
基于规则引擎的多传感器异步通信信息分类方法研究
2022-09-23 12:16陈海燕
成都工业学院学报 2022年3期
陈海燕
(江苏安全技术职业学院 网络与信息安全学院,江苏 徐州 221011)
要对海量传感器异步通信信息进行准确分类,应该先排除多传感器异步信息领域之外的无用信息,如环境干扰信息等,节省获取信息的时间和花销,提升分类质量[1]。目前可应用于信息分类的算法众多,如支持向量机、决策树等,在20世纪中期,国外就开始研究信息分类,其研究过程可分为3个阶段:首先对通信信息分类技术展开可行性论证分析;其次对通信信息分类工作进行相关实验研究;最后在信息分类和过滤方面进行实用化分析,开发了比较成功的信息分类系统[2]。国内对多传感器异步通信信息分类的研究,主要是将信息分类相关理论引入到多传感器异步通信信息分类[3]中,分为可行性分析、信息辅助分类和自动分类。如李湘东等[4]以概率主题模型为书目信息的表示模型,以信息的文本结构和分类能力实现特征加权策略,将特征加权策略融合到概率主题模型当中,实现了数目信息的分类;谢彬[5]运用语义网络对舆情信息建立了分类模型,通过节点在网络中的映射值对舆情信息进行描述,利用概念之间存在的映射关系获取增益,增强舆情信息主体的显著度,实现舆情信息的分类。结果表明,该分类方法的分类效果适合实际应用。
基于以上背景,本文将规则引擎应用到设计中,以提升分类效果。先以时间尺度为标准采集多传感器异步通信信息,对信息进行降维,提取信息熵,得到评价函数的改进设计。然后计算信息权重,改进信息分类算法,实现其信息的分类。最后通过实验验证本文方法的分类效果。
1 异步通信信息分类方法
本次研究信息分类步骤如图1所示。
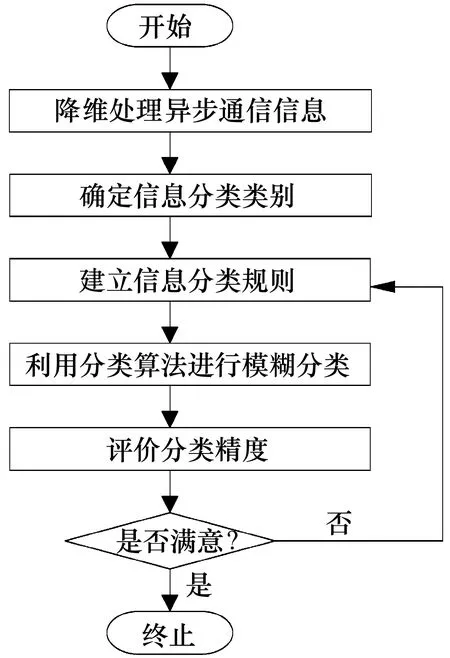
图1 信息分类流程
多传感器异步通信信息分类流程主要分为3部分,先对信息进行降维处理,然后确定信息的分类类别,完成其分类规则的确定,最后对分类算法进行改造,实现模糊分类,提升其分类精度。
1.1 降维处理信息
在对信息处理分类过程中,随着空间高维性和向量稀疏性的不断变化,通信信息的精确度以及效率性也会随之发生改变。因此,为了提高信息分类的准确性和精确度、提升分类处理的效率,需要运用降维处理技术来缩小信息的特征集。降维处理技术[6-7]以特征抽取和特征选择为中心,通过特征函数将通信信息投射或者映射到相应的特征空间内,抽取特征空间内信息值并进行评选估量,选择结果中最具有代表性的特征集来作为信息的特征参考值。
1)信息频率
信息频率是在特征集中选定的特征词的信息集合总数。根据特征函数计算每个特征词的信息频率。通过设定信息频率的范围来选定特征词,信息频率计算方法为:
(1)
式中:tn表示特征词;n表示在信息集中出现的次数;N表示信息的总词汇数。
2)互信息
互信息描述的是随机变量在相互作用下产生的强弱关系[8]。信息度量函数J(f)是互信息特征选择过程中的重点内容,其主要作用是对特征类别、特征子集和特征关键词对应的相关性进行计算。特征词在特征子集中对应的相关性与特征类别、特征子集之间的相关性呈反比。特征词t和类别ci的互信息公式为:
(2)
式中:m表示信息类别数;p(ci)表示信息类别ci的概率;p(t,ci)表示类别ci中包含特征词t的概率;p(t)表示特征词t对应的概率;p(ci)表示类别ci中包含信息的概率。
利用上述降维处理方式,在规则引擎的基础上,以时间尺度为标准,搜索信息,时间间隔设置为5 s,统计5 s内发出的信息,由此建立了信息熵数学模型:
f=[(t1,n1,x1),(t2,n2,x2),…,(ti,ni,xi)]。(3)
式中:f表示按照时间段得到的信息;t表示5 s的时间间隔;n表示在5 s时间间隔内出现的信息量;x表示信息内容;(ti,ni,xi)表示信息内容xi的信息数量ni在ti时间间隔内接收到的数量。
一旦规则引擎不再适用,时间间隔就会设定为15 s,获取信息f,计算信息f的信息熵:
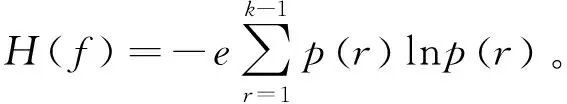
(4)
式中:k表示信息初始状态数量;p(r)表示初始状态下信息出现的概率。
1.2 改进信息分类算法
在信息处理完毕之后,需要对每一个信息特征赋予一个权值,来表示该信息的重要性。利用信息特征评价函数[9-10]ω(tk,d)计算信息的权重,评价函数为:
(5)
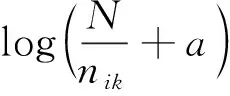
在信息分类算法改进过程中,考虑到特征项tk出现的位置,提出了改进的评价函数:
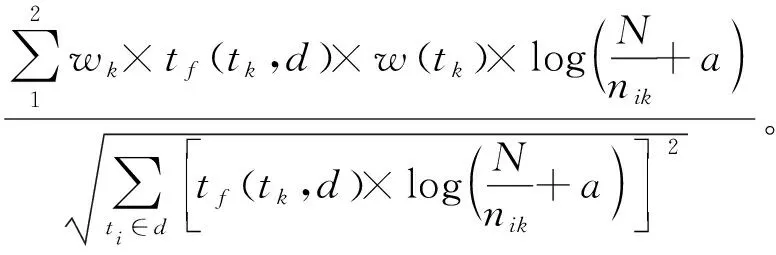
(6)
式中:w(tk)表示特征项tk在信息库中的权重系数;wk表示特征项tk在不同位置的参数。
信息分类时,首先进行分词处理,将信息特征提取和向量处理表示为:X(X1,X2,X3,…,Xn;W1,W2,W3,…,Wn)。其中:X表示信息特征词;W表示信息特征词的权重。
分词处理[11-12]完毕后,对信息进行向量化处理,并分别计算出信息属于每一个类别的概率。通过比较分类概率的大小,将信息分到概率值较大的类别中。全概率分类公式为:
(7)
对于条件独立性假设之后的信息向量,利用式(8)进行概率计算:
(8)
信息分类算法是利用待分类信息特征项tk,在信息集中出现的概率乘积,来计算信息数据某一个类别的概率。但由于信息垃圾特征项的出现,容易使算法出现计算极端的现象。接下来通过信息分类流程,来实现信息的分类。
1.3 分类信息
对信息进行降维处理和分割处理后,需要再根据甄选出的特征词具有的典型特征,利用模糊理论[13-14]对通信信息进行分类处理,基于规则引擎信息技术按照不同种类对应的特征词进行信息分类操作,步骤如下:
Step1:分化实验结果。首先需进行多次实验,在得出的实验结果中选定最佳数值范围,将不同种类逐渐分化,设定分类数值。
Step2:类别区分。根据甄选出特征词的典型特征,创建出合适的引擎规则。模糊区分种类,充分利用典型信息特征挑选出最优隶属函数。
Step3:模糊过程。运用模糊理论对通信信息进行分类处理。根据典型信息特征模糊选定对象,代入隶属函数公式,求取选定对象的模糊化数值,再通过对象的模糊化数值计算出该选定对象的隶属度。
Step4:反模糊过程。反模糊过程表示模糊过程的相反状态,求取分类出选定对象隶属于哪一特征。反模糊过程需要遵循最大隶属原则[15]和最贴近度原则。最大隶属原则是对选定对象在模糊集中对应的特征值进行计算,根据计算结果获取特征值在不同类别中的隶属度,根据隶属度计算结果确定分割对象的类别特征。最贴近度原则是根据子集之间的相似度确定对象的类别特征。
最大隶属原则:
设C1,C2,C3,…,Cn为R的子集,obj表示信息特征元素,如果存在:
fobj=max{μc1(obj),μc2(obj),…,μcn(obj)}。
(9)
则obj∈Ci,说明信息属于Ci类别。
Step5:精度分类评估。如果求取结果符合整个流程操作,则输出并显示结果,如果不符合,则需要重复步骤2。
2 实验对比分析
2.1 设置实验参数
信息分类效果对比试验参数设置如表1所示。
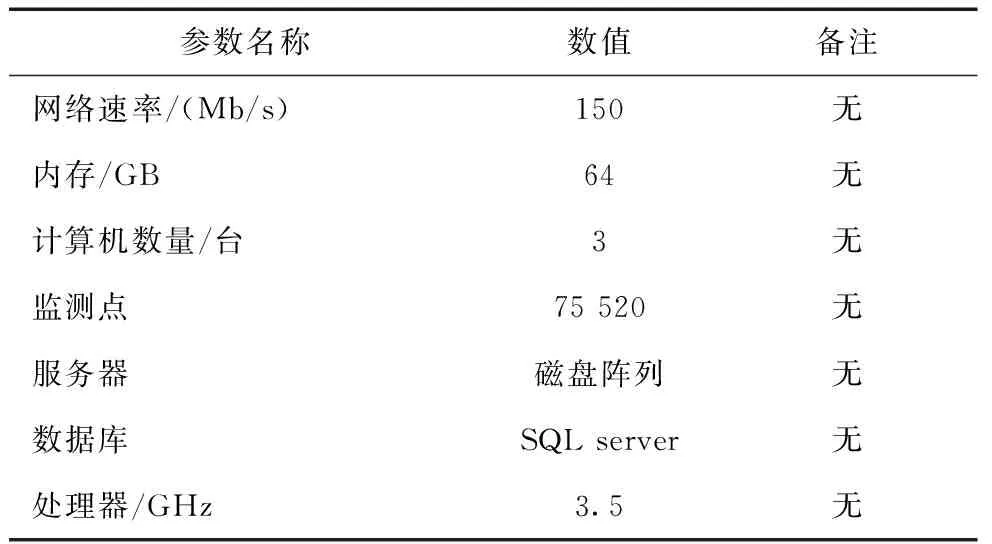
表1 试验参数
2.2 信号干扰条件下信息分类效果对比试验
干扰信号会严重影响信息的分类。采用基于复合加权LDA模型的信息分类方法(方法1)、基于语义网络的信息分类方法(方法2)以及本方法来对信息进行分类,分析了3种方法受到信号干扰的信息状态,如图2所示。
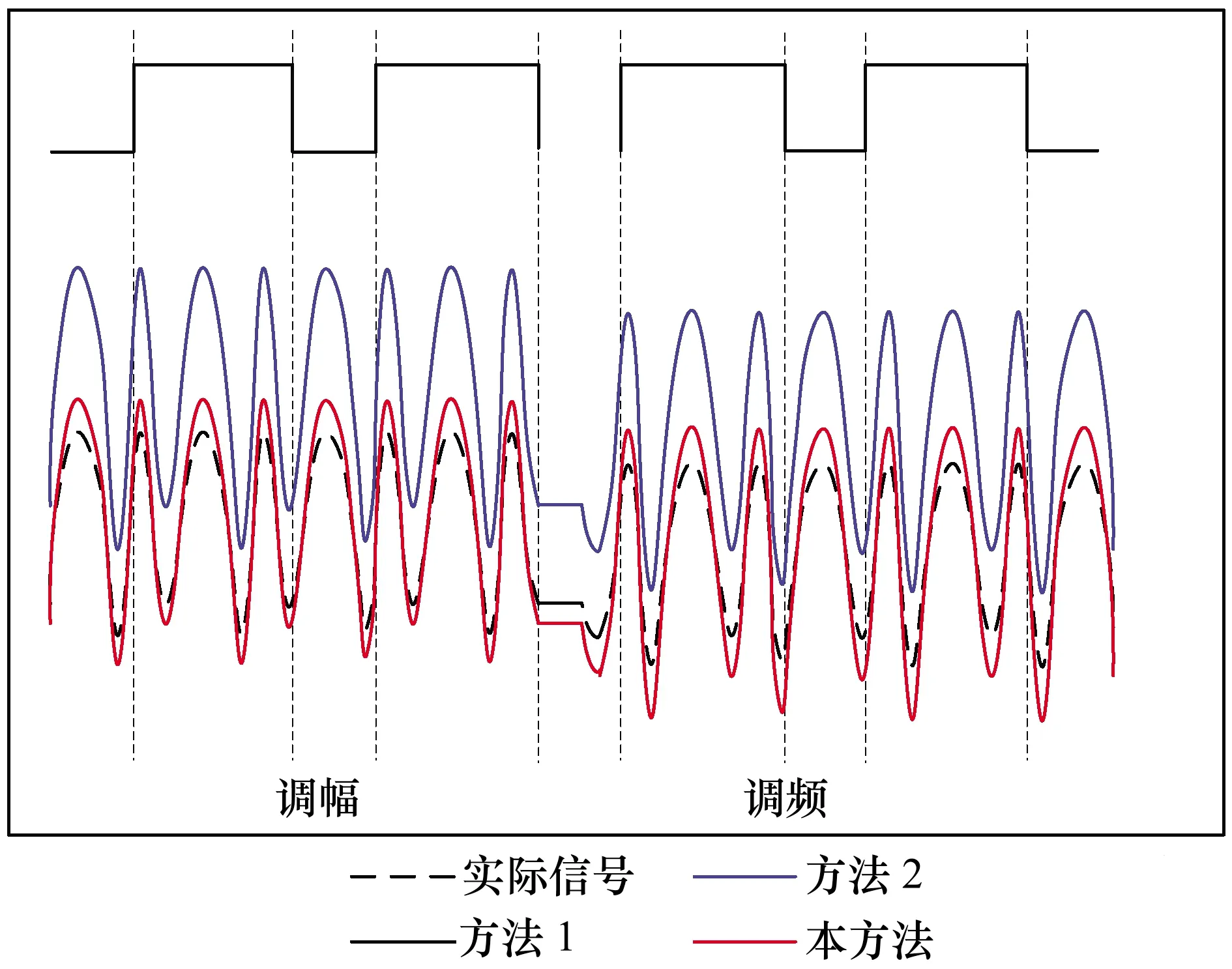
图2 干扰条件下3种方法的信号状态对比
图2可以看出基于规则引擎方法获取的信号波动幅度与实际信号波动的趋势一致。
根据信号状态对比,将3种信息分类方法的分类效果进行对比分析,得到信号干扰下分类效果对比结果,如表2所示。
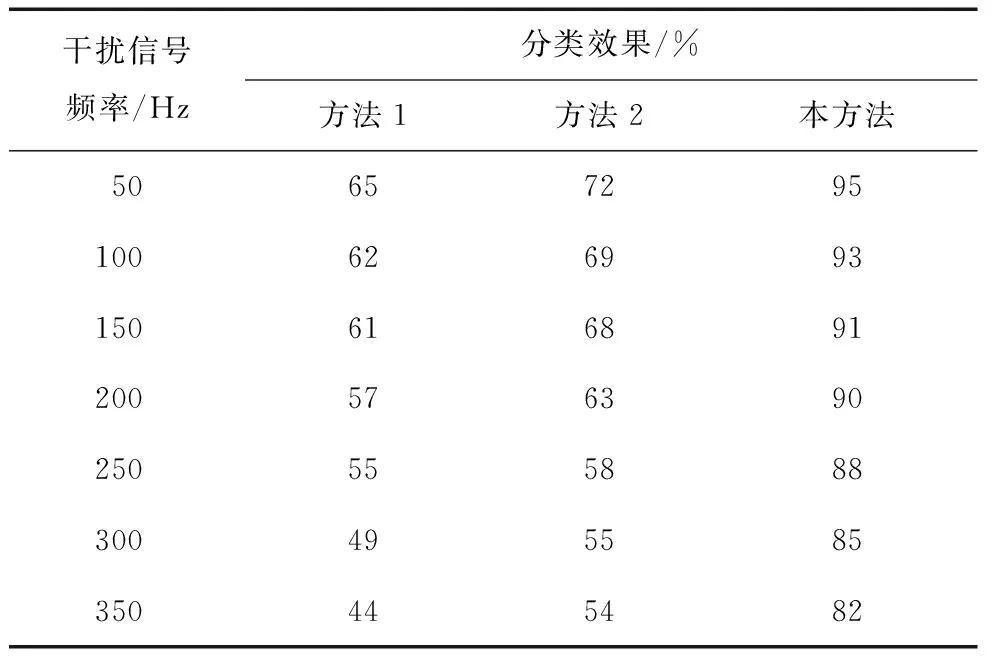
表2 信号干扰下3种方法的分类效果对比
从表2可以看出,在信号干扰下,方法1的过程较为繁琐,在分类过程中易出现误差,降低了分类效果;方法2在设计分类算法时,直接建立了信息分类模型,缺乏信息的预处理步骤,使信息分类效果变差。而本方法在预处理信息的同时,还利用信息分类算法,统计出信息的类别,提高了分类效果。
2.3 环境干扰条件下信息分类效果对比试验
环境干扰对信息分类也会造成一定影响。将方法1、方法2以及本方法的分类效果进行对比,结果如图3所示。
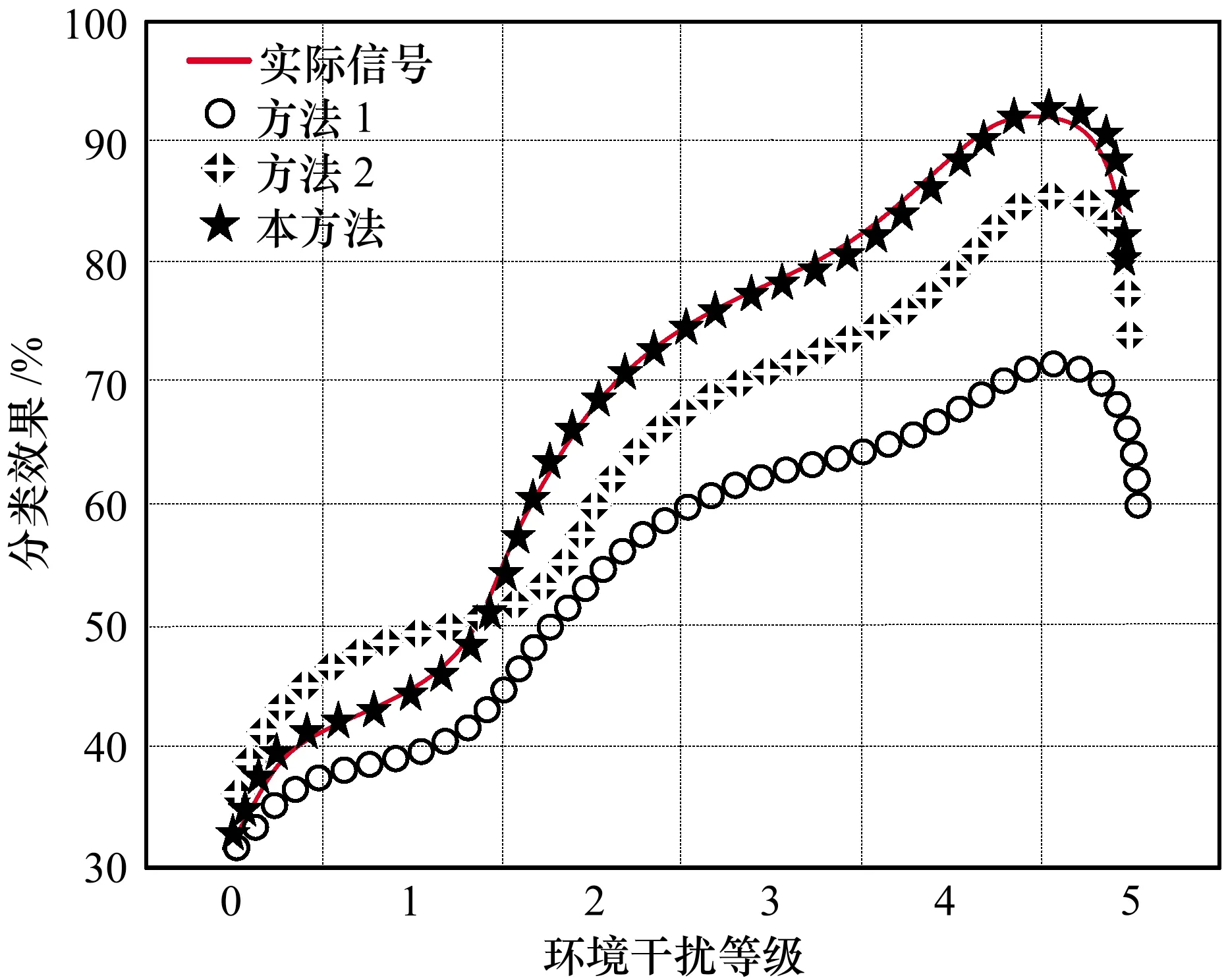
图3 环境干扰下分类效果对比
从图3可以看出,方法1在环境干扰等级超过3级时,信息分类效果明显变差,可能是环境干扰超过3级后,会遭到传感设备发电机、雷击以及无线通信等多方面环境影响,减弱了信息分类的效果;方法2与实际信号的分类效果比较接近,但分类过程中仍然会受到无线通信环境的干扰,使信息分类效果变差;而本方法的分类效果最好,基本不会受到环境的影响,并与实际信号的分类效果非常接近。
基于以上实验结果,无论是在信号干扰下还是环境干扰下,本方法远远好于其他分类方法。
3 结语
为提高多传感器异步通信信息分类效果,本文提出了基于规则引擎的信息分类方法。先以时间尺度为标准完成信息检索,对其进行降维,得到其评价函数的改进设计。然后完成信息改进权重的计算,对其信息分类方法进行改进,实现信息分类流程设计,最后通过实验证明本文研究的实用性。实验结果显示,该方法具有较强的分类效果,分类效果为80%以上,明显优于对比方法。虽然本方法具有一定先进性,但是还缺乏对冗余信息的分类,这也是未来的研究方向。
猜你喜欢
车主之友(2022年4期)2022-08-27
计算机系统应用(2021年9期)2021-10-11
海峡姐妹(2019年12期)2020-01-14
计算机技术与发展(2018年8期)2018-08-21
民族古籍研究(2018年1期)2018-05-21
中国机械工程(2017年22期)2017-12-02
火控雷达技术(2016年1期)2016-02-06
新校长(2016年8期)2016-01-10
中文信息学报(2015年4期)2015-04-21
浙江大学学报(工学版)(2015年1期)2015-03-01
