
基于网络搜索指数的区域科技创新政策有效性影响因素研究
——以新疆为例
2022-10-03 05:37朱海婷吴正平
湖北农业科学 2022年17期
朱海婷,吴正平
(新疆农业大学公共管理学院(法学院),乌鲁木齐 830052)
区域科技创新能力是推进国家科技创新事业发展的主要动力,在中国区域科技创新事业发展进程中,缩小东西部区域科技创新能力差距,引领带动欠发达区域协调发展成为建设创新型国家的重要一步。为了加快中国西部欠发达地区区域科技创新事业发展,国家和地区颁布的一系列科技创新政策为西部地区科技创新事业发展提供了基本保障。新疆作为中亚区域创新中心,在创新驱动发展战略引领下,新疆区域创新系统的培育和发展显得尤为重要,对新疆现有科技创新政策有效性影响因素进行研究,可以为新一轮政策的制定及完善提供重要依据。
随着大数据时代的发展,越来越多的学者关注到海量的网络数据所反映出的行为信息。海量的网络数据所具有的市场价值在于网络数据能实时地将信息传达给需求者,这些数据不仅反映出人们对某一问题的关注度,也反映出人们在现实中的行为规律和趋势。目前,基于网络搜索的研究已延伸到就业、汽车旅游、电影票房预测等众多领域。特别在政策评估方面,网络数据能增强政策目标对象的有效性,为政策评估提供导向,依据数据分析技术,增强信息收集的系统性和针对性,建立健全政策评估和反馈机制,进而有助于公共资源的合理优化。
1 研究综述
1.1 科技创新政策评估相关研究
有关科技创新政策评估研究方法具有代表性的有以下几种。一是回归分析。蒲则文[1]采用经济计量模型,从研发资本收益的角度对山西省2010—2017年的科技创新政策效果进行评估。曾婧婧等[2]以中国“十一五”至“十二五”期间的省级面板数据为基础,采用回归模型考察科技创新政策对各地区的创新驱动效应。二是DEA数据包络法。梁瑞敏等[3]基于区域科技创新子过程构建区域科技创新效率模型及指标体系,采用二阶段网络DEA方法对山西省区域科技创新绩效进行研究。王任远[4]运用网络DEA法和主成分分析法,从科技投入和科技产出两个维度出发,对江苏省科技创新政策效果进行评估。三是文献计量法。张永安等[5]对区域科技创新政策进行梳理分类,并结合政策工具作出分析。苏敬勤等[6]通过对中央和地方的代表性科技创新政策进行关键词提取,建立共词网络和中心性及小团体,分析得到中国技术创新政策的整体构成,并采用内容分析法进行对比分析。四是熵值法。郭强[7]利用相关数据,结合模糊数学理论及熵值法,分别计算出31个省级区域的科技创新隶属度和权重,并对科技创新政策效果进行评估。胡先杰等[8]结合新的科技创新政策范式,参考政府监管的政策绩效评估框架,利用个案研究法,从“内容—执行—效果”进行政策的全过程评估。白晶晶[9]设计了以企业满意度为指标的科技创新政策评估问卷,利用李克特五级量表(5-point likert scale)将指标量化,采用方差分析和相关分析法对浙江省科技创新政策进行绩效评估。张永安等[10]以12项国务院创新政策为样本,构建了PMC指数模型,并绘制了可以直观了解政策优劣势的PMC曲面图,进行政策量化评估。
1.2 网络搜索相关研究
网络搜索行为每时每刻在发生,它可以满足人们对于信息的需求,并为做出决策提供依据。Ginsberg等[11]通过分析Google搜索引擎数据研究流行性感冒症状的发展轨迹。宋双杰等[12]利用谷歌趋势搜索指数对中国股票市场的IPO抑价现象做出研究。崔东佳[13]将百度搜索指数与各个汽车品牌的销量建立预测模型,研究表明,该种预测模型相较于传统预测模型具有更高的精准度,且在时效上具有前瞻性。张应剑等[14]以陕西互联网为研究对象,基于网络求职搜索指数构建时间序列模型,对陕西互联网行业的就业需求情况进行预测。张娟[15]基于与房价相关度较高的关键词,合成综合网络搜索指标,对房屋价格指数进行预测,结果证明,基于网络搜索指数的预测模型对房价波动可以得出较为及时准确的结论。刘超凡[16]以网络搜索关键词为基础,构建了商品住宅价格指数的神经网络预测模型。在政策评估领域,利用网络搜索数据进行研究也取得了较多的研究成果。王博永等[17]在研究房地产政策宏观调控效果问题时,利用网络搜索关键词数据探究网络搜索关键词与房地产政策效果的相关关系,建立网络搜索关键词与房地产政策效果的关系模型,以中国42个城市为样本,对房地产市场不同调控政策产生的不同影响进行分析研究。张永安等[18]将网络搜索相关数据引入中国科技创新政策调控有效性分析中,利用网络搜索方法弥补传统评估方法的不足,提高中国科技创新政策评估的效率和准确性。
目前在科技政策评估中对于政策整体效果的研究较多,对不同政策工具所产生的效果研究较少。传统评估方法需要回收大量的问卷调查,专家打分等量化方法主观性影响的弊端无法避免。还有学者利用年鉴等面板数据更是无法避免数据的时效性问题。对于有效获得即时性数据进而及时对政策评估、纠偏及优化的相关研究显得相对缺乏却又尤为重要。在研究对象上多为针对中国创新事业发展较好的省(市),对西部地区尤其是新疆科技创新政策实施现状及评估的研究几乎为空白。本研究以新疆区域科技创新政策为研究对象,采用网络搜索的方法,对所获得的信息数据进行分类提炼,得到关键词库,构建网络搜索数据与政策有效性的相关模型,通过线性回归方法进行实证研究,在对比不同政策工具所产出的创新成果后,对新疆区域科技创新政策的调控效果进行评估,并对其进行合理优化。
2 理论基础
在理性预期理论和信息搜寻理论基础上,构建基于网络搜索的新疆区域科技创新政策有效性影响因素研究框架,主要基于两方面内容构建该框架。
首先,政府在制定政策时会考虑对创新主体行为的影响。基于理性预期理论,可以预测政策颁布后产生的效果,促使响应政策的创新主体创新产出增加,依据创新产出的变化信息,更多创新主体进行模仿并意图获取相应的科技创新政策信息,创新主体在进行科技创新活动时就对政策效果做出预判,故而他们的决策是有所依据的。创新主体的行为使许多信息变得具有研究意义,他们不仅是科技创新政策作用的对象,同时根据自身的理性预期行为影响着科技创新政策的制定。创新主体对科技创新政策的反应显示出这些政策的有效性。科技创新政策的有效性不仅是由政策制定者决定,身为科技创新活动的创新主体所做出的决定也有着举足轻重的作用。故而创新主体的行为是科技创新政策制定者在制定政策时需要充分考虑的一方面。
其次,在大数据时代,网络已经成为人们搜索信息和获得信息的主要手段,网络搜索行为可以反映创新主体的关注与预判。无论是科技创新政策的制定者还是需求者,他们所做出的行为是一个决策的过程,而决策均需要输入信息、搜索信息,网络搜索作为重要的信息搜索渠道,网络搜索数据可以综合反映创新主体的共性,站在一个独特的视角体现科技创新政策对科技创新事业的影响。
基于以上两方面构建网络搜索数据与科技创新政策有效性影响因素的关系框架(图1),网络搜索数据中的政策工具搜索指数为自变量,科技创新产出数据作为因变量,将科技创新政策有效性定义为科技创新产出,通过政策工具搜索指数与科技创新产出数据的影响程度,对目前的网络搜索数据与科技创新政策有效性影响因素进行分析,进一步结合对科技创新政策的分类进行研究,明确各类科技创新政策产生的不同效果程度,为国家和地区出台相关政策提供依据。
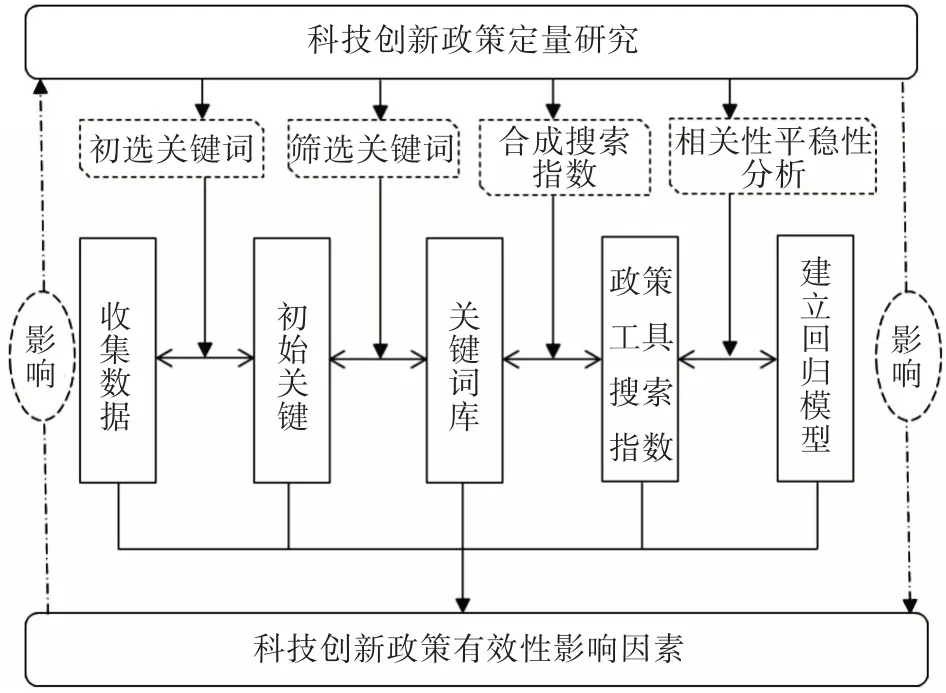
图1 网络搜索数据与科技创新政策有效性影响因素的关系框架
3 数据来源与关键词网格搜索
3.1 数据来源
3.1.1 网络搜索数据来源通过网络搜索指数研究新疆区域科技创新政策有效性影响因素,关键词数据选取来源尤为重要。百度指数是百度网站研发的一类可提供较长时间跨度、数量种类范围广、科学性较强的数据分析工具,以网络用户在百度搜索引擎上的搜索量为基础,以关键词为统计样本,科学计算分析关键词在搜索网页中的频次加权和,以此反映出各关键词所对应的事物被关注程度和热门程度。其具有易获取、透明公开的特点,满足本研究对数据的需求,故采用百度指数作为新疆区域科技创新政策有效性影响因素分析的搜索数据来源。在Python语言环境下利用网络爬虫技术采集百度指数上各关键词在新疆区域上的日数据,时间跨度为2012年1月1日至2020年3月31日,并利用数据分析软件将其加工整理为月度数据。
3.1.2 科技创新产出数据来源本研究将科技创新产出视为新疆区域科技创新政策有效性的变量。基于前人的研究结果可知,目前学术界常将新产品销售额或专利发明量视为科技创新产出的指标[19,20]。但中国高科技产业和国家统计局统计年鉴所公布的均为新产品销售额的年度数据,与所获得的百度指数月度数据不一致,会影响实证分析的准确性。专利发明量中专利授权量指标由于存在从申请到获批的3年滞后期[19],因此也不符合本研究所需数据的要求。基于以上考虑,将国家知识产权局和国家统计局所公布的新疆专利申请量作为科技创新产出数据,时间跨度为2012年1月1日至2020年3月31日,并将其整理为月度数据进行研究。
3.2 网络搜索关键词库的构建
科技创新政策有效性影响因素研究属于对宏观事件的研究,在研究时应对将宏观事件进行降维处理,即将网络搜索数据和观测到的数据按照不同政策工具类型进行分析。基于以往学者对科技创新政策分类的研究成果,将新疆区域科技创新政策分为人力资源政策、公共服务政策、基础建设政策、资金支持政策、目标规划政策、法规管制政策、金融税收政策、知识产权政策、服务外包政策和海外机构政策10类政策10个网络搜索对象。
从现有研究成果看,学术界对关键词选取方法主要有直接取词法、范围取词法、技术取词法和经验取词法。不同的创新主体在使用搜索引擎获取信息时,受到各种客观和主观因素影响,导致搜索关键词具有多样性、复杂性的特点。建立网络搜索关键词库,一方面,要搜集到尽可能全面的搜索关键词,另一方面,也要避免数据缺失和冗余的问题,确保数据的研究价值。在选择搜索关键词时遵守3个原则。①含义充分性。一个关键词应代表要素指标的一方面,所有关键词能概括要素指标的大概含义。②统计充分性。所选关键词数据序列具有连续性,保证关键词与基准指标的稳定性。③与基准指标对应性。所选关键词数据序列的峰谷趋势与基准指标数据的峰谷有一定对应性。
基于此,本研究采用文献研究法、范围取词法、文本挖掘法收集搜索关键词,结合专家经验和相关分析进行关键词筛选,从而建立关键词库。
3.2.1 初始搜索关键词建立初始关键词库,先运用文献研究法,综合前人经验和新疆区域特征提出初始关键词,再将初始关键词输入百度搜索引擎,利用关键词推荐及相关关键词推荐工具,共得到53个非重复的关键词,组成初始关键词库,如表1所示。

表1 初始关键词库
3.2.2 扩充搜索关键词结合文本计量方法,针对10类科技创新政策工具进行信息文本收集,信息文本来源渠道包括网络新闻、政府官方网站、网络论坛,如表2所示。将3~5个初始关键词输入搜索工具,分时段将搜索结果以文本形式保存。应用Python语言环境下的jieba分词工具对信息文本进行文本挖掘,提取频次较高且与政策工具主题相关性较高的关键词作为扩充的关键词集合,去重后得到165个关键词。

表2 关键词来源
3.2.3 筛选搜索关键词本研究搜集的165个网络搜索关键词,若全部引入模型进行回归和预测,由于关键词之间存在弱相关性,将出现变量之间产生多重共线性并导致模型效果欠佳,因此需要筛选出具有代表性的网络搜索关键词,引入模型进行拟合。通过手动筛选和相关系数法两部分确定最终的搜索关键词库。
1)手动筛选。将获取到的所有关键词数据趋势图与专利申请量的数据趋势图作对比,将趋势变化不同或峰谷变化不同的关键词剔除。共剔除27个关键词,剩余138个关键词进行下一步处理。
2)相关系数法。目前学术界探究关键词与研究对象间的关系时,常用Person相关系数法,该方法具有操作简便、判断结果准确的特点。Person相关系数分为3个层次:系数的绝对值大于0.8时,可以理解为2个变量存在强关联;系数的绝对值小于0.8大于0.5时为中度相关;系数的绝对值小于0.5大于0.3为弱相关,当系数绝对值小于0.3为极弱相关或不相关。本研究使用SPSS软件中的Person相关系数法,将一定时间序列上的搜索关键词数据与专利申请量数据进行量化分析,筛选出相关系数绝对值大于0.4的关键词19个,且筛选后的关键词与专利申请量之间均为正相关,如表3所示。

表3 搜索关键词数据与专利申请量相关性
3.3 合成网络搜索指数
搜索关键词库中的关键词与科技创新产出数据(专利申请量)的变化都具有一定的相关性,若将其全部引入回归模型中,搜索关键词间的多重共线性会影响模型的拟合效果。为使网络搜索数据能更好地进行拟合,避免搜索关键词之间的信息重叠现象,保证其独立性,需将众多搜索关键词进行降维处理,成为更具综合性的网络搜索指标。
在指数合成的研究中,确定各个关键词的权重是核心问题,目前学术界常用方法有两种。一是评价系统法,该方法预先明确评价原则,再对各个关键词进行评分,并以该评分决定权重分配,最终合成综合指数。该方法虽然在数据纳入时较全面,但主观性较强。二是利用相关系数分配权重,该方法具有易于操作、客观性较强的优点。
本研究采用相关系数作为赋权方法,将各个搜索关键词按照相关系数合成对应政策工具分类下的网络搜索指数,具体计算公式如下。
人力资源搜索指数=0.645×人才队伍+0.444×人才培养+0.682×创新人才+0.487×技术人才+0.554×科技人员+0.553×科技人才+0.631×科技创新人才
资金支持搜索指数=0.402×专项资金+0.457×研发费用
公共服务搜索指数=0.481×科技交流会+0.494×科技服务平台
基础建设搜索指数=0.632×孵化器+0.551×实验室+0.404×科技企业孵化器
知识产权搜索指数=0.412×专利权+0.442×科技成果转化
服务外包搜索指数=0.421×产学研
海外机构搜索指数=0.488×国际科技+0.496×技术引进
4 回归模型的构建
4.1 定义变量
选择专利申请量Yt为因变量,自变量包含7个政策工具网络搜索指数:人力资源搜索指数Xrl、资金支持搜索指数Xzj、公共服务搜索指数Xgg、基础建设搜索指数Xjc、知识产权搜索指数Xzs、服务外包服搜索指数Xfw、海外机构搜索指数Xhw。7个政策工具搜索指数与新疆专利申请量的相关系数如表4所示。由表4可知,7个政策工具搜索指数与新疆专利申请量相关性较强,且均为正相关。

表4 科技创新政策搜索指数与专利申请量间的相关系数
4.2 平稳性检验
由于各自变量与因变量均为时间序列数据,要求变量具有一定的平稳性,因此,在建立回归模型之前应先对其做平稳性检验。对单位根进行检验可以体现其平稳性,通过检验时间序列数据中是否存在单位根来判定时间序列数据是否平稳。若序列中至少存在1个单位根即判定为不平稳,会使后续回归分析产生伪回归现象。本部分采用应用较为广泛的ADF检验进行单位根检验。
ADF检验的原假设认为时间序列中至少存在1个单位根即为不平稳;若时间序列中不存在单位根,即为平稳序列。当P小于1个临界值(一般为P<0.05)拒绝原假设,即该序列不存在单位根,为平稳序列。ADF检验结果如表5所示。由表5可看出,Yt、Xrl、Xzj、Xgg、Xjc、Xzs、Xfw、Xhw在水平值时均未能拒绝原假设。经过一阶差分后,能够拒绝原假设,且为同阶单整,为平稳序列。
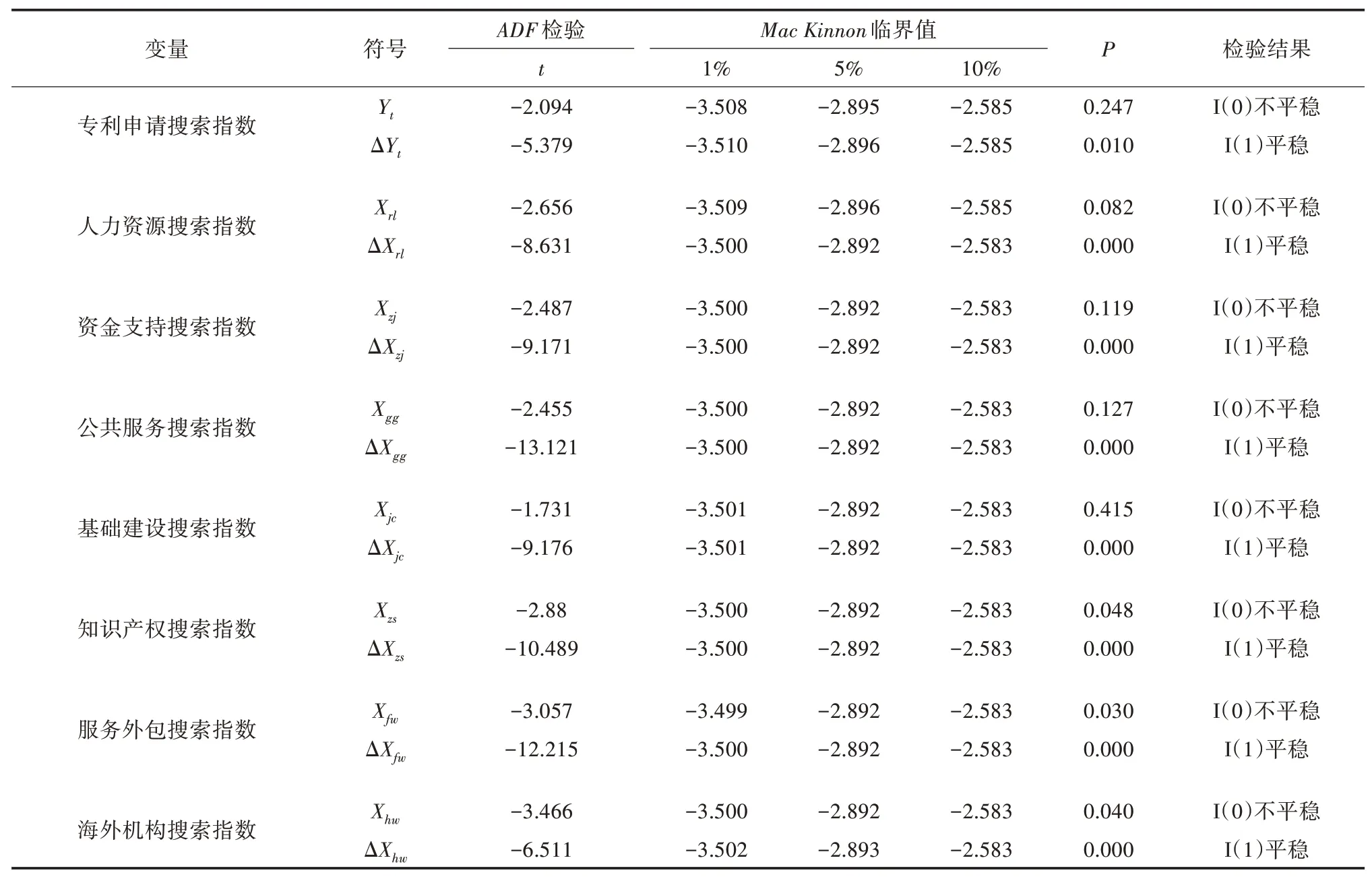
表5 科技创新政策搜索指数平稳性检验
4.3 建立多元线性回归模型
回归分析是一类用于预测建模的计量统计方法,是指确定2个或2个以上变量之间相互影响的定量关系。根据变量的数量分为一元回归分析和多元回归分析。由于影响科技创新产出数据的因素较多,故本研究采取多元线性回归方法进行研究。
n组数据的多元线性回归模型的一般形式为:
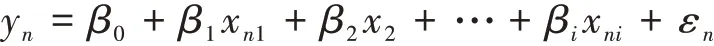
式中,yn为因变量;x1,x2,…,xi为自变量;β0为回归常数项;β1,β2,…,βi为回归系数;ε为随机误差项。
多元线性回归模型需满足5条假设条件,分别为自变量为彼此独立的非随机变量;自变量的所有观测数据需有相同方差的随机误差项;自变量与随机误差项存在不相关关系;随机误差项为彼此不相关,且期望值或平均值为0的随机变量;随机误差项符合正态分布。
模型采用最小二乘估计法,在SPSS软件中选择步进式变量输入方式进行回归分析。当变量进入方式为步进时,能够自动计算出模型的最优拟合。
当模型进行第四次计算时,R2为0.603,此时自变量(基础建设搜索指数、人力资源搜索指数、公共服务搜索指数、知识产权搜索指数)与因变量(专利申请量)的相关关系较强,剔除资金支持搜索指数、服务外包搜索指数和海外机构搜索指数三类相关性不强的因变量,线性回归模型解释度为60.3%,拟合程度较好,具备解释能力。
回归系数估计结果如表6所示,基础建设搜索指数的系数为0.029,人力资源搜索指数的系数为0.019,公共服务搜索指数的系数为0.067,知识产权搜索指数的系数为0.053,自变量系数均大于0,表明自变量与因变量存在正相关关系。经过t检验,常量和因变量的显著性P均小于0.05,故而均有显著性意义。在共线性诊断中,各个自变量的膨胀因子(VIF)均小于10,表示模型中的自变量之间未出现明显的共线性。

表6 回归结果
残差项的正态检验如图2所示,从残差项的直方图可以看出,残差项的分布近似于正态分布。
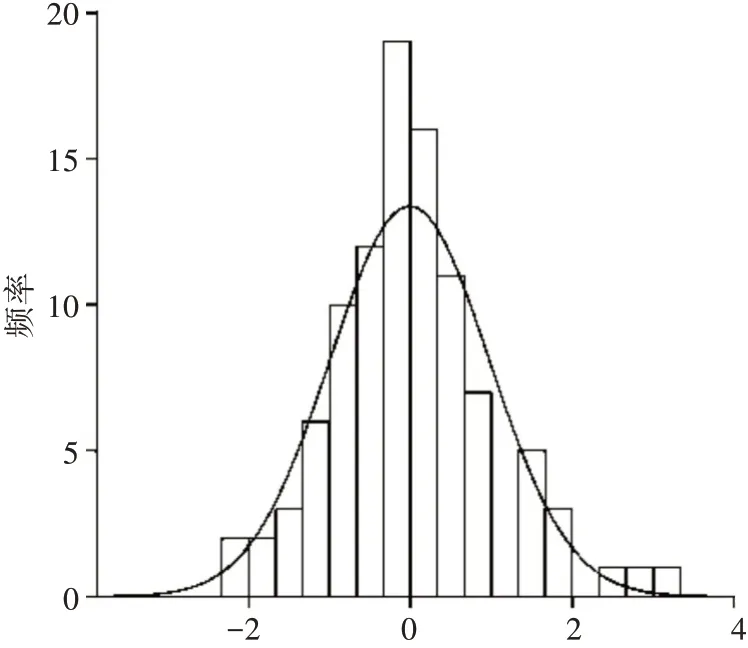
图2 标准化残差
由以上检验结果可知,采用线性函数形式的新疆区域科技创新政策有效性模型满足独立性和正态性假设,具有良好的拟合度和解释力,该回归模型具有统计学意义。
最终建立线性回归方程:
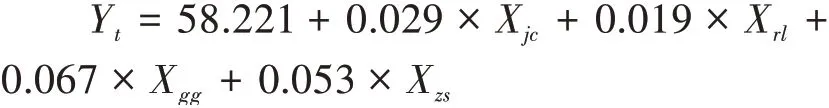
基于该模型,对因变量(专利申请量)进行预测,如图3所示,其中虚线表示专利申请量的预测值,实线表示由国家知识产权局公布的专利申请量实际数据,由图3可看出二者变化趋势比较一致。

图3 新疆专利申请量实际数据与预测数据趋势对比
4.4 模型结果分析
根据回归模型结果,对新疆区域科技创新政策有效性影响因素进行讨论。人力资源、基础建设、公共服务和知识产权4类政策工具的网络搜索指数与专利申请量拟合度较好,表明网络搜索数据与科技创新政策有效性有较为显著的动态关联性,故而网络搜索行为既可以作为政策发布、执行并产生效果后的输出结果,也可以作为新政策制定的需求导向。从政策工具网络搜索指数的系数可以看出,4类政策工具均对科技创新产出呈正向影响。其中公共服务和知识产权为较重要的政策调控工具,对科技创新产出影响最为显著,对科技创新政策有效性影响最大,基础建设和人力资源对科技创新产出影响相对较弱,对科技创新政策有效性影响相对较小。通过线性回归模型也可运算出专利申请量的预测值,将运算得出的预测值与国家知识产权局所公布的实际数据进行比较,可以看出两者变化趋势大体一致。因此,该模型不仅可以用来评估科技创新政策有效性,还可以用来对科技创新产出作出预测,对下一阶段的科技创新政策有效性进行预判和调整。
5 结论与建议
本研究采用网络搜索方法,以新疆区域科技创新政策为研究对象,构建了网络搜索数据与政策有效性影响因素的相关模型,通过线性回归方法进行实证研究,主要得出以下结论并以此提出建议。
1)为新疆科技创新政策有效性研究提供新的研究视角。现有研究所采用的传统研究方法往往以科技创新企业为研究对象,研究结果的准确性受到企业类型、企业数据、企业报表等因素影响。采用网络搜索数据进行科技创新政策有效性研究,在研究数据获取路径、范围和数量上都具有优势。
2)基于网络搜索数据与政策有效性的相关模型,4类政策工具均对科技创新产出呈正向影响。在各类影响因素中公共服务和知识产权对科技创新产出影响最为显著,对科技创新政策有效性影响最大,基础建设和人力资源对科技创新产出影响相对较弱,对科技创新政策有效性影响相对较小。地区政府可以此为参考,合理优化科技创新政策。优化供给类政策工具配比,强化公共服务类和基础建设类政策工具的使用,不断加强信息化基础设施的广度和深度建设;平衡环境类政策工具结构,发挥其渗透作用。在注重知识产权类保护政策的同时,平衡税收金融、目标规划、法规管制类政策的使用;加强需求类政策工具运用,发挥其拉力作用。在目前供给推动力大于需求拉动力的情况下,应大力引进和培育具有带头示范作用的服务外包企业,发展民间自营科研机构,承接国际服务外包业务,借助一带一路的东风,立足新疆地缘优势,利用外资科技创新活动的质量和水平,扩大知识密集型科技创新服务出口,提升科技创新能力。
3)通过回归模型计算出专利申请量的预估值,该预估值与官方网站所公布的真实值变化趋势较为一致。在未来的研究中,可以在大数据背景下充分利用海量、多变的网络搜索数据,基于回归模型对科技创新产出进行合理预测,对下一轮新政策产生的效果进行及时调整。
4)本研究还有很多不足之处。关键词的提取方法在信息分析时非常重要,但目前学术界还未对其进行系统研究,未来还需进一步研究。本研究收集数据的来源渠道较符合中国网民使用情况,针对国内经济社会研究较为有效,但利用该方法探究全球范围的经济社会研究时具有一定的局限性。
猜你喜欢
房地产导刊(2022年8期)2022-10-09
房地产导刊(2022年6期)2022-06-16
非公有制企业党建(2020年2期)2020-03-08
华人时刊(2019年21期)2019-11-17
河南科技(2016年8期)2016-09-03
发明与创新(2016年5期)2016-08-21
中国航海(2014年1期)2014-05-09
发明与创新(2013年1期)2013-03-11
世界制造技术与装备市场(2010年5期)2010-04-14
