
显式融合词法和句法特征的抽取式机器阅读理解模型①
2022-09-20 04:12闫维宏李少博单丽莉孙承杰刘秉权
计算机系统应用 2022年9期
闫维宏, 李少博, 单丽莉, 孙承杰, 刘秉权
1(人民网 传播内容认知国家重点实验室, 北京 100733)
2(哈尔滨工业大学 计算学部, 哈尔滨 150006)
对于机器而言, 自动地阅读并理解文本是一项颇具挑战的任务, 它需要机器能够依照现实世界中的事实和常识来剖析自然语言所表述的内容[1]. 机器阅读理解(machine reading comprehension, MRC)旨在以问答的形式来理解文章, 其输入是自然语言形式的问题, 以及包含了能够支撑该问题回答的证据文章, 输出则是问题对应的答案. 抽取式机器阅读理解规定问题的正确答案会以文本片段的形式出现在输入文章中, 要求在文章中“抽取”出正确的答案片段.
在以GPT[2]和BERT[3]为代表的大规模预训练语言模型出现之前, 该类任务通常的解决方法是通过循环神经网络对输入问题和文章进行编码并交互, 其模型结构主要包括4个部分, 分别是嵌入层、编码层、交互层和输出层. 问题和文章以词序列的形式分别输入到模型中, 嵌入层首先将问题和文章的输入序列转换为词向量序列, 编码层对词向量序列进行编码后得到自然语言序列对应的上下文编码, 交互层负责将问题和文章的上下文编码进行交互, 加强问题和文章之间的相互感知, 最后由输出层计算出答案片段在文章中的具体位置. 在这一经典结构的基础上, 许多工作对其进行了修改. Attentive Reader[4]将细粒度注意力机制应用到模型中来加强交互层的理解能力. Match-LSTM[5]将 Match-LSTM 以及 Answer Pointer 模型相结合, 将Pointer Net中指针的思想首次应用于阅读理解任务.BiDAF[6]通过双流注意力机制来提高问题与文章的交互能力. QA-NET[7]利用自注意力机制和CNN[8]来进行文本的编码, 相比于RNN[9], 其并行运算能力提高了训练速度, 也取得了当时在SQuAD[1]数据集上的最优预测精度.
尽管上述各类方法使得机器阅读理解模型性能逐渐提高, 但是这些模型仅仅使用固定的检索表(look-up table)映射得到词编码的方式具有一些无法避免的缺陷, 例如无法解决一词多义等问题[10]. 而BERT[3]等预训练模型引入动态编码的方式, 利用大规模语料来获取更深层且更加匹配上下文的语义表征, 极大地提高了各类模型的性能, 在机器阅读理解数据集SQuAD 1.0[1]和SQuAD 2.0[11]上的表现甚至超越了人类. BERT做到如此出色的性能提高引起很多相关领域研究者的兴趣, Jawahar等人[12]通过探测任务挖掘BERT中的语言学信息, 实验表明BERT的低层网络学习到了短语级别的信息表征, 中层网络学习到了丰富的语言学特征, 而高层则学习到了丰富的语义信息特征. 而针对阅读理解任务, Si等人[13]的工作表明对BERT的微调主要学习到文本中的关键词如何引导模型进行正确的预测, 而非学习语义理解和推理. Albilali等人[14]则通过对抗样例表明基于预训练的语言模型仅仅依靠表面的线索, 如词汇重叠或实体类型匹配, 就能获得有竞争力的性能; 同时, 预测的错误可以由BERT的低层网络所识别. Aken等人[15]的工作则从BERT不同编码层的粒度揭示了BERT回答问题的过程, 作者将问答模型由低层至高层的输出分别表示为语义聚类, 聚类后语义与问题中相关实体的链接, 对于支持问题事实的抽取以及答案片段抽取4个阶段, 并将该过程与人类阅读理解的过程进行了类比.
目前的工作大都关注于为什么BERT的内部表征能够如此有效地完成机器阅读理解任务, 对显式地在BERT引入额外的特征的研究则较少. 类似工作是SemBERT[16], 该模型通过将BERT输出的上下文特征与语义角色特征相拼接, 显式地利用这两种特征对来抽取答案片段, 在SQuAD 2.0数据集上, SemBERT取得了优于原始BERT模型的表现.
受此启发, 语义角色之外其他的词法或句法特征同样值得我们关注. 人类在理解文本的过程中是先验地知道某些词法或者文法特征的, 例如, CMRC2018中的问题“前秦对前燕发动的灭国战争是谁主导的?”中,我们可以通过问题中的疑问代词“是谁”, 推断出问题的答案是“人名”, 从而更加关注文章中命名实体特征为“人名”的文本片段“慕容垂”. 而对于类似这样的词法、句法特征, 人类同样具有对其理解的能力, 但是在当前的主流模型中并未体现. 为了填补这部分工作的缺失, 我们提出融合词法和句法特征的抽取式机器阅读理解模型. 我们的主要工作如下:
(1) 在BERT输出的上下文表示的基础上, 显式地引入多词法和句法特征, 来探究这些特征是否能够在BERT预训练语言模型所提供上下文特征的基础上, 进一步增强机器阅读理解的性能. 其中词法特征包括命名实体特征和词性特征, 句法特征则包括依存分析特征.
(2) 设计基于注意力机制的自适应特征选择方法对各类特征进行融合, 并探究不同文本特征对BERT模型的影响.
(3) 在公开数据集CMRC2018上, 与基准模型进行对比, 本文所提出的显式融合词法和句法特征的抽取式机器阅读理解模型在F1和EM指标上分别取得了0.37%和1.56%的提升.
1 显式融合词法和句法特征的抽取式机器阅读理解模型
在本节中, 我们首先对本文方法进行概述, 随后对基于BERT的抽取式阅读理解模型进行详细介绍, 并阐述我们使用到的词法句法特征, 最后描述各类特征融合的动态融合方法, 并得到最终的输出.
1.1 概述
抽取式机器阅读理解可以形式化地定义为: 给定一个包含 m 个字符的问题q =(q1,q2,···,qm), 一个包含n 个字符的文章 p=(p1,p2,···,pn) 以及一个包含l个字符的答案 a =(a1,a2,···,al) , 其为 p中的一个子序列. 我们的目标是学习一个机器阅读理解模型f, 来根据输入文章 p 和 问题q 得 到输出答案a, 如式(1)所示:

本文工作的结构如图1所示, 我们利用已有的模型对输入数据进行预处理, 得到文本特征. 我们的问答模型首先使用BERT对问题和文章进行编码得到编码后的输出 HC. 接下来, 将HC与表征为向量的文本特征通过自适应的注意力机制进行融合, 再使用多层Transformer encoder进行编码, 得到融合特征的编码表示HF. 将二者通过自适应的注意力特征融合层, 得到我们最终的输出H , 并利用一个答案位置分类器得到最终的答案开始位置得分和结束位置得分.
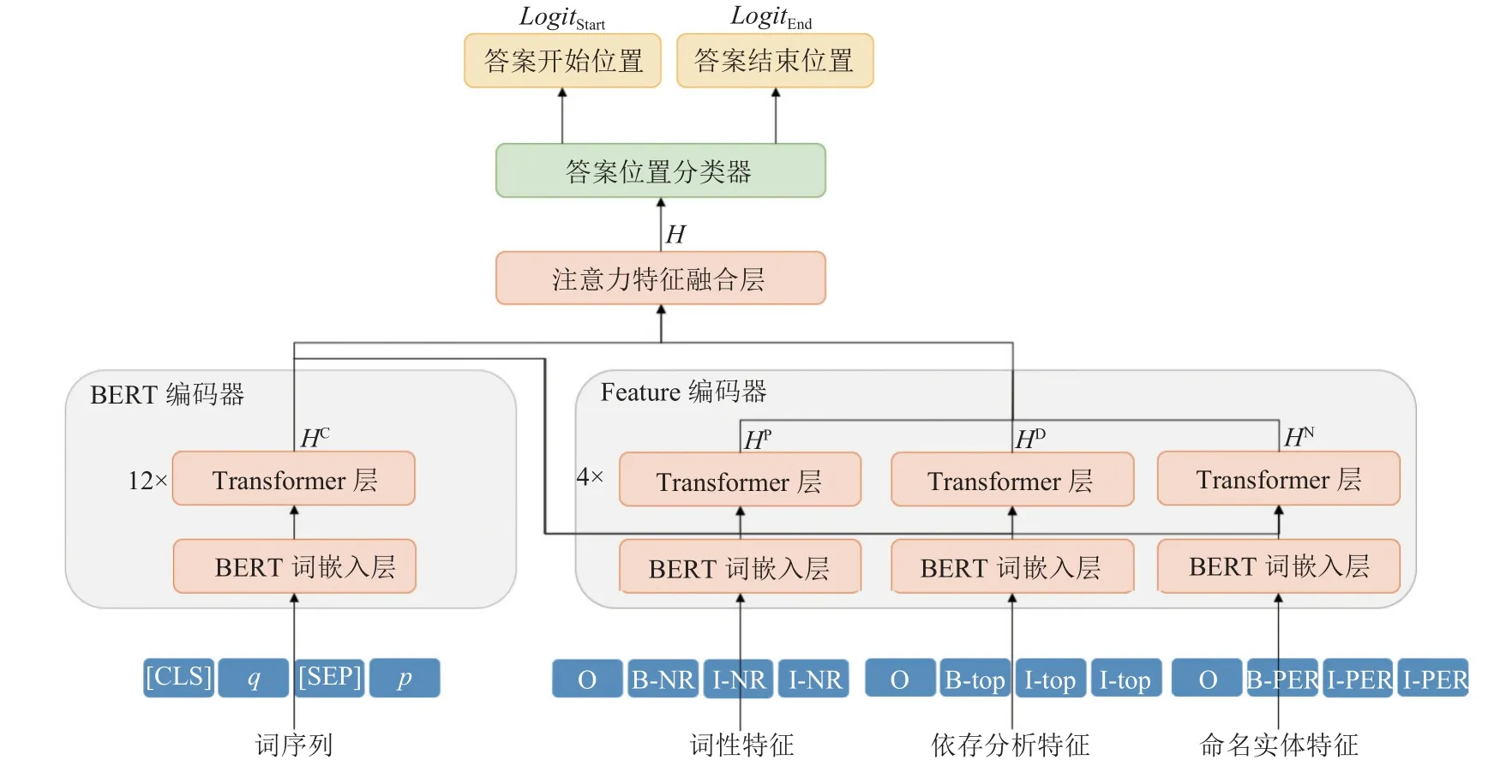
图1 融合词法和句法特征的抽取式机器阅读理解模型结构
1.2 基于BERT的抽取式阅读理解模型
本文使用BERT作为基准模型来解决阅读理解问题. 本文任务输入的问题和文章是一串字符, 神经网络无法直接处理这样的数据. 在预训练模型出现前通常的做法是使用静态词向量将不同的词映射为对应的高维向量, 例如基于局部上下文窗口编码单词的Word2Vec[17]和引入全局统计信息的GloVe[18]. 而BERT则使用基于注意力机制的Transformer encoder, 利用大规模语料通过其强大编码能力将文本编码为具有上下文信息的文本向量.
针对本文所涉及的问答任务这类的上下句任务,BERT通常会将分字后的问题的词序列和文章的词序列连接起来, 输入序列如式(2)所示:
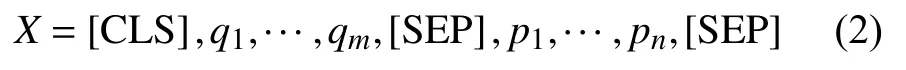
其中, qi表 示问题的词序列中第i 个 字符, pi表示文章的词序列中第i 个字符; [ CLS] 和[ SEP]为BERT中定义的特殊标记, [ CLS]表 示序列开始, [ SEP]则是分隔标记, 用来分隔问题和文章以及标识输入序列的结束. 随后, 我们利用BERT的Embedding层将输入序列分别映射为词向量(token embedding)、类型向量(segment embedding)和位置向量(position embedding), 将三者相加即为BERT的最终输入特征. 接着通过多层Transformer encoder进行编码, 进而获得问题与文章交互的向量表示HC:
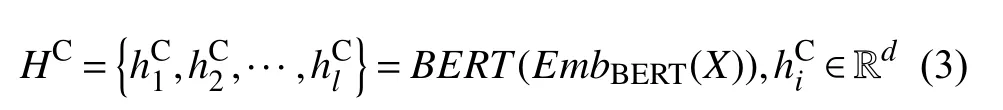
其中, l 表示输入序列长度, d表示BERT输出的每个词对应的向量的维度, 在本文中d =768,表示经由BERT编码后的第i个词对应的上下文表征.
接下来, 通常的做法是使用一个全连接层作为分类器得到答案开始位置和结束位置的得分向量, 如式(4)和式(5):
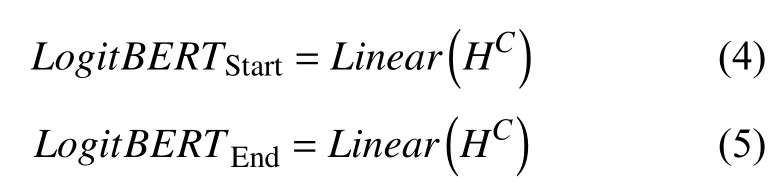
在后续的特征融合模块中, 我们将利用BERT输出的上下文向量HC与词法和句法特征进行融合.
1.3 词法与句法特征
当前的数据集仅仅包括文本形式的问题和文章,并未包含所需的额外词法和句法特征, 为了获取额外特征, 我们利用现有模型进行标注, 并将这些特征进行组合, 其中词法特征包括词性特征和命名实体特征, 句法特征包括依存分析特征. 为了使得我们的文本特征阅读模型尽可能地与BERT阅读模型在输入层的分布相同, 我们以单字粒度进行分词, 使得各个特征构建的向量与BERT预训练模型最大长度相同, 以便直接进行拼接. 文本的特征示例如图2所示.

图2 文本特征标注示例
词性(part of speech, POS)特征: 我们使用词性标注的CTB规范[19], 包括37个词性标签. 以单字切分文本后, 使用BIO规则对特征进行重构, 即某个词w 的词性为 P, 按字切分后为{ z1,z2,···,zn}, 我们将其标注为{B-P,I-P,···,I-P}. 对于BERT中的3种特殊标签[ CLS]、[SEP]和[ UNK], 我们标记为O. 共计75种标签, 我们将其转换为75维的one-hot向量.
命名实体(named entity, NE)特征: 我们使用MSRA的命名实体标注规范, 该规范源于中文文本标注规范(5.0 版), 其中包括专有名词(NAMEX)、时间表达式(TIMEX)、数字表达式(NUMEX)、度量表达式(MEASUREX)和地址表达式(ADDREX)五大类及其下属的31个子类. 我们同样使用BIO规则进行标注, 并将其转换为63维的one-hot向量.
依存分析(dependency parse, DEP)特征: 该特征用来表示句法结构中各项之间的依赖关系[20], 共44项.我们同样使用BIO规则进行标注, 并将其转换为89维的one-hot向量.
1.4 特征融合模块
在处理这些特征标签时, 我们需要将其转换为向量的形式. 首先, 我们对词性、命名实体和依存标签分别通过一个嵌入层映射为固定维度的向量, 并分别将这些特征与上下文特征 HC通过相加的方式融合, 从而将不同的特征融入上下文表示, 见图3. 接着我们使用单个浅层的特征编码器对特征向量进行编码, 该编码器同样是Transformer encoder.
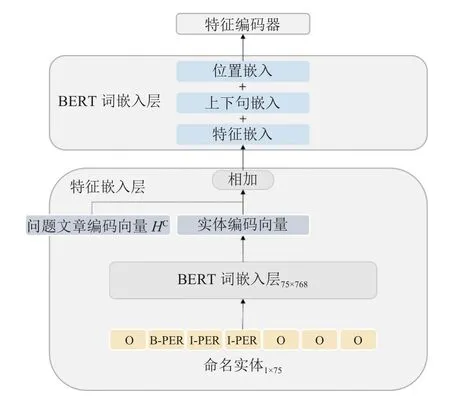
图3 实体特征输入模块
编码后我们便得到了词性特征的向量表示HP(POS),命名实体识别特征的向量表示 HN(NE), 以及依存分析特征的向量表示 HD(DEP), 编码过程可以如式(6)-式(8)所示:

其中, Emb和 T ransformer分别表示嵌入层和编码层. 每个词 xi最 终对应的融合特征hi则通过对3种不同层次的特征进行加权求和得到, 注意力权重使用双线性注意力机制[21]得到, 如式(9)-式(11):
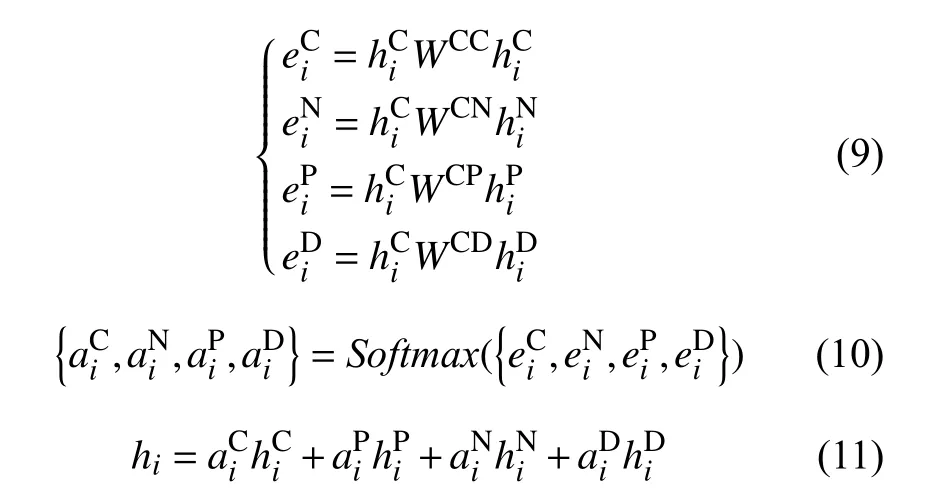

根据上下文编码对各个特征的注意力权重, 将所有特征进行加权融合, 得到最终的融合了词法与句法特征的问题与文章交互向量表示 H , 如式(12)-式(15),我们使用全连接层对 H 进行二分类, 分别得到每个词作为答案开始位置和结束位置的概率, 并使用Softmax得到归一化后的起止位置的最终得分.

2 实验
2.1 数据
本文使用的数据是哈工大讯飞联合实验室机器阅读理解组(HFL-RC)于2018年发布的中文篇章片段抽取型阅读理解数据集CMRC2018[22], 由近20 000个由人类专家在维基百科段落中注释的真实问题组成. 我们使用其给出的训练数据集来进行模型的训练, 用其验证数据集来对模型进行评估. 图4是该数据集的样例, 包括1篇文章以及2个问题, 其中蓝色文字表示与问题1相关的内容, 红色文字表示与问题2相关的内容.
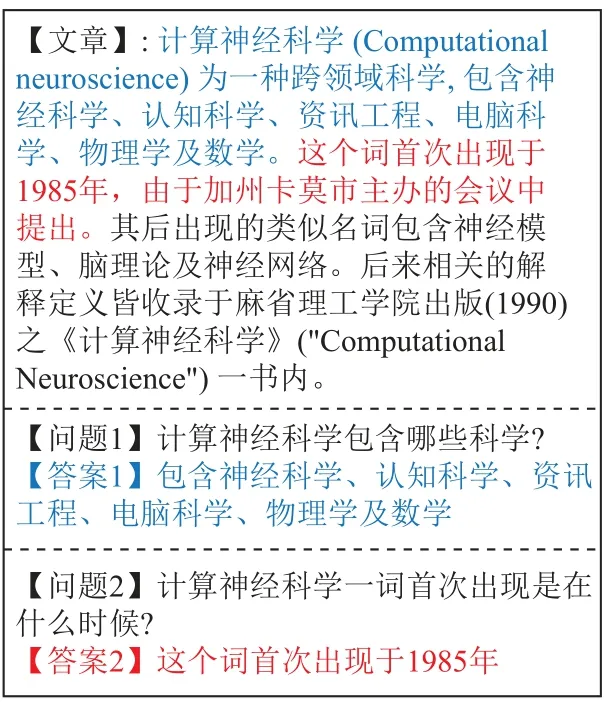
图4 CMRC2018数据集示例
针对基于BERT模型的机器阅读理解任务, 我们对数据进行了一些预处理来使得其符合BERT的输入限制. 首先我们对数据进行字粒度的切分, 并将问题和文章进行拼接, 并固定输入的序列长度为512. 若输入的数量超出这个长度, 则利用128的滑动窗口来切分为多份数据.
而对于文本特征, 我们则利用已有的模型对实验数据进行了词性标注、命名实体识别以及依存分析的预处理. 接着以BIO规则进行标注, 以适应字符级别的输入粒度.
2.2 评价指标
对于抽取式机器阅读理解模型, 我们需要评估答案预测值和真实答案之间的字面匹配程度, 本文采用了文献[1]中的EM和F1两个指标. EM为模型预测的验证数据集中的答案与真实答案完全一致的百分比,而F1为机器学习中常用的指标, 是精确率与召回率的调和平均. 在本文场景下, 将答案的预测字符串与真实值各自按字符切分后, 分别视作词袋, 并计算二者的F1值来粗粒度地评估它们的匹配程度.
2.3 实验设置
算法模型的搭建使用深度学习框架PyTorch[23]实现, 其中的基准模型使用针对中文语料进行预训练的Chinese-roBERTa-wwm-ext模型[24], 相较于最初的中文预训练模型BERT-base-Chinese[6], 该模型将掩码语言模型(masked language model)的训练策略由遮盖单个字变更为遮盖整个中文词, 且使用了更大规模的中文语料, 其在相关下游任务上有更强的表现.
我们使用最后一层的输出作为上下文表示特征,Aken等人[15]和Cai等人[25]的工作也分别展示了在机器阅读理解任务上, BERT中越高层的编码输出越有效. 模型的主要参数设置如下: batch size设置为4, 学习率为3E-5, 并采用学习率预热的策略[26], dropout设置为0.2, 使用训练集微调两个轮次后, 在验证集上取得了不错的基准效果.
接下来我们分别尝试将BERT的输出与文本特征的输入进行交互. 共设置了5组实验, 分别基准模型的实验, 在基准模型基础上分别融合词性特征、命名实体特征和依存分析特征的实验以及融合全部特征的实验. 如表1所示.

表1 对照实验组别与模型
对于每组实验, 我们分别设置了5个随机种子进行多次实验, 使用5次不同随机种子实验中性能的最佳结果以及平均结果作为该组模型实验的最终结果,以排除一些训练过程中的随机性.
2.4 实验结果与分析
(1) 模型阅读理解能力. 在数据集CMRC2018上的实验结果见表2, 其中加粗行分别是添加单特征的最优实验结果和添加全部特征的实验结果.

表2 在数据集CMRC2018上的实验结果 (%)
表2展示了基准模型Chinese-roBERTa-wwmext经微调后, 最高可以达到86.21%的F1匹配率和67.85%的精确匹配率. 在此基础上分别添加词性特征、命名实体特征、依存句法特征进行实验, 实验结果表明每一种特征的融合都能够带来模型的精度的提升, 且对于EM值上的提高要明显高于F1值. 其中词性特征带来的匹配率提升效果最为显著, 可以达到85.85%的平均F1匹配率和67.46%的平均EM匹配率, 相较于基准模型分别可以提升0.3%和0.6%, 而最优轮次的EM相较于基准模型提高0.87%.实体特征和依存分析特征也同样在两个评估标准上相较基准模型有一定的提高, 但较词性特征而言并不显著.
同时添加3项特征后, 实验结果可以达到85.91%的平均F1匹配率和68.27%的平均EM匹配率, 相较于基准模型分别可以提高0.35%和1.43%, 相较于只融合单特征的实验结果, EM值得到了接近一个百分点的提升. 而我们的最优模型达到了86.58%的F1匹配率和69.41%的EM匹配率, 相较于只使用预训练BERT模型, 分别可以得到0.37%和1.56%的提升.
基于上述实验结果以及分析, 我们的方法可以在预训练模型的基础上得到1.5%左右的EM匹配率提升, 证明了提出方法的有效性, 并且在3种特征中, 词性特征更加能够帮助阅读理解模型进行预测. 实验结果也验证了在BERT等预训练模型中引入显式的语言学知识同样能够帮助机器进行阅读理解. 至于EM值的提升如此显著, 我们分析认为显式的语言特征本身就是更加结构化的特征, 因此能够更有效地帮助机器归纳总结出更加精确的答案起始位置.
(2) 效率. 我们对“对预训练模型进行改进”与“引入显示语言学特征”这两种方法的细节进行比较, 包括训练的数据规模与算力成本, 以及各自在CMRC2018数据集上带来的性能提升百分比, 对比结果见表3. 其中,B表示10亿.

表3 对预训练模型改进与引入显示语言学特征两种方法的比较
预训练模型改进: Cui等人[24]提出的BERT-wwmext在BERT的基础上, 将词掩码方式设置为中文全词覆盖, 并引入了包括百科、新闻以及问答页面的训练文本, 词量高达5.4 B. 训练步数的数量级也高达百万,在TPU v3上通常需要数周. 最终在CMRC2018验证集上分别可以得到0.8%和0.1%的EM和F1指标提升. 而RoBERTa-wwm-ext进一步移除了下句预测任务, F1和EM分别提升了1.1%和1.6%.
引入显式语言学特征: 本文方法引入词法和句法特征, 在远小于0.1 B词量的数据集上利用现有模型进行标注, 融合了分词结果和各类特征的训练集大小为107 MB, 以4为batch size在3080Ti上训练2个轮次,共需要20 min, 而EM和F1指标最高可以提升1.56%和0.37%.
本文方法相较对预训练模型进行改进, 使用远少于后者的数据与算力成本, 在阅读理解数据集上获得了持平甚至更优的指标提升. 可见本文方法较为高效,同时也证明了引入显式的词法句法等语言特征能够为特定的下游任务带来较大的性能提升.
3 结论与展望
本文提出一种融合多种特征的抽取式机器阅读理解模型, 显式地引入包括词性、命名实体的词法特征以及依存分析的句法特征, 同时设计了基于注意力机制的自适应特征选择模块, 进一步提升了机器阅读理解模型的性能. 在抽取式机器阅读理解数据集CMRC2018的实验上表明, 本文提出的机器阅读理解模型能够通过极低的算力成本, 在F1和EM指标上取得0.37%和1.56%的提升.
实验结果验证了我们方法的有效性. 对于阅读理解模型而言, 词性特征相较命名实体特征和句法依存分析特征更能够帮助模型理解文本. 同时也说明了对于机器阅读理解这类难度较高的自然语言处理任务,尽管BERT等预训练模型带来的表征能力是突破性的,但是语言本身的一些特征也具有不可忽视的作用. 在未来的研究中包括但不限于词法、句法等各类语言学特征同样值得更多的关注, 它们在与预训练模型的结合中究竟起到了怎样的作用以及这些特征的重要程度都是值得关注的研究课题, 同时在二者的结合中也可以进一步帮助我们了解BERT等预训练模型对于语言的理解机制.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
华文教学与研究(2022年1期)2022-04-27
中国典型病例大全(2022年7期)2022-04-22
中华诗词(2018年3期)2018-08-01
中国房地产业·上旬(2018年1期)2018-05-14
中华诗词(2018年11期)2018-03-26
计算机应用(2016年10期)2017-05-12
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
中国计算机报(2009年27期)2009-04-27
