
基于深度学习的格萨尔史诗命名实体识别研究
2022-09-28 09:56:10环科尤华却才让才让当知多杰才让
中文信息学报 2022年8期
环科尤,华却才让,才让当知,多杰才让
(1. 青海师范大学 计算机学院,青海 西宁 810016;2. 藏语智能信息处理及应用国家重点实验室,青海 西宁 810008;3. 青海省藏文信息处理与机器翻译重点实验室,青海 西宁 810008)
0 引言
命名实体识别(Named Entity Recognition,NER)是自然语言处理(Natural Language Processing,NLP)任务中重要的基础性工作之一,其主要目的是识别给定文本中的命名实体。NER还可用于处理很多下游NLP任务,例如,句法分析、关系提取、事件提取、问答系统和机器翻译等。而格萨尔史诗经典版本《霍岭》中史诗人物超过了1 000人、场景或故事地点达800多个,生活用具1 000多种,武器铠甲等400多种,甚至战马名称也多达140多个,战神等神祇更是多达400多个[1]。若对实体如此庞杂的史诗语料做命名实体自动识别处理,将有助于提升下游藏文信息处理领域的质量。
目前,在英文和汉文的命名实体识别方面相关研究者已经做了许多研究,并且研究内容和实验成果也相对很好[2-6]。而藏文命名实体识别研究中,于洪志[7]、窦嵘[8]和金明[9]等融合词典和基于规则方法进行了藏文命名实体识别的初步尝试,是最早可查的关于此领域的研究成果。后来,加羊吉[10]、华却才让[11]和珠杰[12]等用了基于混合和基于神经网络的方法来研究藏文命名实体。其中,华却才让[11]、加羊吉[10]、刘飞飞[13]和贡保才让[14]等研究了三大类的藏文命名实体。其他研究者研究了一类实体的识别性能。对比以上论文及实验结果发现,目前研究三大类藏文命名实体识别中最高的综合性能为89.09%[10],以及研究单一类藏文命名实体识别中最高的F值分别是藏文机构名为91.09%[11]、藏文人名为88.30%[15]、藏文地名为88.45%[16]。
除上述命名实体识别研究的不同方法,各实验数据的内容及规模也有所不同。尤其是藏文命名实体的类型与数量部分,实体的标注类型仅限于人名、地名和机构名,识别类型相对较少,未见到针对特定领域命名实体自动识别的研究文献。为此藏文命名实体识别存在进一步研究和提升的空间,为进一步丰富藏文命名实体的研究领域,补充和构建不同领域的语料数据资源库。本研究以具有丰富藏文命名实体类型的格萨尔史诗为研究对象,主要以格萨尔史诗经典版本《北方降魔》《霍岭大战》《闷岭大战》和《姜岭大战》等著名的四部降魔史[17]的文献资源为基础,提出了以藏文音节(Tibetan Syllable,TS)为基本单元的TS-BILSTM-CRF的格萨尔史诗命名实体识别(简称GesarNER)方法。将格萨尔文献中的命名实体归纳总结,并分为六种类型,以半自动方式标注了较大规模的格萨尔命名实体语料库,经实验取得了良好的结果。
1 格萨尔命名实体类型及特征
格萨尔史诗的命名实体非常丰富,该史诗中除了包含传统的人名、故事地名、组织机构名等的命名方式外,还包括其独具特色的神祗、神兽坐骑、武器铠甲等实体,每种实体被赋予了独特的文化背景。本文依据格萨尔史诗的命名实体的特征,制定了六种格萨尔命名实体类型,具体内容如下。
1.1 人名实体的特征
人名实体以人类为区分个体,给每个个体给定的特定名称符号,即每个人都有的一种代号[18]。本文研究的格萨尔史诗中人名实体主要包括人名和神祗名,其结构特征以四音节和六音节为主。


1.2 地名实体的特征
地名实体是指人们赋予某一特定空间位置上对自然或人文地理实体的专有名称[20]。本文研究的格萨尔史诗中,地名实体主要以四、六音节为主,包括场景、宫殿和城堡。

1.3 组织机构名实体的特征
1.4 武器铠甲实体的特征

1.5 神兽坐骑实体的特征
1.6 生活用具实体的特征
格萨尔史诗是多领域研究的知识资源,本文从命名实体识别的角度来探索及研究,并制定了六种类型的格萨尔命名实体。其中,第六种实体类型是生活用具及需要分类但还未分类的其他实体组成,这种类型的实体特征暂时无法详细地归纳,需要进一步研究。
2 数据预处理及实体边界算法
2.1 数据预处理方法
在自然语言处理中,词向量表示也称分布式表示(Distributed Representation)或词嵌入(Word Embedding),其目标是将语言的基本单元用最优化的向量表示,以便计算机能够更好地理解自然语言[22]。藏文词向量表示的语言单元为构件、字丁、字、音节和词等,其中音节作为词向量的语言单元,其预处理效果优于其他语言单元,只要解决藏文紧缩词对音节边界的影响即可。
藏文音节是指以藏文音节点为界限的藏文字符组合,是由藏文字丁构成的最小的语言基本单位[23]。以藏文音节为基本单元的语料处理方法有两种,一种是按音节点和特殊符号来切分音节;另一种是在第一种方法的基础上采用规则和还原法来切分紧缩音节。前者保留了原语料的完整正结构和文法接续特征,对信息抽取和句法分析、语义分析等自然语言处理的下层任务有很好的支撑作用。后者虽然较大地提升了分词的效果,但会破坏原语料的语言结构,出现多余的字词,不符合藏文语法规律,因此,本文的预处理方法是第一种方法,其方法没有改变原语料的语法规律、处理效率优于第二种方法,省时省力。两种方法的结果如表1所示。

表1 藏文音节基本单元的切分结果对比
2.2 实体边界识别算法


算法1 格萨尔史诗的实体边界算法Input: 读入格萨尔史诗TextOutput: 抽取格萨尔史诗Named entity1.entitys 识别Text中所有实体2. outputs []3. θ <-实体词缀是紧缩4. ψ <-含有词缀ra的特殊实体集合5. φ <-含有词缀sa的特殊实体集合6. For entity ∈ entitys Do7. words = entity8. If words[-1][-2:] in θ Then9. outputs.add(entity[:-2])10. Else If words[-1] not in ψ and words[-1][-1]=="ra" Then11. outputs.add(entity[:-1])12. Else If words[-1] not in φ and words[-1][-1]=="sa" Then13. outputs.add(entity[:-1])14. Else15. outputs.add(entity)16. Return Outputs
3 基于TS-BILSTM-CRF的GesarNER模型
3.1 长短时记忆网络
长短时记忆网络(Long short-term memory,LSTM)是一种特殊的循环神经网络,它能够在更长的序列中有更好的表现,同时能解决长序列训练过程中的梯度消失和梯度爆炸问题。LSTM单元结构如图1所示。
LSTM的核心主要包括遗忘门、输入门、输出门以及记忆Word。输入门与遗忘门两者的共同作用就是舍弃无用的信息,把有用的信息传入到下一时刻。对于整个结构的输出,主要是记忆Word的输出和输出门的输出相乘所得到的。其结构如式(1)~式(6)所示。
it=σ(Wxixt+Whiht -1+Wcict -1+bi)
(1)
zt=tanh(Wxcxt+Whcht -1+bc)
(2)
ft=σ(Wxfxt+Whfht -1+Wcfct -1+bf)
(3)
ct=ftct -1+ittanh(Wxcxt+Whcht -1+bc)
(4)
ot=σ(Wxoxt+Whoht -1+Wcoct+bo)
(5)
ht=ottanh(ct)
(6)
其中,σ是sigmoid函数。W是权重矩阵,b是偏置向量,it,ft,ot分别是输入门、遗忘门及输出门和单元向量,zt是待增加的内容,ct是t时刻的更新状态,ht则是整个LSTM单元t时刻的输出。在序列标记中可以在给定的时间内同时获得过去和未来的输入特征,因此我们利用了文献[24]中提出的双向LSTM网络,双向长短时记忆网络结构如图2所示。
3.2 TS-BILSTM-CRF网络
在预测当前标签时,BILSTM善于处理长距离的上下文信息,但无法处理标签间的依赖信息。CRF比其他概率图模型能够利用更加丰富的标签分布信息,能通过邻近标签的关系获得一个最优的预测序列,并弥补BILSTM的缺点。本实验将TS-BILSTM网络与CRF网络相结合,形成一个TS-BILSTM-CRF网络,其结构如图3所示。
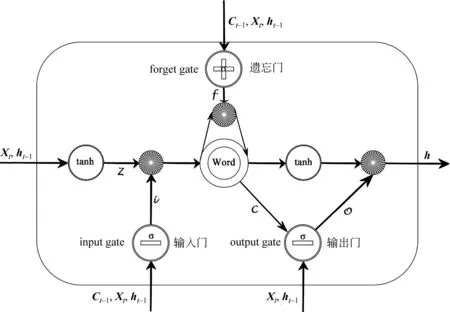
图1 长短时记忆的单元结构
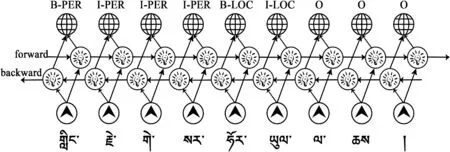
图2 双向长短时记忆模型

图3 TS-BILSTM-CRF网络
4 实验
4.1 实验数据及其规模
实验数据为格萨尔史诗《北方降魔》《霍岭大战》《闷岭大战》和《姜岭大战》等四部降魔史为主的文本语料。数据处理经过了三个步骤: 首先,把收集的语料切分为句子级别的文本;其次,把句子级别的文本进行基于音节模式的分词;最后,在基于音节分词的数据中识别有意义的词汇或命名实体,经人工校对后构建了规模达10万多句的实体标注语料库。实验数据中训练集占80%,剩余作为测试集和开发集,分别对数据中的史诗人物(PER)、史诗地名(LOC)、史诗部落名(ORG)、武器铠甲(WEA)、神兽坐骑(HER)和生活用具(LIV)进行识别,其具体的数据统计如表2所示。
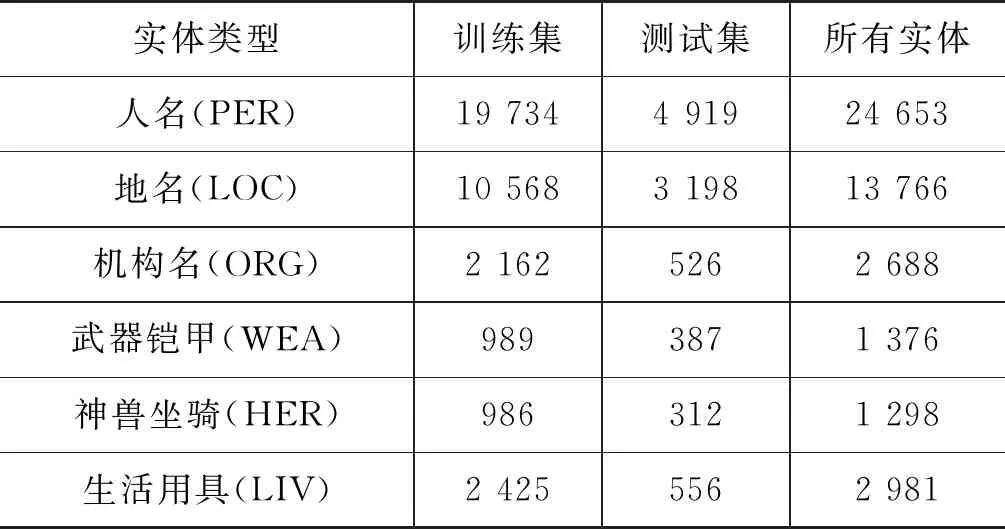
表2 实验数据统计表
4.2 实验参数设置及其评价指标
通过多次试验来优化参数,最终各个参数设置如下: 字嵌入向量维度设置为300;优化算法设置为随机梯度下降法的扩展(Adaptive moment estimation,Adam);模型训练次数设置为2 500;批量处理个数设置为100;隐藏层神经单元个数设置为256;学习率初始化设置为0.001;为了防止双向长短时记忆网络过拟合问题,在各模型的输入输出中采用Dropout,取值为0.5。
实体识别实验需要一个初始音节向量,使用大量文本语料训练音节向量效率更高。本实验把藏文音节作为模型的音节向量单位,用Word2Vec语言模型CBOW(Continuous Bag-of-Words)[25],其实验训练100、200、300以及400维度的向量分别进行对比。实验发现,向量维度过高,实验数据中的噪声容易被捕获,出现过拟合情况;向量维度过低,获取的特征信息不完整,产生欠拟合状况。因此本实验的向量维度为300,结果如图4所示。

图4 不同维度音节向量实验对比
本实验采用准确率P(Precision)、召回率R(Recall)以及F(F-Score)值来评判模型的性能[26]。3个评价指标的计算公式定义如式(7)~式(9)所示。
4.3 实验结果及其分析
(1) 在有限的训练次数(即2 500次)内TS-BILSTM-CRF优于TS-GRU-CRF、TS-IDCNN-CRF、TS-LSTM和TS-LSTM-CRF的结果,所以,在该实验中选用了双向LSTM和CRF结合的方法。其他超参数的选取类似此对比方法。图5是基本超参数不变只有不同迭代时刻的准确率。

图5 不同迭代时刻的准确率
(2) 在已公开的藏文命名实体识别中,研究三类藏文命名实体识别的最高综合性能为89.09%[10],研究单一类藏文命名实体识别的最高F值分别是: 组织机构名为91.09%[11]、人名为88.30%[15]、地名为88.45%[16]。对比已公开的实验,基于TS-BILSTM-CRF模型的人名、地名、组织机构名,以及三类藏文命名实体识别的综合性能分别提升了4.91个百分点、4.66个百分点、1.04个百分点、3.72个百分点。而武器铠甲、神兽坐骑、生活用具是本文首次识别的命名实体类型,目前没有对比系统。以上对比是不同模型和不同数据等不同依据下的结果,对识别方法或模型的有效性无法做出明确的评价。
为了验证本文所提出的数据及实验的有效性,从格萨尔史诗(以四部降魔史为主)中随机抽取98 918条句子作为训练集和9 289 条句子作为测试集进行实验,在同一数据集上设置了基于藏文音节为基本单元的5组对比试验,结果如表3所示。

表3 格萨尔史诗命名实体识别实验对比
实验表明,由于双向LSTM能够获取上下文有效信息特征,再加上CRF能够充分考虑标注序列的顺序性,得到全局最优标注序列。相比于其他四种模型方法,基于TS-BILSTM-CRF模型的命名实体识别的P、R和F值三项指标分别提升了4.39个百分点、7.80个百分点、6.10个百分点。具体识别效果如表4所示。

表4 格萨尔史诗命名实体识别实验结果
(3) 为了进一步展现实验的识别效果,本文设计了格萨尔史诗命名实体识别系统,主要功能有命名实体识别、实体种类分析、实体出现次数统计等。其可视化系统界面如图6所示。

图6 GesarNER可视化系统
5 结语
本文针对特定的格萨尔领域存在标注数量较少且实体识别困难、识别精度不高的问题,提出了一种基于TS-BILSTM-CRF的命名实体识别方法,针对紧缩词和实体边界词黏着问题,设计了格萨尔实体边界识别算法。在自建数据集上实验证明,基于TS-BILSTM-CRF的方法充分学习了文本的特征信息,使得P、R和F值三项指标均有较大程度的提升,优于本实验的其他模型。本方法为专业领域的实体识别提供一种有效的解决思路。
未来工作中,将扩充格萨尔史诗命名实体标注语料的规模,在已有研究的基础上,尝试基于BERT(Bidirectional Encoder Representation from Transformers)嵌入双向LSTM-CRF模型,改进格萨尔命名实体识别方法,为创建格萨尔知识图谱和藏文实体抽取等任务奠定基础。
猜你喜欢
布达拉(2020年3期)2020-04-13 10:00:07
西藏艺术研究(2019年1期)2019-09-04 09:40:14
西夏学(2019年1期)2019-02-10 06:22:34
NBA特刊(2018年17期)2018-11-24 02:46:06
西藏艺术研究(2018年2期)2018-11-15 08:53:38
西藏艺术研究(2018年2期)2018-11-15 08:53:36
NBA特刊(2018年14期)2018-08-13 08:51:40
中华奇石(2017年4期)2017-06-23 08:04:34
西藏大学学报(自然科学版)(2016年1期)2016-11-15 05:23:31
新闻传播(2016年17期)2016-07-19 10:12:05
