
基于“五维”商圈网格的零售终端卷烟市场需求指数模型研究与应用
2022-09-27 09:32:42胡庆展谢邵斌温州市烟草专卖局公司信息中心
管理学家 2022年17期
胡庆展 谢邵斌 温州市烟草专卖局(公司)信息中心
随着“互联网”模式的全面落地,行业累计采集海量消费数据,形成能反应卷烟市场发展动态的“数字网络”。本课题研究小组基于网格化的人地商圈、商业批发、终端零售、消费者及专卖监管“五维一体”数据,研究零售终端卷烟市场需求指数模型,探索建设数据驱动的卷烟市场供需匹配、品牌精准投放应用,助力卷烟营销向“数字化”深度转型。
一、研究背景
当前行业卷烟营销在分析市场容量和需求,制定货源投放计划、投放策略上存在一些问题。
(一)市场需求影响因子度量方法有待创新
目前货源投放以行业批发数据为主要参考指标,终端周边商圈客流、人群特征等市场因素对销量的影响,更多以“定性”方式在投放策略中体现,缺少能度量区域市场需求影响因子的科学方法。
(二)区域市场需求预测能力略有缺失
目前行业较为先进的单位已经采用终端“样本户数据采集”推算社会库存和需求,准确度较高,但用来指导县级以下区域市场需求预测时存在样本户不足、数据颗粒度不够细、维度不够丰富等问题。
(二)卷烟货源精准投放仍有提升空间
货源投放方式以类别为主导,类别划分主要基于历史销量和客情的“ 以量定量”,与真正意义上按照终端市场实施的“千人千面”“一户一策”仍有一定差距。
二、构建思路
基于云计算、大数据平台,将温州数字地图按边长1 公里的正方形网格切分为若干区域,以网格为单元汇聚人地商圈、商业批发、终端零售、消费者、专卖监管“五维”特征数据,搭建零售终端卷烟市场需求指数模型,挖掘特征指标对销量影响度和权重,并以此为基础打造大数据分析系统,通过数据驱动实现市场供需匹配,品牌投放场景化、可视化、精细化应用。
(一)总体架构
系统基于云平台建设推进,共分为以下四层。
基础数据层:基于数据中台大数据离线计算MaxCompute,引入第三方人地商圈数据,按商圈网格汇聚特征指标,通过指标归一化处理,搭建特征指标库,为数据建模层提供基础数据。
数据建模层:基于数据中台规范建模Dataphin,对基础数据层指标进行二次加工,运用随机森林、Pearson、多元线性回归等算法搭建组合模型,输出特征指标对销量影响度和权重。
应用数据层:基于数据中台关系型数据库RDS,融合业务数据、前端交互数据、数字地图对模型输出结果进行等值线处理和热力图叠加,形成零售终端卷烟市场需求指数。
应用服务层:基于ECS 云服务器搭建系统运行环境,开发市场供需匹配、品牌精准投放场景化应用,通过数字地图和数据可视化实现与用户、与业务流程交互。应用输出的周期投放量结果能够导入经营管理平台货源投放模块应用。
(二)数据应用场景架构
针对市场供需匹配、品牌精准投放两个业务场景,开展架构设计和系统功能开发,将模型输出与业务流程、技术组件信息流进行无缝衔接,形成业务场景下数据的应用闭环。
1.市场供需匹配业务场景架构
在需求预测流程分解到周期环节,结合实际周期终端销量,计算实际销量指数,与市场需求指数进行四象限直观比对,判断市场饱和程序,指导后续周期优化总量投放与分类调控策略。
同时将市场供需匹配结果纳入半年度、年分月、月分周需求预测中,优化预测结果。
2.品牌精准投放业务场景架构
应用市场需求指数开展货源投放,包括以下两种投放方式。
(1)在销卷烟投放。输入在销品规“五维”数据,代入模型生成市场需求指数。
(2)新品卷烟投放。输入新品卷烟产品特征,通过产品特性匹配同产地、同价类等同特征数据,代入模型生成市场需求指数。
最后以指数作为权重,按周期总投放量分解到单客户定量,导出周期限量表应用到货源投放。投放后,通过订足率、订足面等指标,对效果进行评估,改进下一周期投放策略,形成优化模型、优化投放的良性循环。
三、搭建特征指标库
(一)引入人地商圈数据
1.人地商圈数据定义
人地商圈数据包括人地数据和商圈数据两类。人地数据定义为网格内的人群年龄、籍贯、消费水平等数据。商圈数据定义为网格内的常驻人口数、流动人口数、商业机构数量等。
2.商圈划分方式比较
商圈区域划分有三种方式,分别按行政区域划分、道路水系划分、标准网格划分。
(1)行政区域
优点:行政区域由政府部门统一规划,统计数。
缺点:某些社区和行政村边界不清晰,划分颗粒度较粗。
(2)道路水系
优点:烟草消费行为属于便利性消费,通常被较高等级道路、河流阻隔。
缺点:较大水系和较高等级道路可能导致划分区域大小均衡性差,不规则区域对管理者、客户来说较难理解和区分。
(3)标准网格
优点:按照1 公里边长划分,区域小,精度相对较高,各地容易推广实施。
缺点:无法体现道路、河流等客观影响消费行为的因素。
3.商圈数据源比较
目前,市场调研人地商圈数据主要来源于通信运营商和大型互联网企业。
(1)通信运营商
优点:实名认证、信息真实、位置轨迹连续。
缺点:无消费信息,缺乏区域商业信息。
(2)大型互联网企业
优点:基于电商和线下支付采集,商圈信息比较全面。
缺点:非实名认证,人群特征真实性欠佳,市区内位置轨迹不连续。
(二)样本数据选择
为模型输入提供科学的样本数据是关键一环。针对每一个卷烟规格找到批发销量和终端销量基本平衡、存销比相对合理、覆盖不同行政区划、商圈类型、经营业态的目标客户群,总样本客户数比例达到总客户数的10%约4500户。以样本数据作为模型训练对象代入建模。
四、建立模型
基于规范建模Dataphin,按网格汇总特征数据与批发销量代入模型,通过搭建随机森林模型计算特征指标重要性,应用Pearson 过滤特征指标,运用多元线性回归输出特征权重。将特征指标值赋予权重,最终由网格热力图叠加生成零售终端卷烟市场需求指数。
(一)随机森林输出特征重要性
随机森林算法原理:将全量特征数据按照7:3 的比例分成训练集与测试集,通过训练集数据进行模型训练,每次随机选取其中k 个指标特征和m 个数据样重复操作n 次,不同随机组合得到n 棵决策树,建立随机森林模型,输出各特征重要性。计算流程如下。
①决策树回归。在训练数据集中,递归地将每个区域划分为两个子区域并决定每个子区域上的输出值,构建二叉决策树。
②构建随机森林。对每个决策树都预测结果,存储所有预测的结果,从n 棵决策树中得到n 种输出值。通过n 颗决策树预测值的平均值计算出随机森林模型最终预测值X:,其中f(x)是每颗决策树的预测值,n 为随机森林中决策树的个数;
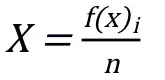
③训练过程检验。通过训练集数据进行模型训练,将每次随机森林模型预测值与实际值进行相关系数检验,以Pearson 相关系数R 为指标用来判断模型准确率。随着训练过程,R 值没有显著提高时,停止迭代。
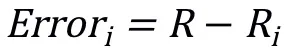

⑥随机森林模型可行性验证。测试集中各网格实际批发量与模型预测销量进行相关性检验,方法同③,相关系数大于0.7 代表测试集与训练集属于强相关。
(二)线性相关检验
根据随机森林算法选择筛选的特征指标将分别与卷烟销量进行线性相关性检验,选取的检验方法为Pearson相关性检验,用于量度特征指标X 与卷烟销量Y 之间的线性关系。
(三)多元线性回归
经过上述线性相关性检验后,我们选出常住人口、存销比等特征指标作为多元线性回归的特征指标,通过这些特征指标建立与卷烟销量的多元线性回归模型。

五、构建零售终端卷烟市场需求指数与热力图
为体现同一个网格内不同位置的零售终端各维度特征,特别是商圈特征值的差异性,利用等值线的计算方法,输入网格中心点及指标权重,按半径扩散进一步确定单个零售终端可能受到所处的网格及周边网格的影响。影响度从网格中心到边缘逐级递减。由此建立覆盖温州地区的多维度等值线图与热力图。
六、系统功能开发与模型应用
通过浙烟数据分析平台建设信息化系统,应用零售终端卷烟市场需求指数,开发市场供需匹配、品牌精准投放两个业务场景化功能,并通过数字地图、热力图、雷达图等数据可视化呈现,将模型输出嵌入到货源调控、货源投放业务场景和工作流程中去,实现业务能力提升。
(一)市场供需匹配应用
通过数据可视化实现系统功能搭建,用户选择品规特征指标进行分析,系统将实时调用模型输出需求热力分布,结合历史实际销量,判断市场饱和程度、市场需求满足程度,进一步指导卷烟总量调控以及分类调控。

(二)品牌精准投放应用
通过数据可视化实现系统功能搭建,用户针对在销品规输入周期总投放量,系统将实时调用模型输出,在线分析各品规零售终端卷烟市场需求指数及周期投放量。如为新品,则从品规同特征指标角度切入,选择卷烟商品特征指标进行分析,计算周期投放量。计算结果以Excel 形式生成周期投放限量表,导入浙烟经营管理平台货源投放模块开展投放运用。
七、结语
项目建设零售终端卷烟市场需求指数模型及应用系统,具有以下三个方面的重要意义。
一是创新市场需求指数。探索零售终端卷烟市场需求指数模型并形成初步研究成果,为度量区域市场、终端市场需求程度给出了一套量化评价方法。
二是强化市场供需评估。在当前需求预测模式基础上,应用指数模型,加强了县级以下区域市场供需匹配程度的分析和研判。
三是深化品牌精准投放。在当前货源投放模式基础上,应用指数模型,找到了投放策略的优化方案,实现真正意义上的“千人千面”“一户一策”。
猜你喜欢
房地产导刊(2021年8期)2021-10-13 07:35:20
纺织科学研究(2021年1期)2021-03-19 05:18:42
今日农业(2020年17期)2020-12-15 12:34:28
减速顶与调速技术(2020年2期)2020-11-16 00:57:32
中国化肥信息(2020年10期)2020-07-22 06:00:40
中国化肥信息(2020年9期)2020-03-29 02:33:54
国际贸易(2018年2期)2018-04-04 02:16:06
中国老区建设(2016年12期)2017-01-15 13:54:00
上海商业(2016年20期)2016-06-01 12:10:14
汽车维修与保养(2015年2期)2015-04-17 01:30:26
