
面向多目标跟踪系统的专用循环目标检测器
2022-09-21 05:38:02牛嘉丰石蕴玉戴佩哲
计算机工程与应用 2022年18期
牛嘉丰,石蕴玉,刘 翔,贺 桢,戴佩哲
上海工程技术大学 电子电气工程学院,上海201600
多目标跟踪(MOT)是对视频帧中多个目标的运动轨迹进行预测的一种方法,它的应用从无人驾驶到智能视频分析和视频摘要等的研究都有着重要意义。
解决MOT 问题的主要策略,即按检测跟踪方法将多目标跟踪分解为两个步骤:(1)目标检测步骤,将视频中各个帧的目标检测出来备用;(2)目标关联步骤,将检测到的目标区域匹配到现有轨迹或者作为轨迹起点。近年来,为了提高多目标跟踪任务的跟踪精度和跟踪速度,学者们针对按检测跟踪方法的两个步骤提出了一系列新的方法。步骤(1)中使用的目标检测器主要分为二阶段和一阶段目标检测器。对二阶段目标检测器,文献[1]使用了Selective search 方法选取候选框并分别进行分类和位置回归。在此基础上,文献[2]和文献[3]分别实现了端到端的训练方式、ROI Pooling 技术和候选框推荐网络(RPN)代替Selective search 选取候选框等优化策略,进一步提高了网络的训练速度和检测速度。文献[4]通过级联几个检测网络达到不断优化预测结果的目的,与普通级联不同的是,它的几个检测网络是基于不同IOU 阈值确定的正负样本上训练得到的。对一阶段目标检测器,文献[5]首先在图像上预定义预测区域,相当于在图像上画网格,并且每个网格有若干个不同大小和不同比例的预候选区域,每个网格负责预测中心点落在该网格的目标,由于其仅使用一个CNN 网络直接预测不同目标的类别与位置,所以检测速度很快。一阶段检测器检测速度比二阶段检测器要快,但两者在检测精度的性能表现却相反。步骤(2)的研究重点是提取目标的外观特征,如使用梯度直方图、颜色直方图和积分通道特征表示目标的外观特征。随着神经网络的发展,文献[6]训练了可以输出具有辨识度的目标外观特征的神经网络模型,并且在训练时引入了空间注意力机制。以上方法均一定程度上提升了目标外观特征的辨识能力,但对MOT系统而言,也多出了一些运算消耗。
为提高MOT系统的运行效率,设计了面向MOT系统的专用循环目标检测器(dedicated cyclic detector,DCD)。它以二阶段目标检测器为基础,提出了低参数量需求和低计算消耗的候选框推荐方法,替代了传统的RPN,使得检测器的检测速度有所提升,并且检测精度不受影响。同时DCD融入了目标外观特征提取分支共享了图像特征图,减少了计算消耗,进一步提高了MOT系统的运行效率。
1 专用循环目标检测器DCD
DCD 结构如图1 所示,其中C表示网络预测类别数,M表示选取的候选框数量的最大值,t代表帧号且最小值为2。DCD网络输入由当前帧图像、先前帧特征图和先前帧目标位置信息三部分组成。网络输出为当前帧特征图、目标类别位置信息和目标外观特征。DCD网络使用了CSPDarkNet-53[7]作为主干特征提取网络和路径聚合网络(PANet[8])生成多尺度特征图,PANet 后共生成四种尺度下的特征图,分别对应原图像1/4、1/8、1/16、1/32的下采样比例。DCD整体网络结构分为目标检测分支和外观特征提取分支,将分别在1.1节和1.2节介绍。

图1 DCD结构流程框图Fig.1 DCD structure flow diagram
1.1 目标检测分支
目标检测分支分为两个部分完成。第一部分的任务类似于搭建传统的二阶段目标检测网络并进行训练,第二部分的任务是用新的候选框选取方法替换RPN选取候选框,替换过程不涉及新参数的引入,不需要再次进行网络训练。
1.1.1 二阶段目标检测网络
搭建的二阶段检测网络与DCD网络的不同在于候选框的获取方法不一样,两种候选框的获取方法将在1.1.2节通过仿真图示说明。另外在anchor模板方面,根据数量,比例和纵横比设计anchor,以使其能够适应目标,即本例中的行人。根据共同的先验,将所有anchor的纵横比设置为3∶1。将anchor模板的数量设置为12,以使每个尺度特征图anchor 模板数量为3,并且anchor的宽度范围约为11到512。
类似于Faster-RCNN[3],网络的损失主要分为RPN和Fast-RCNN[2]的损失,并且两部分损失都包含分类损失和回归损失。
对于分类损失,由于RPN 分为前景和背景两个类别,Fast-RCNN 分为行人和背景两个类别,因此RPN 和Fast-RCNN 都使用了二分类交叉熵损失,计算公式如式(1)所示:

其中,pi是预测为行人的概率,0代表负样本,1代表正样本。
对于回归损失,RPN和Fast-RCNN都是对边框位置偏移预测形成的损失,所用损失函数为Smooth-L1 函数,计算公式如式(2)所示:

其中,ti={tx,ty,tw,th} 是一个向量,包含的元素分别表示边框的左上角横纵坐标以及宽和高的预测偏移量。是与ti维度相同的向量,表示边框左上角横纵坐标以及宽和高相对于真实框的偏移量。不同的是,RPN 和Fast-RCNN训练时σ的取值分别为3和1。
RPN 和Fast-RCNN 的损失函数由分类损失和回归损失加权融合而成,其计算公式如式(3)所示:
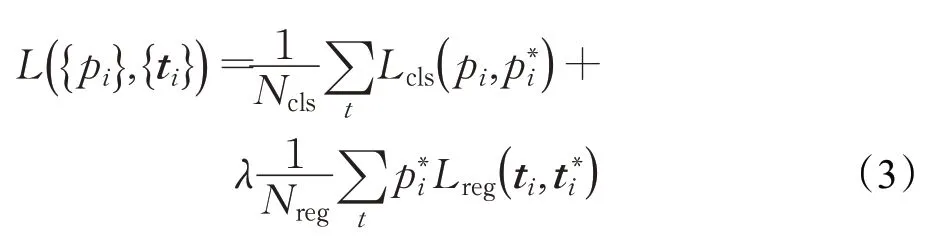
其中,RPN和Fast-RCNN训练时Ncls的值分别为256和64,Nreg取值和Ncls相同,λ值取1。
1.1.2 替换候选框选取方法
传统二阶段目标检测器的RPN结构和DCD检测器在图像t(1 024×1 024×3)的1/4下采样比例特征图上获取候选框的过程对比如图2 所示。不同于传统二阶段目标检测器的候选框来源于RPN,DCD 的候选框一部分由先前帧检测到的目标位置信息转化而来,另一部分通过度量相邻帧间的相似度来判断最容易出现目标的区域,进而选取出的候选框。对于后者,将这种候选框选取方法命名为D-RPN。

图2 候选框获取流程框图Fig.2 Block diagram of candidate frame acquisition process
D-RPN 计算了当前帧对于先前帧在不同尺度下的变化得分图(variation score map,VSM),其在k(k∈{1/4,1/8,1/16,1/32})尺度特征图上位置(i,j)处的得分计算如式(4)所示:

考虑到共有4 种不同尺度的VSM,且不同尺度VSM得分基准、先验框数量和大小都不同,所以候选框的选取需要在不同尺度VSM 上分别进行,记4 种不同尺度的VSM 尺度由浅到深依次为V1、V2、V3、V4。依据经验,不同尺度VSM 候选框选取过程中所需参数如表1 所示。例如对尺度V1 的后选框选取过程为:依据先验框得分依次选取4 000 组,每组先验框个数为6,随后在每组中随机挑选出一个先验框汇总后进行阈值为0.2 的极大值抑制(NMS),同时后选框个数最大值设为400。以上选取过程中分组时如果先验框数量不够则停止分组,极大值抑制后未达到候选框个数最大值时则补0。

表1 后选框选取参数表Table 1 Parameters of candidate boxes select
DCD检测器的候选框获取方法的计算消耗主要来自于D-RPN,但是相对于RPN的候选框获取方法而言,D-RPN的候选框获取方法不但不需要参数,而且减少了检测分支的计算消耗。通过计算可知,RPN 和D-RPN在特征图大小为256×256×256上选取候选框时,所需的参数量分别是119 万和0,所需浮点数计算次数分别是780 亿次和0.735 亿次。而且这只是其中一个尺度特征图的计算消耗对比,4种尺度都计算情况下这种差距还会进一步拉大。可见在候选框选取方法的计算消耗中,DCD检测器相较于RPN结构具有很大的优势。
1.2 外观特征提取分支
1.2.1 外观特征提取
外观特征提取分支共享了目标检测分支的多尺度特征图,并使用检测到的目标位置信息以ROIAlign技术获取目标特征块,并调节为统一的形状7×7×256。随后经过卷积和全连接操作后生成128维的目标外观特征。结构图如图3所示,其中N为图像中检测到目标的个数。

图3 外观特征提取分支结构Fig.3 Appearance feature extraction branch
1.2.2 损失函数
外观特征提取分支使用的损失函数如式(5)所示:
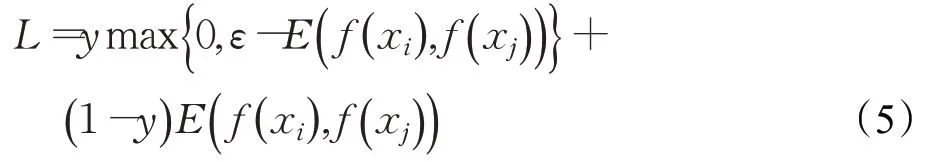
其中,E(⋅)表示f(xi)和f(xj)之间的欧式距离,f(xi)和f(xj)分别是目标xi和目标xj的128 维外观特征。y=0 时,代表两个目标相似,此时的损失值是两个目标外观特征的欧式距离;而y=1 时,代表两个目标不相似,当E(f(xi),f(xj))不小于边界值ε时,即认为两张图像的不相似程度非常高,损失值设为0,若E(f(xi),f(xj))小于边界值ε时,损失值为ε-E(f(xi),f(xj)),ε设为30。
2 实验
2.1 实验设置
实验硬件:处理器CPU为AMD Ryzen Threadr-ipper 1900X 8-Core 3.8 GHz,GPU为4×Nvidia GTX 1080Ti,内存RAM为64 GB,操作系统为Windows 10专业版。
2.2 数据集和评估指标
通过将6个关于行人检测、多目标跟踪和行人搜索的公开数据集组合在一起,为目标检测分支构建了大规模的数据集。这些数据集可分为两种类型:仅包含边界框注释的数据集,以及同时具有边界框和身份注释的数据集。第一类包括ETH[9]数据集和CityPersons(CP)[10]数据集。第二类包括CalTech(CT)[11]数据集、MOT-16[12]数据集、CUHK-SYSU(CS)[13]数据集和PRW[14]数据集。收集所有这些数据集的训练子集以形成联合训练集,并排除ETH 数据集中与MOT-16 测试集重叠的视频以进行检测性能的公平评估。以上步骤生成的联合数据集记为Data-A,其中图像的数量约为50 000,目标框的数量约为240 000,有ID标注目标框的数量约为8 500。
外观特征提取分支融合在了目标检测器中,是在完成了目标检测分支的训练,固定了目标检测分支的参数后才对外观特征提取任务进行训练,根据DCD 检测器的结构和外观特征提取分支的损失函数,外观特征提取分支的数据集的准备有如下两点要求:
(1)训练样本3 个为一组,每组中包含两幅相似图像,一幅非相似图像。
(2)训练样本的输入形式相当于图像经过目标检测后,检测目标在特征图上的映射特征。
为了满足以上两点要求,使用了公开的行人重识别(REID)数据集Market-1501[15]以要求a为条件选取N组图像,然后把每组的图像分别随机粘贴在具有固定尺寸的空白图像上(分辨率为1 024×1 024)。记录每组中图像的粘贴位置,这样就形成了N张具有相同背景且每张图像具有一组满足数据集要求a 的目标和位置已知的图像集。这些图像作为训练集进入网络后经过主干特征提取网络和ROI-Align步骤后得到的目标特征满足要求b。以上步骤生成的数据集记为Data-B,其中N约为16 000,Data-B数据集示例如图4所示。

图4 Data-B数据集示例Fig.4 Data-B demo
使用平均准确率(AP)和运行速度(FPS,帧每秒)作为专用循环目标检测器(DCD)的检测准确度和检测速度的评估指标。使用多目标跟踪准确度(MOTA)、ID F1分数(IDF1)、轨迹改变ID的次数(IDS)、大部分轨迹被跟踪到的目标占比(MT,80%的轨迹被跟踪到)、大部分轨迹跟丢了的目标占比(ML,跟踪到的轨迹小于20%)、运行速度(FPS,帧每秒)作为多目标跟踪系统的评估指标。其中MOTA指标计算如式(6)所示:

其中,mt、fpt、mmet分别是t帧时漏检、误检和错误匹配的数量,gt是t帧时真实框的数量。注意在计算MOTA时计算的是整个跟踪过程的平均值,而不是每一帧的结果。
2.3 实现细节
检测分支:1.1.1小节中二阶段检测网络共分为两个类别,即行人和背景。训练时输入图像通过加灰条的方式保持横纵比,分辨率调整为1 024×1 024,借鉴文献[3]中近似联合训练方式(approximate joint training)使用数据集Data-A 以Adam 优化器训练100 个Epoch,学习率初始化为0.01 并在第30、第60 个和第90 个epoch 时减少到原来的0.1 倍。采用了多种数据增强技术,例如随机缩放和色彩抖动,以减少过拟合,网络的损失收敛曲线如图5 所示。随后继续完成1.1.2 小节中候选框选取方法的替换工作。由于替换过程不需要参数,所以不需要进行额外训练。

图5 损失值曲线Fig.5 Curve of loss
外观特征提取分支:完成DCD检测分支的任务后,接入外观特征提取分支,冻结除外观特征提取分支以外的其他所有权重参数,使用数据集Data-B作为网络输入以SGD 优化器训练21 个epoch,学习率初始化为0.001并在第16、第19 个epoch 时减少到原来的0.1 倍。训练时输入图像分辨率为1 024×1 024。训练的损失值和准确率曲线如图6所示。

图6 损失值和准确率曲线Fig.6 Curve of loss and accuracy
2.4 实验结果分析
对于视频的初始帧,使用了候选框推荐结构改变前的目标检测器输出初始帧的特征图、目标类别和位置作为DCD检测器启动的条件。实验中起始帧检测不进行数据统计。
2.4.1 专用循环目标检测器DCD的消融实验
为了证明DCD在多目标跟踪任务上作为检测器的优势,做了专用循环目标检测器DCD 的消融实验。实现了几种最新的检测器与DCD做检测准确度和检测速度评估指标的对比。实现的检测器包括以ResNet-50和ResNet-101[16]为主干特征提取网络的DCD、Faster RCNN和Cascade RCNN。为公平起见,这些实现的检测器使用的训练数据与DCD相同,同时DCD屏蔽掉外观特征提取分支。评测的基准数据集为MOT-15[17]。对比结果如表2所示。

表2 DCD消融实验对比结果Table 2 Ablation experiments result
从表2可以看出,对于相同检测器,使用ResNet-101比使用ResNet50 作为主干特征提取网络时的AP 性能好,但在FPS性能上的表现相反。如交变比(IOU)阈值为0.5 时,带有ResNet101 的FasterRCNN(ResNet101+Faster RCNN)的AP数值为63.5%,运行速度为9.6 FPS,但是ResNet50+Faster RCNN 的AP 数值为59.2%,运行速度却为11.4 FPS。其次,IOU阈值设置越大,检测器的AP 数值越小,例如当IOU 阈值设为0.5 时,ResNet50+cascade 的AP 数值为62.3%,当IOU 阈值设为0.7 时,ResNet50+cascade的AP数值为47.2%。
当IOU 阈值设为0.5 时,ResNet101+cascade 的AP数值达到了最高67.1%。紧随其后的是CSPDarkNet-53+DCD,它的AP数值达到了66.2%。ResNet101+DCD的AP 数值比ResNet101+cascade 低了3.7%,比ResNet-101+FRCNN 的AP 数值高了1.7%。但是在检测速度上,ResNet101+DCD 的FPS 数值达到了12.3 FPS,约是ResNet101+cascade的FPS数值的1.4倍,约是ResNet101+FRCNN 的FPS 数值的1.3 倍。CSPDarkNet53+DCD 的AP数值不但比ResNet101+DCD检测器高了1.2%,而且检测速度比ResNet101+DCD的提升了约1.6倍,检测速度为20.1 FPS。当IOU阈值设为0.7时表现与IOU阈值设为0.5 时有相同的趋势。因此可得出DCD 方法在多目标跟踪任务上检测准确度和现有检测器相差不大,但是检测速度具有优越性。
2.4.2 MOT系统对比实验
为了证明使用DCD 的MOT(Proposeds)系统的优越性,对比了几种最新的MOT方法。由于DCD训练使用了联合数据集而不仅仅是MOT-16 数据集训练检测分支和外观特征提取分支,公平起见,对比的MOT系统同样使用了除MOT-16以外的数据集,目标关联策略统一使用文献[18]中的方法。对比的MOT方法是TAP[19]、RAR16wVGG[20]、POI[21]和DeepSORT-2[18]。它们都使用了相同的检测器,即以VGG-16为主干特征提取网络的Faster RCNN,该检测器在大型行人检测数据集中进行了训练。它们之间的主要区别在于它们的目标外观特征获取方法。例如TAP、RAR16withVGG和POI分别使用了Mask-RCNN[22]、Inception[23]和QAN[24]作为其外观特征提取模型,且训练数据集互不相同。DeepSORT-2 使用深度残差网络(WRN[25])作为外观特征提取模型,并使用MARS[26]数据集训练。表3 中列出了这些MOT 系统和使用DCD的MOT系统在MOT-16基准数据集上的对比结果。

表3 MOT系统对比结果Table 3 MOT system comparison results
从表3 可以看出,对于MOTA 指标。POI 系统的MOTA数值最高,为68.2%。其次是TAP系统,为64.5%。Proposeds 系统在MOTA 指标上比最高的POI 系统低了约6.6%,比TAP 低了约1.2%,比DeepSORT-2 系统高了约2.7%。对于IDF1 指标、IDS 指标和MT 指标,类似于MOTA 指标,Proposeds 系统没有表现出明显的优劣势。而在ML指标上Proposeds系统是5种MOT系统中最优的,分析原因是DCD 检测器的候选框的一部分来自于先前帧的检测结果,因此在当前帧中很容易检测到先前帧出现过的目标,所以使得轨迹中的目标不容易丢失,进而提升了ML的性能。对于运行速度指标FPS,由于其他4种方法均没有计算检测器的运行时间,因此重新实现了基于VGG-16 的Faster RCNN 检测器,计算时间后,Proposeds系统相较于其他4种方法中最快的DeepSORT-2 方法还要快2.2 倍,为18.2 FPS。图7 为Proposeds系统跟踪效果图。

图7 目标运动轨迹跟踪效果图Fig.7 Objects trajectory tracking result demo
3 结束语
提出的面向MOT 系统的专用循环目标检测器DCD 利用了视频帧序列间具有高度相似性的特点,依据先前帧的目标位置信息和当前帧相对于先前帧的变化得分图VSM 来选取候选框,简单高效地替换了候选框推荐网络RPN 的功能,在保证检测准确度的前提下提升了检测速度,并且DCD 中融入了目标外观特征提取分支,进一步减少了MOT 系统整体的运算消耗。实验表明,DCD 目标检测器提升了MOT 系统的跟踪速度,并且具有较好的跟踪准确度。下一步,将继续改进DCD选取候选框的方法,进一步提高MOT系统的跟踪准确度和跟踪速度。
猜你喜欢
光学精密工程(2022年13期)2022-08-02 08:53:30
计算机工程与应用(2022年1期)2022-01-22 07:46:48
计算机工程与科学(2021年4期)2021-05-11 01:59:36
学生天地(2019年28期)2019-08-25 08:50:54
火力与指挥控制(2018年3期)2018-04-19 11:43:39
数学物理学报(2018年1期)2018-03-26 08:16:36
中国交通信息化(2017年9期)2017-06-06 07:14:57
工业设计(2016年11期)2016-04-16 02:49:43
河南科技(2014年22期)2014-02-27 14:18:12
山西大同大学学报(自然科学版)(2014年3期)2014-01-23 01:56:30
