
基于YOLOv5s模型的车辆类型检测算法
2022-10-11 04:32李建义
廊坊师范学院学报(自然科学版) 2022年3期
刘 鹤,李建义
(北华航天工业学院,河北 廊坊 065000)
0 引言
随着近些年私家车数量的增加,交通问题日益凸显,智慧交通对满足人们的生活需求、提高交通运输效率具有重要意义[1]。车辆类型检测是智慧交通的重要部分,例如在高速路口根据车辆类型会有不同的收费标准。目前,车辆类型检测的方法主要有基于CNN的车辆目标检测[2]、基于改进的Harris角点检测的车型识别[3]、基于SVM的车型检测和识别算法[4]、基于特征融合的车型检测。基于CNN与SVM的算法特征维数高、训练时间长,而且在面对较多车辆时会有遗漏情况。基于改进的Harris角点检测与基于特征融合的车型检测实时性差,不能及时检测车辆类型。因此,以上算法都不能满足车辆类型实时检测的需求。
为解决以上问题,本文选择目前流行的YO‐LOv5s[5]为基础框架,进一步高效地检测识别车辆类型。针对YOLOv5s算法使用Giou[6]作为损失函数时,如果两个目标边界框出现包含关系,或长宽高相同,差集会变为0,无法评估相对位置等问题,提出使用Ciou[7]作为损失函数代替Giou,既提高了模型训练的速度,又进一步改善了模型的精度。仿真实验结果表明:该改进方法对车辆类型的检测具有较好的实时性和较高的精确度。
1 YOLOv5s网络模型
YOLOv5是一种单阶段目标检测算法,它和YOLOv3、YOLOv4整体布局相似,由Input、Back‐bone、Neck、Prediction四部分构成[8],车辆检测流程结构如图1。v5系列总共有四个版本:YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x,这四个版本在结构上一致,其中YOLOv5s网络最小[9],精确度不如其余三种,但是速度最快。其余三种网络在YOLOv5s的基础上不断加深和加宽,精确度高但是速度较慢。由于本次实验是对车辆的类型进行检测,对检测的速度有较高的要求,因此,选择YOLOv5s作为本实验目标检验的框架基础。
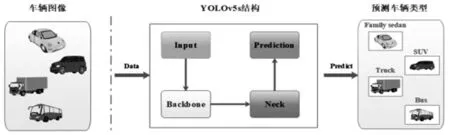
图1 车辆检测流程结构
1.1 Input区域
YOLOv5s输入端结构如图2所示,它采用Mo‐saic数据增强的方式[10],将输入的四张汽车图像进行随机缩放、裁剪、排布拼接[11]。YOLOv5s针对采集的车辆图像信息不一致问题,采用自适应图片缩放的方式,将输入的汽车图像缩放或填充到608*608尺寸。对统一长宽的汽车图像设定初始长宽的锚框,每次训练将预测车型锚框与真实锚框比对,计算两者差距并更新网络参数,自适应找出最佳锚框。

图2 Input结构
1.2 Backbone区域
Backbone[12]是YOLOv5s网络的主干部分,车辆图像依次经过一次Focus结构,X次CBL、CSP1[13]结构和一次SPP[14]结构。
Focus结构的主要工作是对车辆图像进行切片操作,结构如图3所示。Focus将3*608*608切成四个3*304*304的切片,然后采用Concat拼接这四个切片,经过卷积层提取车辆特征。最后使用Leaky_relu激活函数输出一个没有信息丢失的采样特征图[15]。
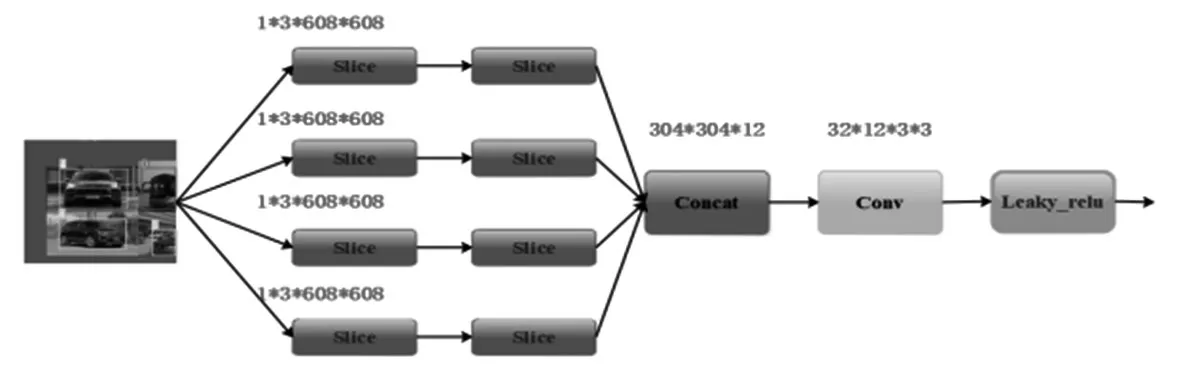
图3 Focus结构
经Focus输出的车辆采样特征图会依次经过X次CBL、CSP1结构。CBL由卷积层、归一化层、激活层组成,即采样特征图先经过卷积层进一步提取不同的特征,其次经过归一化层,实现特征结果的归一化,最后经过Leaky_relu激活函数输出结果到CSP1。
CSP1的结构如图4所示,CSP1的工作是提取特征,一个CSP1由两条“路径”组成,其中一条只有一个卷积层,另一条包含一个或多个CBL块、多个残差组件和一个卷积层。两条“路径”由Concat层拼接经归一化层和激活函数Leaky_relu输出。

图4 CSP1结构
SPP结构由Conv、max pooling和Concat三部分组成,结构如图5所示。SPP接收的图像尺寸为512*20*20,将输入图像通过Conv层进行特征提取之后输出尺寸为256*20*20,将提取后的特征在fea‐ture map上选取候选框,再经过四个max pooling提取固定大小特征,最后由Concat层拼接输出。
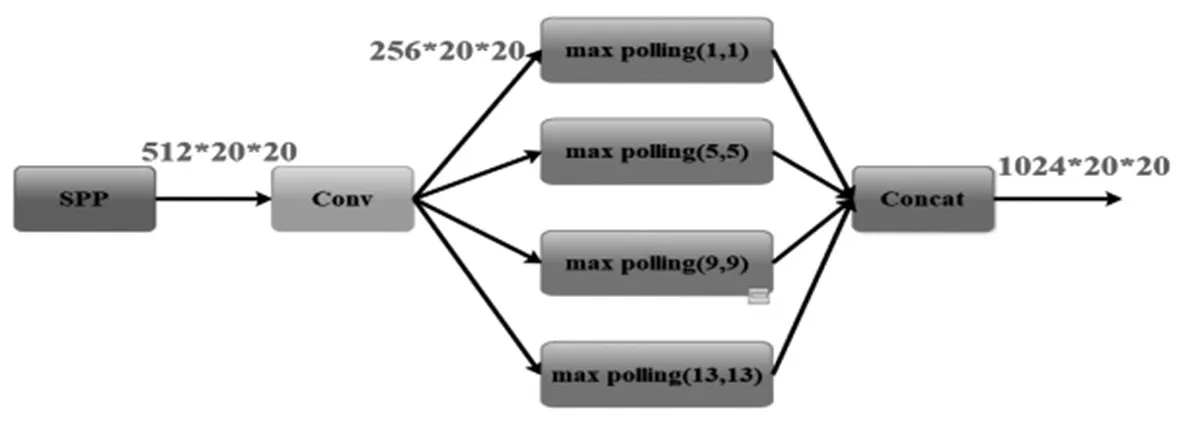
图5 SPP结构
1.3 Neck区域和Prediction区域
Neck区域采用FPN[16]的反向扩展结构FPN+PAN[17],如图6所示。自顶向下传递的FPN结构与两个自底向上的PAN结构结合操作,极大加强了网络特征的融合能力。
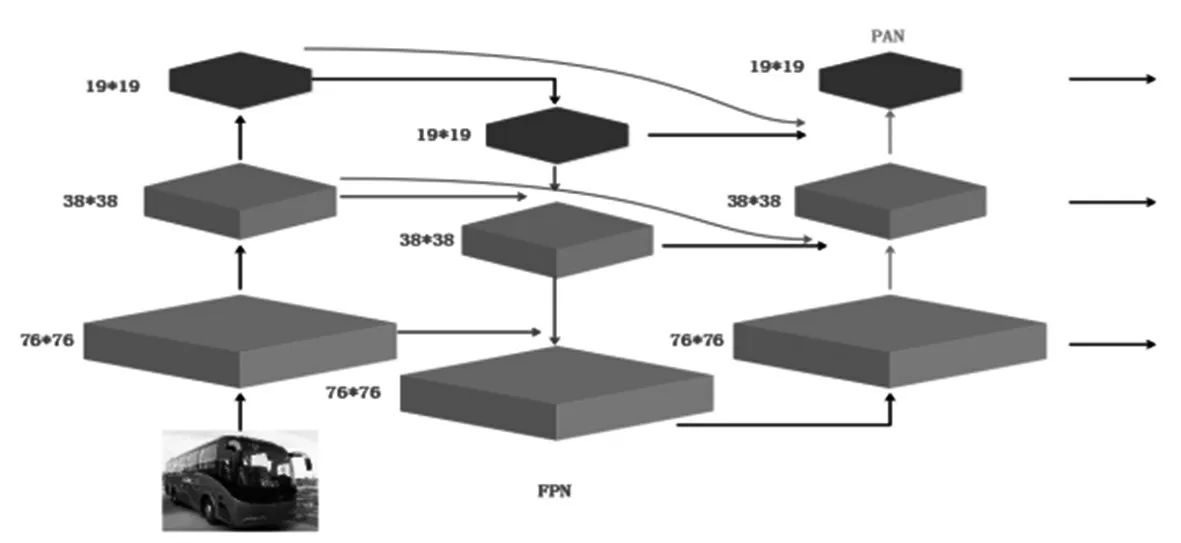
图6 FPN+PAN结构
Prediction负责将输入的车辆图像进行识别和分类。Prediction有三个输出,每个输出都是由卷积层与全连接层构成。针对每个输出,使用非最大抑制(NMS)[18]算法来消除多目标检测。
2 YOLOv5s网络模型改进
损失函数作为评价模型预测值和真实值差距的关键指标,损失函数和构建模型的性能呈正相关关系。传统YOLOv5s采用Giou作为损失函数。不同于Iou只关注重叠区域,对于非重合区域Giou同样关注,但是当两个目标边界框出现包含关系,或长宽高相同时,差集为0,Giou退化成Iou,无法评估相对位置,同时,Giou收敛速度慢。为解决此问题,本文采用Ciou作为损失函数,它可以充分考虑重叠面积、中心点距离、长宽比3个几何参数,使检测框更加符合真实框。因此,本实验采用基于Ciou损失函数的YOLOv5s模型。
Ciou损失函数公式如下:
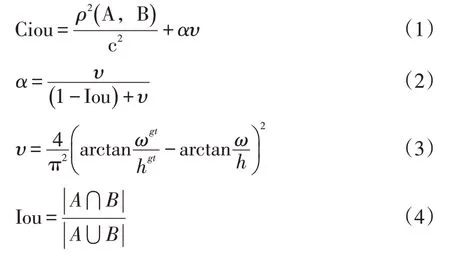
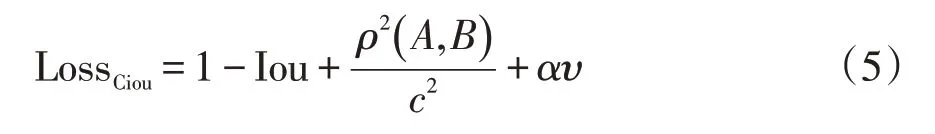
式中α是权重函数;υ用来度量宽高比的一致性;ρ2(A,B)表示A(预测框)与B(目标框)的中心距离;c代表A与B最小并区间对角线距离;Iou等于A和B的交集除以二者的并集是矩形对角线倾斜角度。
3 仿真实验对比及分析
3.1 数据集介绍
本次实验自制了一个车辆信息数据集,包括家用轿车、公交车、消防车、卡车、吉普车、SUV、面包车、出租车八种车型。车辆数据来自街道、校园和汽车展厅,共1260张图像,如图7所示。通过使用LabelImg软件将收集的图片标注出车辆类别,并将每个图像标注好的结果以.txt文件保存,该文件名和图像名称一致,包含对象的类别,对象中心的坐标、宽度和高度。本次实验将以7:3的比例划分训练集和测试集,分别用于本实验模型的训练和测试。

图7 车辆数据集图例
3.2 YOLOv5s网络训练
本实验运行环境:操作系统为Centos7,CPU为Intel Xeon Platinum8156,GPU为NVIDIA GeForce RTX 3080 Ti,内存16G,通过Python编程语言实现,使用框架为Pytorch。
为了查看训练周期对训练模型的影响,本实验对同一数据集训练四次:25、50、75和100个周期,实验周期对比结果见表1。
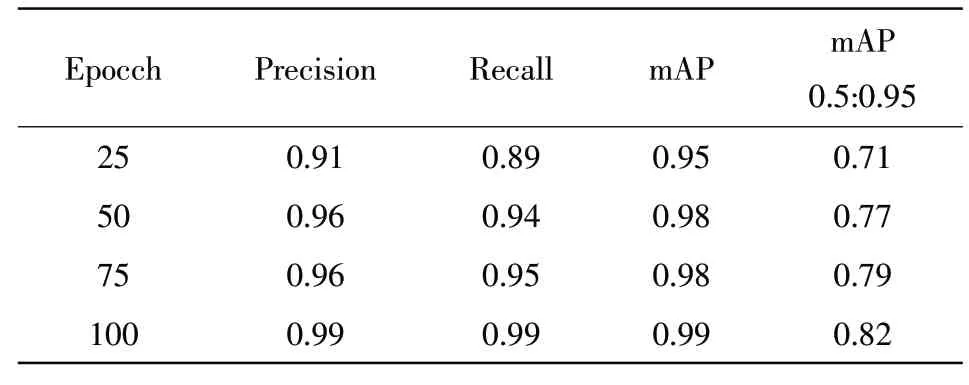
表1 周期对比结果
从表1中可以看出,训练的周期长短影响YO‐LOv5训练模型的质量,当接近100个周期时,参数增加幅度极低,因此,epochs为100时是最佳次数。
3.3 模型评估指标
本实验使用mAP作为模型的评价指标,mAP值越大说明车辆类型检测识别率越好,mAP公式如下:

其中,AP代表平均精度,是P-R曲线下的面积,mAP为AP的平均值。P表示预测为正例的样本中有多少是预测正确的,R表示真正为正例的样本中有多少被预测正确。P和R公式如下:


3.4 测试结果
本实验的YOLOv5s与传统YOLOv5s在训练100个epochs后,新YOLOv5s的mAP收敛速度明显高于YOLOv5s,而且起伏较小,如图8所示。
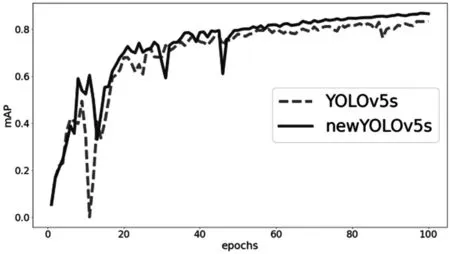
图8 mAP对比结果
从上图可以得出,本实验中的mAP值在60轮时就已经比传统YOLOv5s在100轮的效果要好,可以节省大量的训练时间,在有限时间下改进YOLOv5s会取得更加显著的效果。
除mAP外,本实验训练模型的Precision、Recall分别能达到0.995和0.996,如图9所示。
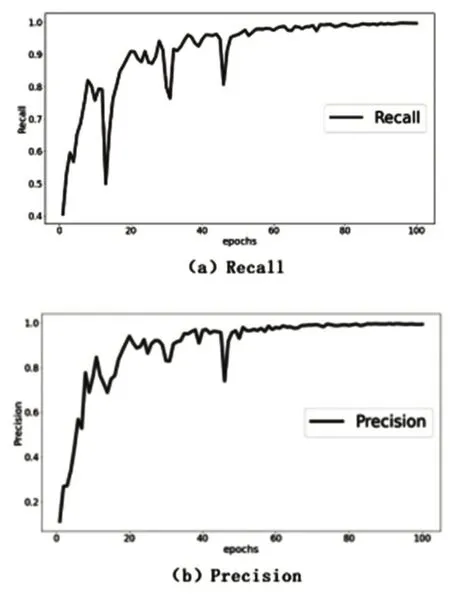
图9 Precision和Recall结果
为了直观检验训练车辆检测模型的效果,随机从测试集抽取部分图片作为输入,这些图片包含多种角度、多种拍摄距离下的交通照片,结果如图10所示。从图中可以看到能够准确识别消防车、公交车和私家车,证明了本实验可以精确的识别车辆类型,满足实际交通应用需求。

图10 优化后检测效果
4 结语
本实验为满足智能交通中对车辆类型检测精度以及速度的需求,提出以YOLOv5s为基础框架,用Ciou代替Giou作为损失函数。实验结果表明,本实验改进的YOLOv5s在mAP上明显优于原YO‐LOv5s,且收敛速度提升20%,实现了速度与精度两个方面的提升,非常适用于车辆类型识别的任务。
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
中学生数理化·中考版(2021年3期)2021-07-22
新世纪智能(数学备考)(2020年9期)2021-01-04
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
小太阳画报(2018年3期)2018-05-14
数学小灵通·3-4年级(2017年9期)2017-10-13
阅读与作文(小学低年级版)(2016年12期)2016-12-22
汽车文摘(2015年11期)2015-12-02
