
基于交通事故数据的自动紧急制动系统测试场景构建
2022-09-29 08:07任立海夏环蒋成约范体强赵清江
科学技术与工程 2022年24期
任立海,夏环,蒋成约*,范体强,赵清江
(1.中国汽车工程研究院股份有限公司博士后工作站,重庆 4011222.重庆理工大学车辆工程学院 汽车零部件先进制造技术教育部重点实验室,重庆 400054)
道路交通事故已成为严重危害人民生命的公共安全问题,2019年中国发生道路交通事故244 674起,造成了250 723人受伤、61 703人死亡[1]。随着传统被动安全技术趋于成熟,在自动驾驶或无人驾驶汽车普及前的“混合”交通时代,道路交通事故风险的降低以及人员伤害的减少将高度依赖高级驾驶辅助系统。随着汽车智能化水平的快速提高,装备有高级驾驶辅助系统(advanced driving assistance system,ADAS)的汽车正在实现快速覆盖;然而,ADAS部署到量产汽车之前,必须对其功能安全进行全面彻底的测试,其研究的核心之一在于构建符合真实交通状况的高保真测试场景[2]。
自动紧急制动(autonomous emergency braking,AEB)系统作为搭载率最高的ADAS,中外学者围绕其测试场景已开展了大量研究,并制定有AEB系统的测试评价规程[3-5]。如欧盟新车安全评鉴协会(European New Car Assessment Programme,Euro-NCAP)在2014年开始将AEB纳入新车安全评级中,并在2020年引入AEB路口测试场景[6]。基于对真实交通事故数据的分析与应用,研究数据转换方法并构建测试场景是开展AEB场景化测试的基础。以聚类算法为代表的机器学习方法能够在进行大数据分析时有效地避免研究人员的主观因素影响,且可重复性高,已广泛运用于典型事故场景的提取与测试场景的构建中。Nitsche等[7]使用K-medoids聚类方法对英国交通事故数据进行聚类分析,获取12类典型路口事故场景;Sui等[8]运用中国交通事故深入研究(China in-depth accident study,CIDAS)数据库中672起汽车-两轮车事故,通过聚类分析确定6类典型场景;Hou等[9]基于对368条自然驾驶数据和90条CIDAS事故案例分析确定了3类AEB-自行车事故场景;廖静倩等[10]从国家车辆事故深度调查体系(national automobile accident In-depth investigation system,NAIS)数据库中筛选出277起交通事故案例,通过层次聚类分析出4类典型丁字路口事故场景;韩大双等[11]从NAIS数据库中筛选出了116起汽车-两轮车碰撞事故,使用分类树的方法实现了对典型AEB两轮车场景的提取。然而,已有研究普遍使用传统聚类算法,其所能处理的数据样本在数量、维度以及数据变化范围等方面是十分有限的。针对大数据量、高维度的交通事故数据,如何实现交通事故数据的科学、准确且高效的聚类分析,还需要进一步研究。
传统K-means聚类算法的聚类效果容易受到离群样本、初始聚类中心和聚类簇数的影响,初始聚类中心随机选取到离群样本时,可能造成算法迭代次数过多;而聚类簇数的选定则直接影响着聚类的科学性[12-14]。在实际运用中往往需要对其进行针对性改进,以提升对数据样本的适配性、提升聚类算法性能并实现目标的达成。Alikhani等[15]采用K-means和自组织映射组合的聚类算法,采用混合聚类思想提高聚类精度;Kumar等[16]提出了高效选取聚类中心点的方法在数据集中的密集区域定位并提取K-means算法初始聚类中心点;郭璘等[17]开发改进算法以消除孤立点对聚类结果的影响。然而,现有的改进方法对交通事故数据聚类分析的有效性尚未得到广泛认可;如何充分利用上述算法改进的原理,结合交通事故数据特征,实现对传统聚类算法的改进和事故场景的有效聚类是非常具有研究价值和工程意义的。
为此,以AEB为研究对象,以真实交通事故数据为依据,探索事故数据到测试场景转换的科学方法,以及AEB测试场景构建。为了克服传统K-means聚类算法容易受到初始聚类中心和聚类簇数影响的缺陷,将层次聚类与K-means聚类相结合,提出针对交通事故数据分析的融合聚类算法;并引入聚类曲线以确定最优的聚类簇数K的值。通过对比传统K-means聚类算法聚类结果,对融合聚类算法的性能进行了评估。
1 数据和方法
1.1 事故样本
从美国高速公路安全管理局(National Highway Traffic Safety Administration,NHTSA)碰撞报告采样系统(crash report sampling system,CRSS)公布的最新交通事故数据库CRSS2019[18]中选取事故样本。CRSS2019数据库采用特有的编码规则将事故中的各特征要素进行编码,将每起事故转换为120个维度的数字,并附有相应的解读手册。基于CRSS2019记录的共54 409起交通事故,本次研究考虑面向AEB系统的测试场景适用性和事故数据可用性,按照以下筛选条件筛选事故:①事故中发生碰撞的车辆限于参与交通的车辆;②选取追尾事故、角碰撞、正面碰撞事故;③事故中仅有两车发生碰撞;④车型为乘用车和商用车。
最终选取6 639起道路交通事故作为本次研究的样本。
1.2 事故特征要素选取
根据测试场景需求和AEB系统功能特性匹配数据库,同时参考文献[19-20]从交通环境描述和车辆描述两个方面选取特征要素,最终在原始道路交通事故原始数据库的特征要素中选取了天气条件、光照条件、事故位置、车型、碰撞部位、碰撞时车速、运动状态、碰撞方向、事故类型9个特征要素,如图1所示。
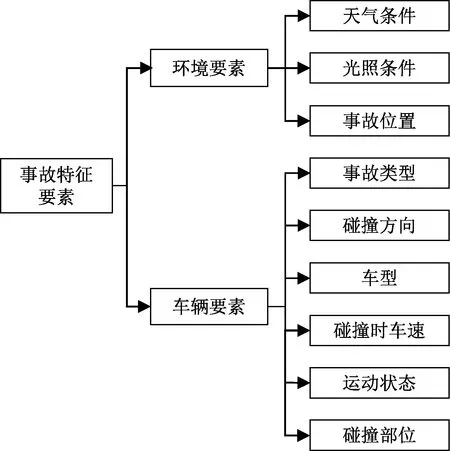
图1 事故特征要素Fig.1 Accident characteristic elements
其中,车辆要素分为两辆车各自的特征要素,根据两辆车各自的碰撞部位将两车划分为该起事故中的撞击车和被撞车(图2),例如,事故中车辆的碰撞部位为前围时,则认为该车为撞击车,另一辆车的碰撞部位为前围以外其他部位时则认为该车是被撞车,V1划分为撞击车,V2划分为被撞车,当两车正面碰撞时,则不做区分。
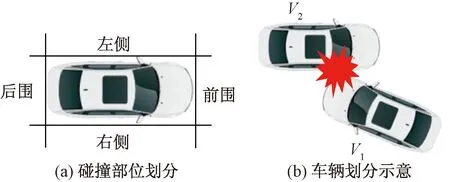
图2 车辆碰撞部位示例Fig.2 Example of vehicle collision site
在数据的编码中,采用原始数据库已有的编码值。为了简化事故数据样本,对数量较少的同类项进行合并并赋予新的编码值。采用权重均值法计算新编码值,计算公式为
(1)
式(1)中:Xn-code为合并后新编码;xi-code为第i个特征编码;m为需要合并的同类项;ni为拥有第i个特征的样本数量;n为合并特征的总样本数量。
编码简化示例如表1所示,对筛选的6 639个事故数据样本进行统计,事故数据样本总体统计及编码值如表2所示。

表1 编码简化示例Table 1 Code simplification example
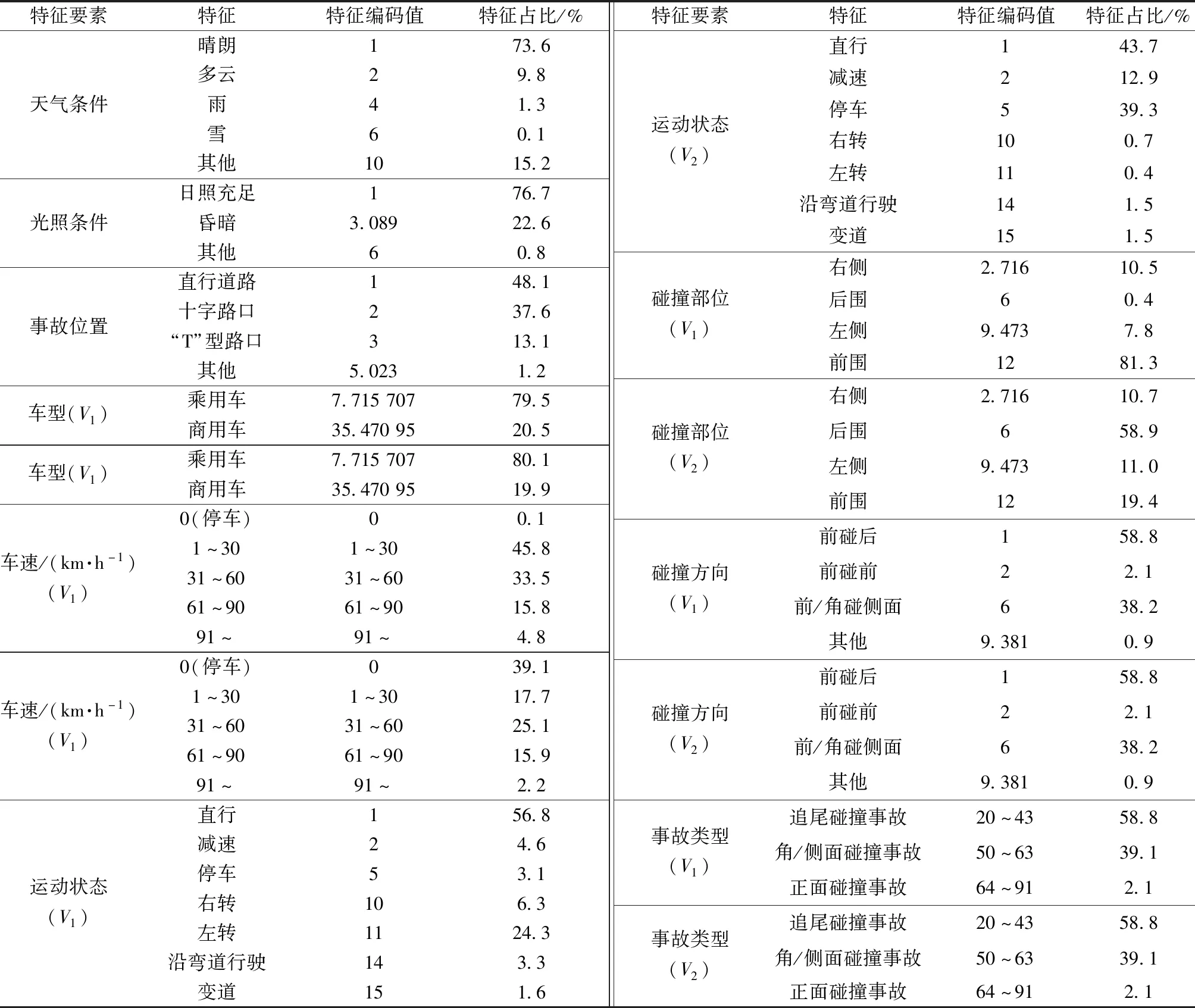
表2 事故样本总体统计Table 2 Overall statistics of accident samples
1.3 融合聚类算法
针对传统K-means聚类算法存在的容易受到初始聚类中心影响的问题,提出融合聚类算法的新方案用于事故数据样本聚类分析。融合聚类算法以K-means聚类算法为核心,运用层次聚类算法对K-means聚类算法进行优化,实现两种算法的融合。首先将随机选取的数据样本进行层次聚类,将获取的层次聚类结果作为K-means聚类的初始聚类中心,以提高初始聚类中心指定的科学性。
算法实现过程如下:
步骤1从整体数据样本中随机抽取500个样本。
步骤2考虑K个聚类簇数(令初始K=2)。
步骤3运行层次聚类算法,计算500个样本中两两样本的距离,将距离最近的两个样本合并为一个样本,反复计算合并使500个样本缩减至K个样本后停止层次聚类算法。
步骤4以第③步结果中的K个样本作为K-means聚类的初始聚类中心。
步骤5运行K-means聚类算法,计算整体数据样本中每个样本到每个初始聚类中心的距离,按照距离最近原则将每个样本分配到每个聚类中心所代表的类别中并建立类别标签。
步骤6将每个样本的本次类别标签与前一次相比较,当某一个样本的两次类别标签不一致时更新聚类中心,重复步骤5。使K-means聚类算法反复迭代,直到所有样本两次类别标签相同时停止迭代,得到聚类数据集。
步骤7画出聚类曲线,进行算法收敛性判定,不收敛时递增K重复步骤2~步骤6,直到曲线收敛效果较好时终止算法。
步骤8根据聚类曲线选取最佳K值时对应的聚类数据集作为最终聚类数据集。
聚类算法流程如图3所示。
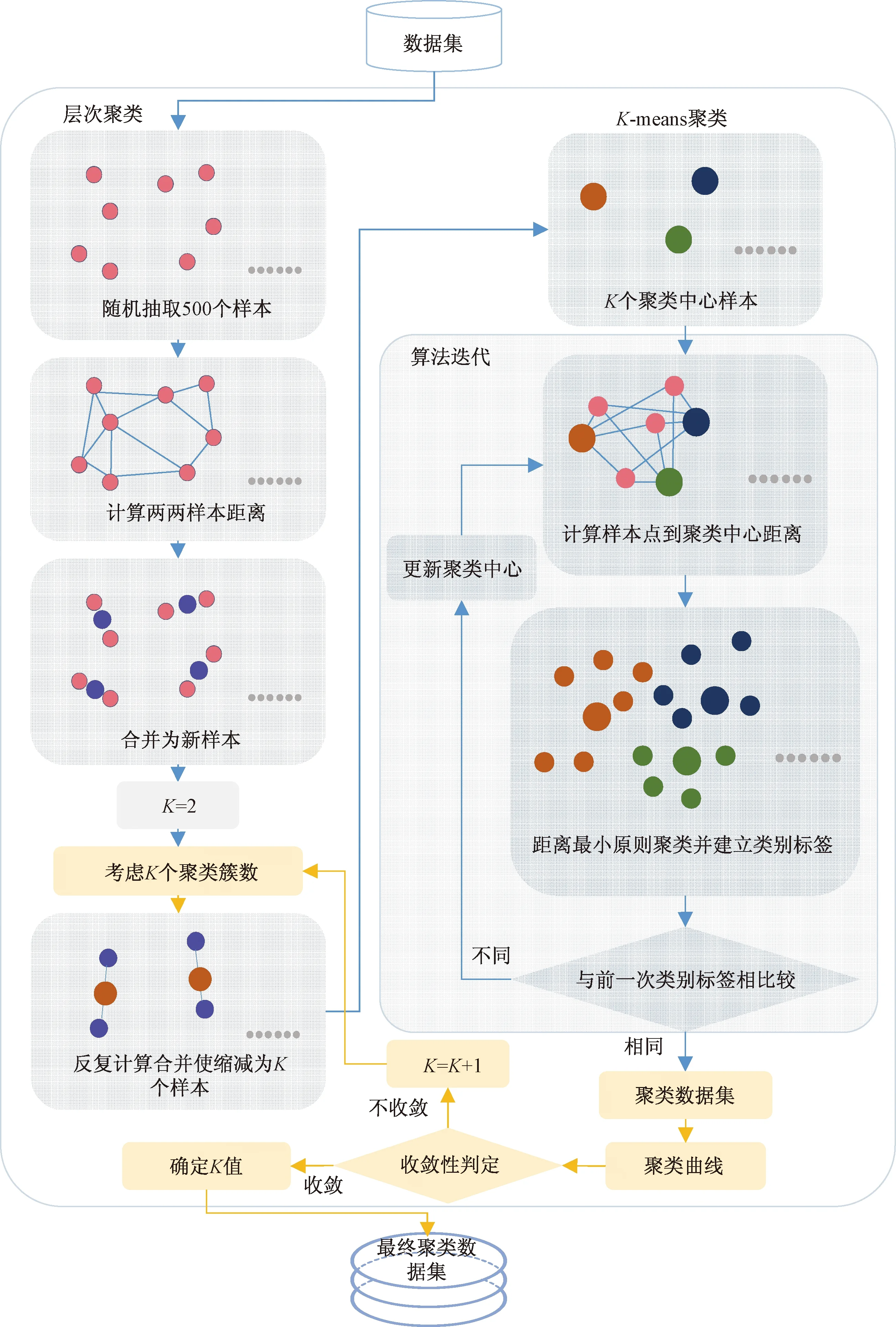
图3 融合聚类算法流程Fig.3 Fusion clustering algorithm process
上述算法中,均采用平方欧式距离计算层次聚类和K-means聚类过程中样本点的距离,其计算公式为

(2)
式(2)中:Xi为单个数据样本;Cj为第j类聚类中心;N为事故样本数量;K为聚类簇数。
在K-means聚类中聚类中心由每个簇内所有样本的均值进行更新,可表示为
(3)
式(3)中:Cjt为更新t次后第j类的聚类中心;Xij为第j类中的第i个样本;nj为第j类中包含的样本数量。
聚类曲线是以聚类簇数为横坐标,以簇内所有样本到聚类中心的距离的和(sum of squares in cluster,SSC)为纵坐标的曲线。SSC值是考察聚类结果中样本聚合程度的重要指标,以SSC曲线的收敛性作为评估算法和聚类簇数选取的依据。SSC的计算公式为
(4)
2 事故场景处理
2.1 确定聚类簇数
根据聚类曲线确定聚类簇数。运行聚类算法得到聚类曲线如图4所示。
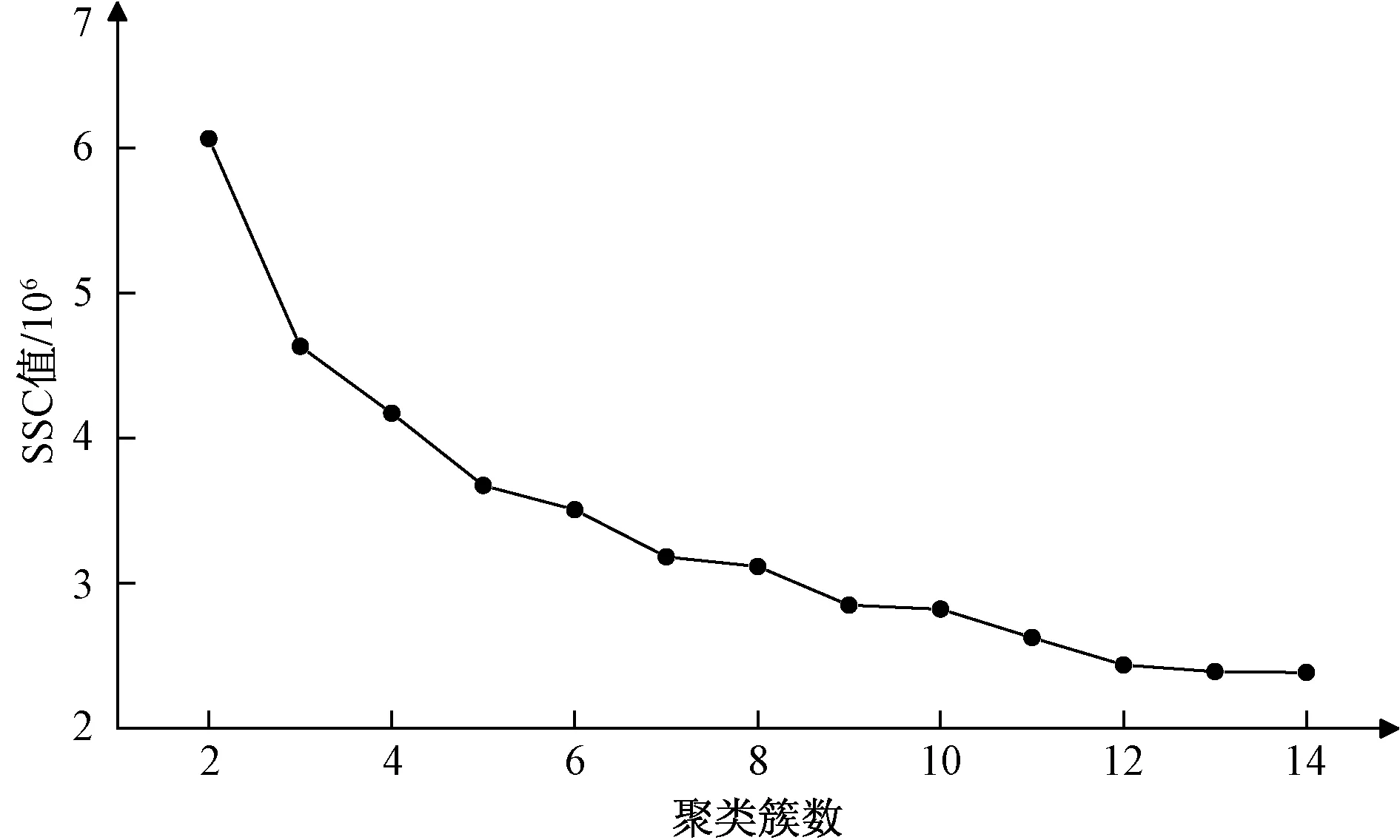
图4 聚类曲线Fig.4 Clustering curve
从聚类曲线(图4)可以看出,随着聚类簇数K增加,SSC值减少,事故数据样本聚类的聚合度逐步升高且趋于收敛。当K=12时,继续递增K到14,聚类曲线趋于平稳,算法收敛效果较好,此时终止算法。说明K=12以后提高聚类簇数所带来的事故数据样本聚合度回报几乎不变且所带来的计算时间增加。因此,选择12作为最佳的聚类簇数,选取K=12时的聚类数据集作为最终聚类数据集进行分析。
2.2 聚类结果及场景解读
根据最终聚类数据集,统计聚类数据集中12类交通事故数据如表3所示。
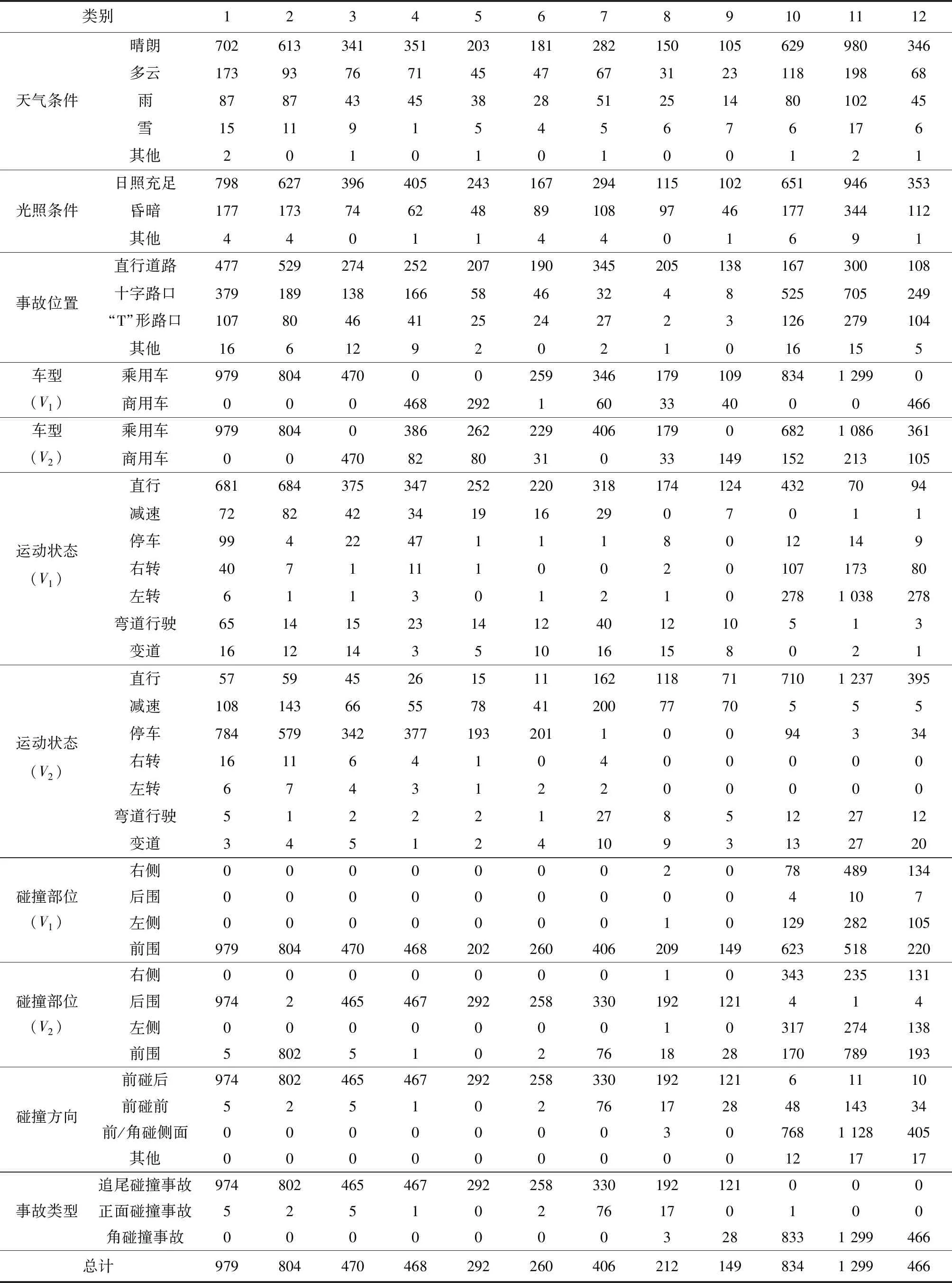
表3 聚类数据集统计Table 3 Clustering dataset statistics
为了直观地表示出每类事故中两车速度的集中区间,画出速度箱线图,如图5所示。
选取每一类别事故的每个特征要素中占比最大的特征作为该类事故的特征,采用速度集中区间的值作为该车的速度,结合解读手册可以解读出各类别交通事故的场景描述如表4所示。场景示意如图6所示。
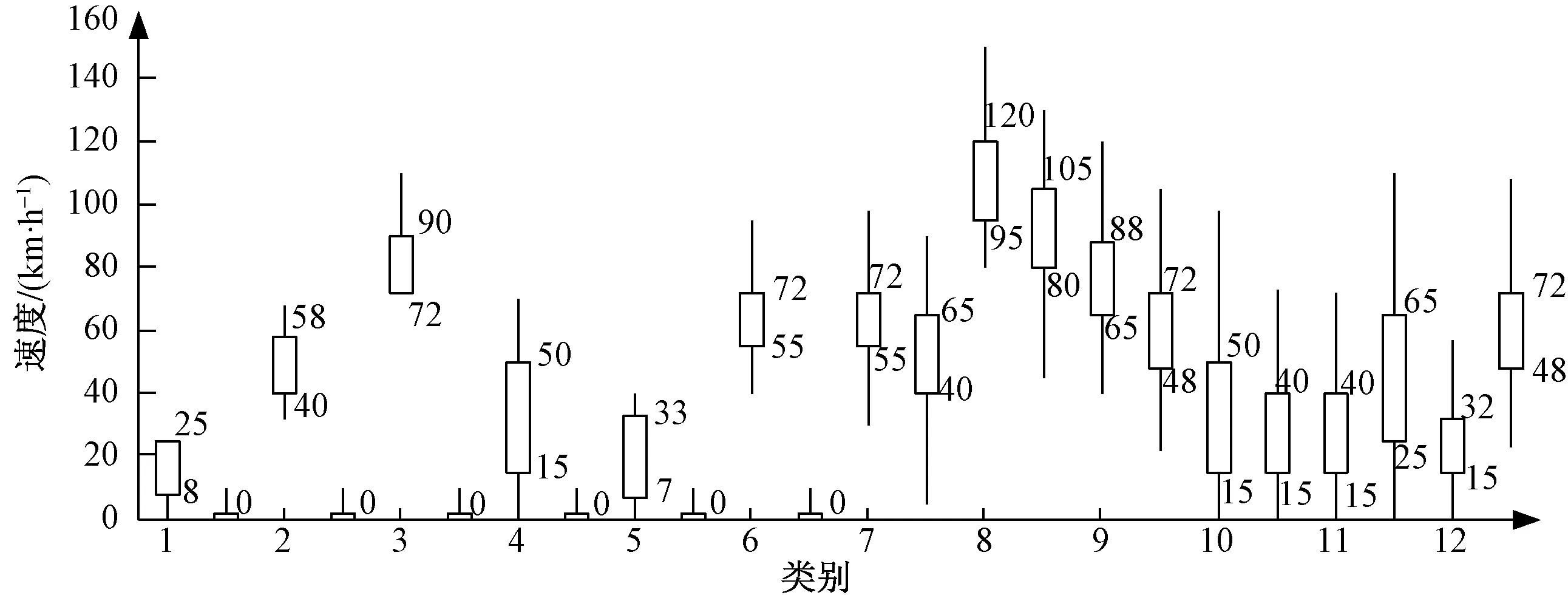
上箱线值表示该类中速度的75百分位值;下箱线值表示类中速度的25百分位值图5 各类事故的车速箱线图Fig.5 Speed box diagram of various accidents
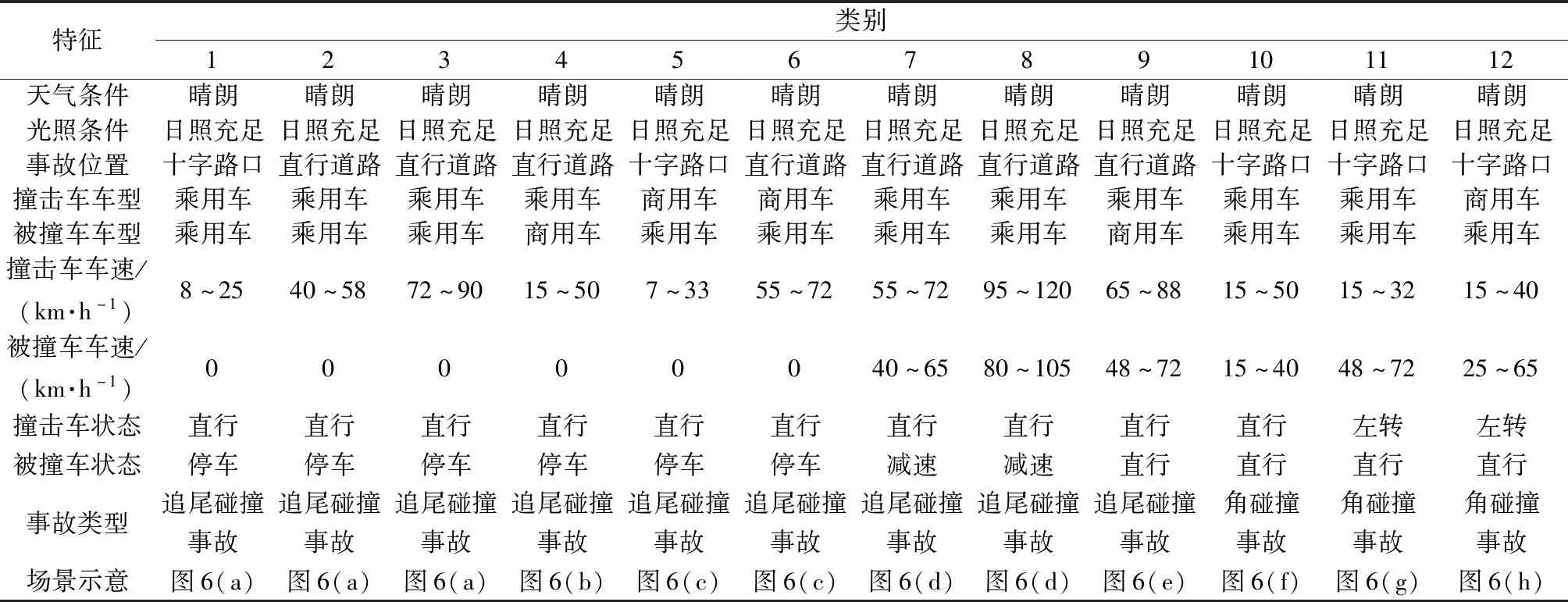
表4 各类别事故场景描述Table 4 Description of different accident scenarios

图6 12类事故场景示意图Fig.6 Schematic diagram of 12 types of accident scenarios
根据表3可以看出:融合聚类算法聚类出的每一类别事故中单一事故类型占比平均达到95%,V1或V2的单个车型占比达80%;单一运动状态占比达75.6%,每一类事故发生位置明确,说明聚类算法对每一类别事故达到了准确聚类。其中第1、2、10、11类事故的数量超过800,第5、6、8、9类事故的数量不足300,因此12类事故做到了对大概率常规事故和小概率特殊事故的有效覆盖。根据表4和图6对聚类数据集中各类别交通事故数据的统计和解读可以看出:各类别事故存在明显的差别;同类型事故的不同速度区间也有较好地体现。
以上说明融合聚类算法对交通事故数据样本的聚类取得了较好的效果,所聚类出的12类事故能够代表整个事故数据样本中的典型事故。
2.3 AEB测试场景设计
根据12类典型事故设计AEB测试场景。将事故中的撞击车设计为测试场景中的测试车(vehicle under test,VUT);被撞车设计为测试场景中的目标车(global vehicle target,GVT),根据各类别事故中车辆的速度的集中区间设计测试速度。设计出1~10类事故场景对应的1~10种测试场景,根据表4第11、12类事故中两车的碰撞部位的统计数据可以将两车互相划分为撞击车和被撞车,因此分别设计为第11、12、13、14种测试场景,以求设计的测试场景均能最大化复现聚类数据集所代表的交通事故数据样本中的典型事故。设计出测试场景共14种如表5所示。各类测试场景示意图如图7所示。
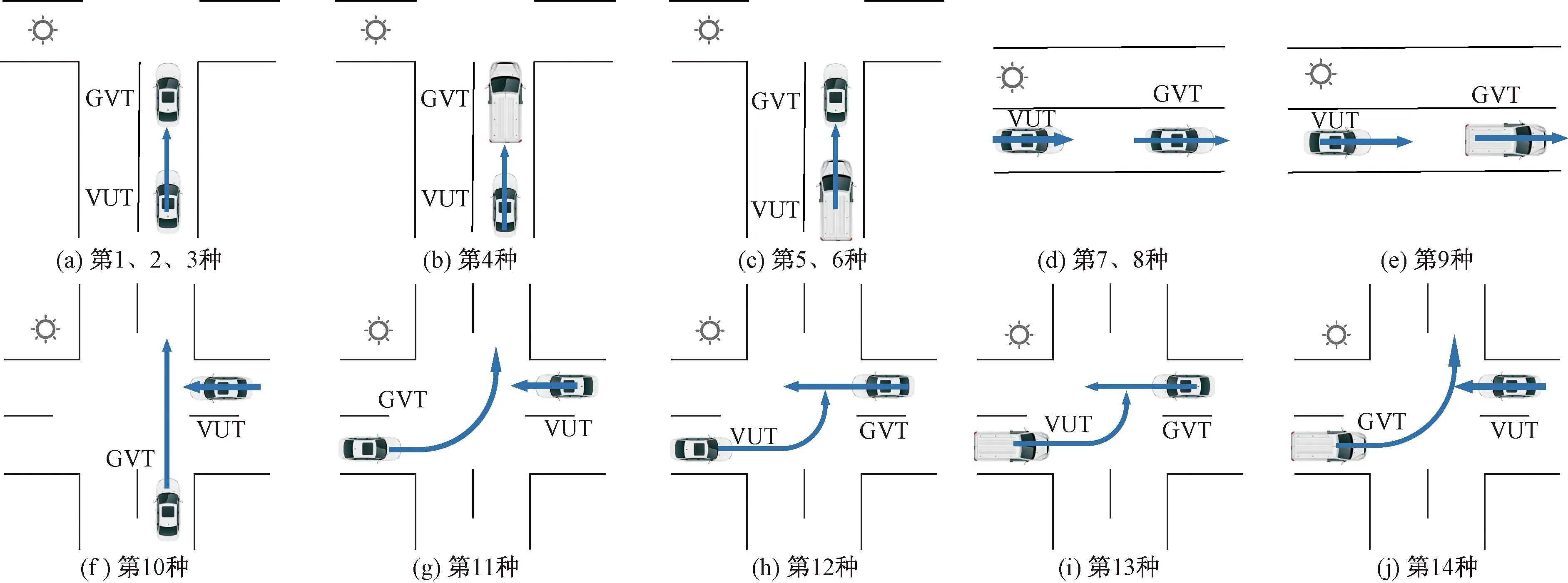
图7 设计的14种AEB测试场景示意图Fig.7 Schematic diagram ofdesigned 14 AEB test scenarios

表5 设计的AEB测试场景Table 5 Designed AEB test scenarios
3 讨论
3.1 典型事故分析
12类典型事故显示样本中的典型交通事故分为:类型A:被撞车停车追尾碰撞事故、类型B:被撞车减速追尾碰撞事故、类型C:路口两车直行侧面碰撞事故、类型D:路口转弯车与直行车角碰撞事故四大类型。类型A分为第1~3类的乘用车低、中、高速追尾停车乘用车事故,第4类的乘用车追尾停车商用车事故,第5、6类的商用车低、中速追尾停车乘用车事故。类型A占总体事故数据样本的50.5%,说明类型A事故为常见高发事故,测试场景的设计应着重关注该类型事故以开展不同GVT车速和车型组合的AEB测试。类型B分为第7、8类的两乘用车追尾事故和第9类乘用车追尾商用车事故;这3类事故中两车速度较高,且被撞车伴随有减速,可以据此3类事故设计测试场景进行极限工况下的AEB测试。类型C体现在第10类,该类事故中车辆在进入路口时速度较高,驾驶员反应时间较短,应针对此类型场景进行AEB优化设计。类型D在第11类和第12类有很好地体现,该类型事故中左转车辆相比直行车辆速度更低;其中,事故中车辆左转占比81.9%,右转占比17.9%,车辆左转事故场景应是AEB测试中值得关注的典型场景。类型C和类型D都是路口交通事故,该两类型事故占事故数据样本总体的39.1%,因此在路口等复杂交通环境中的场景应当开展AEB的针对不同GVT车型和不同GVT运动状态的专项测试。
需要指出的是,聚类获取的12类典型事故中没有涉及正面碰撞事故类型,原因在于其在事故数据样本中的占比仅为2.1%、在原始数据库的占比为1.21%。此外,手册指出记录的正面碰撞事故类型是由于驾驶员紧急转向避险而导致的与对向正常行驶车辆碰撞,不适用于AEB系统。
值得注意的是,图6的场景示意中,12类典型事故中有9类事故示意为事故发生在十字路口及其直行支路,其中1~6类表示被撞车停车追尾碰撞事故场景示意为事故发生在十字路口的直行支路。这是因为CRSS2019数据库的配套手册示意出记录的被撞车停车追尾事故类型的事故位置为十字路口的直行支路,由于被撞车等待通行而停车时发生追尾事故。事故数据样本中发生在十字路口及其直行支路的事故占比达到61.8%,说明该区域是交通事故的高发地,该交通环境在未来的ADAS道路测试中应重点关注。
3.2 测试场景对比
基于事故数据聚类的典型场景设计了AEB测试场景,与中外主要汽车安全检测机构如Euro-NCAP、中国新车评价规程(China-new car assessment program,C-NCAP)、中国保险汽车安全指数(China insurance automotive safety index,C-IASI)等公布的两车AEB标准测试场景[3-5]进行对比。标准测试场景分为GVT静止、GVT减速、GVT低速和路口测试场景,如图8所示。所设计的AEB测试场景中,第1~3种和第7、8、12种与标准测试场景相似;测试场景中环境条件均为良好,这与标准测试场景中要求相同且提出了更多的速度组合。设计的第4种和第9种GVT为商用车的测试场景,增加了乘用车AEB的在高速直行中对不同GVT的适应性测试,这两种测试场景在现有标准测试场景中还未提出。

图8 种标准测试场景Fig.8 4 types of regulatory test scenarios
张诗波等[20]和徐向阳等[21]提出了多个路口测试场景,大致分为图9[20-21]所示的5种测试场景,基本覆盖了大部分常见路口场景,设计的第10、11、12种测试场景与其类似。设计的第13种GVT为商用车左转的路口测试场景增加了乘用车AEB在路口的复杂交通环境中对不同类型GVT的有效性测试。此外本次研究提出了第5、6、13种商用车AEB测试场景,可为今后商用车AEB开发测试工作提供有力支撑。设计的测试场景均以事故数据作为依据,科学性和代表性均有良好保障,从一定程度上可以丰富测试场景,为进一步标准测试场景的制定提供了有力支撑。

图9 文献[20-21]提出的5种AEB路口测试场景Fig.9 5 Types of intersection AEB test scenarios proposed by ref.[20-21]
3.3 聚类算法对比
使用融合聚类算法和传统K-means算法分别对事故数据样本进行聚类,进行5次试验结果对比。对比两种算法各自迭代次数、SSC和SSC波动,其中SSC的波动值为当前SSC与5次试验平均SSC的差值除以平均SSC的值,其大小能判断事故数据样本聚类结果的稳定性。对比结果如表6所示。

表6 两种算法对比Table 6 Comparison of the two algorithms
对比传统K-means聚类算法,融合聚类算法在完成聚类时迭代次数平均减少8次、SSC值平均减少830 892.22、SSC波动平均减少3%。说明融合聚类算法在保证最终良好聚类结果的同时更节省时间,多次聚类中结果更稳定,可重复性更强。融合聚类算法利用层次聚类选取K-means聚类的初始聚类中心,其目的在于弥补K-means聚类易受初始聚类中心影响的缺陷。本文算法核心思想与以往的研究中如运用强化初始聚类中心(ROBust initialisation,ROBIN)算法[22]、改进场景聚类法[23]、基于空间分布选初始聚类中心的聚类算法[24]原理类似,目的是使选取的初始聚类中心能最大程度接近数据样本集的自然数据中心点,以减少传统K-means算法在聚类中初始聚类中心指定的随机性。与这3种算法不同之处在于所设计的融合聚类算法采用随机选取样本后层次聚类的方式,其中心指定评价规则更少、算法结构更简单,在事故数据样本聚类中能明显减少计算量、缩短聚类时间,更能适应大数据量、高纬度的事故数据样本。
4 结论
(1)完成了大量交通事故样本中的典型交通事故的快速提取,并根据典型事故设计了AEB测试场景,形成了从原始数据库中选取事故数据样本构建AEB测试场景的有效方法和手段。所设计的测试场景可为AEB测试提供场景来源,为进一步标准测试场景的扩充提供参考。在数据聚类中,提出了融合聚类算法,从聚类结果可以看出,该算法实现了对事故数据库中典型事故的准确聚类。通过融合聚类算法与传统K-means算法分别处理数据样本的5次试验对比,融合聚类算法平均减少算法迭代次数,减少SSC及其波动,聚类结果中样本聚合度更高。相比传统K-means算法,融合聚类算法对高维度、大数据量的事故数据样本的适应性更好。
(2)受聚类算法原理限制,融合聚类算法只能聚类出特征要素中占比较大的典型特征。事故样本中天气条件和光照条件等特征要素中特征为晴朗和日照充足的事故数量占比达74%,因此聚类出的每一类事故中天气条件和光照条件为晴朗和日照充足的事故数量均占到该类总事故数量的70%,故12类典型事故的环境条件均为晴朗和日照充足。可以在本文所提出的测试场景的基础上设置不同环境条件,以扩充AEB在不同环境中的适应性测试。此外,融合聚类算法对于同一类场景中两车的碰撞部位、运动状态的划分还不够精细,如聚类数据集中第11和第12类场景可以解读出两车互为撞击车的同类型场景。在实现数据样本快速准确聚类、进一步提升聚类算法对数据样本的适应性等方面还需要研究。
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
北京航空航天大学学报(2022年8期)2022-08-31
南京理工大学学报(2022年1期)2022-03-17
计算机应用与软件(2021年7期)2021-07-16
小雪花·成长指南(2020年2期)2020-10-12
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
领导决策信息(2018年16期)2018-09-27
劳动保护(2018年5期)2018-06-05
人大建设(2017年10期)2018-01-23
数学学习与研究(2017年3期)2017-03-09
