
改进生成对抗网络的换衣行人再识别
2022-09-28 08:59张玉霞车进贺愉婷
液晶与显示 2022年10期
张玉霞,车进*,贺愉婷
(1.宁夏大学 物理与电子电气工程学院,宁夏 银川750021;2.宁夏沙漠信息智能感知重点实验室,宁夏 银川750021)
1 引 言
行人再识别[1](Person re-identification,ReID)是指给定一个目标监控行人图像,检索跨摄像头、跨时段拍摄的该行人图像。行人再识别通常被视为一个度量学习问题[2]。由于在安全和监控方面有重要的应用,因此行人再识别受到学术界和工业界的广泛关注。随着深度学习方法的广泛应用,不同算法的ReID性能迅速提高,但由于拍摄的行人图像会受到背景、光照、人体姿态变化、遮挡等引起的显著类内差异的影响,并且行人再识别研究[3-6]都假设同一个人穿着相同的衣服,如文献[7]中提到的一名女嫌犯为躲避追捕,故意将黑色外套换成白色外套,行人再识别算法很容易将穿着不同、ID相同的行人识别错误。因此,行人再识别仍是一项艰巨的任务。
为进一步减少类内变化的影响,文献[8]寻找最优的仿射变换用来更好地区分不同的身份ID,提出PAN网络,在不用额外的标注情况下同时进行行人对齐和学习判别性的特征描述。文献[9]提出一个基于身体部位对齐的双流网络模型,可以将人体姿势表示为部分特征图,并将它们直接与外观整体特征图结合以计算对齐的行人部位表示。张良等人[10]提出将局部特征、全局特征和多粒度特征融合,提高行人再识别精度。文献[11]首次将生成对抗网络(Generative Adversarial Network,GAN)引入到行人再识别中,利用生成的数据扩充数据集来辅助训练,提升行人再识别精度。PTGAN[12]的提出主要是用来弥合不同数据集之间的领域差距。文献[13]提出一种利用姿态以及外观特征混合编码的行人再识别算法,以解决摄像机视角造成的类内差异。PNGAN[14]将每个行人图像生成8个标准姿态的假图,最后将生成图和原数据集图像一起输入识别网络,在一定程度上消除姿态变化的影响。文献[15]采用一个具有双分支结构的孪生神经网络,只学习与行人身份相关的特征。杨海伦等人[16]因行人存在遮挡问题提出基于可变形卷积的CNN模型,并用CycleGAN解决相机风格问题。
以上方法主要是将行人进行对齐或者用GAN生成不同相机风格、不同姿态数据来扩充训练集,再进行分类识别。不同于以上方法,本文在DGNet网络[17]的基础上提出改进生成对抗网络的换衣行人再识别算法,不仅将GAN数据生成和行人再识别学习端对端结合起来,而且不需要任何辅助信息就能够生成高质量图像,对ReID进行图像增强。生成模块中的编码器将每个行人分解为外观编码(衣服+鞋子+手机+包包+身份信息等)与结构编码(姿态+头发+脸型+背景等)。通过切换外观编码和结构编码,生成模块能够生成高质量的合成图像,然后在线反馈给鉴别器进行辨别真假,并用于行人再识别模块提高行人识别精度。其中,鉴别模块与行人再识别学习是共享的。通过在鉴别模块中加入通道间的注意力机制模块(Normalization-based Attention Module,NAM)[18],突出网络显著特征,更好地辨别图像真假,提高行人分类识别的精度。用DenseBlock[19]替换DG-Net网络中生成器与鉴别器的ResBlock,加强特征传播,避免梯度消失问题,再一次提高生成图质量与行人再识别精度。通过实验可知,本文算法在Market-1501、DukeMTMC-reID两大公开数据集上的rank-1/mAP分别达到95.7%/88.6%和87.1%/75.7%,证明本文算法并具有一定的优势。
2 网络架构
本文网络架构如图1所示。图像生成模块与行人再识别模块端对端结合起来,外观编码器和鉴别器是共用的,这也是行人再识别学习的主干。生成器通过自生成网络和互生成网络两种映射合成假图像,将数据集图像与生成图像一起输入到鉴别器中判别真假,并且对其进行分类识别,提高行人再识别的识别精度。鉴别模块包含主要特征学习、细粒度特征挖掘以及注意力机制NAM。通过不同角度进行学习,网络不仅能够得到行人衣服等外观的信息,而且学习到外貌等更细致的结构特征,从而更好地鉴别图像真假,提高识别精度。

图1 网络架构Fig.1 Network structure
2.1 生成网络
生成网络框架图如图2所示。本文数据集中的真实图像与身份标签用X=和Y=表示,其中N表示图像的数量,yi∈[1,K],K表示数据集中类别的数量。给定训练集中两幅真实图像,通过生成模块交换两幅图像的外观与结构代码生成几幅新图像。生成网络包括自生成网络和互生成网络,生成模块由一个外观编码 器Ea:xi→ai、一 个 结 构 编 码 器:Es:xj→sj、一个生成解码器G:(ai,sj)→xij以及一个区分生成图像与原始图像的鉴别器D组成。

图2 生成网络框架图。(a)自生成网络;(b)互生成网络。Fig.2 Generate network frame diagram.(a)Self generation network;(b)Mutual generation network.
2.1.1自生成网络
自生成网络框架如图2(a)所示。给定一对行人图像xi,xj∈X(身份相同),首先生成模块学习如何重建图像,自生成网络首先提取图像xi的外观特征ai以及其结构特征si生成与原始图像外观、结构均一致的假图像,使用像素级损失函数:

自生成网络同时会生成同一身份、不同结构的图像,因此采用图像xi的结构特征si与xt的外观特征at生成图像,同样使用像素级损失函数:

这种跨图像(相同身份但不同结构)重建用外观编码器将相同身份的外观联系一起,减少类内变化。对于不同身份的图像来说,使用身份损失来区分不同身份。

其中,p(yi|xi)是基于外观编码预测xi属于实际类别y(iID)的概率。
2.1.2互生成网络
互生成网络框架如图2(b)所示。互生成网络的输入图像为xi,xj∈X(身份不同,即yi≠y)j,主要是生成不同身份的图像。该网络提取图像xi的外观特征ai、结构特征si和xj的外观特征aj和结构特征sj,通过交叉组合成新图像和。其中生成图像与xi外观一致、xj结构一致;生成图像与xj外观一致、xi结构一致。这里,使用外观和结构编码控制图像生成,损失函数如式(4)和式(5)所示:

与自生成网络一致,同样采用身份损失判断图像身份ID是否一致。

其中p(yi)是预测属于真实类别yi的概率,并且使用对抗损失使生成数据的分布更接近真实数据的分布。如式(7)所示:
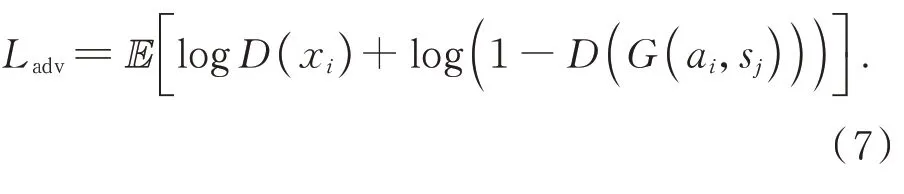
生成器的结构图如图3所示,本文将DGNet网络中的生成器模块内ResBlock模块替换为DenseBlock模 块。结 构 图 中 输 入 图 像xi、xt、xj,首先经过外观编码器得到128个64×32的特征图,经过4个DenseBlock模块之后,输出依旧为128×64×32,特征图不变。其次,进行上采样操作得到128个128×64的特征图,第一次卷积是5×5,卷积后得到64个128×64的特征图;同样进行上采样操作得到64个256×128的特征图,进行第二次卷积操作得到32个256×128的特征图;Conv3、Conv4、Conv5的卷积核分别为3×3、3×3、1×1,最终得到3×256×128大小的生成图。
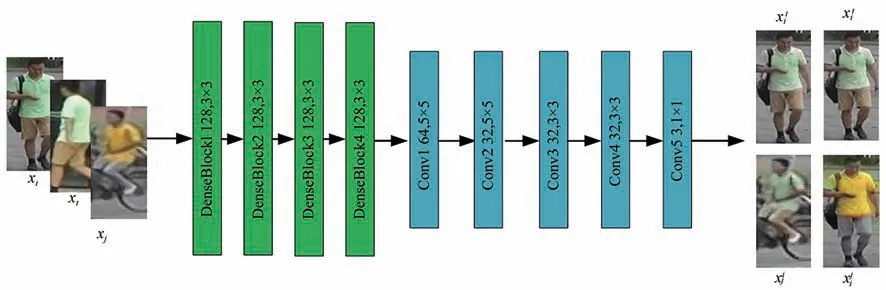
图3 生成器结构图Fig.3 Generator block diagram
DenseNet是Huang等人[19]提出的 一 种 稠 密卷积网络,它主要从特征的角度提高网络性能,并且随着网络深度的增加,能够避免梯度消失问题。ResBlock主要含有一个跳跃连接,而Dense-Block中将所有的特征计算单元的结果以密连接的方式沿着某一维度进行压缩,不是进行简单的求和。DenseBlock结构如图4所示。DenseBlock结构图中除了输入端,还包含4个模块,每个模块均为4层。以X0作为输入,通过Hi进行非线性变化,依次进行归一化、激活函数以及卷积操作,然后传递到后续网络。本文采用即插即用型模块DenseBlock代替原来的ResBlock模块,一方面能够提取更多特征信息,另一方面改善网络的特征提取能力,减少过拟合现象的出现。经过Dense-Block之后,特征图大小不变。DenseBlock结构的任何两层之间都是直接连接的,而每层的特征图也会直接传递给其后的所有层,传递方式为:

图4 DenseBlock结构图Fig.4 DenseBlock structure diagram
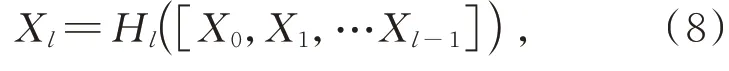
其中,[X0,X1,…Xl-1]表示从第0层到第l层生成的特征图并且各个特征图大小一致,可在通道维度上连接。
2.2 鉴别网络
鉴别网络框架图如图5所示,通过共享外观编码器Ea作为行人再识别学习的主干,将鉴别网络(同是识别模块)嵌入在生成模块中。生成网络通过外观编码和结构编码生成图像,鉴别网络中提出特征学习与细粒度特征挖掘以及新加入的通道间的注意力机制NAM三者进行联合学习判断生成图像真假,以更好地利用生成图像。
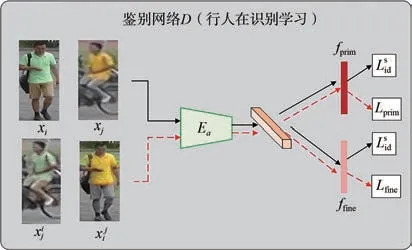
图5 鉴别网络框架图Fig.5 Discriminator network frame diagram
(1)主要特征学习。将真实图像xi、xj与生成图像xij、xji一起输入Ea中作为训练样本,由于生成图像的多样性,采用带有身份损失的卷积神经网络(即教师模型)、外观编码器学习主要特征,通过损失函数将预测概率分布与真实概率分布差异降到最低。
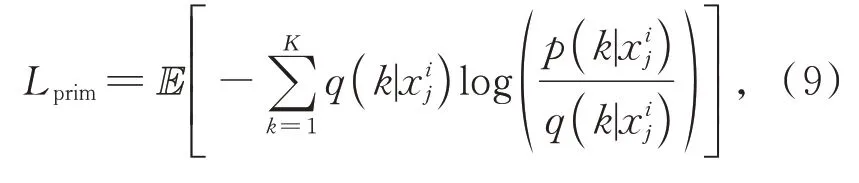
其中,K表示身份类别数量。
(2)细粒度特征挖掘。当生成的图像用主要特征学习无法判断真假时,本文采用细粒度挖掘。当相同身份的人穿着不同的衣服或者不同身份人穿着同样的衣服时,鉴别模块采用细粒度特征挖掘,使网络被迫学习与衣服无关而与细粒度ID相关的特征(如头发、体型等),进一步提高鉴别能力与行人再识别分类识别的精度。损失函数如式(9)所示:

该损失为鉴别模块增加身份监督,不仅学习到细节纹理特征,而且有利于解决行人外观(如换衣)发生变化均导致识别下降的问题。
(3)注意力机制NAM。鉴别网络结构图如图6所示。输入原图像xi、xj与生成器生成的图像xi

图6 鉴别网络结构图Fig.6 Discriminator network structure diagram
j、xi
j,首先用1×1的卷积得到32个256×128的特征图,然后经过通道注意力NAM,这里特征图大小不变。然后在经过4次卷积核为3×3的卷积运算,得到64个64×32的特征图,并经过4个DenseBlock模块。这里后3个DenseBlock模块前加入通道注意力NAM,不改变通道以及特征图大小,依旧是64个64×32的特征图。最后,经过1×1的卷积得到一个64×32的特征图,给出一个0~1之间的数值判断图像真假,同时对图像进行分类识别。
除了主要特征学习与细粒度特征外,本文在鉴别器的第一次卷积之后与前3个DensesBlock模块之后加入了2021年提出的新型注意模块NAM,主要是通过利用训练模型权重的方差度量来突出显著特征。以前的注意力机制模块大多数都是通过抑制不重要的权重来提高神经网络的性能,NAM作为一种高效、轻量级的注意力机制,在保持相似性能的同时计算效率更高。采用CBAM[20]的模块集成,并重新设计了通道和空间注意力模块,使用标准化BN中的比例因子,如式(11)所示,测量通道的方差并指示其重要性。

式中,μB和σB分别表示小批量B的平均值与标准偏差;γ和β是可训练的仿射变换参数。通道注意力模块如图7所示。其中,F1表示输入特征,γ是每个通道的比例因子,权重由公式Wγ=获 得,Mc表 示 输 出 特 征,如 式(12)所示:

图7 通道注意力机制NAMFig.7 Channel attention mechanism NAM
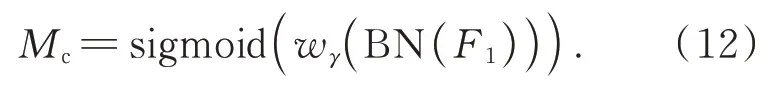
2.3 总体损失函数
由2.1节与2.2节介绍可得,总体损失函数为:

2.4 参数设置
本文是基于PyTorch1.1、Python3.6深度学习框架下实现的。网络模型中采用SGD优化器来优化外观编码器Ea,使用Adam优化器来优化结构编码器Es、生成器G和鉴别器D。本文参数β1=0,β2=0.999,设 置 初 始 学 习 率为0.001,共20个epoch,每个epoch迭代训练10 k次,批尺寸(Batch size)为16。训练过程中保持所有图像的长宽比,将大小统一为256×128。
3 实验结果与分析
3.1 数据集和实验环境
本文在行人再识别算法的公开数据集Market1501[21]、DukeMTMC-reID[22]上进行实验。Market1501数据集共有1 501个行人的32 668个检测行人矩形框,共6个摄像头,包括训练集、测试集、查询集。DukeMTMC-reID共有1 812个行人的36 411个检测行人矩形框,由8个摄像机采集。因为有408人没有出现在两个摄像头以上,所以只选择1 404个行人作为训练集与测试集。该数据集包括训练集、测试集、查询集。公开数据集的详细信息如表1所示。实验室拥有一台具备4块TITAN V GPU的图形工作站,具备良好的开发环境。本实验将在Ubuntu 16.04.5 LTS操作系统,TITAN V 12G×4显卡,Pytorch1.1深度学习框架,python3.6的服务器下实现。

表1 公开数据集详细信息Tab.1 Public datasets details
3.2 评价标准
行人再识别模型用首位命中率(Rank-1)、平均精度均值(mean Average Precision,mAP)和累计匹配曲线(Cumulative Match Characteristic,CMC)3种评价指标衡量模型。这里,Rank-k表示在查询集中行人特征相似度大小的排序列表中前k位存在检索目标的准确率。
3.3 生成图像示例
改进网络通过切换姿态与外观生成大量的高质量图像。给定输入图像xi和xj,网络模型提取输入图像的外观特征以及结构特征,既可以生成具有xi的外观、xj的结构的假图像xi j,又能生成具有xj的外观、xi的结构的假图像xj i。两个数据集生成的图像如图8所示。

图8 交换外观与结构生成图像示例Fig.8 Examples of images generated by swapping appearance and structure
假设每行每列输入图像都一致,通过切换外观或结构代码在Market-1501、DukeMTMC-reID上生成图像的示例如图9所示,可以看出横轴行人生成外观不同、结构相同的假图像;同样地,纵轴行人生成外观相同、结构不同的假图像。在Market1501、DukeMTMC-reID数 据 集 上,模 型分别生成共计140 625张、123 201张假图像。虽然改进生成对抗网络方法能够生成大量的高质量图像,但是由于数据集本身存在模糊、分辨率不高的问题,并且图像的背景影响导致生成的图像会出现少许效果差的结果图像,如图10所示。

图9 切换外观或结构代码生成图像的示例Fig.9 Examples of images generated by switching the appearance or structure code
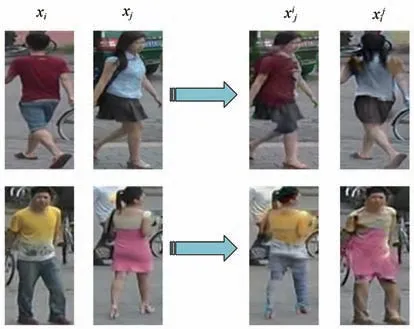
图10 少许失败案例Fig.10 A few failure cases
3.4 实验结果
为了进一步证明该网络的有效性,使用相应的评价标准计算得到了该算法的Rank-1和mAP,并与现有算法在Market1501、DukeMTMC-reID数据集上的结果进行对比分析,如表2所示。
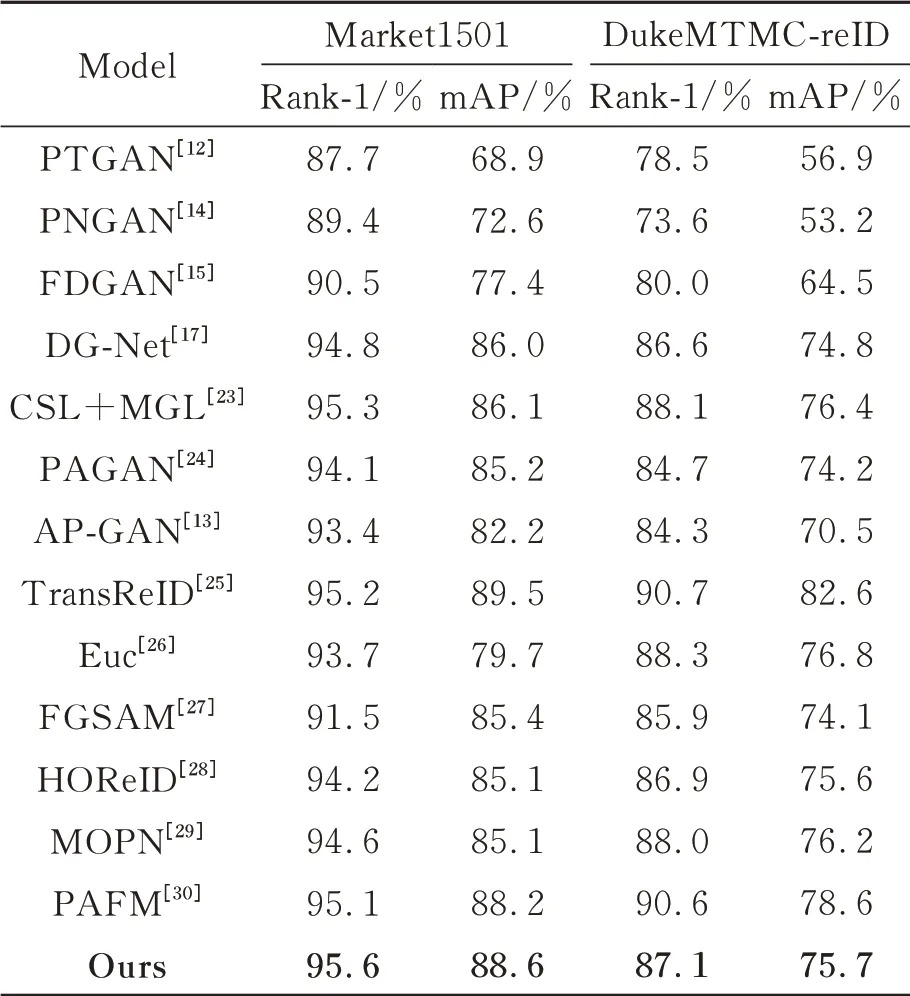
表2 本文算法与现有算法的比较Tab.2 Comparison of the algorithm in this paper with existing algorithms
将本文算法与8种基于GAN的ReID方法和5种有监督的ReID方法进行性能比较。针对基于GAN的ReID方法性能比较可知:对于Market1501数据集,从表2的实验结果可以分析到本文算法在Rank-1和mAP的指标上均优于其他算法(除TransReID之外),Rank-1相比于DG-Net、CSL+MGL、PAGAN、AP-GAN、TransReID分别提高了0.8%、0.3%、1.5%、2.2%、0.4%;mAP相比于DG-Net、CSL+MGL、PAGAN、AP-GAN、Trans-ReID分别提高了2.6%、2.5%、3.4%、6.4%、-0.9%。对 于DukeMTMC-reID数 据集,本文算法在Rank-1和mAP的指标上仅次于CSL+MGL、TransReID算法。Rank-1相比于DGNet、CSL+MGL、PAGAN、AP-GAN、TransReID
分别提高了0.9%、-0.7%、1.5%、5.2%、-6.9%。针对5种有监督的ReID方法性能比较可知:对于Market1501数据集,本文算法的Rank-1和mAP均优 于 这5种 算 法,Rank-1和mAP分 别 比Euc、FGSAM、HOReID、MOPN、PAFM提高了1.9%、4.1%、1.4%、1.0%、0.5%和8.9%、3.2%、3.5%、3.5%、0.4%;对于DukeMTMC-reID数据集,本文算法的Rank-1和mAP高于FGSAM、HOReID算法,Rank-1和mAP分别比FGSAM、HOReID高1.2%、0.2%和1.6%、0.1%。说明本文算法在Market1501上的效果更显著。同时进一步说明本文算法具有一定的优势。综上所述,所提算法不仅能够较好地提高行人识别的精度,还使模型有较强的泛化能力。
3.5 不同改进点的消融实验
本文主要有2点改进:(1)使用新型注意力机制NAM;(2)将原有的DGNet网络中的Res-Blocks替换为DenseBlocks,采用像素损失、对抗损失、身份损失等多种损失联合优化提高生成图的质量。以Market1501为例,对不同改进点进行性能评估,如表3所示。
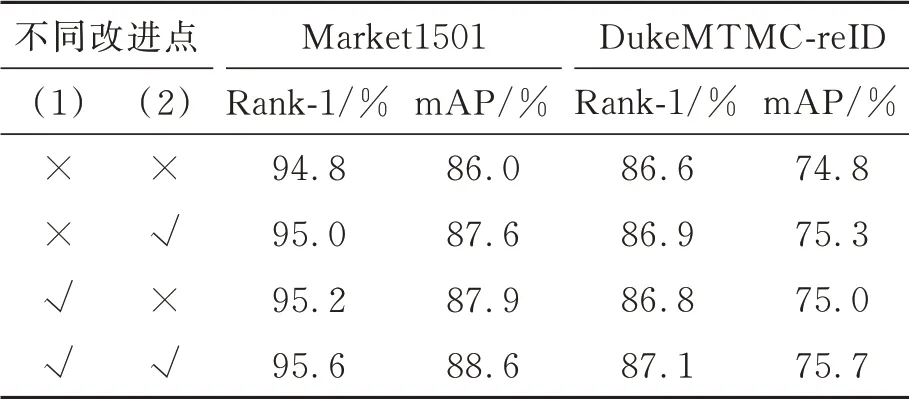
表3 不同改进点的性能评估Tab.3 Performance evaluation of different improvement points
4 结 论
本文提出改进生成对抗网络的换衣行人再识别算法,是一种将生成对抗网络(GAN)数据生成和行人再识别学习端对端结合起来的联合框架,通过切换外观与结构编码,生成模块中的自生成网络与互生成网络生成大量图像,鉴别模块与生成模块之间在线循环,将生成的图像在线反馈给鉴别器,鉴别器通过主要特征学习、细粒度特征挖掘与注意力机制NAM三者联合学习,进一步提高鉴别器鉴别能力与行人再识别分类识别的准确率。生成器与鉴别器中的残差块ResBlock替换为DenseBlock,加强特征传播并且大幅度减少参数数量。本文算法不仅解决了行人再识别数据集不足的问题,而且提高了跨摄像头下由于行人外观(如衣服)改变的识别率,在图像生成质量和行人再识别分类识别精度方面都有显著的改进,在Market1501和DukeMTMC-reID数 据集上Rank-1和mAP分别达到了95.7%/88.6%和87.1%/75.7%。
猜你喜欢
北京工业大学学报(2022年9期)2022-09-15
北京航空航天大学学报(2022年8期)2022-08-31
计算机系统应用(2022年7期)2022-08-04
学苑创造·A版(2022年4期)2022-06-18
阅读(快乐英语高年级)(2022年6期)2022-06-17
激光与红外(2022年4期)2022-06-09
家庭影院技术(2021年10期)2021-11-20
意林(2021年5期)2021-04-18
扬子江(2019年1期)2019-03-08
小天使·一年级语数英综合(2017年6期)2017-06-07
