
我国图情档领域关联数据的研究现状与前沿热点
2022-09-20 13:08:52苏州大学图书馆社会学院
图书馆理论与实践 2022年5期
王 飞,徐 芳(苏州大学 .图书馆,b.社会学院)
1 引言
关联数据(Linked Data)是由Web的发明人Tim Berners-Lee提出的一种数据规范,用来在万维网上发布和连接各类数据、信息和知识,使人们能借助互联网发现更多相互关联的信息[1]。由于关联数据是一种较为容易掌握的技术规范,随着关联数据发布工具的日益成熟,瑞典、美国、英国、法国、德国等国家图书馆开始创建和传播自己图书馆书目记录、主题词表(LCSH)的关联数据[2-3]。2015年,国务院印发的《促进大数据发展行动纲要》明确提出要大力推动政府数据共享,稳步进行公共数据资源开放[4]。截至2021年5月,关联开放数据(LinkedOpenData,LOD)云图中收集的全球地理、政府、媒体及用户等机构和个人发布的开放关联数据集已经达到1,301个,链接 16,283 条[5]。
国内对于关联数据的研究始于2006年,2011年之前的研究成果以关联数据概念介绍和文献综述为主,少有对关联数据实践应用的研究。此后,关联数据吸引了更多学者的关注,相关研究成果的数量和质量都有了明显增长,已有文献对2016年之前传统受控词表的语义化描述、关联数据成果发布、计算机与图书情报领域关联数据的研究现状进行了文献计量分析[6-7]。随着我国将构建全国信息资源共享体系上升为国家战略[4],作为数据共享开放的重要基础,关联数据研究的重要性进一步提升。2017年至今,CNKI(中国知网)中收录的相关新增文献超过383篇,约占所有相关文献总数的一半。有鉴于此,本研究旨在通过对我国图情档领域关联数据研究现状进行全面的梳理与分析,挖掘该领域的核心主题和前沿热点,以期为后续研究提供参考和借鉴。
2 数据采集与分析方法
2.1 数据采集
本文选择CNKI为文献数据来源,以 “主题” 为检索选项, “关联数据” 为检索词,限定学科为 “图书情报与数字图书馆” 与 “档案及博物馆” ,检索时限为2006—2020年,共检索到中文文献874篇,去除序言、报纸文章等非研究型文献及外文文献后,将剩余的867篇文献作为本文分析的对象。
2.2 分析方法
本研究一方面利用SATI文献题名信息统计分析工具[8]对研究机构、学者、期刊等主体关系进行计量分析,以了解其知识关系模式;另一方面综合利用词频分析、共词分析以及聚类分析对文献的关键词进行研究和可视化展示,以厘清该领域的核心主题和发展趋势。最后,笔者选择重点文献对该领域的研究内容进行述评,揭示该领域研究的核心内容和热点前沿。
3 文献分布特征与合作网络
3.1 文献增长特征分析
笔者对我国图情档领域关联数据研究的文献发表数量按年份进行了统计分析,2006—2020年我国图情档领域关联数据研究的发文量和增长率见表1。

表1 2006—2020年我国图情档领域关联数据研究的发文量和增长率
从表1可以看出,2010年之前相关研究的年发文量均为个位数,研究的开展尚处于萌芽阶段。从2011年起,该领域的研究热度逐年提升,2012年发文量迎来爆发性增长,增长率达到了200%,并且这种增长趋势一直持续到2015年,发文量达到125篇。此后两年发文量趋于平稳,均在120篇上下。这一时间线与我国一系列推动数据资源开放共享文件的发布时间点基本重合,反映了我国图情档领域学者对国家政策的敏感性,以及研究开展的果断与快速。2018年,发文量出现较明显回落,但此后两年又基本维持在同一水平,关联数据的研究进入第二个平稳期。
3.2 研究机构分布及合作网络分析
科学文献与研究机构之间的数量关系和分布情况反映了研究主体的文献产出能力。表2为笔者利用SATI和EXCEL统计出的发文数量大于或等于10篇的研究机构分布情况。为了更客观地了解机构分布情况,笔者对机构更名,学院或图书馆下属的系、研究所(中心)和部门的数据做了合并处理。
根据表2数据,发文数量超过10篇的研究机构共有18个,发文量之和约占总体1,034个机构全部发文量的40%,表明我国图情档领域关联数据研究机构分布比较分散。进一步统计发现,这18个核心机构由高校院系、公共图书馆和中国科学院研究所组成,其中高校院系有13家,占据了绝对主力地位,这与高校学术氛围浓厚、科研队伍强大密不可分。笔者对18个机构的发文量按年份统计发现,上海图书馆开展关联数据研究的时间最早(2009年),且延续性最强,他们的研究队伍遍布图书馆的所有部门。中国科学技术信息研究所和中国科学院国家科学图书馆也较早开展了相关研究(2010年)。两者不同的是:前者将研究一直延续了下来,而后者在2013之后暂停了相关研究。总体而言,高校开展关联数据研究的时间较晚,2014年之前13所高校的发文量之和与另外5家机构相比还有不小差距,而近7年的发文量统计情况则展现了高校在研究持续性和爆发性上的优势。
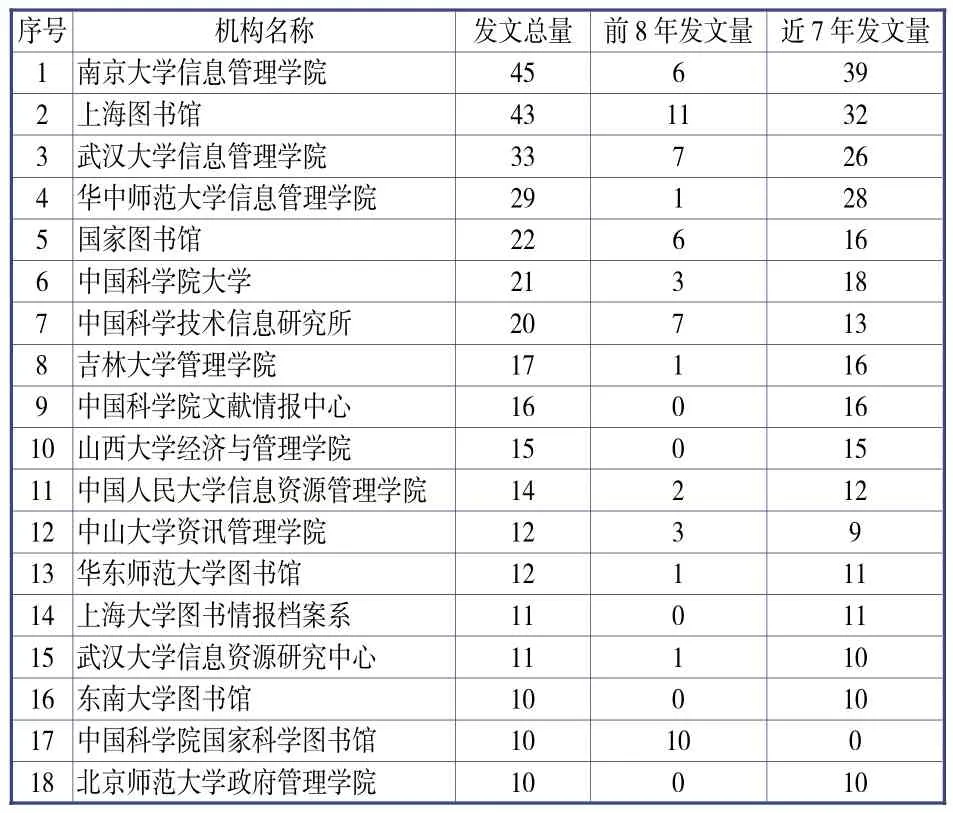
表2 总发文数量≥10篇的研究机构分布
3.3 核心作者及合作网络分析
SATI统计显示,本研究搜集的867篇文献共有1,652位作者,其中夏翠娟发文量最多(20篇)。根据普莱斯定律,本项研究中核心作者的最Nmax为最高产作者的发文量[9]),计算得出M≈3.35,即核心作者的最低发文量为4篇。符合这一要求的作者共有63位,他们的总发文量为388篇,约占全部论文的45%,基本符合普莱斯 “核心作者集群发文量约占总发文量的一半” 的理论,由此说明我国图情档领域关联数据研究核心作者集群已经基本形成。对核心作者发文的总被引量进行统计发现,刘炜撰写的16篇文献总被引835次,夏翠娟撰写的20篇文献总被引690次,欧石燕撰写的13篇文献总被引356次,陈涛撰写的12篇文献总被引216次,以他们为代表的核心作者在该研究领域具有很大的影响力。
为进一步分析学者间的合作关系,笔者采用知识图谱对63位核心作者之间的合作网络进行描绘(见图1)。为了更清楚地显示主要合作者间的关系,笔者在数据处理中进行了去除噪点处理。
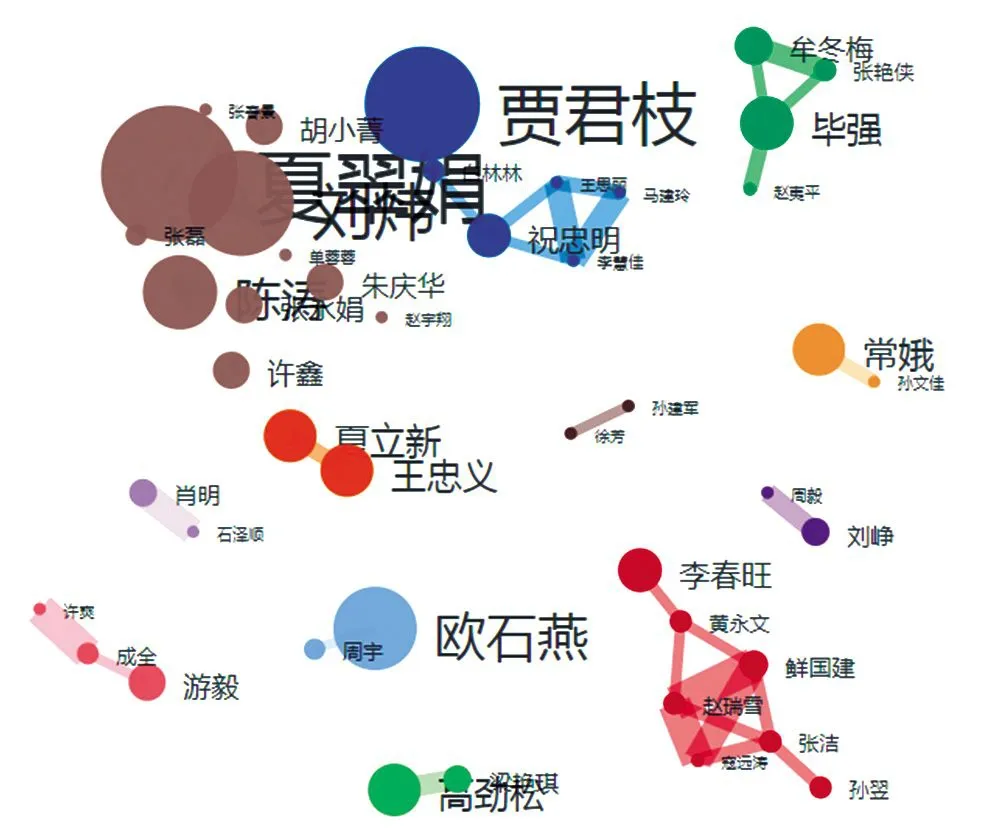
图1 我国图情档领域关联数据研究核心作者合作网络
从图1中可以看出,核心作者之间的合作度较弱,63位作者仅形成了12个合作集群,且只有3个集群的合作者超过了5人。其中,夏翠娟、刘炜、陈涛等组成的集群规模最大,发文量最多,他们来自上海图书馆的不同部门,属于内部合作,具有很强的专业能力和文献产出能力。规模第二的集群由中国科学院文献情报中心的李春旺、中国农业科学院农业信息研究所的黄永文等组成,调研发现他们是以师生关系为基础构建的合作网络。同样地,规模第三的集群也是基于师生和同事关系形成的山西大学、中国人民大学以及中国科学院之间的合作网络。总之,虽然我国图情档领域关联数据研究已经形成了具有一定影响力的核心作者集群,但学者之间的合作交流还不够密切,大部分都是师生或同一机构内部的合作,高校内部各院系之间的合作以及高校与公共图书馆之间的合作都不常见。
3.4 来源期刊分布
一般来说,核心期刊刊载的论文质量较高,论文的研究主题具有一定的学术创新力,因此对刊载论文的期刊进行统计分析不仅可以在宏观上判断关联数据研究主题的创新力,还有助于挖掘该领域的高影响力期刊。笔者利用UCINET进行统计分析,构建期刊载文量分布图,并将载文量低于10篇的期刊归于其他类(见图2)。
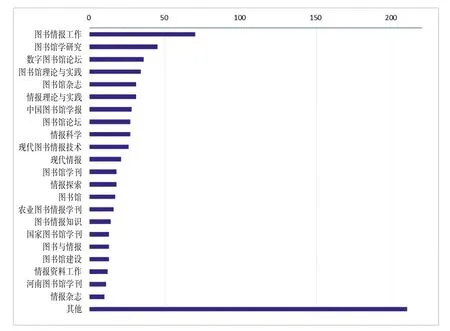
图2 期刊载文量分布图
从图2可以看出,在载文量大于10篇的22种期刊中,核心期刊有15种,占比68%;CSSCI来源期刊1种,CSSCI扩展版来源期刊2种,一般期刊仅有4种。可见,我国图情档领域关联数据研究的学术成果大部分都刊载在核心期刊上,论文整体质量较高,论文的研究主题具有较强的学术创新性。根据布拉德福定律,笔者将各种期刊的载文量降序排列,并将论文数量划分为数量大致相等的三个区域,得到三个区域的期刊数为5∶17∶100,近似等于1∶3.4∶4.472,其中第二区在严格数值(4.49)的基础上下浮动了约24%,可以认为此种情况符合布拉德福定律[10]。据此,我国图情档领域关联数据研究的 “核心区” 期刊为《图书情报工作》《图书馆学研究》《数字图书馆论坛》《图书馆理论与实践》《图书馆杂志》和《情报理论与实践》(两者载文量相同,排序不分先后)。
4 研究主题及其发展趋势
4.1 关键词词频分析
关键词是文章核心内容的高度凝练,体现了作者的学术思想和观点,词频分析法是利用关键词在某一研究领域文献中出现的频次高低来确定该领域研究热点和发展动向的文献计量方法[11]。笔者利用SATI对本研究所选文献的关键词进行统计分析,共得到1,536个关键词,由于词频最高的 “关联数据” 与数据采集所用的主题检索词一致,且词频与其他关键词相差太大,因此在下面的分析中将 “关联数据” 一词去除。其中,关键词词频大于10的关键词有43个,词频之和为955次,占总词频3,169次的30%,根据 “二八定律”[11],上述43个关键词为高频关键词,从中可以分析出该领域的研究特点。图3为这43个高频关键词云图,图中的字体越大表示该关键词的词频越高。

图3 前43个高频关键词云图
从图3可以看出,国内学者围绕关联数据在图情档领域应用的研究主要集中在书目数据、书目框架发布、数字资源、资源整合、数据模型构建、知识组织、知识服务、知识发现等领域,反映出图情档机构和学者紧跟时代发展,注重利用新兴技术为用户提供更好的服务,提升用户体验。同时,国内学者对关联数据相关的关键技术也进行了深入研究,产生了本体、元数据、RDF、RDA、D2R等研究主题。科学数据、机构知识库、科技文献等高频关键词则显示了关联数据在促进科技资源开放共享、提升知识资产管理效能方面应用的潜力。
4.2 关键词的聚类和共现分析
笔者利用UCINET对高频关键词进行聚类分析,分析得到的8个聚类可以看作8个研究领域,包括:图书馆数据模型构建、书目数据语义化编制、科学数据和科技文献开放共享、知识组织系统SKOS化和关联化、元数据与本体、高校图书馆知识发现系统建设、数字图书馆资源整合和机构知识库建设、博物馆资源整合和数据关联。这8个研究领域在一定程度上集中体现出图情档领域关联数据的研究状况。为了更直观展示高频关键词之间的共现关系,笔者利用知识图谱进行可视化描述(见图4)。
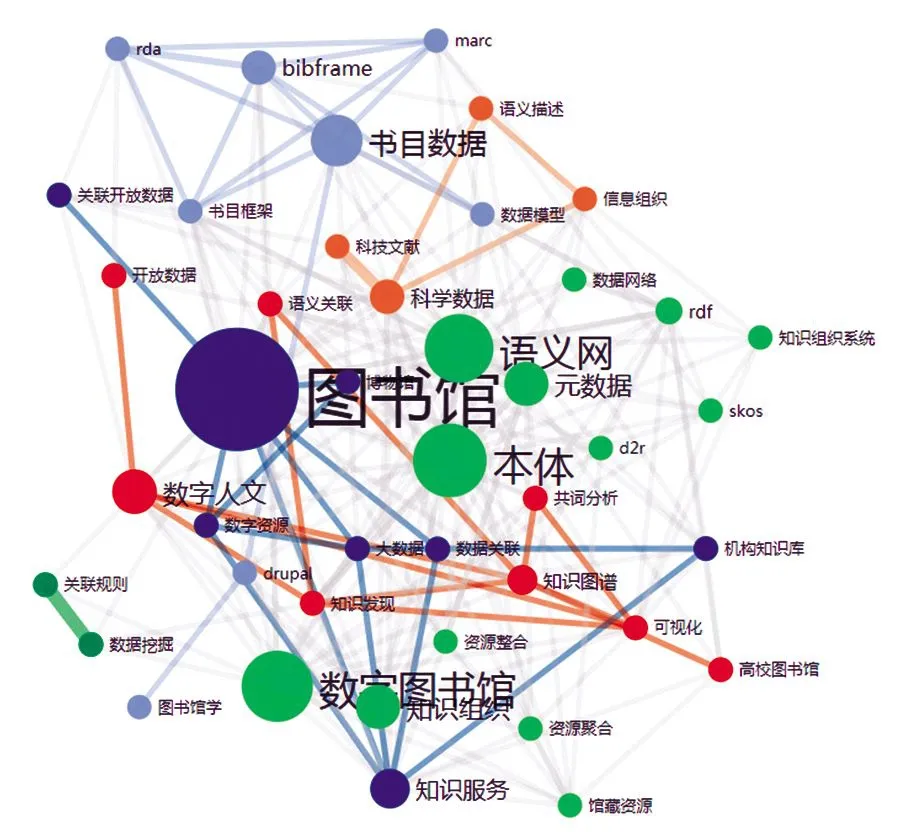
图4 高频关键词共现关系
从图4可以看出,关键词层层相连,形成了一张完整的网络图,没有出现孤立的点。其中,图书馆的节点最大,与周围关键词形成网络连线最多,知识服务、机构知识库、数字资源、数据关联、大数据、书目数据、数据模型等都与图书馆联系密切,说明关联数据在图书馆的应用研究涉及图书馆服务的多个方面。此外,本体、语义网、元数据占据了中心位置,几乎与每个关键词都有联系,是关联数据应用研究的重要技术基础和支撑。而数字人文、知识图谱、知识发现、共词分析、开放数据、语义关联等关键词也联系紧密,同样是研究的热点主题。
4.3 研究主题动态分析
在聚类和共现分析的基础上,笔者按年份对高频关键词进行统计分析,进一步理清了热点研究主题的动态发展脉络。分析表明,高频关键词的数量逐年增加,2010年以前,所有关键词的频次均低于5;2011—2015年,频次达到5的关键词快速增长,共有22个;2016—2020年,这一数字增长到了40个。15年内高频关键词增长速度近似等差数列,一方面说明我国图情档领域关联数据研究的逐渐扩展,另一方面也表明研究热点正在快速形成。笔者根据上文聚类分析的结果,将8个聚类内的关键词分别相加,绘制出8个研究主题的频次随时间变化的图像(见图5)。
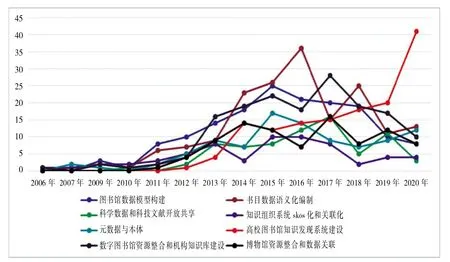
图5 高频关键词频次时间图(基于8个聚类)
从图5可以看出,高校图书馆知识发现系统建设这一研究热点近年来一直处于上升趋势,2020年更是迎来爆发性增长,关键词频次在2019年的基础上翻倍增长,达到了41次。书目数据语义化编制、图书馆数据模型构建、数字图书馆资源整合和机构知识库建设、科学数据和科技文献开放共享、博物馆资源整合和数据关联五个研究热点的波动性较大,在2015—2017年之间达到峰值后,整体均呈下降趋势。元数据与本体的研究在经历了2016—2018年的短暂降温后,又恢复了上升趋势。相对而言,知识组织系统SKOS化和关联化的研究热度一直不高。以上结果在很大程度上反映了我国图情档领域关联数据研究的发展方向。
5 核心内容与前沿热点分析
5.1 技术与平台视角的关联数据研究
关联数据在图书馆、档案馆和博物馆(以下简称LAM)中的应用可以归纳为发布、消费、服务和平台四种模式,其中数据的发现和检索机制是关联数据成功应用的关键。与此同时,关联数据与其他Web服务的整合、不同语义描述系统之间的互操作、消费关联数据在本地系统的功能实现、嵌入外部社会信息环境的稳定性等都是关联数据应用面临的技术性挑战[12]。各类信息资源的关联数据化发布可以分解为六个关键步骤:数据建模、实体命名、实体RDF化、实体关联化、实体发布、开放查询[13],发布方式主要包括静态发布、批量存储、调用时生成、事后转换(D2R)四种类型,常见的实现技术和工具有VoID词表、前端转换工具、OWL及SKOS相关工具、Web Services、Web应用框架、CMS及RDFa、Drupal等[14]。为了实现LAM中不同类型的数据、信息和知识的发现与共享,需要以OAI-PMH协议为基础,构建由数字图书馆(DL)、数字档案馆(DA)、数字博物馆(DM)和图档博数字化协作中心(DLAM)组成的D-LAM框架,通过DLAM对DL、DA、DM的元数据进行收割、语义映射和关联标引,形成面向用户的一体化信息服务体系[15]。此外,随着关联数据集的快速增加,基于关联数据的服务平台、监护平台建设与信息资源的移动视觉搜索和可视化展示逐渐成为高效消费和利用关联数据的热点主题。为了保障关联数据发布及消费参与者的合法权益,提升关联数据集的质量,关联数据的开放应用协议、建设标准、发布规范以及质量评价方法的制定与实施也是关联数据在LAM中应用发展迫切需要解决的问题[16]。
5.2 数据资源视角的关联数据研究
LAM兼有资源收集、管理和服务功能,在关联数据运动中扮演着发布者、信度验证者、消费者和组织协调者的角色[17],关联数据的发展为数据资源的独立标识、结构化描述和语义化关联提供了契机。数据资源视角的关联数据研究大致可以分为三个阶段。
第一阶段,数据资源的发布。在关联数据发展初期以中国科技信息研究所、中国科学院文献情报中心为代表的机构对书目组织语义化,词表、分类法、规范数据等知识组织关联化展开了大量研究。此后,更多的机构参与进来,进一步完善了科学数据、科技文献、科研实体、档案与异构数据等更多形式数据资源的关联数据化[18-19]。目前,国家图书馆已经建设了关联数据注册与服务系统,实现了涵盖关联数据整个生命周期的管理,发布了中分表、国图公开课、馆藏文献3个数据集[20],书目数据涵盖了目录资源、期刊、引文、手稿、家谱等多种资源类型,规范数据已经扩展到生物、医学、农业、经济、信息技术、艺术图像等众多领域[21]。
第二阶段,数据资源的聚合。数据资源的关联数据化满足了用户的一般需求,但主动、多元、深层次的信息服务还需要数据资源的深度聚合,关联数据强大的语义聚合能力促进了数据集中URI的开放复用,语义链接机制将各类客观实体与抽象概念关联在一起,从而为数据资源的聚合提供了一种现实可行的途径[22]。与元数据、本体、叙词表等资源聚合模式相比,关联数据在关联强度、关联维度、关联阶度、关联粒度等方面都具有独特优势[23]。
第三阶段,知识发现。人类知识活动的价值在于可用知识的发现,从知识生命周期来看,知识发现包含数据收集、数据预处理、数据挖掘、关联数据生成和数据表示等阶段,数据资源的关联数据化发布与多维度聚合为知识发现打下了坚实基础,关联数据提升了半结构化与非结构化文档的知识发现能力,增强了知识发现结果的语义验证能力[24]。通过关联数据的语义关联,可以更准确地发现所需知识,拓展知识发现的范围,简化知识发现的过程。然而,由于关联数据只是 “弱连接的三元组” 构成的数据网络,需要进一步的知识发现才能满足用户的深层知识需求,因此关联数据的发展离不开知识发现的推动,知识发现是关联数据应用的基本方法和最终目标[25]。虽然将关联数据应用于知识发现仍然面临着关联数据的制备问题、不同语言的语义差异问题以及可信度的挑战,但关联数据依然是LAM扩展资源发现平台、推进知识服务的有效方案,基于关联数据的知识发现研究将会是未来一段时期内的研究热点[24]。
5.3 用户视角的关联数据研究
智能技术和信息技术的发展促进了LAM服务由大众化向个性化、由一般向精准转变。由用户需求驱动,通过数据资源的聚合与知识发现,提供知识资源与用户需求高度匹配的知识服务是当前关联数据研究的热点。用户视角的关联数据研究主要包含两方面内容。① 基于关联数据的用户需求与行为研究。用户需求组织是对用户需求进行描述和揭示的过程,将关联数据应用于用户需求组织,利用关联数据技术创建和发布关于用户需求及其相互间联系的规范化描述信息,可以形成以用户需求为节点,以用户需求之间的关系为边界的语义化用户需求网络[26]。利用物联网、大数据、关联数据等技术,收集并关联用户与LAM交互中产生的各类数据,构建用户小数据行为的关联数据库,进而更清楚地了解用户需求[27]。在保护用户隐私的前提下,将用户信息通过关联数据的方式发布有利于扩展知识发现服务,实现数据融合与语义检索[28]。② 用户需求与知识资源的关联匹配与精准服务。在通过调查问卷、用户行为本体模型、FP-growth关联挖掘算法、科研本体等方式深入了解用户的显性兴趣和隐性需求的基础上,将关联数据、书目框架技术引入学科信息资源、科研实体资源、纸电资源等资源体系中形成基于用户需求的信息资源规范化语义描述,并在此基础上实现个性化精准服务,帮助用户形成关联知识发现[29-30]。基于用户视角的关联数据研究已经覆盖科研服务、学科服务、文献传递、阅读推广等多个领域,而基于用户需求和关联数据技术的自动问答、智能参考咨询服务研究也取得了一定进展。
5.4 数字人文视角的关联数据研究
从实践角度来看,数字人文就是利用数字工具、技术和媒体改变艺术、人类和社会科学知识的生产和传播,其本质上是一种知识创新[31]。LAM拥有规模庞大、种类丰富的数字化馆藏资源,以上海图书馆刘炜、夏翠娟等为代表的研究团队已经探索出了一个让人类记忆和文化遗产在数字时代充分发挥价值的实现方案。上海图书馆以家谱为实践探索的起点,利用关联数据的知识组织功能,把散落在不同家谱文献中的人、地、时、事关联起来,并进行可视化展示[32],于2016年推出了上海图书馆家谱知识服务平台,同时推出了开放数据应用开发竞赛。日前,该竞赛已经成功举办了5届,汇聚了丰富、海量的历史人文数据,其中家谱元数据有72,593余条,家谱的家规家训全文文本300余种,世系表3家[33]。经过6年的发展,上海图书馆已将家谱的成功经验应用到了历史地理数据、名人档案、人物传记、古籍等其他历史文化记忆资源,数字人文数据基础设施的建设也取得了显著进展。除上海图书馆外,吉林大学、武汉大学、华东师范大学、山东大学等研究团队也纷纷加入该研究领域,在LAM资源整合、视觉资源知识组织、城市记忆资源整合[34]等方面作出了重要贡献。
6 研究结论
作为一种数据发布规范,关联数据已成为影响互联网基础结构的关键技术之一,在全球开放数据运动的推动下,国内学者对关联数据展开了跨学科、多视角的研究,取得了丰硕的研究成果。
(1)我国图情档领域关联数据的研究正处于第二个平稳期,形成了以夏翠娟、刘炜、贾君枝、欧石燕、李春旺等为代表的核心作者集群,研究期刊分布呈现出核心化趋势,研究成果具有较强的创新性和影响力。但另一方面,也存在着核心作者集群规模小、研究机构分散、学者间合作度低、多数学者研究持续性不强等问题。
(2)国内学者能够紧跟国家宏观政策走向和时代热点,及时调整研究方向,不断丰富关联数据研究的理论体系和实践成果,对关联数据的关键核心技术、在图情档领域的实践应用、对促进信息资源开放共享、提升知识资产管理效能等方面的作用均展开了大量的研究,形成了图书馆数据模型构建、书目数据语义编制、科学数据和科技文献开放共享、知识组织系统SKOS化和关联化、元数据与本体、高校图书馆知识发现系统建设、数字图书馆资源整合和机构知识库建设、博物馆资源整合和数据关联8个聚类。此外,一些学者在不断延伸研究广度的同时,也在不断拓展研究深度,关联数据的研究已经覆盖了图情档领域业务工作和理论体系的方方面面。
(3)我国图情档领域关联数据的研究主要从技术与平台、数据资源、用户和数字人文四个视角展开,随着关联数据相关技术的不断完善以及数据资源关联数据化覆盖面的不断扩大,以用户需求为驱动,提升关联数据服务平台的资源聚合度和颗粒度、促进用户需求与知识资源的高效匹配、支持用户便捷知识发现与精准服务是该领域研究的核心主题和热点前沿。关联数据的开放应用协议、建设标准以及质量评价方法的制定与实施是当下迫切需要解决的问题。与此同时,主动参与数字人文研究,将数字化的馆藏资源融入数字人文基础设施,充分发挥人类记忆和文化遗产的巨大价值也是图情档领域必须抓住的重要机遇。
猜你喜欢
办公室业务(2022年21期)2022-12-17 13:01:06
图书与情报(2020年6期)2020-04-06 03:25:19
——写在《图书与情报》“图情档青年学者专辑”出版之前
图书与情报(2019年6期)2019-11-12 20:20:00
青年生活(2019年23期)2019-09-10 12:55:43
当代陕西(2019年15期)2019-09-02 01:52:00
学苑创造·A版(2018年11期)2018-02-01 06:29:20
读者(2017年5期)2017-02-15 18:04:18
新世纪图书馆(2016年6期)2016-05-14 09:15:44
中共南宁市委党校学报(2015年4期)2015-02-28 11:48:10
中国音乐教育(2014年7期)2014-02-06 21:46:15
