
基于多维特征表示的文本语义匹配
2022-09-26 13:06黄定江
华东师范大学学报(自然科学版) 2022年5期
王 明,李 特,黄定江
(华东师范大学 数据科学与工程学院,上海 200062)
0 引 言
文本语义匹配是指给定两个文本,可能是短语、句子,也可能是段落、文档,判定其表达的语义是否相同.文本语义匹配是自然语言处理中一个关键任务[1].在自然语言处理领域中,许多落地运用的算法基础都是文本语义相似度匹配.例如社交媒体热点话题的挖掘,同一时间社交媒体上会有大量用户发布非结构化文本,依据不同的话题对这些海量文本进行分类,其本质就是对这些海量文本进行语义匹配;在问答系统中,通常会在数据库中保存大量常被查询的问题及答案,当有用户在系统中提问时,可以根据现有问题,将匹配的答案直接输出给用户,其本质上也是文本语义相似度匹配;同样,在搜索引擎和文本查重系统中,也都是通过文本语义匹配去检索相关文本.由此可见,对文本语义匹配进行深入研究,提高文本语义匹配的准确率和效率,是十分有必要的.
在文本语义匹配任务中的一个难点是文本中每一个词包含的信息量不均匀,信息特征可能集中在某些词中,如文本中出现的停用词,即“的”“地”等出现频率较高的词,并不含有太多的语义信息.当需要匹配的问句为“文本语义匹配如何学习”与“如何学习文本语义匹配”时,通过词汇的比较很容易匹配.但是文本匹配不是简单的文本词汇的比较.由于语言的博大精深,很可能词汇完全不相同的文本的语义是相同的,例如,“厕所在哪里?”与“去洗手间怎么走?”.并且文本的一个微小改变就可以改变文本的语义,例如,“黑上衣配什么裤子”与“黑裤子配什么上衣”只是调换了词汇顺序,已经是含义表达不相同的文本了.又如,“我喜欢吃蔬菜”与“我不喜欢吃蔬菜”之间仅仅相差一个字,但语义完全不同.因此,文本语义匹配的任务要求不只是获取文本的词汇信息,而是要从词汇、句法结构、语义表达等多维度进行文本匹配.
除此之外,提高文本语义匹配的效率也是该任务需要解决的难点之一.自从OpenAI 提出GPT[2]及Google 提出BERT[3]模型以来,自然语言处理的发展到了大模型预训练的阶段.通过海量的文本语料训练出来的语言模型,在各个自然语言处理任务上,都取得了优异成绩,自然文本语义匹配任务也不例外.在使用预训练模型时,通常认为将文本输入到模型中即可获取含有语义的句向量.事实上,Devlin 等[4]就指出,通过预训练模型得到的文本向量表示并不具有语义特性,即相似的文本的表示向量在映射空间中并不会更加靠近,所使用的通过多层全连接网络输出判定结点的任务,其本质并非根据语义相似度进行判定.此外,预训练模型在进行判定时要求两个文本同时输入到模型中.这意味着每一次的判定都需要重新提取文本的特征,这将会付出高昂的时间成本,在实际运用的场景中是无法接受的.
综上所述,文本语义匹配需要平衡匹配的准确率和效率才能真正投入使用.为解决上述问题,本文提出了基于自注意力机制的孪生网络,避免重复计算文本特征,以此提高效率.此外,通过提取具有多维度语义信息的文本特征进行文本匹配,以提升匹配的准确率.
1 相关工作
文本语义匹配的模型框架,简单来说,可以分成两部分: 文本特征表示和文本相似度的度量.
文本相似度的度量方式主要分为两种: 一种是在无监督情况下,利用各种距离的计算方式,如余弦距离、欧式距离、杰卡德距离等,计算文本表示向量之间的距离,以此表示其相似程度;另一种是在有监督情况下,通过模型去预测其匹配的标签,例如,神经网络模型映射成一个结点值,根据结点值判断是否匹配.
早期文本特征表示主要提取文本中的词汇信息,如由Salton[5]提出的向量空间模型,将文本分割成不同的词汇,使用TF-IDF 权重分配方式给不同的词汇分配不同的权重,从而将文本向量化,通过向量比较文本的相似度.后来又有大量工作对该方法进行改进,以便更准确地筛选相似文本,其优点是易于实现、效率高,但缺点也很明显,统计词汇无法真正地表示文本的语义信息.自然语言的词汇含义丰富,在不同语境下表示的含义可能存在较大差异,故这种方法的准确率不高.此后,WordNet[6]、《同义词词林》等语义词典被提出,很多模型利用语义词典获取文本的语义表示.例如,Kolte 等[7]利用WordNet[6]消除一些含有歧义的词汇,从而更精准地表示文本信息.利用语义词典,在一定程度上获取了文本语义,提高了匹配的准确率;但自然语句相对比较自由,且会随着时代不断更迭变化,因此,构建语义的成本巨大,很难构建一个不同背景下的语义词典.随着神经网络的发展,研究者开始利用神经网络提取文本的语义特征.2013 年,Google 提出了Word2Vec[8]模型,采用Skip-gram 和CBOW 两种模型,根据上下文语义信息推出词汇的分布式表示.在分布式词向量表示的基础上,出现更多神经网络模型进一步提取文本的语义特征.这些神经网络模型大致可以分成两种框架类型,一种是表征学习型,另一种是交互型.表征学习型模型通过CNN (Convolution Neural Network)[9]、LSTM(Long Short Term Memory Networks)[10]、GRU (Gate Recurrent Unit)[11]等深度神经网络,分别提取两个文本的语义信息,再进行文本语义匹配计算.例如,SiamGRU[12]利用共享GRU 网络提取两段文本的特征,根据特征向量判断其是否匹配,在提取特征向量的过程中,两段文本不发生语义的交互.交互型模型是指两段文本同时输入同一个模型中,利用注意力机制进行两段文本的信息交互,并聚合成一个特征向量,通过值映射的方式获取短文本的相似度值,而不需要进行文本特征相似度的度量,如ESIM[13]、BiMPM[14].基于表征学习的模型相对简单,更容易训练,且提取一次文本特征可以重复利用,效率更高.但与交互型模型相比,基于表征学习的模型缺少交互特性,无法捕捉到两者相互影响的信息.交互型模型能更有效地提取交互信息,进行特征融合,准确率更高;但对于同一文本需要反复提取不同配对下的特征,所以效率低下.自GPT[2]和BERT[3]等模型问世以来,预训练模型得以发展,其基于Transformer[15]框架,利用海量语料进行预训练,能够更好地提取文本的语义信息.其本质也是交互型模型,更能提取隐藏的交互信息,故进一步提升了文本匹配的准确率,对设备也提出了更高的要求.
提高文本语义匹配的性能需要更精确地提取文本的语义信息.此外,在构建文本匹配模型时,需要权衡模型的准确率和匹配效率,从而提高模型应用的价值.
2 模型介绍
正如Reimers[4]提出的那样,如果数据库中有 1000 对文本需要通过语义匹配找出语义相似的文本,采用交互型模型需要计算 1000×999/2 次文本的特征向量,而采用表征学习的模型只需要进行1 000次计算,具有更高的效率.在问答搜索的场景下对效率的要求是极高的,因此,本文所构建的是基于表征学习的短文本匹配模型,总的模型架构如图1 所示.
本文所构建的模型采用孪生网络框架,即在训练过程中,需要匹配的两个文本分别输入到两个架构完全相同的特征编码器中,其参数是共享的,本质上是同一个特征编码器.基于自注意力机制的预训练模型在自然语言处理方面取得了极大的成就,如BERT[3]、GPT[2]等,因此,本文采用基于自注意力机制的中文预训练模型ERINE[16]作为文本特征编码器.由图1 可知,文本特征编码器通过处理输入的文本,可以获得1 层词嵌入表示及12 个不同的特征表示,进一步提取特征得到语义特征v.在此基础上,通过设计基于注意力机制的特征融合模块,分别提取文本词汇、句法、语义等不同维度的特征.最后,设计基于递归神经结构的特征抽取模块抽取基于浅层词汇及深层语义文本特征表示,得到融合多维语义特征a.接下来,对模型的结构进行详细介绍.

图1 模型架构图Fig.1 Model architecture
2.1 句子特征表示
2.1.1 多维特征提取
本文模型采用百度提出的预训练模型ERINE[16]作为文本特征编码器.ERINE[16]模型是以Transformer[15]框架为基础,主要有1 层嵌入层和12 层编码层.嵌入层将字符向量化,是文本字符的数字化表示.每一个编码层主要包括两个部分: 自注意力层和Feed Forward Neural Network (FFN)层.
注意力机制的目的是从一系列相关背景信息中提取最感兴趣也是最相关的部分.
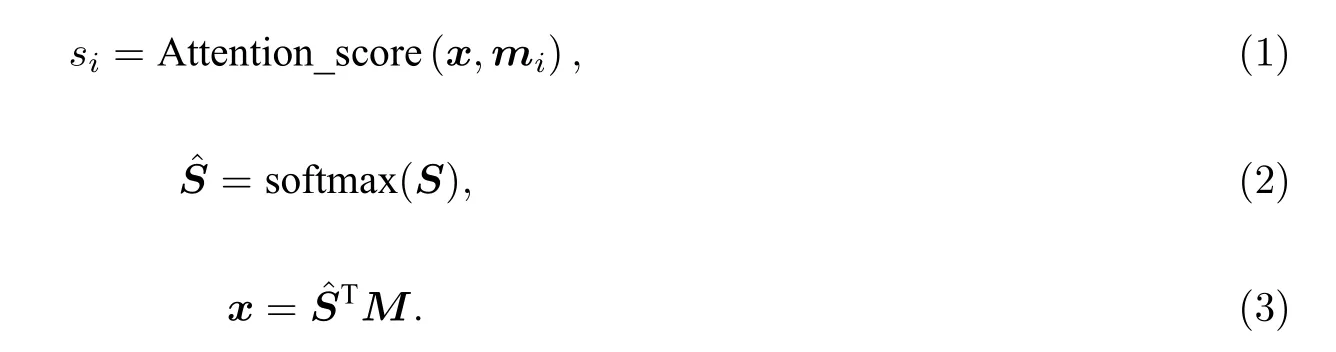
式 (1)—(3) 中: 注意力机制的计算主要分为3 个部分,首先计算所求向量x与背景信息M中第i个背景信息mi的相似度得分si,然后对所有相似度得分S进行归一化处理,得到,最后对背景信息M加权求和,得到特征向量x的重新表示.自注意力机制是注意力机制中的一种形式,即特征向量x本身也是背景信息M中的组成部分.
在ERINE[16]的编码层中使用的就是自注意力机制.输入编码层的文本编码为P,经过线性层的映射得到K,Q,V,通过Q与KT矩阵相乘,并经过K中列向量维度大小dk的放缩,得到文本编码中每一个字符与所有字符的注意力得分,最后自注意力加权,得到一个获取上下语义信息的.

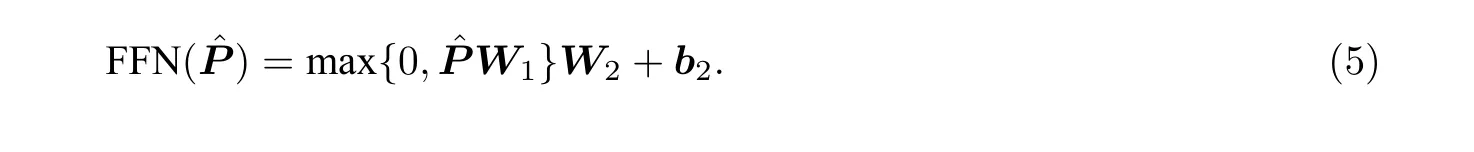
最后使用残差结构关联到输入特征,得到文本特征的新的表示.在ERINE[16]模型中共有12 个这样的编码层,所以可以得到12 个不同的文本特征表示.
Jawahar 等[17]以BERT[3]模型为对象,深入探索了该类预训练模型不同编码层捕捉到的文本语言特征.通过设计3 类任务,即表层任务、句法任务、语义任务,最终可以发现,该类预训练模型在底层网络中可以学习到文本中短语级别的结构信息,在中层网络中可以学习到文本的句法信息,而在高层网络中可以学习文本的高层语义信息.
在编码文本特征时,孪生网络无法通过文本对的交互而取舍文本的某些语义特征,故需要提取多维度细粒度的文本特征.基于Jawahar[17]的研究,将12 层的文本特征划分为3 个层次,分别提取文本的词汇特征、句法特征和高层语义特征,并设计基于注意力机制的特征融合模块,融合层次内特征向量.
本文在模型中设置特征融合模块,目的是将ERINE[16]模型中每一层提取的特征融合为一个特征向量,得到整体文本的语义表示,如下所示:

式 (6)—(7) 中:Z表示ERINE[16]所有的特征输出,Zi表示第i层编码层输出的特征.在特征融合模块中,文本特征Zi通过一个仿射变换和一个非线性映射层分别得到vi,ki.
使用线性映射得到vi,进一步提取第i层特征向量Zi的特征信息,通过非线性 sigmoid函数得到ki,其每一维度值压缩到 [0,1] ,表示向量vi相对应维度特征与语义表示的相关程度,接下来由vi,ki的内积值得到该层文本特征Zi的注意力机制得分:

最后通过归一化后的注意力机制得分,融合语义特征Zi,得到该层次特征的最终表示.

式 (9) 中:Y={y1,y2,y3}表示从ERINE[16]编码器中获取的文本特征经过特征融合模块得到的融合特征,其中y1融合了前三层特征,提取文本的词汇特征;y2融合了中间三层特征,提取文本的句法特征;y3融合了后三层特征,提取文本的高层语义特征.
2.1.2 语义特征表示
本文发现基于Transformer[15]架构的模型做语义相似度匹配时,最后一层特征向量对应的是文本中每个词的词向量,即使包含了上下文信息,但通过词向量的直接融合得到的文本向量很难表达完整的语义信息.通过分析实验样本数据,发现一旦配对文本的重合度较高,使用词向量融合的模型几乎都会打出很高的匹配分数.例如,样本中出现的“梦见自己生病”与“梦见自己生病死了”,“妈妈再爱我一次”与“妈妈再打我一次”都得到极高的匹配分数,第一个样本的匹配分数达到了0.96.从而进一步发现,当匹配文本只有微小变化时,匹配句子会有较高得分,但是当微小变化发生的位置不同时,则影响程度差异较大.当发生在边缘位置时,如第一个样本,更容易被忽视;而发生在中间位置,如第二个样本,得分就会降低较多,只有0.83.因此,本文猜测位置信息会较大地影响模型语义信息提取,通过分析错误样例和调换句子顺序构建新的测试样例.本文发现位置信息的确在较大程度上影响了打分,容易导致错误分类.这种情况对于交互型模型来说,甚至是优点,因为能促使模型关注到匹配文本存在差异的地方,更容易得到正确的分类.由于自然语言本身的特性,重点信息出现的位置具有很大的不确定性,因此,对于表征型模型来说,在匹配文本未知的情况下,获取完整的文本语义信息非常关键.
为了解决这个问题,我们在模型中提出特征抽取模块,分别利用模型的嵌入层和最后一层CLS(在下游任务中通常使用CLS 特征向量处理需要文本语义任务)对应的特征向量,自上而下及自下而上地筛选,并提取文本不同层次的特征.
嵌入层是文本字符简单的数字化表示,从中抽取的文本表示给予每个字符的关注度是相对均匀的,不包含偏见.因此,本文利用嵌入层特征向量e,不断向下提取相对均衡的文本特征,受到LSTM[9]模型的启发,采用门控信号来控制向下过程中信息的提取.
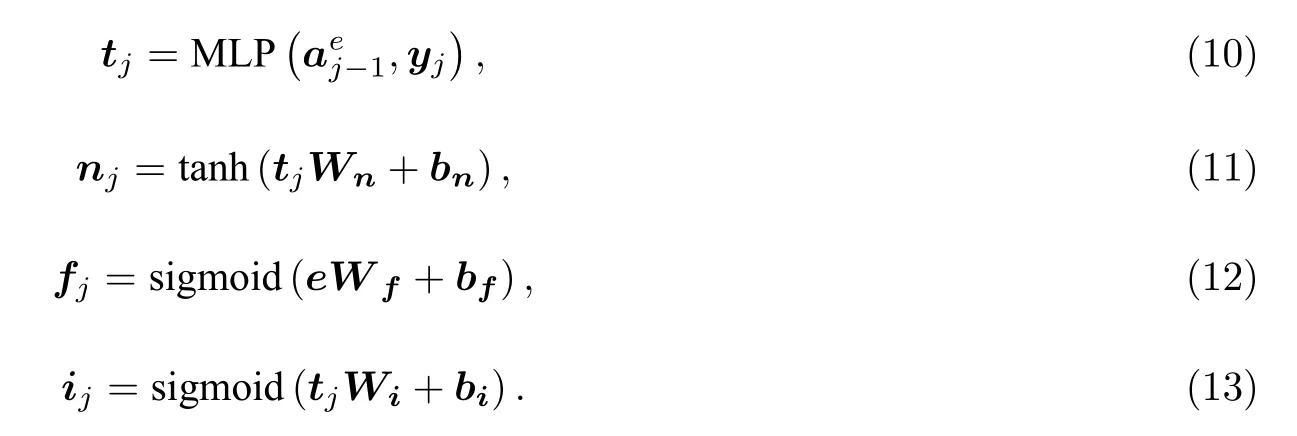
拼接当前层特征及前一步层处理后的特征,再经过多层感知机得到维度不变的融合特征tj,最后通过映射嵌入层特征向量e和融合特征分别得到遗忘门控信号fj和信息提取控制信号ij.

式 (14) 中:⊙表示元素逐个相乘.最终通过门控信号筛选信息,得到在该层的文本语义表示,通过这种方式依次提取Y={y1,y2,y3}的信息.
通过CLS 对应的语义特征c提取不同层信息的方式相同,如下所示:

通过拼接向量ae、ac得到最终文本句向量a,包含多维语义特征.
2.2 模型训练策略
2.2.1 适应领域的预训练(Masked Language Modeling,MLM)
自然场景下的问答有许多口语化的词汇,更贴近生活.涉及不同业务的问题也需要领域知识才能更好地获取文本语义.本文模型实验的数据集包含金融领域的相关数据和百度知道收集的问答.实验在这些数据集上进行了预训练任务.使用的预训任务是MLM,是由Devlin 等[3]在训练BERT 时提出的.MLM 与Language Modeling (LM)相比,区别在于MLM 可以获取上下文信息,改善传统单向模型的缺点.本文实验预训练设置,与BERT 模型一致,字符以15%的概率被随机掩盖,需要模型对该字符进行预测.通过预训练任务,模型可以更好地理解一些特定的词汇含义,如“借贷”“借款”“开通”“投资”等专业领域词汇.
2.2.2 句向量的语义约束
孪生网络做文本语义匹配的关键点是获得一个充分获取文本语义信息的句向量.受到Grill 等[18]在BYOL 工作中的启发,理论上,如果两个文本是由同一个文本通过某种数据增广方式得来,其所获得的文本特征向量是相近的,那么一个语义特征就应该具备预测另一个语义特征的能力.同样地,如果两个文本表达的语义相同,一个文本应当也具有预测另一个文本语义特征的能力.因此,在本文模型训练的过程中,增加了获取更好语义特征的约束.预测的方式为

式 (20) 中:a,u表示配对文本分别提取的语义特征,增加一个预测的损失函数,在得到文本对的特征向量a,u之后,分别经过一个线性映射gθ2.使用a去预测向量u时,a经过一个线性映射Pθ1去计算与u映射之后向量的均方误差值.在训练过程中不断优化这个损失函数,从而获得具备更好语义特征的句向量.
2.2.3 文本语义匹配判定: 余弦相似度
本文模型的训练过程中,使用余弦相似度作为判定两个文本语义是否匹配的依据.

当两个文本匹配时,其距离较小,不匹配时距离较大,这也符合人们的直观理解.在训练过程中使用均方误差函数去优化余弦相似度.
3 实 验
3.1 数据集介绍
本文实验所使用的数据集为百度千言语义相似度竞赛中所使用的数据集.该数据集包含以下3 个公开的数据集.
(1) LCQMC (a Large-scale Chinese Question Matching Corpus)[19].该数据集是从百度知道社区不同领域的用户问题中抽取的真实问题数据构建的,训练集有238 766 个文本对,验证集有8 802 个文本对,测试集有12 500 个文本对.
(2) BQ Corpus (Bank Question Corpus)[20].这是从线上银行系统日志里抽取的问题对,是银行金融领域的问题匹配数据.训练集有100 000 个文本对,验证集有1 000 个文本对,测试集有10 000 个文本对.
(3) PAWS-X (中文).PAWS (Paraphrase Adversaries from Word Scrambling)[21]是谷歌发布的包含 7 种语言释义对的数据集,包括PAWS (英语) 与 PAWS-X (多语).数据集里的样本特点是文本对重合度高,仅具有微小差别.训练集有49 401 个文本对,验证集有2 000 个文本对,测试集有2 000 个文本对.
3.2 实验设置
本文所有的实验是在3 个NVIDIA Tesla V100 GPU 上并行完成,256 GB 内存,32 GB 显存.编程语言为Python,所采用的深度学习框架为PyTorch.训练过程中设置文本的最长长度为100,优化函数为RAdam,学习率设为2.0 × 10–5,batch size 设为32.余弦相似度判为匹配的阈值为0.7.
模型的评价指标为准确率:

式 (22) 中:A表示准确率,NTP表示将正类预测为正类,NTN表示将负类预测为负类,NFP表示将正类预测为负类,NFN将负类预测为正类.
3.3 结果分析
3.3.1 消融实验
在上述3 个数据集合并的大数据集上对不同模块进行了测试,结果如图2 所示.

图2 验证集准确率Fig.2 Accuracy of validation set
baseline 模型表示使用ERINE[16]预训练模型,并提取最后一层CLS 对应的特征向量,作为文本的语义特征向量.从图2 可以看出,使用预训练模型通常只需要训练5 个周期左右就可以达到最佳效果.本文提出的特征融合模块、特征提取模块和增加语义预测对提升模型的性能都有不同程度的作用.融合不同维度的特征对模型性能的提升比较明显.因此,融合不同维度的特征对于提升模型语义匹配的性能非常关键.此外,增加语义预测的损失函数在baseline 上并没有提升模型的性能.原因可能是此时的模型很难学到一个语义完整的特征,所以即使增加语义的约束也很难提升模型预测的准确率.但一旦增加特征融合模块和特征抽取模块,语义预测的损失函数使模型学习到更丰富的语义特征,从而增强了模型的预测能力.
表1 展示了各个测试模块的最终结果,可以看到,本文的最终模型取得了较好结果,准确率达到0.852.增加多维特征融合模块,准确率提高了7 个百分点,在此基础上增加特征提取模块,准确率又提高了1.6 个百分点.因此,提取多维语义特征,且均衡文本不同位置的注意力程度,能够有效提升表征学习型文本匹配的性能.

表1 不同模块的实验结果Tab.1 Results of models
3.3.2 对比实验
对比了基于多维特征表示的模型与两个基于性能相对较好的中文预训练模型的交互型模型的性能,结果如表2 所示.
由表2 可知,本文模型的准确率已经超过了基于Nezha[22]的交互型模型,足以说明该提取文本多维特征的模块能够有效地提取文本词汇、句法和高层语义信息,性能与不断交互所提取到的特征相当.但是与基于ERINE[16]的交互模型相比,准确率仍有一定差距.但本文模型的优势在于平衡准确率与检索效率,为了验证模型检索效率,进一步做了效率的对比实验,结果如表3 所示.

表2 准确率对比实验结果Tab.2 Results of accuracy comparison experiment

表3 效率对比实验结果Tab.3 Results of efficiency comparison experiment
在3.2 节中提到的实验平台上进行实验,当进行单文本匹配时,本文模型耗费的时间为133.261 ms,其中余弦相似度的计算耗费了0.594 ms.而基于ERINE[16]的交互型模型所消耗时间为126.376 ms.但在1 000 个文本中进行检索时,本文模型仍然只需要做一次特征抽取,就能与数据库中1 000 个文本特征进行匹配,但交互型模型需要重新计算1 000 次特征,需126 376 ms,即超过2 min 才能完成检索;而本文模型仅需729.776 ms,不足1 s 即可完成检索.在10 000 个文本中进行检索时,交互型模型需要超过20 min 才能完成检索,这样的效率远远达不到应用要求,而本文模型只需7 s 就能完成检索.因此,本文模型在性能上做到了准确率与效率的平衡.
4 结 论
在真实使用的场景下,相较于交互型模型,表征学习型模型具有更高的效率,更具有落地应用的价值.在缺乏交互型模型大量密集交互的情况下,获得文本多维度的特征非常关键.本文通过特征融合模块,提取了文本词汇、句法特征和高层语义等不同维度的特征能够有效地提升文本匹配的性能.此外,预训练模型可能存在对位置比较敏感的情况,但由于自然语言的属性,句子中的语义重点可能出现在任何位置,所以在没有交互的条件下均衡地提取不同位置的语义信息同样非常重要.本文提出的特征抽取模块能够有效地获取均衡的语义信息,提升文本匹配的准确率,而且基于表征学习的模型框架,提高了检索效率.因此,本文提出的基于多维特征表示的模型实现了文本检索准确率和效率的良好平衡.
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
北京航空航天大学学报(2022年8期)2022-08-31
保定学院学报(2022年2期)2022-04-07
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
数学学习与研究(2018年15期)2018-11-12
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
