
基于CA-Res2Net和可变形卷积的图像去模糊方法
2022-09-27 06:13李武斌李春国杨绿溪
无线电通信技术 2022年5期
李武斌,李春国,杨绿溪
(东南大学 信息科学与工程学院,江苏 南京211189)
0 引言
高质量的图像是众多基于图像的智能视觉算法有效运行的基础,在交通管理、智能监控和医学影像等各个领域具有广泛的应用前景。在实际获取图像的过程中,相机抖动、物体运动和景深变化等多种因素引起的非均匀运动会带来图像模糊,降低图像质量,在影响主观感受的同时,更会严重降低智能视觉算法的性能。因此,图像去模糊技术具有重要的研究意义。
传统图像去模糊算法[1-5]主要是基于简单的假设对图像模糊过程建立退化模型,然后在优化过程中使用不同的图像先验来进行正则化约束,估计出近似模糊核。但是这些传统的优化方法对模糊模型的过度简化使得它们不适用于非均匀的动态模糊场景,且优化模型引入了非凸和非线性约束函数,导致优化过程计算量大,复原速度慢。
近几年,基于深度学习的图像去模糊方法获得了快速发展。这些方法[6-11]主要基于多尺度框架或图像分块框架,跳过了复杂的数学建模过程,利用深度神经网络强大的拟合能力直接学习一个从模糊图像到清晰图像的转换网络。尽管这些端到端的深度学习方法在去除非均匀运动模糊方面显示出了较大优势,但目前这类方法的网络参数量仍较大,图像的局部细节恢复欠佳,去模糊效果仍有提升空间。
本文以自编码器为基础架构,提出了一种新的图像去模糊算法CADNet。为了更好地恢复图像高频细节,CADNet主要做出了以下两方面的改进:在解码网络中引入可变形卷积模块以增强网络适应复杂形变的能力;为了从更细粒度的层次上表示多尺度的特征信息,提出了一种细粒度多尺度注意力机制模块CA-Res2Net。CA-Res2Net充分利用细粒度多尺度特征提取机制和注意力机制,有效提升了CADNet的特征表示能力。CADNet相比于当前主要的图像去模糊算法,在不增加参数复杂度的前提下有效提升了图像去模糊的效果。
1 CADNet网络结构
本文提出了一种以编解码[12](Unet)结构为基础架构的图像去模糊算法CADNet。同时为了提升局部细节恢复能力,引入了可变形卷积模块;为了增大网络的感受野,充分利用局部多尺度信息,引入了细粒度多尺度残差[13](Res2Net)模块;最后,为了充分利用和融合多尺度特征信息,采取对不同尺度的解码特征进行逐步的跨尺度特征融合,最终重建出清晰图像。本文将这种去模糊算法命名为CADNet。图1为CADNet网络的整体架构图,下面详细介绍CADNet的每个部分。
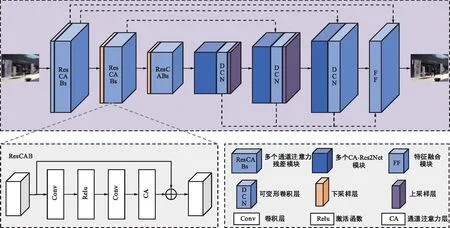
图1 CADNet网络整体结构
1.1 可变形卷积编解码结构
如图1所示,本文提出的CADNet网络以编解码结构为基础架构,同时CADNet的核心层是可变形卷积特征提取层。传统的卷积特征提取层由于卷积核构建的固定性,在卷积运算时作用在像素点周围的一个固定的矩形区域,导致其对未知形状变换的特征建模存在一定的固有缺陷。Dai等人[14]提出了一种可变采样点的卷积操作,即可变形卷积操作。
可变形卷积(Deformable Convolution)能够增强卷积神经网络对复杂形变的建模能力。标准卷积操作中,对于输入图像或特征的每一个像素点,卷积核始终作用在像素点周围卷积核大小的矩形区域。而如图2所示,可变形卷积在标准卷积中的每一个采样点位置上都增加了一个偏移量,这个偏移量是由输入特征通过卷积层学习得到的,具体包括x和y两个方向的偏移值,然后偏移后采样位置的像素值采用线性插值的方式得到。

图2 可变形卷积模块示意图
可变形卷积可以在正常采样位置附近随机自适应采样,增加了对特征的空间采样位置,从而改变网络感受野的范围,提升网络的学习能力。CADNet选择在解码网络中嵌入可变形卷积模块,使解码网络对提取到的模糊特征进行特征复原时,能够自适应地关注不同的模糊形变,提升图像去模糊效果。
1.2 细粒度多尺度注意力残差模块CA-Res2Net
通道注意力残差模块(Residual Channel Attention Block,ResCAB)是CADNet编解码结构中的骨干模块。通道注意力残差模块堆叠了卷积层、激活函数、通道注意力层和残差连接,其中通道注意力机制[15]的引入可自适应地调整通道特征,强化重要的特征信息,增强特征提取能力。
考虑到去模糊网络需要大的感受野,为了在不增加参数复杂度和时间复杂度的前提下提升网络的去模糊能力,CADNet对ResCAB残差模块进一步改进,嵌入了细粒度多尺度残差(Res2Net)结构,将正常的卷积层替换为Res2Net结构,并将该模块命名为CA-Res2Net模块。CA-Res2Net模块的具体结构如图3所示,它由卷积层、激活函数、Res2Net结构层和通道注意力层堆叠组成,并且保留了残差结构。其中Res2Net结构将输入特征x∈H×W×C按通道维度均分为s个特征子集xi∈{1,2,…,s}∈H×W×(C/s),而输出特征子集用yi∈{1,2,…,s}∈H×W×(C/s)表示。输入特征子集与输出特征子集的关系表示为:
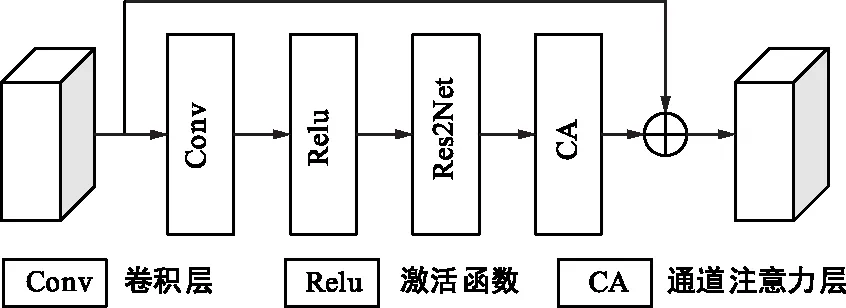
图3 CA-Res2Net模块结构
(1)
式中,Ki表示3×3的卷积核。最后将输出特征子集重新在通道维度上进行拼接,得到输出特征y∈H×W×C。Res2Net结构对特征按通道分组,用一组通道数更少的卷积核替换了原有卷积核,内部结构以类似残差的层次化方式进行连接,不同组的输出特征子集的感受野不断增大,增加了最终输出特征所包含的多尺度信息,有利于提升网络恢复高频细节的能力。同时结合通道注意力机制对重要特征通道信息的进一步强化,CA-Res2Net模块能够有效提升图像去模糊的效果。
问:您在数学建模上的研究一方面启发了数学教育工作者对于将学生数学建模能力的探究,为数学知识联系到现实生活世界的教育目标及其相关研究做了重要贡献,另外一方面也启示了研究者将数学教育领域与其它学科领域相结合的趋势.您在大会报告中包括刚刚也提到了心理学在数学教育研究领域内的重要作用,但同时也提出了心理学不是我们唯一可以联系的学科.在交叉学科研究不断发展成为一种趋势的情况下,您认为数学教育领域研究者为什么需要进行交叉学科研究呢?
1.3 跨尺度特征融合模块
为了充分利用编解码网络中的多尺度信息,跨尺度特征融合模块将浅层的图像特征与不同尺度下解码得到的特征进行逐步的跨尺度特征融合,最终重建出清晰图像,如图4所示。具体来说,最低分辨率的解码特征经过上采样层后与浅层特征相加,然后输入由多个CA-Res2Net模块及残差连接组成的模块(Residual In Residual Channel Attention Block,RIRCAB)中进行充分的特征融合。之后,输出特征通过相同结构的RIRCAB模块与其他尺度下的解码特征进行特征融合和重建,最终输出重建的清晰图像。这样跨尺度的逐步特征融合可以促进信息的流动,减少信息丢失,从而有效利用了多尺度的特征信息。

图4 特征融合模块结构图
1.4 损失函数
本文使用了多尺度内容损失函数。经过实验发现L1损失相比于均方误差(Mean Square Error,MSE)损失,能够帮助网络产生更好的最终性能和更快的收敛速度。本文的内容重建损失函数表示为:
(2)

由于图像的高频分量是图像恢复的重要成分,因此本文还对恢复图像在频域做了损失计算,损失函数是多尺度频率重建损失函数(Multi-Scale Frequency Reconstruction,MSFR)[11]。MSFR损失是不同尺度下真实清晰图像与网络输出的去模糊图像在频域的L1损失,可表示为:
(3)
Ltotal=Lcont+λLMSFR,
(4)
式中,λ为MSFR损失函数的权重系数,实验中设置为0.1。
2 实验结果与分析
2.1 实验数据集与网络训练设置
为了验证CADNet算法的有效性,本文采用国际公开的GOPRO数据集[6]进行训练和测试。GORPO数据集总共包含3 214对模糊和真实清晰图像对,其中2 103对作为训练集用于训练,训练时将训练集拆分为训练集和验证集,1 111对作为测试集用于测试,图像分辨率大小为1 280×720。
本实验模型基于Pytorch深度学习框架进行训练和测试,实验使用的硬件环境是NVDIA GeForce GTX 3090 GPU。训练时对原始图像数据进行预处理,首先从大小为1 280×720的原始图片中随机裁剪出大小为256×256的图像块,然后对图像块进行数据增强操作。数据增强主要是为了扩增数据集,增加网络的训练样本,使训练得到的网络去模糊性能和泛化能力更强。数据增强的方式主要包括随机水平翻转、随机垂直翻转、90°旋转、RGB通道转换和图像饱和度变化,最后将图像归一化到[0,1]作为网络的初始输入。训练过程中,网络使用Adam作为优化器进行梯度更新,Adam优化器使用默认参数,beta1=0.9,beta2=0.999;初始学习率设置为2×10-4,使用余弦退火策略(Cosine Annealing Strategy)[16]逐步降低学习率至1×10-6;受GPU内存限制,批处理大小(batch size)设置为8,共训练了1 000个epoch。训练时编码网络中的ResCAB模块个数和解码网络中的CA-Res2Net模块个数设为16,特征融合模块中的CA-Res2Net模块个数设为4,卷积核大小均为3×3。
2.2 与其他算法的去模糊性能对比
本节选取了近几年主要的几种基于深度神经网络的去模糊算法作为对比算法,包括Nah等人[6]提出的DeepDeblur、Tao等人[7]提出的SRNet、Kupyn 等人[17]提出的DeblurGAN-v2、Zhang等人[8]提出的DMPHN、Suin等人[9]提出的SAPHN网络、Zamir等人[10]提出的MPRNet和Cho等[11]人提出的MIMO-Unet。各算法的去模糊性能对比如表1所示,表1的结果均是以GOPRO数据集作为训练集训练,并在GORPO测试集上测试得到的,其中PSNR以dB为单位,参数量以百万(millions)为单位。需要说明的是,表中的CADNet是完成训练后直接测试得到的结果,而CADNet+是在CADNet的基础上增加了几何自集成(geometic self-ensemble)[18]方法测试得到的。

表1 CADNet与当前主流算法的性能对比
表1中的测试结果表明“CADNet+”在GOPRO测试集上取得了最高的PSNR值和SSIM值,说明了本文方法最终实现的去模糊效果最好。“CADNet+”的PSNR值比表中其他算法中性能最好的MIMO-Unet算法的PNSR值仍高出0.25 dB,即使都不使用几何自集成方法,CADNet的PSNR值仍比MIMO-Unet算法高出0.13 dB,表明本文方法的去模糊性能取得了较好的提升。从网络参数量来说,CADNet的参数量与MIMO-Unet算法相近,比MPRNet算法更小,网络更加轻量化。
为了从主观的角度评价不同算法的去模糊效果,图5显示了不同算法在GOPRO测试图像的去模糊效果示例。从图5可以看出,虽然不同算法获得的结果都比原始模糊图像的模糊程度要低得多,但从复原图像的整体质量以及局部图像细节的恢复效果来看,CADNet的去模糊效果都要优于其他算法,CADNet能够恢复出更清晰的局部细节和结构。

(a) 原始模糊图像
2.3 关键策略的有效性分析
本节设计了消融实验来分析评估各结构的有效性。需要说明的是,消融实验在数据集GOPRO上进行,其中编码网络中的ResCAB模块个数和解码网络中的CA-Res2Net模块个数设为8,特征融合模块中的CA-Res2Net模块个数设为2。实验结果如表2所示,同时包含不同组件的网络模型的PSNR收敛曲线如图6所示。

图6 不同结构模型的PSNR收敛曲线
本文主要测试了可变形卷积模块(DCN)、CA-Res2Net模块和多尺度频域重建损失函数(MSFR)的有效性。首先在不使用这3个组件的情况下训练基线模型(baseline),得到的PSNR均值为31.42 dB。如表2所示,相比于基线模型,可变形卷积模块的使用将PSNR提升了0.22 dB,多尺度频域重建函数的使用则进一步提升了0.27 dB 的PSNR。在使用这两个组件的基础上添加CA-Res2Net模块将PSNR进一步提升了0.12 dB。相比于基线模型,同时使用这3个组件时PSNR均值提高了0.61 dB。实验结果说明这3个组件都能够有效帮助提升图像去模糊的效果。
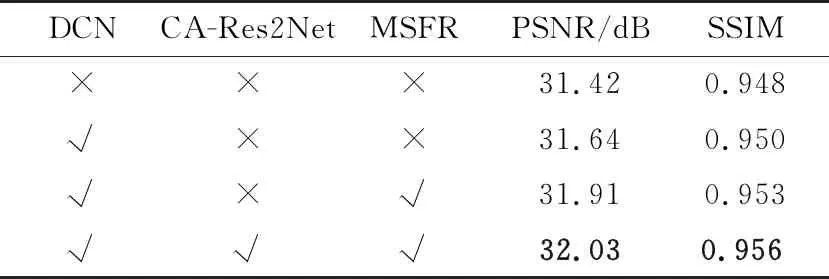
表2 CADNet不同组件的消融实验结果
3 结束语
本文针对动态场景下的非均匀模糊问题,提出了基于CA-Res2Net和可变形卷积的图像去模糊方法CADNet。CADNet网络的特点是以可变形卷积增强自编码结构适应复杂模糊形变的能力;提出CA-Res2Net模块从更细粒度的层次上表示多尺度特征信息,增大网络感受野,增强网络的特征表示能力。实验结果表明,相比于MPRNet和MIMO-Unet等主要去模糊算法,CADNet在各个测试指标上均取得了有效的提升,同时在复杂度方面没有增加,证明了CADNet能够更好地恢复图像细节,提升了图像去模糊的效果。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2020年10期)2020-11-14
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
电子制作(2019年13期)2020-01-14
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
太空探索(2016年5期)2016-07-12
