
双回归网络的单图像超分辨率重建
2022-09-21 05:38:24张永,吕庚
计算机工程与应用 2022年18期
张 永,吕 庚
兰州理工大学 计算机与通信学院,兰州730050
图片的超分辨率(super resolution,SR)是从低分辨率(low resolution,LR)图像中恢复高分辨率(high resolution,HR)图像的过程,是计算机视觉和图像处理领域中一种重要的图像处理技术。得益于深度学习的发展,深度神经网络(DNN)被应用于包括图像分类、视频理解和许多其他应用。基于深度神经网络的超分辨率模型通过学习从LR图像到HR图像的非线性映射函数,在图像超分辨率方面表现出了良好的性能,使基于深度学习的图像超分辨率成为研究从LR 图像中重建HR图像的一项重要应用。
Dong 等人[1]首先提出了一种三层卷积神经网络,称为SRCNN(super-resolution convolutional neural network)。SRCNN采用双三次插值将LR图像放大到目标倍数,然后再输入三层卷积神经网络学习LR图像和HR图像之间的映射关系,成功使用CNN 解决超分辨率问题。在此之后,基于卷积神经网络,提出了许多方法来提高SR性能。Kim等人[2]第一次将残差学习融入CNN网络并提出一种深度卷积神经网络,He等人[3]在残差学习基础上针对超分辨率问题首次提出了残差网络结构,通过恒等连接构建深度残差网络来克服退化问题。Haris 等人[4]提出了一个反馈网络(DBPN),该网络由多个上、下采样层组成,迭代式生成LR 和HR 图像,通过迭代上下交替采样的纠正反馈机制,重建出具有丰富纹理细节的图像,在高倍数重建上表现出良好的质量。Zhang 等人[5]提出建立通道注意力机制,通过通道间的相互依赖性来自适应地调整不同通道的权重,构建了RCAN的深度模型,RCAN允许丰富的低频信息通过多个跳跃连接直接进行传播,使主网络专注于学习高频信息,从而使模型更好地学习图像的纹理细节特征,进一步提高SR 的性能。使用在HR 图像上应用理想的降采样核(如:双三次插值)获得LR 图像作为训练集训练的模型在应用到现实数据时,模型性能会急剧下降。基于此问题,Zhou 等人[6]提出用于学习未知下采样的SR方法解决模型在实际应用中的适应性问题,但由于感知质量问题和训练不稳定问题造成输出图片缺乏高频纹理细节。为了解决使用特定方法下采样配对数据造成的模型适应性问题,Guo等人[7]在U-net的基础上引入对偶回归方法,使模型不依赖于HR 图像,可以直接在LR图像中学习。席志红等人[8]在原始低分辨率图像上直接进行特征映射,只在网络的末端引入子像素卷积层,将像素进行重新排列,得到高分辨率图像,能够恢复更多的图像细节,图像边缘也更加完整且收敛速度更快。Li等人[9]提出深度递归上下采样网络DRUDN。在DRUDN中,原始LR 图像直接馈送,无需额外插值,然后使用复杂的递归上下采样块来学习LR图像HR图像之间的复杂映射。彭晏飞等人[10]首先迁移支持向量机中的hinge损失作为目标函数,其次使用更加稳定、抗噪性更强的Charbonnier 损失代替L2 损失函数,最后去掉了残差块和判别器中对图像超分辨率不利的批规范化层,并在生成器和判别器中使用谱归一化来减小计算开销,稳定模型训练。
对偶学习方法[11-14]包含原始模型和对偶模型,同时学习两个相反的映射。对偶学习最关键的一点在于,给定一个原始任务模型,其对偶任务的模型可以给其提供反馈;同样的,给定一个对偶任务的模型,其原始任务的模型也可以给该对偶任务的模型提供反馈;从而这两个互为对偶的任务可以相互提供反馈,相互学习、相互提高。在新的研究中,此方案被用于在没有配对训练数据的情况下进行图像转换。基于对偶学习方法,CycleGAN[15]和DualGAN[16]提出循环一致性损失以避免GAN方法的模式崩溃问题从而帮助最大限度地减少分布差异。但是,CycleGAN是将一类图片转换成另一类图片,不能直接应用于标准SR 问题。基于CycleGAN 模型,Yuan 等人[17]提出CinCGAN 模型,放弃使用特定方法下采样配对合成数据,在没有配对数据的情况下生成HR图像,减少特定方法配对数据对模型适应性的影响。
对偶学习和已有的学习范式有很大的不同。首先,监督学习(supervised learning)只能从标注的数据进行学习,只涉及一个学习任务;而对偶学习涉及至少两个学习任务,可以从未标注的数据进行学习。其次,半监督学习(semi-supervised learning)尽管可以对未标注的样本生成伪标签,但无法知道这些伪标签的好坏,而对偶学习通过对偶游戏生成的反馈(例如对偶翻译中x和x1的相似性)能知道中间过程产生的伪标签(y1)的好坏,因而可以更有效地利用未标注的数据。第三,对偶学习和多任务学习(multi-task learning)也不相同。尽管多任务学习也是同时学习多个任务的模型,但这些任务必须共享相同的输入空间,而对偶学习对输入空间没有要求,只要这些任务能形成一个闭环系统即可。第四,对偶学习和迁移学习(transfer learning)也很不一样。迁移学习用一个或多个相关的任务来辅助主要任务的学习,而在对偶学习中,多个任务是相互帮助、相互提高,并没有主次之分。
尽管上述方法在图像超分辨率任务中表现出了良好的性能,然而这些方法仍然存在不足之处。首先,由于LR→HR可能的函数映射空间非常大,采用特定方法配对的数据集模型泛化能力受限,学习好的模型通常需要更深的网络和更多的参数。此外,残差结构没有充分利用结构上的层次特征。针对上述问题,提出了一种双回归方案,主要贡献点如下:
(1)在原始回归任务基础上引入对偶回归,形成闭环对重建图像引入额外的约束来减少LR→HR 的可能映射空间。
(2)在残差结构中引入傅里叶变换得到图像的不同层次的高频信息。利用残差结构中的高频层次信息,增强模型对高频细节的复原能力。
(3)采用配对的LR→HR 数据和未配对的LR 数据作为训练集,减少特定方法配对数据集对模型泛化能力的影响。
1 模型设计
1.1 模型网络架构
如图1 所示,双回归模型由两部分组成:原始回归网络和对偶回归网络。原始回归网络包含特征提取模块和重建模块。对偶回归网络由两个下采样模块组成。定义输入图像为X,输出图像为Y。
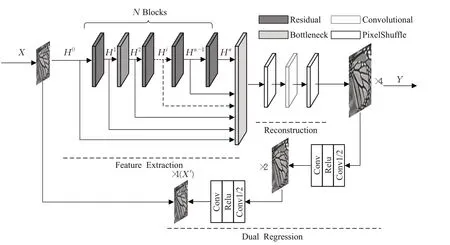
图1 双回归网络模型架构Fig.1 Architecture of dual regression network model
特征提取模块由N个残差块和一个特征融合模块组成。残差块进行特征提取,特征融合块对所有残差块的输出做特征融合。
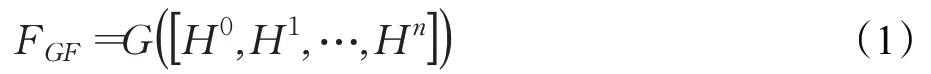
式(1)为全局特征融合式,其中[H0,H1,…,Hn]表示全局特征的级联操作,Hi表示第i(i=1,2,…,N)个残差块的输出(H0为输入图像X),G(⋅)表示1×1 卷积操作,FGF为全局特征融合式输出。重建模块由两个卷积层和一个亚像素重建块组成。全局特征融合输出经过一个卷积层后作为亚像素重建模块的输入,亚像素重建模块的输出经过一个卷积层得到输出Y。
对偶回归网络是对下采样核的估计,通过下采样模块通过卷积实现对Y的下采样,得到和输入一样大小的图像X′。
1.2 双回归网络闭环
设x∈X为LR图像,y∈Y为HR图像。
定义1(原始回归任务):寻求一个函数P:X→Y,使预测P(x)接近于其相应的HR图像y。
定义2(对偶回归任务):寻求一个函数D:Y→X,使D(y)的预测接近于输入的LR图像x。
双回归网络模型学习原始映射P来重建HR图像,并学习对偶映射D来重建LR 图像,如图2 所示。原始和对偶学习任务可以形成一个封闭的环,训练模型P和D以提供额外的监督。如果P(x)是正确的HR 图像,则其下采样得到的图像D(P(x))应非常接近输入的LR图像x。
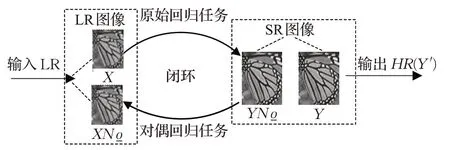
图2 原始回归任务和对偶回归任务形成闭环Fig.2 Original regression task and dual re-gression task form closed loop
提出的双回归方案超分辨率模型表示如下:
给定M个未配对LR 样本和N个配对样本,模型训练损失可以写成:


设P∈P,D∈D,其中P、D 分别表示原始回归和对偶回归映射函数空间。对于本文的双回归方案,对于∀P∈P,∀D∈D,其泛化误差(期望损失)为:
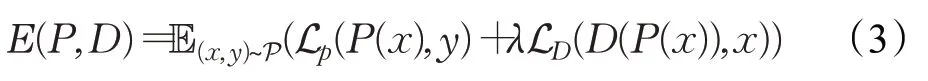
其经验损失为:
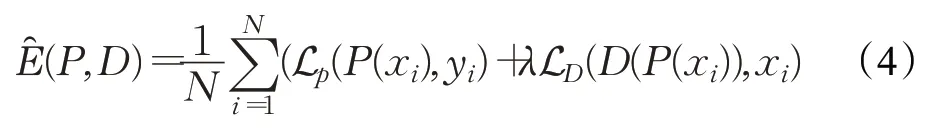
对于样本空间Z=(z1,z2,…,zN),其中zi=(xi,yi),双回归方案的Rademacher复杂度为:

设Lp(P(x),y)+λLD(D(P(x)),x)为X×Y到[ ]0,C的映射,上界为C,映射函数空间Hdual为无穷,Hdual∈P×D。且对于任意δ>0,至少有1-δ的概率使以下不等式成立:
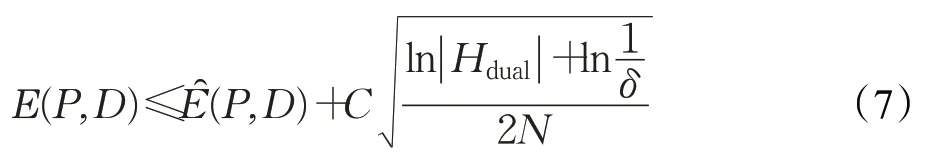
根据Rademacher复杂度的推论3.1[18]得:
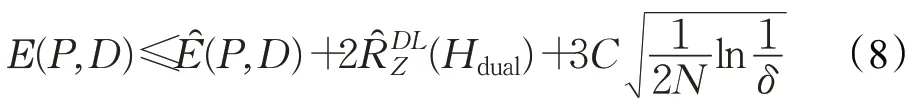
设B(P,D)为双回归方案的泛化界,则:
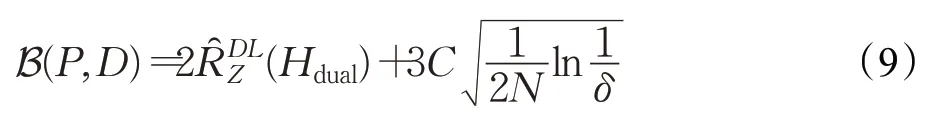
对于原始回归方案,即当泛化误差式(3)中λ=0时,其泛化界为:
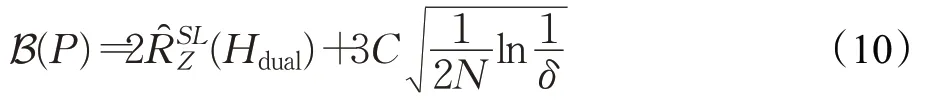
其中为原始回归的经验Rademacher复杂度。
由于Hdual∈P×D的函数空间小于Hdual∈P 的函数空间,根据Rademacher复杂度原理:

则:

上述结果证明了引入对偶回归方案后模型的泛化界依赖于函数空间的复杂性,加入对偶回归的双回归SR 方案比未加入对偶回归的SR 方法具有更小的泛化界,即在原始回归基础上加入对偶回归有助于减少LR→HR 的可能映射空间,使模型实现更准确的SR 预测,并且当训练数据足够多时,双回归模型的泛化界越精确。
1.3 残差块结构
残差块结构如图3。输入通过傅里叶变换得到其频谱图,提取高频部分,通过反傅里叶变换得到图像对应的高频部分。残差块有三个并行的特征提取块,每个特征提取块有两个卷积层和一个ReLU激活层,激活层位于两个卷积层中间。特征提取块对输入及其两个不同层次的高频部分进行特征提取,特征提取块输出级联经过局部特征融合后结合残差作为残差块的输出。
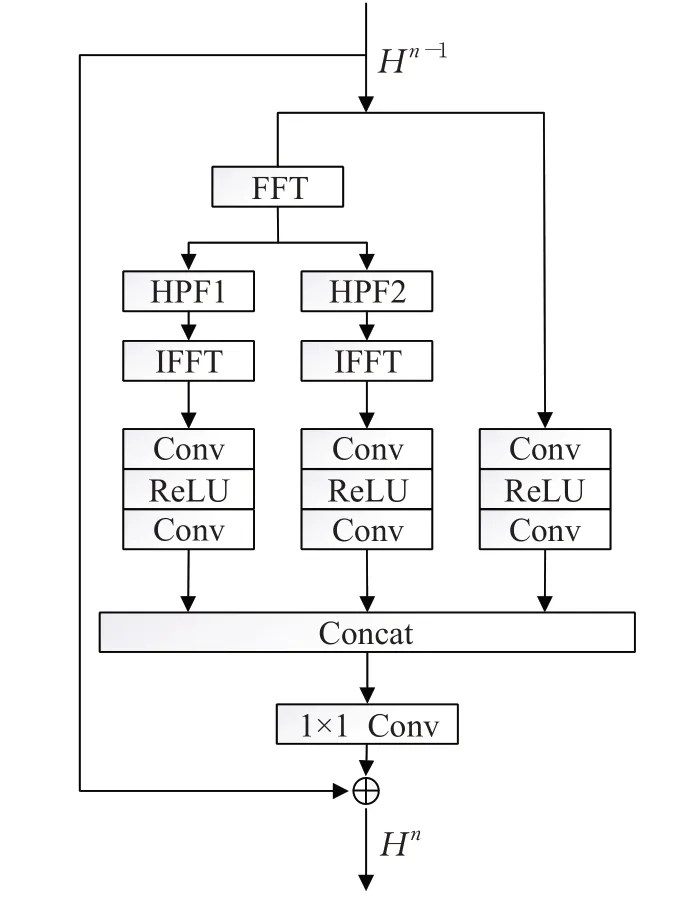
图3 残差块结构Fig.3 Architecture of residual block
定义Hn为第n个残差块的输出,则第n个残差块的结构表示如下:
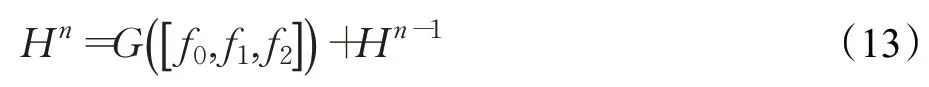
其中[f0,f1,f2] 表示局部特征的级联操作,f0表示残差块的输入Hn-1的特征,f1表示Hn-1经过第一次傅里叶变换后的高频部分特征,f2表示Hn-1经过第二次傅里叶变换后的高频部分的特征,G(⋅)表示1×1卷积操作。
残差结构的特征提取过程表示如下:
输入Hn-1的特征提取:

其中φi(⋅)(i=1,2)表示卷积操作。
输入Hn-1的高频特征提取:
输入Hn-1并行经过两个高通滤波器,输出其不同层次的高频部分,高通滤波器输出表示如下所示:

其中FFFT(⋅)表示快速傅里叶变换,ψi(i=1,2)为高通滤波操作,gi为Hn-1经过高通滤波器后的高频谱图,gi进行反傅里叶变换FIFFT(⋅)后作为特征提取块的输入。

则对应特征可以表示为:

其中(⋅)(i,j=1,2)表示卷积操作。与全局特征融合类似,每个残差块内部对输入及其不同层次的高频部分的特征进行局部特征融合。
每个残差块的输出表示为:
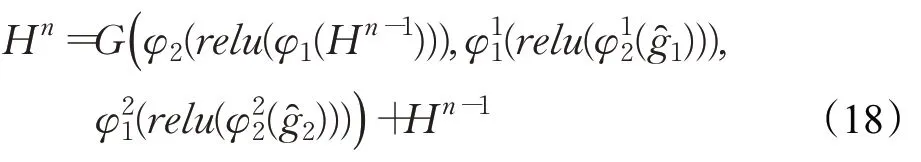
LR 图像与HR 图像的差别主要表现在图像的高频区域,表现为图像的纹理细节等。而图像的高频特征通常在网络的深层才开始学习的到。
对图像进行傅里叶变换时选取不同的滤波器可以得到不同层次的高频部分如图4,通过在残差结构中加入傅里叶变换提取输入的高频区域,可以使模型在浅层网络就能学习通常需要深层网络才能学习到的高频信息,使模型通过较少的层数和参数达到深层模型的性能。
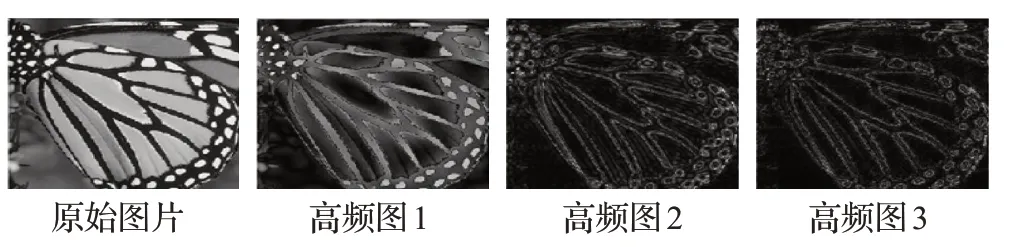
图4 通过不同滤波器得到的图像高频部分Fig.4 High-frequency part of image obtained by different filters
2 实验
2.1 实验设置
(1)参数设置。网络中基本块的卷积核大小均设置为3×3,边缘补0 确保输入和输出的大小一致。在下采样模块中,输出尺寸变为输入的一半。网络残差组数量设置为16。
(2)训练设置。采用DIV2K+Flickr2K[19]作为训练数据集,从训练集中随选择100 个图像,并使用不同的下采样方法获取LR图像。通过对训练集图像进行下采样来获取配对合成数据。考虑到现实世界中的SR 应用,所有配对数据都属于未配对数据不同的区域。图像块的尺寸设为64×64,即训练模型时低分辨率图像X及高分辨率图像Y尺寸为64×64。使用L1 型损失函数,初始学习率设置为1E-4,优化器在SGD 基础上使用指数衰减学习率。
对于合成配对数据,采用有监督的SR 方法的训练方式。使用配对数据集时,损失函数式(2)中的指示函数1SP(xi)等于1。使用未配对数据时,损失函数式(2)中1SP(xi)等于0。对于每个迭代,分别从数据集中取样m对未配对的真实世界数据和n对配对合成数据,将未配对数据的比例定义为ρ=m/(m+n)。
(3)测试设置。在3个基准数据集上比较了多个方法的效果,包括SET5[20]、SET14[21]和MANGA109[22]。模型结果测试使用每个测试数据集的所有图像。其中SET5有图像5 幅,SET14 有图像14 幅,MANGA109 有图像109幅。采用了峰值信噪比(peak signal-to-noise ratio,PSNR)和结构相似度(structural similarity,SSIM)作为评价指标。
2.2 与先进方法的比较
2.2.1 主观质量比较
比较提出的方法与最先进的SR 方法的主观评价。从图4可以看出,Bicubic为下采样后的图像,相比于HR图像,SRCNN算法的纹理细节重建效果较差,重建结果纹理模糊且出现重叠,没有重建出清晰的边缘。SRGAN算法的重建结果相比SRCNN算法区域更清晰,但出现模糊边缘和重影。RCAN 算法的重建结果和双回归算法重建结果相近。RCAN 算法和双回归算法的重建结果有丰富的纹理细节,且双回归算法边缘更清晰,出现更少的重影和模糊。图5 的对比结果表明:双回归算法重建的图像拥有丰富的纹理细节和清晰边缘,重建图像出现更少的模糊和重影。表明提出的双回归网络超分辨率算法具有良好的重建效果。
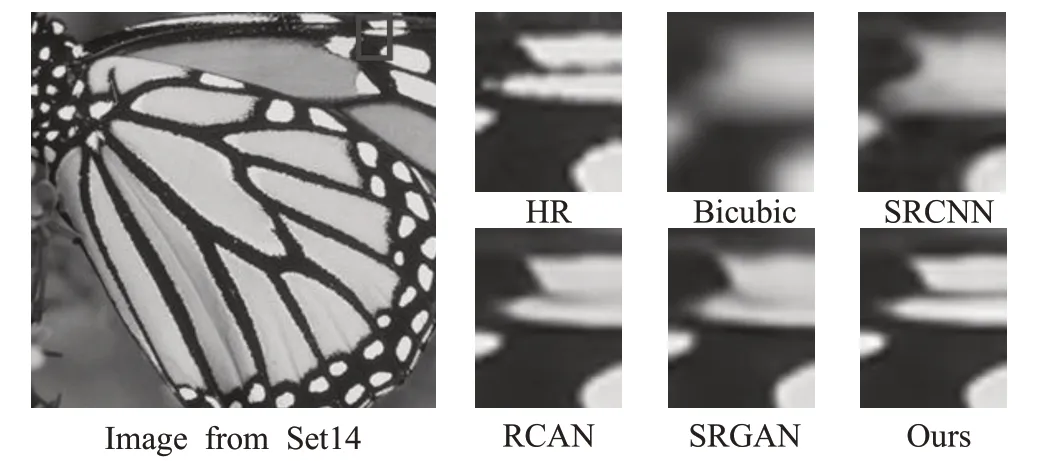
图5 不同方法在测试集上4×SR重建效果对比Fig.5 Comparison of 4×SR reconstruction on test sets by different methods
2.2.2 客观质量比较
比较提出的方法与先进的SR 方法的数据对比结果。在此比较了多种方法在4×SR 下的PSNR 和SSIM值,比较结果如表1所示。
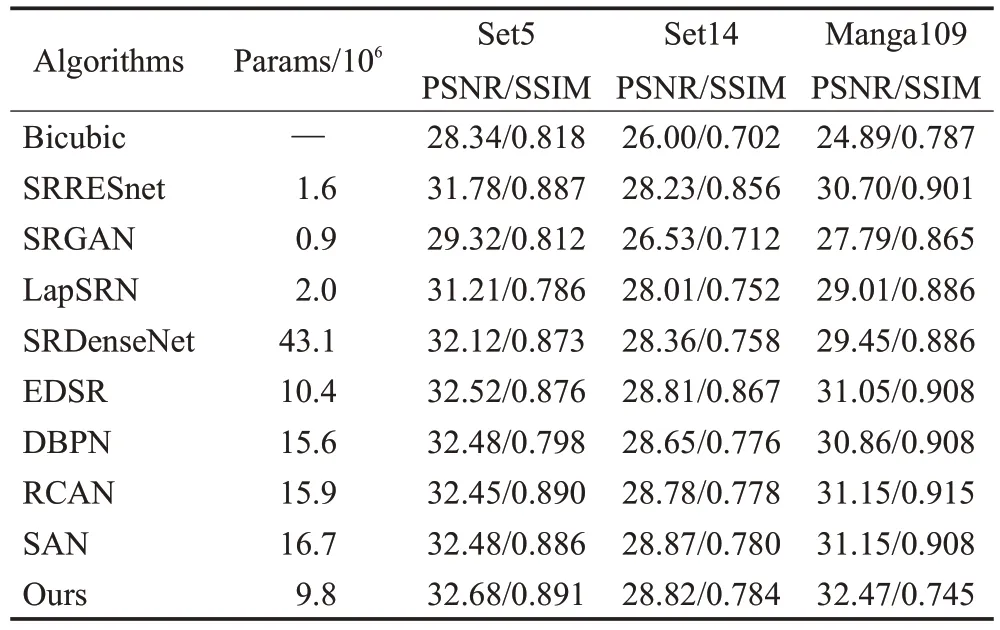
表1 与先进的4×SR算法的性能比较Table 1 Performance comparison with advanced algorithms on 4×SR
从表1 来看,SRGAN 方法只有90 000 的参数量,可能是由于对抗生成网络在参数量方面的优越性;DBPN、RCAN和SAN的参数量都在16 000 000左右,而本文提出的模型因为使用了傅里叶变换,使用了相比于其他模型更少的网络层数使得模型的参数量只有10 000 000。通过表1 可以看出:本文提出的双回归模型虽然只有大约10 000 000的参数,却产生了更好的性能,表明了本文所提出的双回归方案的优越性。
通过表2可以发现,在测试集Set5和Set14上,ESPCN方法的测试时间要快得多,可能是因为该方法模型深度相对较少;SAN 比ESPCN、SEGAN 慢很多可能是因为SAN方法网络层数较深;本文方法要比SRGAN快1 s左右,比SAN快2 s多,表明本文方法的优越性。

表2 不同超分辨率重建方法4×SR测试时间对比Table 2 Comparison of testing time for eachsuper-resolution reconstruction method on 4×SR s
2.3 消融实验
为了验证对偶回归网络对原始回归的约束作用,去除双回归模型的对偶下采样部分,只使用原始回归网络进行训练。以PSNR作为评价指标,在测试数据集Set5、Set14、Managa109上与双回归方法进行比较,表3为4×SR的结果。
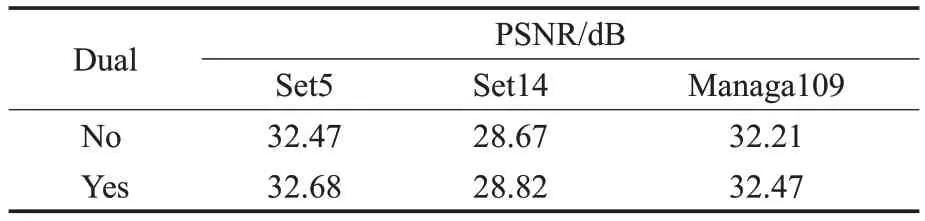
表3 加入对偶回归对4×SR的影响Table 3 Effect of adding dual regression on 4×SR
结合表1、表3的对比结果可以看出:在去除对偶回归部分时,模型在Set5 测试集上拥有和SAN 方法相近的性能且优于其他方法;在测试集Set14上,模型优于大多数方法,SAN方法表现最优;在测试集Managa109上,模型表现优于其他方法1 dB 左右,但SAN 最优。加入对偶回归之后,相比于没有加入对偶回归时,在测试集Set5、Set14 和Managa109 上性能均有提升。在Set5 上,本文优于所有对比方法;在Set14上,SAN方法有最好的重建性能,但本文的双回归方法只比SAN 方法低0.05 dB;在Managa109 上,本文的双回归方法拥有最好的性能且优于其他方法0.7 dB以上。
对比结果表明,配备了双回归方案的模型相比没有配备对偶回归的模型在所有测试数据集上都有更好的性能。说明通过引入额外的约束来减少映射函数的空间的方案是有效的,可以帮助改善HR图像的重建质量。
为了评估模型对未配对数据的自适应性能,比较了4×SR时不同方法采用Nearest(最邻近插值)和BD(bicubic degradation,双线性三次插值)下采样方法的PSRN 和SSIM 值。从表4 中可以看出,模型在所有数据集上的性能优于有监督方法。
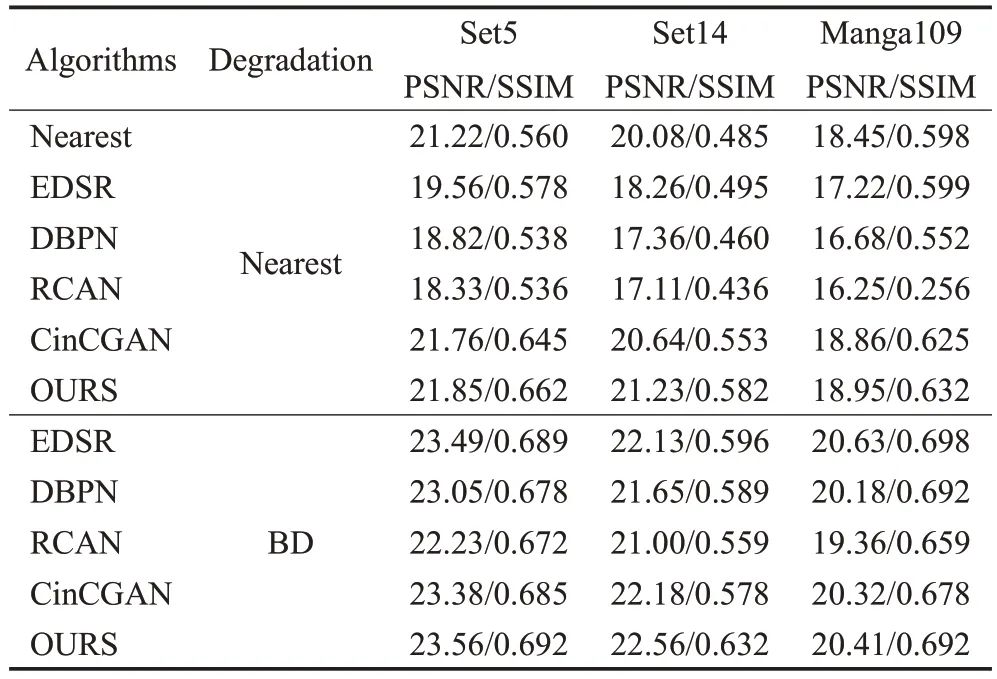
表4 模型对不同下采样方法图像的自适应性能Table 4 Adaptive performance of model to images of different downsampling methods
2.4 λ 对模型的影响
λ控制双回归网络中原始回归网络和对偶回归网络的权重。对表5 可以看出,在双回归网络上,当λ从0.001增加到0.1时,网络的对偶回归损失逐渐变得越来越重要。进一步将λ增加到1或10,对偶回归损失将压倒原始回归损失,最终阻碍模型的性能。为了在原始回归和对偶回归之间得到良好的权衡,在具体实践中将其设置为λ=0.1。

表5 超参数λ 对4×SR的影响(测试集:Set5)Table 5 Effect of hyperparameter λ on 4×SR(Test set:Set5)
2.5 ρ 对自适应算法的影响
在引入对偶回归后,因为模型可以不依赖于HR 图像,所以模型可以使用监督学习、半监督学习或无监督方式对模型进行训练。考虑到未配对数据主导实际应用中的超分辨率任务,本文使用半监督学习方法训练模型,同时对比了使用无监督和监督学习方式训练的模型在测试集Set5上的性能表现。
使用ρ表示未配对数据的比例,ρ=m/(m+n),其中m为未配对数据数量,n为配对数据数量。图6中显示了当改变未配对数据的数据比率ρ时相应的训练曲线。
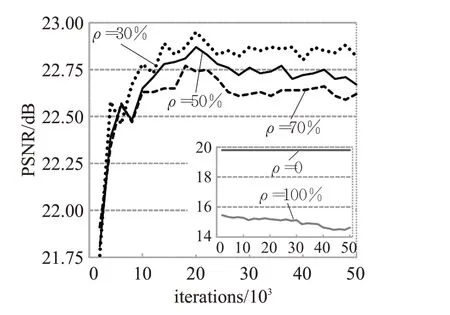
图6 不同数据比例下模型的性能Fig.6 Performance of model at different data scales
通过图6 可以看出:当ρ为0 即使用监督训练方式时,双回归方案的性能随着迭代次数的增加无明显变化,表明双回归方案不适合使用监督学习方式训练。当ρ为100%即无监督训练方式时,双回归方案的性能随着迭代次数的增加逐渐下降,表明双回归方案不适合监督学习方式训练。因此本文使用半监督学习方式训练模型。从图6可以看出,当设置ρ∈{30%,50%,70%}时,所得到的模型获得更好的性能。在具体实验中,本文设置ρ=30%以获得最佳性能。
2.6 傅里叶变换的作用分析
为了分析在残差结构中引入傅里叶变换对模型提取高频信息的提升作用。本文对比了在相同网络架构下,残差结构引入傅里叶变换与不引入傅里叶变换时残差块对高频细节的提取能力。
从图7和图8可以看出,在相同的网络深度上,使用傅里叶变换的残差块输出的特征相比于没有傅里叶变换的残差块拥有更丰富的纹理细节特征。而且在未加入傅里叶而变换时,随着网络层数的加深,网络会逐渐丢失高频信息,导致特征融合的结果缺乏一部分纹理的信息,而加入傅里叶变换时网络中的高频信息可以在网络层数加深时保留更多的高频信息,特征融合结果可以表明该方法提取和传递高频信息的有效性。
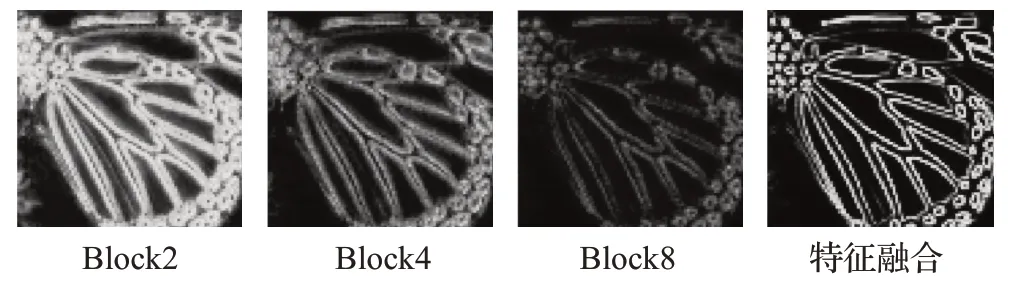
图7 残差块中未加入傅里叶变换的特征Fig.7 Features without Fourier transform
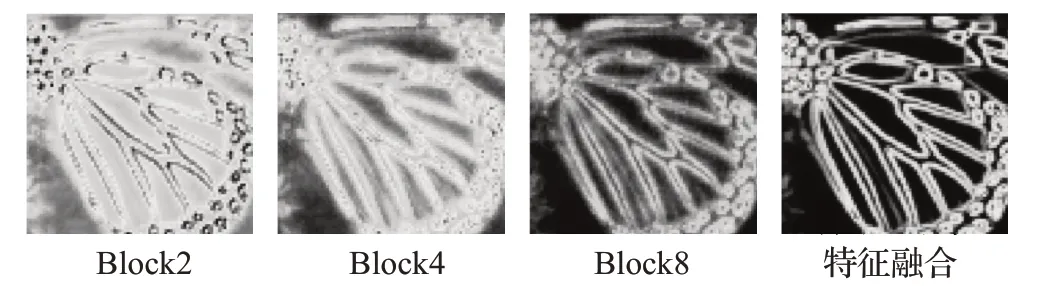
图8 残差块中加入傅里叶变换的特征Fig.8 Features with Fourier transform
3 总结
提出一种使用配对数据和未配对数据共同训练的双回归网络方案。对于配对数据,通过重构LR 图像对其引入一个额外的约束,以减少可能的映射函数的空间,可以显著提高SR 模型的性能。使用未配对数据训练解除了特定方法配对数据对模型的限制,使模型更好地适用于实际应用中的超分辨率任务。在配对和非配对数据上的实验表明,提出的方法对图像纹理细节重建具有良好的效果,且比同类方法拥有更少的参数量。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
自动化学报(2019年6期)2019-07-23 01:18:32
数学物理学报(2019年2期)2019-05-10 11:32:38
测控技术(2018年7期)2018-12-09 08:58:26
舰船科学技术(2016年1期)2016-02-27 15:39:21
应用数学与计算数学学报(2015年1期)2015-07-20 11:39:06
电测与仪表(2015年5期)2015-04-09 11:30:44
河南科技(2015年8期)2015-03-11 16:23:52
数学年刊A辑(中文版)(2014年4期)2014-10-30 01:50:38
