
基于面部关键点和图卷积的表情识别方法
2022-09-27 06:13吴宇凡李春国杨绿溪
无线电通信技术 2022年5期
吴宇凡,李春国,杨绿溪
(东南大学 信息科学与工程学院,江苏 南京 211189)
0 引言
在人类交流过程中,有55%的信息通过人脸表情传递[1]。人脸表情识别技术的应用场景非常广泛,包括但不限于:在社会公共区域进行多目标跟踪与表情分析,加强公共安全管控;识别分析机动车驾驶人的面部表情判断驾驶人是否疲劳驾驶、酒后驾驶,降低交通事故发生率;通过高清高速摄像设备的辅助,分析嫌犯的微表情,为警方办案提供有效帮助等,因此人脸表情识别技术具有重要的研究意义。
传统人脸表情识别算法主要是基于特征算子,对人脸表情图像进行变换,并将变换域中的系数作为初始表情特征值,去除冗余信息,保留关键特征,进而根据所得特征进行表情识别。常见的方法包括:Gabor算子[2]、局部二值模式(Local Binary Patterns,LBP)算子[3]、尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)[4]。但是这些传统的表情识别方法依赖像素级手工特征,倾向于关注浅层颜色信息,难以保证表情识别的准确率。
近年来,随着深度学习技术的快速发展,许多基于深度神经网络的人脸表情识别算法[5-11]涌现出来。这些方法主要基于堆叠层次更深的卷积神经网络,通过增加网络的深度,使得网络学习到更高维度的图像特征,从而对不同的人脸表情进行拟合。
虽然这些基于卷积层的深度学习方法在人脸表情识别领域相较于传统方法有了显著提升,然而卷积计算缺乏对面部器官关系的显式表示,容易丢失面部细节的局部信息。
本文将传统卷积(Convolution)与图卷积(Graph Convolution)结合,提出了一种新的人脸表情识别模型CGNet。为了更好地对面部细节特征进行提取,CGNet主要做了以下三方面的改进:基于dlib人脸识别库,提取面部关键点信息,并对面部各个器官进行区域划分后并行输入网络;在卷积网络中添加多尺度的空间注意力机制,增加模型对于细节区域的关注度;额外添加图卷积网络对面部关键点的结构特征进行提取,增强CGNet的特征学习能力。CGNet相较于当前主要的人脸表情识别算法,在保证识别实时性的前提下,有效提升了表情识别准确率。
1 CGNet网络结构
本文提出了CGNet网络结构,通过结合传统卷积网络与图卷积网络(GCN)实现人脸面部识别。首先,输入图像进行预处理,并按照面部器官位置进行了图像划分;其次,引入了空间注意力机制(Spatial Attention),提高网络对细节特征的关注度,并采用图卷积神经网络提取面部结构特征;最后,使用通道注意力机制(Channel Attention),对卷积特征、图卷积特征进行特征融合,充分利用各通道的特征信息,最终输出表情识别结果。图1为CGNet的网络整体架构图,图中,CGNet网络建立了两条特征提取主线,基于空间注意力的图像特征提取尽可能保留图像细节信息;基于图卷积的关键点特征提取构建点特征关系,为图像特征提取补充面部结构信息。
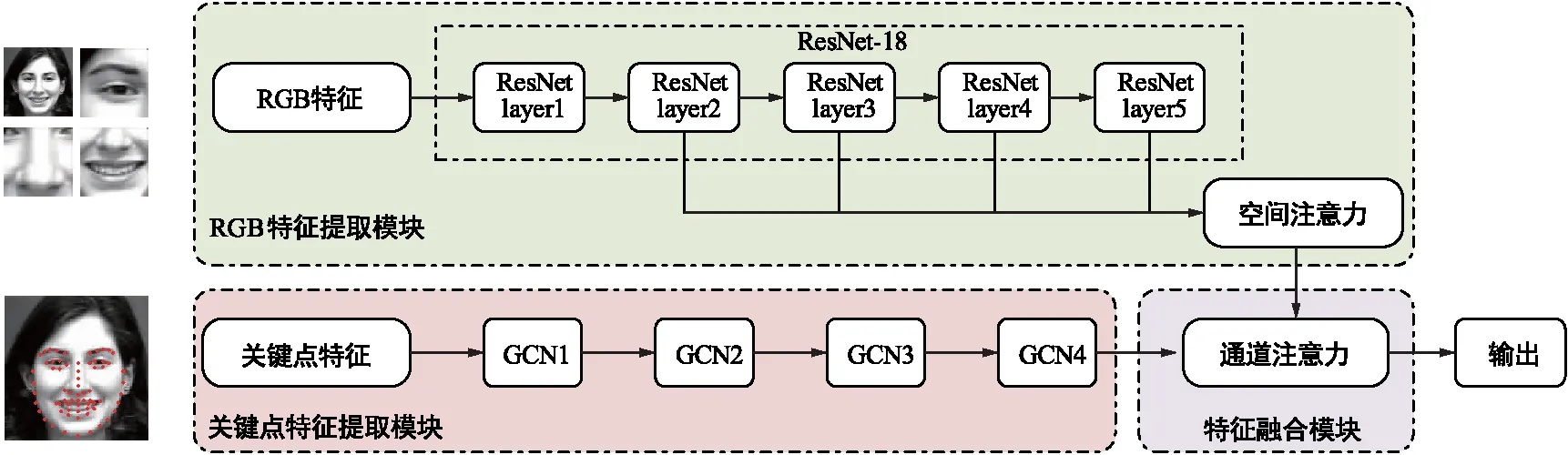
图1 CGNet网络整体结构
1.1图像特征提取模块
如图1所示,本文所提出的CGNet网络可以提取图像特征以及关键点特征,其中图像特征属于整个网络的核心部分。
传统的卷积特征提取层通常采用单张图像作为输入,通过增加卷积层的深度获得更高维度的特征。人脸在表现不同表情时,各器官会呈现出不同的表现形式,并且不同器官的表现形式有一定联系。为表示图像中各器官位置处图像的关联信息,在预处理阶段将人脸图像按器官区域进行分割,将各个器官区域的图像(包括整张人脸、眼部区域、鼻部区域、嘴部区域共4张图像)共同输入网络,提取多尺度特征。
CGNet的图像特征提取模块基于ResNet-18[12]的架构,如图2所示,ResNet-18包含5个中间特征,分别用layer1~layer5表示。输入图像首先经过ResNet-18的layer1进行下采样;接着通过4个包含残差块结构的layer进行多尺度特征提取,针对每一个layer的输出特征,将其提取出后送入空间注意力模块,可以得到4个通道数分别为64、128、256、512的特征向量,并将这4个向量进行拼接,获得长度为960的空间注意力特征向量;最终,将4张图像输出的特征向量进行特征级联(Concat),得到尺度为4×960的输出特征向量。
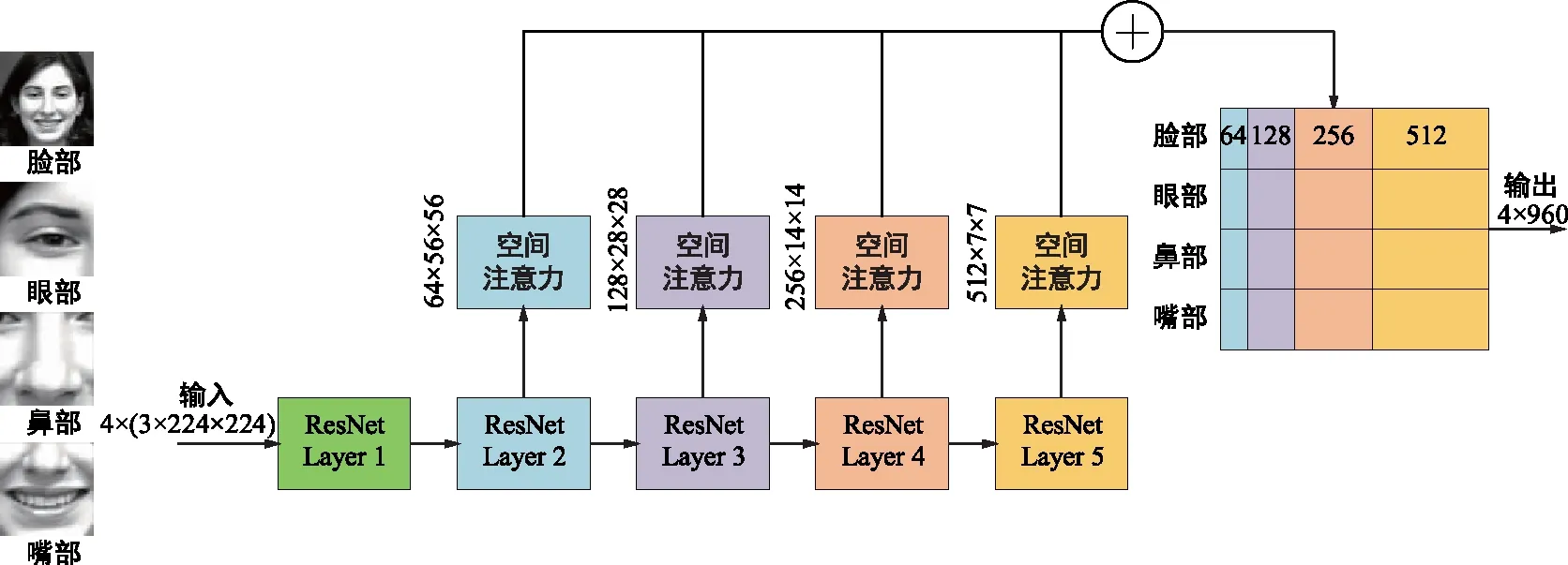
图2 图像特征提取模块结构
空间注意力机制[13]受启发于人类在观察图像的过程中选择性地关注其中某些重点区域的行为。卷积计算依赖卷积核,更关注局部区域信息,空间注意力机制能对图像中的长距离依赖进行补充,发掘远距离像素间的关系。通过对图像的不同位置进行权重分配,并对各个位置的特征进行加权求和。 CGNet通过在卷积层中嵌入空间注意力机制,从图像中发掘更多细节信息,有助于表情识别准确率的提升。
1.2 关键点特征提取模块
区别于其他的计算机视觉任务,在人脸表情识别场景下,由于不同对象的面部通常有相似的结构特征,且肤色、年龄等会导致面部图像层面出现巨大差异的因素对表情分类没有任何实质作用。因此为了提取对表情识别更具意义的结构特征,CGNet引入了图卷积算法,对人脸关键点进行特征提取。
本文采用dlib人脸识别库,对输入图像进行68关键点[14]提取,如图3所示。为了不增加计算量,每个关键点仅使用位置特征表示,即对于某一关键点,其特征表示为坐标。

图3 人脸68关键点示意图
如图4所示,CGNet的关键点特征提取模块基于图卷积层,GCN1~GCN4是4个图卷积层,关键点特征经过4个图卷积层,提取出更高维度的特征后,将特征送入全连接层,最终获得通道数为960的关键点特征。其中,图卷积层可以表示为以下的非线性函数:

图4 关键点特征提取模块结构
Hl+1=f(Hl,A),
(1)
式中,H0=X为第一层的输入,X∈RN×d,N为图的节点个数,d为每个节点特征向量的维度,A为邻接矩阵。具体来说,每一层图卷积层都可以表示为:
(2)
式中,σ(·)为ReLU激活函数,Wl为第l层的权重参数矩阵,D为图的度矩阵。通过在 CGNet中添加关键点特征提取模块,使得网络以增加少量参数量及计算量为代价,能够提取出用于人脸表情识别的结构特征,有效提升了网络的人脸表情识别准确率。
1.3 特征融合模块
为了充分利用图像特征提取模块与关键点特征提取模块中获得的多尺度特征,特征融合模块引入了通道注意力机制[15],将两个特征提取模块的输出特征进行融合,最终对人脸表情做出识别,如图5所示。具体来说,将图像特征提取模块输出的4×960的多尺度特征与关键点特征提取模块输出的1×960的特征通过级联获得融合特征,随后通过通道注意力机制自适应计算不同通道特征的重要性,加权求和各通道的特征,得到输出特征后,对人脸表情做出分类判断。表现高兴表情时,嘴角上扬的动作更明显,表现难过表情时,人们皱眉的动作更明显,在不同的表情时,人的各个器官提供了不同的信息量。通道注意力机制针对不同人的不同表情,可以动态计算各器官提供信息的权值,同时尽可能利用图卷积网络提供的结构特征。各路特征经过加权后,使用最大池化、平均池化函数实现多路特征的特征融合。
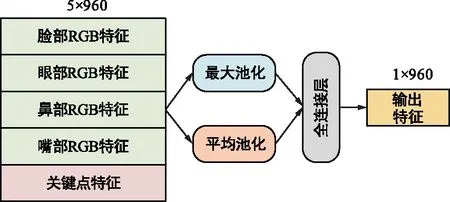
图5 特征融合模块结构
1.4 损失函数
本文使用了Focal loss损失函数,相比于交叉熵(cross entropy)损失,Focal loss在面对样本类别分布不均时,能够帮助网络更好地对样本数量较少的类别进行学习。
Focal loss被提出的问题场景是目标检测,在图像中寻找目标物时,图像中极大比例的部分是背景而不是前景,所以在使用交叉熵计算损失时会有极大的不平衡。虽然目标检测是一个二分类问题,在面对诸如面部表情识别的多分类问题时,也可引入Focal loss的思想:在交叉熵损失函数的基础上增加动态调整因子,使得简单样本的损失权重小于难样本的损失权重,此外,增加样本平衡因子,用于应对样本不均衡的场景。本文的Focal loss损失函数表示为:
(3)
式中,αk为类别k的样本平衡因子,γk为类别k的动态调整因子。
2 实验细节与结果分析
2.1 实验数据集与网络训练设置
为了验证CGNet算法的有效性,本文采用国际上公开的CK+数据集进行训练和测试。CK+数据集为图像序列形式,共包含593个图像序列,每一个序列包含从无表情状态到表情巅峰状态(即完整做完表情的状态)的多张正面人脸图像。本文使用其中有明确标注的321个图像序列的最后3张图像,共963张图像,其中840张图像作为训练集用于训练,训练时按2:1的比例将训练集拆分为训练集与验证集,141张图像作为测试集用于测试,图像分辨率为640×490。
本实验模型基于Pytorch深度学习框架进行训练和测试,实验使用的硬件环境为NVDIA GeForce GTX 3090 GPU。训练时对原始图像数据进行预处理,首先从大小为640×490的原始图片中检测出人脸,并按照人脸检测框对图片进行裁剪,随后采用双线性插值法将人脸图像变换为224×224大小。由于数据集量级不足,还需要对数据集进行数据增持操作以扩充数据集,文中使用的数据增强方法主要有随机裁剪、水平翻转、旋转0~30°以及图像亮度、色度、对比度、饱和度变换。数据增强后,进行器官切割以及关键点获取,最终再次使用双线性插值法对图像大小进行变换后,得到4张224×224分辨率的RGB图像以及68个面部关键点坐标信息,并将其分别进行归一化后作为网络的初始输入。训练过程中,网络使用Adam作为优化器进行梯度更新,Adam优化器使用默认参数,beta1=0.9,beta2=0.999;初始学习率设置为1×10-4,每经过200个epoch学习率下降5%;批处理大小(batchsize)设置为64,共训练了1 000个epoch。
2.2 与其他算法的表情识别性能对比
本节选取了近几年主要的几种基于深度神经网络的表情识别算法作为对比算法,包括Rifai等人提出的MSR[6],Liu等人提出的3DCNN-DAP[7],Han等人提出的IB-CNN[8],Meng等人提出的IACNN[9],Jung等人提出的DTAGN[10]、Zhang等人提出的ST-RNN[11],以及将经典的图像分类网络AlexNet[16]与VGG-19[17]引入至人脸表情识别任务。各算法的人脸表情识别准确率对比如表1所示,表中的结果均是以CK+数据集作为训练集训练,并在CK+测试集上测试得到的。
表1的测试结果表明CGNet在CK+测试集上取得了最高的准确率值,说明本文方法最终实现的人脸表情识别效果最好。CGNet的表情预测准确率相较于表中性能最好的ST-RNN算法,准确率高出0.41%,表明本文方法的人脸表情识别效果取得了较好地提升。
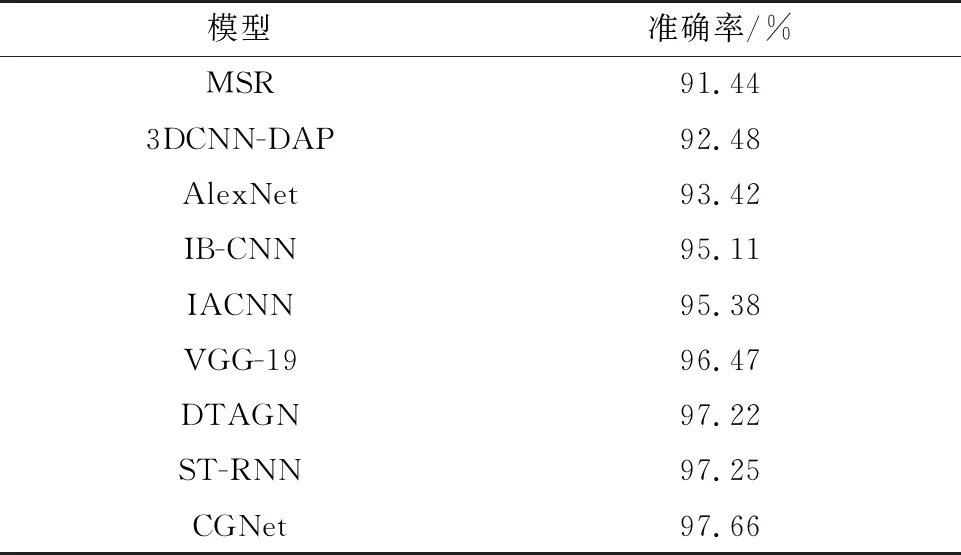
表1 CGNet与当前主流算法的准确率对比
为了从主观的角度评价不同算法的人脸表情别别效果,图6对比了包括CGNet在内6种效果较好的算法在CK+测试集上的混淆矩阵,即模型将某表情错认为其他表情的概率。从图6可以看出,在CK+数据集中,由于“疑惑”“难过”两个类别的数据量相对较少,大部分算法都容易对这两个类别进行误判,但由于CGNet增加了对于面部细节处的关注度,以及对损失函数的改进,对这两个类别的识别准确率优于其他算法,总体来看,CGNet能够更准确地对人脸面部表情进行识别。
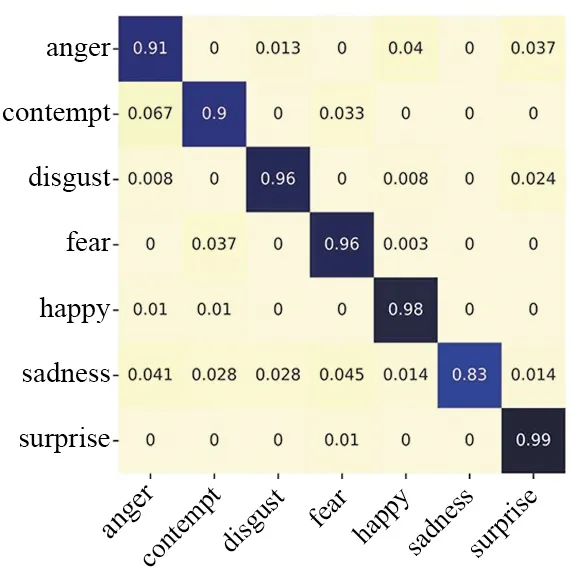
(a) IB-CNN
2.3 关键策略的有效性分析
本节设计了消融实验来分析评估各结构的有效性。需要说明的是,消融实验在CK+数据集上进行,实验结果如表2所示。

表2 CGNet不同组件的消融实验结果
本文主要测试了关键点特征提取模块中的空间注意力机制,关键点特征提取模块以及特征融合模块中的通道注意力机制的有效性,其中,在测试不使用通道注意力机制时,将得到的各路特征采用直接求平均的方式进行融合。首先在不使用这3个组件的情况下训练基线模型(baseline),得到的平均准确率为93.55%。如表2所示,相较于基线模型,空间注意力机制的使用使得平均准确率提升了1.87%,通道注意力机制的使用则进一步使得平均准确率提升了0.56%,在此基础上,基于面部关键点进行图卷积特征提取,则使平均准确率进一步提升了1.68%。相较于基线模型,同时使用这3个组件使得平均识别准确率提升了4.11%。实验结果说明,CGNet中引入的这3个组件均对提升人脸表情识别准确率有着显著效果。
3 结束语
本文针对现有人脸表情识别方法对于面部细节处的局部特征关注度不足的问题,提出了基于面部关键点和图卷积的人脸表情识别方法CGNet。CGNet将面部图像按面部器官进行切割后以多尺度信息输入网络,辅以空间注意力机制,提升网络对于面部细节处的关注度;提取人脸关键点,利用GCN提取出人脸面部的结构信息,提升网络对于高维度特征的表示能力。实验结果表明,相较于ST-RNN、DTAGN等主流人脸表情识别网络,CGNet在表情平均识别准确率取得了有效提升。
猜你喜欢
建材发展导向(2022年3期)2022-04-19
今日农业(2021年8期)2021-11-28
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
建材发展导向(2021年11期)2021-07-28
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
动漫星空(2018年9期)2018-10-26
