
基于ACNNC模型的中文分词方法
2022-09-28 09:56张忠林闫光辉袁晨予
中文信息学报 2022年8期
张忠林,余 炜,闫光辉,袁晨予
(兰州交通大学 电子与信息工程学院,甘肃 兰州 730070)
0 引言
中文分词(Chinese Word Segmentation,CWS)是将组成句子的汉字序列用分隔符切分成单独的词语序列的过程[1]。在英文文章中,单词与单词之间以空格作为分界符,在中文文章中只有字、句和段有明显的分界符,词之间没有分界符,因此需要在词与词之间加标记进行划分,虽然英文也同样存在短语划分问题,但在划分词的层面上,中文划分比英文划分却要复杂、困难得多。中文分词是从信息处理需要出发,按照一定的规范,将文章划分成词的过程,分词结果的好坏直接影响以此为基础的中文信息处理应用[2]。
在中文分词技术中,基于统计机器学习的分词模型引入了文本局部上下文信息,相较于传统的基于词典和规则的方法,其歧义切分和未登录词(out of vocabulary,OOV)识别问题有了较大的提升[3]。
一般分词方法可分为两大类: 字符匹配分词法和基于统计的分词法。正向最大匹配法、逆向最大匹配法和最少切分等方法是字符匹配分词常用的方法,该方法对于歧义切分和未登录词的识别等问题无法很好地解决。基于统计的分词法常用的有隐马尔可夫模型[4](Hidden Markov Model,HMM)、最大熵隐马尔可夫模型[5](Maximum Entropy Markov Model,MEMM)、条件随机场模型[6](Conditional Random Field,CRF)等。其中,HMM最大的缺点是不能选择复杂特征, MEMM则解决了HMM限制特征选择问题,但存在每个节点都要做归一化处理问题,只能得到局部最优值。同时,还存在标记偏见的问题,即训练语料中没有出现的情况会被忽略,而CRF很好地解决了MEMM的局部最优和标记偏见问题。基于统计的分词方法的优势在于能够平等地对待词表和未登录词的识别问题,在分词性能方面有较大提升,但缺点在于学习算法的复杂度较高,计算代价较大,对于标记语料的依赖程度较高,然而现在的计算资源相较于以前有较大提高,因此目前主流的方法大多是深度学习网络模型。
1 相关研究
循环神经网络(Recurrent Neural Network,RNN)是针对序列建模的网络,节点与节点之间相互连接形成有向图,使得RNN 能够表现时间序列的动态时间行为,但由于RNN结构的局限性,在对较长的序列进行预测过程中,只能学习过去短时时间隔的记忆[7]。Hochreiter S 和 Schmidhuber J[8]于1997 年提出了长短时记忆神经网络(Long Short-term Memory,LSTM),在RNN 的隐单元模块上增加遗忘门和输入门,对上一时刻的隐状态信息进行选择性记忆,解决了RNN只能学习短时时间间隔记忆的问题。LSTM虽然已经被广泛应用,但其本质是一个马尔科夫的决策过程,依然无法很好地学习全局信息,并且其计算是递归式进行的,计算速度较慢。
注意力(Attention)机制最早应用在视觉图像领域中。Mnih等[9]于2014年将RNN的模型与注意力机制结合应用于图像分类。Bahdanau等[10]是第一个在NLP领域中使用注意力机制的。Vaswani等[11]于2017年使用自注意力机制(self-Attention)代替RNN结构学习文本,并提出了多头注意力机制(multi-head Attention)。Duan等[12]提出将注意力机制与编码器/解码器结合的方式,使用编码器进行输入,然后使用注意力进行评分,经过解码器进行输出。
卷积神经网络(Convolution Neural Network,CNN)由Santors等[13]于2015年提出并使用新的损失函数。Collobert等[14]首次将CNN应用于自然语言处理。Wang等[15]使用完整的单词信息对词向量进行训练,使用CNN模型抽取特征,但CNN的不足是不适合学习远程语义信息。
随着深度网络的快速发展,其模型越来越多地被应用于中文分词。Chen等[16]将LSTM应用于中文分词,在一定程度上解决了RNN无法学习远程语义信息,存在对下文依赖不足的问题。金宸等[17]采用BiLSTM模型解决了对上下文依赖不足的问题,并引入遗失率,取得了不错的分词效果。He等[18]提出BiLSTM CRF与多准则学习结合的模型,在学习上下文特征的同时,并且考虑CRF层输出标签依赖关系,虽然BiLSTM能够捕捉序列整体信息,但与Attention相比较仍然无法很好地学习全局信息,并且存在忽略局部特征的缺点。
针对以上问题,本文提出了注意力卷积神经网络条件随机场模型ACNNC并使用SIGHAN CWS BACKOFF 2005提供的PKU、MSR、CITYU和AS四个数据集进行训练测试。首先,嵌入层使用Word2vec算法在该训练语料上练得到词向量,并对词向量进行训练得到词向量矩阵,嵌入层输出结果分别输入注意力层和CNN层,其次,使用注意力机制学习文本上下文信息能够很好地捕捉语义依赖,CNN用来抽取局部特征和位置特征,将注意力层和CNN层学习到的特征进行融合;然后,输入CRF层,条件随机场考虑标签之间的依赖信息,以提高分词性能。
2 ACNNC建模
本文提出的ACNNC模型包含以下几层: 嵌入层、注意力层、CNN层、融合层和CRF层。模型的具体框架如图1所示。嵌入层训练得到128维词向量,将词向量输入注意力层和CNN层,注意力层学习序列全局特征,CNN层学习序列局部特征和位置特征,融合层将注意力层和CNN层学习到的特征信息进行融合,融合后的特征输入CRF进行解码。
2.1 嵌入层
嵌入层将训练语料中的词xi转换成向量ei,并进行预训练得到词向量矩阵X,对于X来说存在X∈Rd×|N|,其中|N|为语料中有效字符的个数(词表),d为词向量的维度。假设句子x由n个词组成x=(x1,x1,…,xn),第i个词对应的词向量为ei,每个词可以通过词向量矩阵X将其转换成词向量表示,如式(1)所示。
ei=X×i
(1)
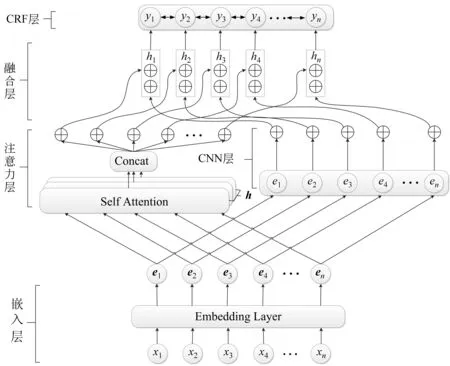
图1 整体框架图
2.2 注意力层
注意力机制借鉴了人类注意力机制,人类在注意某一事物时,大脑首先快速扫描全局信息,然后获得需要重点关注的目标域,而后对该区域投入更多的注意力资源,极大地提高了处理信息的效率与准确性,可以将注意机制描述为查询和一组键值对映射到输出、查询、键,值和输出都是向量。 输出以加权总和计算值,其中分配给每个值的权重是通过用相应的键查询得出的,其定义如式(2)所示。
(2)

单个注意力头部会产生随机的误差,多头注意力机制可以完善单个注意力头部的缺陷。多头注意力机制,首先将Q、K、V进行线性映射,然后在做单个的注意力计算h次,单次的注意力计算公式如式(3)所示,将其结果进行拼接的公式如式(4)所示,其示意图如图2所示。本文使用8个头的自注意力机制,自注意力机制与注意力机制的区别在于Q、K、V是同一个值,即序列本身的依赖关系、多头自注意力机制框架图如图2所示。

图2 多头注意力机制框架
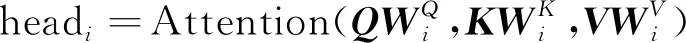
(3)
MultiHead(Q,K,V)=Concat(head1,
head2,…,headh)Wo
(4)
2.3 CNN层
卷积神经网络可以看作是一种特殊的多感知器或者前馈神经网络。卷积神经网络一般包括5个部分: 输入层、卷积层、池化层、全局平均池化层和输出层。因本模型不是单纯的卷积神经网络模型,因此不存在完整的5个部分,仅有输入层和卷积层。
由于自然语言任务的特殊性,卷积操作在本文中使用一维卷积核。设输入句子x=(x1,x1,…,xn)的矩阵为X,其中每个字符的维度为d。为了得到句子的特征表示,模型的滤波器大小设置为k用于卷积操作,宽度为w。卷积操作如式(5)所示。
(5)
其中,σ表示激活函数,“∘”表示点乘,X[i:i+k]表示i到i+k的词向量序列,Hk表示为宽度为k的卷积核。
2.4 融合层
为了将学习到的句子局部特征和较长序列前面的语义信息输入到CRF层,本文使用了融合层将学习到的局部特征和序列整体信息叠加起来作为新的特征输入到CRF层。融合有两种策略: 第一种是两个向量的维度相同,直接相加;第二种是两个向量维度不同,进行拼接,本文采用后者进行融合。
2.5 CRF层
2.5.1 分词序列标注
分词序列标注定义为: 任意句子x=(x1,x2,…,xn),从所有可能的标记序列中挑出最有可能的句子y=(y1,y2,…,yn),其中,xi表示一个字符,i∈{1,2,…,n},yi表示字符xi对应的词语位置。一个字符的位置共有四种,包括: 词首(begin,B)、词中(middle,M)、词尾(end,E)和单个字符(single,S)。一个词语的序列标注可能为: S和B{M}E,其中,S表示单个字符的词,B{M}E表示以B开头以E结尾,且B、E之间可存在M也可不存在M(用{M}表示)。
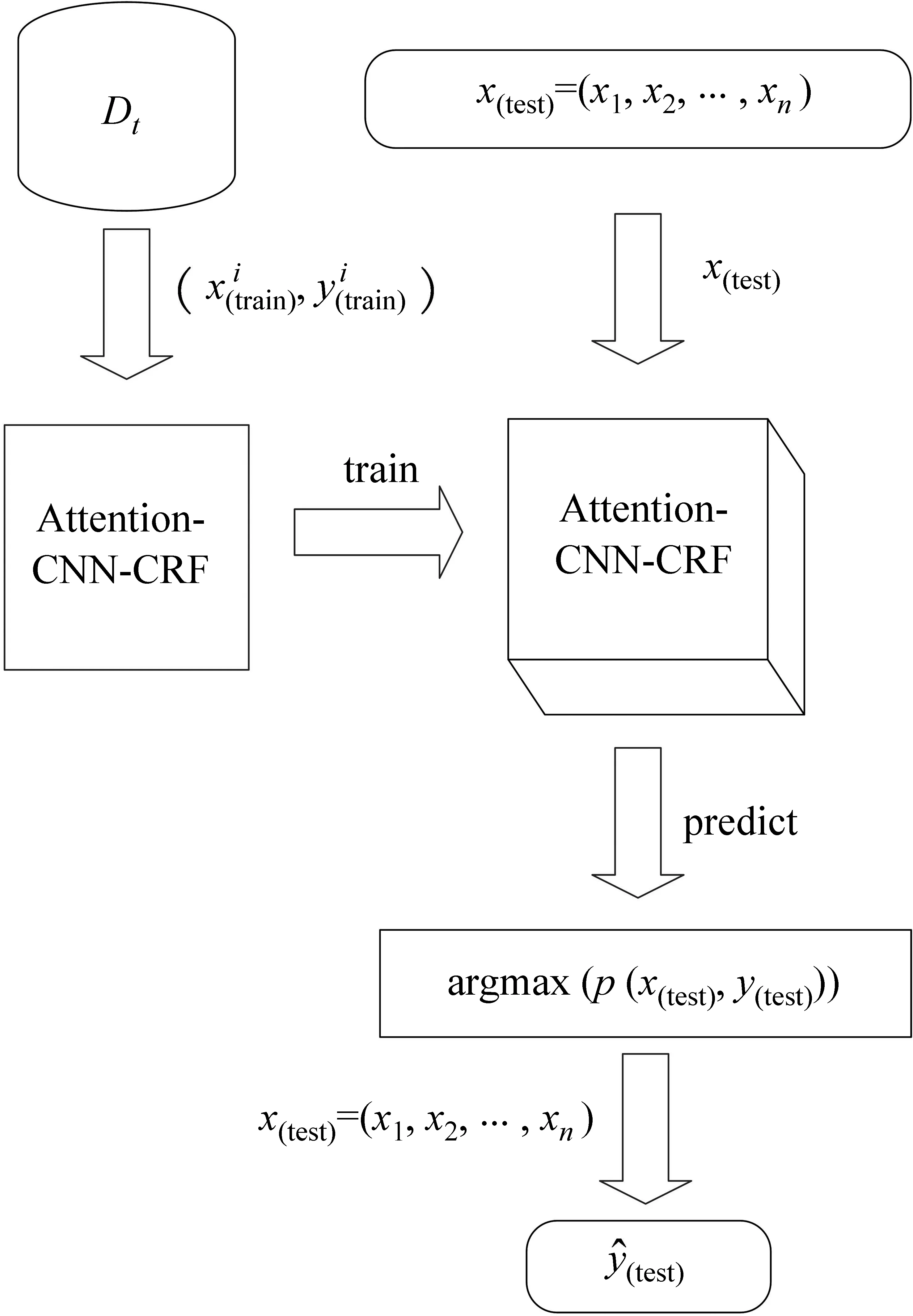
图3 分词序列过程图
2.5.2 条件随机场

(6)
(7)
(8)
3 实验结果与分析
3.1 实验数据、实验环境和评价指标
分词性能的好坏不仅依赖于模型的好坏,而且依赖于训练语料的质量,因此一个高质量的训练语料对于分词的性能有提升。本文使用的语料是SIGHAN CWS BACKOFF 2005提供的PKU、MSR、CITYU和AS四种数据集。对于四种数据集分词的标准各有不同。其中,PKU由北京大学语言研究所提供,它的特点是姓和名是分开的,组织机构等实体词在其词典中是直接标记的,大多数短语性的词语先进行切分然后再组合;MSR 是微软亚洲研究院所提供的语料库,它的分词特点是很多长单词由大量的命名实体构成;CITYU是由香港城市大学提供的语料库,其规范与香港地区的使用习惯相关;AS是由台湾中央研究院提供的语料库,分词规范与北大制定的分词规范类似,但同时也受台湾地区的语言使用习惯影响。数据集的大小和数据集的分词示例具体如表1所示。
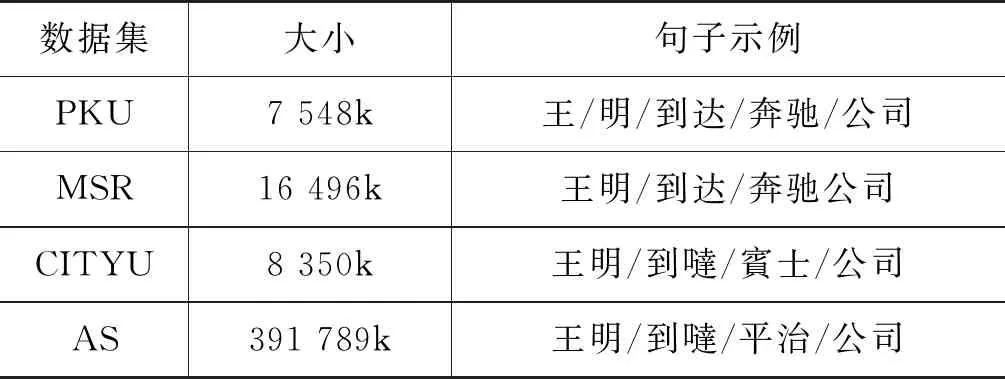
表1 BACKOFF 2005数据集
本文的实验环境如下。处理器: Inter(R) Core(TM) i5-10300H CPU @ 2.5Hz;内存16 GB;图形加速器: NVIDIA GeForce GTX 1080Ti 4GB;操作系统: Windows 10(64bit);深度学习框架: TensorFlow 2.0.0和Keras 2.3.1。本实验采用准确率P(precision)、召回率R(recall)和综合指标F1值作为衡量模型分词性能的评价指标,其中F1的值作为主要参考指标,其计算如式(9)~式(11)所示。
3.2 参数设置
深度学习超参的取值影响模型的性能。本文在参考了文献[19-20]等的超参设置之后初始的超参设置为如表2所示。
将训练语料按照9∶1的比例划分,90%作为训练集,10%作为验证集。测试语料用其提供的测试集,对测试集进行分词后与其提供的标准结果进行对比并计算评价指标准确率P、召回率R和综合指标F1值。

表2 初始超参设置
在模型的训练过程中,与RNN不同的是注意力机制在训练的过程中能学习到序列的全局特征,但对于位置信息则不能充分学习。为了验证位置信息是否对模型性能有影响,即加入位置向量的模型分词性能是否有提升。本文做了如下实验: no_pos未加入位置向量;att_pos在注意力层加入位置向量,CNN层未加入位置向量;pos在自注意力层和CNN层都加入位置向量,三个实验其实验结果如图4所示。由图可知,前5次迭代no_pos和att_pos的F1值略高于pos;随着迭代次数增加,三者差异逐渐减小;从整体看来F1值差异不大。由此可知加入位置向量的模型的分词性能并没有明显提升,因此本文在训练过程中未加入位置向量,即后文的实验均未加入位置向量。

图4 位置向量对比图
训练时,考虑到超参对于模型的性能影响十分重要,我们首先分析学习率(learning rate,lr),学习率作为监督学习以及神经网络中重要的超参,它决定着模型目标函数收敛的时间和能否收敛到局部最优值,合适的学习率能够使目标函数在较短的时间内迅速收敛到局部最小值,缩短模型的训练时间。本文的优化器初始学习率分别设为0.001、0.000 1和不设置,迭代10次并且对比每次迭代后的F1值的变化情况,如图5所示。由图可见,初始学习率不设置时第一次迭代的F1的值接近91%。高于其他两个实验。随着迭代次数增加,这种优势依然存在。总体来看,不设置初始学习率的分词性能优于初始学习率为0.001和0.000 1。一个合适的学习率能够快速收敛和提高模型的性能,因此本文采用不设置初始学习率的Adam优化器进行参数更新。
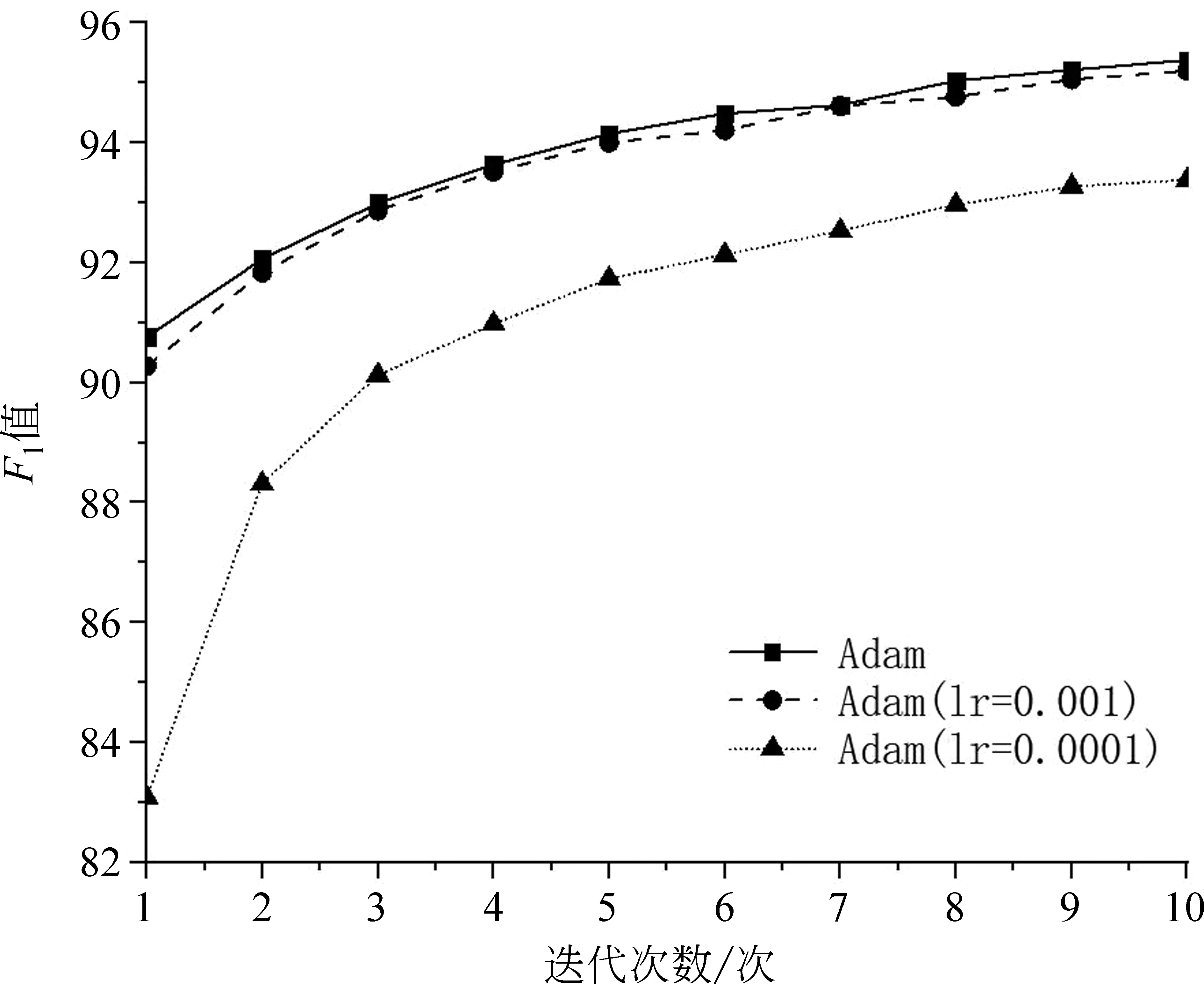
图5 不同学习率对比图
batch_size是指每次训练所抓取的数据样本数量,它的大小影响训练速度和模型优化。若batch size过小,则会花费过多的时间,并且梯度震荡严重,不利于目标函数收敛;若batch_size过大,不同batch的梯度方向不会产生变化,同时容易陷入局部极小值。将batch_size分别取8、16、32和64进行对比(使用不设置初始学习率的Adam优化器进行参数更新),对比结果如图6所示,训练时间增量表如表3所示。可以看出,当batch_size=8时F1值整体是优于其他batch_size取值时的F1,但其训练时间相对较长;当batch_size=16时,F1值虽然不及batch_size=8,但整体呈上升的趋势;当batch_size取32或64时,虽然其训练时间缩短了,但分词性能不及batch_size取16。
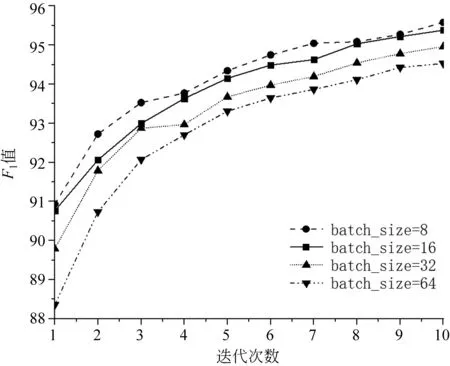
图6 不同batch_size对比图
如表3所示,四种不同的batch_size取值,随着取值逐渐减小: 迭代10次的总时间是逐渐递增的(time of 10 epoch);F1值是逐渐增大的,分词性能要达到相同的精度,越大的batch_size值需要迭代的次数越多;训练时间的增量是增加的,训练时间最短的设为1,其余为与最短时间的比值,且在取值16和8之间的增量达到最大值0.22,但二者的F1值却只相差0.2%,综合考虑训练时间和F1值,本文的batch_size取值为16。
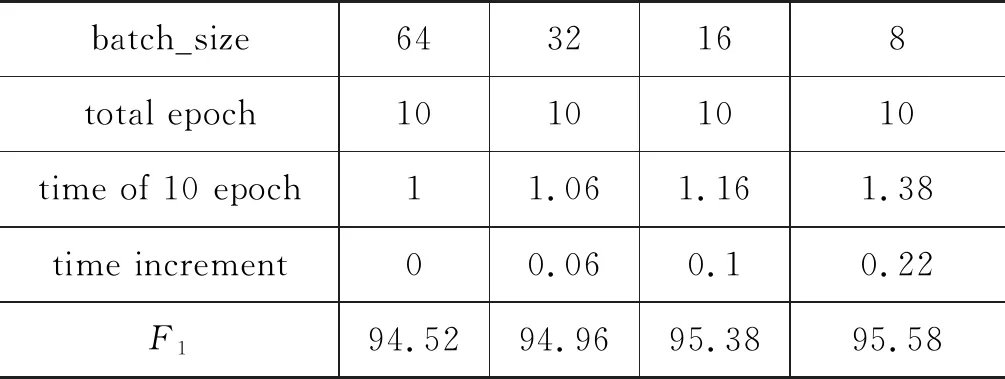
表3 batch_size时间增量表
在机器学习的模型中,若训练样本太多,并且所有特征都用以学习训练参数,容易产生过拟合的现象。过拟合是很多机器学习的通病[21],为减少过拟合现象,本文采用了三种不同的策略。
(1) dropout作为训练深度学习一种减少过拟合现象策略,在每个训练批次中,通过随机地让部分神经元失去活性,可以明显地减少过拟合现象。本文在注意力层和CNN层都添加了dropout,并将dropout分别设置为20%、50%和0%,对比其差异(使用不设置初始学习率的Adam优化器进行参数更新,batch_size=16,迭代10次)如图7所示。三个不同的dropout值模型性能差异较大,可看出大dropout值将语料的重要特征丢弃,并且越大的dropout值重要特征丢弃的越多。当dropout取值50%时,15次迭代后,F1值最高为94.2%;当dropout取值为20%时,F1值始终增大,并且在第14次迭代超过dropout取值为0%;当dropout取值0时,F1值最高为95.8%,但存在停止增加的趋势,继续训练性能可能提升不大。
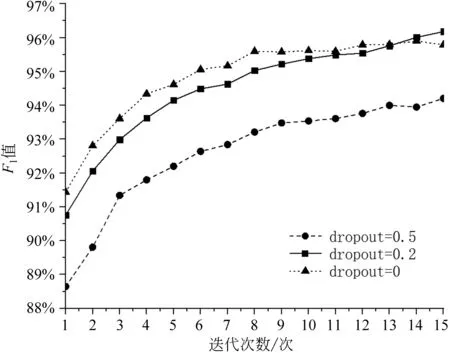
图7 不同dropout对比图
(2) 添加正则项。本文使用的损失函数如式(12)所示。

(12)
其中,x和y分别表示训练数据中的句子和对应的标注序列;U(α)为正则化项,如式(13)所示。
(13)
其中,α为正则项系数,用于平衡对数似然项和正则化项之间的比重,n为训练集大小,w为模型所有参数。
(3) 部分使用ReLU激活函数,定义如式(14)所示。
f(x)=max(0,x)
(14)
ReLU激活函数与Sigmoid和Tanh激活函数相比运算更简单,并与人类神经元细胞对信号处理更加相似,重视正向信号,大于0的留下,其他一律当作0处理,即忽略负向信号。经过该函数处理后的数据有更好的稀疏性,所以在神经网络中取得了很好的拟合效果。
3.3 不同分词方法性能对比
本文通过实验对比分析模型的分词性能最终确定的参数如下: 参数更新使用Adam优化器,不设置初始学习率,dropout丢失率为20%,batch_size为16,在BACKOFF 2005训练集上迭代15次,在测试集上进行测试。
表4列出了近些年来神经网络中文分词模型,并与本文提出的模型做比较。其中,文献[22,24-25]中的模型基于LSTM框架,文献[23]中的模型基于对抗网络框架,文献[26]中的模型基于BiLSTM和CRF框架,本文提出的模型与文献[12,27]基于注意力机制框架。从表中可以看出,基于注意力框架的分词模型在PKU、MSR和AS三个数据集上取得最高F1值,在CITYU数据集上与文献[25]一样高,因此基于注意力框架的分词模型在整体上优于其他框架。

表4 不同分词方法F1值
本文的ACNNC模型融合了注意力机制、CNN和CRF框架,与基于LSTM框架模型相比,本文提出的模型在PKU和AS数据集上取得最优性能,在CITYU上与文献[25]一样高,在简体和繁体数据集上均能取得较优的F1值。本文提出的模型与Adversarial Nets[23]相比在四个数据集上均取得最优。本文提出的模型与BiLSTM CRF[26]相比在三个数据集上均高于BiLSTM CRF模型,因为本文使用注意力层代替BiLSTM层,并添加CNN层捕捉局部特征,使得抽取的句子特征更加完整。
本文提出的模型与纯注意力机制模型(文献[12])相比在PKU和CITYU数据上集优于纯注意力机制模型,在MSR和AS数据集上不及该模型,因此各有优势。与联合多准则模型(文献[27])相比,在简体数据集上不及该模型,但本文可适用于繁体和简体两种中文数据集。由于添加了CNN层,CNN可以提取句子的位置特征,因此本文的嵌入层不需要添加句子的位置特征,而只使用注意力机制的模型需要在输入向量中单独抽取位置特征并融入输入向量,并且本文的训练时间复杂度和预测时间复杂度优于联合多准则模型。
4 结论
针对现有的神经网络分词模型不能很好地捕捉全局信息和局部信息的问题,本文提出了一种融合局部特征和序列整体特征的神经网络模型ACNNC。该模型以自注意力层代替BiLSTM层能更好地提取序列的整体信息,并且能够缩短训练时间,用CNN层提取序列的局部特征和位置信息,然后将抽取的序列特征进行融合,通过CRF层进行标签解码。在BACKOFF 2005的数据集上,通过实验确定各个参数值,并与近些年神经网络分词模型对比,突出本文提出的模型优势。
本文提出的模型虽然能有效提高分词性能,但仍存在不足,注意力机制代替BiLSTM层能够高模型的速度,但添加CNN层提取局部特征会影响训练时间和分词速度,后续研究在提升模型的分词性能的同时缩短训练时间。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
现代计算机(2021年33期)2022-01-21
校园英语·月末(2021年13期)2021-03-15
长江丛刊(2019年25期)2019-11-15
电脑知识与技术(2019年23期)2019-11-03
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
教学与管理(理论版)(2009年9期)2009-11-04
