
基于深度LSTM与遗传算法融合的短期交通流预测模型
2022-09-27 06:12李静宜李湘媛
无线电通信技术 2022年5期
李静宜,丁 飞*,张 楠,李湘媛,顾 潮
(1.南京邮电大学 物联网学院,江苏 南京 210003;2.南京邮电大学 江苏省宽带无线通信和物联网重点实验室,江苏 南京 210003)
0 引言
“十三五”以来,我国高速公路发展总体适应经济社会发展需要,但与高质量发展和构建新发展格局要求相比,高速公路补短板、强弱项、增质效任务仍然艰巨,转型发展亟待加快。信息化智慧化建设相对滞后,信息资源配置较为分散,运行监控、预测预警等信息管理平台不完善,数字化新技术、新手段运用较薄弱。道路交通状态瞬息万变,交通流预测可以为交通优化控制和智能服务提供决策参考。
目前,国内外研究者在交通流预测方面已有较多有益成果。现有交通流预测模型可分为:基于统计分析的预测模型[1-2]、非线性理论模型[3]、仿真预测模型[4]、智能预测模型[5-6]、混合模型[7-8]等。近年来,以LSTM为代表的反馈神经网络在时间序列数据的预测方面具有广泛的应用,而且可作为非线性单元用于构造更大型的混合模型。王博文等人[9]提出一种基于编码器-解码器的卷积神经网络(CNN)门循环单元模型,在单模特征或多模特征输入时均可获得较好的预测性能,且可以缓解预测误差的迅速积累问题。邵春福等人[10]提出基于皮尔森相关系数法(PCC)与双向长短时记忆(BLSTM)的交通流预测模型,通过PCC筛选目标路段空间的路段并重构数据集,然后由BLSTM进行交通流预测,短时交通流预测精度获得较好提升。由于长短期记忆网络(LSTM)在长时间序列预测中表现出对历史信息的优秀整合能力,大多数学者也倾向于使用基于LSTM模型的交通流预测。Chu等人[6]利用LSTM进行车道级交通流预测,相较于门控循环单元(GRU)、堆叠自动编码器(SAEs)等模型具有更优的预测性能。王庆荣等人[11]设计了一种多尺度特征融合的短时交通流预测模型,考虑了时间序列的连续性以及天气、节假日等因素,可以提升预测模型的预测泛化能力。李磊等人[12]提出基于改进CNN与LSTM的交通流预测模型,设计了分层网络结构自动提取交通流序列的空间特征,优化LSTM网络模块来减少网络对数据的长时间依赖,并引入改进后的自适应矩估计(RAdam)优化算法,从而提高网络输出的准确性和鲁棒性。文献[13-14]分别使用双层LSTM构建电网能量消耗预测模型,前者结合了近邻节点拓扑关系,后者融入了注意力机制,二者均认为双层LSTM网络结构相较于单层LSTM能更好地表征能耗时空的变化,可以更准确地实现电网能量消耗曲线的预测。
考虑到神经网络在训练时易受其超参数影响,从而影响到模型的预测精度。Zhang等人[15]提出一种改进遗传神经网络(GA-BP),在遗传算法迭代过程中,选择前n个最优个体,自适应优化种群的搜索步长,保证种群的多样性且提高交通流预测模型的收敛速度。何祖杰等人[16]提出基于改进灰狼算法(IGWO)优化支持向量机(SVM)的短期交通流预测模型,引入帐篷混沌序列初始化灰狼种群,优化收敛因子并对灰狼群体进化差分丰富种群多样化,从而提升预测模型的鲁棒性和泛化能力。温惠英等人[17]采用遗传算法对数据时间窗步长、LSTM神经网络的隐藏层数、训练次数、dropout进行参数优化,相比传统LSTM模型具有更好的预测性能,由于选用了不同固定采样周期间隔的数据集,因此在通过固定采样周期的交通流预测场合无法复制应用。
基于以上分析,本文提出一种基于深度LSTM与遗传算法融合的交通流预测模型(GA-mLSTM),通过LSTM的深度网络设计保证模型泛化能力;引入遗传算法在全局空间获得最优解,加速模型收敛;通过差分运算对预测误差进行优化,提升整体交通流预测模型的准确率。最后,利用公开数据集进行模型测试并性能评估,对比传统两层LSTM、支持向量回归(SVR)模型和循环神经网络(RNN)模型,验证所提GA-mLSTM模型的有效性与预测性能。
1 遗传算法超参数优化
基于深度LSTM进行预测时,网络层数和隐藏层神经元个数取值对于预测结果有直接影响。LSTM网络的层数和隐藏层神经元个数决定了神经网络的复杂程度和拟合程度[18]。考虑到交通流日内波动性明显,使用单层长短期记忆网络(LSTM)存在泛化能力不足的问题,堆叠多层LSTM易导致模型难以快速收敛。隐藏层接收来自输入神经元的输入后,根据输入的重要性分配权重,输入所分配的权重越大,则该输入量越重要。Dense层的目的是将提取的特征通过非线性变化提取关联因子并映射到输出中。在实际训练中,Dense层的增加能够加快收敛速度。
遗传算法(Genetic Algorithm,GA)在求解过程中模拟生物进化中染色体基因的选择、交叉、变异等过程,并求取最优解的方法。其核心是通过适应度函数评估个体的优劣,对于结果更好的个体,在下一代种群中占比更高。GA在求解较为复杂的组合优化问题时,相对于传统优化算法,通常能够较快地获得较好的优化结果,有较强的鲁棒性。因此,本文采用遗传算法对LSTM层及Dense层的层数、隐藏层及Dense层的神经元个数的组合进行寻优,将获得的优化参数用于预测模型,从而达到降低误差,提升收敛性的目的。
GA-mLSTM模型将深度LSTM与GA进行融合,将GA中的每个染色体基因描述为LSTM网络结构层数和每层神经元个数等信息。染色体基因的编码结构示意如图1所示,X1、X2分别代表LSTM的层数与Dense层的层数,X3~X8按顺序代表LSTM与Dense各层神经元个数。此外,在模型结构设计中,除了染色体中所定义的Dense层外,还需要添加一层神经元个数为1的Dense层用于输出预测结果。

图1 染色体基因的编码结构
堆叠LSTM的层数会导致预测模型的时间和资源开销的增加,文献[13-14]均采用了两层LSTM网络结构,可以获得时序数据预测性能的提升;文献[19]指出当LSTM层数超过3层时,会产生较明显的层与层之间的梯度消失问题。
本文在深度LSTM网络结构设计时,将LSTM网络层数限定为1~3层,同时将隐藏层的神经元个数约束在[32,256]区间。
基于GA优化深度LSTM网络超参数的核心操作包括:
(1) 选择
遗传算法通过适应度函数对子代染色体基因进行选择,按照预定策略从父代种群中进行个体选择和淘汰。本文利用轮盘赌选择方法实现遗传算法的选择操作,采用均方误差(MSE)作为适应度函数,若MSE越小,则代表该个体适应度越高,其被选择的概率将变大。
(2) 交叉
交叉是对选择操作后存活的父代个体的基因进行组合,具体实现方式为个体生成一个随机数rc∈[0,1),若rc小于预设交叉概率Pc=0.5,则随机选择父代种群中的某个个体进行交叉,生成一个8位二进制数并转化为布尔类型决定发生交叉的基因位点。基因位点X1、X2代表LSTM的层数与Dense层的层数,由于层数交叉会影响到神经元参数的数量,因此基因位点X1、X2 不产生交叉。
(3) 变异
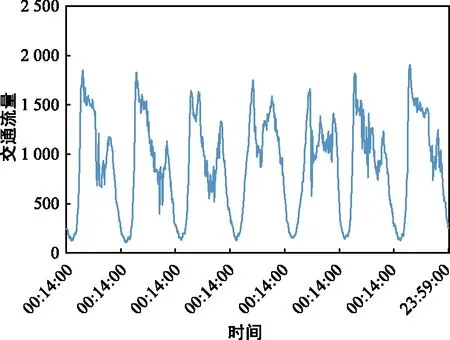
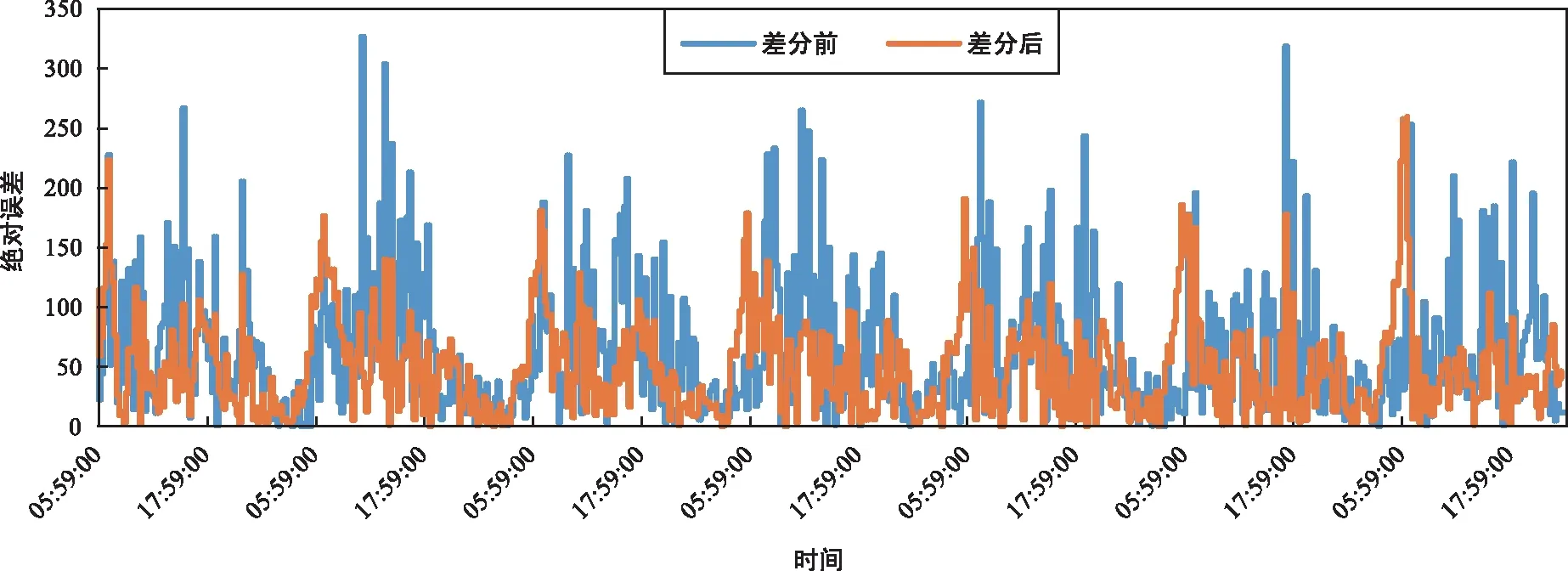
变异是指遗传过程中染色体基因发生的突变。假定变异率Pm设为0.01,则通过遍历所有染色体基因个体,当生成随机数rm∈[0,1) 每一代种群生成后,将其子代个体所表示的网络结构参数代入深度LSTM网络中进行训练,本文通过对连续迭代训练设置最大迭代限定值以结束此次遗传进程。 GA-mLSTM模型的整体框架如图2所示,主要包括数据准备模块、参数优化模块和预测训练模块。采用遗传算法对LSTM层数、Dense层数、隐藏层神经元个数和Dense层神经元个数进行优化。 图2 GA-mLSTM模型框架 基于GA-mLSTM模型进行交通流预测的步骤描述如下: 步骤1:数据预处理,使用Min-Max-Scaler函数对初始数据进行归一化处理; 步骤2:使用遗传算法优化参数,得出1~3层LSTM网络结构的最优解; 步骤3:构建模型,使用遗传算法寻优得出的参数训练LSTM模型; 步骤4:使用训练好的模型,对测试集进行交通流预测; 步骤5:对输出数据进行反归一化; 步骤6:差分处理并计算误差。 本文使用公开的高速公路数据集[20]检验模型性能,该数据集包含英国M、A级高速公路交通流量数据,以15 min为采样间隔。图3为该数据集中2018年8月1—7日共7天的原始交通流序列曲线,每天含00:14:00—23:59:00共96条交通流量数据。本文实验选取该数据集2018年8月1—24日共2 304条样本数据作为训练集,8月25—31日共672条样本数据作测试集。 图3 原始交通流序列曲线 为提升模型的收敛速度及预测准确度,使用Min-Max-Scaler函数对初始数据进行统一规约,通过式(1)将原始交通流量数据线性转换为[0,1]区间。 (1) 式中,xmax为样本数据的最大值,xmin为样本数据的最小值。处理后的输入输出数据格式如表1所示,输入步长设为20,即输入特征矩阵X由前20条数据进行构造,模型预测后输出预测值Y。 表1 模型输入输出格式示例 LSTM是循环神经网络RNN的变形,其解决了RNN在长序列训练过程中出现的梯度消失以及梯度爆炸问题。LSTM网络通过输入门、遗忘门以及输出门控制信息的传递,输入门决定当前时刻需要保存到单元状态的数据,遗忘门对输入进行选择记忆,将重要信息保留,输出门控制输出内容。 ft=σ(Wf·[ht-1,xt]+bf), (2) it=σ(Wi·[ht-1,xt]+bi), (3) ot=σ(Wo·[ht-1,xt]+bo), (4) (5) (6) ht=ot×tanh (Ct)。 (7) 交通流作为时间序列数据,由于时间序列预测存在自相关性,即t时刻的预测值更贴近t-1时刻的真实值。因此,本文将为预测输出值采用差分操作,消除一阶自相关性,并将差分后的结果作为最终交通流预测值。 GA-mLSTM模型的参数设置如表2所示。为防止模型过拟合,于每个LSTM层后加入Dropout层,丢弃率设置为0.2。选择Adam优化器,该优化器结合了AdaGrad和RMSProp方法的最佳属性,自动为模型参数使用自定义学习率,能够使训练收敛性能更佳。 表2 模型参数设置 实验所使用的计算机配置为:Intel(R) Core(TM) i5-10400F CPU @ 2.90 GHz,内存为16 GB,Windows10(64位)操作系统,软件开发环境为Python 3.7.11。 为对GA-mLSTM模型进行性能评价,使用均方误差(MSE)、均方根误差(RMSE)以及平均绝对误差(MAE)作为误差评价指标,对应计算公式如式(8)~(10)所示。 (8) (9) (10) 基于遗传算法的深度LSTM网络的优化训练过程如图4所示,可以看出,遗传算法在训练迭代过程中,初始阶段的均方误差存在明显波动性,但在进入27次迭代后,其均方误差趋于最优解,且波动性相对较小,即在该区间可以确定遗传算法的近似最优解。因此,在GA-mLSTM模型进行交通流预测时,将迭代次数设为30次,则认为在30次迭代训练中种群子代可获得近似最优适应度,即在遗传搜索空间能找到近似最优解。 图4 基于遗传算法的迭代训练结果 为评估GA-mLSTM的性能,参照文献[22]所用双层LSTM神经网络的设置参数,将LSTM模型中的batch size和步长分别设置为64和8。在GA-mLSTM模型中,将LSTM层数设为1~3层,通过遗传算法探索解空间的最优解。经预测训练,获得GA-mLSTM模型的优化参数设置为表3所示,即GA-mLSTM模型中LSTM层数取为3层。 表3 遗传算法寻优结果 从表4中可知,相较于已有双层LSTM模型方法[22],使用遗传算法优化深度LSTM网络结构参数的模型预测性能更优,其中MSE、RMSE、MAE分别提高了1 870.92、10.23、7.55;加入差分操作后,MSE、RMSE与MAE分别提高了4 150.47、24.63、20.65。 表4 不同LSTM模型预测性能比较 图5为GA-mLSTM模型在差分处理前后的预测值与真实值的绝对误差对比图,在进行差分处理后,日高峰时间段交通流预测结果得到显著提升,总体误差得到有效减小。不同模型预测结果对比如图6所示,可以看出,GA-mLSTM模型能够较好拟合交通流的变化趋势,且在交通流趋势为下降以及突变的时间区段,GA-mLSTM模型的预测精度更高,显示其交通流预测的有效性。 图5 融入差分处理的绝对误差对比 图6 不同模型预测结果对比 图7给出了GA-mLSTM模型与支持向量回归 (SVR) 模型、循环神经网络 (RNN) 模型的交通流预测对比结果,在8:00—20:00时间段,GA-mLSTM、SVR、RNN模型预测值与真实值之间的绝对误差区间分别为[0.042,177,276]、[0.355,386.955]、[1.026,399.682],因此,GA-mLSTM模型相较于SVR和RNN具有更优的交通流预测性能,性能比较如表5所示。 图7 不同算法模型预测结果 表5 不同算法模型预测性能比较 由于交通流复杂程度高,实现对交通流的高精度预测对于城市交通管理具有重要意义。针对LSTM网络结构模型依赖传统经验难以确定结构参数的问题,基于遗传算法优化的深度LSTM网络结构,融合差分处理,提出一种交通流预测模型GA-mLSTM。通过公开交通流数据集测试验证,相比传统LSTM模型,本模型具有更好的预测精度。本文提出的GA-mLSTM模型仅考虑交通流量单指标输入,且对于预测的时效性方面未作深入研究,未来研究可考虑在日内时序划分、长期交通流预测需求下的模型参数自适应调节等方面进一步优化和深入研究。2 GA-mLSTM交通流预测模型设计
2.1 模型预测框架

2.2 数据预处理

2.3 长短期记忆神经网络
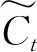
2.4 差分处理设计
3 实验与性能分析
3.1 环境配置与评价指标

3.2 GA-mLSTM交通流预测与分析




3.3 不同模型的交通流预测与分析


4 结束语
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
中国交通信息化(2022年5期)2022-07-23
科学技术创新(2022年15期)2022-05-18
西安邮电大学学报(2020年1期)2020-12-17
科学与财富(2020年24期)2020-10-27
计算机系统应用(2019年9期)2019-09-24
计算机系统应用(2019年6期)2019-07-23
电子制作(2019年11期)2019-07-04
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
小天使·五年级语数英综合(2015年4期)2015-04-20
