
数据挖掘算法在大学图书借阅大数据中的分析与应用
2022-10-12 12:41曹流,韦相,王晶
红河学院学报 2022年5期
曹 流,韦 相,王 晶
(1.中国石油大学地球科学学院大数据研究所,北京 102200;2.红河学院工学院,云南蒙自 661199)
1.图书馆用户聚类
1.1 聚类指标
聚类分析是通过计算样本的距离并按照某种标准将样本划分成若干不相交的子集。大多数的聚类算法都需要事先确定聚类数。然而,目前常用的一些聚类有效性指标都存在着一定缺陷,对图书馆用户进行聚类研究时应使用何种聚类指标、如何确定最佳聚类数也尚无确切方法。
文章引用聚类有效性指标——G A 指标(Generalization Ability),该指标可以对当前聚类结果的泛化能力进行评价来判断聚类结果的优劣,计算流程如图1所示[1]。借用GA指数计算结果来确定图书馆用户最佳聚类数是一种可行的有效方法,计算过程及结果如图2所示。
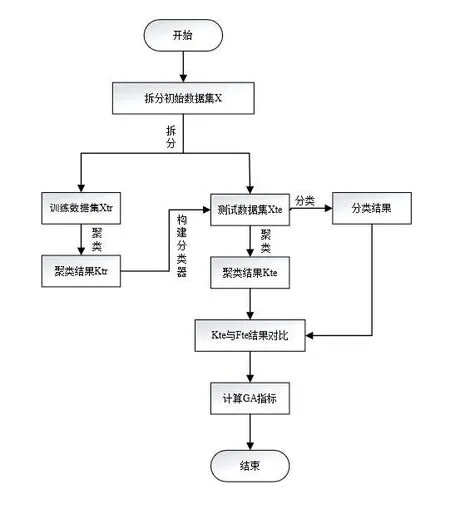
图1 GA指标计算流程图
1.2 用户聚类
由图2可知,图书馆借阅用户聚类时的最佳聚类数为3。采用基于欧式距离的K-means聚类,以借阅次数为聚类中心,将借阅用户分为了三类(惰性用户、一般用户、活跃用户),如表1所示。
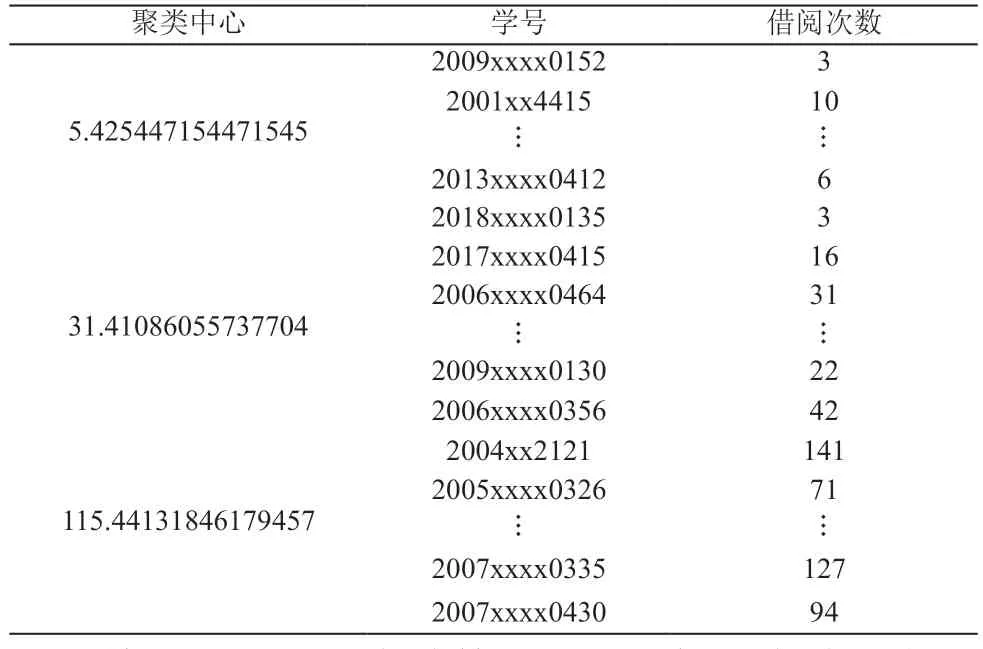
表1 用户聚类示意表
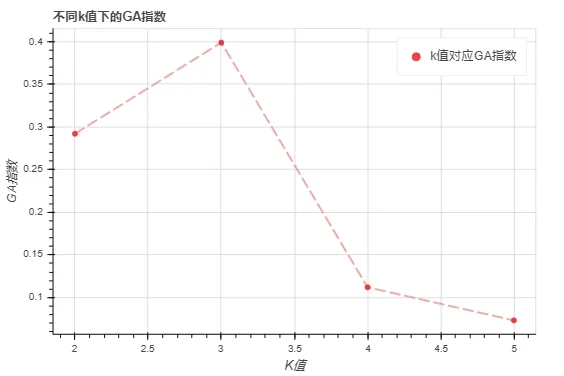
图2 不同K值下的GA指数图
分析发现,对于惰性用户,在大学四年里总共借书5.425 本,每年平均借书约1.35 本;对于一般用户,四年共借书31.41 本,每年平均借书约8 本;而对于活跃用户,四年共借书115.441 本,每年平均借书约28.86 本。
经过分析,不同类别用户数量的分布情况和分类比例可以看出,惰性用户占多数,达到42%,活跃用户占比最少,占21%,三类用户占比约是4:4:2,符合二八定律。
综上所述,图书馆管理层可根据图书馆用户活跃程度的差异,分析这三类用户不同的个性化阅读需求,提出相应的个性化策略,提高图书馆藏利用率。例如,每当购进新书时,可以通过信息推送的方式将新到图书推荐给图书馆的活跃用户以提升馆藏利用率;又或者,针对图书馆活跃用户的个性化需求,以信息推送、问卷调查等形式与活跃群体保持联系,获取不同方面的信息反馈以改进图书馆服务、图书购买计划等。
2.关联规则在图书馆藏书关联性中的应用
关联规则是指支持度和置信度分别满足给定阈值的规则。支持度是指同时包含A和B的事务占所有事务的比例;置信度表示包含A的事务中同时包含B事务的比例,即同时包含A和B的事务占包含A事务的比例。
该算法用于超市订单分析时,能够确定顾客在一次购物中可能一起购买的商品,挖掘不同商品之间的联系、顾客购买行为之间的关联。因此可以认为关联规则能够分析图书馆被借阅图书之间的关联性[2],引导图书摆放、图书购置等工作,提高图书借用率。
依照中国图书分类号,设定支持度阈值为0.05对表2所示项集进行第一次筛选。
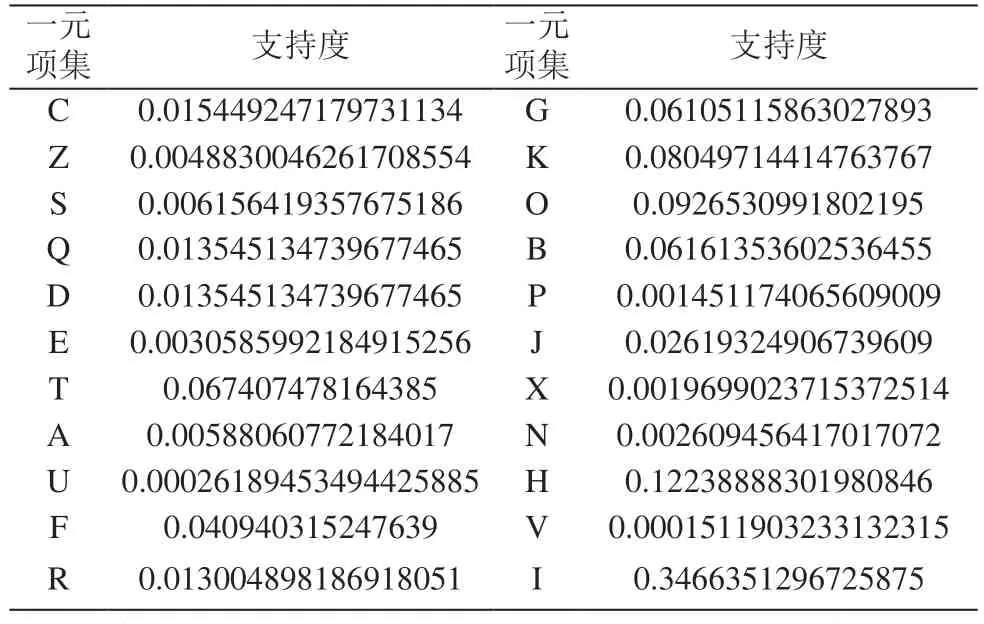
表2 一元项集支持度
由表2得到一元频繁项集结果:['T','G','K','O','B','H','I']。
再对一元项集进行排列组合,得到二元项集,如表3所示:
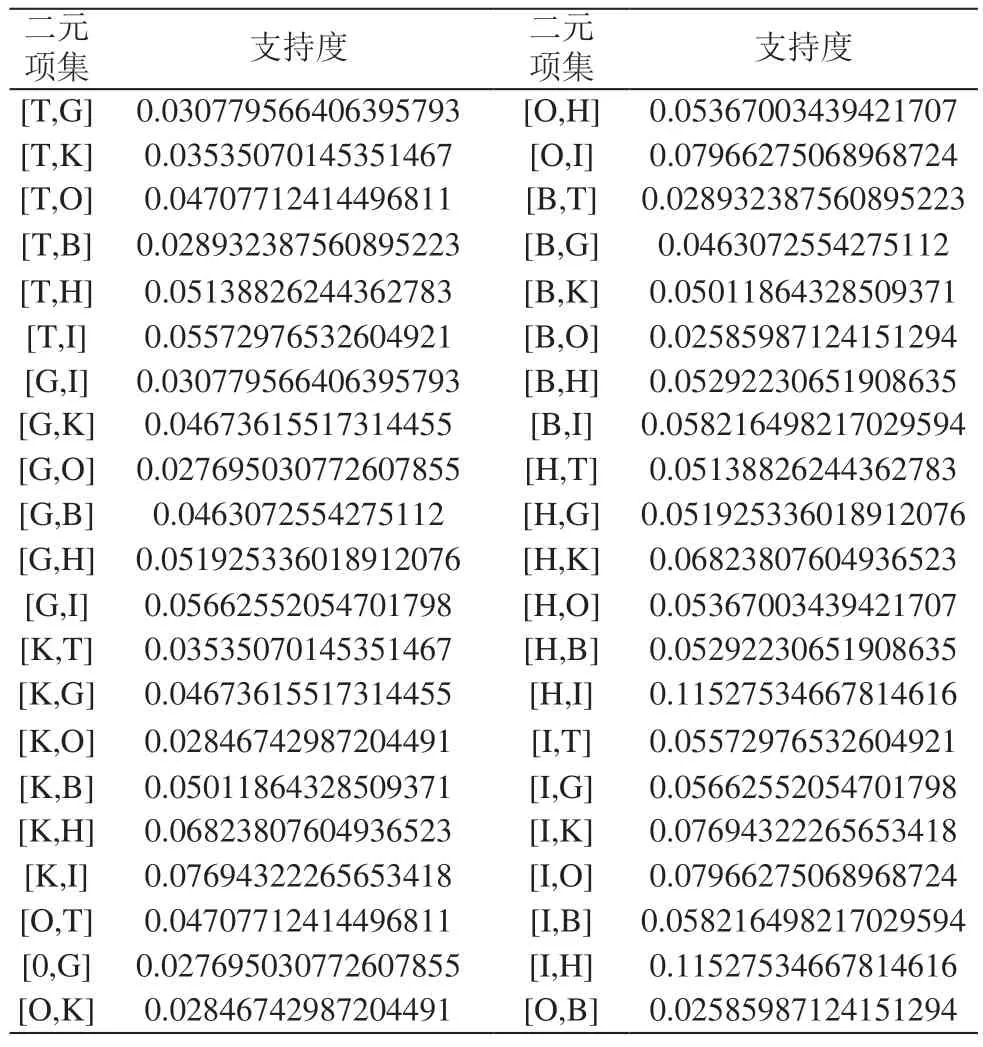
表3 二元项集支持度
再设定二元项集支持度阈值为0.05,对表4项集进行筛选,得到二元频繁项集,形成了关联规则:[['T','H'],['T','I'],['G','H'],['G','I'],['K','B'],['K','H'],['K','I'],['O','H'],['O','I'],['B','K'],['B','H'],['B','I'],['H','T'],['H','G'],['H','K'],['H','O'],['H','B'],['H','I'],['I','T'],['I','G'],['I','K'],['I','O'],['I','B'],['I','H']]。
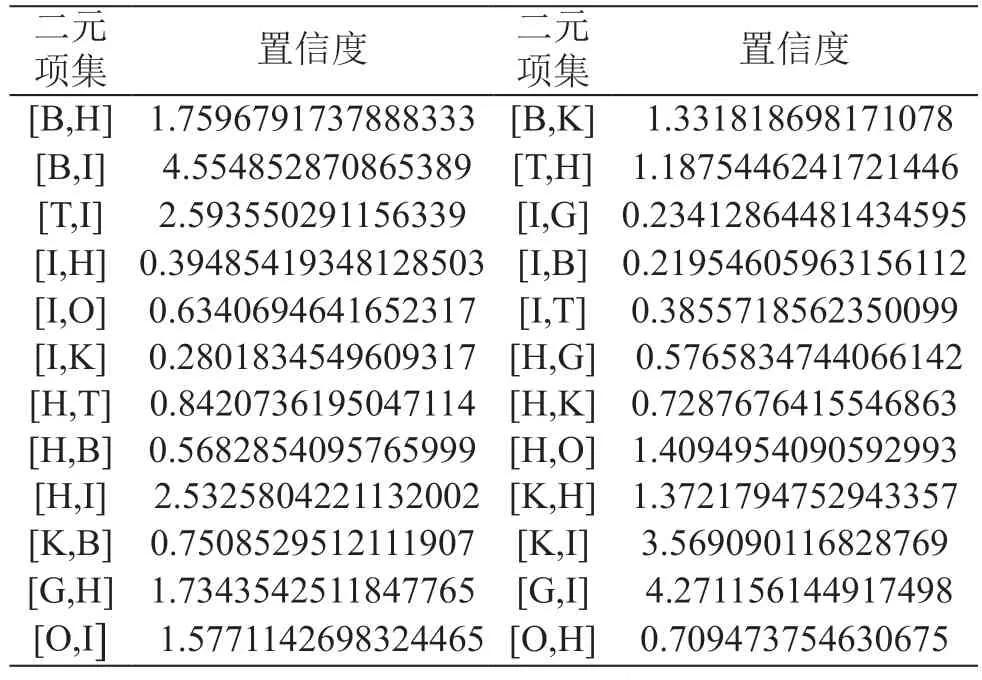
表4 二元项集置信度
根据中国图书分类号,T表示工业技术类,H表示语言文字类,I表示文学,关联规则['T','H']表示借阅了工业技术类书籍的用户,很大程度上也会借阅语言文字类书籍;关联规则['T','I']则表示借阅了工业技术类书籍的用户,很大程度上也会借阅文学类书籍。
综上所述,借助关联规则可以引导图书馆的图书排放、图书购置等工作,提高图书馆的工作效率。例如,将工业技术类书籍和语言文学类书籍摆放在同一借阅区域;或是在用户使用自助借阅系统、电子借阅系统借阅工业技术类书籍时,自动推荐语言文学类书籍以提高其他图书的借阅率。
3.图书借阅次数统计与文本分析
读者喜欢借阅哪类图书,受到什么因素的影响,一直是图书馆和出版社关注的焦点。通过对红河学院图书馆2004年到2018年,共14年所有图书借阅次数进行统计,获取历年理工类和文史类最受欢迎(被借阅次数最多)的20本书,并对这类图书进行文本分析。因表格较多,且得到的是一些共性的规律,因而主要对2004年、2006年、2008年、2010年、2012年、2014年、2016年和2018年的统计数据进行分析。这里以2004年为例:
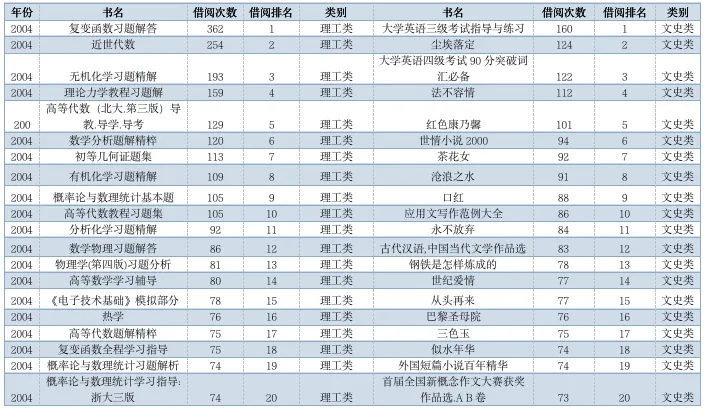
表5 2004年理工和文史类借阅次数前二十名图书
通过对2004年的借阅数据进行分析发现,对于理工类而言,学生借阅最多的数学类书籍,占20本理工类书籍的65%、其他的是物理类、计算机类和化学类相关专业平台必修课的参考书籍;对于文史类而言,借阅的书籍主要分为2类:(1)英语考试和写作类的书籍,分别是排名第1的《大学英语三级考试指导与练习》和排名第3的《大学英语四级考试90分突破词汇必备》,以及排名第10的《应用文写作范例大全》;(2)任课教师推荐的经典小说,比如排名第2的《尘埃落定》、排名第7的《茶花女》、排名第16的《巴黎圣母院》、排名第17《钢铁是怎样炼成的》和排名第19的《外国短篇小说百年精华》。对于2006年、2008年、2010年、2012年、2014年、2016年和2018年的数据统计和分析结果,详见与补充材料。
结合所有分析结果可知:该校在2006年时的借阅书籍还以网络小说为主,而从2008年开始经典名著的借阅次数便开始逐步上升。从2010年开始,国内外名著的借阅次数排名开始全面占优且一直持续到2018年。同时,从2014开始逐渐有了与教师行业相关的图书借阅记录。结合实际情况,十一五期间是我国图书馆转型发展的重要时期,业界和学界都积极响应了国家政策,大力推动我国图书馆的发展、让图书走进各级各类学校,从红河学院图书馆的借阅记录发展变化中也可见一斑。此外,也可以看出国家“多读书,读经典”的号召取得了不错的效果,读者的阅读素养在随时间变化不断提高。
图书馆和出版社可以借助该项研究,结合第1章的用户聚类结果分析不同用户群体的需求方向,扩大出版书籍的受众面,并在出版策略上更加积极的向国家政策靠拢。也可以结合第2章的关联规则算法分析高频借阅书籍的关联书籍,仔细考究高频借阅书籍与其关联书籍的摆放,提高其他书籍的借阅率。
4.时间序列分析在图书馆借阅趋势中的应用
时间序列分析研究一组真实数据在长期变化过程中存在的统计规律,通过揭示该规律来了解所要研究的动态系统,得出预测模型,解决实际问题或提高决策水平[3]。
通过一系列的数据处理和检验后,使用ARMA模型[4]对未来借阅趋势进行预测,如下所示,图6上图是2005—2018年原始借阅数据趋势图;图6下图蓝线表示2016年—2018年原始借阅数据趋势图,红线为预测值,不难看出除陡然上升的特殊数值外,其他预测值与实际值拟合较为准确。
由图3可以发现纸质书籍借阅量在2007年至2009年间达到顶峰,随后开始大致保持下跌趋势,直至2016年迅速回升,随后再次下跌。主要原因如下:
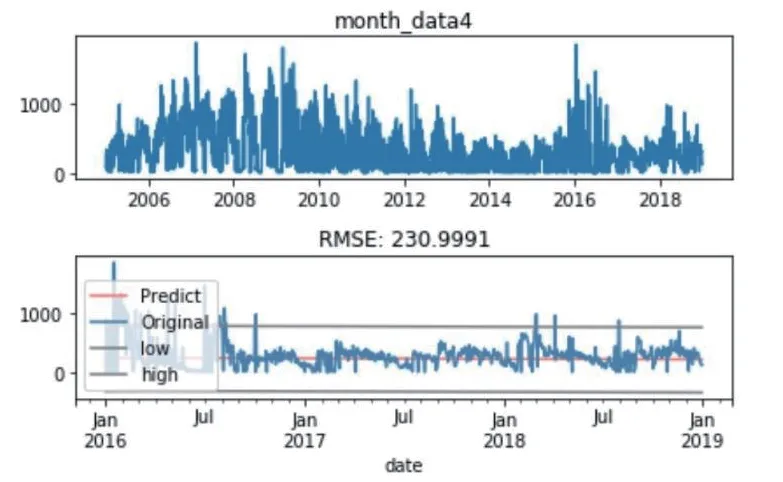
图3 借阅趋势预测模型图
(1)红河学院在2016年新建图书馆,随后借阅量陡然上升,从中可以看出一个良好、舒适的学习环境,有利于提高学生学习积极性和自觉性。
(2)而从总体趋势不难看出,纸质图书的借阅逐年降低。通过了解发现,电子图书因其便捷的获取方式,逐渐成为同学们快速获取信息的方式,因此对纸质图书的借阅带来了不可避免的冲击,导致学生纸质图书的借阅逐年降低。
综上所述,图书馆可以借助时间序列相关分析提高电子书籍的馆藏占比,结合第1章与第2章的研究内容将电子书籍以信息推送的方式推荐给活跃用户群体,提高图书借阅率;或者合理安排服务人员配置,在借阅高峰来临前安排好人员配置、清洁打扫和图书回收整理等工作,以便在人流高峰时间提供更为优质的服务。度过高峰后便可以减少人员配置、降低清洁频率等,降低人力成本和日常开支。
5.总结
对文章内容总结如下:
(1)通过基于GA指标的聚类分析算法得到了图书馆用户的最佳聚类数为3,以借书量1.35本、8本、28.86本为聚类中心将借阅用户分为了惰性、一般、活跃三类,可以结合关联规则、文本分析等算法对图书馆用户进行详细画像以支撑其他研究或图书馆决策;
(2)通过关联规则算法得到了被借阅图书之间的关联性,例如借阅了工业技术类书籍的用户,很大程度上也会借阅语言文字类书籍,该项研究可以引导图书馆的图书排放、图书购置等工作,提高图书馆的工作效率;或是在用户使用自助借阅系统、电子借阅系统借阅工业技术类书籍时,自动推荐语言文学类书籍以提高其他图书的借阅率;
(3)通过统计和文本分析发现了专业区别、教师引导及政策导向对学生图书借阅存在关键作用。可以借助该项研究,结合用户聚类结果分析不同用户群体的需求方向,扩大出版书籍的受众面,并在出版策略上更加积极的向国家政策靠拢。也可以结合关联规则算法分析高频借阅书籍的关联书籍,仔细考究高频借阅书籍与其关联书籍的摆放,提高其他书籍的借阅率;
(4)通过时间序列算法分析了该校图书馆2007年至2019年的借阅趋势变化,发现电子图书对纸质图书的冲击导致纸质图书借阅量呈现总体下降的趋势以及阅读环境对图书借阅量有着一定影响,并给出了借阅趋势变化预测和提高电子书籍馆藏占比的建议。该算法可以与聚类分析和关联规则的研究内容相结合,将电子书籍以信息推送的方式推荐给活跃用户群体,提高图书借阅率;或者合理安排服务人员配置,在借阅高峰来临前安排好人员配置、清洁打扫和图书回收整理等工作,以便在人流高峰时间提供更为优质的服务。度过高峰后便可以减少人员配置、降低清洁频率等,降低人力成本和日常开支。
以上四个结论有助于图书馆管理层或出版社从用户群体、用户需求、时间纬度等不同角度针对不同用户个性化需求,提出相应的个性化服务策略;也可以结合多个算法给予图书馆及出版社决策层以大数据支撑,准确提出图书刊印、购买计划,从而提高图书馆藏利用率和工作效率。
猜你喜欢
文化产业(2022年23期)2022-09-03
辽宁大学学报(自然科学版)(2022年1期)2022-04-26
新世纪智能(数学备考)(2021年9期)2021-11-24
阅读(高年级)(2020年10期)2020-12-14
时代英语·高二(2020年4期)2020-08-20
当代陕西(2019年15期)2019-09-02
计算机与数字工程(2018年10期)2018-10-23
学苑创造·A版(2018年11期)2018-02-01
计算机与数字工程(2017年2期)2017-03-02
读者(2017年5期)2017-02-15
