
基于特征迁移学习的提升机轴承智能故障诊断
2022-10-12 04:53潘晓博葛鲲鹏董飞
工矿自动化 2022年9期
潘晓博,葛鲲鹏,董飞
(1. 徐州工程学院 信息工程学院,江苏 徐州 221008;2. 扬州工业职业技术学院 信息工程学院,江苏 扬州 225127;3. 安徽大学 互联网学院,安徽 合肥 230039)
0 引言
矿井提升机作为连接煤矿井下与地面的关键设备,担负着提升煤炭、矸石,下放材料,升降人员和设备的重要任务,其运行状况将直接影响煤矿生产。轴承作为提升机的关键部件之一,一旦发生异常状态,可能造成重大安全生产事故,因此,研究提升机轴承故障诊断方法具有重要意义[1-4]。
近年来,许多研究者对基于人工智能的提升机轴承故障诊断方法进行了大量研究。张梅等[4]提出了一种基于模糊故障树和贝叶斯网络的矿井提升机故障诊断方法,实现了故障类型的快速识别。王保勤[5]提出了一种基于一维卷积神经网络的提升机轴承故障诊断方法,利用卷积神经网络算法对振动信号进行提取与处理,对提升机发生的故障进行分类。刘旭等[6]设计了一种基于小波包与隐马尔可夫的矿井提升机主轴故障诊断模型,实现了矿井提升机主轴故障数据特征提取,并提高了抗干扰性,实现了较高的故障诊断准确率。马辉等[7]为提高提升机轴承故障诊断精度,提出了一种基于深度神经网络的双层次故障诊断系统,该系统利用滑动窗口重叠采样技术对数据进行增强,利用自编码器减少噪声影响,实现了诊断精度的提升。虽然上述基于人工智能的提升机轴承故障诊断方法取得了一定的效果,但缺乏足量有标签故障数据用于故障诊断模型训练,未充分考虑提升机在实际工作中常处于变工况,会导致相同故障数据间存在分布差异,使故障诊断准确率下降和适应性减弱。 针对上述问题,本文在深度学习方法基础上,融合近年来逐渐被研究者关注的迁移学习方法,提出了一种基于深度迁移特征 选 取(Deep Transferable Feature Selection,DTF)与平衡分布自适应(Balance Distribution Adaptation,BDA)的提升机轴承智能故障诊断方法。首先利用深度置信网络(Deep Belief Network,DBN)[8-9]对原始故障信号进行高维深度特征提取;其次利用基于ReliefF与域间差异的迁移特征选取(Transferable Feature Selection Based on ReliefF and Differences between Domains,TFRD)方法对各特征的可迁移性进行量化评估,选取可迁移特征构建深度特征子集;然后采用BDA处理源域和目标域特征集,降低域间分布差异;最后采用源域特征集训练故障模式识别分类器,对目标域样本进行故障识别与分类。
1 提升机轴承故障诊断
1.1 故障诊断流程
基于DTF-BDA的提升机轴承智能故障诊断流程如图1所示,具体步骤如下。

图1 基于 DTF-BDA 的提升机轴承智能故障诊断流程Fig. 1 Flow of hoist bearing intelligent fault diagnosis based on deep transferable feature selection and balance distribution adaptation
(1) 对不同工况下的轴承故障信号进行时频分析,提取时域、频域统计特征,采用DBN提取深度特征。
(2) 为从高维深度特征集中选取出既有利于故障模式识别,也有利于跨域故障诊断的特征,采用TFRD方法对各深度特征进行类别区分度和域不变性量化评估。采用ReliefF算法处理各类特征数据,获得表征类别区分度的权重值;计算同一特征在不同域间的最大均值差异(Maximum Mean Discrepancy,MMD),表征其域不变性,构建一种新的特征可迁移性量化指标。
(3) 基于TFRD 方法,选取特征可迁移性大的深度特征构建特征子集,利用BDA对源域和目标域的特征子集进行分布适应,降低两者间的分布差异。
(4) 基于特征迁移学习后的源域有标签特征数据训练故障模式识别分类器,本文采用支持向量机(Support Vector Machine,SVM)作为模式识别分类器。将迁移学习后的目标域无标签特征数据输入训练好的分类器,输出故障模式分类结果。
1.2 基于DBN的深度特征提取
采用经典的DBN从时频域统计特征集中进一步挖掘深度特征。本文采用受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)和反向传播(Back Propagation,BP)网络堆叠而成的多隐含层神经网络构建深度特征提取网络,如图2所示,图中,v1,v2,v3分别为RBM1,RBM2和RBM3的输入层数据,h1,h2,h3分别为RBM1,RBM2和RBM3的隐藏层数据[9]。本文将RBM3的隐性神经元作为深度特征,构建深度特征集,用于后续的特征可迁移性量化分析和特征迁移学习。

图2 基于3层RBM构建的DBNFig. 2 Deep belief network based on three layer restricted Boltzmann machine
1.3 TFRD
虽然深度学习具有强大的隐藏特征挖掘能力,但其挖掘出来的特征并非全部都具有良好的故障模式识别和分类能力,尤其在变工况情况下,相同故障数据间存在分布差异,导致大多数基于深度学习的故障诊断模型会出现诊断效果不佳且泛化能力较弱的结果。因此,本文通过对深度特征的可迁移性进行量化分析,提出了TFRD方法,选取既有利于故障模式识别,也有利于迁移学习的深度特征,用于特征迁移学习和故障诊断模型训练。TFRD方法从特征的类别区分度和特征域不变性2个方面对深度特征的可迁移性进行量化评估。
1.3.1 特征的类别区分度量化
ReliefF算法作为经典的特征评价方法,能够根据各个特征与类别的相关性赋予特征不同的权重,实现特征类别区分度的量化[10]。在TFRD方法中,采用ReliefF算法对各深度特征数据进行处理,获取表征类别区分度的权重值。
给定包含P种特征样本源域特征集FS=,共有K种故障类别数据,其中,第p(p∈[1,P])个特征为

基于ReliefF算法,获得P种特征的权重值,构成类别区分度权重值序列:

式中w(p)为第p个特征经ReliefF算法得到的权重值,当特征的权重值越大,其类别区分度越好,则越有益于故障模式识别与分类。
1.3.2 特征域不变性量化
MMD目前被广泛用于迁移学习中度量数据间分布差异[11-12]。因此,本文采用MMD来计算同一特征在不同域下的分布差异。给定概率分布不同的源域样本DS={x1,x2,···,xnS}和目标域样本DT={xnS+1,xnS+2,···,xnS+nT},nS与nT分别为源域和目标域样本数。DS和DT间边缘概率分布的分布差异为

式中:xi,xj分别为第i个源域样本和第j个目标域样本,i∈[1,nS],j∈[nS+1,nS+nT];H为再生核Hilbert空间;φ (·)为H中的非线性映射函数。
本文采用轴承正常状态下的源域特征集和目标域特征集样本计算特征的分布差异,可获得各特征的分布差异序列:

式中m(p)为第p个特征在源域和目标域间的分布差异。
当分布差异越大,表明该特征在不同工况下数据分布差异越大,因此,特征在不同域下样本的分布差异越小,其域不变性越好,越有利于特征迁移学习。
1.3.3 特征可迁移性量化指标构建
基于表征特征类别区分度的权重值和表征域不变性的分布差异,构建一种新的特征可迁移性量化指标——类别权重与最大均值差异比(Ratio of Class Weight and Maximum Mean Discrepancy,RCM),表达式如下:

对于P种特征,基于式(5),可获得对应的RCM序列:

当特征的RCM值越大,其类别区分度和域不变性的综合性能越好,即可迁移性越好,越有利于特征迁移学习。因此,本文将计算各深度特征的RCM序列,并对其降序排列,选取排序靠前的深度特征构建新的可迁移特征集,用于后续的特征迁移学习和故障诊断分类器的训练。
1.4 基于BDA的特征迁移学习
BDA是由Wang Jindong等[13]于2017年提出的一种新的特征迁移学习方法,用于不同域数据之间的分布适应,降低分布差异。BDA旨在解决经典的特征迁移学习方法的迁移成分分析(Transfer Component Analysis,TCA)和联合分布自适应(Joint Distribution Adaptation,JDA)在进行不同域数据间分布适应时,边缘概率分布和条件概率分布存在的问题。为此,BDA引入了一种动态平衡因子,对边缘概率分布和条件概率分布的自适应进行动态调整,进而提高不同域间分布自适应的效果。
给定2个边缘概率分布和条件概率分布均不相等的域数据,有标签源域DS_Class={(x1,c1),(x2,c2),···,(xnS,cnS)}(ci为对应样本xi的类别标签)和无标签目标域DT={xnS+1,xnS+2,···,xnS+nT}。BDA的优化目标是通过源域有标签样本和目标域无标签样本学习得到一个映射矩阵A,使得映射变换后的源域和目标域间分布差异最小:

式中:μ为平衡因子,μ∈[0,1],根据人工经验确定数值,实现动态调整对源域和目标域的边缘概率分布和条件概率分布的适应;Y(DS_Class,DT) 和YConditional(DS_Class,DT)分别为经映射矩阵A变换后的源域和目标域数据间的边缘概率分布距离和条件概率分布距离,采用的度量方法为经典的MMD距离;为Frobenius规范正则项,λ为权衡参数;X为源域和目标域样本矩阵;H0为中心矩阵;I为单位矩阵。


式中:c∈[1,Z],Z为目标域样本类别;为第c类的源域样本;为第c类的目标域样本;为第c类的源域样本数;为第c类的目标域样本数。
2 实验验证
2.1 实验数据与任务设置
为验证基于DTF-BDA的提升机轴承智能故障诊断方法的有效性与优越性,采用美国凯斯西储大学轴承故障数据集[4,5,8,13]开展不同工况下数据故障诊断的实验分析。实验台如图3所示,数据集见表1。本文采用4种工况下的12种轴承状态数据开展实验验证,设置4个域数据:电动机转速为1 797 r/min时的12种状态数据为1个域数据(域1),电动机转速分别为1 772,1 750,1 730 r/min时的12种状态数据为另外3个域数据(域2-域4)。每个域数据中包含随机抽取的720个样本,每个样本由2 000个连续数据点构成。
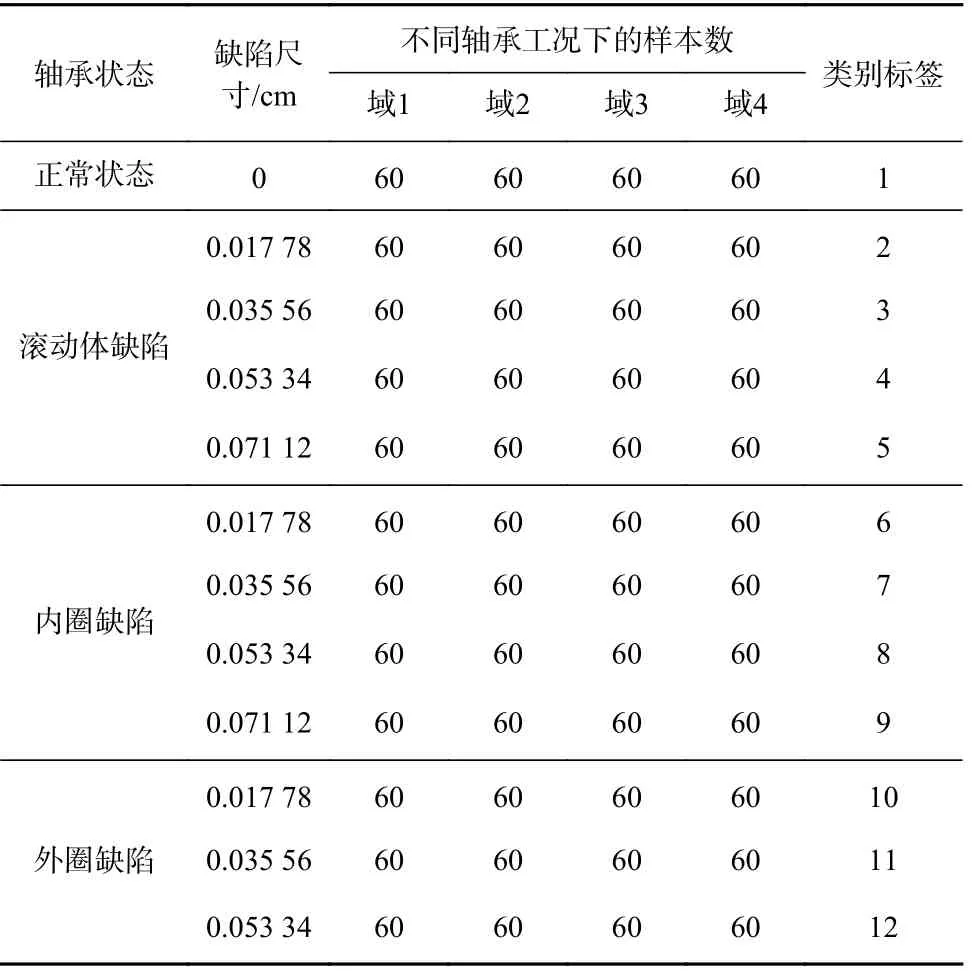
表1 凯斯西储大学轴承故障数据集Table 1 Bearing fault dataset of Case Western Reserve University

图3 凯斯西储大学轴承故障实验台Fig. 3 Bearing fault test rig of Case Western Reserve University
由于实际工业场景下的提升机轴承运行状态常为变工况,与训练故障诊断模型的样本所处工况不同,因此,实验分析共设置4个故障诊断任务。任务1:电动机转速为1 750 r/min时的数据作为源域(训练样本),电动机转速为1 730 r/min时的数据作为目标域(测试样本);任务2:电动机转速为1 730 r/min时的数据作为源域,电动机转速为1 750 r/min时的数据作为目标域;任务3:电动机转速为1 772 r/min时的数据作为源域,电动机转速为1 750 r/min时的数据作为目标域;任务4:电动机转速为1 750 r/min时的数据作为源域,电动机转速为1 772 r/min时的数据作为目标域。在该4个任务下进行故障诊断对比实验。
2.2 实验结果分析
根据图1所示的基于DTF-BDA的提升机轴承智能故障诊断流程构建对应的DTF-BDA故障诊断模型。首先,将原始轴承振动信号经小波包变换(Wavelet Packet Transform, WPT)4层分解后,对终端16个节点进行单支重构,提取重构信号的Hilbert包络谱和边际谱,再计算11种统计参数(能量、偏度、波峰因子、能量熵、平均值、极差、峰度、标准差、形状因子、脉冲因子和纬度因子)[9,14-15],共获得352个特征,即原始时频特征集。将352个时频特征输入DBN进行深度特征提取。激活函数选用sigmoid函数,隐含层神经元个数设置为500,300,200,学习率为0.01。本文共提取200个深度特征构建深度特征集。其次,采用TFRD方法对深度特征集中各特征进行可迁移性量化,获得RCM序列,并对其降序排列,选取RCM值大的深度特征构建特征子集。然后,使用BDA对来自源域有标签和目标域无标签的特征子集进行分布适应,减少分布差异。最后,利用BDA处理后的源域特征集训练故障模式识别分类器(SVM),将已训练好的SVM分类器用于目标域无标签样本的故障模式识别与分类。
本文采用经典机器学习方法、深度学习方法和迁移学习方法构建了8种故障诊断模型,分别为FS(Feature Set,特 征 集)-SVM,FS-KNN(k-Nearest Neighbor,K-最近邻),FS-DBN-Softmax(Soft Version of Max),FS-DAE(Deep Auto-Encoder,深度自编码器)-Softmax,FS-TCA-SVM,FS-JDA-SVM,FS-TFRD-TCA和FS-TFRD-JDA,用于与DTF-BDA故障诊断模型进行对比。FS-SVM模型是将原始数据经时频方法处理后提取的时频特征集直接输入SVM进行模型训练和测试。FS-KNN模型是将原始数据经时频方法处理后提取的时频特征集直接输入KNN进行模型训练和测试。FS-DBN-Softmax模型是将时频特征经DBN做深度特征提取,再输入Softmax模型进行模型训练和测试。FS-DAE-Softmax模型是将时频特征经DAE做深度特征提取,再输入Softmax模型进行模型训练和测试。FS-TCA-SVM模型是将时频特征集经TFRD特征选取后输入TCA进行特征迁移学习,再采用SVM分类器进行故障模式识别与分类。FS-JDA-SVM模型是将时频特征集经TFRD特征选取后输入JDA进行特征迁移学习,再采用SVM分类器进行故障模式识别与分类。FS-TFRD-TCA模型是将时频特征集经TFRD特征选取后输入TCA进行特征迁移学习,再采用SVM分类器进行故障模式识别与分类。FS-TFRD-JDA模型是将时频特征集经TFRD特征选取后输入TCA进行特征迁移学习,再采用SVM分类器进行故障模式识别与分类。
9种模型在不同工况下故障诊断准确率对比结果见表2,FS-TFRD-TCA,FS-TFRD-JDA和DTF-BDA模型的故障诊断实验结果见表3。

表2 不同故障诊断模型在4个任务下的故障诊断准确率对比Table 2 Comparison of fault diagnosis accuracy of different fault diagnosis models under 4 fault diagnosis tasks %

表3 不同故障诊断模型实验结果Table 3 Experimental results of different fault diagnosis models
(1) 从表2可看出:在4个故障诊断任务下,DTF-BDA模型的故障诊断准确率明显高于其他模型,最高可达100%,验证了基于DTF-BDA的提升机轴承智能故障诊断方法的有效性。
(2) 从表2还可看出:仅采用经典机器学习方法SVM,KNN和经典深度学习方法DBN和DAE构建的故障诊断模型用于不同工况下的故障诊断,其故障诊断性能较低,FS-SVM和FS-KNN模型仅任务1的故障诊断准确率可达95%以上,其余任务的故障诊断准确率均明显降低;FS-DBN-Softmax和FS-DAE-Softmax模型的故障诊断准确率更低,与DTF-BDA模型的故障诊断准确率差距较大。FS-TFRD-TCA和FS-TFRD-JDA模型的最高故障诊断准确率均能达到95%以上,明显高于FS-TCA-SVM和FS-JDA-SVM模型,表明由于TFRD方法的引入,使故障诊断准确率得到了明显提高。
(3) 从表3可看出:选取不同数量的可迁移特征时,对模型故障诊断准确率有明显影响:FS-TFRDTCA模型在选取140个可迁移特征时,任务1能够达到96.46%的故障诊断准确率,比200个可迁移特征时(即未使用TFRD方法,此时与FS-TCA-SVM模型等效)的故障诊断准确率高18.96%;FS-TFRD-JDA和DTF-BDA模型也有类似的规律。基于表2中FS-TCA-SVM,FS-JDA-SVM,FS-TFRD-TCA和FS-TFRD-JDA模型的结果对比和表3结果,表明了TFRD能够明显提升基于迁移学习方法的故障诊断模型在不同工况下的故障诊断性能。
(4) BDA相比于TCA和JDA在提升故障诊断模型在不同工况下的故障诊断性能上更具优势。根据表3中当可迁移特征数为200时,3个模型在4个任务下的故障诊断准确率可知,DTF-BDA模型在任务1-4下的故障诊断准确率分别为88.75%,86.46%,83.75%和82.08%,均明显高于FS-TFRD-TCA和FS-TFRD-JDA模型的准确率,表明BDA方法的故障诊断性能优于TCA和JDA。
3 结论
(1) 提出了一种基于DTF-BDA的提升机轴承智能故障诊断方法。首先利用DBN对原始故障信号进行高维深度特征提取;其次利用TFRD方法对各特征的可迁移性进行量化评估,选取可迁移特征构建深度特征子集;然后采用BDA处理源域和目标域特征集,降低域间分布差异;最后采用源域特征集训练故障模式识别分类器,对目标域样本进行故障识别与分类。
(2) 为验证基于DTF-BDA的提升机轴承智能故障诊断方法的有效性和TFRD与BDA方法的优势,采用美国凯斯西储大学轴承故障数据集开展了故障诊断对比实验分析。实验结果表明:① DTFBDA在获得理想的故障诊断准确率方面优势突出,最高故障诊断准确率达100%。② TFRD在提升迁移学习方法的故障诊断性能方面具有明显优势,FS-TFRD-TCA和FS-TFRD-JDA模型最高故障诊断准确率分别可达96.46%和97.67%。③ BDA相比于TCA和JDA,在提升故障诊断模型在不同工况下的故障诊断性能上更具优势,DTF-BDA模型在使用所有200个可迁移特征时在任务1-4的故障诊断准确率分别为88.75%,86.46%,83.75%和82.08%,均明显高于FS-TFRD-TCA和FS-TFRD-JDA模型的故障诊断准确率。
猜你喜欢
世界有色金属(2022年14期)2022-10-21
防爆电机(2022年4期)2022-08-17
电子乐园·上旬刊(2022年5期)2022-04-09
计算机技术与发展(2020年11期)2020-12-04
汽车与驾驶维修(维修版)(2019年7期)2019-09-10
科技风(2018年23期)2018-05-14
青年文学家(2015年29期)2016-05-09
中国高新技术企业(2015年13期)2015-04-30
微型计算机·Geek(2009年8期)2009-12-15
