
一种面向UI手稿识别的数据集制作方法
2022-10-06 09:26刘牧耕
郑州大学学报(工学版) 2022年6期
杨 起, 刘牧耕, 马 郓
(1.北京大学深圳研究生院 信息工程学院,广东 深圳 518055;2.北京大学 计算机学院,北京 100871;3.北京大学 人工智能研究院,北京 100871)
0 引言
图像目标检测旨在从一张图像中寻找目标物体,并给出目标物体的所属区域。图像目标检测应用场景广泛,如在农业领域实现蔬菜的识别检测[1]、工业领域实现产品瑕疵检测[2]、电商领域实现图片文字提取[3]等。随着以深度学习为代表的人工智能技术的快速发展,基于深度神经网络的图像目标检测算法在算法性能方面取得了巨大突破。
在软件工程领域,利用图像目标检测技术可以实现从设计师绘制的UI手稿图像中识别UI组件及其位置,进而通过代码生成技术直接生成UI界面程序,提高软件开发效率。近年来,学术界和产业界均基于UI手稿识别算法开发了多种界面自动生成工具[4-6],并组织了相关竞赛[7]。
与普通图像相比,UI手稿没有颜色特征,仅有纹理特征,且UI手稿对坐标的精准度要求较高[8]。这些特点导致了UI手稿识别任务需要大量特定的训练数据来获得高鲁棒性的模型。然而,UI手稿一般由设计师个人自行保存,难以从互联网大规模获取,训练模型所需的数据集仅为少数志愿者绘制的少量手稿,导致UI手稿识别的准确率始终与其他图像识别领域的准确率相差甚大。
针对这一问题,本文设计了一种能够大幅提高手稿数据集制作效率并显著提升原数据集性能的方法——UIsketcher。该方法取消了人工标注数据集的环节,不要求绘制者完成整幅手稿设计图的绘制,而仅需要绘制特定的UI组件,即可完成数据集制作的全部人工工作。
1 相关研究
1.1 UI手稿识别
UI手稿识别的本质为图像目标检测。当前目标检测任务主要通过深度学习技术实现,而深度学习模型需要由标注过的数据集进行训练。通过对大量已标注的手稿图片的训练,实现对手稿元素的分类和定位。因此,对于不同需求的手稿识别应用,其需要识别的目标分类也是不同的,这就涉及数据集的定制化。
1.2 手稿绘制
相对于其他类型的图像,UI手稿图像难以从互联网中采集到原始数据,因此制作UI手稿数据集通常需要由专业的UI设计师来完成若干种不同布局样式的手稿图绘制,如微软的sketch2code[4]工具使用了数百个UI手稿。
1.3 标准化处理
由于UI手稿通常是由画笔在纸张上绘制而成,可能存在画笔的颜色不同、粗细不同、纸张的颜色差异等情况。同时,在拍摄成图片输入至识别应用之前,还会存在拍摄倾斜和拍摄摇晃导致的模糊、拍摄时光线不均匀造成的画面明暗不一等各种影响识别准确率的因素。因此通常会在识别之前进行标准化处理,即对原始图片进行旋转、剪裁、灰度处理等操作,尽可能减少外部因素的干扰。
1.4 数据集标注
在得到电子档的手稿图片数据集之后,还需要对其进行标注工作。对于目标检测任务,通常采用框选目标对象的最小外接矩形的方式来确定该元素的位置,并标注该区域所属的分类。
2 UIsketcher方法设计
在大规模数据集的制作中,随着手稿数量的大量增加,分类的数量也随之增加。这就需要多个志愿者来绘制不同的手稿以满足数据集的多样性要求。然而,传统的绘制方法有两个缺点:一是志愿者需要学习UI组件如何构成前端页面,且还需要尽可能地不重复绘制,以实现随机效果,这就要求参与数据集绘制的人员付出额外的学习成本与精力;二是手稿的背景参差不齐,有些可能存在较为明显的阴影,有些可能绘制在带有特殊纹理的纸张上。虽然丰富的背景噪声可以提高模型的鲁棒性,但可能存在同一个志愿者绘制的手稿背景都是一种样式的情况,这样反而减少了背景噪声的多样性,也就是说,通过传统方法制作的手稿数据集中,一种风格的背景噪声往往对应一种风格的笔迹。
针对上述两个问题,本文提出了一种面向UI手稿识别的数据集高效制作方法——UIsketcher。UIsketcher不要求绘制者绘制完整的UI元素组合,而是仅仅根据数据集分类标签绘制整页的UI组件。通过UIsketcher的组件图像分割工具分割提取出组件,并放入素材库中待用;同时,支持给数据集添加纸张背景库,放入不同样式的背景噪声图案。以上准备工作完成后,生成工具会自动变换素材并生成带有标注信息的数据集。
图1为UIsketcher工作的完整流程,包括绘制UI组件、组件拆分、组件增强、训练数据集生成等步骤。

图1 UIsketcher工作流程Figure 1 Workflow of UIsketcher
2.1 绘制UI组件
传统方法的难点之一在于需要绘制完整的前端页面并进行标注。实际上,对于机器学习的模型来说,训练时主要依赖的是图片的纹理特征、色彩特征等。目标在画面中的任意位置均应被AI识别。因此,本文方法直接忽略掉页面中各个组件的位置关系,只需要通过组件模板库任意组合出各种组件元素即可。
同时,设计了一种将画面中的不同位置的元素进行最小外接矩形切割的算法。该算法只需要在一个页面上绘制n个K类型的组件,并为该页面进行唯一一次标注,将其标注为K类型,从而得到n个K类型的独立组件图片,如图1中的原始数据集。通过这种整页绘制相同组件的方式,减少人工绘制工作量。这样获得的原始数据集将作为UIsketcher的输入。
2.2 组件拆分
在完成手稿绘制后,由于已知原始手稿中每张图所绘制的组件类型,则可以将组件从图像中分离出来,构建一个组件库,以便进行数据集的手稿图片的最终合成。
考虑原始组件的拆分需要保证尽可能高的精准度,例如其准确的最小外接矩形,因此,设计了一种专门用于手稿原始图像的组件拆分算法。在原始数据集无可见重叠,拍摄图片无明显阴影的情况下,该算法可以准确地分割出原始图片中的每一个组件,其原理为通道蒙版抠图,而非现在各类图像处理应用上常见的魔棒抠图。魔棒抠图的主要流程为指定图像中一个起始像素点,根据像素的颜色阈值范围,逐个搜索周围相似的像素点,并清空其色彩值,直至搜索完画面中所有符合条件的像素点。这种方式主要针对纹理单一、图像造型规则的情况。但由于手稿图像时常会出现未闭合的线框和线段,普通的魔棒抠图法对抠图区域判断的准确性会受到明显影响。因此,通过更具鲁棒性的设计对该问题进行改进。与魔棒抠图法最大的不同在于通道蒙版抠图对画面中所有层级的纹理轮廓都进行了一次搜索,并通过其最小外接矩形的并集得到每个组件真实的外边界。图2(a)为一个典型的非封闭图形的例子,如果直接采用魔棒抠图或漫水填充,则无法忽略掉红色圈出的缺口。因此,将图片处理为图2(b)所示的形式,再进行分离操作,就很容易获取目标组件的真实位置,如图2(c)所示。
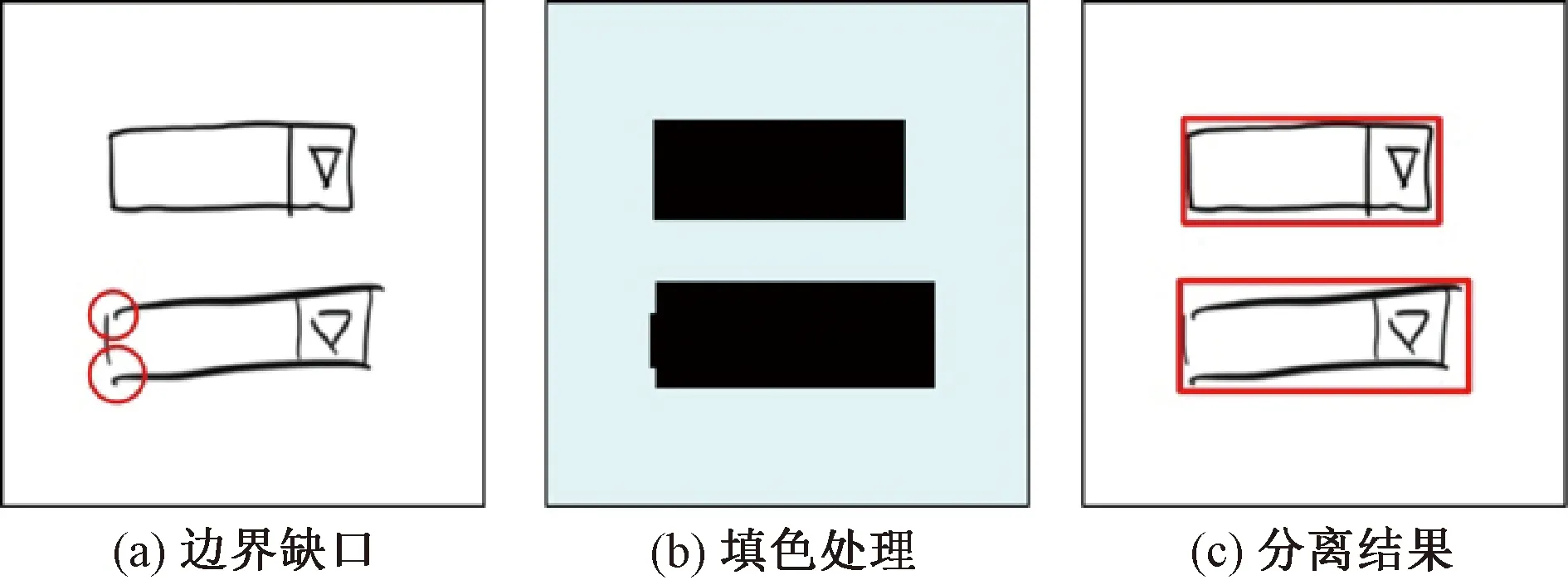
图2 非封闭图形举例Figure 2 Examples of unclosed shape
手稿识别技术通常与画笔颜色、纸张颜色无关,因此首先对图片进行灰度处理。由于笔迹的颜色通常和纸张是有明显区分的,手稿输入的内容本质上是一张二值化图像。因此,通过式(1)将图像转为灰度图后,再进行二值化处理。根据式(2),将图像的像素点取值由{(R,G,B)∣R,G,B∈[0,255]}转化为{0,1}。
fgrey(R,G,B)=0.299R+0.587G+0.114B;
(1)
(2)
BMap={(fgrey∘fbinary)(Ri,Gi,Bi)|Ri,Gi,
Bi∈Pixeli,Pixeli∈Image}。
(3)
在处理过程中,λ为可变参数,默认值为127,可根据图像的实际情况进行调整。由于图像中笔迹通常是偏深色的,背景通常是偏浅色的,因此取图像灰度值的中位数与笔迹灰度值的中间值,可得到适用的λ值。需要注意的是,如果是纸张为深色,笔迹为浅色的情况,还须进行一次反色处理。式(3)表示图像中的每一个像素通过灰度值进行二值化处理,可得到一个二值化映射表(BMap),二维矩阵的每个元素对应原先图像的每个像素。自此,图像的内容区域与背景区域已经可以被轻松地分离。
虽然图像转为BMap后的内容已经比较干净清晰,但是计算机并不能直接获取到每个组件的准确轮廓和轮廓断开的情况,如图2所示。此外,算法的目标在于获取每个组件的外轮廓,并取其最小外接矩形,即只需要获得组件的造型。因此,本文设计了一种算法来实现对组件内部的填充。当组件内部被填充后,可以轻松地获取组件的外轮廓,且不受内部内容干扰。
为了填充组件的内部区域,考虑了轮廓膨胀、高斯模糊等常见的处理方式。但是由于组件的样式各异,单一的处理并不适用于所有的情况。于是从连续轮廓的外接矩形的角度来考虑解决方案,因为只要轮廓存在相连的地方,都可以被认为是一个整体。当对这个整体取最小外接矩形时,就很容易覆盖掉缺口区域。组件拆分示例如图3所示,具体步骤如下。
(1)对于画面中的每个轮廓对象,计算出能够覆盖该轮廓范围的最小外接矩形。
(2)绘制该矩形,由于矩形框是一个封闭的图形,故不进行实心填色也依旧是封闭的图形,如图3所示。相较于图3(a),图3(b)的每个组件都有一个清晰的最小外接矩形。

图3 组件拆分示例Figure 3 Example for splitting components
(3)对组件的内部区域进行填充操作。倘若在图3(b)中使用实心填色,组件内部区域并不一定是完全填满的,如果存在个别像素没有被识别为轮廓而绘制出最小外接矩形,这样的像素就会成为画面的噪点。因此,设计了另一种更为合理的方法,保证矩形内部一定能够被完全填色。
由于前面的处理工作已经对组件的外轮廓进行了清晰的描边处理,并且背景区域是纯色,所以此时对轮廓外的区域进行填色会十分高效。设计的填色公式为
(4)
通过fflood对画面的非组件区域进行漫水填充操作,为与背景色区分,将填充的目标颜色以α代替。当完成填充后,组件内的空白区域还是背景色,但组件外部的区域全部都为α,如图3(c)所示。
(5)
(4)通过式(5)对画面进行反相处理。由于在漫水填充之后,所有的背景区域都变成了α,但组件边框及其内部不为α。此时图像为三值图像,包括α、背景色、边框色。如果将不是α的值找出并进行统一填色,即可使画面重新变成二值图像,并且该二值图像不存在任何组件内纹理,如图3(d)所示。
(5)在经过上述的步骤之后,通过搜索第1层图像轮廓,即可获得准确的框选信息,且无其他干扰元素,如图3(e)所示。
(6)将矩形框的信息在原图上叠加后,得到图3(f)的效果。
2.3 组件增强
在得到每个手稿图片中的组件绘制位置的最小外接矩形和坐标后,将各类型中的组件剪裁出来,并将分类信息标注于每个组件,得到基础组件库,如图1中的基础组件集。
但这样的基础组件库中包含的组件数量并不够丰富,由于需要使数据集中的数据尽可能的多样化,组件需要进行各种维度的变化。因为组件素材可能是在任意背景平面上绘制的,这可能造成背景纹理不一。如果直接用于数据集的生成,会导致背景的割裂,从而与真实的UI手稿差异较大。因此对原始组件进行了笔迹提取处理,去除掉背景图案并保留笔迹线条。
在得到组件的笔迹线条数据后,对组件的尺寸、长宽比、深浅、粗细等进行随机变换,以增加数据的多样性,从而得到了拓展的数据集,如图1中的拓展组件集。
2.4 训练数据集生成
Ghiasi等[9]通过对实例分割数据集的抠图—复制—粘贴处理,在不需要额外增加人工工作量的情况下,实现数据集更好的训练效果。根据该思路,采用随机取出组件再排列到画布中的方式生成数据集手稿图片。
如果直接随机放置组件在画布中,可能存在组件重叠甚至完全遮挡的问题,因此设计了如下方法来实现合理的随机排布:
(6)
fdotset(X1,X2,Y1,Y2)={Dotxy|x∈[X1,X2],
y∈[Y1,Y2]}。
(7)
其中,式(6)用于辅助储存随机信息,其结构为一个二维矩阵。对于每一张手稿图片,均生成一个等尺寸的二值画布UsageMap。式(7)中,fdotset(·)表示在(X1,X2,Y1,Y2)所对应的矩形区域内所包含的所有像素点。
考虑到重叠率的问题,首先,通过算法1计算出组件若放置在某个位置与当前的画布上已存在的组件的重叠率。然后,通过算法2给组件分配一个坐标,即从UsageMap中获取一个可以放置的区域。算法2为递归函数,表示所有组件持续地获取放置位置。
算法1重叠率计算。
输入:组件的坐标及当前的二值画布UsageMap;
输出:组件的重叠率。
① FUNC getCoverage(X1,X2,Y1,Y2,UsageMap)
② count=0∥初始化计数器
③ FORDotinfdotset(X1,X2,Y1,Y2)∥由4个坐标围成的区域
④ count++∥只要点包含于对应区域,则重叠点+1
⑤ RETURN count/(X2-X1) (Y2-Y1)/
算法2随机放置。
输入:当前的二值画布UsageMap;
输出:组件的坐标。
① FUNC getPosition(UsageMap)
②X1,X2,Y1,Y2= random(range=UsageMap)∥随机获取坐标信息
③ IF getCoverage(X1,X2,Y1,Y2,UsageMap) ∥R为允许的重叠率 ④ FORDotinfdotset(X1,X2,Y1,Y2)∥遍历区域内的像素点 ⑤UsageMap[X][Y]=1∥缓存区域内的每个点 ⑥ RETURN (X1,X2,Y1,Y2) ⑦ END ⑧ ELSE∥重叠率过高,重新获取位置 ⑨ getPosition(UsageMap) 除此之外,由于纸张背景纹理可能作为噪声信息来影响机器学习的训练效果,并且真实的手稿也通常在纸张上绘制。因此,加入随机的纸张背景,并对背景进行随机的缩放、翻转、改变透明度等操作,与画布叠加,使手稿图片更真实。 UIsketcher方法保存了每个组件的坐标信息、重叠率等各种标注信息,所以不需要人工标注即可得到带有丰富标注信息的数据集,即UIsketcher的最终输出,如图1中的训练数据集。 由于本文的最终数据集是由单个UI组件生成的,因此,将使用传统方法制作的UI手稿数据集的训练效果与其组件拆分后生成新数据集的训练效果进行对比,并采用相同的验证集来验证本文方法生成的数据集的性能表现。 本文进行了两个维度的实验:一是假定完成传统方法工作量的25%、50%、75%、100%,观察其训练效果;二是设定2倍、4倍、8倍、16倍增强来观察增强幅度与数据集训练效果的关系。 微软sketch2code公开的UI手稿数据集共提供了10种不同分类的UI组件,其数据集为人工绘制UI原型图于纸张或电子手绘板上,通过扫描以图片文件形式储存并使用json储存标注信息。考虑到本文的研究工作是UI手稿组件识别的数据集,而非OCR手写字体识别任务,在微软sketch2code中不涉及文字识别的组件共有7种,因此,实验数据集也采用7种组件进行实验。 建立如下数据集作为传统方法基准数据集:82张手稿图用于训练,35张手稿用于测试;同时,通过删减手稿图的绘制数量来控制人工的工作量,以模拟出不同工作量下数据集的训练效果。 由于最终输出的数据集可能是任何的通用格式,如coco2007、voc2007等,但这些数据集都有自己的文件结构和数据标注的标准,因此,开发了一套工具并自定义了一种方便中转为其他数据集标注信息的数据格式。该数据格式将每个组件视为一个目标对象,目标对象包含了组件的尺寸、坐标信息、重叠率、分类等。在数据集生成的过程中会先转为这样的中转格式,再转换为训练所需要的数据集格式,这样方便管理,降低了出错率。 实验选用YOLOv5模型作为实验模型,使用coco2007格式作为数据集图片格式。 目前,深度神经网络在目标检测领域快速发展,取得了非常好的效果,其中具有代表性的有两类。一类是以Faster-RCNN[10]为代表的双阶段模型,这类模型提供了一系列的待筛选目标区域,并对这些目标区域进行卷积分类,这类算法提取出大量冗余特征,训练过程较为复杂耗时。另一类是以YOLO[11]为代表的单阶段模型,这类模型对整张图像同时进行检测和分类。近年来,YOLO模型在目标检测领域有了长足的发展,尤其是YOLOv5模型[12],因其模型小、速度快、准确率高等特点而大受欢迎。对于UI手稿的识别来说,YOLOv5算法在进行端到端识别工作时更加简洁高效。因此,选用YOLOv5模型作为实验模型。 YOLOv5模型包括:YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x。由于网络UI界面手稿具有清晰简洁、无重叠、无遮挡、背景干扰少等特点,因此选择推断速度快、平均精度(mAP)高的YOLOv5s模型进行训练。 本文采用的评估指标包括准确率Precision、召回率Recall、mAP@0.50和mAP@0.50/0.95。准确率是指在所有预测为正例中真正例的比率,即预测的准确性。召回率是指在所有正例中被正确预测的比率,即预测正确的覆盖率。mAP@0.50是将IoU阈值设为0.50时,计算各类别AP(average precision)的平均值。其中,目标检测中的交并比IoU是指预测框与实际框的交集除以并集。mAP@0.50/0.95表示在不同IoU阈值(0.50、0.55、0.60、0.65、0.70、0.75、0.80、0.85、0.90、0.95)上mAP的平均值。 对每个数据集进行了1 024次迭代的训练并达到收敛,具体训练情况如图4所示,其中,Baseline表示传统方法100%工作量。图4(a)为选取的25%工作量在不同随机增强幅度下的训练表现,图4(b)为选取的75%工作量在不同随机增强幅度下的训练表现,可以看到随机幅度和训练效果大致为正相关。表1为不同工作量和增强幅度的训练效果。当工作量达到传统方法的75%时,不论随机幅度多少,其准确率均大于传统方法。在75%工作量8倍增强的情况下,4个评价指标均超过了传统方法。而即使仅有25%工作量的情况下,训练效果也未有明显的下滑。因此,对于想要验证想法的研究人员,仅仅需要完成25%的工作量即可进行实验,而对于采用本文方法制作的用于正式使用的数据集,在工作量仍然低于传统制作方式的情况下,可以进一步提升模型的训练效果。 表1 不同工作量和增强幅度的训练效果Table 1 Results with different workload and enhancement 除此之外,当固定增强幅度的时候,并非工作量更高的数据集的训练效果更好。如图4(c)所示,当训练不足24次迭代时,75%工作量所带来的训练效果明显好于100%工作量的训练效果。 图4 不同迭代次数下的训练情况Figure 4 Training processes in different epoch 25%工作量的训练效果在27次迭代之前甚至优于使用传统数据集制作的100%工作量的训练效果。因此进一步进行实验,观察在更高的随机增强幅度下,是否会出现这样的情况,结果如图4(d)所示。 同样,在图4(d)中仍然出现了类似的趋势,即低工作量的数据集在训练量较少的时候可以得到比传统方法制作的数据集更高的mAP。这可能是由于超低工作量的数据集组件变化较少,因此AI模型可以更快地学习其特征,从而更快拟合,但这并不能提高其最终精度,因为鲁棒性不足。在这里还有个附加条件,即虽然数据集的绘制工作量不同,但是相同的增强幅度下,数据集的数据量几乎是一致的,同时它们的验证集也是一致的。 (1)通过本文提出的UI手稿数据集制作方法,在仅需传统方法25%的人工工作量情况下,仍能保持与传统方法制作的数据集相近的训练准确率;在达到传统方法75%的人工工作量情况下,可超过传统方法制作的数据集的训练准确率。因此本文提出的制作方法对人工的依赖显著少于传统方法。 (2)相较于传统方法,本文提出的方法减少了数据集的标注环节,不需要专门设计不同布局样式的UI界面,只需要绘制者根据要求绘制单个的组件即可,通过减少定制化程度,显著降低了人工成本。 本文方法可以为UI手稿识别、手稿生成等领域的研究人员提供新的数据集制作思路以及数据集的增强方法。在下一步工作中,将考虑改进优化由组件库到生成最终数据集的处理方法,从而实现更佳的训练效果。3 实验与结果分析
3.1 实验方法
3.2 实验数据集
3.3 模型
3.4 评估指标
3.5 实验结果


4 结论
猜你喜欢
绿洲(2022年3期)2022-06-06
绿洲(2022年2期)2022-03-31
计算机仿真(2021年4期)2021-11-17
哈尔滨轴承(2020年3期)2021-01-26
学生天地(2020年6期)2020-08-25
童话世界(2019年17期)2019-07-04
中国公路(2017年8期)2017-07-21
作品(2017年2期)2017-02-23
中国信息化周报(2016年45期)2016-12-27
终身教育研究(2015年1期)2015-02-28
