了尽可能地保障算法的有效性,可以构建一个标签数据库,该数据库提前收集整理好常见标签,并预设好各种标签可能的同义词或近义词等关系。基于该标签数据库,对学习资源上的标签数据进行预处理,剔除错误标签、规范不合理标签以及融合同义词标签。在进行融合同义词标签操作时,可以根据同义词进行归并性融合。如果是近义词标签,则可以在标签之间构建连边,连边的权值可参考近义词的相似度值来设定。
3 学习资源个性化推荐算法的应用场景分析
学习资源是在线学习的基础性物质条件,基于个性化的学习资源推荐技术则可以衍生出丰富的教育学应用。
目前,自主学习和终生学习成为一种必然趋势,这种学习形式与传统学历教育的区别在于它不适合采用统一的课堂教学形式,更多的是应用在线学习的方式,并且每个学习者的基础和需求都不尽相同。对每个学习者而言,网络上海量的学习资源大概率包含他们所需要的内容,真正困难的不是缺乏资源而是如何准确地找到合适的资源,而这正是学习资源个性化推荐算法适合解决的问题。利用学习资源个性化推荐技术,学习者就能获取到自己感兴趣的资料。
另外,随着学习过程的深入,学习者的兴趣会逐渐发生改变,相应的所推荐的资源也会发生变化。如果在学习系统中对这种所推荐资源的变迁进行跟踪,就可以勾勒出学习者的学习路径。如果结合学习效果,就可以抽取出成功学习者的学习路径。很明显,成功者的学习路径是一种珍贵的资源,可以将其作为参考指导处于迷茫状态的其他学习者,使其更快地进入正确的学习路径中来,不至于陷入学习误区。
4 结语
面对互联网上海量的学习资源,如何为学习者提供一种个性化推荐方法,使其能准确、快速地找到符合其兴趣的内容,是开展个性化学习的基础性条件。该文对数字化学习资源上的标签信息加以利用,结合二部图网络信息扩散推荐算法特点,探讨了一种融合标签信息的三部图个性化推荐算法。该算法通过标签信息,将被推荐者的历史选择信息进行扩展,为缓解推荐算法中的数据稀疏问题提供了一种思路。基于这种个性化推荐技术,既可以为学习者检索资源提供便利,也可以在学习路径规划、自主学习引导等上层个性化学习应用提供基础性技术支持。
猜你喜欢
导航定位学报(2022年4期)2022-08-15
房地产导刊(2022年1期)2022-02-28
现代电子技术(2022年4期)2022-02-21
智能计算机与应用(2021年4期)2021-06-05
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
海峡姐妹(2018年3期)2018-05-09
成才之路(2016年18期)2016-07-08
Coco薇(2015年11期)2015-11-09
试题与研究·教学论坛(2015年5期)2015-09-02
少儿科学周刊·少年版(2015年2期)2015-07-07
