
异构集群节点与作业特性感知资源分配算法
2022-09-21 05:38:36胡亚红吴寅超朱正东李小轩
计算机工程与应用 2022年18期
胡亚红,吴寅超,朱正东,李小轩
1.浙江工业大学 计算机学院,杭州310023
2.西安交通大学 计算机学院,西安710049
随着大数据时代的到来,用户产生的数据呈指数级增长。单一节点已经满足不了数据处理的需求,传统的计算模型也无法满足大数据处理的性能和效率要求,故Hadoop[1]、Spark[2]和Storm[3]等分布式框架应运而生。在这些框架中,Apache Spark由于其出色的性能和丰富的应用程序支持而成为通用且最受欢迎的大数据处理平台。与其他的平台相比,Spark 在性能上有着较大的优势,例如Spark的运行速度是MapReduce框架的数十倍[4-5]。
Spark提供了几种部署模式,包括Local、Standalone、Spark on YARN 和Spark on Mesos 等。它的调度策略根据运行层次可以分为application scheduling、job scheduling、stage scheduling 和task scheduling 等[6]。以上的四个调度策略,除了application scheduling 是对用户作业(也称为应用)的调度,其余三个都是系统较为底层的调度。Standalone 模式中,默认的多作业任务调度方式采用FIFO 或FAIR 两种策略,资源调度算法则有SpreadOut和非SpreadOut[7]。这两种资源调度算法采用了非常简单的逻辑,即通过对比作业的资源需求以及节点的可用资源来进行调度。
由于分布式系统的复杂性,Spark 在实际运行环境中不能充分利用集群中计算机的全部性能,因此优化Spark 系统的执行效率非常重要,其中对于资源调度机制的研究已成为当前的研究重点。分布式框架的调度算法主要分为基于用户作业级别的调度和基于任务级别的调度。现在已有许多基于Hadoop 的相关研究工作,这些为进行Spark调度优化提供了良好的基础。
徐佳俊等认为随着硬件的更迭和高性能硬件的引用,集群的异构化现象日趋显著[8]。基于集群同质化假设提出的Spark原生调度策略已经无法适应集群的异构化,因此引入了分层调度的思想。调度算法综合考虑了任务复杂度、节点性能及节点资源使用情况等因素,实现了高效公平的任务调度。这个新的Spark调度策略虽然对系统性能的提升效果较为明显,但是其未考虑应用程序的类型和节点的实时处理能力的偏向性。
不同的用户作业对于集群资源的需求差异很大。针对这一问题,Xu 等提出了一种面向大数据平台的异构任务调度系统RUPAM[9],该调度系统考虑了任务级的资源特性、节点的硬件特性和数据本地性,有效提升了集群的性能。
Spark 集群的异构性会导致集群计算资源的不均衡,而Spark 默认的调度算法在任务调度时未考虑集群的异构性以及节点资源的利用情况,影响了系统性能的发挥。针对该问题,胡亚红等利用节点的优先级来表示其计算能力,提出节点优先级调整算法来动态调整任务执行过程中节点的优先级,并提出基于节点优先级的Spark 动态自适应调度算法,根据实时的节点优先级完成任务的分配[10]。
杨忙忙提出了均衡-饱和度的概念以衡量程序运行时节点资源的有效利用率。该定义不仅可以量化CPU与内存资源使用的均衡性关系,还能够量化资源的有效利用率[11]。
丁晶晶等认为Spark的资源调度方式和资源的利用率直接关系到集群的效率。他们提出的新的调度算法通过综合考虑工作节点资源实时利用情况、节点CPU处理速度和CPU剩余利用率等以进行资源的调度与分配,能够满足Spark 系统的高并发请求、低延迟响应,同时也减少了资源利用倾斜现象,提高了资源的利用率[12]。该算法考虑了集群中节点的实时资源使用情况,并根据得到的集群状态进行资源的分配,但是未考虑异构集群中的节点处理不同类型的用户作业的能力不同。
为了满足硬实时调度的需求,Wang 等提出了一种新的硬实时调度算法,称为DVDA(deadline 和value density aware)[13]。与仅考虑截止日期的传统EDF(earliest deadline first)算法相比,DVDA算法同时考虑应用的截止期限和值密度。在YARN 上实现的基于DVDA 的Spark调度实验验证了算法的有效性。该算法将用户作业的截止日期加入到算法的评价体系,但是没有考虑集群中节点的实时资源使用状况。
Cheng 等提出了一种资源和期限感知的Hadoop 作业调度算法RDS[14],该算法能够在最小化作业期限错失时考虑将来的资源可用性。RDS 设计了一个自学习模型来估计作业完成时间,并使用一个简单但有效的模型来预测将来的资源可用性。
为解决电力供应受限集群中的任务调度问题,Kumbhare 等提出了基于任务价值的任务调度方法[15]。该算法首先预测出所有待执行任务在所有可能的资源配置条件下的运行时间;之后计算每一个任务在每种资源配置条件下能够获得的价值。算法挑选出获得价值最大的任务,为其提供所需的最优集群配置,进行任务的执行。
异构集群中并行执行的任务会争用集群中的资源,从而导致集群性能的下降。Zhang 等提出的基于强化学习和神经协同过滤的两阶段任务调度方法,通过对任务进行分割来解决上述问题。其学习驱动的负载并行化算法能够为相互独立的任务找到适合的运行节点[16]。
默认的Spark资源调度方法将重点聚焦于合理分配计算资源,却未考虑网络资源,这可能会使网络延迟变大,降低集群性能。针对该问题,Du等提出了一种任务完成时间感知的章鱼调度优化方法OctopusKing[17]。该算法考虑了节点的异构性、每个任务的数据量和计算复杂度以及网络传输等四个影响因素,采用深度学习方法来预测任务完成时间,较为有效地减小了任务的运行时间并提高了集群资源利用率。
异构集群中影响数据本地性的不仅仅是网络带宽,另一重要影响因素是存储设备的差异,如选用的是固态硬盘还是机械硬盘。忽略存储设备读写速度的差异,会导致高速存储设备的利用率低下,进而影响集群整体性能。因此,Pan等提出了一种基于异构存储集群的任务调度策略H-Scheduler[18]。该策略可以根据存储类型区分存储设备的速度,同时结合数据位置和存储类型来对任务进行优先级的排列,以减少作业执行时间。该调度策略考虑了存储设备速度的异构性问题,但未考虑影响节点性能的其他因素。
对于数据密集型任务,数据加载成本是影响任务完成时间的最主要因素。缓存中的数据有助于提高任务执行效率,因此需要最小化缓存未命中率。针对该问题,Meng 等提出了一种贪婪在线调度算法[19]。该算法综合考虑了负载平衡、数据相关性和数据本地性,解决了数据密集型任务的并行调度问题。但是它只考虑了数据密集型负载,对于其他类型的负载未加考虑。
现有的资源调度算法在给作业分配集群资源的时候没有同时考虑作业的类型(任务偏向)以及节点的处理能力(性能偏向),虽利用了具有可用资源的节点,但在多作业运行的时候,会造成一些节点在运行其不擅长类型的作业,导致系统较低的执行效率。为了解决上述问题,本文提出了用户作业类型及节点性能偏向感知的资源调度算法ATNPA(application type and node preference-aware scheduling)来进行用户作业层次的资源调度。在用户提交作业之后,该调度算法判断应用程序的类型并结合节点的实时处理性能来进行准确、高效的资源调度。
1 Spark主要运行模式及流程
Spark大数据框架采用了分布式计算的Master/Slave模型,其中Master 作为整个集群的控制端,主要负责Spark 的正常进行、应用管理与资源管理;Slave 的主要职责是接收Master的命令并进行用户作业的执行。
Spark框架中有两个核心的组件,即Driver和Worker。Driver是任务的调度器也是程序执行的入口,Worker是任务的实际执行者。在负载被提交到Spark 时,Driver首先将代码分发到各个Worker 节点,然后Worker 节点上的Executor工作进程对相应分区的数据进行处理,当处理完成后将结果返回给Driver进程。
目前,Spark的几种主要运行模式及其特点如下:
(1)local:主要用于开发调试Spark应用程序。
(2)Standalone:即独立模式,自带完整的服务,采用Master/Slave 结构,无需依赖其他的资源管理系统。为解决单点故障,可以采用Zookeeper实现高可靠性。
(3)Apache Mesos:运行在著名的Mesos 资源管理框架基础之上,该集群运行模式将资源管理交给Mesos,Spark只负责运行任务调度和计算。
(4)Hadoop YARN:集群运行在YARN 资源管理器上,YARN完成资源管理,Spark只负责进行任务调度和计算。
本文旨在优化Spark 集群的资源调度算法,因此选用了Standalone 模式。Standalone 模式下Spark 的运行流程如图1所示。
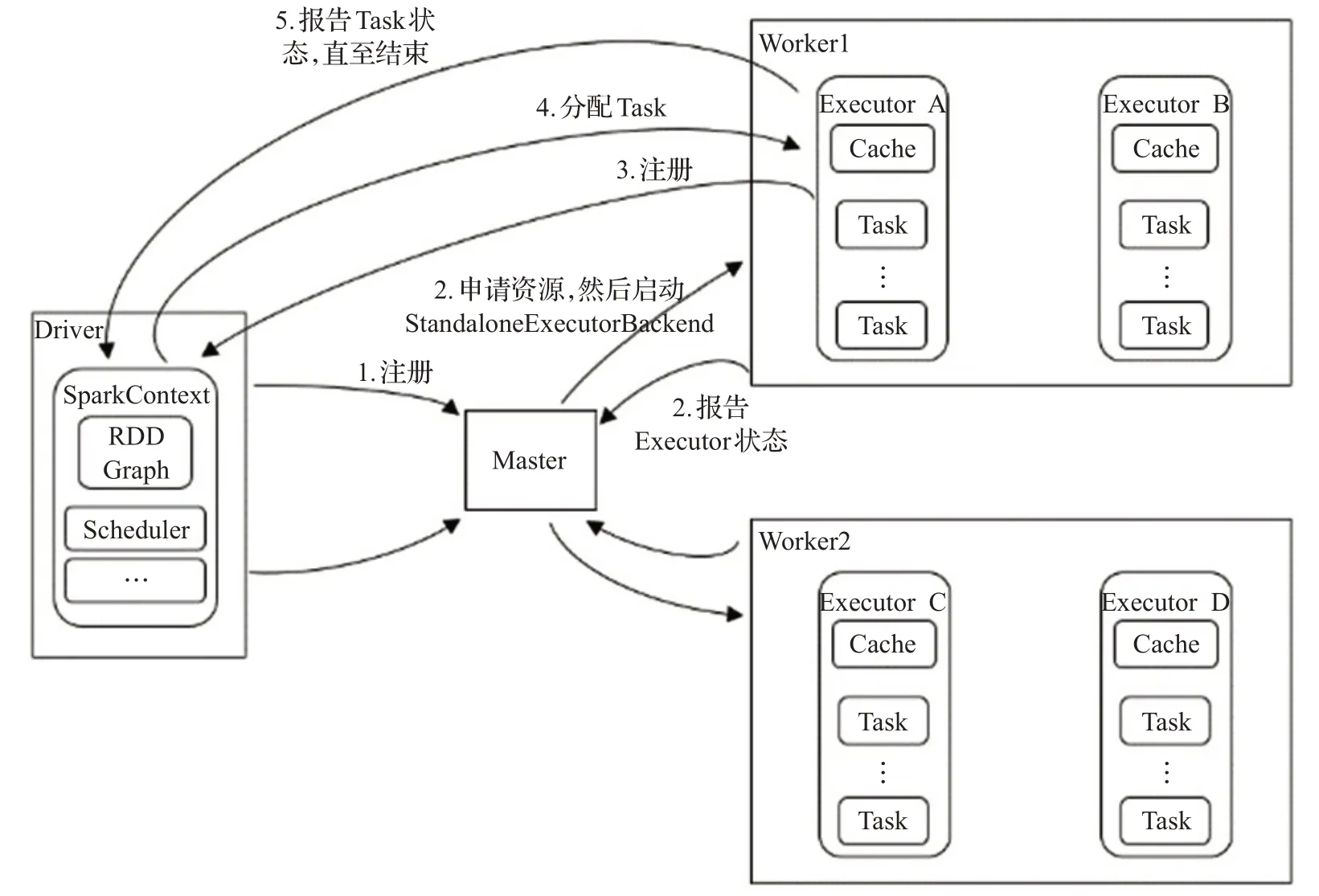
图1 Spark Standalone模式Fig.1 Operating mode of Spark Standalone
2 用户作业类型和节点性能偏向性感知的资源调度算法ATNPA
将用户作业匹配到最适合其特点的节点,能够充分发挥节点的性能,有效缩短作业的执行时间,提高节点吞吐量。下面分别定义用户作业类型和节点性能偏向性。
2.1 用户作业类型
现实应用场景中可以根据用户作业对计算资源的需求确定其类型。目前,运用较为广泛的用户作业类型有CPU密集型、内存密集型、I/O密集型和网络密集型等等。不同种类的用户作业对于集群资源的需求不同。用户在提交作业的时候,一般需要指定该作业运行所需的资源,如需要的CPU 核数、内存等。在Spark 默认的配置下,每个用户作业需要开启若干个Executor以满足其资源需求以及运行的并行度,从而提升作业执行效率。Spark默认每个Executor包含1个CPU核和1 GB内存[6]。
从用户作业层面上看,作业的类型是用户作业的固有属性。本文引入UAT(user application type)表示作业类型。
定义1 用户作业类型(UAT)
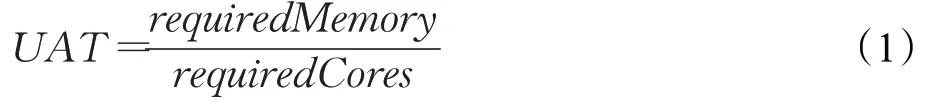
requiredMemory是作业运行所需的内存资源,requiredCores是作业运行所需要的CPU 核数,这两个参数由用户指定。UAT 阈值的选取对于判断用户作业的类型至关重要。使用不同的UAT值,本文使用ATNPA算法和Spark默认调度算法进行了大量的实验。图2给出了实验数据的分析结果。
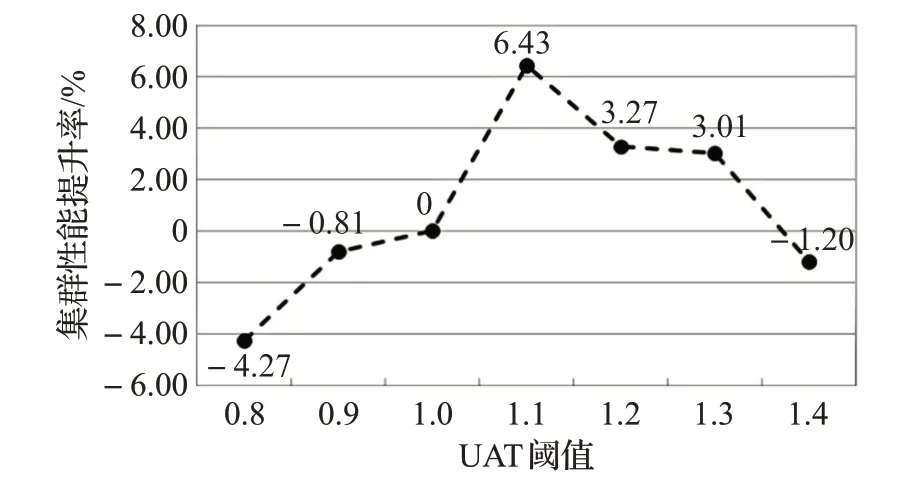
图2 不同UAT阈值对集群性能提升的影响Fig.2 Effects of UAT value to cluster performance improvement
可以看到,当UAT 的阈值取1.1 时,系统整体的优化效果最优。即当UAT ≤1.1 的时候,认定该作业为CPU 密集型,反之为内存密集型。ATNPA 将根据所得到的作业类型为其分配合适的集群资源。
2.2 节点性能偏向性
Spark默认调度策略仅依据CPU核数来完成节点选择,节点的内存量仅仅作为一个简单的比较参考,而节点的其他信息(如是否包含GPU、网络带宽等)都未被考虑。
随着集群异构性的增强,集群中各节点的处理能力相差很大。一些节点的CPU 处理能力非常强劲,故其在处理CPU 密集型的用户作业时,效率相较于其他节点会比较高;而有些节点具有较为高速的I/O读写能力,故而处理注重读写的用户作业会有更加优秀的表现。
因此需要进行节点对用户作业的偏向性分析。
定义2 节点偏向性(node preference type,NPT)
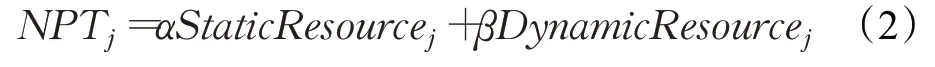
其中,StaticResourcej是节点j的静态资源值;DynamicResourcej是节点j的动态资源值;j∈{1,2,…,N},N为集群中节点个数。α、β分别是节点静态资源值和动态资源值的对应权值。
根据专家分析得到,节点的静态资源可以用CPU速度、CPU 核数、内存大小以及磁盘容量表示。节点的动态资源可以用其CPU剩余率、内存剩余率、磁盘剩余率及磁盘读写速度表示。
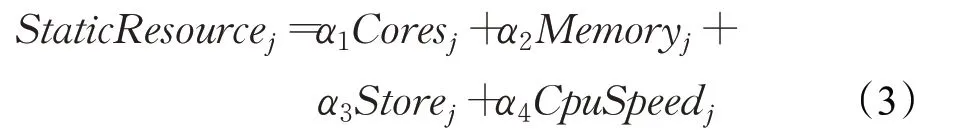
其中,节点静态资源各影响因素的权值α1+α2+α3+α4=1。Coresj是节点j的CPU核数;Memoryj是其内存总量;Storej表示磁盘容量,CpuSpeedj则是其CPU速度。

其中,节点动态资源各影响因素的权值β1+β2+β3+β4=1。AvaiCoresj是节点j的CPU剩余率;AvaiMemoryj是其内存剩余率;AvaiSSdSpdj是当前磁盘读写速度,AvaiSSdj是其磁盘剩余率。
2.3 节点性能偏向性各影响因素权值的确定
本文采用层次分析法(analytic hierarchy process,AHP)来确定影响节点性能偏向性的各因素的权值,层次结构模型如图3所示。
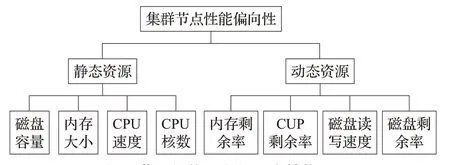
图3 节点性能偏向性层次结构模型Fig.3 Hierarchical model for node performance
经专家打分,静态因素的四个影响因素的判断矩阵如下:
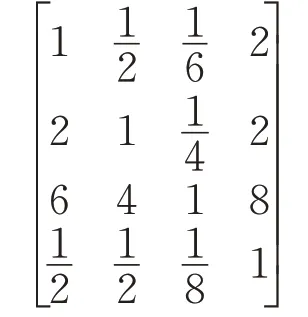
计算得到W=[0.113 0.641 0.073 0.173]T,对应的CR=0.017<0.1,满足一致性要求。
动态因素的四个影响因素经专家打分,构造出的判断矩阵如下:
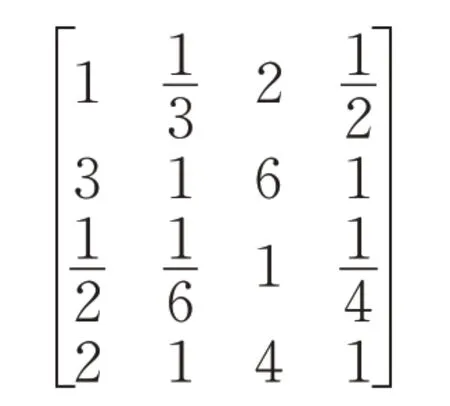
计算得到W=[0.344 0.422 0.156 0.078]T,对应的CR=0.008<0.1,满足一致性要求。
公式(2)中的静态资源值和动态资源值经专家打分生成的判断矩阵为:
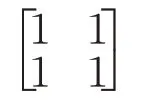
根据相同步骤,得到α、β分别为0.5和0.5。
因为使用AHP 计算得到的权值具有一定的主观性,因此,在后续的实验过程当中,将根据实验的运行结果对权值做出相应的调整,使作业运行时效率达到最优。
2.4 基于用户作业类型及节点性能偏向的资源调度算法ATNPA
为了提高Spark集群性能、缩短用户作业执行时间,本文设计了基于用户作业类型及节点性能偏向的资源调度算法ATNPA。因为集群是多用户共享的,所以会有很多的用户作业在队列中等待资源分配。ATNPA根据每个用户作业的类型计算当前集群中各节点的性能偏向,进而确定节点的优先级,并根据节点的优先级进行节点的选择和用户作业的分发,将用户作业分配到最适合作业特点的集群节点。ATNPA调度算法的实现框架如图4所示。
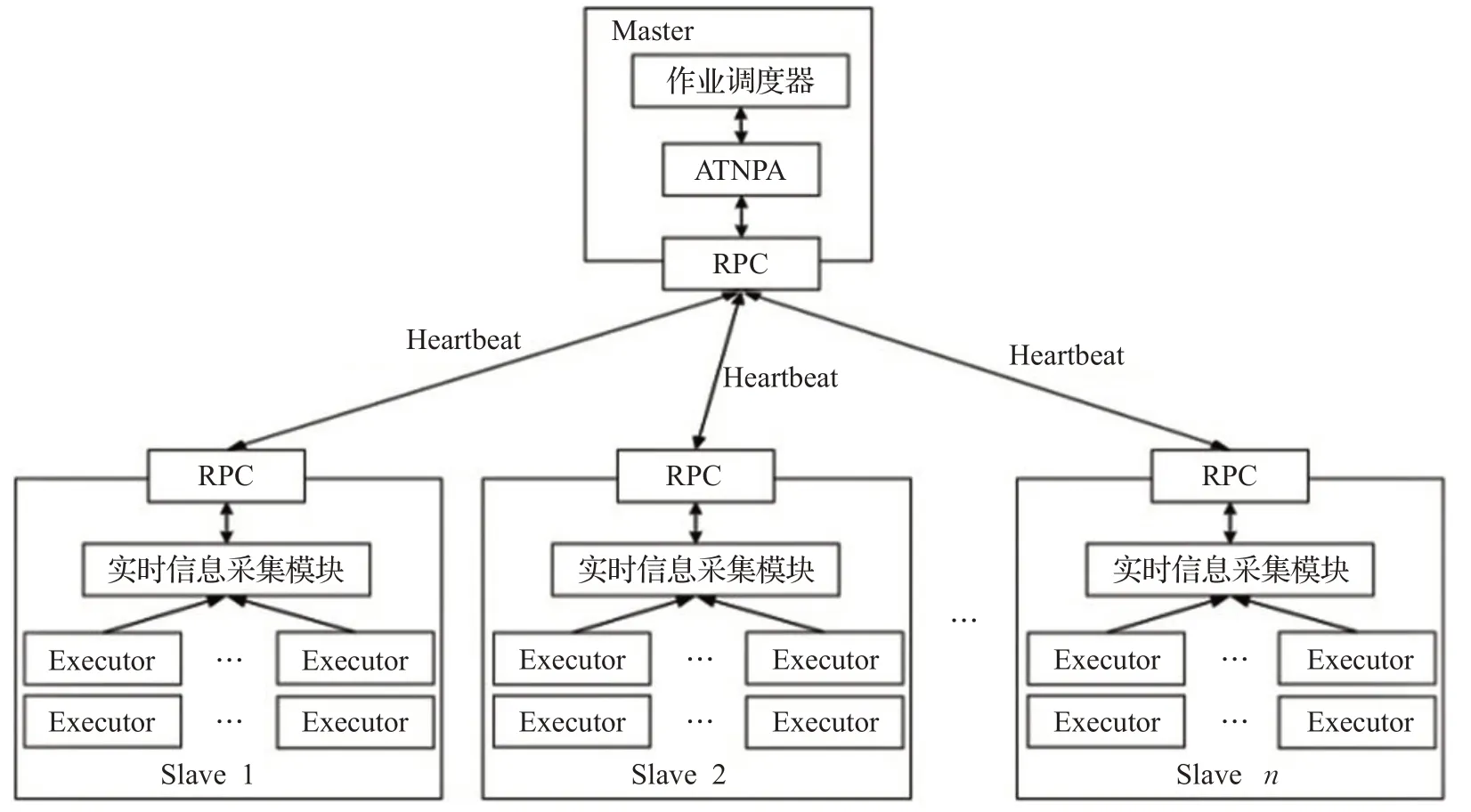
图4 ATNPA实现框架Fig.4 Implementation framework of ATNPA
Spark 集群启动时,Worker 节点向Master 提交资源注册消息。用户提交作业时需要提供所需的CPU核数和内存大小。当为一个用户作业进行节点资源分配时,ATNPA 算法根据各个作业提交的参数,计算出用户作业的类型,并在此基础上计算得到集群中各节点的实时优先级。ATNPA将用户作业分发至若干个高优先级的节点,直到满足用户要求的资源量。当集群中某个用户作业运行结束,Master会结合Spark心跳信息机制,自动获取各个Worker节点的现有资源状态并重新计算出节点的动态资源数据,更新节点的优先级,并为等待队列中的用户作业进行资源分配。
ATNPA算法的伪代码如下。

3 仿真实验
为了验证ATNPA 调度算法的有效性,本文分别进行了串行作业和并行作业的实验,下面将进行详细介绍。
3.1 实验环境
本文的实验环境如表1与表2所示。
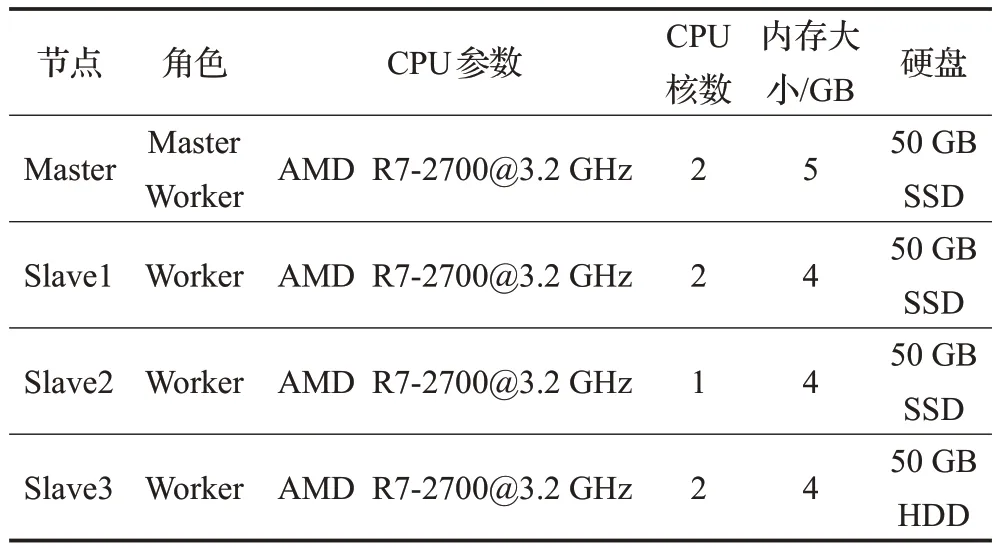
表1 仿真实验硬件配置Table 1 Hardware configuration of simulation experiments

表2 仿真实验软件配置Table 2 Software configuration of experiments
根据节点性能偏向性的定义,影响节点性能的主要因素包括节点的内存大小、CPU 核数、CPU 速度和磁盘读写速度等。在搭建仿真实验环境时,各节点在这些因素上取值都加以区分,以体现出节点性能的偏向性和集群的异构性。从表1可以看到,Master节点与其他节点内存容量不同;Slave2 的CPU 核数较少;Slave3 采用的是普通机械硬盘,而其他节点均采用了固态硬盘,这样可以体现出节点在存储设备读写速度上的差异。在小型物理集群实验中,各节点的CPU速度也有所不同。
3.2 实验数据集及权值计算
本文采用的负载来自于中国科学院计算技术研究所研发的基于大数据基准测试的开源性程序集Big-DataBench[20]。BigDataBench总共包含了14个真实数据集和34个大数据工作负载。本文从BigDataBench基准测试套件中选择了WordCount 和Sort 两种工作负载。选择WordCount 和Sort 的理由是这些工作负载简单易懂,可以代表基本的Spark 应用程序,具有广泛的应用性;同时它们在宏观上分表代表了CPU 密集型和内存密集型两类应用。
为了弥补层次分析法主观性强的缺点,本文通过具体的实验对影响节点性能的各项动态因素的权值进行了调整。针对CPU 密集型和内存密集型的任务,实验中各指标的权值如表3所示。
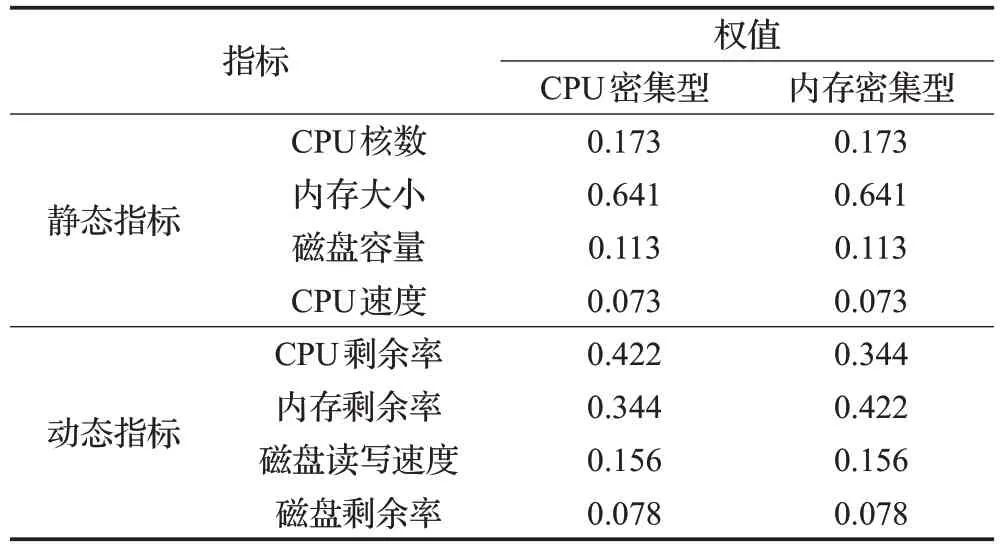
表3 不同类型作业对应的指标权值Table 3 Weighs of indexes under different type of tasks
3.3 实验过程
通过ATNPA 算法可以主动获取节点的资源状态,感知对应不同类型任务的节点的计算能力。本节根据仿真实验的配置,按照以下步骤展示ATNPA的执行过程。
(1)串行实验。按照串行的方式分别向集群提交用户作业Wordcount 和Sort,两种作业数据集的大小均为6 GB,其中Wordcount 要求CPU 核数为3,内存3 GB;Sort 要求CPU 核数为3,内存6 GB。根据公式(1)可以得到,WordCount 是CPU 密集型作业,Sort 为内存密集型作业。集群按照FIFO的顺序运行这两个用户作业。
(2)根据步骤(1)的提交顺序,通过公式(1)计算出用户作业的类型,再根据此类型使用公式(2)、(3)、(4)计算节点的优先级。之后按照优先级列表进行用户作业的分发。在串行运行作业开始时各个节点的优先级如表4所示。
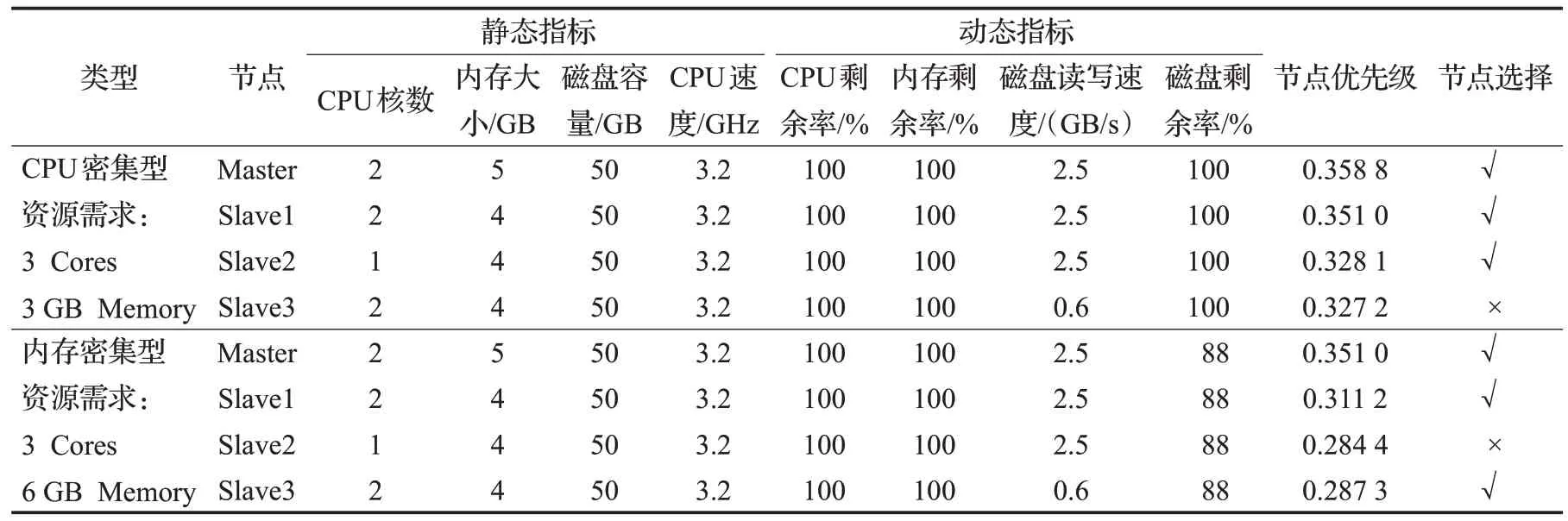
表4 用户作业串行运行集群节点优先级Table 4 Nodes priorities with serial user application execution
(3)并行实验。重启集群,按照并行的方式向集群提交WordCount和Sort的数据集。WordCount和Sort作业的具体要求与步骤(1)中描述的相同。集群按照并行的方式运行这两个作业。
(4)通过公式(1)计算出各用户作业的类型,再据此类型使用公式(2)、(3)、(4)计算集群中各节点的优先级,同时按照优先级列表进行用户作业的分发。在并行运行作业开始时,各个节点的优先级如表5所示。
从表4 和表5 给出的节点选择结果可以看出,针对不同类型的用户作业以及不同的运行模式(串行或并行运行),集群中的节点的优先级是不一样的,各节点的优先级会随着集群中作业的状态而发生改变。所以本文提出的ATNPA算法会根据用户作业的类型计算集群中节点相应的优先级,并根据此优先级把作业分配到最适合的节点,从而充分发挥节点的性能,缩短作业的完成时间。
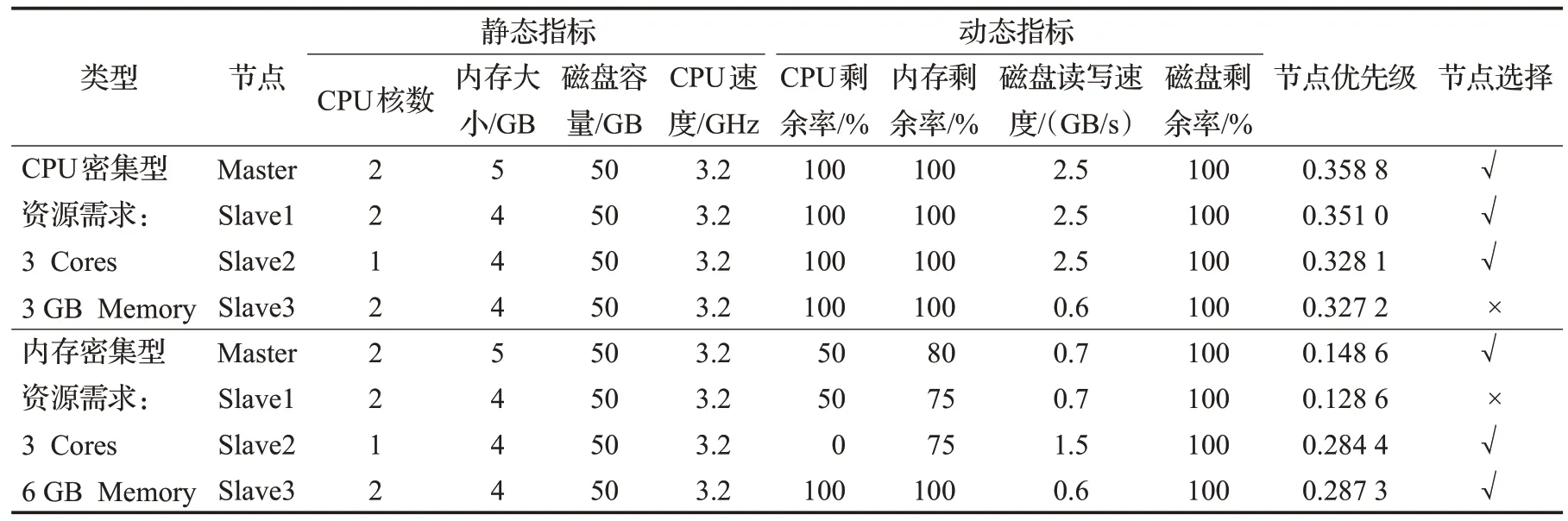
表5 用户作业并行运行集群节点优先级Table 5 Nodes priorities with parallel user application execution
3.4 实验结果
3.4.1 相同作业不同数据量
本小节选取了比较典型的WordCount和Sort任务,分别在使用Spark 默认调度算法和使用ATNPA 算法的Spark 集群中运行。任务采用不同规模的数据集,分别是2 GB、4 GB、6 GB、8 GB 和10 GB。每个数据规模实验5次,取平均值作为实验结果。实验结果如图5所示,图5中的横坐标代表不同的数据量,纵坐标表示完成整个用户作业所需要的时间。
从图5 可以看出,ATNPA 算法相较于Spark 默认的调度算法,可以将WordCount作业时间平均缩短8.33%;将Sort 作业时间平均缩短9.71%。因而无论是CPU 密集型还是内存密集型的作业,使用ATNPA 算法都能够有效缩短作业执行时间,提高集群的效率。
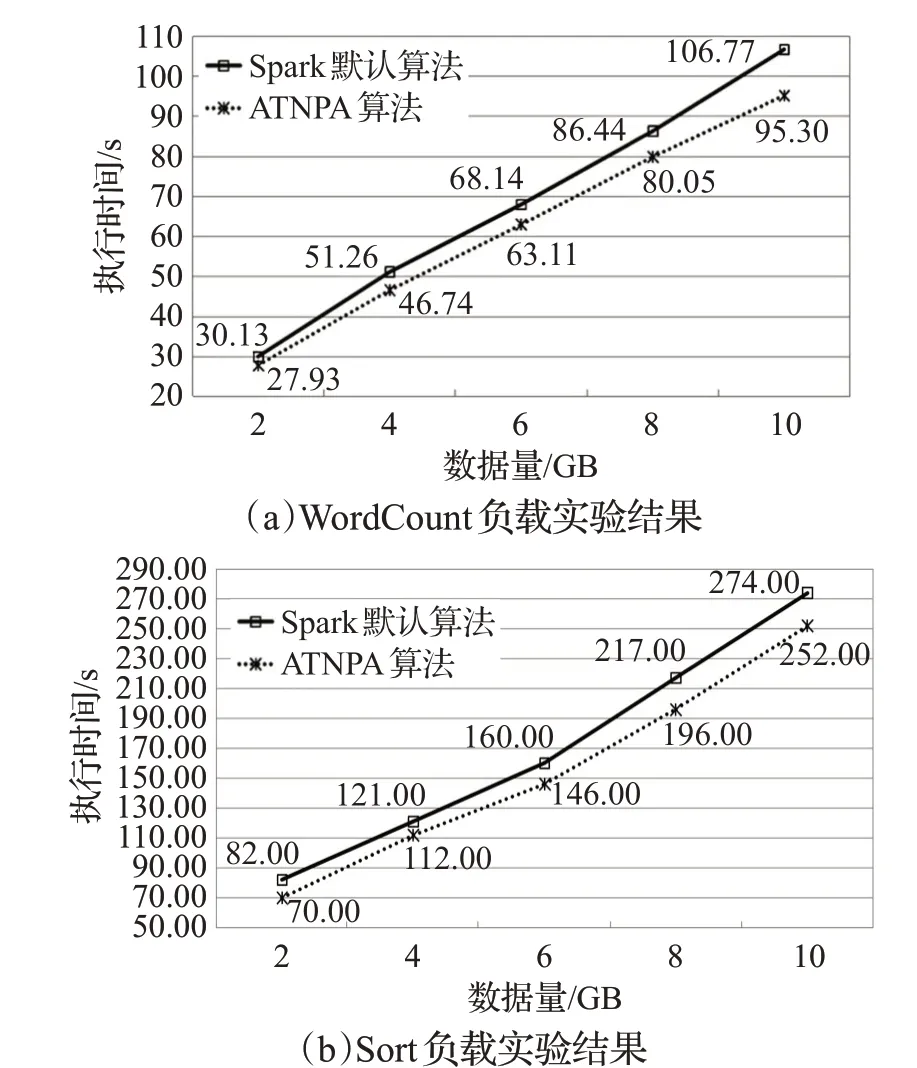
图5 相同作业不同数据量完成时间比较Fig.5 Comparison of completion time of same workloads with different amount of data
3.4.2 相同数据量不同负载并行实验
本小节同样选取了WordCount和Sort任务,让这两个负载进行并行运算来验证ATNPA算法处理并行作业的系统效率提升。每次实验两类程序采用等量的数据量,分别为6 GB、8 GB 和10 GB,每个数据规模实验5次,取平均值作为实验结果。实验结果图6所示。
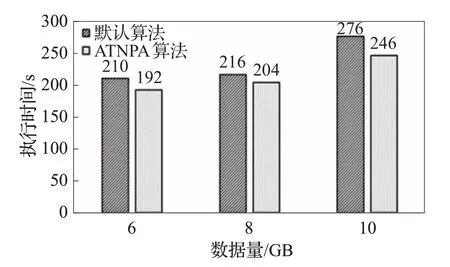
图6 WordCount和Sort负载并行运算时间比较Fig.6 Comparison of completion time when both WordCount and Sort are executed in parallel
从图6 可以看出,当WordCount 和Sort 两个负载进行并行运算时,相比于Spark 的默认调度算法,ATNPA算法有着平均8.33%的提升。
从并行和串行的实验结果分析表明,当集群一次运行一个用户作业或是同时运行多个用户作业时,由于ATNPA 能够为每个作业分配到最适合其特点的节点,因此作业的完成时间都能够减少,集群的性能从而得以提高。
4 结束语
目前关于Spark集群的资源调度算法没有充分考虑用户作业的类型和节点处理性能偏向性之间的关系。为了进一步提高Spark 集群的性能、有效地缩短作业运行时间,本文提出了ATNPA资源调度算法,它综合考虑了作业的特性和节点处理性能偏向性。仿真实验表明,与Spark默认的资源调度算法和没有考虑节点性能与作业类型相关性的SDASA算法相比,ATNPA能够有效提升系统性能,缩短作业的执行时间。未来的工作将在以下几个方面进行:
(1)目前本文考虑的作业类型只包括CPU 密集型和内存密集型,下一步研究将讨论更多的用户作业类型,如I/O密集型、通信密集型等。将引入机器学习等人工智能方法更加准确地确定用户作业类型的判定阈值。
(2)将增加节点动态资源影响因素,以便更加准确地确认节点在不同时间段的处理性能偏向。
(3)在大规模的集群上进行实验,以验证算法的有效性。
猜你喜欢
中国民间疗法(2021年1期)2021-04-20 02:30:48
铁道通信信号(2020年10期)2020-02-07 01:01:32
成都信息工程大学学报(2019年3期)2019-09-25 08:31:10
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
山东冶金(2019年3期)2019-07-10 00:53:56
三门峡职业技术学院学报(2019年1期)2019-06-27 07:32:58
电子制作(2018年11期)2018-08-04 03:25:40
酒·饮料技术装备(2018年1期)2018-04-28 09:09:07
中国交通信息化(2017年3期)2017-06-08 06:09:28
知识就是力量(2017年2期)2017-01-21 18:29:36
