
基于私有云安全防护的网络密文数据防泄露方法
2022-10-08 01:12张凌超高彦伟阎永华李政伟
河南工程学院学报(自然科学版) 2022年3期
米 捷,张凌超,高彦伟,张 昕,阎永华,李政伟
(1.河南工程学院 计算机学院,河南 郑州 451191;2.机械工业第六设计研究院有限公司,河南 郑州 450007;3.郑州市中原区教育局,河南 郑州 450000)
网络密文数据是指网络中敏感的、隐私的明文数据按照一定加密算法变换成的难以识别的数据。随着计算机技术的快速发展,即使网络中的数据均采用加密方式实施保护,但是由于网络的形成是依据各节点和链路完成的[1],在该过程中,节点和链路之间安全水平存在差异,难以完全避免网络密文数据泄露[2]。密文数据的泄露会造成用户信息的大量泄露,对个人和单位都会造成极大影响。因此,如何避免网络中的密文数据发生泄露,成为网络安全防护的重要问题。
针对网络密文数据泄露问题,相关学者设计了一系列防泄露方法。包空军等[1]提出了一种基于同态加密算法的数据防泄露方法,根据混沌序列轨迹点,将明文数据序列与密钥序列视作数据流的字节,通过设定数值使序列符合白噪声规律,从而使密文数据能够均匀分布,完成对数据的防泄露处理。李西明等[3]提出了一种基于生成对抗网络的抗泄露加密方法,该方法在16位密钥对称加密方案的支持下,通过修改激活函数建立了比特密钥泄露环境下的加密算法模型,然后添加解密方和敌手模型,再通过规格化处理提升抗泄露加密通信能力。上述方法在进行防泄露处理过程中,均以数据库加密方式完成密文数据的保护,但是针对攻击者对数据实行恶意攻击导致数据泄露的处理,依然存在一定不足。
私有云是一种单独构建的平台[4],该平台仅为构建企业提供相应的云计算服务,企业可在构建的私有云平台上部署所需的服务应用,同时具备对该平台中资源、数据等实行控制的能力,故可在极大程度上保证数据安全[5],并提高服务质量。基于此,本研究基于私有云安全防护设计了一种新的网络密文数据防泄露方法。
1 私有云安全防护框架
首先,本研究利用私有云的优势,以网络密文数据的安全防护为目标,结合网络对于安全等级的需求和私有云平台的实际业务情况,采用互补的安全防护理念,设计了私有云安全防护的整体框架(图1)。
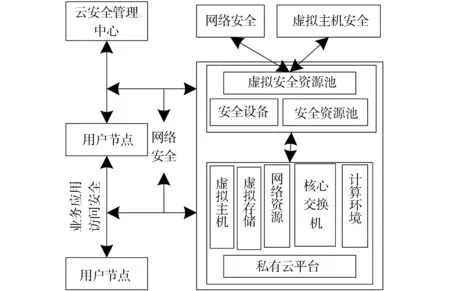
图1 私有云安全防护框架Fig.1 Private cloud safety protection of the ciphertext data leakage protection framework
图1中的框架共包含4个部分,分别为网络安全设计、虚拟机安全设计、网络业务访问安全设计及私有云管理中心。这4个部分的结合实现了对网络内外的安全防护。
网络安全设计:该设计主要针对网络内部安全进行控制,包含两个方面,分别是节点和链路的安全防护。在设计过程中,对经由链路的数据进行分析,确定该数据主要有两种,即私有云平台流入和流出的数据,以及平台内各虚拟服务节点之间的数据。为实现网络密文数据的安全防泄露,部署了核心安全网关和虚拟防火墙,前者部署在核心交换机内,后者部署在链路虚拟安全资源池中,实现了平台和平台内虚拟服务节点之间网络密文数据的安全控制[6]。
虚拟机安全设计:该设计的主要目的是实现对虚拟服务器内存的监控,主要是对物理和虚拟服务节点进行安全防护病毒虚拟机和代理插件的部署,前者实现密文数据的杀毒处理[7],后者则利用分散加载方式,实现密文数据的资源灵活调配,提升CPU的运行效率。
网络业务访问安全设计:该设计是框架中最核心的部分,主要目的是对向私有云发起访问请求的外网络中全部用户的访问和服务进行控制,其部署网络密文数据可追溯防泄露安全访问控制方案[8],实现服务端和用户端的安全防护。
私有云管理中心:该部分的主要作用是对整个私有云的部署进行管理,依据实际情况对相应服务和功能进行调整,同时对加入私有云平台的物理和虚拟两种节点进行授权和权限设定及控制。
该框架可分析私有云平台流入和流出的数据,以及平台内各个虚拟服务节点之间的数据,从而控制网络内部密文数据安全传输,利用虚拟机对密文数据进行杀毒处理,并灵活调配密文数据。
2 网络密文数据防泄露方法
基于上述安全防护框架,采用差分隐私保护和防泄露追踪防护两种方法,保护网络密文数据的隐私性、用户权限认证匹配的正确性及攻击源的追踪和标记。
2.1 基于差分隐私的网络密文数据隐私保护
差分隐私保护方法主要采用转换的方式对数据进行处理,并在输出的密文数据中添加噪声,以此来保证即使数据泄露,密文数据集中的单个记录被篡改,也无法完全识别数据中的全部信息[9-10]。其详细步骤如下:
设A表示随机算法,且A∶D→R,D和D′为相邻密文数据集;O∈R表示任意输出结果,位于D和D′上且对应A,输出结果O如果满足公式(1),此时差分隐私(ε,δ)的实现则用A表示。公式为
Pr[A(D)=O]≤eε×Pr[A(D′)=O]+δ,
(1)
式中:ε表示隐私预算,隐私保护程度随着该值的增加而降低;δ表示概率,用于描述差分隐私的不合格程度。
f表示任意函数,且f∶D→Rd,其敏感度计算公式为
(2)
式中:‖·‖p表示Lp的范数。可通过Δf的计算结果衡量单条数据记录对于输出的影响程度,决定隐私保护时噪声的添加量。
如果A的输出结果为数值,其敏感度采用L2描述,那么将高斯噪声添加至f中,以此可完成网络密文数据的差分隐私,其公式为
A(D)=f(D)+N(0,(Δfσ)2I),
(3)
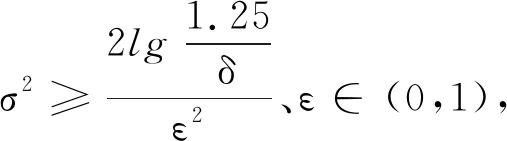
(4)
如果A符合公式(4),断定其满足ε-差分隐私。
通过上述步骤,即可完成网络密文数据的隐私保护,将保护后的网络密文数据存储至私有云虚拟数据库中。
2.2 网络密文数据防泄露追踪防护
完成网络密文数据的隐私加密保护及存储后,用户在对网络密文数据进行访问时,私有云安全防护方法的网络业务访问安全设计部分对该访问进行授权[11],依据用户的匹配结果,开放其对应的访问权限。
用户的属性授权用L′表示,其中间参数用DKu表示,用户将两种参数发送给私有云,私有云对其授权属性进行判断,如果其授权属性满足私有云定义的策略P,则此时私有云将中间解密参数Fu、ψ*回传给用户,详情如下:
用户在对云端网络密文数据进行访问时,需要向私有云管理中心发送自身的属性集合L′和中间参数DKu,私有云管理中心则将两者与P对比,判断用户是否具有访问权限[12],同时计算中间参数DL′:
(5)
式中:Ai表示数据属性;g表示生成元;Ti表示访问结构;ti表示Ai中的随机参数。
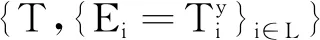
(6)
式中:ξx表示x的秘密值;y表示随机参数;qx(0)表示多项式,对应x;ω表示关联元。
如果x不是访问树的叶节点,z表示x的全部子节点,采用DepNode(Hp,D,x)算法对z实施运算后得出fx;Sx表示子节点集合,其值用kx表示,继续运算DepNode(Hp,D,x)算法;反之,fz=⊥。
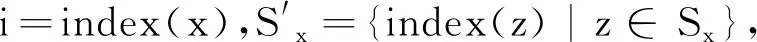
(7)
通过上述步骤得出,用户属性集关联的私钥在满足访问树的前提下,Tx(r)=1,此时,
Fu=DepNode(Hp,D,r)=e(g,ω)εy。
(8)
如果用户属性集合满足访问权限,私有云管理中心则依据用户属性计算得出用户ID所对应的参数
(9)
完成公式(8)、(9)的计算后,私有云管理中心将计算得出的ψ*和Fu回传至用户。用户则依据回传的参数完成网络密文数据解密,实现访问。
如果用户属性集合不满足访问权限,表示该用户为非法用户,私有云在对网络密文数据进行防泄露安全防护时,会对每个访问用户回传相应参数,且均会记录用户的ID及ID对应的参数,并将结果存储在W列表中[13]。用户在进行密文数据访问时,私有云管理中心进行策略匹配的同时也将用户的信息发送给密文数据的授权或者管理者,对用户进行二次权限认证[14]。如果无法通过认证,则表示该用户为非法用户,不对其开放权限,并对其进行追踪,确定其攻击源并将其标记为禁止访问用户,以此避免网络密文数据发生泄露。因此,该过程可分为两部分,一是用户身份核查,二是对非法用户追踪和记录。
用户身份核查时依据用户的属性集合L、DKu和公钥PK对DKu实行核查,判断其是否为有效数据,计算公式为
(10)
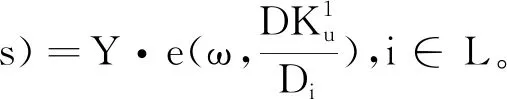
(11)
完成用户身份核查后,采用攻击源追踪方法确定非法用户的攻击源,其中攻击源信息的获取可依据解方程的方式完成。由于非法用户在对网络密文数据进行恶意攻击时存在增量式特点,故在对其进行追踪时,先解码其部分攻击源,将解码得出的攻击源信息与部分PK信息结合,即可获取新的攻击源空间信息,用ψ(V)={X(v1),X(v2),…,X(vμ(s))}表示,以此完成攻击源追踪,并将其空间域设置为禁止访问区域。
3 实验与分析
3.1 性能验证实验
将本方法用于某社交网络进行相关测试,统计相关测试结果。随机选取该社交网络中的200个社交账户为200个不同的节点,将其中10个节点定义为攻击节点,获取每个节点的100条数据(共2 000条数据)作为测试的网络密文数据集合。测试使用的服务器操作系统为Linux Ubuntu,四核3.4 GHz处理器,内存为8 GB。
为测试本方法的差分隐私加密效果,在网络密文数据不同属性数量下,随机抽取10个节点的数据,不包含攻击节点,采用本方法对其进行差分隐私保护,结果如图2所示。
依据图2可知:在不同的属性数量下,10个数据节点的差分隐私保护结果均在1.0以下,该值较小。因此,认为本方法具有较好的差分隐私保护效果,能实现网络密文数据的保护。
本方法在对网络密文数据进行保护的过程中需要对数据实行转换。因此,为进一步衡量本方法的保护效果,采用转换后的数据分布程度s和离散度c作为评价标准,判断转换后的数据质量:
s(G)=exp(Ex-G(x))KL[Pr(y|x)‖Pr(y)],
(12)
(13)
式中:G表示生成器,其样本为x;Pr(y|x)表示样本x归属样本y的条件概率类别;Pr(y)表示所有样本的边缘分布,如果转换后的数据具备良好的多样性,则会呈现均匀分布,故s(G)的值越大,表示转换后的数据质量越佳;Bp表示伯努利分布。数据分布程度和离散度两个指标的取值均为[0,100]。
依据公式(12)、(13),随机抽取12个节点的网络密文数据,不包含攻击节点,采用本方法在不同数据转换数量下获取两个指标的值(图3)。
依据图3可知:虽然数据转换数量在逐渐增加,但离散度和数据分布程度两个指标均在95.5%以上,即使数据转换数量达到1 200万个,两个指标依然在96%左右。因此,本方法能够在保证数据质量的前提下,完成数据的转换加密。
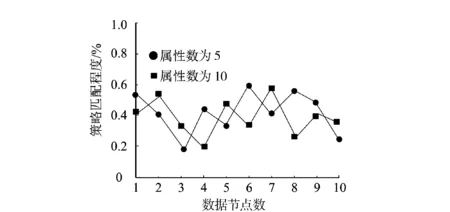
图2 差分隐私保护结果Fig.2 Differential privacy protection results
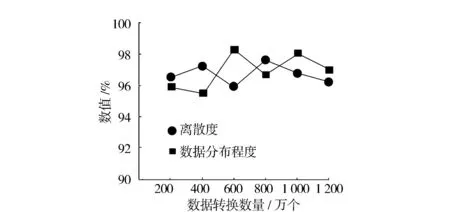
图3 数据转换效果测试结果Fig.3 Data transformation effect test results
本方法在对用户访问进行控制和匹配的过程中,需要确定公钥的最佳长度,以保证最佳的用户权限认证效果。因此,测试本方法在不同公钥长度下满足私有云定义的策略匹配程度,以衡量本方法的访问控制效果,结果如图4所示。由图4可知:随着公钥长度的逐渐增加,本方法在不同的节点数量下,策略匹配度发生明显的差异性变化,且波动较大。当公钥长度为40字节时,策略匹配程度最低,在92%以下;当公钥长度超过40字节时,策略匹配程度发生波动性上升,其中当公钥长度为80字节时,策略匹配程度最佳,达到99%左右。因此,确定公钥的最佳长度为80字节,且可用于后续实验。
确定公钥最佳长度后,为进一步测试本方法的权限匹配控制效果,在授权了不同数量属性时,采用本方法对所有节点的访问控制进行权限认证匹配,获取其匹配结果(图5)。由图5可知:在不同的节点数下,随着授权属性数量的逐渐增加,未通过权限匹配的节点数均为10。这表示在2 000个节点中存在10个权限外的节点,即攻击节点,该结果与实际的攻击节点数一致。因此,采用本方法能够精准完成节点权限安全匹配,能够保证网络密文数据的安全,避免发生攻击泄露。
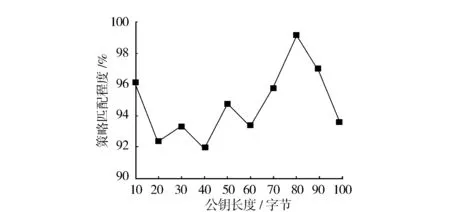
图4 用户权限认证效果测试结果Fig.4 User privileges authentication effect test results
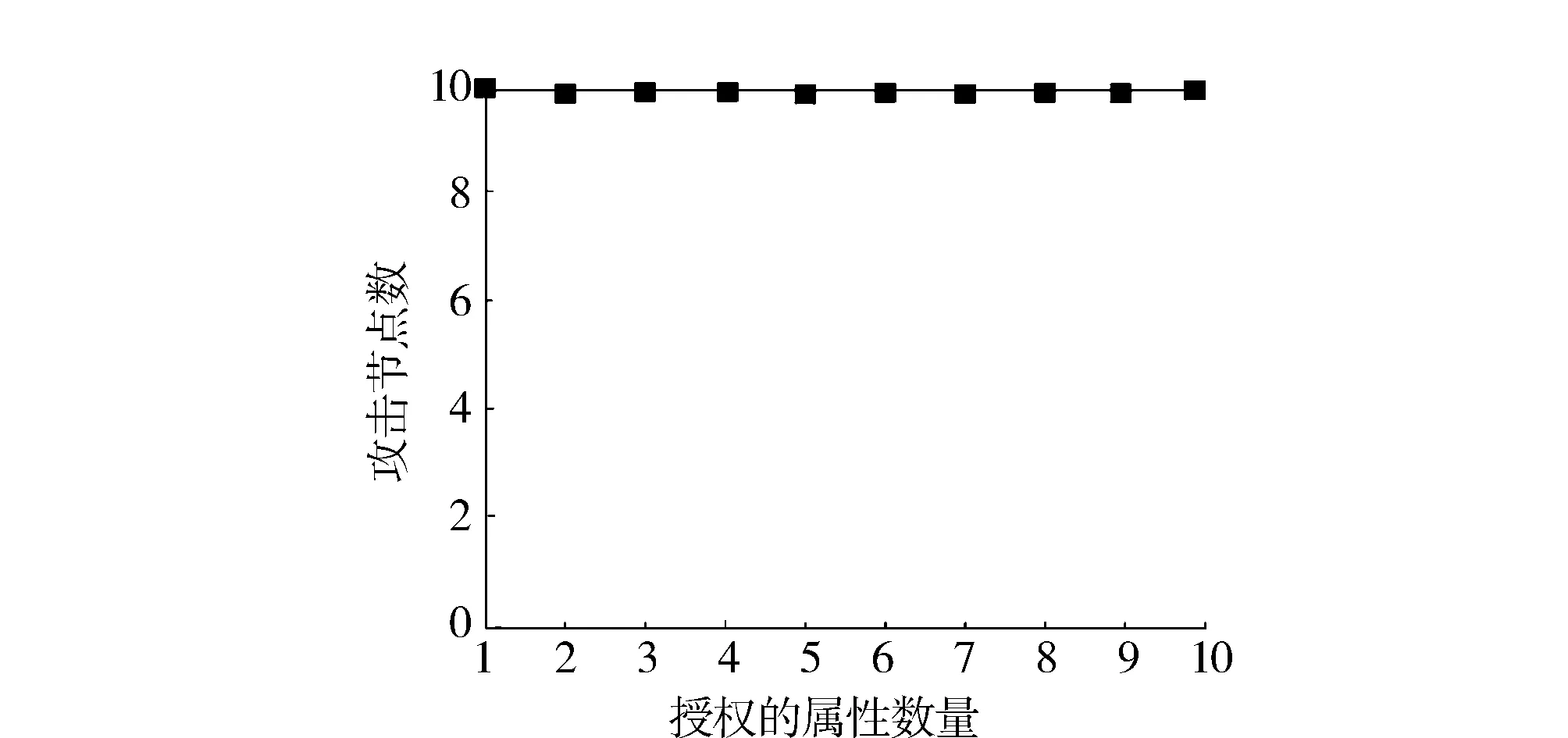
图5 权限控制匹配结果Fig.5 Access control matching results
3.2 对比与分析
为更直观地突出本方法的应用效果,将文献[3]和文献[4]的方法与本方法进行对比检验。获取3种方法在不同的攻击路径跳点数(攻击节点与目标节点之间的网络节点间隔)下,对攻击源的追踪和空间域的标记结果(表1)。由于篇幅有限,仅随机呈现了3个节点的追踪结果。
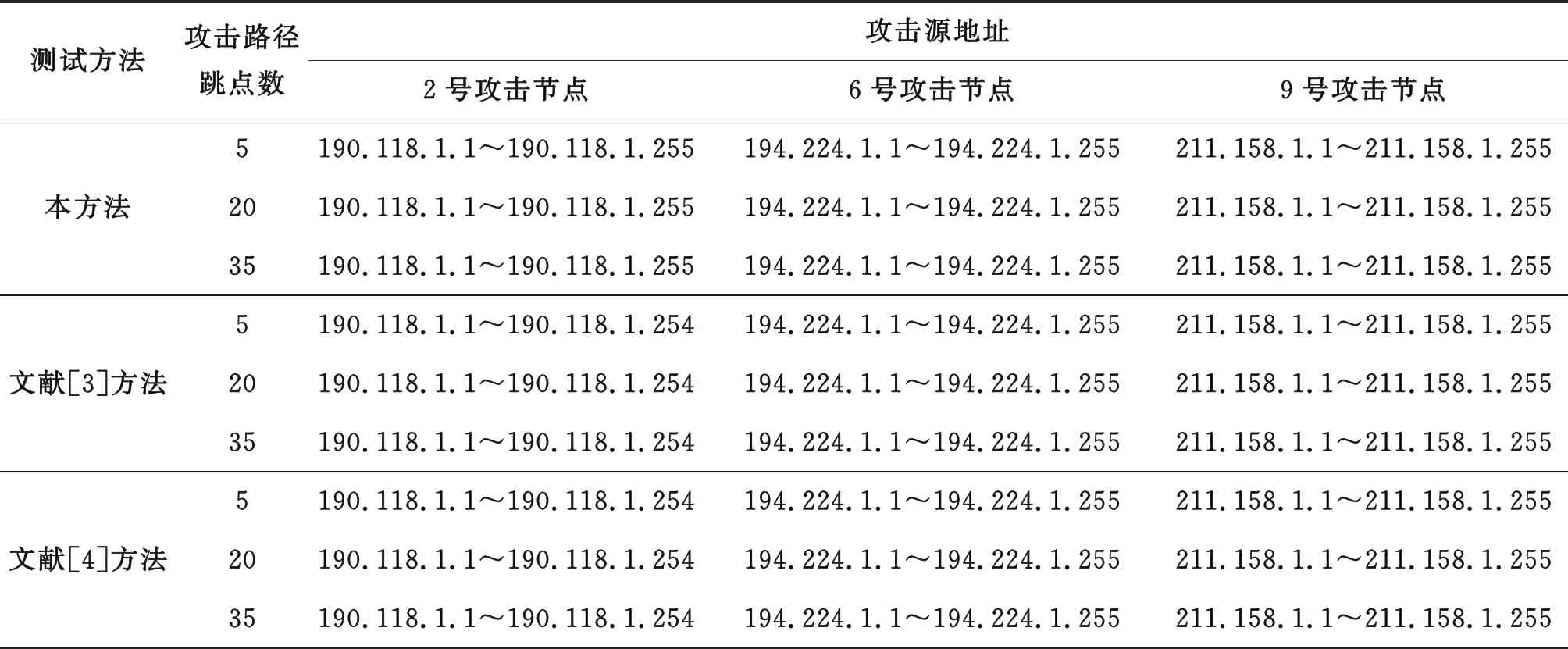
表1 攻击源追踪标记结果Tab.1 Attacks on the source tags
由表1可知:在不同的攻击节点下,随着攻击源攻击路径跳点数的逐渐增加,本方法能够完成攻击源的全部追踪,并且能够获取所有攻击源的全部空间域ID结果,但两种传统方法均出现了未能追踪攻击源的情况。因此,本方法能够更佳地保证网络密文数据的安全,进一步提升了网络密文的防泄露效果。
4 结语
本研究提出了基于私有云安全防护的网络密文数据防泄露方法,并对该方法的实际应用效果进行了测试。结果显示:该方法能够完成网络密文数据的差分隐私保护,并且不会影响网络密文数据的原始质量,同时能够可靠地对访问用户的权限进行安全匹配和认证,能够精准判断节点中的攻击节点并完成该节点ID的标记,最大限度地避免了网络密文数据发生泄露。
猜你喜欢
数学杂志(2022年5期)2022-12-02
湘潭大学自然科学学报(2022年2期)2022-07-28
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机仿真(2021年10期)2021-11-19
新世纪智能(数学备考)(2021年5期)2021-07-28
南京邮电大学学报(自然科学版)(2021年6期)2021-02-24
沈阳工业大学学报(2020年2期)2020-04-11
知识就是力量(2018年10期)2018-10-18
中国新通信(2017年18期)2017-10-22
成长·读写月刊(2017年4期)2017-05-16
