
一种基于主题过滤和语义匹配的服务发现方法
2022-10-06 09:26周澳回翁知远周思源
郑州大学学报(工学版) 2022年6期
周澳回, 翁知远, 周思源, 黄 乔, 汪 烨, 张 华
(1.浙江工商大学 计算机与信息工程学院,浙江 杭州 310018;2.内布拉斯加大学林肯分校 计算机科学与工程系,美国内布拉斯加州 林肯市 68508)
0 引言
随着Web服务技术、移动网络计算和社交网络的快速发展,面向业务服务的开发显得更加的重要。业务服务通常是通过利用Internet上现有的服务来开发的,因此如何从大量服务库中发现最适合的服务,以满足不断变化的业务需求,是面向业务流程开发的大问题。
目前,基于服务的业务开发存在3个问题:①服务间的隔断性,如在Programmable Web中,一个业务目标可能涉及多个服务,但是两个服务之间没有直接的连接或关系;②服务的合适性,目前存在数以千计的服务来满足各种不同的目的,而开发人员常常不知道是否存在适合他们业务目标的服务,一般来说,对于业务目标通常涉及许多可能的替代方案,而选择将在很大程度上取决于业务目标;③服务的冗余性,服务常常具有详细说明文档,但这些文档并不都是对服务功能的描述,所以有效地发现合适的服务是亟待解决的问题,也是其中最为关键的一步。
因此,本文提出了一种基于主题过滤和语义匹配的可用于海量服务发现的方法。基于多次召回的思想,本文算法将基于自然语言的业务目标与服务描述文本进行匹配,采用Word2Vec[1]的相似度计算业务目标的相关主题,通过TextRank[2]从每个服务描述文本中提取关键句子,将业务目标和相应的服务描述文本输入循环神经网络计算相似度,通过相似度排序找到最匹配的服务,组合并协调这些服务来满足业务目标。
1 相关研究
1.1 自然语言处理与特征提取
在自然语言处理应用方面,深度学习技术可以从各种复杂的文本信息中提取出关键特征,这些关键特征可以反映文本(例如业务目标和服务)的丰富信息。因此,深度学习也被广泛应用于服务匹配中,并取得了良好效果。
Word2Vec是一种基于无监督学习的轻量级模型,不仅可以用于文本语义特征向量提取,还可结合余弦相似度等算法用于比较文本之间的相似度。卷积神经网络(convolutional neural network, CNN)[3]是一种带有卷积结构的深度神经网络,卷积结构可以减少深层网络占用的内存量,但是并不完全适用于学习时间序列,因此不能很好地把握句子顺序问题。还有一种有效的神经网络——循环神经网络(RNN)[4]。它的提出便是基于记忆模型的思想,其能够记住长文本序列出现的特征,并依据这些特征推断出后面的结果,而且整体的网络结构不断循环,通过衍生出来的变体——双向循环神经网络(BRNN)[5]对文本数据进行双向信息提取,更好地抓取文本特征,在自然语言处理应用上比传统的RNN模型应用更广泛,例如通过BiLSTM进行文本情感分析[6]。
1.2 服务发现
业务目标服务发现是指根据业务目标对期望服务功能上与非功能上的需求和约束,通过匹配算法从服务库中检索出能够满足业务目标的服务集。因此,高效而又准确的服务发现是实现服务重用的重要前提和基础。
魏强等[7]提出了从词汇表数据库或领域本体中提取相关概念并进行查询扩展的方法。现有查询扩展方法[8]严重依赖于外部知识库,而不是与服务注册相关的本地知识。因此,大多数查询扩展对特定服务注册中心中的服务发现不起作用。郑垛萍等[9]采用基于WordNet的概念语义及逆行功能进行相似度匹配,然后根据服务的调用率,从服务文档质量角度构建服务质量评价模型,从而选取服务。WordNet可以从book和hotel中提取高度相关的单词(包括同义词、上下词),如{book, reserve, record, enter, hold}和{hotel, lodge, hostel, building, edifice}。但是,从语法的角度来看,许多单词是不相关的,这导致了不必要或不完整的服务检索。由于基于本体的查询扩展方法[10]无法区分一词多义,且计算非常复杂,因此,该方法缺乏合适的领域本体,应用受到限制。
基于逻辑的方法主要使用基于本体的语义Web服务描述语言,设计基于逻辑的服务检索推理算法来描述服务。Wei等[11]提出了一个可定制的SAWSDL服务匹配器,它通过使用各种相似度度量支持基于不同应用程序请求的多个匹配策略来扩展XQuery。由于服务和查询的准确描述,基于逻辑的方法可以获得良好的性能。但是实际应用较困难,这是因为指定和管理本体以及注释服务和查询工作量大。
基于非逻辑的方法主要用于发现利用潜在主题模型的类似服务。例如,一些研究者使用主题模型将服务文档从高维词向量空间映射到低维主题向量空间,提取隐含的主题和语义,并基于主题概率实现服务功能聚类。LDA[12]被认为是使用最广泛的主题模型。例如,相关主题模型CTM采用逻辑正态分布替换狄利克雷分布,扩展了LDA在主题建模时的应用范围。此外,基于WordNet中概念与其他本体之间的语义距离,Chen等[13]提出了几种基于非逻辑的相似度度量方法。
除了上述的基于LDA主题模型等的服务发现方法,还有基于卷积神经网络的服务发现方法。Yin等[14]提出了一种通过卷积神经网络学习用户特征,并通过集成矩阵分解模型对服务进行预测的方法。在简短的句子任务中,CNN可以对句子的整体结构进行处理,但对于长文本任务,CNN只能处理窗口中的信息,相邻窗口中的信息只能由卷积一层一层地提取。提取效率很大程度上依赖于卷积核大小和移动步长,所以CNN较少用于处理长文本服务描述文档。
综上所述,现有方法都难以实现服务发现的高效性和可用性。此外,用户很难指定高质量的查询,这可能导致返回低质量的服务。
2 本文方法
本文方法框架如图1所示。该方法可更高效提取文本双向语义特征,从而解决服务发现过程中存在的效率不高和可用性较低的问题。具体流程如下。
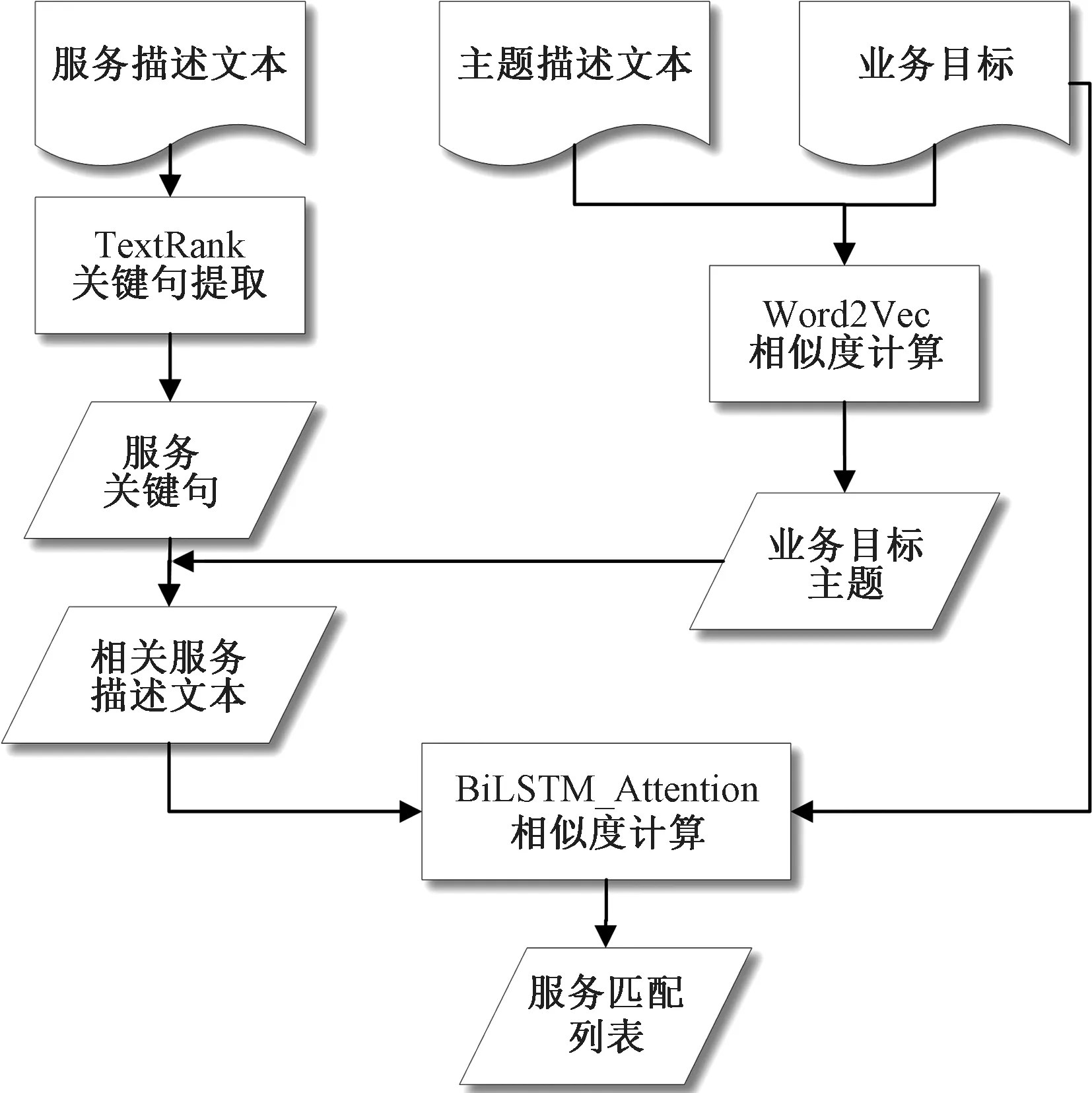
图1 本文方法框架Figure 1 The method framework of this paper
(1)业务目标主题提取。主题说明文本是指描述了每个不同服务主题的解释。首先,对业务目标文本数据进行预处理;其次,利用Word2Vec将业务目标和主题说明文本转换为单词向量矩阵;最后,计算两者的余弦相似度获取业务目标主题。
(2)服务关键句抽取。对服务描述文本的数据进行预处理,并将TextRank提取的句子作为服务描述文本的关键句。
(3)使用神经网络计算语义相似度,即计算业务目标和相应的服务描述文本之间的文本相似度。首先,将经过预处理的业务目标和相应的服务描述文本进行Word embedding;其次,输入神经网络计算二者的相似度;最后,根据相似度,将最相似的N个服务列表返回给业务服务开发人员进行选择。
2.1 业务目标主题提取
首先,对业务目标的数据进行预处理,包括将所有单词转换为小写,删除非法字符和停止词,以防止无效的文本数据对主题的提取过程造成干扰。其次,使用Word2Vec将业务目标映射到相应的词向量矩阵。词向量的处理采用谷歌新闻语料库,该语料库总大小为11 GB。最后,利用余弦相似度计算业务目标与主题描述文本之间的相似度,并对其进行排序。由于业务目标可能包括多个关键主题,因此采用相似度得分最高的两个主题作为业务目标的主题。
2.2 服务关键句提取
一般而言,从Programmable Web上抓取的服务描述是冗余的,而且大部分的句子描述与服务的功能不是很相关。为了防止冗余信息对实验造成干扰,本文采用TextRank提取最关键的两句话作为服务的描述。TextRank算法是一种抽取式的无监督的文本摘要方法,利用词与词之间的共现关系获取段落中各个句子的重要性排序。该算法的具体步骤如下。
步骤1 将业务目标分割成单个句子;
步骤2 为每个句子生成句向量;
步骤3 计算业务流程句向量间的相似度并存放在矩阵中;
步骤4 将相似矩阵转换为以句子为节点、相似度得分为边的图结构,用于句子TextRank的计算;
步骤5 根据重要性的大小进行排序,选取排名最高的句子作为业务目标的主要描述。
2.3 业务目标和服务相似度度量
业务目标和服务相似性度量的步骤如图2所示。将服务描述文本和业务目标进行预处理之后,通过词向量化输入到神经网络中进行学习。为了获得更多的交叉特性,在输出前进行向量信息拼接,同时,在网络中加入注意力机制,提升特征向量的质量。因此,相似度的最终得分是经过多种信息融合的,增加了实验的可靠性。具体流程如下。
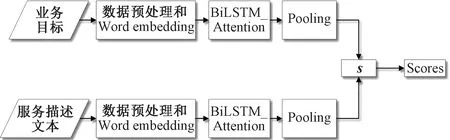
图2 业务目标和服务相似度度量步骤Figure 2 Steps to measure the similarity of business targets and services
(1)将业务目标和相应的服务描述文本经过数据预处理之后,使用Word2Vec进行文本向量化。数据预处理的主要目的是通过停止词列表删除不必要或无意义的字符,如“#” “The”等。将业务目标和相应的服务描述文本转换为神经网络可以处理的词向量矩阵,并将矩阵输入神经网络。
wti=Word2Vec(ti)。
(1)
式中:ti、wti表示Word2Vec预训练词向量矩阵。
(2)经BiLSTM计算,由BiLSTM隐藏层输出pi和qj,经池化层,pi和qj同时执行Max_pooling和Ave_pooling,将这两个池化结果进行拼接。为了提取每个句子的所有信息,对p和q向量采用不同的聚合方式。句子对之间的交叉特征主要是向量交叉特征。
s=[p;q;p+q;p-q;|p-q|]。
(2)
式中:+、-和||均为推断两句关系的元素,其中+表示整合优势,-表示突出差异,||表示增加相似度。
为了使分布更均匀,首先采用BN对隐藏层数据进行归一化,通过Pooling层,对数据维度进行压缩和选择;然后利用两个全连接层和ReLu激活函数将线性数据转换为非线性数据;最后导出预测的相似度评分。损失函数为
(3)
式中:Num为训练数据的个数;x、y分别为真实值和预测值;λ为L2正则化的超参数。
(3)在对该模型进行训练后,将其用于计算业务目标与服务描述文本之间的相似度。把所有描述语句导入到该模型中,将最相似的N个服务列表返回给业务服务开发人员进行选择。
3 实验与分析
采用Python中的Tensorflow框架来实现本文算法模型。GPU为NVIDIA Tesla V100。
3.1 实验数据收集
PWeb是一个服务注册中心,该平台包含了各个领域的各种服务。PWeb上的服务描述信息一般为中等长度,适用于本文方法需要的数据。在实验过程中,服务描述文本包括业务目标描述文本和服务描述文本。
实验收集了PWeb上所有的服务和服务的相关信息存入数据库中。在爬取过程中,针对实验要求设置一些规则用来过滤不符合要求的服务:①服务描述文本信息为空;②服务分类信息为空;③已废弃的服务。对于重复提交的服务,只保留其中一个,这样可以保证实验的有效性。实验共收集了398个类别的14 282项服务。对这些服务进行文本预处理,过滤掉非常短的描述,并替换特殊字符,最终选择了1 310个服务,字段为Email (223)、Video (228)、 Transportation (236)、Photos (214)、Travel (206)、Music(203)。其中括号中的数字表示当前字段中的选择数。由于不同主题之间可能存在功能重叠,因此,选择业务目标的TOP-2主题进行服务发现。因为当主题数量>3时,召回结果太多,导致选择性很大,这样会对实验造成干扰;当主题数量<2时,覆盖不全面,无法满足业务目标。
3.2 训练集数据收集
实验对象为12名计算机科学专业的研究生和6名本科生,将他们按1∶1分为A、B两组,每组9人。数据集标注流程如图3所示,该数据集包含大约5 000个业务目标-服务句子对。业务目标文本和服务描述文本可以重复使用,但每对文本都包含一个业务目标和一个服务描述文本。所有实验对象都有服务开发经验。随机给实验对象分配服务,让他们在一周内使用互联网资源熟悉自己所指定领域的背景知识。然后实验对象执行训练任务,任务步骤如下。
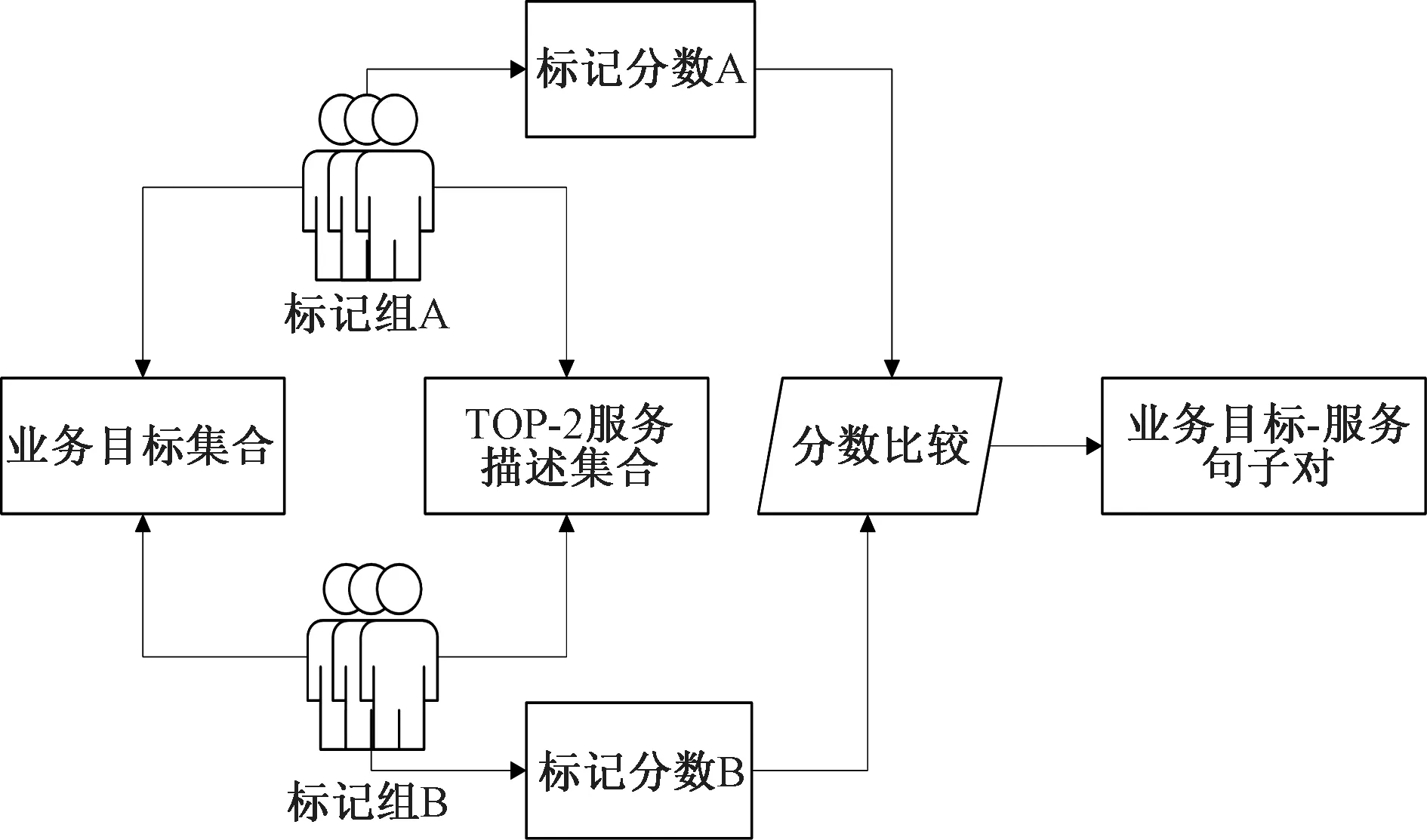
图3 数据集标注流程Figure 3 Dataset annotation process
步骤1 从服务开发人员常用的业务目标集中随机选择一个句子;
步骤2 从与业务目标相对应的TOP-2主题的服务描述文本中选择一个服务描述文本;
步骤3 对每个请求服务句子进行标记,将得分作为训练数据集;
步骤4 重复步骤1,直到每个实验对象完成5 000对业务目标-服务句子的标记。
业务目标是从经验服务开发项目中收集的公共需求。分数为0~100分。在训练数据集中,为了使网络更快地收敛和学习关键特征,将两个相同句子的得分设置为100分,并要求各实验对象结合语句关键词匹配度、语义相似度和自身开发经验得出相似度分数,同时相似度得分在整个分数区间上均匀分布。这样,实验结果不会受到数据集不平衡的影响,避免了数据重采样。然后,分别计算两组实验对象的得分平均值并比较,若两组的相似度得分差值大于20分,则由两组人员交流后重新打分。两组分数的平均值作为最终分数从而得到最终的训练数据集。训练集数据样例如表1所示。
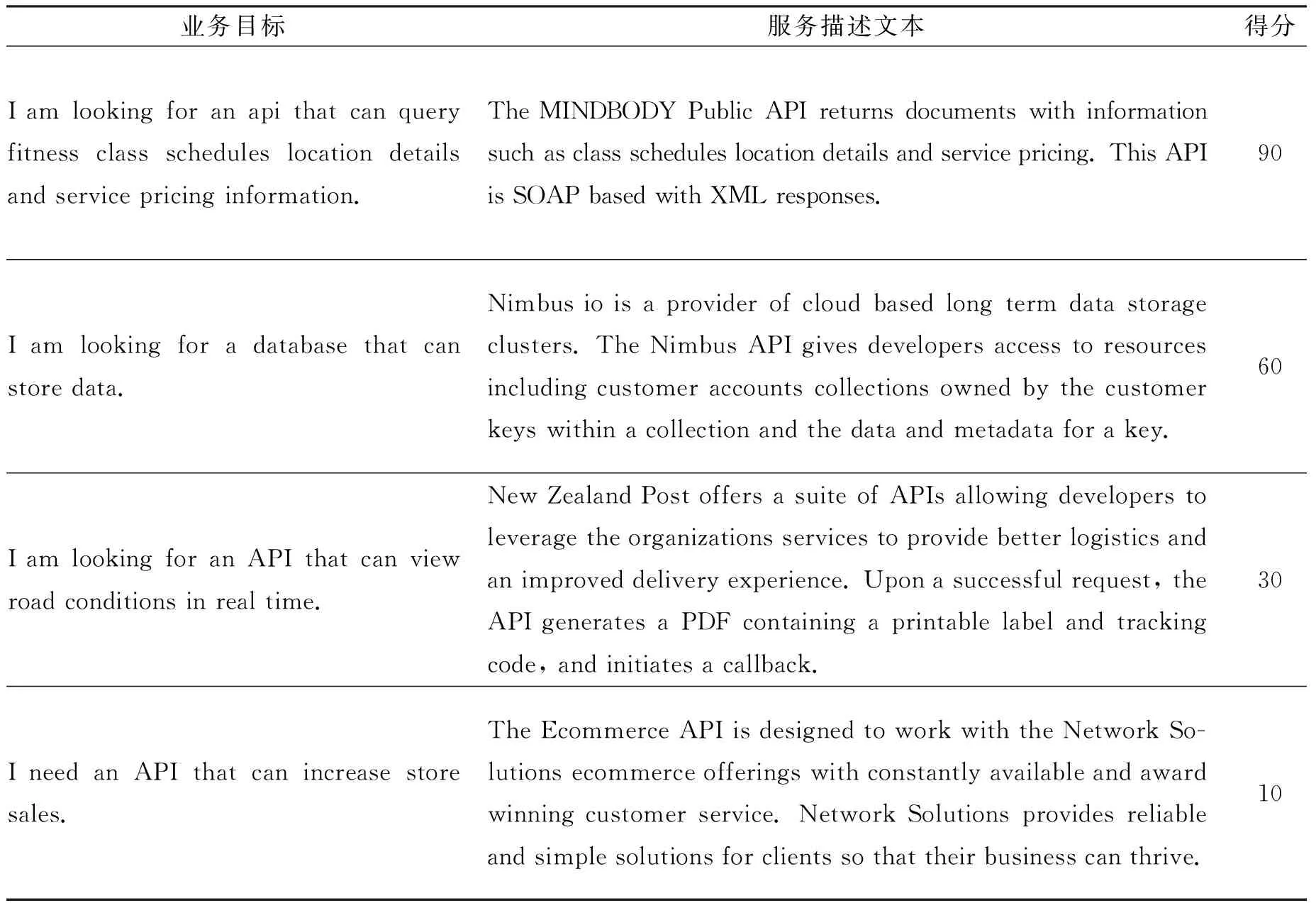
表1 训练集数据样例Table 1 Training dataset sample
3.3 实验设置
实验使用预训练好的200维Word2Vec向量作为初始化单词嵌入,并在训练过程中固定,词汇表以外的单词也被初始化为0。单词和字符嵌入层时均采用Dropout(随机失活)。这是因为在训练过程中,如果模型的参数过多,会造成训练出来的模型很容易产生过拟合的现象。在训练过程中,隐藏层的部分权重或输出被随机设置为0。对于Adam优化器,初始学习率为0.01。嵌入矩阵以外的所有权重受L2正则化约束,正则化常数λ=10-5。将每个句子的最大长度设置为100。如果单词小于最大长度,用填充符号的索引进行填充,否则删除超过的部分。采用不同的随机初始化参数集对模型进行训练,并保存最佳模型。
3.4 评价标准和评价指标
为了评估本文方法的最终效果,实验邀请4位专业服务开发人员建立标准服务列表,并设置5个业务目标。标准服务列表为4位服务开发人员在PWeb上对应的TOP-30服务列表的加权平均值。
在实验中将本文方法(带注意力机制的BiLSTM模型)与不带注意力机制的BiLSTM模型、TextCNN模型[15]以及Word2VecSD(service discovery based on Word2Vec)[16]模型进行比较,计算MAP@N[17],并进行了5次重复实验,取平均值作为最终评价结果。
MAP@N是信息检索领域的一个常用指标,用于评估每个排名列表的TOP-N所发现的服务。MAP@N的计算公式如下:
(4)
式中:R表示一个业务目标集合;ni表示最终排在集合R中真实排名中的服务数量;I(i)表示排在第i位的服务是否在集合R中。
3.5 实验结果
图4为4种模型在不同TOP-N列表下的MAP(TOP列表个数分布为5、10、15、20、25、30)。实验结果表明,在MAP指标上,本文方法相较于不带注意力机制的BiLSTM模型、TextCNN模型和Word2VecSD模型分别提高了1.41百分点、4.61百分点、4.95百分点,具有较好的性能。

图4 MAP结果比较Figure 4 MAP comparison of results
4 结论
(1) 提出了一种轻量级的面向语义级别的大规模服务发现方法。该方法利用多次召回的思想,首先对业务目标进行主题提取,对服务进行粗召回,缩小了服务发现的范围。而后通过比较业务目标和服务句子的相似度进行精召回,最终提升了算法的效率。
(2) 构建了来自PWeb的数据集,并对本文方法的有效性进行了评价。实验结果表明,本文法具有良好的性能。
在下一步研究中,将考虑通过更新的方法获取词嵌入向量,如Bert[18]和Simcse[19],并利用Node2Vec[20]和服务社交网络[21]等工具挖掘更多特征,以提高方法的性能,并扩展实验数据集,采用更丰富的数据源来验证方法的准确性。
猜你喜欢
现代电力(2022年2期)2022-05-23
云南教育·小学教师(2022年4期)2022-05-17
艺术评论(2020年3期)2020-02-06
电子制作(2019年19期)2019-11-23
制造技术与机床(2019年10期)2019-10-26
电子制作(2019年24期)2019-02-23
电子制作(2018年18期)2018-11-14
海军航空大学学报(2015年4期)2015-02-27
中学英语之友·上(2008年2期)2008-04-01
中学英语之友·上(2008年2期)2008-04-01
