
基于钢铁物流数据的索引与查询技术研究
2022-09-26 13:06:28钱荣涛毛嘉莉
华东师范大学学报(自然科学版) 2022年5期
邹 韬,钱荣涛,毛嘉莉
(华东师范大学 数据科学与工程学院,上海 200062)
0 引 言
随着大数据时代的发展,钢铁物流也迎来了数字化转型,越来越多的网络货运平台应运而生,由此产生了大规模的多源物流数据.这些数据作为网络货运平台的基础,为司机画像、车货匹配、车辆调度以及运输监控等关键任务提供支撑,因此,研究面向物流数据的索引与查询是极为重要的.
然而,使用传统的关系型数据库对物流数据进行管理面临一系列挑战.首先,货运数据类型繁多且来源复杂.以山东省某钢铁集团下属的物流企业—京创智汇物流科技有限公司 (以下简称京创)为例,在其研发的网络货运平台上每天产生的数据类型包括购买和销售场景中的订单数据,仓储场景中的库存数据,运输场景中的运单数据和轨迹数据等.然而,京创在使用关系型数据库管理这些数据时,对不同场景中的数据存储在不同表中管理,仅在每列数据上构建索引,并不能直接满足物流数据复杂查询的需求.这体现在: ①对于不同表中数据的连接查询是最常用的查询类型之一,京创通过多表连接构建宽表的方式来完成连接查询,这导致了大量的冗余查询与计算,从而影响查询性能;② 面对以轨迹数据为代表的时空数据的快速更新与动态增长,传统关系型数据库由于存储容量和平台可扩展性的影响,无法很好应对海量时空数据的存储与查询.例如,随着单表中轨迹数据的增长,仅通过B 树索引会存在大量冗余计算,使得时空查询性能随着数据的增多而降低.而选择各类R 树进行索引则存在频繁插入导致R 树分裂,更新索引开销过大的问题.综上所述,面向钢铁物流数据,进行数据融合,并设计合理的存储方式、高效的索引与查询方案是亟待解决的实际问题.表1 给出该货运平台货运物流数据量情况,可以发现轨迹数据总量最大、相应的增长速度也最大.随着业务的增多和对更高质量 (采样间隔更低) 轨迹的需求,轨迹数据的增长速度会大大提高.而京创现行的管理方式无法很好管理这些仍在快速增长的轨迹数据。
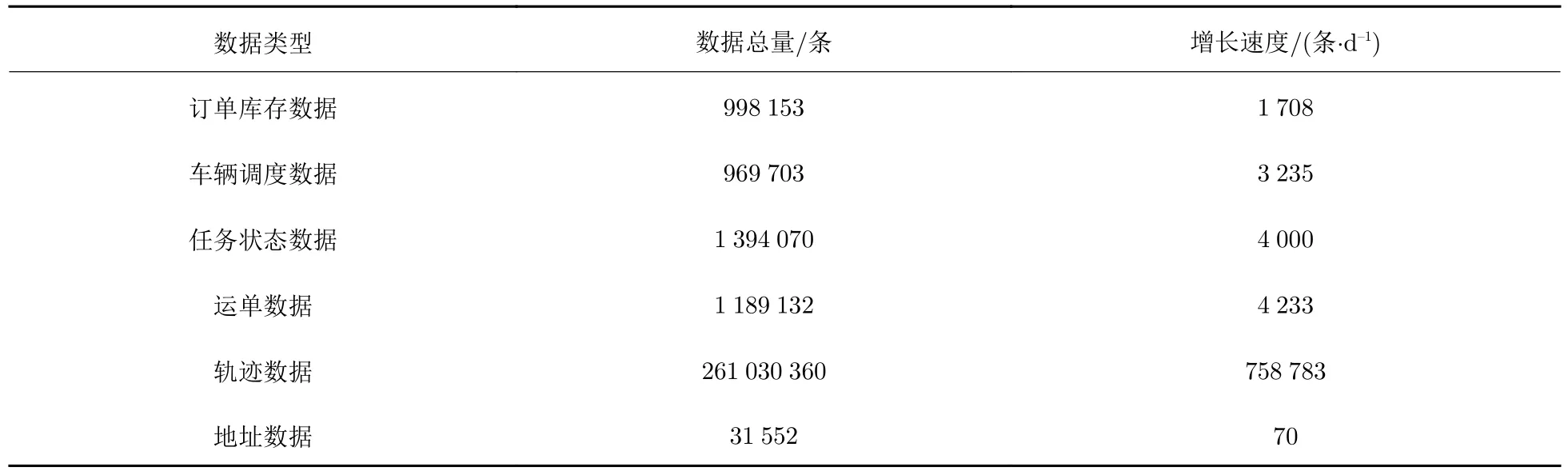
表1 货运物流数据量Tab.1 Volume of freight logistic data
为了解决钢铁物流数据存储查询时面临的上述挑战,本文将实时数据和历史数据分级存储,并构建相应的索引,以期提高物流数据的存储和查询效率.具体步骤为: 首先,使用Spark 对于多源的物流数据进行融合;然后,对于海量的历史物流数据与货运平台实时采集到的多源数据采用分级管理,将实时采集得到的物流数据存储在内存数据库Redis (Remote Dictionary Server) 上,以保证其高效的访问性能,并将历史数据存储在基于磁盘的HBase (Hadoop Database) 数据库中;最后,在此基础上,利用开源索引工具GeoMesa 构建时空索引与属性索引以支持历史数据的高效查询,同时,在 Redis 上为实时数据构建相应的索引,并按照设定的时间周期对数据进行切片导出,将导出的历史数据保存到HBase 中.
本文的主要结果如下:
(1) 针对钢铁货运平台所产生的海量多源数据,利用分布式云存储和NoSQL 技术,设计分级存储策略,将货运平台所产生的历史数据与实时数据分开存储,确保实时数据的高效访问.
(2) 为满足物流调度决策必需的基于跨源数据的高频次关联查询、分析需求,利用Spark 对车辆所产生的轨迹数据、运单数据、车辆信息数据等跨源数据进行融合,生成具有多属性的运单轨迹数据.
(3) 为历史数据和实时数据构建时空索引和属性索引,以提升属性查询、时空范围查询和运单轨迹时空范围查询的效率.
(4) 在物流企业提供的真实数据集上进行了大量对比实验,验证了本文所提出的存储方式和构建的索引相较于传统方法有显著的性能提升.
1 相关工作
时空数据作为物流数据中最重要的组成部分,是物流数据管理中最为关键的一环,许多物流数据管理平台都为物流中的时空数据设计特有的管理策略,如京东的城市时空数据引擎 (Jd Urban Spatio-temporal Data Engine),菜鸟的STAMP (Spatial-Temporal Analysis and Management Platform)平台等.因此,对于物流数据的管理,要先考虑对于时空数据的存储和索引.现有对于时空数据索引和查询的研究可以分为两类: 单机系统和分布式系统.
在单机系统中,许多索引是在R-Tree 基础上进行扩展,主要分为两类.第一类是增加时间维度,构建3D R-Tree,例如,STR-Tree (Sort-Tile-Recursive-Tree),TB-Tree (Trajectory-Bundle-Tree),以减少查询对磁盘的访问.第二类则是先对时间段进行分区,然后在每个时间分区内再构建R-Tree 索引.例如,Historical R-Tree,Multi-version 3D R-Trees.然而随着时空数据规模的不断增大,各种基于R-Tree结构的索引查询性能受到单机计算资源的限制,导致难以高效查询出一定时空条件下的时空对象.
在分布式系统中,很多研究[1-8]在这些系统之上构建时空索引扩展模块,以支持对时空数据的高效查询.Simba[1]基于Spark SQL 框架进行扩展,结合RDD (Resilient Distributed Datasets)结构构建了两层索引机制: ①为所有分区构建一个全局索引;② 在各个数据分区内部构建本地索引,以支持范围查询和kNN (k-Nearest Neighbor)查询在内的多种查询.DITA (Distributed In-Memory Trajectory Analytics)[2]利用起止点信息进行分区和构建全局索引,根据轨迹中的关键点构建本地索引,以支持高效的相似查询,并设计了负载均衡策略.Ratel[3]构建了两层索引: ①在全局根据轨迹的起止点建立R 树索引;② 在本地为轨迹中间的节点构建网格索引,以支持轨迹的相似查询和起止点范围查询.Dragoon[4]设计了一个可变RDD 模型,以混合方式对于历史轨迹和实时轨迹流进行管理,并设计不同的分区策略以支持ID (IDentity)查询、范围查询和kNN 查询.这些系统是基于Spark 的数据管理系统,在处理数据时需要将所有数据加载到内存中,这就要求有大量内存的高性能集群,对于平台而言代价过于高昂.还有许多研究[5-8]基于Hbase 构建时空数据管理系统,如multi-dimensional-HBase[5]在HBase 的基础上扩展了对空间查询的支持.通过构建KD (K-Dimensional)树和四叉树索引支持空间范围查询和kNN 查询,GeoMesaa[6]利用GeoHash 将多维空间信息转换为一维字符串,与时间信息交叉编码生成时空索引,并通过ECQL (Extended Common Query Language)过滤器查询数据,以支持时空范围查询.ST-Hash[7]在GeoHash 的基础上提出ST-Hash 编码方式,在编码过程中除了空间维度外,还包括时间维度,以支持时空点查询和时空范围查询.JUST[8]在GeoMesa 的基础上构建时空数据引擎,增加Z2T、XZ2T 索引和查询算法以支持更高效的ID 查询和时空范围查询.STEHIX[9]利用Hilbert 填充曲线对空间进行划分和编码,并对Region 中的数据构建粒度更细的空间索引和时间索引.当进行时空查询时,首先,利用空间信息定位到具体的Region;然后,分别利用空间索引和时间索引检索结果;最后,取二者查询数量较小的作为索引结果返回.
在物流场景中除了时空数据外,还有非时空数据,这类数据对于物流场景的应用同样关键,因此,同样需要对它们构建索引,以支持对它们的查询. GR2-Tree[10]由3D R-Tree 和包含R-Tree 节点属性的结构体组成,可以实现对多属性的轨迹的查询,但随着轨迹点的插入,会引起R-Tree 节点的分裂,相应的属性结构体也需要更新,维护索引的开销较大.JUST 以属性为主键构建属性索引,每构建一个属性索引,就需要复制一份数据,随着属性类别的增加,索引也相应急剧增加,导致大量数据冗余.Feng 等[11]通过图模型对实体节点构建全局索引,并在内存中以对象形式存储节点和相关联的属性数据,但是由于索引结构依赖于不同数据库系统,全局索引与局部索引关联性较弱,存在索引不一致、维护代价高等问题.
2 整体框架与实现
2.1 数据介绍和整体框架
本文所使用的数据主要来自于货车的轨迹数据表、运单数据表与运单司机表,其中后两个表中的字段较多,仅列出其中重要的字段.轨迹数据表由12 个字段组成包括: 车牌号,采样时间,经度,纬度,速度,方向,地址,省份,市,县,查询时间和插入时间,轨迹数据包括39 142 000 个GPS (Global Positioning System)轨迹点,共526 359 条轨迹.而运单表则有130 个字段组成,是一张宽表,主要包括3 部分的信息: 运单相关信息,如运单号、运单状态、发货与收货公司标识符、返单时间、返单地址等;货物相关信息,如货物类型、重量等;运载相关信息,如起止点标识符、运送货车的车牌号等.运单数据表包括2 157 000 条运单数据,表中的许多数据都是缺失的,是典型的稀疏数据.运单司机表包括18 个字段,运单司机表是以运单为单位呈现司机的信息,包括运单号、公司标识符、司机姓名、电话、车牌号等字段,运单司机表包括2 251 814 条数据.
京创所使用的关系型数据库存储运单表与运单司机表这样的稀疏数据存在的问题有: 数据冗余,浪费大量存储空间,并且查询性能较差.当按行存储时,即使该位为空,也需要占用空间.当查询时,并不需要读出所有表中的所有属性,但是关系数据库会对记录按顺序逐条访问,这导致了较长的查询延迟.
针对以上问题,选取HBase 来存储数据.一方面,HBase 作为面向列存储的分布式数据库,适合用来存储海量的轨迹数据和稀疏的运单数据,因为是面向列存储,空列并不占用空间,可以有效节省存储空间,在查询时仅遍历需要的列,也可以大大节省查询时间.另一方面,因为,参考京东与阿里在存储海量物流数据时,也是在HBase 上进行扩展的,相关资料比较多,所以,本文选取HBase 来存储海量的历史物流数据.京创希望冷热数据能够分开存储,以满足场景中对于实时数据的查询要求.Redis 作为一个高性能的内存数据库,是用来缓存热点数据的最佳选择之一,本文使用Redis 缓存实时数据.
论文整体框架如图1 所示,首先,对多源物流数据进行分类,分为时空数据和非时空数据,并按照场景中数据之间的关联,将二者融合关联起来.然后,将历史数据存储在HBase 里并构建属性索引、Z2 索引、XZ2 索引,将实时数据存储在Redis 里并构建属性索引和时空网格索引.最后,分别在HBase 与 Redis 上实现属性查询、时空范围查询和运单轨迹的时空范围查询.

图1 整体框架Fig.1 Overall architecture
2.2 数据融合
在钢铁货运的运力预测、运力调度与车货匹配等应用中,所需的数据除了车辆的轨迹数据外,还包括该车辆的信息、运送的货物类型等数据,因此,查询就涉及对运单、车辆以及轨迹等跨源数据的关联.如果不预先对数据进行融合,在完成相关查询与分析时,需要通过连接多表查询获得结果,这样会耗费大量的时间.鉴于此,本文以货车的轨迹数据为中心,将其与不同来源的物流数据进行融合,并将融合后的中间结果保存在HDFS (Hadoop Distributed File System)文件中,这样既可以将其作为物流数据挖掘的输入数据,又便于后续数据的写入和索引构建.
数据融合旨在将预处理过后的轨迹数据与网络货运平台的物流运营数据按照应用需求进行融合,产生多属性的运单轨迹.运单轨迹是由带有时间戳的位置序列和表征车辆、货物信息的属性组成.以轨迹数据和运单数据融合,生成带有运单号和货物类型的运单轨迹为例.具体步骤为: ①读取轨迹数据,将相同车牌的轨迹点放在一个列表里,并按照采样时间对其进行排序.如果两个邻接的轨迹点采样时间间隔超过设定阈值 (如1 h),将轨迹进行分段.② 根据车牌号将运单号和轨迹段进行匹配,将同一辆货车的轨迹按运单号进行拆分,根据轨迹段中第一个轨迹点的采样时间将其与装载时间最近的运单进行匹配.③获得的运单轨迹形式为“车牌号+运单号+货物类型+轨迹点列表”,采用这种存储方式可以有效减小轨迹数据存储所占的空间,其中每一行是一条与运单匹配的轨迹,具体示例如图2 所示.

图2 数据融合举例Fig.2 Example of data fusion
2.3 数据的存储和索引
对于运单轨迹数据的存储和索引,主要分为两部分: 一部分是对于历史数据的处理,另一部分是对于实时数据的处理.
2.3.1 历史数据的存储和索引
对于历史数据,考虑到其巨大的数据量以及需要进行频繁的插入,选取分布式NoSQL 数据库HBase 来进行存储,因为HBase 扩展简单、读写速度大且存储成本低.HBase 中的数据以键值 (keyvalue) 的形式进行存储,其中key 由行键、列族、列和时间戳组成,当想要获得相应数据时,需要通过key 获得相应的value.
对于索引,则使用GeoMesa 来进行构建.GeoMesa 共支持6 种索引,分别是ID 索引、属性索引、Z2 索引、Z3 索引、XZ2 索引和XZ3 索引.其中,ID 索引和属性索引属于普通属性索引,主要用于查询非时空属性.Z2、Z3、XZ2、XZ3 属于时空索引,用于查询时空属性,其中,Z2 和Z3 索引用于索引点类型的数据,Z2 索引针对包含经纬度的二维点类型数据,Z3 索引针对包含经纬度和时间的三维点类型数据.XZ2 和XZ3 索引则是在Z2、Z3 索引基础上进行扩展,用于索引线或者面等类型的数据.
GeoMesa 中时空索引的原理是,利用GeoHash 编码系统将二维的地理位置编码为由字母和数字组成的一维字符串,然后用这个一维的字符串对时空数据进行索引.GeoHash 属于二维Z 阶填充曲线的实际应用,编码过程如下: ①转换经纬度,将地球纬度区间[–90°,90°]和经度区间[–180°,180°]不断进行左右划分,如果给定坐标属于二分的右区间范围,则标记一个1,否则标记一个0,针对不同的编码层级,分别得到经度和纬度的二进制编码;② 将经度依次放在偶数位上,将纬度依次放在奇数位上组成一维的二进制编码;③利用Base32 编码技术将二进制编码转换为由数字和字母组成的字符串.对于三维数据,则是在GeoHash 的基础上针对时间纬度进行扩展,生成时空索引.
存储数据的存储类型选择经纬度组成的坐标点类型,将ID 设置为车牌号加采样时间组成的字符串,对货物类型和运单号这两个属性构建属性索引,用于支持对这两者的属性查询,并构建Z2 索引和Z3 索引,用于支持对点数据的时空查询.
基于GeoMesa 的Java 接口开发了将货运物流数据导入HBase 数据库的程序,程序的主要步骤为: ①根据HBase 的配置信息,构建连接,创建存储对象;② 根据货车轨迹数据的属性创建相应的属性名和类型,并创建相应的表结构;③根据实际需求设置索引的属性;④ 将数据转换成已定义的结构类型,然后写入数据库.
2.3.2 实时数据的存储和索引
在货运物流场景中,实时数据作为最近产生的数据,具有极高的时效价值,经常被运用到各种实时场景分析中,属于热点数据.Redis 是一个开源的内存中的数据结构存储系统,在内存中存取数据比磁盘读取效率高,并且支持多种类型的数据结构,更符合实时数据的存储和查询要求.并且Redis 可以设置key 的过期时间,便于淘汰随时间推移的过时数据.对于实时产生的流数据,将其存储在Redis 中,并构建相应的网格索引和属性索引,以支持各种实时查询.
实时的运单轨迹数据由车牌号、经纬度、采样时间和其他属性如货物类型、订单号等组成.在Redis 中,采用集合来存储运单轨迹,集合的key 为车牌号加时间段,value 为该时间段内这辆货车的所有运单轨迹点,具体处理步骤为: ①时间段划分与归并.这里设置时间段长度为1 h,在实际使用中可以根据场景对数据时间范围的不同要求,更改时间段的长短.将1 h 内接收到的数据归入同一个时间段,使同一辆货车在同一时段内具有相同的key.例如,对于时刻2021-05-19 7:35:58,按照1 h 间隔,将其归入2021-05-19 7:00:00,转换成时间戳为1621378800,将归并后的时间戳作为key 的组成部分.② key 的组成.用时间段转成的时间戳以及车牌号组合成key,例如,归并后时间戳为1621378800,车牌号为苏H5435Z,则key 为苏H5435ZT1621378800,增加的T 表示时间段前缀.③value 的组成.用Redis 中特有的数据结构,即有序集合,来存储运单轨迹数据,集合中存入的是每条运单轨迹数据的时间戳、经纬度坐标及其他属性,如货物类型、运单号等.在有序集合中用轨迹点采样时间的时间戳作为分数值 (Redis 中用于对数据进行排序),value 为经纬度、时间、货物类型、运单号等信息拼接而成的字符串.
为了提高运单轨迹的查询效率,需要构建索引,因此,设计了网格索引和属性索引,以支持运单轨迹的查询.
关于实时数据的时空索引构建,本文采用网格索引,主要是因为数据需要实时更新,所以要求索引能够在数据增删时进行更新.网格索引在每次更新时只需要修改某一网格范围内的轨迹点数据,开销较小.Redis 作为key-value 的数据库,通过网格编码将二维经纬度数据映射为一维数据,再加上归并的时间段,实现起来较为简单,无须额外的存储结构.索引的具体构建步骤为: ①网格划分.货运物流轨迹数据分布在我国的各个省份,需要查询的数据范围覆盖我国大部分省份.本文把经度范围设置为73°E~ 135°E,纬度范围为3°N~ 53°N.这里综合考虑设置网格索引粒度为0.1°,采用经度、纬度对网格编码,以每个网格中最小经纬度坐标编码,横坐标表示东经 (用E 表示),纵坐标表示北纬 (用N 表示) .例如,坐标 (119.329 711°,35.174 452°) 所在网格的网格号表示为E119.3N35.1.② key 的组成.索引key 值中的时间段也按照1h 间隔划分,则key 由网格编号加时间段转换后的时间戳.例如,对于2021-05-19 7:35:58,经纬度坐标为 (119.329 711°,35.174 452°) 的轨迹点,将其归入2021-05-19 7:00:00,转换成时间戳为1621378800,所在网格号为E119.3N35.1,所以key 为E119.3N15.1 T1621378800.③value 的组成.value 是一个有序集合,集合内存入的是所对应网格在该时间段内所有轨迹点的车牌号,每个车牌号所对应的分数值为每条轨迹数据的采样时间.例如,车牌号为苏H5435Z 的轨迹点所对应的分数值为2021-05-19 7:35:58,转换成的时间戳1621380958,value 为苏H5435Z.
属性索引同样需要考虑索引更新问题,所以对于属性索引也加上其所属的时间段,便于当其所对应轨迹点过期时,同时删除所对应的属性索引.具体步骤为: ①时间段划分与归并.与存储模块中一样,将1 h 内的接收到的数据归入同一个时间段,使同一属性在同一时段内具有相同的key.② key 的组成.属性索引的key 主要由属性值和时间段转成的时间戳组成,例如,对货物类型构建属性索引,假设货物类型为热轧卷板,归并后时间戳为1621378800,则key 为热轧卷板T1621378800.③value 的组成.本文使用无序集合来存储属性索引的value,集合中存入的是该时间段属性为key 中所对应属性值的车牌号.例如,key 为热轧卷板T1621378800,所对应的value 为2021-05-19 7:00:00—8:00:00 内所有运送货物类型为热轧卷板的车牌号集合.
2.4 数据的查询
2.4.1 查询需求分析和定义
在货运物流信息平台的实际应用中,经常需要通过查询得到所需的数据结果以进行分析.在钢铁货运场景中,常用的查询包含属性查询、时空范围查询和运单轨迹时空范围查询.例如,当查询某辆货车执行某个运单的轨迹时,需要实现属性查询;当查询指定时段 (如15:00:00—17:00:00) 返回钢厂的货车信息时,需使用时空范围查询;当查询特定范围内运力数时,涉及时空范围与货物类型,需要执行运单轨迹的时空范围查询.
定义1(轨迹点p) 轨迹点是通过定位设备采集到的货车的位置信息,表示为p=(pid,plat,plon,pt),其中pid表示轨迹点编号,plat表示纬度,plon表示经度,pt表示采集时间.
定义2(轨迹T) 轨迹T可以表示为一个由轨迹点{p0,p1,···,pn}构成的序列,描述货车在一定时间范围内的位置变化.
定义3(运单轨迹O) 运单轨迹由货车执行运输任务时被分派的运单属性以及货车轨迹组成,可以表示为O=(Oatt,Ot) ,其中Oatt=(Owb,Oti,Ogt)表示运单属性集合,Owb表示运单编号,Oti表示车牌号,Ogt表示运送货物类型,Ot表示货车轨迹.
定义4(运单轨迹数据集So) 运单轨迹数据集So={O1,O2,···,O|So|}是一定时空范围内运单轨迹的集合,其中|So|表示集合的元素个数.
定义5(属性查询) 给定运单轨迹数据集So和轨迹属性值Qa,返回轨迹集合Sa,其中Sa由所有满足查询轨迹属性值Qa的轨迹组成.
定义6(时空范围查询) 给定运单轨迹数据集So和时空范围Qr,返回轨迹集合Sr,其中Sr由所有存在轨迹点在查询范围Qr内的轨迹组成.
定义7(运单轨迹的时空范围查询) 给定运单轨迹数据集So、轨迹属性值Qa和时空范围Qr,返回轨迹集合Qar,其中Qar包含所有存在轨迹点在查询范围内且属性满足Qa的轨迹组成.
因为实时数据和历史数据分别存储在Redis 和HBase 里,并构建了相应的索引,所以将从历史数据和实时数据这两个方面介绍.
2.4.2 历史数据的查询
历史数据存储在HBase 里,并通过GeoMesa 构建了属性索引、Z2 索引、Z3 索引等.对于历史数据的查询也是通过GeoMesa 这个中间件来实现的.GeoMesa 提供了一套统一的GeoTools Query 查询接口,这个接口采用基于CQL (Common Query Language)的条件查询,支持各种空间关系谓词和时间关系谓词.
使用GeoTools 进行查询的基本流程如下.
(1)根据查询条件编写ECQL 下面给出每种类型查询的例子.
①属性查询.定义查询的CQL 为String attribute=“truck_no=苏H5435Z”,如果需要查询满足多个属性要求,可以用关键字“AND”将多个条件连接起来,在查询语句中关键字为大写.
② 时空范围查询.定义查询语句“String range=“BBOX(geom,119.37,35.17,119.38,35.30)AND dtg DURING 2021-05-21T00:00:00.000Z/2021-05-22T00:00:00.000Z””,其中关键字“BBOX”用于限制空间范围,“DURING”用于限制时间范围,“AND”用于连接不同的查询条件.
③运单轨迹的时空范围查询.对于历史数据的运单轨迹时空范围查询,给出查询的时空范围和相应的属性值限制,使用关键字“AND”进行连接.例如,定义CQL 语句 String capacity=“goodDes=‘热轧卷板’ AND BBOX(geom,119.37,35.17,119.38,35.30) AND dtg DURING 2021-05-21T00:00:00.000Z/2021-05-22T00:00:00.000Z”.
(2)获取待查询表的表名与表结构.
(3)用CQL 创建Filter 类型的对象.
(4)创建查询对象,将(2)与(3)中获取的表结构、表名和Filter 对象作为查询对象.
(5)构建GeoMesa 连接,创建存储对象.
(6)使用存储对象获取数据读取器,将查询对象传给数据读取器执行查询,查询结果通过读取器获取.
GeoMesa 在执行查询计划时,重写CQL 以进行快速评估并优化,再根据可用索引对过滤条件进行拆分,由索引选择决定主过滤器和辅助过滤器.例如,对于运单轨迹的时空范围查询,GeoMesa 分解出两种索引方案.
(1) Z3 索引+属性Filter 索引.
Z3 索引 (主过滤器): BBOX(geom,119.37,35.17,119.38,35.30) AND dtg DURING 2021-05-21T00:00:00.000Z/2021-05-22T00:00:00.000Z.
属性Filter 索引 (辅助过滤器): goodDes=‘热轧卷板’.
(2) Z2 索引+时间和属性Fliter 索引.
Z2 索引 (主过滤器): BBOX(geom,119.37,35.17,119.38,35.30).
时间和属性Flite 索引 (辅助过滤器): dtg DURING 2021-05-21T00:00:00.000Z/2021-05-22T00:00:00.000Z AND goodDes=‘热轧卷板’.
GeoMesa 会对以上两种索引组合进行比较,并选择更优的组合.
2.4.3 实时数据的查询
实时数据存储在Redis 里,对于实时数据的查询主要通过构建相应索引表,加速查询的过程.
(1) 属性查询.当对轨迹数据进行存储时,key 用的是货车车牌号,对于车牌号的属性查询,可以使用Redis 中有序集合的Zrange 命令获得指定车牌号的轨迹.对于其他属性的属性查询,则需要先通过该属性的索引,以得到满足该属性条件的车牌号,再根据车牌号查询得到轨迹数据.当查询满足多个属性要求的轨迹时,首先,需要根据属性索引得到满足每个属性的车牌号;然后,对这些车牌号的集合求并集;最后,根据并集中的车牌号查询其轨迹数据.
(2) 时空范围查询.对于时空范围查询,首先,需要根据给定的时间范围,计算得到与其相交时间段的候选时间戳;其次,根据给定查询的空间范围,获得与其相交的候选的网格集合,最终的查询结果在候选的网格集合中;再次,将候选时间戳和候选网格集合两两组合得到候选时空网格集合,取出候选时空网格中的轨迹点;最后,筛选出满足时空范围条件的轨迹点集合,并返回结果.
(3) 运单轨迹的时空范围查询.首先,计算与查询的时空范围相交的网格和时段,将网格与时段逐一组合成候选 key 集合,并筛选出候选 key 集合中满足时空范围要求的车牌号集合;然后,计算符合属性要求的车牌号集合;最后,对这两个车牌号集合求交集,根据交集中的车牌号查询最终结果并返回.具体流程如图3 所示.

图3 运单轨迹时空范围查询流程Fig.3 Process of spatio-temporal range query on attribute trajectory
3 实 验
本文在真实数据集上进行实验,对查询的性能进行评估.本文所使用的数据集来自山东省某钢铁物流企业运营的网络货运平台的真实数据集,包含从2021 年05 月01 日至2022 年02 月28 日共10 个月的运单及其轨迹数据.其中,轨迹数据包含39 142 000 个GPS 轨迹点,共526 359 条轨迹;运单数据有2 157 000 条.实验所使用的集群共有3 个节点,每个节点配备Centos7.4、4 核中央处理器、16 G 内存、200 G 磁盘,选择PostgreSQL 数据库作为对比数据库,版本是13.3.PostgreSQL 是一个对象关系型数据库,通过安装PostGIS 插件扩展了PostgreSQL 对空间数据的支持.将轨迹数据和运单属性存入PostgreSQL 中,并对其中的经度、纬度、时间戳构建索引,实验中对比了PostgreSQL 与本文所提出方案的存储性能和查询性能.
3.1 存储性能
存储性能的评价指标主要分为两部分: 一部分是存储轨迹数据和运单数据所需的磁盘空间;另一部分是将数据导入数据库所需时间.
图4 展示的是数据融合前后数据存储磁盘所需要的空间大小,将全部轨迹数据分为5 等份,分别测试占全部数据20%、40%、60%、80%与100%数据量的存储空间.在融合前,原始数据一条记录存储一个轨迹点,融合后一条记录存储一条轨迹.从图4 中可以看出,随着数据规模的增大,数据融合前后占用磁盘空间大小差异更加明显,和融合前相比,融合后的数据存储所占用的空间更小.说明经过数据融合可以显著减小轨迹的存储空间.

图4 存储空间Fig.4 Data size
将本文所提出的物流数据管理系统与PostgreSQL 的数据存储时间进行对比,结果如图5 所示,可以看出,本文所提出的数据管理系统存储数据耗时更短,在批量插入数据时更有优势.究其原因,是本文使用的HBase 数据库底层是基于分布式文件系统HDFS,能够实现对海量数据存储的秒级响应,在轨迹这类超大规模的数据处理中非常高效.PostgreSQL 这一传统的关系型数据库,本身不支持并行插入数据,而且PostgreSQL 内部所使用的是R-Tree 索引,随着数据的不断插入,R-Tree 索引频繁更新,导致存储性能不高.本文所提出的系统使用网格索引并且按照键值对的形式存储管理数据,所以存储效率较高,适合物流管理领域对大量轨迹等数据进行存储.
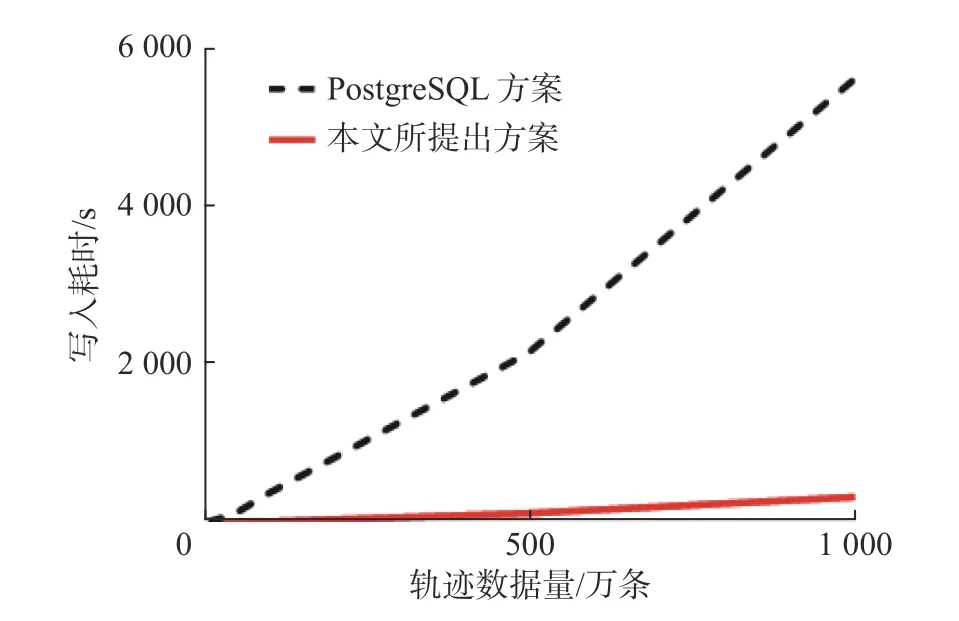
图5 写入耗时Fig.5 Writing time
3.2 查询性能
(1) 属性查询.使用货车的车牌号和运送的货物类型作为查询条件,测试属性查询的性能,结果如图6 所示.可以看出,在数据量较少时,PostgreSQL 查询耗时更短,因为,本文所提出的方案使用GeoMesa 进行查询,在执行查询计划时,都需要解析 CQL,并计算不同索引的查询性能,无论数据规模的大小,这一过程都需要耗费一定的时间,所以,在数据较少时优势并不明显.但是随着数据量的增加,PostgreSQL 的查询耗时急剧增长,而本文所提出的系统中使用HBase 的查询耗时增长则比较平缓,当数据量达到千万级别时,本文所提出的方案远优于对比方案.反映了本文所提出的物流数据管理系统查询性能的高效率.

图6 属性查询性能Fig.6 Performance of attribute query
(2) 时空范围查询.在全部数据上分别测试了不同时间范围和不同空间范围下的查询耗时.在空间范围查询实验中,分别选取5 km × 5 km、10 km × 10 km、15 km × 15 km、20 km × 20 km、25 km × 25 km 共5 个不同矩形空间范围作为查询条件,同时保持其在相同的时间范围,在本文所提出的系统和PostgreSQL 上分别进行实验.在时间范围查询实验中,分别选取1 h、1 d、7 d、30 d 共4 种不同的时间范围,并控制空间范围相同进行实验,实验结果如图7 所示.

图7 时空范围查询性能Fig.7 Performance of spatio-temporal range query
从图7(a)中可以发现,无论是本文所提出的系统,还是PostgreSQL,整体上,查询耗时和查询的空间范围关系不大,因为,在真实的物流场景中,数据分布是不均匀的,增大时空范围不能保证查询到更多的结果,所以,查询时间受空间范围的影响较小.另外,可以看出,本文所提出的系统的查询耗时远短于PostgreSQL 的查询耗时,后者的查询耗时大概是前者的6 倍.图7(b)的时间范围查询实验结果与图7(a)类似,与PostgreSQL 相比,本文所提出的系统的查询性能更优.
(3) 运单轨迹的时空范围查询.分别进行时间范围查询和空间范围查询的实验,对于同样的属性条件,选取不同空间范围测试查询耗时,实验结果如图8 所示.从图8(a)中可以发现,随着空间范围的增大,PostgreSQL 查询耗时逐步增长,而本文所提出系统的查询耗时没有明显变化,这是因为,本文所提出的系统底层使用HBase 进行存储,HBase 的扩展性非常高,所以,即使查询数量增加,查询所需要的时间几乎不变.从图8(b)中可以看出,对于运单轨迹的时空范围查询,时间范围的改变对于查询性能影响较小,但因为本文所提出的系统底层HBase 的高扩展性,本文所提出的系统的查询耗时也短于PostgreSQL 的查询耗时.

图8 运单轨迹时空范围查询耗时Fig.8 Performance of spatio-temporal range query on attribute trajectory
从以上3 种查询实验的结果可以看出,本文所提出的物流数据管理系统对于属性查询、时空范围查询和运单轨迹的时空范围查询这3 类查询较为高效.特别是当数据量非常大时,查询性能明显优于传统的关系型数据库,更适合钢铁物流数据管理的场景.
4 结 语
为实现对钢铁网络货运平台产生的海量、多源的物流数据的存储和查询,本文基于HBase 和Redis 将海量历史数据和实时数据分级存储管理,并在此基础上构建 Z2、Z3 与网格索引等时空索引与属性索引来提升查询效率.通过在真实物流数据集上进行实验,验证了本文所提出的索引能有效提高查询效率.在未来研究中,考虑针对场景中常用到的其他查询,如相似查询和kNN 查询,并设计相应的索引和查询优化策略.
猜你喜欢
中国储运(2024年1期)2024-04-13 22:08:34
铁道运输与经济(2022年5期)2022-05-25 09:22:46
四川党的建设(2022年8期)2022-04-28 21:29:35
小学生学习指导(低年级)(2020年11期)2020-12-14 07:28:10
作文大王·低年级(2018年10期)2018-12-06 06:22:44
莫愁(2018年6期)2018-11-14 14:06:12
高中生·天天向上(2018年9期)2018-11-06 07:39:34
中国交通信息化(2016年3期)2016-06-05 02:21:35
小猕猴智力画刊(2016年5期)2016-05-14 09:21:39
实践·党的教育版(2016年4期)2016-05-04 15:47:46
