
全方位空间自闭症儿童眼动信号处理与分析
2022-10-11 08:52段慧煜任晓雨王琳琳史芳羽范磊翟广涛
信号处理 2022年9期
段慧煜 任晓雨 王琳琳 史芳羽 范磊 翟广涛
(1.上海交通大学图像通信与网络工程研究所,上海 200241;2.上海市董李凤美康健学校,上海 200233)
1 引言
孤独症谱系障碍(autism spectrum disorder,ASD),也称自闭症,是一种神经发育障碍,其主要特征包括表达困难、社会交往障碍、重复刻板的行为及狭隘的兴趣[1]。自闭症的致病原因目前尚不清楚。近年的流行病学调查数据显示,全球范围内自闭症患病率呈现上升趋势,患病率在1%左右。自闭症患者多预后不良,成年后缺乏独立生活的能力,给家庭和社会带来沉重负担。但研究发现早期确诊和早期干预治疗可显著改善自闭症患者的核心症状,呈现较好的预后效果[2]。
社会交往障碍被认为是自闭症的核心特征之一。作为社交障碍的重要表象,非典型的视觉注意经常出现在自闭症患者身上[3],即患有自闭症的人对各种视觉刺激,尤其是在有关社会交流活动的视觉刺激(如人脸、文字等)上经常表现出非典型的视觉注意[4]。因此,学习这种非典型的视觉注意可以帮助我们更好地了解自闭症。
针对自闭症患者视觉注意的研究已取得了一些成果。Dawson等人[4]证实自闭症患者对面部、声音、手势等社会性刺激的关注减少,对非社会性刺激的关注增加,且对社会和联合注意行为的减少。然而先前这些研究绝大部分都使用了限制性或非自然的刺激,如独立的面部和物体,或者是只有低语义特征的刺激,这限制了对自闭症共同特征的探索。
眼球运动编码了大量有关个体的注意力、动眼神经控制和个人心理因素的信息。与眼跳和注视有关的眼动特征已经被证明在识别精神状态、认知过程和神经病理学方面具有价值[5-7]。因此,分析自闭症儿童的眼球运动,能够在一定程度上描述自闭症的特征,有助于自闭症的诊断。
针对自闭症的眼球运动研究也取得了一些成果。Tseng 等人[6]的研究分析了人类观看短视频时的注视模式,将其与低层特征结合,证实了纳入视觉注意在识别特殊疾病方面的优势。但该工作并没有考虑高层语义特征和社会信息。随着机器学习的发展,高层语义特征可以很容易地被提取。Wang 等人[8]使用线性支持向量机(SVM),首次通过多层次特征量化了自闭症患者的非典型视觉注意,并证实自闭症患者的注视模式有更强的中央偏好,对低层特征的关注度更高,对高层语义特征的关注度更低。但该工作依赖于人工标记提取的特征。随着深度学习的快速发展,物体检测走向成熟,使机器提取物体特征成为可能。Liu 等人[9]提出了一种机器学习方法,基于他们在人脸识别任务中的注视模式,对自闭症患者与对照组进行分类。但该工作高度依赖于自闭症患者的现有认知,因此很难推广到不同教育水平的个体。随着深度神经网络(deep neural networks,DNN)的发展,对于自闭症患者非典型视觉注意的研究取得了很大进展。Jiang等人[10]应用深度神经网络提取了眼球运动特征,并用于微调一种显著性预测算法,以对被试进行分类,结果证明他们的工作获得了更好的表现。Duan 等人[11]建立了孤独症儿童显著性预测(SPCA)数据库,并微调了四个基于深度神经网络的显著性预测模型,以研究自闭症儿童的注视模式。
之前的针对自闭症眼动的研究还存在着一些共性的不足之处。例如,这些研究所采用的图像刺激都受限于研究人员的预期选择和摄影师的有限视野(field of view,FOV),而他们都不曾患有自闭症。此外,这些研究所使用的大多是在被试处于“被动”观察情况下的眼动数据,即在头部固定的状态下对平面图像进行观察的眼动数据。然而事实上,积极的观看条件影响知觉加工。在“被动”状态下,被试只能通过眼球运动探索单一视野的场景。相反,在“主动”状态下,人们会通过眼球转动、头部转动和身体运动积极地探索周边场景[12-13]。因此,这种“被动”状态下采集到的数据并不能完全展示出被试的视觉注意。并且这些平面图像大多显示在与现实世界相比视野受限且相对较小的屏幕上,对于这些图片和对于真实世界的语义感知依旧存在很大差异。现实中自闭症患者的视觉注意仍是未知的。
针对上述研究的不足,本文选择应用360°全景图像,在虚拟现实(VR)环境下收集眼球追踪数据,建立了首个大规模的全景图像ASD 眼动数据集;改进了三层显著性计算模型[14],使用物体检测和深度估计等算法取代人工标记,对数据集中所有图像的特征进行量化;从对不同特征的视觉关注度,到头眼运动的区别与联系,进行了对自闭症儿童在现实世界中非典型视觉注意的定性与定量分析,得出自闭症儿童的非典型视觉注意特征:对场景中的焦点和社会性信息的关注较低,且在人脸不突出且未表达出与观察者互动倾向的场景中,其视觉注意往往更局限;对图像深度、赤道及背景特征的关注度更高,对图像语义级特征的关注度更低;在室外场景中,中心偏好更弱,且更倾向于向下看;头眼运动的协调性更低等。这有助于进一步了解自闭症,也有助于相关的应用领域,如诊断[10,15]和预后康复[16]。
文中剩余内容分为四个部分,第一部分介绍了全景图像ASD 眼动数据集及其构建;第二部分介绍了改进的三层显著性计算模型;第三部分分析了自闭症儿童在现实世界中的非典型视觉注意;第四部分总结全文。
2 全景图像ASD眼动数据集介绍
2.1 全景图像与数据采集设备介绍
本实验从两个大规模全景图像数据集中选取了300 张高分辨率全景图像,其中85 张选自Salient360 数据集[17],215 张选自SUN360 数据集[18]。考虑到自闭症患者/非自闭症患者对社会性/非社会性刺激的视觉注意的差异,还平衡了数据集中各图像所包含的语义信息。如图1 所示,选取的图像中包含各种像素级、物体级和语义级信息,也囊括室内场景、室外场景、城市风景、自然风景、物体、人群等多种图像类别。

图1 本数据集中的图像样本Fig.1 Sample stimuli of the database
本实验使用HTC Vive Pro Eye 来展示全景图像刺激并收集眼动数据。该设备采用双OLED 显示器,分辨率为2880×1600 像素,视场角为110°,刷新率为90 Hz。该设备含有内置眼动仪,采用五点校准,数据输出频率(双目)为120 Hz,可以进行精准眼动态追踪。软件系统通过Unity3D 平台搭建,用于控制实验过程和记录所有数据。
2.2 被试介绍
本实验共有被试31 名,其中包括15 名自闭症儿童和16 名健康儿童(typically developing,TD)。所有自闭症被试都属中高功能自闭症,可以满足实验要求。自闭症被试的年龄从7 岁至13 岁不等,平均年龄为10.4 岁。健康儿童作为对照被试,年龄从7 岁至9.6 岁不等,平均年龄为8 岁。除年龄外,两组被试的性别、惯用手和表现智商也是匹配的。实验前,所有被试的父母都阅读并签署了知情同意书。实验中,所有被试的视力都正常或矫正正常。
2.3 实验过程
具体的实验过程包括以下几个步骤:VR 设备使用练习、校准和正式采集数据。在VR 设备练习阶段,被试佩戴VR 设备HTC Vive Pro Eye,首先进行两次全景图像的观察,以确保被试在开始正式实验之前已经适应了在虚拟环境中的观察。完成练习阶段之后,执行眼动仪校准程序,以验证眼球追踪的准确性,确保数据的可靠性。
关于正式眼动数据采集,目前有三种在VR 环境下进行眼球追踪实验的方法。Rai 等人[17]进行了被试坐立情况下自由探索场景的眼球追踪研究。Sitzmann等人[19]进行了被试在坐立和站立两种情况下自由探索场景的眼球追踪研究。Haskins 等人[20]选择在被试坐立情况下进行眼球追踪,但与此同时全景图像会以恒定速度旋转。考虑到自闭症儿童可能存在的认知和交流障碍,分别采取以下两种情况进行了两次实验:
站立情况:第一次实验中,被试在站立情况下,通过设备的头戴式显示器(HMD)自由观察探索200 张全景图像。考虑到ASD 被试缺乏耐心,和被试眼部疲劳会导致所采集数据准确性降低等问题,将实验划分为20 组,每组包含10 幅全景图像。实验过程中,每幅图像显示20 秒,图像之间有1 秒的灰屏作为分隔。一组10幅图像观察完成后,被试会进行短暂的休息。休息完毕后,再次执行眼动仪校准程序,校准完成后开始下一组图像观察。
坐立情况:由于Haskins 等人[20]的方法易引起眩晕,本文提出一种改进方法。第二次实验中,被试被指示坐在一个固定的椅子上观察100张全景图像。实验划分为10 组,每组包含10 幅全景图像,每幅图像显示20 秒,但每5 秒会旋转90°。其他设置均与站立情况相同。
在被试观察过程中,由设备自动记录被试的头动、眼动数据和时间戳等信息。
2.4 全景图像ASD眼动数据集介绍
全景图像ASD 眼动数据集包含300 张全景图像,以及相对应的眼动数据。目前为止,已采集到15名自闭症儿童与16名健康儿童观察300张图像所得到的总8639组有效眼动数据,因校准失败和因其他原因导致观察时长不足等异常数据已被去除。数据集中每张全景图像的平均观察者总数为28人,平均每张图片的自闭症观察者为12 人,健康观察者为16人。
眼动数据包含:时间戳、眼球注视点在观察球面上的三维直角坐标、头部所在位置的三维直角坐标和头部旋转的姿态角。
由于图像尺寸原因,最终只有299 张全景图像被用于后续研究。需要注意的是,为了规范计算,数据集中所有全景图像都被重新调整尺寸至900×450(宽×高)。
3 改进的三层显著性计算模型
本文改进的三层显著性计算模型如图2 所示。主要在所考虑图像特征及其提取方法上进行改进,使模型适用于自闭症儿童非典型视觉注意的分析。

图2 三层显著性计算模型概述Fig.2 Computational saliency model
3.1 图像特征的改进
为了更好地对比分析自闭症儿童在现实世界中的非典型视觉注意,高级特征十分关键。原三层显著性计算模型考虑像素级特征(颜色、亮度、方向),物体级特征(尺寸、复杂度、凸度、实心度、偏心率),语义级特征等三级特征,和背景特征[14]。针对全景图像ASD 眼动数据集,本文改进了三层显著性计算模型所考虑的图像特征,各特征的详细描述可见表1,具体改进如下所述:
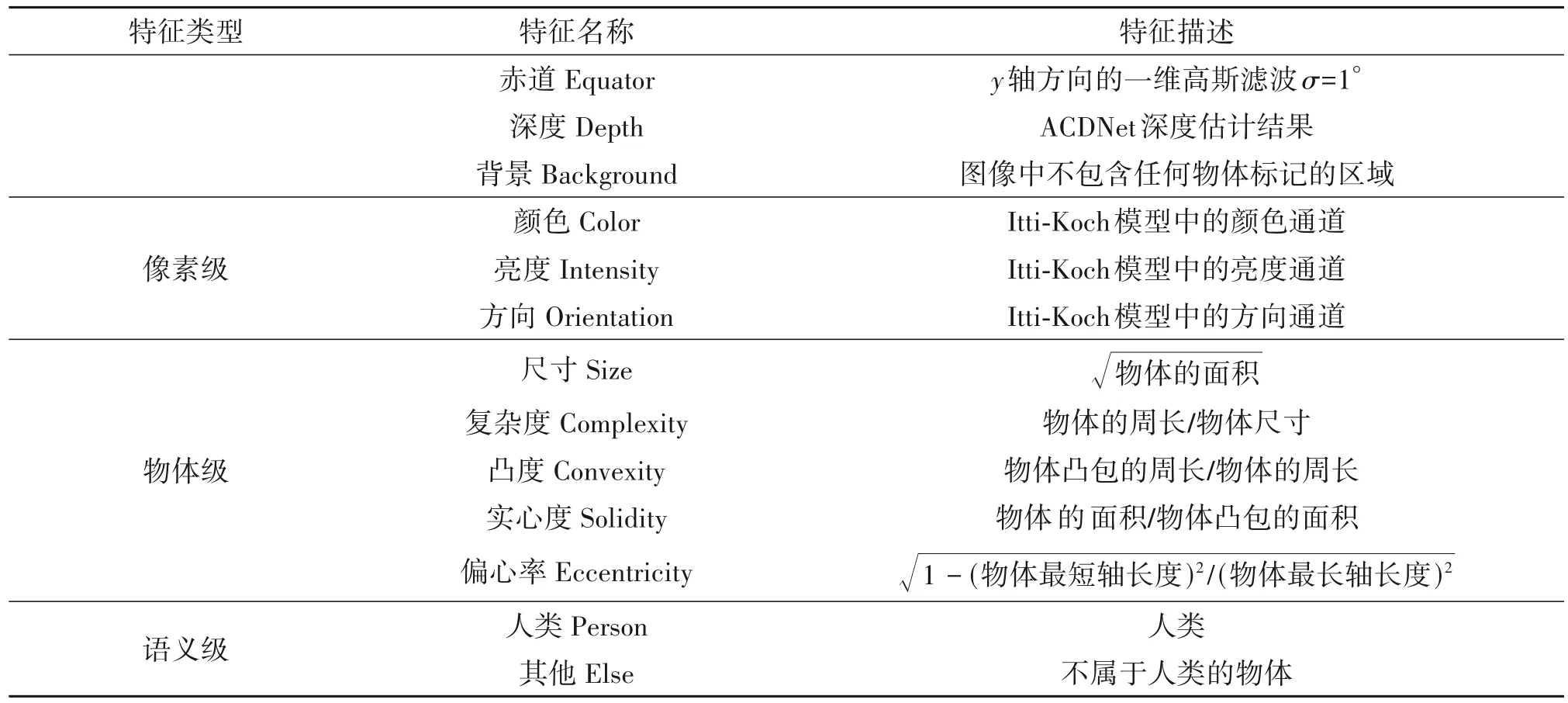
表1 三层显著性计算模型使用的图像特征总结[8]Tab.1 Summary of all features used in the three-layered computational saliency model[8]
(1)更改语义级特征的分类
比起物体级特征,人类更倾向于将视觉注意集中在语义实体上。人类和灵长类动物有专门的神经系统用来处理人类面孔这种视觉刺激[21]。研究表明,人类的视觉注意偏向于关注人类面部[22]。本文的主要研究目的不在于分析各语义级特征对视觉注意影响的差异。因此,本文假设各物体都具有一定语义属性,且只将“人类”这一语义属性单独考虑,其余语义属性都被归为“其他”。
对于数据集中每张包含物体的全景图像,对其所蕴含的语义级特征进行评分,1 代表该物体蕴含该语义级特征,0代表该物体不蕴含该语义级特征。
(2)增加全景图像赤道特征
Wang 等人[8]证实了人类的视觉注意更被平面图像的中心区域所吸引,而自闭症患者的注视模式有更强的中央偏好。Rai 等人[17]证实了对于全景图像观察,人类对图像赤道区域的注视更加频繁,却不显示对于特定经度的偏好。本文考虑被试对全景图像赤道区域的视觉注意。
(3)增加全景图像深度特征
研究表明,在三维场景中,深度这一线索被人类用于理解周围的环境,并在视觉显著性中发挥着重要作用[23-24]。
3.2 图像物体特征提取方法的改进
(1)像素级特征的提取
像素级特征图依旧根据Itti等人的算法生成[14]。
(2)物体级、语义级和背景特征的提取
关于显著性的一些重要特征只能通过物体的精细轮廓分割来测量。比如凸度是一个重要的物体级特征,低凸度的物体一般表示被其他物体所遮挡的物体。如果使用方形边界框,这个特征就会丢失。因此,需要数据集各图像中物体的种类及精细分割的掩膜。Xu 等人[14]使用了一种交互式手动物体分割工具[25]进行人工标记提取特征。但手动提取物体特征需要大量的人力和时间资源,且可能受到个人偏好的影响。
本文为了改进该不足,经过对比选择Cascade Mask R-CNN 物体检测算法,由于出现在本数据集中图像上的物体多为日常事物,故应用MMlab 开源代码库mmdetection 模块[26]中在coco 数据集上的预训练模型Cascade Mask R-CNN X-101-32x4d-FPN(具体参数见表2),来识别图像中所有像素点的类别。为每张全景图像中每个识别出的物体生成一张完整的mask 掩膜,包含该物体的像素点为1,其余为0;并标注了其蕴含的语义属性,如人类或其他物体。而没有包含任何物体的图像区域则被视为背景。

表2 预训练模型参数Tab.2 Pre-trained model parameters
物体级和语义级特征图的生成方法,是在每个物体的中心放置一个σ=12°的二维高斯核,选用依据与文章[14]相同。再与计算得出的物体级/语义级特征数值相乘,最后归一化得到物体级/语义级特征图。背景特征图的生成方法,是将图像上所有包含物体的像素点设为0,不包含物体的像素点设为1。
(3)全景图像深度特征的提取
为了提取深度特征,在全景图像ASD 眼动数据集上应用了SliceNet[27],BiFuse[28],UniFuse[29],Ho-HoNet[30],ACDNet[31]五种专为全景图像设计的深度估计算法,对比结果后,最终选择了在本数据集上表现最好的ACDNet。从结果中可以看出,此算法在室内和室外场景中均工作良好。但在全景图像南北两极处皆存在畸变情况,这是全景图像深度估计算法的通病。但在实际采集数据实验中,被试很少会观察天和地,也就是全景图像中南北两极的位置。因此,选择遍历深度图,用颜色最深处的灰度值覆盖每张深度图的畸变处,以生成最终的全景图像深度特征图。
(4)全景图像赤道特征的提取
全景图像赤道特征图的生成方法为:首先生成一张900×450 的全黑图片,将图片赤道设成1,再在经度方向上应用σ=1°的一维高斯滤波。
3.3 模型训练
本文使用SVM 来评估六个因素对视觉注意分配的影响程度:全景图像赤道特征、全景图像深度特征、背景特征、像素级特征、物体级特征以及语义级特征。相应特征图被用来训练三层显著性计算模型(见图2)。为了训练和测试这个模型,将数据集分为240张训练图像和59张测试图像[14]。
需要注意的是,由于等距柱状投影的全景图像并不能完全反映被试在VR 环境下看到的真实场景[32],且在南北两极处存在畸变,本文将等距柱状投影的全景图像分割成六个立方投影,并在立方投影上也完成了特征提取工作。事实上,在训练模型的过程中使用到的特征图,除了全景图像赤道和深度的特征图以外,都是由立方投影的特征图再转成等距柱状投影的。具体过程如下:
首先,基于全景图像ASD 眼动数据集中的眼动数据,生成对应的注视点图,注视点密度图,以及热度图。
然后,计算出数据集中每张全景图像的赤道和深度特征图。再将全景图像转换为立方投影,计算出对应的像素级、物体级、语义级以及背景特征图,再将这些立方投影的特征图转回等距柱状投影。
最后,分别对于ASD 组和TD 组的数据,完成两个三层显著性计算模型的训练和测试,得出显著性权重。
4 自闭症儿童非典型视觉注意的分析
4.1 自闭症儿童的观察特征
基于全景图像ASD 眼动数据集,本文对比不同场景中自闭症儿童和健康儿童的视觉注意分布热度图,以分析其视觉注意的差异和相似性。如图3所示,热度越高,被试注视该区域的时间越长。
图3(a)~图3(c)表明,比起健康儿童,自闭症儿童对人脸的视觉注意集中程度更低,相对来说目光更为发散。此外,自闭症儿童还会被场景中人脸以外的物体所吸引,比如图3(a)中的方向盘,图3(b)中的挂画和图3(c)中的树。图3(d)~图3(h)展现了自闭症患者的核心特征,即社会交往障碍,他们对非社会性信息的视觉注意增加,而健康儿童则倾向于对社会性信息给予更多的关注。另外,如图3(d)和图3(g),在人脸不突出且未表达出与观察者互动倾向的场景中,健康儿童的注意力分布范围较广,而自闭症儿童往往局限于某个或某些部分,从这个角度来说,健康儿童比自闭症儿童表现出对整个场景更强的探索行为。并且,如图3(g)和图3(h)所示,自闭症儿童比较缺乏信息整合的能力,他们对场景中主要焦点的关注度降低。图3(i)和图3(j)表明,对于不含人的室外场景、语义信息的空间分布相对均匀的场景,或者是非社交场景来说,自闭症儿童和健康儿童在整个场景中的全局视觉注意是相似的。

图3 不同场景中自闭症儿童(上)和健康儿童(下)的视觉注意分布热度图Fig.3 Visual attention of autistic children(top)and healthy controls(bottom)
4.2 自闭症儿童非典型视觉注意的定量分析
三层显著性计算模型为每个特征输出一个显著性权重,代表该特征对预测视觉注意力分配的相对贡献。从图4 中可以看出,两组被试观察图像时都有较强的赤道偏好,这是符合预期的。值得注意的是,自闭症儿童对于图像赤道特征的偏向明显更强,但是对于语义级特征的偏向明显减低。
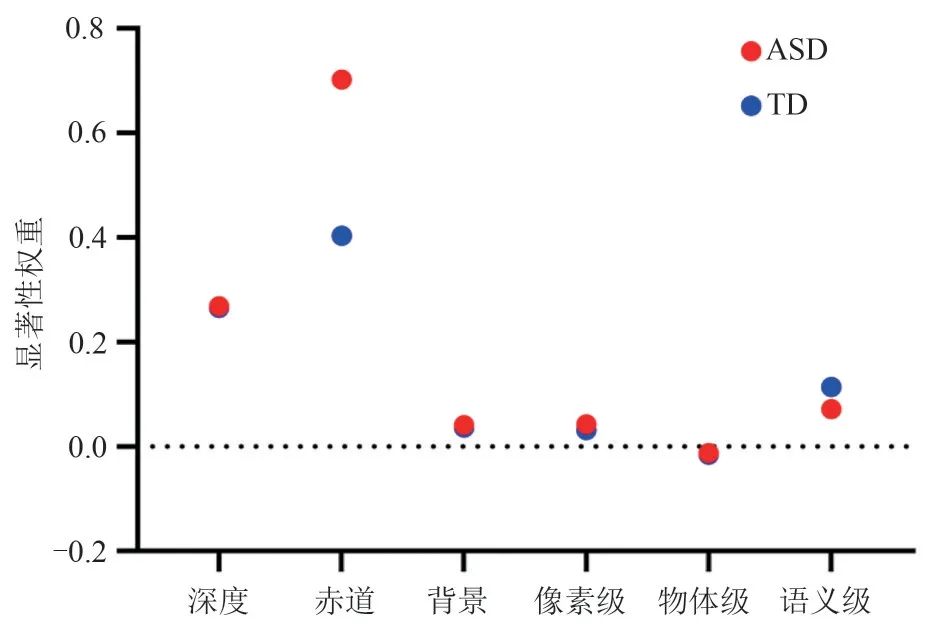
图4 分组特征的显著性权重Fig.4 Saliency weights of subgroup features
本文也针对两组眼动数据生成的注视点密度图和特征图,计算了常用的显著性评价指标,即CC、SIM 和NSS,统计细节见图5(星号*表示经过U 检验,自闭症与健康受试者的数据存在显著差异:*p<0.05,**p<0.01,***p<0.001)。可以看出自闭症儿童对于全景图像深度、赤道和背景这三个特征的偏好更强,这验证了上一节中定性分析自闭症儿童观察特征的结论,即自闭症儿童会减少对图像中物体的关注,而倾向于关注不含任何语义信息的图像背景。还验证了先前研究得出的自闭症儿童的注视模式特征,即他们有更强的中央偏好(对于全景图像来说为赤道偏好),且倾向于观察更远的地方[8]。此外,对于赤道特征来说,三个评价指标的对比都具有统计意义,因此进一步研究自闭症儿童与健康儿童的赤道偏好是有意义的。
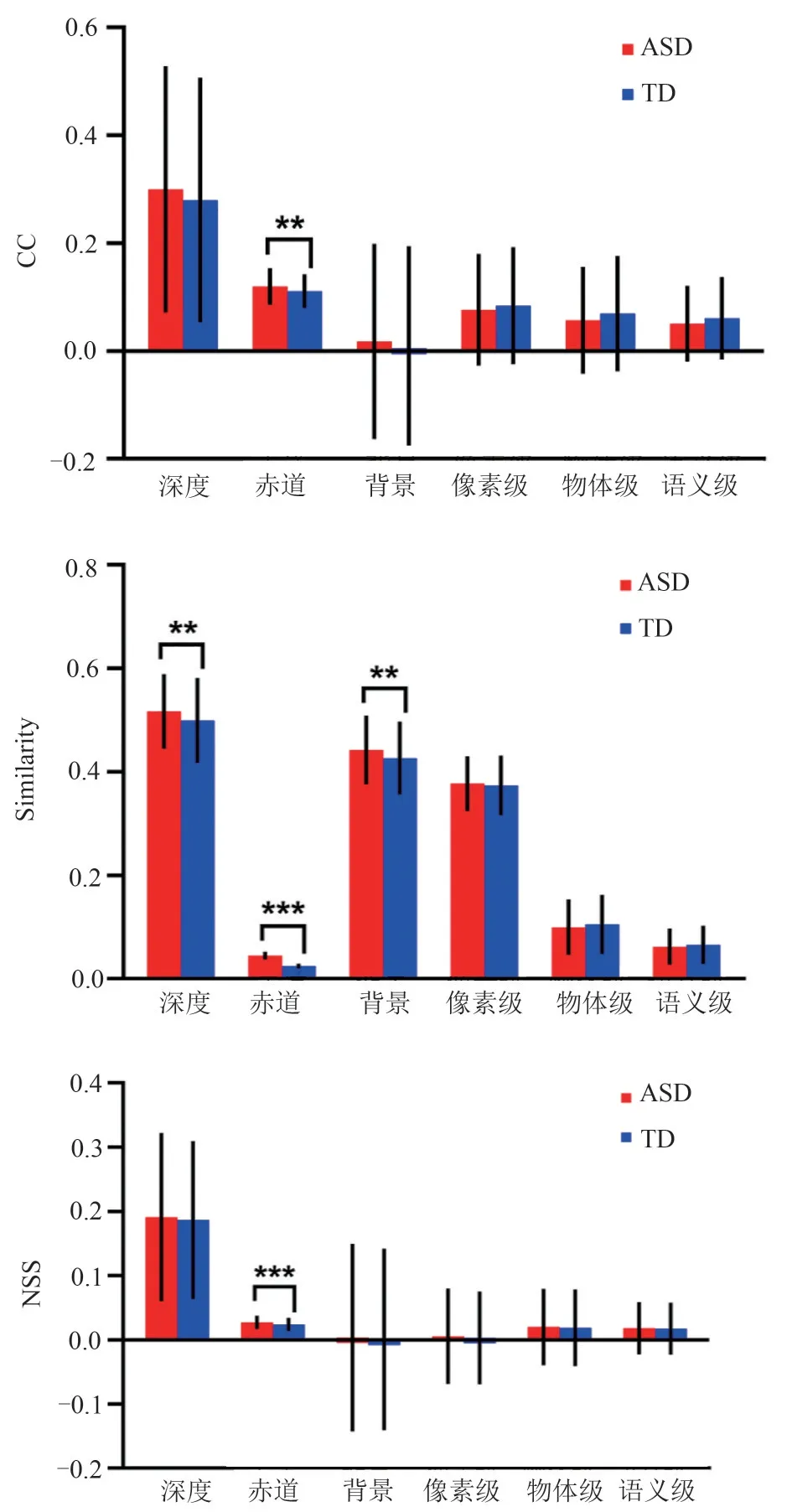
图5 分组特征的显著性评价指标Fig.5 Saliency metrics of subgroup features
为了分析自闭症儿童与健康儿童的赤道偏好,本文计算了每张全景图像的注视点的纬度,以1°为最小区间,统计每个区间内注视点的数量,最后将全部图像的注视点数量相加得到总和,进行归一化处理后,得到两组被试注视点频率关于纬度的分布图,如图6(a)和图6(b)所示。可以看出对于本数据集而言,两组被试在全景图像上的视觉注意力分布都是赤道附近最多,向两极呈递减趋势。并且,两组被试都有向下看的倾向。
Fang 等人[15]证实,对于高层语义信息含量较低的室外场景,如街道场景和自然场景,健康儿童的中心偏好往往更明显。本文选取了数据集中符合条件的75张图像,并同样得出该类型场景下两组被试注视点频率关于纬度的分布图,如图6(c)与图6(d)所示。可以看出在这类场景中,健康儿童注视模式对于赤道附近区域的偏向更加显著。此外,自闭症儿童向下看的偏好更加明显。通过高斯拟合(拟合系数见表3)可以得出,自闭症儿童注视点的纬度中心更靠下,且其拟合曲线的宽度更宽。这也许可以说明在室外场景中,自闭症儿童的“赤道集中”偏好没有健康儿童强烈。

表3 高斯函数拟合系数(室外场景)Tab.3 Gaussian function fitting coefficients(outdoor scenes)
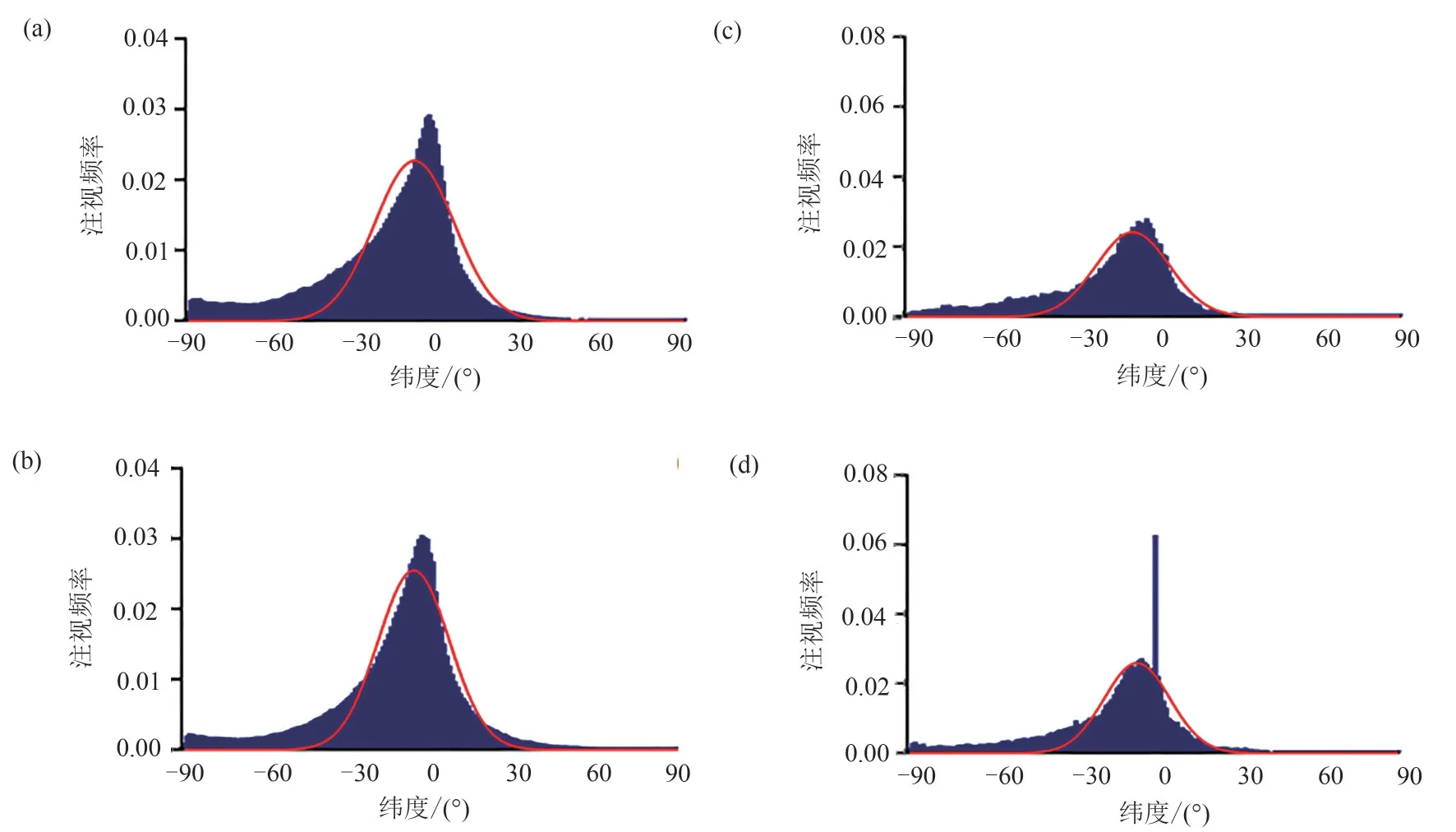
图6 注视点频率关于纬度的分布图及其高斯拟合((a):ASD,(b):TD,(c):ASD室外,(d):TD室外)Fig.6 Frequency of fixations for each latitude and Gaussian curve approximation((a):ASD,(b):TD,(c):ASD outdoor,(d):TD outdoor)
4.3 头眼运动的区别与联系
眼球运动通常受到头部运动的影响,头部运动与眼球运动通常是相关联的[33]。事实上,在VR 环境中观察全景图像时,眼前显示的场景会随着头部的旋转和身体的平移而发生相应的变化[17]。因此,研究头部运动及眼球运动的协调性,也有助于分析自闭症儿童的非典型视觉注意。
为了研究头眼运动的区别与联系,生成了基于头部运动的“注视点密度图”和热度图,部分热度图如图7 所示。可以看出对于两组被试而言,头部运动和眼球运动的存在范围基本一致,符合头眼运动的协调性。但是头眼运动得出的热度图也存在差异。首先,两组热度图的注视焦点,即热度最高的区域的中心位置存在偏差。因为根据头动数据生成头动“注视点密度图”,是基于眼球注视点为头部所对视口的中心点这一假设的,然而事实上在探索场景时,被试的眼球并不总是正视前方。此外,头动热度图在分布上呈连续趋势,而眼动热度图呈点状分布的特点。这是因为在观察过程中,头部的运动趋势比较平缓,大多是连续的过程,而眼球的运动相比之下更具有跳跃性,从一个注视点到另一个注视点的空间跨度更大。经过对两组头眼运动热度图,可以发现自闭症儿童头部运动与眼球运动的协调性更低。这可以从某些角度解释一个通常的现象,即自闭症在社交时,其面部朝向社交事物,而眼睛看向其他方向。

图7 头动热度图(上)与眼动热度图(下)Fig.7 Heat map of head movement(top)and heat map of eye movement(bottom)
在整个数据集上,计算了每幅图像所对应的头动与眼动“注视点密度图”之间的CC,结果如图8 所示。可以得出自闭症儿童比健康儿童的头眼运动的相关性更低,自闭症儿童的头眼运动协调性低于健康儿童。

图8 头动和眼动“注视点密度图”的相关系数分布Fig.8 CC between the fixation density map of head movement and the fixation density map of eye movement
5 结论
本文构建了首个全景图像ASD 眼动数据集。基于该数据集,改进了三层显著性计算模型,使其更适用于自闭症儿童眼动分析。通过对比分析,得出自闭症儿童的非典型视觉注意特征:对场景中的焦点和社会性信息的关注较低,且在人脸不突出且未表达出与观察者互动倾向的场景中,其视觉注意往往更局限;对图像深度、赤道及背景特征的关注度更高,对图像语义级特征的关注度更低;在室外场景中,中心偏好更弱,且更倾向于向下看;头眼运动的协调性更低。本文得出的结论有助于了解自闭症,眼动分析或许有助于自闭症新型诊断工具的开发。但分析方向不够全面,今后的研究中需要通过增加对被试的个人情况(如智商、逆商和年龄)、注视点演变、凝视时长等,和各图像特征之间的相互影响的分析,进一步得出自闭症视觉注意的特征。
猜你喜欢
汽车实用技术(2022年7期)2022-04-20
载人航天(2021年5期)2021-11-20
家庭影院技术(2021年6期)2021-07-28
文萃报·周五版(2021年14期)2021-06-08
科教新报(2021年14期)2021-05-11
大自然探索(2019年7期)2019-12-13
英美文学研究论丛(2018年1期)2018-08-16
海峡姐妹(2018年5期)2018-05-14
海峡姐妹(2017年5期)2017-06-05
特别文摘(2016年21期)2016-12-05
