
基于视点图像与EPI特征融合的光场超分辨率
2022-10-11 08:52安平陈欣陈亦雷黄新彭杨超
信号处理 2022年9期
安平 陈欣 陈亦雷 黄新彭 杨超
(新型显示技术及应用集成教育部重点实验室,上海先进通信与数据科学研究院,上海大学通信与信息工程学院,上海 200444)
1 引言
普通的二维成像只能记录场景内光线在取景平面的2D 投影,仅能获取光线的空间信息;而光场(Light Field,LF)成像[1]能够记录整个空间内的光线分布,既能获取光线的空间信息,也能获取光线的角度信息[2]。光场图像可通过特制的光场相机[3]获取。光场相机由传统相机在原有的感光元件和主透镜之间放置一层微透镜阵列改造而成,通过相机主透镜的光线在到达感光元件之前,将通过微透镜阵列发生二次折射。因此光场相机不仅能够利用微透镜位置记录入射光线的位置,还能够利用光线二次折射的折射角度记录入射光线的方向,即同时获取光线的空间信息和角度信息。利用光场成像技术可以实现深度估计[4]、图像重聚焦[5]、三维建模[6]等应用,具有十分重要的研究意义。
在实际应用中,光场通常表现为视点图像(Viewpoint Image,VI)阵列的形式,记作L(s,t,x,y),其中,s和t是角度维度;x和y是空间维度。光场图像的分辨率可以表示为S×T×X×Y,其中,S×T是角度分辨率,表示光场中包含的视点图像数量;X×Y是空间分辨率,表示每一个视点图像的尺寸。光场实现了高维的图像数据表达,但是由于光场采集设备的限制,在有限的成像条件下,光场图像的空间分辨率和角度分辨率需要折中。这导致了光场图像的空间分辨率远低于传统成像设备得到的二维图像的分辨率,例如商用光场相机Lytro Illum获取的光场图像分辨率仅为14×14×376×540。因此,如何提高光场图像的空间分辨率成为一个亟须解决的问题。
不同于传统二维图像基于场景内容先验的超分辨率,光场图像超分辨率所需的像素信息实际存在于光场内部的各个视点图像中。传统的光场超分辨率方法根据光场视点图像视差和像素点之间的对应关系,利用先验的视差信息对视点图像像素信息进行显式投影(Warp)来达到超分辨率的目的。但视差先验信息严重依赖视点图像本身的质量,现有的视差估计方法通常不能满足这类方法对视差先验信息的高精确度要求。近年来,随着深度学习的发展,许多基于深度学习的光场超分辨率方法被提出,利用卷积神经网络能够隐式地学习视点图像之间的视差关系。基于深度学习的光场超分辨率方法无需先验的视差信息,能够直接通过网络学习光场信息达到良好的超分辨率质量。但现有基于深度学习的方法没有充分利用光场特性,光场超分辨率的整体性能还有很大的提升空间。
固定光场的角度维度采集光场数据得到的二维图像,即视点图像。视点图像记录了在固定角度下对场景的观察,能够获取场景中的主要纹理信息。固定光场的一维角度维度和一维空间维度采集光场数据得到的光场二维切片,即极平面图像(Epipolar Plane Image,EPI)。场景中同一个可见的物体点由于不同视点图像之间的视差关系,在EPI中形成一条连续的直线。该直线能够有效地反映出光场图像内部的几何一致性。同时,光场中存在水平和垂直两个方向的EPI,能够从两个不同的角度维度反映出视点图像之间的关联性。因此,利用视点图像和EPI 信息实现光场超分辨率,能够充分探索光场的纹理信息及几何一致性,学习光场图像整体信息。结合以上光场特性,本文提出了一种基于视点图像与EPI特征融合的端到端光场超分辨率方法。本方法主要创新性如下:
利用三维视点图像堆栈包含EPI 信息的特点,将输入的四维光场数据按照水平/垂直EPI 方向堆叠排列,使用3D 递减卷积网络提取特征,不仅能同时感知视点图像和EPI 信息,还能学习光场图像不同角度维度之间的联系,有效增强了光场超分辨率质量。
采用双分支结构的网络设计,同时结合光场图像水平和垂直EPI 信息进行光场超分辨率,有效提高了超分辨率结果的几何一致性。
采用端到端网络设计,能够同时超分辨率所有视点图像。在真实和合成光场数据集上的实验结果均表明,本方法相比于现有主流方法,取得了更好的超分辨率效果。同时,在网络参数量和执行速度上也具有更好的表现。
本文共分为五个部分。第一部分为引言;第二部分简要介绍现有的光场超分辨率方法;第三部分阐述本文所提出的整体模型框架和具体实现方法;第四部分给出具体的实验设置和结果分析;最后一部分是结论。
2 相关工作
传统的光场超分辨率方法基于光场视点图像之间的空间关联性,利用先验的视差信息对视点图像像素信息进行显式Warp,通常需要复杂的优化算法以获取较优的超分辨率结果。Bishop 等人[7]首次提出了光场超分辨率重建,利用盲反卷积提高了光场图像的空间分辨率;而Mitra 等人[8]分析了EPI 的低秩性与视差之间的关系,提出了使用混合高斯模型的光场超分辨率方法。与方法[8]不同的是,Wanner 等人[9-10]在EPI 上应用结构张量计算视差图,并利用变分模型进行光场超分辨率。Rossi 等人[11]利用基于图的正则化对光场超分辨率设计了全局优化问题,通过计算Warp 矩阵优化超分辨率结果。Ghassab 等人[12]在基于图的正则化的基础上,结合交替方向乘子法模型和边缘保留技术实现光场超分辨率。然而,由于光场图像中存在遮挡、噪声等问题,缺少有效的像素信息,同时现有的视差估计方法也无法提供高精度的视差图,因此传统光场超分辨率方法难以获得高质量的超分辨率结果。
Dong 等人[13]首次将卷积神经网络应用至单图像超分辨率,通过特征提取、非线性映射和重建等步骤达到良好的超分辨率结果,随着单图像超分辨率的发展[14],卷积神经网络也逐渐被应用于光场超分辨率。Yuan 等人[15]提出了一种基于EPI 的联合卷积神经网络,首先将单图像超分辨率方法应用于光场图像,随后使用EPI 增强网络提高超分辨率结果的几何一致性。Zhang 等人[16]将视点图像按照四个方向堆叠输入残差网络中提取特征,并利用不同的视点图像组合方案实现对所有视点图像的空间超分辨率。Yeung 等人[17]提出了一种空间-角度可分离卷积,在卷积过程中不断变换光场图像的表达形式以实现空间超分辨率。Farrugia 等人[18]使用光流对齐所有视点图像,结合低秩先验和深度卷积神经网络实现光场超分辨率。Jin 等人[19]提出了一种以其余视点图像作为辅助信息,利用视点图像之间的互补性提升参考视点图像分辨率的方法,并使用结构一致性正则化网络提高超分辨率结果的几何一致性。Wang 等人[20]利用普通卷积和膨胀卷积分别从光场原始图像中提取出空间特征和角度特征,并利用网络进行特征融合实现光场超分辨率。Liang 等人[21]提出了一种混合角度分辨率训练策略,使用解耦融合模型实现了适用于多角度分辨率光场的空间超分辨率,有效提升了超分辨率性能。
对光场进行空间超分辨率处理时,需要着重考虑光场原有的特性,而不是将不同的视点图像作为独立的个体来考虑。而现有的基于深度学习的超分辨率方法中,基于单图像超分辨率的方法[15]忽视了光场的整体性;基于不同视点图像组合的方法[16]没有充分利用视点图像信息;基于不同类型特征提取的方法[17-21]没有充分利用光场特有的EPI 信息。因此本文提出了一种基于视点图像与EPI特征融合的端到端光场超分辨率方法,使用双分支网络充分学习视点图像信息以及水平和垂直EPI 信息,能够同时完成所有视点图像的高质量超分辨率。
3 本文方法
3.1 方法框架
本文利用三维视点图像堆栈包含EPI信息的特点,提出了一种基于视点图像与EPI 特征融合的端到端光场超分辨率方法。本方法的网络结构如图1所示,主要分为三个模块:特征提取模块、特征融合模块、上采样模块。特征提取模块分为水平和垂直两个分支,分别由三层3D 递减卷积层组成,能够同时感知视点图像和EPI 信息,用于对四维光场数据提取中间特征;特征融合模块的设计参考Yeung 等人[17],由一层2D 卷积层和Q层空间角度卷积组成,用于将中间特征转换为全局特征;上采样模块主要由一层2D 反卷积层和一层2D 卷积层组成,用于对全局特征进行上采样,获取高分辨率残差信息。

图1 网络结构图Fig.1 Proposed network structure
整体的超分辨率过程可以简要描述如下:首先将低分辨率的光场图像按照水平/垂直EPI 方向堆叠排列得到两组四维光场数据,输入双分支结构的特征提取模块得到两个中间特征;随后利用特征融合模块将两个中间特征转换为全局特征并对其进行优化;最后将优化后的全局特征输入上采样模块得到高分辨率光场残差,与同样经过反卷积上采样的垂直分支中间特征相加,得到最终的超分辨率结果。选用垂直分支中间特征的具体原因将在4.3节给出解释。
3.2 视点图像堆栈中的EPI
已知四维光场数据L(s,t,x,y),固定角度维度s和空间维度x得到的EPI 称为水平EPI,记作;固定角度维度t和空间维度y得到的EPI称为垂直EPI,记作。而固定角度维度s或t堆叠视点图像,即按照水平或垂直EPI 方向堆叠视点图像,可以得到三维水平或垂直视点图像堆栈,记作。如图2所示,水平/垂直三维视点堆栈中包含一个水平/垂直EPI 切面。将按照水平EPI方向堆叠排列的四维光场数据输入网络时,输入数据尺寸为N×S×T×X×Y,其中N是Batch 维度;S和T是视点图像的角度维度;X和Y是视点图像的空间维度。对上述四维光场数据进行3D 卷积操作,角度维度S将作为卷积处理的通道维,角度维度T为卷积处理的深度维,3D 卷积核的直接卷积对象是尺寸为T×X×Y的三维视点图像堆栈,其中包含了水平EPI切面。因此,这样做不仅能够同时学习S组三维视点图像堆栈中的视点图像和EPI 信息,还能够学习S组三维视点图像堆栈之间的联系,即三维视点图像堆栈在另一个角度维度的关联,达到通过网络学习光场图像整体信息的效果。基于以上特点,本文将输入的低分辨率四维光场图像按照水平/垂直的EPI 方向堆叠排列,并采用双分支结构3D 递减卷积网络充分学习视点图像、水平和垂直EPI信息,以达到更好的超分辨率效果。
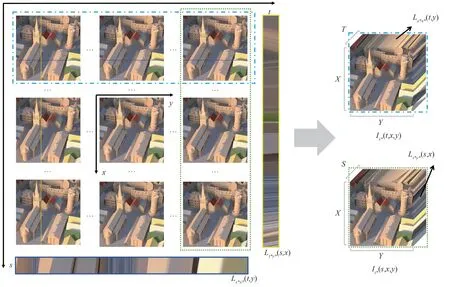
图2 光场的四维表示、EPI和三维视点图像堆栈Fig.2 4D representation of light field,EPI and 3D viewpoint image stack
3.3 特征提取模块
为了充分利用水平和垂直两个方向的EPI 信息,特征提取模块采用双分支结构设计,分为水平和垂直两个分支。如3.2 节所述,不同于其他基于深度学习的光场超分辨率方法,本文为了充分利用光场图像的几何一致性,特征提取模块采用3D 卷积层而非2D 卷积层进行特征提取,特征提取模块的水平和垂直分支分别由三层3D 递减卷积层所组成。水平分支的输入为按照水平EPI方向堆叠排列的四维光场数据,尺寸为N×S×T×X×Y,其中T×X×Y包含水平EPI 信息;垂直分支的输入为按照水平EPI 方向堆叠排列的四维光场数据,尺寸为N×T×S×X×Y,其中S×X×Y包含垂直EPI信息。
按照水平/垂直EPI 方向堆叠排列的低分辨率四维光场数据通过三层3D 递减卷积层,得到中间特征Fh和Fv,尺寸均为N×(S·T)×1×X×Y。在卷积过程中,特征的深度维逐层递减为1。以本文所使用角度分辨率为7×7 的光场为例(即S=T=7),在此过程中特征尺寸变化如下所示:

用公式表达以上卷积过程为:
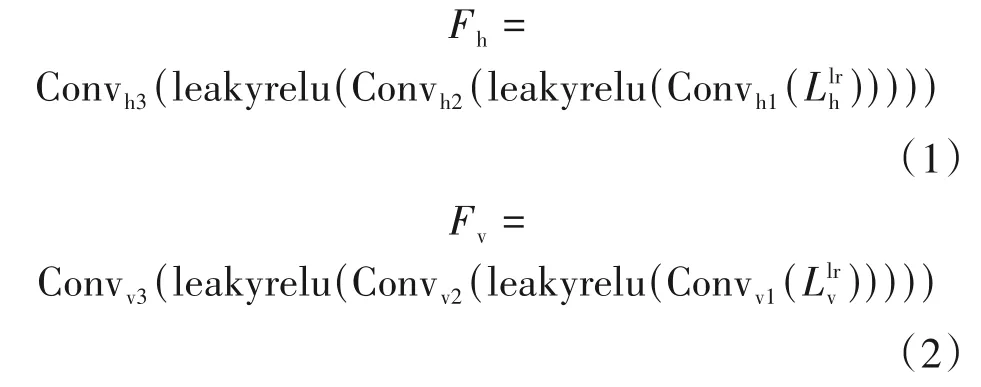
其中,h 和v 表示水平和垂直EPI 方向;Convi(·)表示第i个3D 卷积层,i=1,2,3;leakyrelu(·) 表示Leaky ReLU 激活函数;表示按照水平EPI 方向堆叠排列的低分辨率四维光场数据;表示按照垂直EPI 方向堆叠排列的低分辨率四维光场数据,用公式表达如下所示:

3.4 特征融合模块
为了进一步整合不同堆叠方向下学习到的视点图像与EPI信息,以提升超分辨率结果的整体性,特征融合模块采用了Q层空间角度卷积来融合优化特征提取模块得到的中间特征Fh和Fv。首先连接两个中间特征得到全局特征Fg:

将得到的全局特征Fg输入空间角度卷积中进行进一步的融合优化。空间角度卷积由空间卷积和角度卷积两个2D 卷积层顺序组成,输入空间卷积的特征尺寸为(N·S·T)×C×X×Y,2D 卷积核的直接卷积对象是尺寸为X×Y的视点图像;输入角度卷积的特征尺寸为(N·H·W)×C×S×T,2D卷积核的直接卷积对象是尺寸为S×T的宏像素,中间使用Reshape 操作来改变特征尺寸。利用空间角度卷积可以学习光场图像的空间维度(视点图像)和角度维度(宏像素)信息之间的联系。以上步骤用公式表达如下:

其中,SAConvj(·)表示第j个空间角度卷积,j=1,2,…,Q;SpaConv(·)表示空间卷积;AngConv(·)表示角度卷积;表示通过Q层空间角度卷积后输出的全局特征,尺寸为(N·S·T)×C×X×Y。
3.5 上采样模块
该残差与同样经过一层2D 反卷积层上采样后的垂直分支中间特征相加,即可得到最终的超分辨率结果Lsr。用公式表示如下:
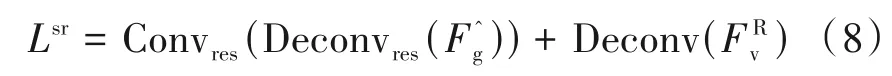
其中,Conv(·)表示2D 卷积;Deconv(·)表示2D 反卷积。
3.6 训练细节
本文使用的训练数据集参照Jin 等人[19],选定了来自Stanford Lytro LF Archive[22]中6 组不同类别的88 张真实光场图像(光场相机图像)、来自Kalantari 等人[23]的72 张真实光场图像(光场相机图像),以及来自HCI new[24]的20 张合成光场图像,共180张光场图像用于训练,具体信息如表1所示。

表1 训练数据集和测试数据集Tab.1 Training datasets and test datasets
本文仅针对角度分辨率为7×7 的光场图像进行空间超分辨率,用于训练的真实及合成光场数据集角度分辨率分别为14×14 和9×9,训练时对其进行裁切,仅使用其中心区域的7×7 视点图像。同时本文使用双三次插值(Bicubic)的下采样方式获取训练所需的低分辨率光场图像,训练时对原始空间分辨率的光场图像进行在线随机裁切,使用尺寸为7×7×64×64 的光场图像块进行训练。同时对训练数据进行在线增强,对图像块随机进行上下或左右的翻转以及90°、180°或270°的旋转,以提高训练模型的鲁棒性。
本文在RTX 3090 GPU上使用PyTorch 1.9对提出的模型进行训练。特征提取模块中的三层3D 递减卷积层均包含49个卷积核,每层的卷积核尺寸分别为3×3×3、2×3×3 和2×3×3,卷积层之间加有Leaky ReLU 激活函数。特征融合模块中所使用的2D 卷积均包含64 个卷积核,尺寸为3×3,卷积层之间加有ReLU 激活函数,空间角度卷积数量Q设置为6。本文使用Xaviers 算法初始化每个卷积层的权重,并使用Adam 优化器对网络进行训练,Batch 的大小设置为1,学习率初始值为10-4,每2000个epoch 学习率减半。网络训练过程中,使用最终的超分辨率结果Lsr和原始参考图像Lhr之间的L1损失函数对网络进行监督:

4 实验结果与分析
4.1 实验设置
本文选取了四个常用的光场超分辨率数据集用于测试,分别为两组真实光场数据集:Stanford Lytro LF Archive 的General 分类(共57 张光场相机图像,分辨率为372×540)、Kalantari 等人[23]的测试数据(共30 张光场相机图像,分辨率为372×540);两组合成光场数据集:HCI old[25](5 张合成光场图像,分辨率为786×786)、HCI new(4 张合成光场图像,分辨率为512×512),共96 张光场图像用于测试,具体信息如表1所示。
实验结果的展示主要分为客观评价和主观评价两个部分:客观评价主要采用峰值信噪比(Peak Signal to Noise Ratio,PSNR)和结构相似性(Structural Similarity,SSIM)作为评价指标;主观评价将对各方法的超分辨率结果及其误差图、图像细节和纹理部分的EPI进行展示和分析。
4.2 对比实验
为了客观评价所提出方法的有效性,本文主要选用了六个对比方法,包括四个现阶段较为先进的光场超分辨率方法:resLF[16]、LF-ATO[19]、SA-Inter[20]、LF-AFnet[21],一种基于深度学习的经典单图像超分辨率方法:VDSR[26]和一个单图像超分辨率基线方法:Bicubic。本文中所有的实验数据均来自各论文作者给定的代码和训练模型,VDSR 使用3.6 节中所述训练数据集中的所有光场视点图像对其重新训练,网络设置和训练方式参照原论文。此外,resLF原论文提供了使用Bicubic 下采样的×2 模型和使用模糊(Blur)下采样的×2和×4模型,本文对以上三个模型都进行了客观指标展示,主观实验部分仅展示使用Bicubic 下采样的超分结果。而SA-Inter 提供了针对5×5 光场图像的×2 模型和针对7×7 光场图像的×4模型,因此本文利用该×2模型分别超分4组5×5 光场图像,重叠视点图像部分取其客观指标最优,以达到超分7×7光场图像的效果。
上述方法在4.1 节中所述测试数据集上×2 及×4的超分辨率结果客观指标如表2和表3所示。表格中所展示的数据为该数据集中所有测试光场图像的平均PSNR 和SSIM,加粗展示的为最优数据,加下划线展示的为次优数据。可以看出,在×2的超分辨率任务下,本文方法仅在HCI new 数据集上的平均SSIM 略低于LF-AFnet 0.06%,而平均PSNR 相比提高了0.006 dB。在剩余三个测试数据集上的表现相比次优数据分别提高了0.159 dB/0.03%、0.268 dB/0.07%、1.394 dB/0.55%;在×4 的超分辨率任务下,本文方法的平均PSNR 和SSIM 相比次优数据分别提高了0.063 dB/0.27%、0.208 dB/0.96%、0.133 dB/0.52%、1.427 dB/3.52%。由此可证明,本文提出的方法无论在真实还是合成光场数据集上的测试结果均优于其他方法,同时在×2 和×4 的超分辨率任务下,均能保持较高的超分辨率质量。

表2 ×2超分辨率结果平均PSNR(dB)/SSIM对比Tab.2 Comparison of average PSNR(dB)/SSIM of ×2 super-resolution results

表3 ×4超分辨率结果平均PSNR(dB)/SSIM对比Tab.3 Comparison of average PSNR(dB)/SSIM of ×4 super-resolution results
同时,本文在测试数据集中挑选了四张测试光场图像进行超分辨率的主观结果对比。图3 为×2超分辨率主观结果对比,展示了中心视点图像Y 通道的误差图和超分辨率结果局部细节放大,同时绘制了局部纹理部分的水平和垂直EPI,图像下方标注了该图像所有视点图像的平均PSNR 和SSIM。其中误差图为超分辨率结果与原始参考图像(Ground Truth)的差值,截断值为0.1,颜色越暗表示误差较小,反之则误差较大。图4 为×4 超分辨率主观结果对比,展示了中心视点图像超分辨率结果及其局部细节放大、局部纹理部分的水平和垂直EPI,以及其平均PSNR 和SSIM。通过主观结果对比可以看出,本文方法的超分辨率结果和Ground Truth更为接近,相比其他方法具有更丰富的细节信息、更清晰的图像纹理和边缘。同时本文方法在EPI 上的表现也更为优秀,连续性更好,EPI 中由于视差所形成的直线没有断连和错连,也没有出现明显的锯齿现象。尤其是bedroom 和general_23_eslf这两张光场图像的EPI,可以观察到,本文方法得到的EPI 更接近Ground Truth 的EPI,而其他方法在超分辨率过程中丢失了图像细节信息,EPI 中的视差线条信息不全,出现了断连和错连的现象。这也表明,本文方法相较于其他方法具有更好的几何一致性。图5 展示了×2 任务下,不同方法在测试光场图像bicycle 上的视点图像质量可视化分布,颜色越深代表质量越高,反之则质量越差。方格内为该角度位置视点图像的PSNR,通过该图也可以看出,本文方法在各个视点图像上的超分辨质量整体高于其他方法。
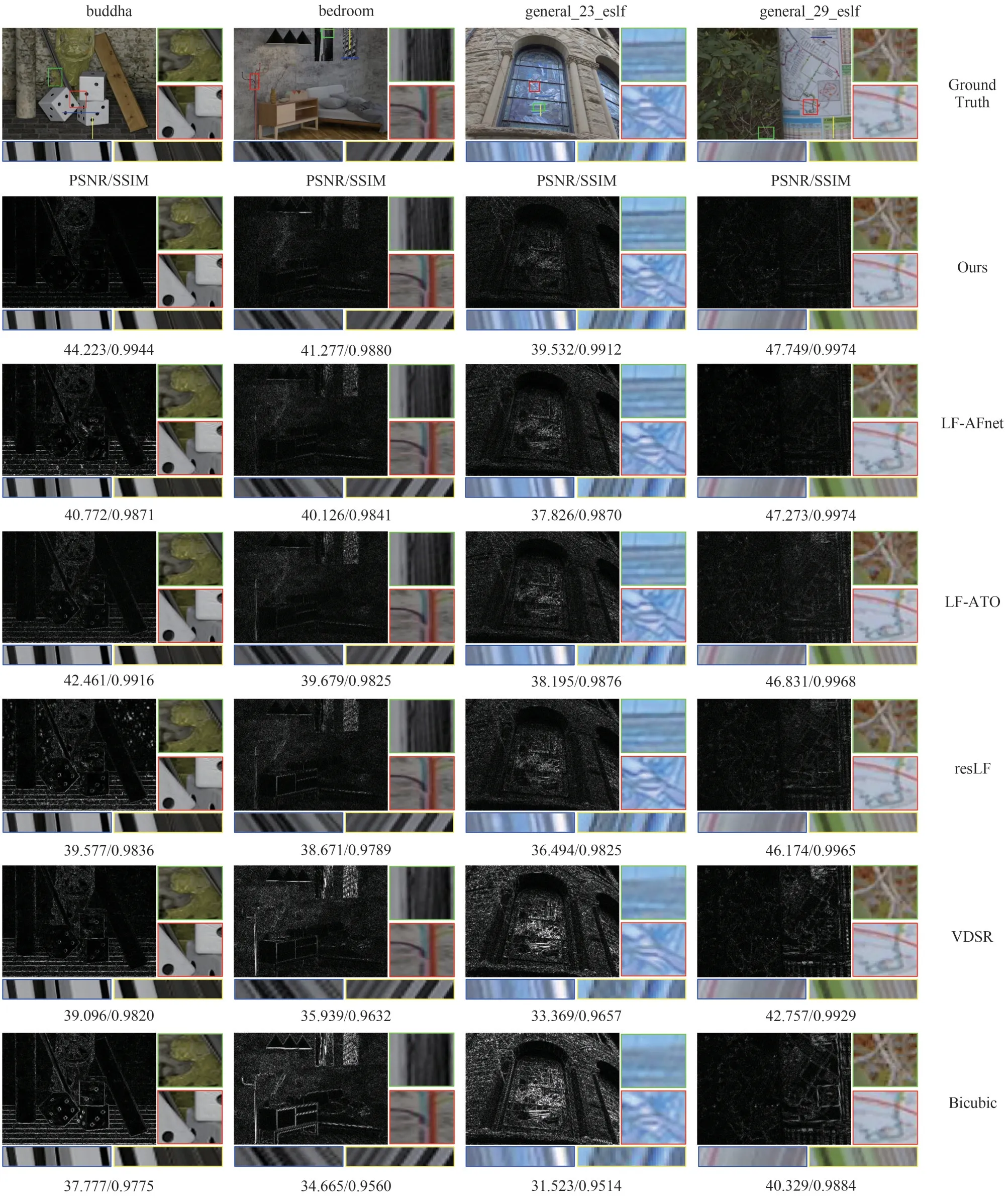
图3 ×2超分辨率主观结果对比,展示了中心视点图像Y通道的误差图、局部细节放大、水平EPI(下左)和垂直EPI(下右),以及平均PSNR(dB)/SSIMFig.3 Comparison of ×2 super-resolution subjective results,which shows the error map of the Y channel of the central viewpoint image,the zoom-in of the partial details,horizontal EPI(bottom left),vertical EPI(bottom right),and the average PSNR(dB)/SSIM

图4 ×4超分辨率主观结果对比,展示了中心视点图像的超分辨率结果、局部细节放大、水平EPI(下左)和垂直EPI(下右),以及平均PSNR(dB)/SSIMFig.4 Comparison of ×4 super-resolution subjective results,which shows the super-resolution result of the central viewpoint image,the zoom-in of the partial details,horizontal EPI(bottom left),vertical EPI(bottom right),and the average PSNR(dB)/SSIM

图5 ×2任务下,测试光场图像bicycle的视点图像PSNR(dB)分布Fig.5 The PSNR(dB)distribution of viewpoint images of the test light field image bicycle under×2 task
为了进一步验证本文方法相较其他方法有更好的计算效率,本文还从网络模型的参数量以及超分辨率任务执行时间的角度来评估上述不同方法。表4 展示了×2 任务下,不同方法在Kalantari 等人[23]和HCI new 两个测试数据集上使用RTX 3090 GPU进行超分辨率的平均执行时间,以及在上述四个测试数据集上的平均PSNR 和SSIM。从表格中可以看出,本文方法在保证超分辨率结果质量的基础上,还能够较大幅度地缩减网络参数量。在×2任务下,本文提出的方法与LF-AFnet和LF-ATO 相比,参数量分别缩减了69%和52%,同时执行速度也是对比的光场超分辨率方法中最快的。
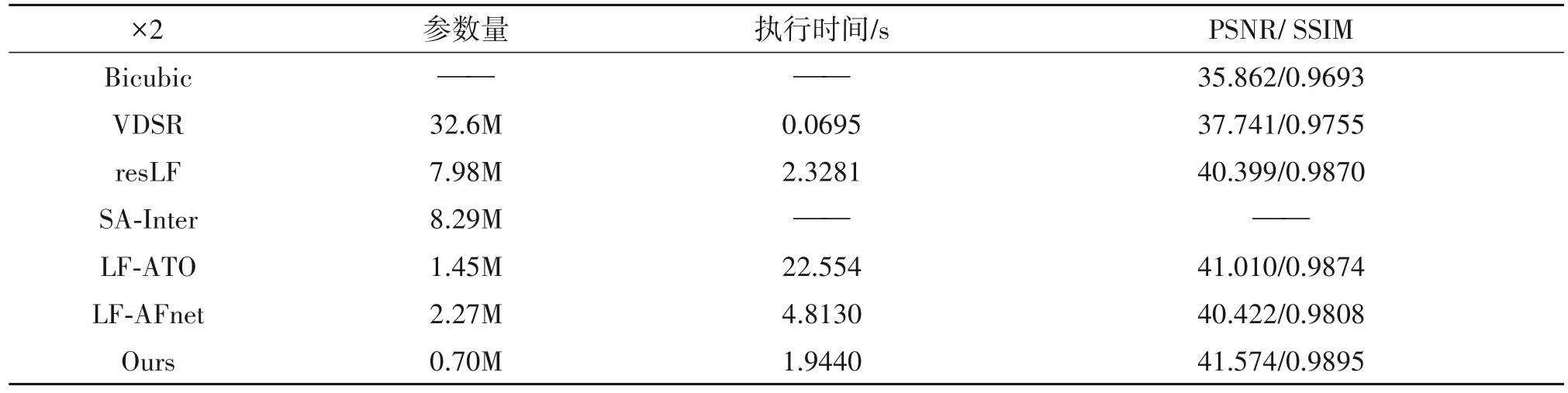
表4 ×2任务下,不同方法的计算效率和平均PSNR(dB)/SSIM对比Tab.4 Comparison of computational efficiency and average PSNR(dB)/SSIM of different methods under×2 task
4.3 消融实验
为了进一步验证本文方法的有效性,本文在×4任务下主要针对特征提取模块进行了消融实验,网络其他部分均保持不变。消融实验主要分为两个部分,共设计了3 个变体,网络模块设计如图6 所示,实验结果客观指标如表5所示。

图6 不同特征提取模块的消融Fig.6 Ablation of different feature extraction module
1)为了验证双分支网络结构的有效性,本文设计了两组单分支变体。单独保留使用按照水平EPI方向堆叠排列的光场数据作为输入的水平分支,记作消融A;单独保留使用按照垂直EPI 方向堆叠排列的光场数据作为输入的垂直分支,记作消融B。
如表5所示,消融A和消融B的实验结果十分近似,可以看出,将视点图像按照水平或垂直EPI方向堆叠排列得到的学习效果相近。而本文的双分支结构网络的实验结果明显高于消融A和B,即双分支结构网络相比单分支结构网络得到的超分辨率效果有着明显提升,这验证了本文双分支结构的有效性。同时消融B的实验结果略高于消融A,因此网络设计时,本文选择使用垂直分支中间特征与高分辨率残差信息相加,得到最终的超分辨率结果。

表5 ×4任务下,消融实验参数量及超分辨率结果平均PSNR(dB)/SSIM对比Tab.5 Comparison of parameters and average PSNR(dB)/SSIM of super-resolution results of ablation experiments under×4 task
2)为了验证将输入的四维光场数据按照水平/垂直EPI 方向堆叠排列的有效性,本文还设计了将按照视点图像顺序排列的光场数据(尺寸为1×(S·T)×X×Y)直接整体输入单分支结构网络的消融实验,代替使用按照水平/垂直EPI 方向堆叠排列的光场数据(尺寸为S×T×X×Y或T×S×X×Y)作为输入,记作消融C。
如表5 所示,消融C 的实验结果明显低于消融A 和B,可以看出,将输入的光场数据按照EPI 方向堆叠排列能够有效提高光场超分辨率性能,同时也验证了,使用按照EPI 方向堆叠排列的四维光场数据作为网络输入能够有效利用EPI信息。
仿照本文原本的网络设计,以本文所使用角度分辨率为7×7 的光场为例(即S=T=7),消融C的输入尺寸为1×49×X×Y,在输入三层3D 递减卷积网络的过程中,特征尺寸变化如下:
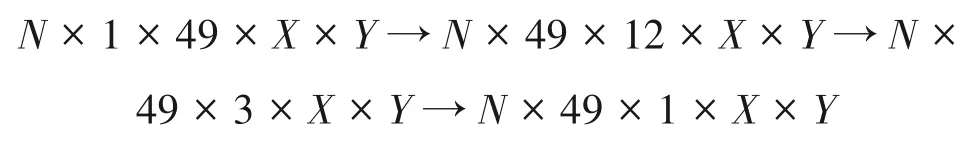
相比原网络设计,消融C增大了特征的深度维,同时增大了3D 卷积核的尺寸,相应增大了3D 卷积的感受野。因此在网络参数量上,该单分支设计的参数量为746K,与本文的双分支网络的参数量784K 基本相当,高于消融A/B 的参数量688K。从实验结果可以看出,消融C远低于本文的双分支结构网络,这也印证了本文的双分支网络结构以及将输入光场数据按照EPI方向堆叠排列的有效性。
从以上分析可以看出,将低分辨率光场图像按照EPI 方向堆叠排列形成的四维光场数据作为输入,同时使用本文所设计的双分支结构网络,能够更加充分地利用光场视点图像、水平和垂直EPI 信息,探索光场图像原有的纹理信息和几何一致性信息,有效提高了光场超分辨率性能。
5 结论
本文提出了一种基于视点图像与EPI特征融合的端到端光场超分辨率方法。本方法强调了三维视点图像堆栈包含EPI 信息这一特点,将四维光场数据按照水平/垂直EPI 方向堆叠排列,使用双分支结构的3D 递减卷积网络同时感知光场视点图像和EPI 信息,提取光场特征。本方法充分利用了视点图像信息、水平和垂直EPI信息,有效增强了光场超分辨率质量,提高了超分辨率结果的几何一致性。实验结果表明,本文方法在多个数据集上的客观指标和主观质量均优于其他主流方法。同时,相较于其他方法,本文的网络模型参数量能够保持在较低水平,在超分辨率任务执行速度上也有较好的表现。未来,我们的工作方向是结合光场更多特性以获得质量更佳的超分辨率结果。
猜你喜欢
现代计算机(2021年8期)2021-05-13
信息化视听(2017年3期)2017-04-15
光学仪器(2017年1期)2017-04-10
环境(2016年7期)2016-05-14
CHIP新电脑(2016年3期)2016-03-10
国外科技新书评介(2014年7期)2014-12-01
摄影之友(2014年3期)2014-04-21
微型计算机(2009年4期)2009-12-23
数码摄影(2009年12期)2009-12-07
中国校外教育(上旬)(2009年6期)2009-08-04
