
NOMA-MEC系统中基于改进遗传算法的协作式计算卸载与资源管理
2022-09-22 03:37:30周天清胡海琴曾新亮
电子与信息学报 2022年9期
周天清 胡海琴 曾新亮
(华东交通大学信息工程学院 南昌 330013)
1 引言
随着机器学习和人工智能等科学技术的兴起,人脸识别、智能家居、自动驾驶和医疗保健等应用应运而生。这些新型应用在实时处理时占用了大量的计算和存储资源,对存储空间、计算资源和电池容量受限的智能设备提出了巨大的挑战[1-3]。为应对该挑战,移动边缘计算(Mobile Edge Computing,MEC)允许资源受限的智能设备将计算密集型任务卸载至边缘网络,让具备计算和存储能力的边缘节点处理任务。
超密集异构网络(Ultra-Dense Heterogeneous Network, UDHN)与MEC的结合进一步缩短了用户与计算中心的距离,且UDHN通过在宏小区内部署大量小基站(Small Base Station, SBS),极大地提升了服务覆盖率和资源利用率,降低了智能设备至基站的传输时延。但是,密集部署的小基站会导致大量的能耗[4,5]。此外,在UDHN中,每个基站覆盖下的用户密度较大,区内与区间均存在严重干扰[6]。
合适的干扰消除和频带资源分配方案有利于降低MEC系统时延和能耗,从而有效提升系统性能。在单MEC服务器和多用户场景下,文献[7]提出了基于正交频分多址接入的MEC系统。具体而言,它将系统频带划分为多个正交子信道以消除用户间的干扰,并最大化了系统计算效率。在多小区和多用户的MEC场景中,文献[8]最小化时延和能耗的加权。其中,小区内的用户通过正交信道进行信号传输,但小区间的用户可能相互干扰。在多宏小区、多小小区和多用户的UDHN场景下,文献[9]研究了系统总能耗最小优化问题。它为消除UDHN中层间和层内干扰,提出了一种频谱资源分配方案。但是,随着用户规模的增大,频谱资源分配会变得越来越紧张。
为进一步提升频谱利用率、实现高速率传输及广覆盖,已有多数研究将非正交多址接入(Non-Orthogonal Multiple Access, NOMA)和MEC结合起来。文献[10]研究了时分多址接入(Time Division Multiple Access, TDMA)和NOMA下的部分卸载与二元卸载问题,并尝试最大化系统计算效率。文献[11]考虑了NOMA-MEC在车联网领域内的应用。为最大限度保证用户效益,它利用基于深度学习网络的博弈算法来为用户选择最优的卸载策略。文献[12]构建了UDHN下的NOMA-MEC系统,并研究了多SBS、多用户的资源分配问题以最小化用户能耗和任务时延。
上述研究都有对干扰进行消除和对频带资源进行分配,或者引入NOMA技术进一步提升频带利用率。然而,其中大部分研究考虑每个用户仅有一个任务需要处理的情况,单个宏小区场景与非协作场景;很少研究考虑UDHN场景下多用户多任务协作式计算卸载问题。不同于上述研究,本文构建了UDHN场景下NOMA-MEC系统,其中每个用户均存在多个计算任务,且宏基站(Macro Base Station,MBS)与小基站间存在协作式卸载。针对该系统,在MEC计算资源和用户时延约束下,联合优化计算资源分配、用户任务卸载和用户发射功率以最小化系统总能耗。本文具体工作如下:
(1)在UDHN中融入频带划分机制与NOMA技术。为解决UDHN中存在的层内与层间干扰,引入了频谱划分机制。在此基础上,为进一步提升上行频谱效益,又引入NOMA技术。
(2)在NOMA-MEC系统中,考虑多蜂窝与多用户。同时,假定每个用户有多个不可拆分的计算任务,且小基站可与宏基站协作完成任务。其次,根据计算任务所需计算资源占比,分配用户计算资源。这种计算资源分配方式既能很好地满足用户计算需求,又能简化优化问题,便于算法实际应用。
(3)鉴于所建模问题具备非线性整数形式,利用多样性引导变异的自适应遗传算法(Adaptive Genetic Algorithm with Diversity-Guided Mutation, AGADGM)设计出了协作式计算卸载与资源分配算法。不同于一些组合算法[9,13],本文仅考虑单纯遗传算法(Genetic Algorithm, GA),仅涉及单层循环。显然,此种考虑可以削减算法的运行时间,且更适合超密集网络场景。最后,在仿真中,引入全本地算法、最强信道增益关联算法和传统遗传算法进行对比,调查了用户发射功率、用户密度与频谱划分因子对系统性能的影响。
2 系统模型
2.1 网络模型
本文考虑了如图1(a)所示的UDHN场景下的NOMA-MEC系统。图中每个正6边形代表一个宏小区,每个宏小区内部署了1个MBS、多个SBS与多个用户终端。具体而言,在超密集异构MEC系统中,部署了N¯ 个MBS,N˜ 个SBS和K个用户终端,其中SBS的索引集记为N˜ ={1,2,...,N˜},MBS的索引集记为N˜ ={N˜ +1,N˜ +2,...,N˜ +M},则所有基站的索引集为N=N˜∪N¯;用户终端集合表示为K={1,2,...,K}。此外,假定每个宏小区内所有SBS构成一个SBS簇,且所有基站均配置了MEC服务器;假定每个用户终端有多个计算任务,其任务可以在本地执行,也可卸载至基站MEC服务器执行;假定用户与基站之间的通信采用无线链路,MBS与SBS之间的通信采用有线回程链路(速率为r0)。
2.2 资源模型
为消除UDHN中层内干扰与层间干扰,根据文献[9,14],本文亦对频谱进行分割,如图1(b)所示。在UDHN中,为消除MBS与SBS间的层间干扰,将频带F(带宽为W)划分为子带F1和 子带F2,其中子带F1(带宽为µW)分配给MBS,子带F2(带宽为(1-µ)W)分配给SBS,0≤µ≤1为频谱划分因子;为消除相邻MBS间的干扰和SBS簇间的干扰,子带F1被分割为带宽为µW/3 的3个子频带F11,F12与F13, 且F2被 分割为带宽为( 1-µ)W/3的3个子频带F21,F22与F23。为消除簇内SBS间的干扰,子频带F21,F22与F23被再次均分为多个更小的子频带,它们的带宽为 (1-µ)W/3θ,其中θ为一个SBS簇内SBS的数目。
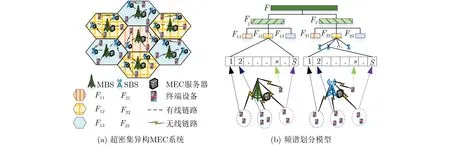
图1 系统模型
区别于文献[9]中MBS和SBS将频带资源均分给其所关联的所有用户,本文在上行链路中引入NOMA技术以解码传输信号,并借此提升频谱利用效率。如图1(b)所示,在NOMA技术下,将任意MBS和SBS的频带资源划分为多个NOMA子信道,允许多个用户同时使用某个基站的同一子信道。假定每个子信道带宽为w,则任意MBS的子信道个数为S¯ =µW/3w, 其子信道索引集记为S¯ ={1,2,...,S¯}。 同理,任意SBS的子信道个数为S˜ =(1-µ)W/3wU,其子信道索引集记为S˜ ={1,2,...,S˜}。
2.3 通信模型
在上述资源模型中,本文考虑了上行NOMA技术。该技术按信道增益递减顺序进行信号解码,这与下行NOMA的解码顺序相反[15]。假设有多个用户接入基站n的子信道s,Kns为 关联至基站n的子信道s的用户集合。类似于文献[16],对于任意基站的子信道,将用户至该子信道的信道增益按升序排列,onsk表示用户k在基站n的子信道s上的排序序号。当用户j和 用户k同时接入基站n的 子信道s,且用户j的信道增益hnsj低于用户k的信道增益hnsk时,onsj 根据上行NOMA的特性[15,16],用户关联基站子信道时,其上传速率分为以下两种情况: (1)当用户终端k选择关联MBSn的 子信道s时,用户k的上传速率rnsk为 鉴于UDHN中部署了大量SBS,消耗了大量能耗,本文尝试最优化任务完成总能耗,它涉及用户端与基站端的能耗。具体而言,在计算资源和时延约束下,联合优化基站子信道选择X={xnsk,∀n ∈N,∀s ∈Sn,∀k ∈K}、 任务卸载决策y={yk,∀k ∈K}和z={zk,∀k ∈K}及 用户发射功率p={pk,∀k ∈K}以最小化系统总能耗E。其中,Sn为 基站n的子信道索引集。优化问题可规划为 不难发现,问题P1为0-1非线性混合整数规划问题。为解决该问题,可以采用文献[9]中的联合自适应遗传算法和自适应粒子群算法的双层搜索算法。但是,考虑到其中粒子群算法是对遗传算法所获解局部的刷新,对问题解的优化不存在较大的影响,本文仅尝试利用其第1层搜索算法(多样性引导变异的自适应遗传算法)求解问题P1。最后,根据该改进遗传算法,本文设计出了有效的协作式计算卸载与资源分配算法。 多样性引导变异的自适应遗传算法(AGADGM)是对传统遗传算法(Traditional GA, TGA)的改进。在TGA算法中,1个种群包含多个个体。这些个体是带有染色体特征的实体,它们是优化问题的潜在解。待种群初始化后,根据适者生存和优胜劣汰的原则,TGA用适应度函数评价种群个体适应度并筛选出最佳个体。具体而言,在一些特定规则下,TGA执行选择、交叉、变异等操作,经过逐代演化,最终找到问题的近似最优解。相比于T G A,AGADGM在自适应交叉和变异运算之前进行了多样性引导变异,克服了早熟收敛问题[9]。该算法重要内容及相关操作如下。 类似于文献[13],本文考虑实数编码。对于问题P1的任意一种解的优化参量{X,y,z,p}可以编码成 某 个 个 体i ∈I的 染 色 体{Li,Qi,Ui,Vi},I={1,2,...,I}记 为个体索引集合,I为种群的规模,Li={lik,k ∈K},Qi={qik,k ∈K},Ui={uik,k ∈K}与Vi={vik,k ∈K}为个体i的染色体片段。为实现对参量X的编码,假定每个基站的子信道构成一个虚拟基站,并对其标记唯一索引。因为任意用户仅能关联至某个基站的某一个子信道,因此用户关联结果可用虚拟基站索引表示。于是,在任意个体i中 ,lik取 值为用户k所关联虚拟基站的索引。此外,qik和uik分 别为用户k卸载至基站的任务数和自SBS上传至MBS的任务数,且vik为 用户k的发射功率。值得注意的是,qik不能超过用户k的任务数,uik不 能超过qik并满足qik的限制条件,且用户k的发射功率需满足0≤vik ≤pmkax。 遗传算法从初始化种群开始,需要生成满足条件的系列个体。为满足问题P1的约束C2-C6,按照以下规则初始化种群,即 为从当前种群中选择优良个体,本文采用锦标赛方式进行选择。在此方式中,高适应度值的个体被选择的概率较大。此外,在迭代更新过程中,每一代都保留历史最佳个体。当历史最佳个体没有选入下一代时,用历史最佳个体替换当前种群中的最差个体,从而提高遗传算法性能。 为克服早熟收敛问题,在自适应交叉和变异之前进行多样性评价,让其引导变异。对多维数值问题,其多样性评价[9]定义为 步骤2 按照式(7)和式(9)求取计算资源;根据式(16)计算所有个体的个体适应度值,并找出当前最佳个体;如果当前最佳个体的适应度值高于历史最佳个体的适应度值,则以前者替换后者。 步骤3 重复如下操作; 步骤4 根据锦标赛选择法选择个体建立新种群;如果历史最佳个体没有进入下一代,则以历史最佳个体替换种群中的最差个体;根据式(25)中的概率,按式(19)-式(22)进行多样性引导变异;按照式(7)和式(9)求取计算资源,并根据式(16)计算所有个体的适应度值。 步骤5 任意两个相邻个体按照式(17)中的自适应交叉概率执行交叉操作;根据式(18)中的自适应变异概率,所有个体按式(19)-式(22)进行变异操作。 步骤6 按照式(7)和式(9)求取计算资源;根据式(16)计算所有个体的适应度值,并找到当前种群的最佳个体。如果当前最佳个体的适应度值高于历史最佳个体的适应度值,则以前者替换后者。 步骤7 按照t=t+1更新迭代次数;如果t ≤T(T为最大迭代次数),则回到步骤3,反之则输出历史最佳个体的染色体片段,并终止循环。 为凸显本文算法的有效性,仿真中引入其他计算卸载与资源分配算法,包括最强信道增益关联算法(Maximum Channel Gain Association algorithm, MCGA)[9]、基于传统遗传算法的计算卸载与资源分配算法(Traditional Genetic Algorithm based Scheme, TGAS)[18]及全本地计算算法(Local Computing Algorithm, LCA)[5]作比较。在MCGA中,任意用户将计算任务全部卸载至最强信道增益的基站子信道;TGAS则固定交叉和变异概率,且没有引入多样性保护变异;LCA让用户自己完成所有任务。 在保持µ=0.5、用户最大发射功率为23 dBm及其他条件不变的情况下,图3显示了用户密度ρ(宏小区内用户个数)对系统效能的影响。根据式(13)可知,ρ值的增大必定会导致系统总能耗的增大。如图3(a)所示,4种算法的系统总能耗均随ρ的增长而增长。类似于图2(a),图3(a)中MCGA系统总能耗一直低于其他算法,本文算法获得了较前者更高的系统总能耗。类似于图2(b),图3(b)中TGAS, LCA与本文算法总能支持所有用户在规定时间内完成所有计算任务。然而,MCGA支持率却一直低于1,且总体上随着ρ先增加后下降。在低ρ域,用户密度的增加导致靠近基站的用户增加,系统支持率可能随ρ上升;在高ρ域,用户密度的增加导致可利用资源的下降,系统支持率可能随ρ下降。 表1 参数设置 图2 用户最大发射功率p mkax对系统总能耗和系统支持率的影响 在保持K=35、用户最大发射功率为23 dBm及其他条件不变的情况下,图4显示了频谱划分因子µ对系统效能的影响。由2.2节的资源模型可知,µ越大,MBS的频带资源越多,SBS的频带资源则越少。如图4(a)所示,总体上,TGAS, MCGA与本文算法的系统总能耗随着µ的增大而增加。其原因在于,随着µ的增大,部分选择SBS的用户因频带资源不足转而选择MBS。由式(6)可知,距离MBS较远的用户越多,传输时延及能耗越大,系统总能耗也随之增加。但是,因为LCA中用户任务全部本地执行,故其系统总能耗不随µ变化。此外,类似于图2(a)、图4(a)中MCGA系统总能耗一直低于其他算法,本文算法获得了较前者更高的系统总能耗。众所周知,MBS中MEC服务器计算资源有限。根据式(7)可知,越多用户接入MBS,用户分配到的计算资源越少,计算时延就越长,于是越来越多的用户不满足时延约束。因此,图4(b)中MCGA的系统支持率随着µ的增大而减小。类似于图2(b)和图3(b),图4(b)显示TGAS, LCA与本文算法总能支持所有用户在规定时间内完成所有计算任务。 图4 频带划分因子µ 对系统总能耗和系统支持率的影响 图5显示了遗传算法中最佳个体适应度值的收敛情况,其中K=35,µ=0.5及用户最大发射功率为23 dBm。容易发现,TGAS具有较本文算法更快的收敛速度,但因前者陷入局部最优而导致获得较后者更差的适应度值。究其原因,固定的交叉和变异概率容易使得TGAS陷于局部最优,过早收敛。而本文算法引入了多样性引导变异、自适应交叉和变异概率等操作,这些操作使得搜索更加细致的同时,避免了过早收敛。 图5 最优个体的适应度值在遗传算法下的搜索情况 综合上述,尽管MCGA能达到较其他算法更低的系统总能耗,但其系统支持率一直较其他算法更低。虽然本文算法的系统总能耗高于MCGA,但它都低于LCA和TGAS。此外,本文算法的系统支持率始终为1,即本文算法总能支持所有用户在规定时间内完成所有计算任务。总体而言,同其他算法相比,本文提出的基于改进遗传算法(AGADGM)的协作式计算卸载与资源分配算法具备一定优势,且能在问题约束条件下较好地优化系统能耗。 本文构建了UDHN场景下的NOMA-MEC系统,并在该系统中研究了多用户多任务协作式卸载策略。为合理消除干扰和分配频谱资源,融入了频带划分机制与上行NOMA技术。然后,在计算资源占比分配策略与时延约束下,联合优化用户关联、卸载决策与用户发射功率以最小化系统总能耗。为求解所规划的问题,在改进遗传算法(AGADGM)的基础上,提出了协作式计算卸载与资源分配算法。仿真结果表明,同其他算法相比,本文所设计算卸载与资源分配算法具备一定优势,且能在问题约束条件下较好地优化系统能耗。未来研究可涉及单用户多信道接入场景与大规模天线场景等。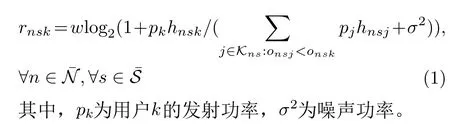

2.4 计算模型



2.5 问题描述


3 基于改进遗传算法的协作式计算卸载与资源分配算法
3.1 染色体
3.2 种群初始化

3.3 适应度函数

3.4 选择
3.5 交叉

3.6 变异

3.7 多样性评价

4 系统仿真
4.1 参数设置

4.2 仿真结果分析



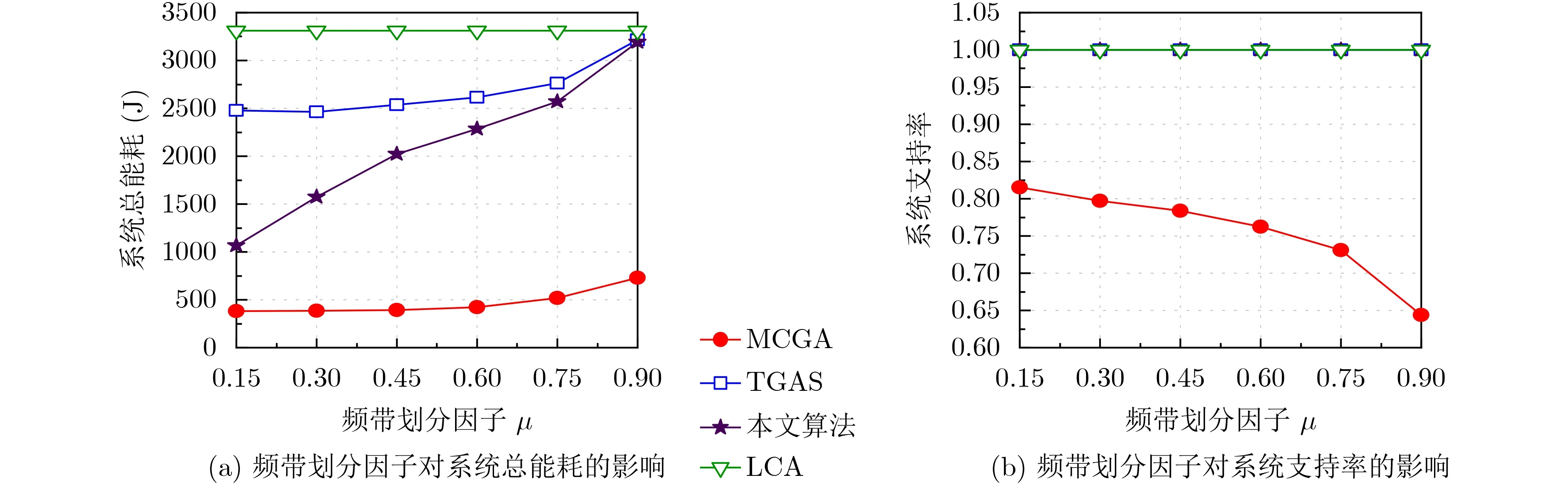
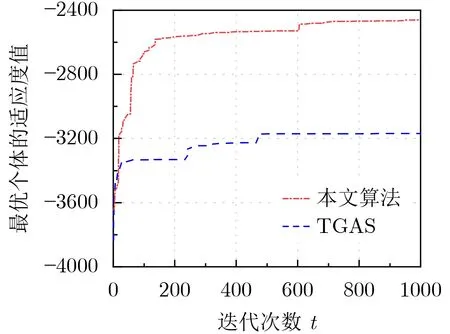
5 结束语
猜你喜欢
计算机仿真(2022年8期)2022-09-28 09:53:02
电脑知识与技术·经验技巧(2020年5期)2020-06-22 13:19:24
航天电子对抗(2019年4期)2019-06-02 08:22:44
电子测试(2017年15期)2017-12-18 07:18:51
石油地球物理勘探(2017年2期)2017-11-23 06:02:04
中央民族大学学报(自然科学版)(2017年1期)2017-06-11 07:13:32
统计与决策(2017年2期)2017-03-20 15:25:24
中国塑料(2016年11期)2016-04-16 05:26:02
智能系统学报(2015年4期)2015-12-27 09:38:39
电测与仪表(2015年12期)2015-04-09 11:44:50
