
耦合平均影响值-连续投影算法优化种子活力近红外检测模型
2022-10-09 08:14杨冬风李爱传刘金明陈争光
光谱学与光谱分析 2022年10期
杨冬风, 李爱传, 刘金明, 陈争光, 时 闯, 胡 军
1.黑龙江八一农垦大学信息与电气工程学院, 黑龙江 大庆 163319 2.黑龙江八一农垦大学工程学院, 黑龙江 大庆 163319
引 言
种子活力是指种子的潜在发芽能力或者种胚所具有的生命力,是预期种子具有长成正常幼苗的潜在能力。种子活力水平测定在育种、种子生产、种子加工、种子收购、种子贮藏、种子检验及种子调运等环节中是不可缺少的重要方法[1]。国际种子检验协会规定的常规种子活力测定方法主要有标准发芽试验、四唑染色试验、离体胚测定法、电导率测定法等。上述方法不仅检测周期长、操作步骤复杂,而且都是有损检测。
近红外光谱(near infrared spectroscopy,NIRS)涵盖了有机分子的倍频与合频的吸收光谱,能够反映分子的结构、组成和状态信息。随着NIRS技术在农业领域研究的不断深入,NIRS技术也开始在种子活力无损检测中崭露头角。Maythem等[2]采用偏最小二乘(partial least squares,PLS)建立大豆种子活力的等级预测模型,对于两种等级(高、低)活力的预测准确率在85.7%~89.7%之间,对三种等级(高、中、低)活力预测时,不能正确区分高活力和中等活力种子。He等[3]采用极限学习机(extreme learning machine,ELM)模型对三种不同年份的水稻种子进行鉴别,鉴别精度较高;采用连续投影算法(successive projection algorithm, SPA)结合支持向量机(support vector machine,SVM)从不同年份的可存活种子中鉴定出不可存活的种子,其分类准确率达94.38%。李武等[4]利用前向间隔偏最小二乘(forward interval partial least squares,FiPLS)、竞争自适应重加权(competitive adaptive reweighted sampling,CARS)、无信息变量消除(uninformative variable elimination,UVE)等变量筛选方法对甜玉米种子的近红外光谱进行特征波长区域选择,采用PLS建立发芽率、发芽指数和活力指数的预测模型,取得了较好的预测效果。金文玲等[5]利用主成分分析(principal component analysis,PCA)结合PLS建立带稃壳水稻种子的近红外超连续激光光谱的预测模型,对3种不同年份的水稻种子进行分类,训练集和预测集的准确率分别为94.44%和95.92%。
从以上研究中可以看出,NIRS技术在种子活力检测方面是有效的,可以对3种活力等级的种子进行较为准确的区分。采用的建模方法主要是适合于线性预测的PLS和适合于小样本分类的SVM,而适合于非线性大样本建模的BP神经网络用的不多。从目前的文献来看,种子活力检测所采用的特征波长优选方法只有少数的几种常规算法,譬如SPA,CARS以及UVE等,或几种方法的简单组合。以上两点使得目前的种子活力检测陷于等级少(3个等级以下)、检测精度不够高的状况。
在NIRS分析领域,特征波长优选和预测方法的确定始终是决定模型优劣的关键。针对不同研究对象,学者们采用不同的波长选择方法[6-8]、多种选择方法组合[9-11]、改进的选择方法[12-13]以及不同的预测方法[14-17]以增强模型的鲁棒性和准确性。为了构建多等级、高精度的种子活力检测模型,首先对SPA算法加以改进得到自适应SPA(SPAsa),然后对在BP神经网络中评价输入变量对结果影响较为有效的指标—平均影响值(mean impact value, MIV)加以优化得到MIVopt方法,将MIVopt与SPAsa算法进行耦合,建立既适合线性模型又适合非线性模型的特征波长提取方法MIVopt-SPAsa。然后建立全谱、MIV、SPAsa、MIVopt-SPAsa和CARS的BP预测模型并比较模型的预测精度和效率,以证明MIVopt-SPAsa算法优化近红外种子活力检测模型的有效性。
1 MIVopt-SPAsa算法原理
1.1 SPA算法
SPA算法[18]是一种基于变量信息的变量降维技术,它利用向量的投影分析来寻找含有最低冗余信息的变量组合,能够有效地消除光谱波长共线性、奇异性和不稳定性的影响,使向量间的共线性达到最小,减少建模所用变量的个数,降低模型复杂度。对于光谱矩阵Xn×m(n为样本数,m为光谱变量数),首先设定待选特征变量个数H,然后执行以下步骤:
(1)初始迭代t=1时,在光谱矩阵中任选一列向量xj,记为xk(0),k(0)为所选变量的最初位置(j=k(0),1≤j≤m),则其他剩余变量位置的集合定义为s
s={j,1≤j≤m,j∉{k(0),…,k(H-1)}}
(1)
(2)计算剩余列向量xj(j∈s)在所选向量xk(t-1)构成的正交向量空间中的投影
(2)
xj=Pxj
(3)
其中,I为单位矩阵;P为投影算子。
(3)提取最大投影值变量arg[max(‖Pxj‖)],j∈s,加入所选变量集。
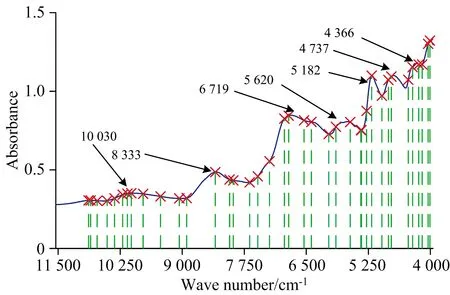
(4)t=t+1,如果t 当循环终止时,得到的变量集合{xk(0),xk(1),…,xk(H)}就是选取的特征波长集合。因为迭代的第一个变量xk(0)是随机选取的,因此令光谱中的每个波长都作一次初始变量,进行上述迭代,每次迭代选取H个变量,即可得到n×H维矩阵X={X1,X2,…,Xn}T,此矩阵为基于n个初始变量的迭代所选取的n个候选变量集。然后对每个变量集进行PLS交叉验证,得到交叉验证均方根误差RMSECVj(1≤j≤n),取最小的RMSECV所对应的k(0)和所选出的变量组合,即为最终筛选出的最优组合。 SPA方法在特征波长选择方面具有一定的优势,但存在两方面的不足:一是候选变量个数的确定没有标准,H过小会造成所选变量不能包含光谱中的大部分关键信息,而由于变量之间的共线性,H又不能设置过大以至于超过独立变量的个数,因此需要寻找取得最优H值的方法;二是将每一个光谱变量都作为初始变量进行迭代,得到备选变量组合,之后要对每组变量进行PLS交叉验证,当光谱变量较多时,算法的效率不高,需要寻找合适的降维方法,在SPA之前对光谱数据进行预降维。针对H确定的问题,采取的改进方法如下: (1)令H在某个合理的范围[M,N]内变化,得到N-M组最小RMSECVi(1≤i≤N-M)和对应的变量组合。 (2)从中选取最小RMSECVi所对应的H以及变量组合。 这样获取的H值具有区域范围的最优性,称之为自适应(Self Adaption)SPA,简称SPAsa。 针对SPA预降维的问题,提出一种改进的平均影响值(MIV)方法。MIV方法[19]最初由Dombi提出,用于表示神经网络中权重矩阵的变化,且可用于评估输入变量对神经网络模型性能的影响,通常应用于质谱分析、生物医学中[20-21]。本研究中的最终建模方法采用BP神经网络,使用MIV方法可以精确给出波长变量对种子活力等级影响程度的排序,然后使用SPA方法从排序靠前的波长中进一步进行优选,达到提高算法效率的目的。MIV的具体步骤如下,对于光谱矩阵Xn×m(n为样本数,m为光谱变量数)有: (1)首先采用全谱BP建模,训练出预测准确率超过90%的模型。 (4) (5) (5)对得到的平均影响值进行排序。 MIV方法可以得到波长变量的平均影响值排序,但如何确定序列前多少个波长作为有效波长不同文献的方法不一。李大虎等[22]采用相对贡献率来表征某个因素的MIV值对于全部因素MIV总和的百分比。在其研究中,全部因素只有9个,以相对贡献率超过10%作为特征筛选的依据可以有效地实现BP神经网络输入特征的筛选。但对于数目众多的近红外全谱数据来说,每个波长的相对贡献率很小且相互之间的差异不大,以相对贡献率作为筛选指标不够妥当。因此,提出相对距离比δj作为选择标准 (6) 将优化的MIV算法MIVopt对全谱BP模型进行平均影响值排序及选择,得到的光谱变量作为SPAsa算法的输入,由此降低SPA算法的循环次数,提高波长选择的效率。耦合MIVopt-SPAsa算法是一种基于变量信息的波长选择方法,在MIVopt阶段,将非线性的BP模型预测用于平均影响值排序,剔除了非线性模型无关的波长变量;在SPAsa阶段,使用相对全谱变量较少的波长变量,并采用线性的PLS作为交叉验证,剔除了与线性模型无关的波长变量,并进行自适应的筛选,得到最优的波长变量组合。 实验用种子样本购自大庆市萨尔图萨中种子公司,为黑龙江省农垦科学院作物所玉米育种研究室杂交培育的垦粘一号玉米品种。实验用仪器如图1所示。(a)是近红外光谱采集仪器,为德国Bruker公司Tango近红外光谱仪,采用积分球漫反射测量方式,分辨率为8 cm-1,样品和背景的扫描时间均为32 s,谱区范围11 550~3 950 cm-1,每条光谱采集的数据点数为1 845个;(b)是科文KW-TH型种子老化(恒温恒湿)实验箱;(c)是上海菁华公司JA2003N高精度电子天平,精确到1 mg;(d)是近红外光谱仪配套的IN312-SHD0型量杯。光谱分析及建模采用的软件主要使用挪威CAMO公司的UnscrambX10.3和美国MathWorks公司的Matlab R2020。 图1 近红外光谱仪(a),老化实验箱(b),电子秤(c)和IN312-SHD0量杯(d) 种子在自然条件下的贮藏时间越长,种子的活力和生活力下降的越快。研究表明,人工加速老化与自然老化对种子内部物质含量及结构的影响差异不大,且发芽情况相近。将种子置于干燥(湿度低于10%)、低温(温度10~20℃)的环境中保存备用,实验前对种子进行筛选,清除干瘪、瘦小、损伤以及腐坏的种子,选出健康、饱满的种子总计5 000 g。Tango采集颗粒状样本时,要求样本的容量要达到量杯容量的2/3以上,以此确定每个样本的种子质量为(37.0±0.3)g,用高精度电子秤量出。将种子共分为5组(D0,D2,D4,D6,D8),D0组样本15个,不进行老化处理;其余各组每组样本13个,进行不同程度的老化处理,将样本装入尼龙袋中并编号。根据《国际种子检验规程》中对玉米种子人工加速老化测定的规定,将样本放入高温高湿老化箱中,薄层平铺于老化箱的网架上进行老化,温度设为41 ℃,相对湿度设为99%,5组样本的老化时间分别为0,48,96,144和192 h。 使用积分球漫反射测量方式采集光谱数据,为了扩大样本数目,将每个样本重复装样3次(每次装样都要将样本翻动摇匀)测3条光谱取平均。所有样本光谱采集的环境条件相同:温度22 ℃,相对湿度30%。采样点数为1 845个,开始波数为11 542.16 cm-1,结束波数为3 926.249 cm-1,采样间距为4.119 cm-1。 采集共得到402条光谱数据,如图2所示。可以看出,不同老化时间的样本光谱的整体趋势、波峰位置高度相似,属于高相似度样本分类问题。 图2 402个玉米种子样本光谱图 测量的样品光谱中除了包含样品的真实信息还包括与仪器响应、测试条件和光的散射等有关的背景信息[23],这些信息导致了光谱噪声和基线漂移。因此,在建立种子活力检测模型之前,进行光谱预处理以削弱各种背景信息对真实光谱的影响、降低模型的复杂度并提高模型的稳健性是十分必要的。在进行预处理方法选择时,首先使用高斯滤波(guassian filter,GS)、卷积平滑(Savitzky-Golay,SG)平滑、多元散射校正(multiplicative scatter correction,MSC)、标准正态变量变换(standard normal variate,SNV)方法及其组合对原始光谱进行预处理,然后使用Kennard-Stone(KS)法将预处理后的光谱按3∶1划分为训练集和预测集,最后建立全谱BP预测模型并根据模型性能确定种子活力分级所采用的预处理方法。 由表1可知,在光谱平滑处理时,SG平滑消除随机噪声的效果较GS好,SNV消除样品颗粒大小和表面散射光的影响优于MSC,组合预处理方法SG-SNV的模型表现最优,训练集的准确率达到92.53%,预测集的准确率达到90.18%。组合预处理之后的光谱如图3所示,与原始光谱相比减弱了噪声干扰和光谱散射问题,吸收峰的位置更加清晰。在波长8 210,6 846,5 182,4 737和4 366 cm-1处有5个显著的吸收峰。吸收峰在光谱的低频部分更为频繁,吸光度随着波数的减少而增加。 表1 不同预处理方法的BP全谱模型建模结果 图3 SG-SNV预处理之后的光谱曲线 首先利用经典SPA对全谱数据进行特征选择,设置选择变量数20个,采用PLS交叉验证择优,其中校正集样本282个,预测集样本120个。 图4显示了SPA根据交叉验证均方根误差(RMSECV)从1 845个变量中选出的20个波长变量的位置。从图中可以看出,选中的波长集中在光谱第一个波峰附近,只有几个波长分布在其他几个吸收峰附近,这些特征波长所携带的信息量明显缺失,此时的交叉验证误差RMSECV为0.714 7,SPA波长选择的时间为12.125 3 s。当设置选择变量数为26时的交叉验证误差RMSECV为0.685 0,SPA波长选择的时间为14.417 5 s;当设置选择变量数为35时的交叉验证误差RMSECV为0.669 1,SPA波长选择的时间为16.824 3 s。由此可见,设置不同的变量数得到的最小RMSECV是变化的,总的趋势是随着选择变量数的增加而减小,但什么时候RMSECV达到最小,很难通过不系统的抽样式的SPA选择来确定。 图4 设置20个选择变量的SPA所选择的变量 下面采用SPAsa进行波长变量选择,设定H的变化范围为[1, 80],校正集和预测集样本的设定保持不变,变量的选择结果如图5(a)所示,此时选中波长在各个吸收峰的附近都有分布,提取的信息比较均衡。在H变化过程中,以选择的变量数为横坐标,以RMSECV为纵坐标,绘制RMSECV随变量数变化的趋势图,如图5(b)所示。当选择变量数增加时,RMSECV最小值是逐渐减小的,当变量数达到47时,RMSECV值达到最小0.6217;当变量数继续增加时,RMSECV趋向于稳定。当变量数增加到接近80,继续增加会引入与预测值无关的波长变量或具有较大噪声的变量,此时RMSECV会急剧增加。 图5 SPAsa特征波长选择结果(a)和SPAsa波长选择中RMSECV随设定变量的个数的变化(b) 由于SPAsa需要在H的一定范围内反复进行SPA操作,因此其运算时间相当于多次SPA的时间累加。当光谱数据量较大时,算法的运行时间较长,因此对其进行预降维十分必要。下面首先对11 542.16~3 926.249 cm-1范围的光谱数据进行MIV平均影响值计算,MIV影响值随波长的分布如图6所示。 由图6可见,不同波长变量的MIV数值差异较大,为了去除与种子活力信息无关或相关性较小的波长,根据式(6)计算各个波长对应的相对距离比,选取的波长变量作为SPAsa的备选光谱数据。为了找到最佳的D,建立选取的波长数、BP模型预测的准确率随D变化的关系,如图7所示。 图6 全谱数据的MIV值分布 图7 MIVopt预降维 从图7可以看出,D值的范围从0.05开始逐渐增加,随着D值增加,选择的波长数逐渐减少,BP模型的预测准确率开始时逐渐增大,而后逐步降低。当D值在0.35附近时,预测准确率达到94.31%,当D值取0.40时,预测准确率变为94.28%。让D值在[0.35,0.40]范围内以步长0.01变化,求得对应的预测准确率。当D为0.37时达到预测准确率最大值94.79%,此时选择的变量数目为644个。以这644个变量作为SPAsa的备选光谱数据,设定SPAsa的优选变量个数小于75个,校正集和预测集样本数目保持282和120个不变,经过SPAsa共筛选出变量37个,此时PLS模型的RMSECV为0.504 9,运算时间为14.357 s。 如图8所示,筛选出的特征波长主要集中在7个波峰附近。在4 000~4 500 cm-1波段,以4 235为中心,左右分布着4 165和4 358等几个特征波长,此波段为玉米脂肪C—H基团的吸收峰。在4 600~5 500 cm-1波段,以5 000为中心,两侧各有一个波峰,分布着4 787,4 844,4 976,5 182和5 285等特征波长,此波段为玉米蛋白质N—H基团及淀粉O—H基团的合频吸收峰区。在5 500~7 500 cm-1波段,有两个波峰,一个以5 620为中心,两边分布着5 615和5 903等特征波长;一个以6 719为中心,两侧分布着6 397,6 546,6 854和6 941等特征波长,此吸收峰是水份的倍频吸收区。在8 000~9 000 cm-1波段,以8 333为中心,分布着7 971,8 045和8 910等特征波长,此波段为玉米淀粉甲基C—H基团二级倍频的吸收谱带。在9 000~11 000 cm-1波段有一个波峰,以10 030为中心,两侧分布着9 437,9 787,10 200,10 360和10 510等特征波长,此波段是淀粉甲基C—H基团三级倍频及组合频的吸收谱带。 图8 MIVopt-SPAsa筛选出的特征波长分布 由上述分析可知,MIVopt-SPAsa优选得到的特征波长分布与玉米种子生化物质构成有着高度的一致性,具有明显的物理意义,可以体现玉米老化过程中种子内部物质组成的变化;实现光谱数据的大幅度降维,是一种有效的基于变量信息的特征提取方法。 BP神经网络能学习和存贮大量的输入-输出模式映射关系,而无需揭示描述这种映射关系的数学方程。其学习规则为梯度下降法,通过反向传播不断调整网络的权值和阈值,使网络的误差平方和最小[24]。本研究采用三层的BP网络,隐层采用sigmoid激活函数,输出层采用softmax损失函数,训练算法采用比例共轭梯度反向传播算法。样本集划分方法采用KS法,训练集和预测集的比例为3∶1,将402个样本数据划分为训练集(282)、预测集(120),最大迭代次数设为1 000。 为了对比全谱、MIV、SPAsa、耦合MIVopt-SPAsa以及目前为许多学者青睐的CARS波长提取方法对模型性能的影响,建立了5个BP模型,Full-BP、MIV-BP、SPAsa-BP和MIVopt-SPAsa-BP以及CARS-BP。待输入的光谱数据均经过SG-SNV预处理,模型的最佳隐层节点数根据经验公式和数据实测综合确定。所依据的经验公式为 (7) 式(7)中,m为隐层节点数;n为输入层节点数;l为输出层节点数,α为1~10之间的常数。 表征模型效率的评价指标是运算时间;表征模型精度的指标有准确率和交叉熵(cross-entropy, CE),每个模型都经过50次训练,各个指标取平均来表征模型最终性能,5种模型的性能对比如表2所示。 表2 5种模型的性能对比 从表2可以看出,全谱模型的总的运算时间最少,其次是MIVopt-SPAsa-BP,效率最低的是SPAsa-BP。这是因为具有相同输入变量的SPAsa算法与BP的运算时间相比要大得多,对于具有1 845个输入的BP来说,其运算时间一般是几十毫秒,而SPAsa-BP一般要达到100 s左右,而具有1 845个输入的MIVopt-SPAsa-BP的运算时间一般是十几秒。从模型的准确性和稳健性来看,MIVopt-SPAsa-BP模型的准确率可达99%以上,最佳交叉熵为0.007 892远远小于另外4个模型。 以提高玉米种子活力等级预测模型性能为目标,从优化特征波长提取的角度改进BP模型,提出了耦合MIVopt-SPAsa特征波长提取算法。该算法综合了MIV算法和SPA算法的优点,在MIV算法中引入相对距离比这个评价指标为数据降维提供了有效的衡量标准;在SPA算法中设定提取波长数量的范围,在此范围内优中选优,有效地解决了SPA算法特征波长数量确定的问题。由于在本质上SPA算法是一种基于偏最小二乘模型的特征提取方法,而MIV算法是一种评估输入变量对BP模型影响的算法,因此,耦合的MIVopt-SPAsa算法融入了线性和非线性预测模型的内核,该算法对适合于线性模型和非线性模型预测的基于信息的特征波长提取兼收并蓄,提取出与玉米种子生化物质NIRS吸收特性一致的特征波长分布,极大地提高了BP预测模型的精度和稳健性,为基于信息的光谱数据特征波长提取提供了新思路。该算法需要进一步改进的地方是SPAsa的运算效率不够高,在建立算法数据结构以及存取数据时进一步优化代码量并降低运算次数是解决该问题的关键。1.2 改进的SPA算法(SPAsa)
1.3 优化的MIV方法(MIVopt)

1.4 耦合MIVopt-SPAsa算法
2 实验部分
2.1 材料与仪器

2.2 玉米种子老化实验
2.3 光谱数据采集
3 结果与讨论
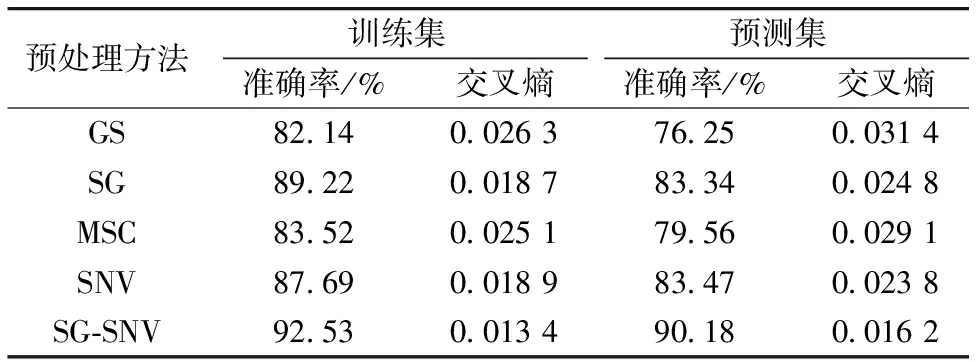
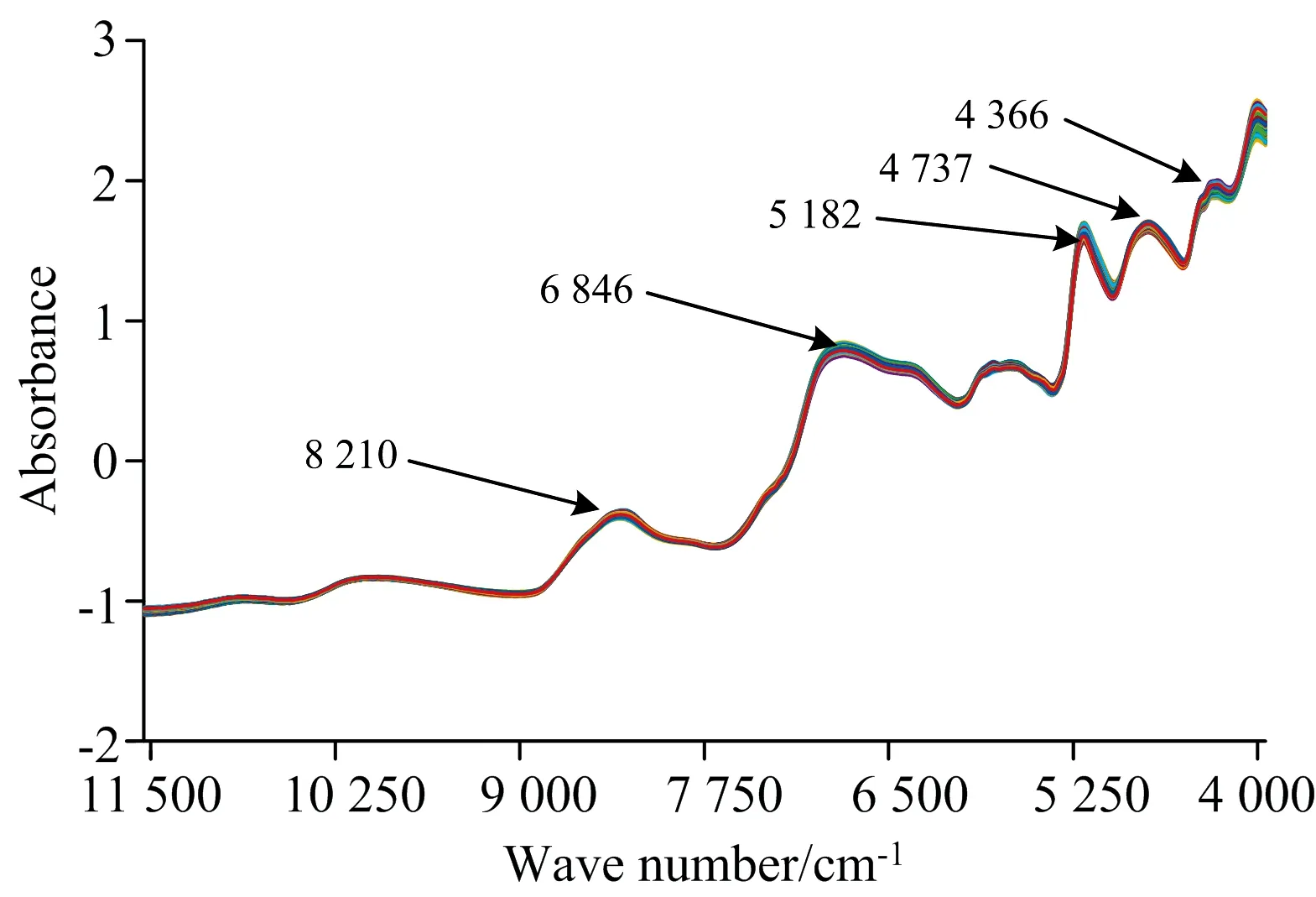
3.1 光谱数据预处理
3.2 SPA特征波长选择
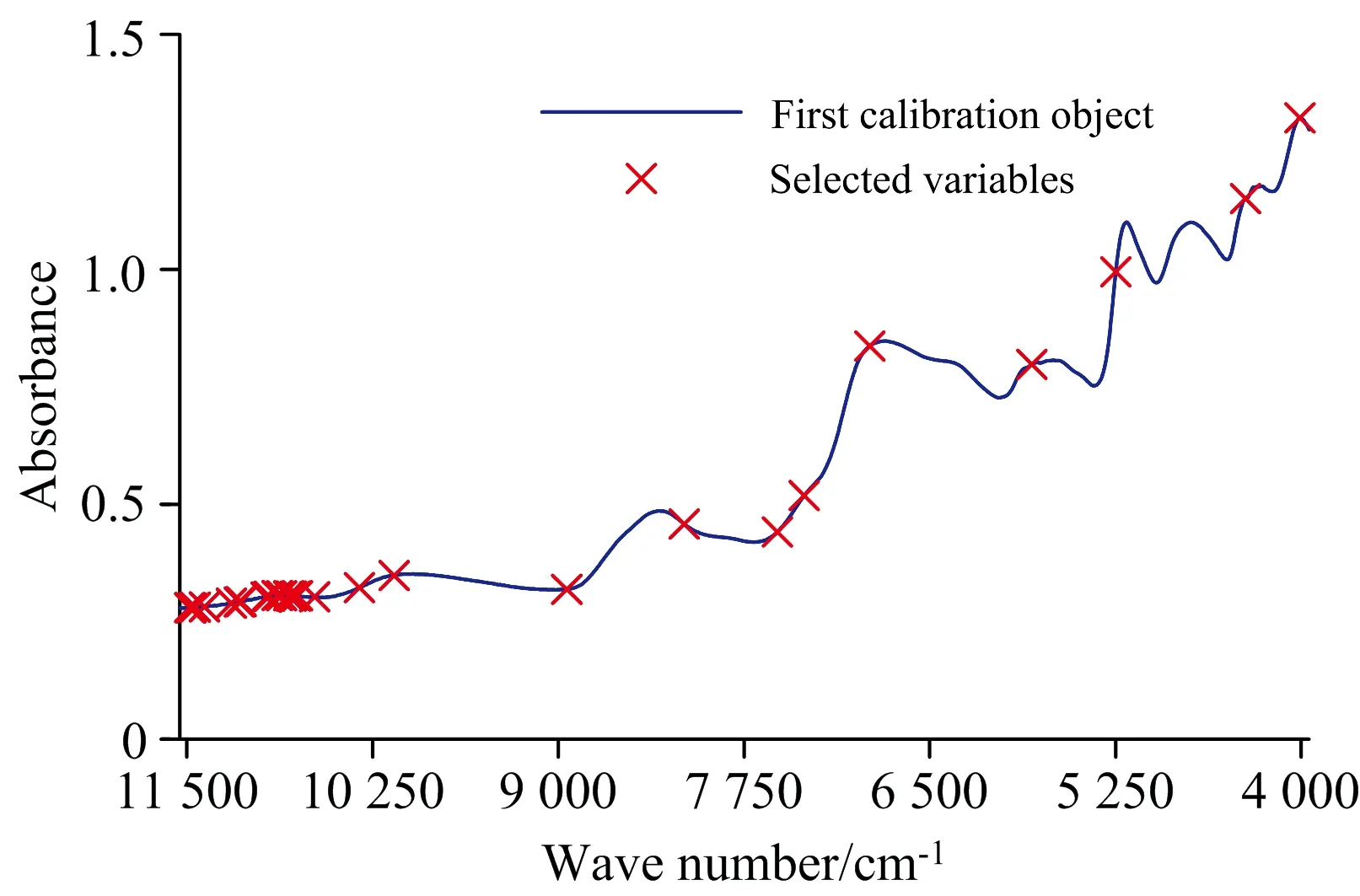
3.3 SPAsa波长变量选择

3.4 耦合MIVopt-SPAsa特征波长优选


3.5 模型对比

4 结 论
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
农业工程学报(2022年8期)2022-08-08
今日农业(2022年6期)2022-07-05
杭州电子科技大学学报(自然科学版)(2022年3期)2022-06-08
黑龙江大学自然科学学报(2022年1期)2022-03-29
阅读(科学探秘)(2021年8期)2021-09-01
科学导报(2020年8期)2020-03-12
现代园艺(2016年2期)2016-03-15
