
基于自注意力机制的钢铁物流运力预测
2022-09-26 13:06:20苗晓变廖家俊梅华杰毛嘉莉
华东师范大学学报(自然科学版) 2022年5期
苗晓变 ,廖家俊 ,梅华杰 ,冯 冲 ,毛嘉莉
(1.华东师范大学 数据科学与工程学院,上海 200062;2.华为技术有限公司,杭州 310000)
0 引 言
随着大数据、人工智能、云计算等新一代信息技术的日趋广泛应用,传统的钢铁物流行业开启了数字化转型,进入网络货运时代.通过构建网络货运平台,对车辆和货物进行合理匹配,解决了货源与车源之间的信息不对称问题.货运平台将所有客户所在地 (运输终点) 按照行政区域划分为多个流向,对于各个流向承运货物的车辆统称为运力.由于钢铁产成品常采用公路长途运输,需要由重卡、超重卡汽车执行运输任务,货运平台仅对货车进行单程 (即由钢厂到客户企业) 运输任务指派,返程 (返回钢厂) 货源则由货车司机自行联系,司机更倾向于接受其熟悉流向的运输任务,故承运不同运输流向的车辆数分布极不均匀.如图1 所示,在某一家物流企业的网络货运平台上注册有6 048 名货车司机(山东省内),其中超过2 700 名司机只承担过1 个流向的运输任务.图1 反映了钢铁物流中车辆对路线的依赖度.为缓解企业的仓库货物囤积问题,保证运输任务的高效执行,亟需恰当的运力预测方法来支持运力调度与车货匹配决策.
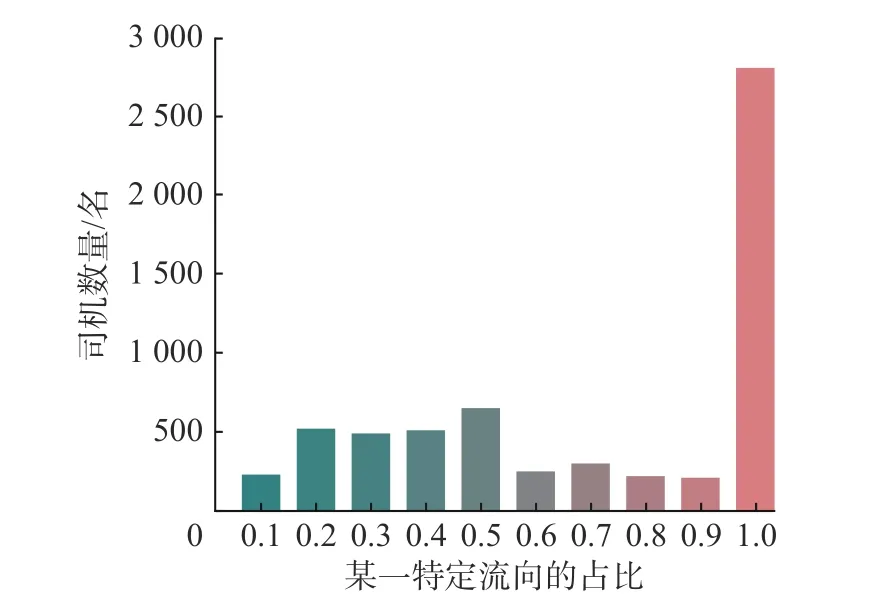
图1 车辆对路线的依赖度分析Fig.1 Analysis of vehicles dependence on routes
钢铁物流中的运力预测问题,其目是预测未来时段内运输某个流向的空闲车辆信息.近年来,仅有少数研究基于车辆轨迹为网约车派单平台设计了给定区域的空载车辆数预测方法[1],该类方法仅关注局部时空区域对进/出给定区域车辆数的影响.与运力预测类似的交通预测问题受到了学术界、工业界的普遍关注,并获得了较为广泛的研究,这些研究大多是解决城市道路的流量预测以及旅行时间预测[2-5]等问题.上述方法和研究未关注不同车辆对运输流向的偏好,不适合用于解决钢铁物流的运力预测问题.鉴于货车司机对运输流向的高度依赖性,为支持运力的有效调度,运力预测需要提供不同流向可服务车辆的信息 (如车辆ID).随着网络货运平台业务的不断发展,海量的货车轨迹、运单、车辆以及运输终点等物流数据被积累,这些物流数据为运力预测问题的研究提供了机会.钢铁物流对不同流向的可用运力预测问题主要包括2 部分工作: ①预测各个时段内返回钢厂的空闲运力信息,称为运力的可达性预测;②预测到达钢厂的运力在未来时段选择承运的运输流向.
鉴于钢铁物流的复杂性,运力预测正面临严峻的挑战.基于历史物流数据的分析发现,货车再次成为钢厂的可用运力,其时长包括完成平台分配运输任务的执行时间和任务完成后返回钢厂的时间.如图2 所示,每次运输中,货车的行程涉及离开钢厂(运输起点,Pstart)运输货物到客户企业(运输终点,Pend) 和再驱车返回钢厂.运力预测亟需解决的2 个问题: 第一,根据车辆每行驶4 h 司机必须休息20 min 的交通法规,货车在执行长距离运输途中需要多次在休息区停留.由于司机的个体习惯以及停留原因的不同,导致在各个休息区耗时的不同,增加了预测运输完成时间的难度.第二,由于返程时司机自行联系运输货源,导致运输返程轨迹缺失,从而造成返程时间的不确定.

图2 钢铁货运全程示例Fig.2 Illustration of steel freight
对于运输任务执行过程中的停留时长不确定问题,究其原因是受司机个体差异化的驾驶习惯以及客户企业收货时间不同等因素影响.鉴于此,本文通过结合运单、车辆、运输终点以及车辆轨迹数据等提取多个表征司机驾驶习惯的特征,同时获取不同客户的收货习惯 (这里指客户企业的工作时间范围) 特征,并将上述特征输入所构建的运力可达性预测模型.针对返程轨迹缺失导致返程货起/终点不确定带来的返程时间预测误差过大问题,本文将运输任务执行与返程时间的预测问题并入运力可达性预测问题进行研究.文中首先通过对历史物流数据进行分析,提取包括反映司机驾驶习惯的特征与返程时间的相关特征;考虑到特征之间的相互影响,受注意力机制[6]的启发,在构建运力可达性预测模型时设计了两个注意力网络,分别用于捕捉对驾驶习惯有影响的不同特征及其影响权重、以及对返程时间有影响的特征及其影响权重.
此外,鉴于运力服务流向的有限性,本文通过对运单和轨迹数据的进一步分析发现,货车司机在缺少熟悉流向时倾向于接受相似流向的运输任务.因此,为降低货车的空驶率,可以根据流向间的相似性进一步扩充货车的服务流向集合.为此,本文定义了流向间的相似度,从而基于相似流向生成运力的候选运输流向集.考虑运输流向在地理空间上的距离相近 (称为流向的地理相似度) 以及流向间的潜在相似性 (称为流向的语义相似度),将流向间的相似度定义为地理相似度与语义相似度的加权和.关于语义相似度计算,若货车的历史运输任务中除运输次数最多的流向外,还运输过其他流向,则认为这两个流向具有语义相似性.如果历史数据中同时选择运输这两个流向的司机越多,那么这两个流向之间的语义相似度越大.
对于各运输流向的运力候选集,本文根据可达性预测模型得到各时段内的可达运力集.随后,需要结合货车司机长期的运输流向偏好与流向价格变化给司机带来的短期流向选择影响,预测未来时段内可用运力选择的运输流向.为提取司机的流向选择行为随时间变化的规律,本文将该问题建模为一个时间序列预测问题.具体地,按照运单时间基于司机历史承运的流向生成随时间变化的流向序列,预测未来时段司机选择接受的运输流向.鉴于长短期记忆网络 (Long Short-Term Memory,LSTM) 在捕捉长周期时序特征方面的优势[7],本文利用LSTM 模型预测可达运力选择接受的运输流向,从而获得未来时段内各个流向的可用运力列表.
本文的主要贡献如下.
(1) 首次提出了钢铁物流的运力预测问题,并设计了1 个三阶段的运力预测方法,包括基于流向相似度的运力候选集生成、候选运力的可达性预测,以及可达运力选择承运的流向预测等.
(2) 为降低停留时长不确定与返程轨迹缺失对运力可达性预测精度的影响,基于历史物流数据提取车辆停留行为特征、运输终点特征、环境特征;同时,引入自注意力机制分别获取不同特征对货车运输行程与返程耗时的影响及其权重.
(3) 基于物流企业真实数据集上的对比试验,验证了本文所提预测方法的有效性;此外,本文模型已成功地应用于钢铁物流企业的网络货运平台.
本文后续结构: 第1 章梳理运力预测的相关工作;第2 章对重要概念进行形式化定义,并给出本文研究的问题定义;第3 章详细介绍本文提出的技术方案;第4 章在真实数据集上对本文所提方法与一些经典方法进行对比实验;第5 章是对全文的总结.
1 相关工作
交通流量预测与运力预测较为相似,其主要任务是通过分析城市道路网络中的时空数据 (如车辆的轨迹数据),对各条道路或不同地理区域内通行的车辆数进行预测,该问题已得到广泛而深入的研究.早期,Kamarianakis 等[8]利用自回归移动平均 (Auto-Regression and Moving Average model,ARMA) 模型对道路网络交通流进行建模.但是由于统计模型仅关注单个路段或较小的道路网络区域,捕捉复杂非线性关系的能力有限,不适用于由数千个路段组成的大型城市路网的交通流量预测问题.随着机器学习模型的兴起,不少学者开始将机器学习模型引入交通预测研究中.Manoel 等[9]使用支持向量机回归模型 (Support Vector Regression model,SVR) 预测短期高速公路交通流量.Guy 等[10]结合集成学习方法 (如随机森林) 与自适应增强算法 (Adaptive Boosting,AdaBoost) 组成弱学习器用于交通流量预测.近年来,随着深度学习技术的迅猛发展,更多学者在交通流量预测工作中引入深度神经网络模型以提升预测精度.Zhang 等[11]将城市路网中的交通流量数据视为图像数据进行处理,提出了基于卷积神经网络 (Convolutional Neural Networks,CNN) 的深度时空残差网络 (Spatio-Temporal Residual Networks,STResNet) 模型对交通流量进行预测.
在运力预测方面,Wong 等[2]提出了两阶段的方法预测空闲出租车的行驶行为与出租车数量分布的变化,并提出了定制的深度残差神经网络(Deep Supply-Demand,DeepSD) 模型来预测每个区域的网约车服务供需缺口,继而根据供需缺口进行运力调度.DeepSD 模型可以看作是1 个使用多种数据源的多层感知器[12].Ke 等[13]对城市道路网络按照六边形网格进行划分,提出了基于六边形的卷积神经网络集成框架,实现网约车服务的供需缺口预测.该模型不考虑司机的偏好,只关注每个区域内的运力总数预测.不同于上述方法应用的网约车场景,在以钢铁物流为代表的大宗物流场景中,货车司机对运输流向依赖性较强.此外,交通流量预测仅根据各个区域之间的时空关系预测出每个区域的流量数量,无法预测每个流量的具体信息.如果采用交通流量预测方法进行运力预测,会导致在后续的运力调度阶段无法兼顾运力对流向和货物的偏好,导致司机满意度下降,造成司机流失,影响平台的长远发展.因此,为支持运力调度以及车货匹配的有效决策,本文提出的运力预测问题需面向不同运输流向预测可用车辆的信息 (如车牌号),不能直接采用上述方法解决.
如前所述,本文提及的运力预测问题与给定时段内运力的可达性预测相关,后者的预测精度取决于运输到达时间与返程时间预测的有效性.近年来,车辆的旅行时间预测问题已成为交通、物流等领域内的经典预测问题,涌现出了一大批研究工作.它们大致可以分为2 类: ①基于路径的时间预测,即预测车辆行驶通过给定路径需要的时长;②基于起点/终点 (Origin-Destination,OD) 的行驶时长预测,即给定起点和终点,不指定具体路径,预测车辆从起点出发行驶至终点所需时间.在基于路径的旅行时间预测方法中,给定路径的总的旅行时间常被估算为车辆在每个路段的行驶时间与每个交叉路口的等待时间的总和.Jenelius 等[14]提出了SMA (Spatial Moving Average) 模型,根据历史数据提取不同路段之间的空间相关性.Zheng 等[15]将旅行时间预测问题建模为1 个回归问题,提出了WDR(Wide-Deep-Recurrent) 模型,Wide-Deep 用于捕捉行程的整体信息,并采用循环神经网络 (Recurrent Neural Networks,RNN) 模型对轨迹建模以学习路段之间的关联信息.与之相比,基于OD 的旅行时间预测方法则聚焦于给定OD 的旅行时间预测.Jindal 等[3]提出的用于旅行时间估计的多层前馈神经网络(Spatio-Temporal Neural Networks,ST-NN)模型,先以起点和目的地的经纬度坐标作为输入来预测旅行距离,再结合旅行距离与时间信息估计旅行所需时间.Li 等[4]提出了无需路线信息的到达时间预测方法,根据有限的可用信息以及复杂的时空依赖性,提出了预估到达时间的多任务表征学习(MUlti-task Representation learning model for Arrival Time estimation,MURAT)模型,并通过多任务学习在训练阶段利用历史行程的路径信息进一步提升了模型的性能.Wang 等[5]通过计算具有相似起点和目的地位置的相邻行程的加权平均值来估计被查询行程的行驶时间.与上述工作不同的是,本文提出的可达性预测方法不仅考虑了时空相关性,还关注了对运力可达预测结果有影响的环境因素、司机个人驾驶习惯、客户地卸货规律、货物品种等方面.
2 问题定义及数据处理
2.1 概念定义
(1)终点
每个终点表示1 个客户所在地,即1 次运输任务需要送达的具体位置.本文中终点由(eid,eadd,elon,elat)组成.其中,eid为终点ID,eadd为自然语言表示的终点地址,elon、elat分别为终点的经度和纬度.
(2)流向
流向表示对终点的划分,多个距离相近的终点属于同一个流向.本文中终点根据行政区县划分为流向,将山东省内的20 000 余个终点划分为135 个流向.
(3)货车
货车为在平台上注册的运输车辆,由 (cid,cno,cer)组成.其中,cid表示车辆ID,cno表示车牌号,cer表示车辆司机.
(4)运力
(5)运单
运单表示1 次运输任务的记录,由1 个五元组 (cid,eid,s,l,Δt) 组成.五元组是由运输任务的承载货车cid、终点eid和开始时间s,并加入钢厂至终点的历史平均路径距离l和完成运输并返回钢厂所需时间 Δt组成.其中,历史平均路径距离l为该终点所有历史运单路径距离的平均值,且每个历史运单的路径距离为货车行驶轨迹经过的路径总长度.
(6)货车历史轨迹
货车的历史轨迹记录每辆货车从运输开始至货物送达之间的行驶过程,每间隔2 min 进行1 次采样,每条轨迹为S个连续的历史GPS 点,即货车轨迹Ptra,i={p1,p2,···,pS},每个GPS 点包含经度、纬度和时间戳.此外本文所用轨迹数据集中也记录了产生当前轨迹的货车ID.
(7)运力预测问题

公式(1)中:F(·)表示本文提出的模型预测函数;表示流向i在t+1 时刻的运力.
2.2 数据预处理
本文所采用的数据来自山东某钢铁物流公司运营中采集的真实数据,主要包括车辆轨迹数据和订单数据,以及运输终点和车辆的辅助信息.平台采集的原始轨迹数据不记录轨迹生成时车辆的行为目的,然而,本文的运力预测模型训练需提取车辆每次运输任务完成过程中的特征,从而学习车辆的驾驶习惯.因此,本文需要对轨迹数据进行切分,将每个车辆的原始轨迹根据运输任务切分为不同的子轨迹,为提升轨迹质量,对子轨迹进行异常点处理和缺失识别并补齐,为提取车辆到达客户地的卸货特征,还需识别车辆在客户地附近的停留行为.除此之外,由于司机驶离钢厂后平台无法对司机进行实时监控,只可通过GPS 轨迹采集轨迹数据,为预测货车的可达性,本文需要对运输完成和返程时间等数据进行补齐,并为防止异常数据对训练的干扰,需剔除运单数据中的异常值.综上所述,为方便后续的特征正确提取,本文需要对平台采集的原始轨迹和运单数据进行多种预处理.
2.2.1 轨迹数据预处理
轨迹数据是指有带时间戳的位置组成的序列,在对车辆轨迹分析的过程中,可以提取司机的驾驶行为,如停留时间、停留频次等.轨迹数据预处理旨在提高轨迹质量,并将每个车辆的轨迹切分为与运单匹配的子轨迹.
(1) 切分子轨迹
采集原始轨迹数据中每辆货车执行每个自然月的运输任务位置信息作为1 条轨迹,本文根据各个运单的起始时间,将车辆轨迹切分为与不同运单匹配的多条子轨迹.
(2) 异常点处理
在轨迹数据的采集过程中,由于GPS 设备故障或信号不稳定,会产生一些异常数据点.本文主要识别并处理速度异常轨迹点,货车的行驶速度通常小于60 km/h,本文将速度大于90 km/h 的轨迹点识别为速度异常轨迹点予以删除.
(3) 缺失轨迹识别与处理
在货车行驶过程中,由于车内信号设备故障或卫星信号不稳定等情况,在相当长一段时间内无法正常采集货车的位置信息,导致货车部分轨迹缺失.以车辆轨迹中从信号丢失到再获取的时间间隔作为轨迹缺失时间段,令每条轨迹中存在M个缺失时间段,则以1 条轨迹中M个缺失时间段的总和与该轨迹总时间的比值作为轨迹的缺失率.当1 条轨迹的缺失率超过50%,则称该条轨迹为严重缺失轨迹,将其剔除;若缺失率不超过50%,则使用线性插值法补充缺失时间段的轨迹点序列.
(4) 客户地停留行为识别与处理
客户地停留行为是指货车从进入客户企业所在地到离开的这段时间内的停留行为,反映了货车在客户企业的卸货过程,包括排队等待与卸货作业.根据同一客户不同运单的卸货时间可以获得客户企业的有效工作时段,称之为收货习惯.
2.2.2 运单数据预处理
(1)数据补齐
原始运单数据包括运单的终点 (客户地)、出发时间、承运车辆、货物品种.为预测货车的可达性,根据历史运单轨迹中货车在客户企业完成卸货作业与再次返回钢厂的时间间隔获得货车完成运输任务返回钢厂耗费的时长.
(2)异常数据剔除
由于车辆故障或者司机延时确认运输完成等因素,部分运单存在严重超时问题,根据95%的置信区间剔除同一终点的时间异常运单数据.
3 技术方案
本文构建了基于自注意力机制的三阶段运力预测方案,包括运力候选集生成、候选运力可达性预测与各流向的可用运力预测,总体框架如图3 所示: 首先,计算流向之间的相似度,根据当前流向及其相似流向的历史运力集生成各个运输流向的运力候选集.然后,在可达性预测阶段,引入自注意力机制构建可达性预测模型.具体地,在从多个来源的物流数据集上提取特征之后,考虑货车运输途中受各种复杂因素的影响,结合自注意力机制学习不同特征的重要性,并将其输入全连接神经网络中预测车辆是否可达.最后,在可用运力预测阶段,根据每个可达车辆的历史运输流向,计算未来时段货车到达钢厂后选择承运的流向,最终产生任一流向的可用运力列表.
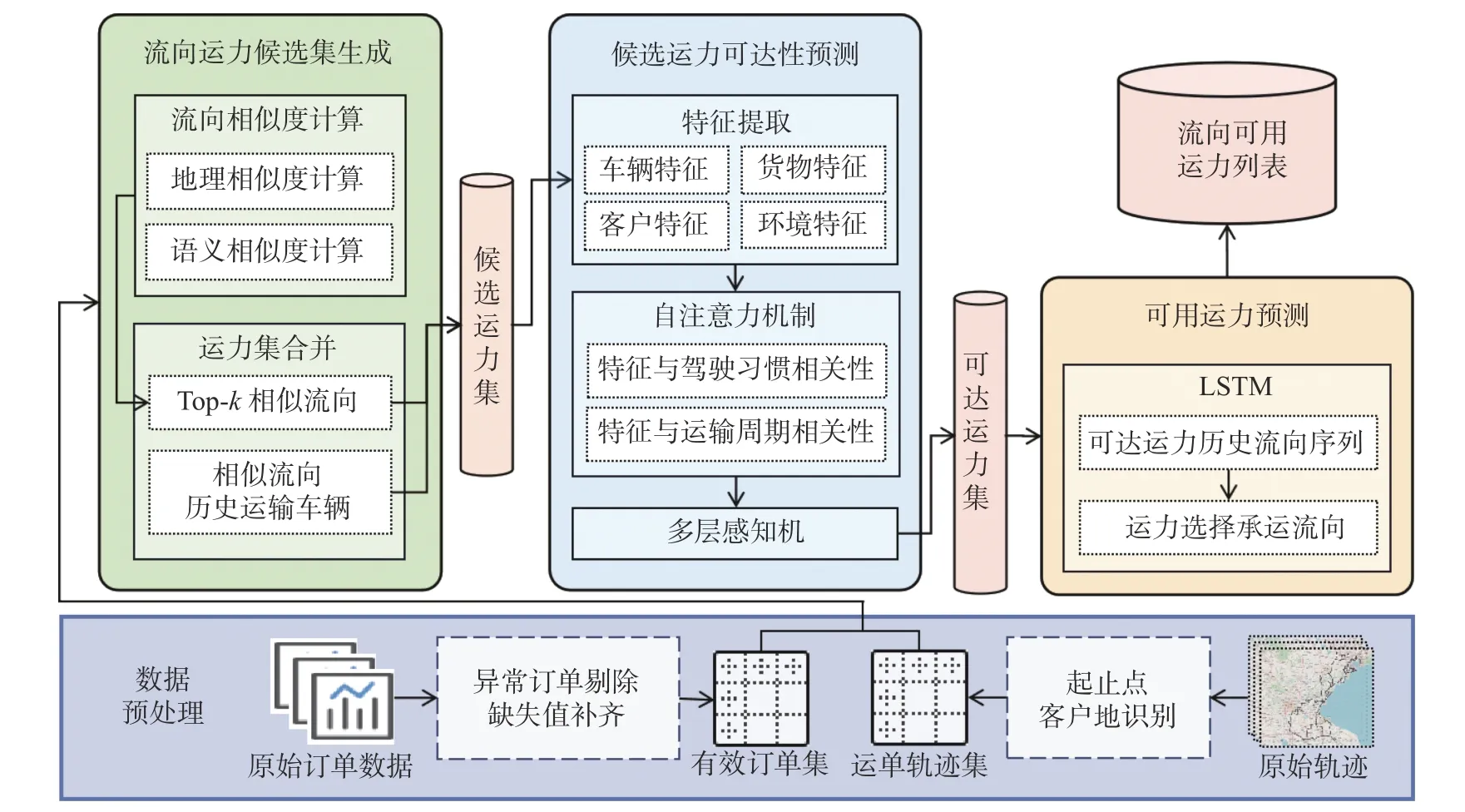
图3 总体框架Fig.3 Framework of capacity prediction
3.1 运力候选集生成
不同流向对运力的需求不同,若司机偏好流向货源不足时,司机可能选择其他流向承运.为预测各运输流向的可用运力,本文通过计算运力候选集,扩充可能承运每个流向的运力.首先,利用历史数据捕捉历史运输任务中承运过各流向的车辆;然后,通过计算流向之间的相似度,根据当前流向及其相似流向的历史运力集生成各流向的运力候选集.
3.1.1 流向相似度
给定N个流向,流向之间的相似度包括流向之间的地理相似度和流向之间的语义相似度.
(1) 地理相似度
地理相似度衡量流向之间在地理空间上的相近程度.1 个流向中包含多个终点.为衡量2 个流向之间的距离,首先确定每个流向的中心位置,然后对流向所包含的所有终点进行聚类,如图4 所示.图4中,将聚类后终点数最多的A1类的中心位置作为该流向的中心位置,表示流向的地理位置.

图4 流向位置计算示例Fig.4 Calculation and graphical presentation of flow location
假设流向Fi中心位置的经纬度为 (llon,1,llat,1),流向Fj中心位置经纬度为 (llon,2,llat,2),则流向Fi和流向Fj之间的地理距离ddist(i,j) 为两中心位置之间的半正矢距离.半正矢距离表示地球表面两点之间的球面距离,计算公式为
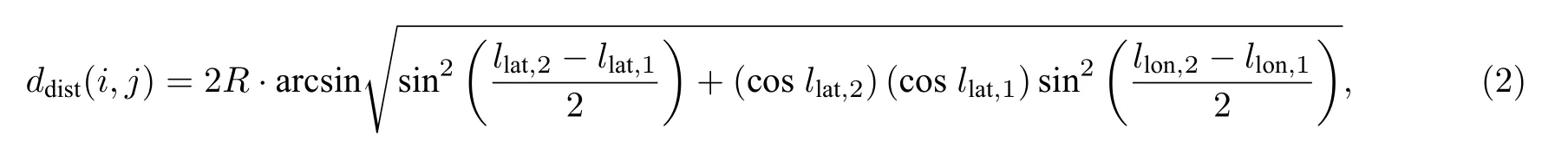
其中R为地球半径.流向Fi和流向Fj之间的地理相似度Ssim1′,ij的计算公式为
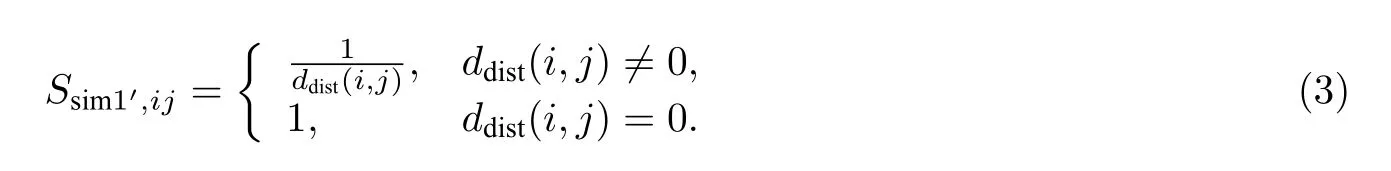
对Ssim1′,ij进行归一化处理,得到地理相似度Ssim1,ij.其计算公式为
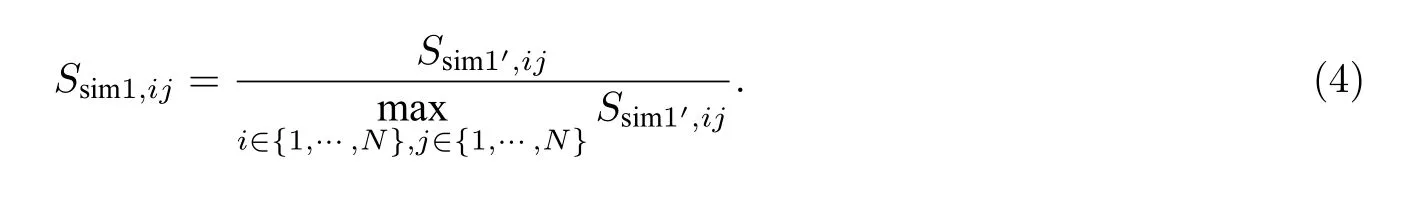
(2) 语义相似度
语义相似度用于衡量流向之间的潜在相似性.具体地,若货车的历史运输流向集合中既包括流向Fi又包括流向Fj,可推断流向Fi和流向Fj之间具有某种相似性,比如,流向Fi和流向Fj可从同一条国道上到达.本文把此类相似性称为语义相似度.当同时包括2 个流向的车辆数越多时,流向间的语义相似度越高.根据历史运单数据得到流向Fi的历史运输车辆集合Si={c1,c2,c3,···,cm},ci表示货车i.利用Jaccard 相似度计算流向Fi和流向Fj之间的语义相似度Ssim2′,ij,公式为

对Ssim2′,ij进行归一化处理,得到语义相似度Ssim2,ij.其对应公式为
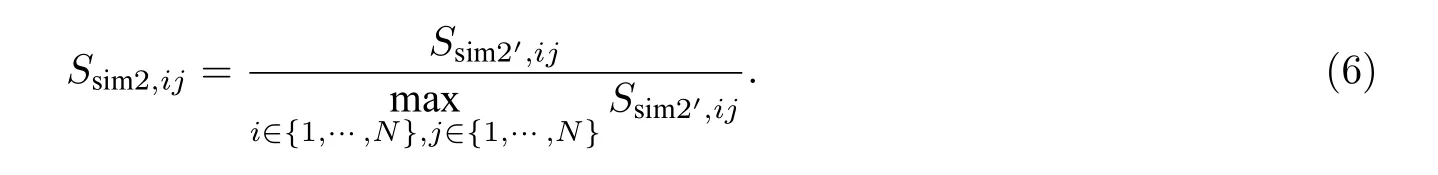
结合地理相似度和语义相似度,就可获得流向Fi和流向Fj之间的相似度Ssim,ij.其计算公式为
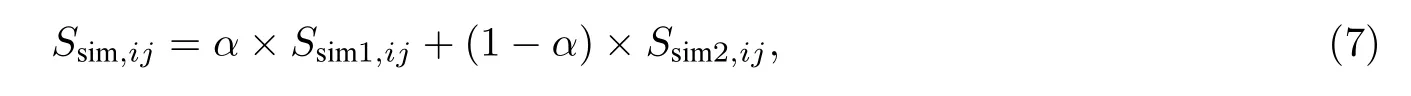
其中,α为超参数,表示不同相似度的权重,取值范围为(0,1).对于有同一条国道与高速公路经过的流向,其地理距离影响程度与交通不便地区相比更小,则α取值相应减小.α值视具体业务情况而定.
3.1.2 运力候选集计算
流向的运力候选集表示可运输该流向的所有运力的集合,不仅包括历史上运输过该流向的所有车辆,还包括潜在可能运输该流向的车辆.鉴于此,本文根据当前流向和相似流向的历史运力集的集合生成各流向的运力候选集,根据公式(7)计算流向间的相似度,选择与每个流向最相似的k个流向,则流向Fi的运力候选集XFi表示为

3.2 候选运力可达性预测
本节将结合各流向的运力候选集,通过特征提取,结合自注意力机制构建候选运力可达性预测模型,预测候选运力在预期时间内能否到达钢厂成为可用运力.候选运力可达性预测模型整体如图5所示.
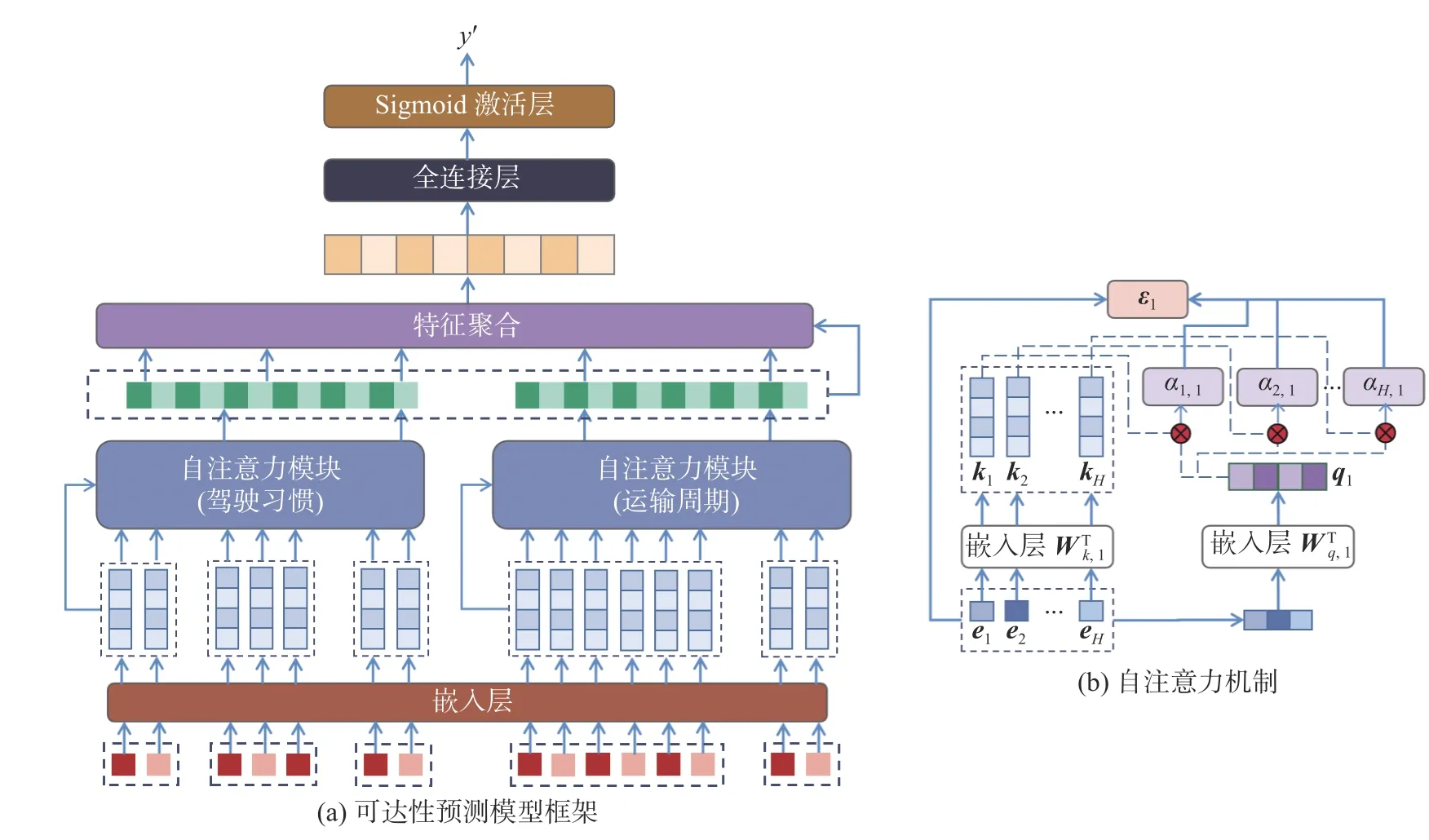
图5 候选运力可达性预测模型Fig.5 Candidate capacity accessibility forecasting model
3.2.1 特征提取
目前基于OD 的旅行时间预测方法普遍采用深度学习模型[3-5],从数据中提取丰富的特征是深度学习模型的关键步骤.本文从运单、轨迹等数据中提取多个特征,包括运力特征、流向客户特征、货物特征、时间特征和环境特征等,如表1 所示,随后对其建立高维特征映射.
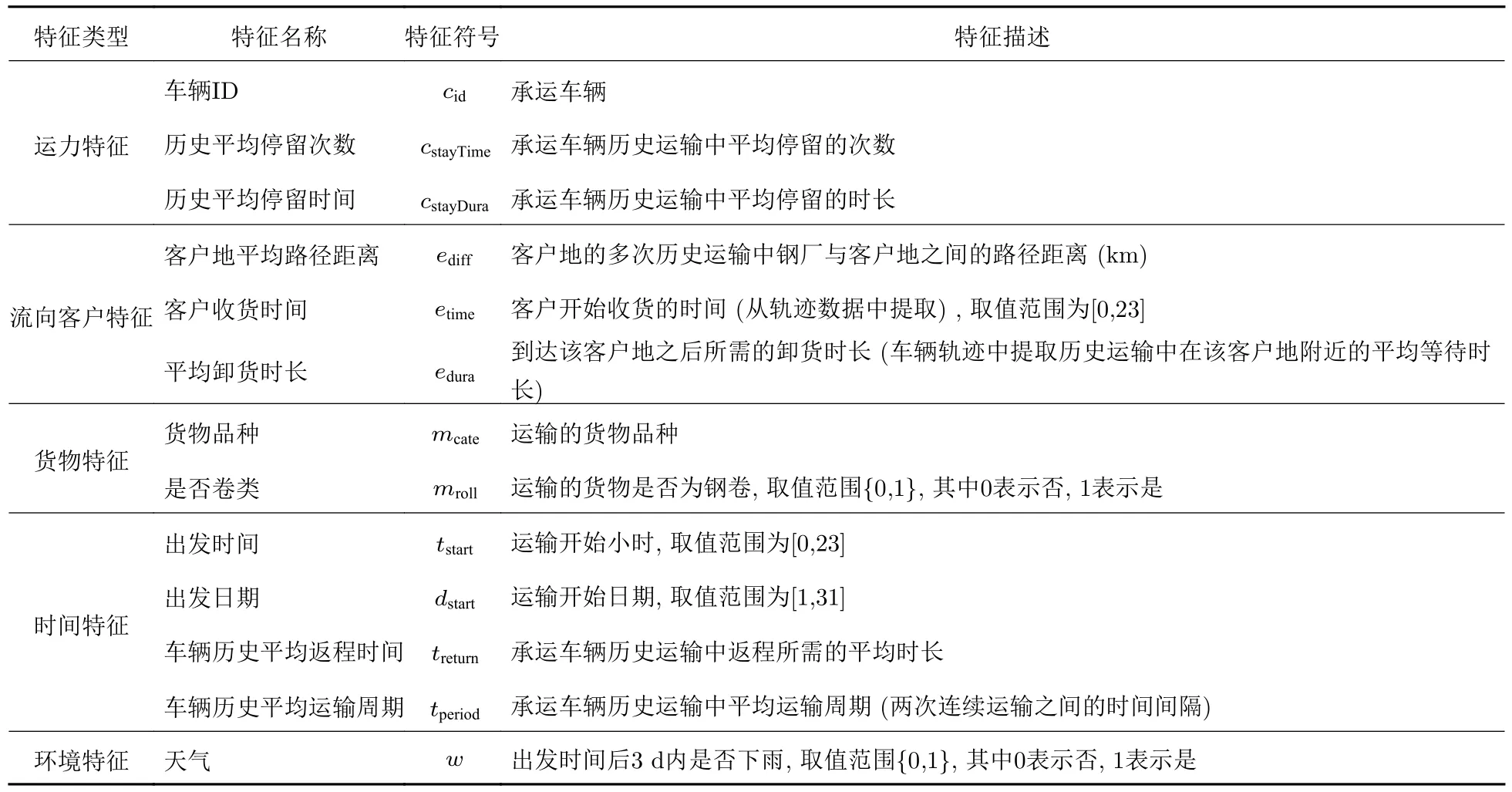
表1 特征描述Tab.1 Description of features
(1) 运力特征
货车司机的驾驶习惯影响车辆的行程时长.本文提取车辆的cid作为车辆特征,以历史平均停留次数cstayTime和停留时间cstayDura作为驾驶习惯特征.
(2) 流向客户特征
运力可达性与其执行运输任务的终点紧密相关.因此,本文根据客户目的地的历史运单和轨迹提取相关特征.车辆到达客户地的时间以及从客户地返回钢厂的行驶时间依赖于客户企业与钢厂之间的距离,故提取每个终点所在区县及该终点与钢厂之间的平均路径距离ediff作为特征;除此之外,不同客户的收货习惯 (工作时段) 不同、客户收货时间的早晚会影响货车将货物送达之前行程中的停留时间、客户企业的收货能力 (即卸货设备作业能力) 也会影响货车在送达之后等待卸货的时间.因此,本文提取客户的收货时段etime和历史平均卸货时长edura作为特征.历史卸货时长通过提取轨迹在客户地的停留时长得到.
(3) 货物特征
货车运输的货物品种影响运输的速度与到达目的地后的卸货时长.通过对历史数据的分析发现,运输钢卷类和钢管类货物的货车行驶速度比运输板材类货物的货车行驶速度慢.因此,本文提取货物品种mcate以及是否是卷类mroll作为货物特征.
(4) 时间特征
时间特征也是影响货车返回时间的一个重要因素.如果货车早上由钢厂出发,司机为了1 d 中能再运输1 趟,会尽可能早地返回钢厂;如果货车是在下午或者晚上出发,司机很可能选择在第二天返回钢厂.因此,本文提取运单的出发时间tstart、日期dstart、历史平均返程时间treturn、历史平均运输周期tperiod作为时间特征.
(5) 环境特征
提取其他可用信息作为环境特征,例如天气w.由于货车运输周期长,故本文的环境特征为出发之后近3 d 之内是否有阴雨天.
上述步骤提取的特征包括数值特征和ID 等类别特征 (高维的一元特征).本文将类别特征引入Embedding 嵌入层;同时,将稀疏的类别特征向量通过神经网络映射为固定长度的低维稠密向量,对该嵌入层不做单独训练,与整个神经网络同时训练.
3.2.2 自注意力机制(Self-Attention)
本文在模型中设计了2 个不同的注意力网络(ATT1 和ATT2),用于解决运输途中的停留时长不确定问题和因返程轨迹缺失而导致的返程时间不确定问题.
虽然由于司机个体的驾驶习惯不同,每个司机运输途中的停留时间难以确定,但在数据分析中仍可观察到各流向包含停留时间在内的总运输时长具备的时间与空间的相关性.如图6 所示,不同流向的货车返回时间相对于出发时间具有不同的模式.如山东省临沂市蒙阴县流向(图6(a)),随着出发时间越来越晚,货车的平均返回时间反而越来越短;而对于承载河东区流向的货车(图6(b)),凌晨出发的车辆会及时返回,下午出发的车辆返回所需时间均在6~ 8 h 之间.
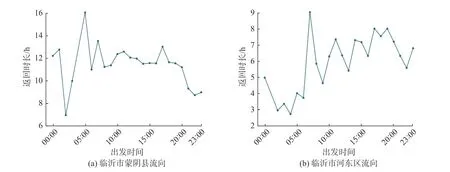
图6 不同终点与出发时间的相关性Fig.6 Correlation of transport duration with vehicle departure times for different delivery terminals
本文在模型中首先设计了1 个自注意力网络ATT1 用以捕捉运输途中的停留时长特征.该模块捕捉多个特征对不同司机驾驶习惯的作用,每个特征被分配1 个注意权重.本文设定,ei ∈RE表示第i个特征的E维嵌入向量,共H个特征向量;ej1∈RE表示显式反映司机驾驶习惯特征 (历史平均停留时长) 的第j个向量;每个特征向量对驾驶习惯的影响权重αi,1.先由第一个查询向量q1∈RH和索引向量k1∈RH点积得到原始分值Ssocre,i,1; 再对原始分值归一化处理.计算过程对应的公式为
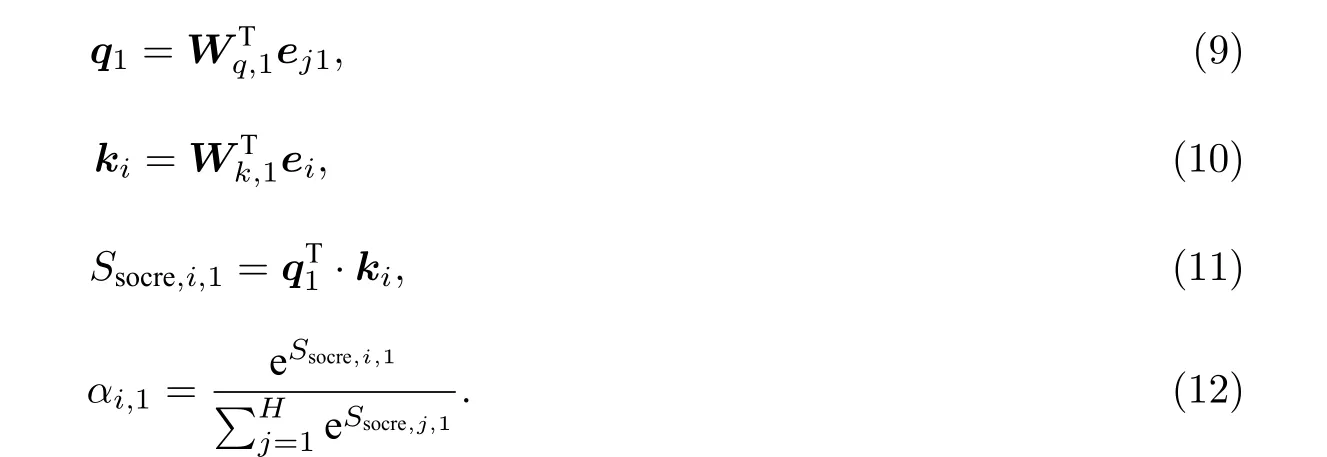
公式(10)—公式(11)中:Wq,1∈RE×H;Wk,1∈RE×H.如式公(9)—公式(11)所示,特征向量ei通过转换矩阵进行非线性变换转换到注意力空间,变换后的索引向量ki与查询向量q1进行点积,得到Ssocre,i,1,表示特征ei对ej1的重要性;再通过Softmax 函数归一化处理得到每个特征的权重αi,1(公式(12));然后通过公式

将所有特征向量按照权重合并为嵌入向量εi1∈RE,并将εi1输出至下一层网络,如图5(b)所示.
在使用上述注意力网络捕捉运输途中的停留时长特征之后,本文可以更准确地估计司机当前运输任务的运输完成时间,但仍需估计司机在运输完成后司机何时能返回并进行下一次运输.其中难点是由于返程司机自行联系货源、运输返程轨迹缺失导致返程时间不确定.此处引入对不同流向各司机的运输间隔周期特征 (此次运输结束时间至下次运输结束时间为一个运输间隔周期),并使用另一个注意力网络捕捉特征.
与ATT1 不同,第二个注意力网络 (ATT2) 用以捕捉影响司机返程的特征重要性.ATT2 中的查询向量q2∈RH,计算公式为

其中ej2∈RE为反映司机返程时间的特征 (包括运输间隔周期特征).ATT2 的输出表示为ε2.
本文使用的2 个自注意力机制各自使用共享的查询向量.与使用不同查询向量学习不同字段的特征相比,使用共享查询向量学习不同字段的特征有助于构建更健壮、更准确的选择准则,特别是对于具有稀疏特征的字段[16].
对由3.1节中计算得到的流向Fj的运力候选集XFj中的货车使用可达性模型预测,判定每辆候选
3.3 可用运力预测
可用运力预测旨在为可达运力集预测每个可达运力选择运输的流向.3.2 节中预测出流向Fj可达运力集合Vj={c1,c2,···,cl},ci表示1 个可达货车i.对于这些可达货车,由于每一辆货车并非只是1 个流向的固定运力,当司机熟悉的流向缺少待发货源或价格下降等情况发生时,司机可能会根据车队需要选择运输其他相似流向.在本阶段根据可达运力的历史运输流向,采用LSTM 模型预测每个可达运力下次选择的运输流向,获得各流向的可用运力列表.
LSTM 是传统循环神经网络 (RNN) 的变体,可以处理时序的长期依赖问题[17],适用于货车司机根据自身运输经验和车队需要选择运输流向的场景.1 个LSTM 模块主要由输入门、输出门、遗忘门等组成.LSTM 模型预测可达运力流向选择过程如图7(a)所示,每个LSTM 单元结构如图7(b)所示.

图7 LSTM 模型结构示意Fig.7 LSTM structure
该LSTM 的训练过程: 对于每个可达运力ci,其历史流序列为 [fflow,1,fflow,2,···,fflow,t],fflow,k表示ci的1 次历史运输任务对应的流向,对其进行独热编码生成输入序列[fflow_embed,1,fflow_embed,2,···,fflow_embed,t],每个LSTM 单元隐藏层状态为 [h1,h2,···,ht],则每个单元的更新公式为

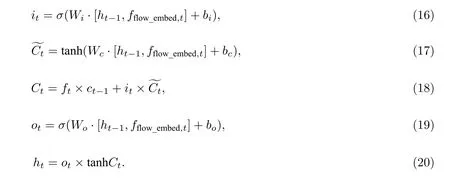
公式(15)—公式(20)中:ft为遗忘门决定前一时刻的状态Ct-1有多少信息被保留,一般而言,对于车队固定运力该值较小,而对于个人流动运力该值较大;it为输入门决定输入xt有多少信息被输入,该部分输入货车司机近几次的历史运输流向;ot为输出门决定要输出当前状态Ct中的多少信息,即决定本次运输流向及近期运输模式有多大程度上可代表司机的长期运输习惯;σ为Sigmoid 激活函数;表示单元更新值.
随后,计算每个可达运力选择的运输流向,进而获得每个流向在t+1 时间段的可用运力列表
算法1 给出了本文所提运力预测模型的执行过程: 首先,基于历史运单集,根据相似性计算公式(公式(6))得到流向之间的相似度矩阵A,则流向运力候选集X为最相似的k个流向历史运输车辆集合;然后,对候选运力中的每个运力分别提取特征ri,通过嵌入层将高维特征映射为低维稠密向量ei,通过两层自注意力机制分别捕捉影响司机驾驶习惯和运输周期的特征,得到融合特征向量ε1、ε2,再将其聚合输入多层感知机(Multilayer Perceptron,MLP)训练,获得该运力的可达性{0,1},从而得到流向Fj的可达运力集合Vj;最后,将每个可达运力的历史承运流向序列输入LSTM 模型中获得每个可达运力选择的流向,从而产生每个流向Fj的可用运力集


4 实 验
本文在真实数据集上进行了一系列实验,对所提出的技术方案的有效性进行了评估.本文所用数据集来自山东某钢铁物流企业的真实数据集,包含了2021 年11 月至2022 年2 月共4 个月320 499 条运单数据及其对应的轨迹数据、车辆数据和终点数据,其中训练数据的时段为2021 年11 月至2022 年1 月 (共3 个月).为构建训练集,本文将每个训练日的时间按 1 个/2 h 时间片进行划分,预测后续时间片 (可选) 的流向可用运力集合.因此,本文共有3 909 446 个训练项.
4.1 评价指标
本文采用混淆矩阵评价运力预测模型的有效性,混淆矩阵包括了样本的实际标签与模型预测标签之间的关系.
总样本数为N;对于每个样本xi,预测值yi={0,1}表示可用运力i在预测时间片是否会选择该流向;样本真实值ti={0,1}表示运力i在预测时间片是否真实到达钢厂并运输了该流向.评价指标如下.
(1) 准确率
准确率(Accuracy,A)表示预测正确的样本比例.其计算公式为
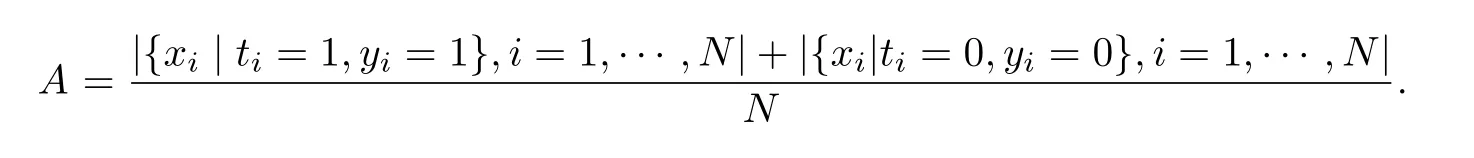
(2) 精确率
精确率(Precision,P)表示预测为可用的运力中真实运输该流向的运力占比.其计算公式为
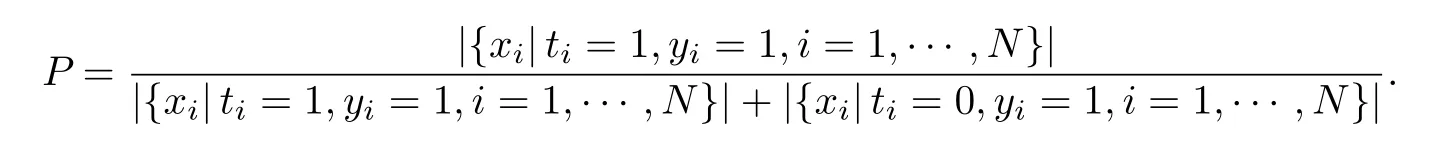
(3) 召回率
召回率(Recall,R)表示在预期时间真实运输该流向的运力中预测正确的运力占比.其计算公式为
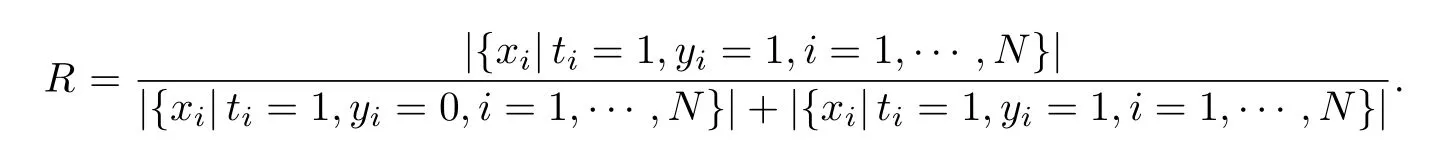
(4)F1分数
F1分数(F1-score)表示精确率和召回率的调和平均值,综合了精确率和召回率.F1-score 的取值范围为[0,1],其值越接近1 表示模型预测效果越好,而越接近0 表示模型效果越差.其计算公式为

4.2 可达性预测模型实验结果
可达性预测模型对本文中的运力预测结果起决定性作用,若可达性预测模型效果不理想,则运力预测结果必然更差.因此,先对可达性预测模型的有效性进行评估.由于没有相关工作预测车辆在预期时间是否可达,本文对几种基于OD 的旅行时间预测模型的输出进行修改以适应钢铁物流的预测场景,具体地,通过比较行程的出发时间加上模型输出的旅行时间是否早于预期时间,达到可达性预测的目的.以下是本文选择的几种用于评估可达性预测的模型.
(1)历史平均 (History Average,HA)[18]
历史平均是指旅行时间为该终点历史记录的平均值.
(2)线性回归(Linear Regression,LR)[4]
线性回归是指将返回时间视为钢厂与终点之间的距离L 的函数,训练一个简单的线性回归模型作为基线模型.
(3)随机森林 (Random Forest,RF)[19]
随机森林是1 个集成学习模型,将司机、终点、客户、出发时间作为输入,训练1 个随机森林模型;
(4)基于最近邻的方法(Temporally Weighted Neighbors,TEMP)[5]
基于最近邻的方法利用所有具有相似起点和目的地的历史行程的加权平均旅行时间估计本次的旅行时间,每个相邻行程的权重为相邻行程与预测行程平均速度的相似性.
(5)本文所提出的可达性预测模型(Proposed Method,简称Proposed)
本文所提出的可达性预测模型考虑了司机驾驶习惯和货物、流向等偏好,来预测每个候选运力的可达性.
本文用于评估可达性预测模型的性能指标如4.1 节所述.图8—图11 分别展示了几种模型在数据集上的准确率(A)、精准率(P)、召回率(R)、F1分数(F1-score)的对比.
由实验结果可以看出,每个模型的准确率(A)都比其他几个评价指标高.这是因为准确率表示分类预测正确的比例.在本文中,由于司机运输周期长,在预测时间片之前若货车的上1 个运单未结束,则货车不可达,每个运单在多个时间片的可达性均为0,数据整体负样本比例较大,所以准确率相对其他指标较高.
从图8—图11 中可以看出,使用简单平均的方法也会有相对较准确的结果.出乎意料的是,对线性回归(LR)和随机森林(RF)这2 个模型增加司机和终点距离等特征后,各个指标相对于简单平均都有所下降.这表明同一终点、同一司机的行驶习惯也是差异化的,如果只是简单地使用1 种模式预测效果反而更差.与简单平均类似,同样也是将历史行程返回时长的平均值作为预测行程返回时长的TEMP,利用行程速度定义了不同行程之间的相似度,根据行程之间的相似度加权平均历史行程的返回时间,提升了TEMP 方法的预测性能.TEMP 为多个对比实验中精确率和召回率均较高的模型.
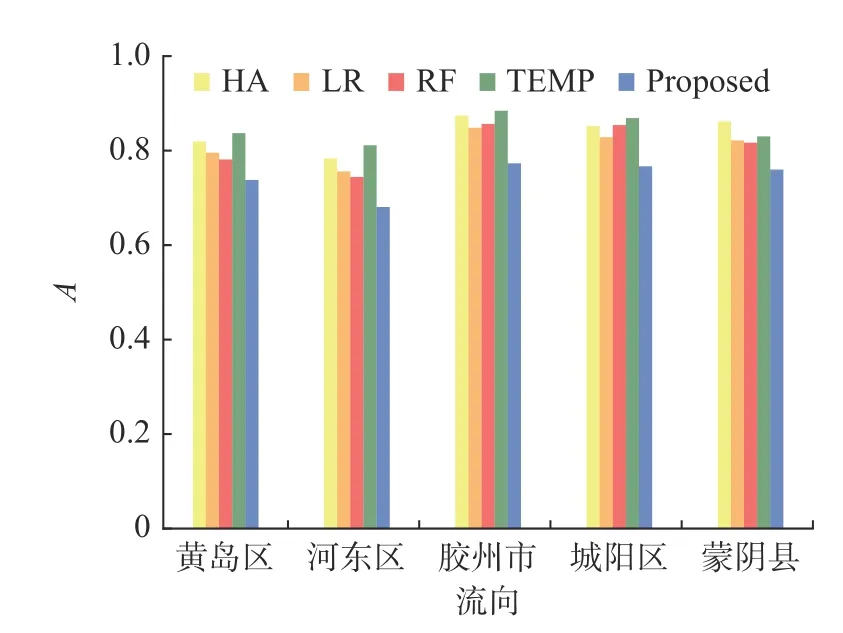
图8 不同流向的准确率 (A) 比较Fig.8 Accuracy comparison of multiple accessibility prediction methods for different flows
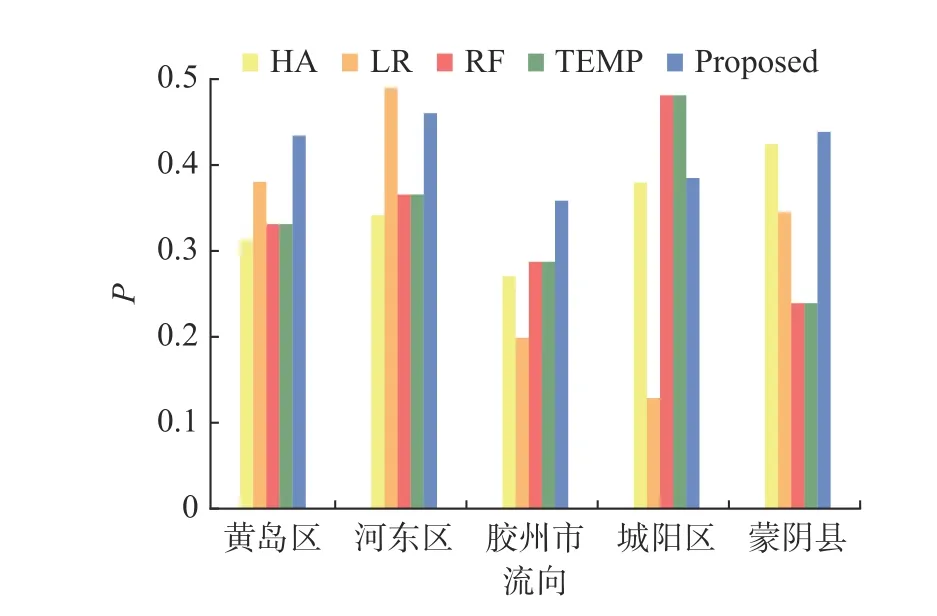
图9 不同流向的精确率 (P) 比较Fig.9 Precision comparison of multiple accessibility prediction methods for different flows

图10 不同流向的召回率 (R) 比较Fig.10 Recall comparison of multiple accessibility prediction methods for different flows
本文所提出的方法(Proposed)虽然准确率没有提升,但是精确率和召回率都相对其他模型有了明显上升.由图11 可以看出,尤其是黄岛区、胶州市、城阳区这3 个流向,本文提出的模型对预测精度的提升最为明显.F1-score 为精确率和召回率的调和平均值,可以反映出模型的整体性能,这表明本文所提出的可达性预测模型是有效的.

图11 不同流向的F1-score 比较Fig.11 F1-score comparison of multiple accessibility prediction methods for different flows
4.3 不同属性的特征有效性
本节中验证了不同属性特征的有效性,包括车辆特征、货物特征、终点特征、时间特征、环境特征.为此本文基于上述的数据集设计了1 组对比试验,每个实验剔除其中一种属性的特征.如表2 所示,根据实验结果发现,车辆特征和货物特征对预测效果有显著的影响,消除这两个属性会使得F1-score 指标分别下降43%和20%.这与本文前述挑战相符合,货车运输行驶时间与网约车行驶时间预测中不同,网约车所在的城市路网场景中,其他条件不变时,不同的司机不会导致行驶时间有较大差异,大多数出租车网约车司机都很有经验,对有限的路网非常熟悉,有相似的驾驶习惯[20],而钢铁物流中,由于运输时间长,路途遥远,司机对路线和整个路网的熟悉程度不同,因此不同的司机驾驶习惯不尽相同,所以在此场景下,针对司机进行个性化的返程预测非常重要.

表2 不同属性特征的重要性分析Tab.2 Effect of attribute component on the accessibility prediction
4.4 可用运力预测模型实验结果
本文将基于可达运力集的可用运力预测视为时间序列预测问题,即根据可达运力的历史运输流向预测每个可达运力在预期时间的承运流向.本文选择以下几种模型进行对比.
(1)直接法 (Direct)
直接法认为货车司机倾向于选择历史运输最多的流向.
(2)k-近邻 (k-Nearest Neighbors,kNN)[21]
k-近邻认为如果1 个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别.找到训练集样本空间中的k个距离预测样本x最近的点,统计k个距离最近的点的类别,找出个数最多的类别,将x归入该类别.
(3)朴素贝叶斯 (Naive Bayes,NB)[22]
朴素贝叶斯是一种基于贝叶斯定理与特征条件独立假设的分类方法.对于给定的训练数据集,首先基于特征条件独立假设学习输入/输出的联合概率分布;然后基于此模型,对给定的输入x,利用贝叶斯定理求出后验概率最大的输出y.
(4)梯度提升决策树 (Gradient Boosting Decision Tree,GBDT)[23]
梯度提升决策树是以CART 决策树作为基学习器的boosting 集成学习算法,其中每一棵决策回归树学习的是之前所有树的结论和残差,通过拟合得到1 个当前的残差回归树,其最终预测值等于所有回归树预测值之和.
(5)随机森林 (Random Forest,RF)[19]
随机森林是以决策树为基学习器的bagging 集成学习算法,集成学习的核心思想就是将若干个弱(基) 分类器组合起来,得到1 个分类性能显著优越的强分类器.
(6) ARIMA (Auto-Regressive Integrated Moving Average)模型[24]
ARIMA 模型将非平稳时间序列转化为平稳时间序列,根据差分后的平稳序列建模预测.
(7) 长短期记忆网络(LSTM)[7]
LSTM 是时间循环神经网络,为解决一般的循环神经网络存在的长期依赖问题而提出,是具有长短期记忆能力的神经网络.
除直接法外,其他方法预测时均考虑了有运输需求流向的库存和价格信息.选择准确率(A)作为评价指标,若预测的可达运力倾向流向与司机实际选择的流向相同,则认为预测正确,否则预测错误.具体实验对比结果见图12.由图12 可以发现,LSTM 模型的准确率(A)最高.尽管ARIMA 模型也是一种时序预测模型,但ARIMA 模型预测要求时间序列数据是稳定的,且本质上只能捕捉到线性关系,对于不稳定数据ARIMA 模型无法有效捕捉规律.本文的预测序列为历史承运流向序列,会受到当时的价格及车队需求影响.使用ARIMA 模型的预测效果较差;LSTM 模型不仅可以捕捉到短期内价格等因素变化的影响,也可以捕捉到长期序列中司机对流向的偏好.因此,LSTM 模型预测效果最佳.

图12 可用运力预测模型效果对比Fig.12 Accuracy comparison of multiple available capacity prediction models
本文所提出的三阶段运力预测方法已成功应用并部署于山东省某钢铁企业的在线物流平台,可支持山东省内共136 个流向的运力预测,用于平台上6 000 余辆注册货车的运力调度.
5 结 论
本文针对钢铁物流的运力调度决策提出了一种三阶段的运力预测模型,包括运力候选集生成、候选运力可达性预测与流向可用运力预测等.基于运单、车辆、运输终点与车辆轨迹等数据,提取影响运输任务执行时间与返程时长的重要特征,通过引入双层自注意力机制获取不同特征的影响权重,有效解决了长距离运输过程中的停留时长不确定与返程轨迹缺失的问题.基于真实数据集上的对比实验验证了本文所提方法的有效性.在未来的研究中,会结合车辆的实时位置以及钢厂所在地的交通状况进一步提升运力预测精度.
猜你喜欢
幼儿画刊(2023年12期)2024-01-15 07:06:14
井冈教育(2020年6期)2020-12-14 03:04:42
能源(2017年12期)2018-01-31 01:43:03
中国交通信息化(2017年8期)2017-06-06 07:16:31
学与玩(2017年6期)2017-02-16 07:07:24
股市动态分析(2016年3期)2016-09-27 16:31:48
专用汽车(2016年9期)2016-03-01 04:16:52
中国卫生(2015年7期)2015-11-08 11:09:44
航空知识(2015年6期)2015-07-13 16:51:12
鸭绿江(2013年11期)2013-03-11 19:42:04
