
基于字符与单词嵌入的航空安全命名实体识别
2022-09-16 06:50孙安亮时宏伟王金策
计算机技术与发展 2022年9期
孙安亮,时宏伟,王金策
(四川大学 计算机学院,四川 成都 610000)
0 引 言
近年来,随着航空出行数量的不断增加,促使航空安全领域需要更加有效的方法进行评估管理。为保护航空安全,管理部门制定了详细周密的工作流程。但在实际工作中,往往只能注重其中的一个部分,无法全面有效地处理整体情况,这就可能造成某个危险源在不同系统逐渐扩散。同时航空安全系统会收集产生的大量详细数据,例如时间信息、气象条件信息、飞行器状态信息等。这些信息为消除航空隐患,制定有效的纠正措施和宏观政策提供了重要依据。这些数据中包含大量的知识概念并且具有相关性,但是大部分数据储存在分离的无结构文件中,无法有效地将这些数据进行关联。如何有效使用已经存在的大量先验知识和历史记录,并将这些数据以及知识进行关联,构建系统化的关联事件模型,提取有效的知识来提高航空安全变得十分迫切。知识图谱[1]可以提供一个较好的解决方案,首先通过信息抽取从异构数据源中自动抽取候选单元,该过程可以将分离存储的数据文件集合并获取实体、关系和属性单元信息;之后通过知识融合将候选单元进行连接合并,该过程可以将无结构文件结构化;最后通过知识加工将整体信息网络化,该过程将整体数据系统化关联。知识图谱在航空安全领域可将复杂的安全因子关系可视化,为有效分析潜在的安全风险提高助力。
命名实体识别是构建知识图谱中基础且关键的任务,实体识别的质量对知识图谱的构建效率和质量影响极大。而航空安全命名实体识别主要特点在于航空安全领域包含大量较长的专有名词和名词缩写混合的情况,例如起降机场、飞机类型和具有专有缩写的组织单位等,加大了命名实体识别的难度。另外在航空安全实体识别中会出现多种描述指向同一实体的情况,例如引擎故障可以描述为左引擎故障,右引擎故障,1号引擎故障,动力减弱,动力丧失等。这导致在航空安全命名实体识别对局部特征更加敏感。这些特殊性使得一般命名实体识别模型在航空安全领域表现效果不佳,需要构建一个适用于航空安全领域的命名实体识别方法,为航空安全领域知识图谱的自动构建提供更好的基础。该文提出使用BILSTM模型进行字符级别的特征提取,该方式可以较好地克服航空安全领域中专有名词较长以及名词缩写的局限。同时在联合特征提取使用CNN模型而非LSTM模型,可以较好地处理航空安全领域数据对于局部特征敏感的情况。
1 相关方法
命名实体识别(Named Entity Recognition,NER)是自然语言处理(Natural Language Processing,NLP)中一项基本性的任务,主要任务是识别句子中表达特殊实体的词语或者短句,比如表示人物、组织、地点等[2]。同时NER也是信息提取、文本理解[3]、信息检索[4-5]、自动文本摘要[6]、问题回答[7-8]、机器翻译[9]、知识图谱构建[10]等任务的基础工具。命名实体识别主要包括两个部分,分别是确定实体边界和识别实体的类别,对于一个实体的正确识别需要确保该实体的边界和类型都正确。航空安全命名实体识别主要目的在于识别航空安全实体,例如航班类型、起降地、事故原因等实体。相较于通用命名实体识别任务,航空安全命名实体识别的难点在于任务实体类别增多、专有名词较多、实体全称与缩写混合表示以及相同实体多种描述。 早期的命名实体识别方法较多基于字典和规则的方法[2],因为需要专家知识,识别效果较差。之后随着机器学习的发展,命名实体识别逐步发展为使用机器学习方法,比如Hidden Markov Model (HMM)[11]和Conditional Random Field (CRF)[12]。也有将机器学习与字典规则方法结合取得了较好的效果,但是这些方法较大地依赖人工选择数据特征无法广泛推广[13]。随着深度学习在各个领域的成功应用,不断吸引着研究者的兴趣。在短短几年的时间里,一系列关于深度学习应用的研究在NER领域展开,并且取得了较好的效果。从Collobert等[14]首次将CNN应用在命名实体识别任务中,通过CNN获取局部特征后通过池化操作获取全局特征,到张聪品等[15]使用BILSTM-CRF模型,使用BILSTM高效利用上下文信息,使用CRF利用句子级别的标签信息,通过BILSTM与CRF的结合使得模型整体具有更好的鲁棒性。
航空领域命名实体识别目前还以BILSTM-CRF模型为主,王红等[16]提出BILSTM-CRF用于民航突发事件实体识别,Cheng等[17]提出BILSTM-CRF用于航空安全命名实体识别任务。但因为航空领域的特殊性,Bao等[18]提出AR-BILSTM-CRF用于航空设计领域,通过增加注意力机制解决航空设计领域包含较多专有名词的问题,并取得了较好的结果。考虑到航空安全领域包含较多专有名词,并且专有名词和缩写表示的情况,同时受Kuru等[19]工作的启发,字符特征嵌入可以较好地解决单词超出词典范围的问题。该文考虑在航空安全命名实体识别任务中增加字符特征,解决专有名词以及缩写的问题。之后通过Chen等[20]工作的启发,考虑到航空安全领域对于局部特征敏感的情况,在获取字符特征与单词特征后通过CNN获取联合特征。最后通过CRF进行序列标注,提取命名实体。经过对比实验,提出的模型具有较好的结果,相比BILSTM-CRF的表现更佳。
2 模型建立
为了提取出航空安全领域命名实体,适应航空安全领域数据特点,即包含专有名词以及缩写表示,并且对于局部敏感的情况,该文提出了基于字符和单词多粒度嵌入模型。模型结构如图1所示。
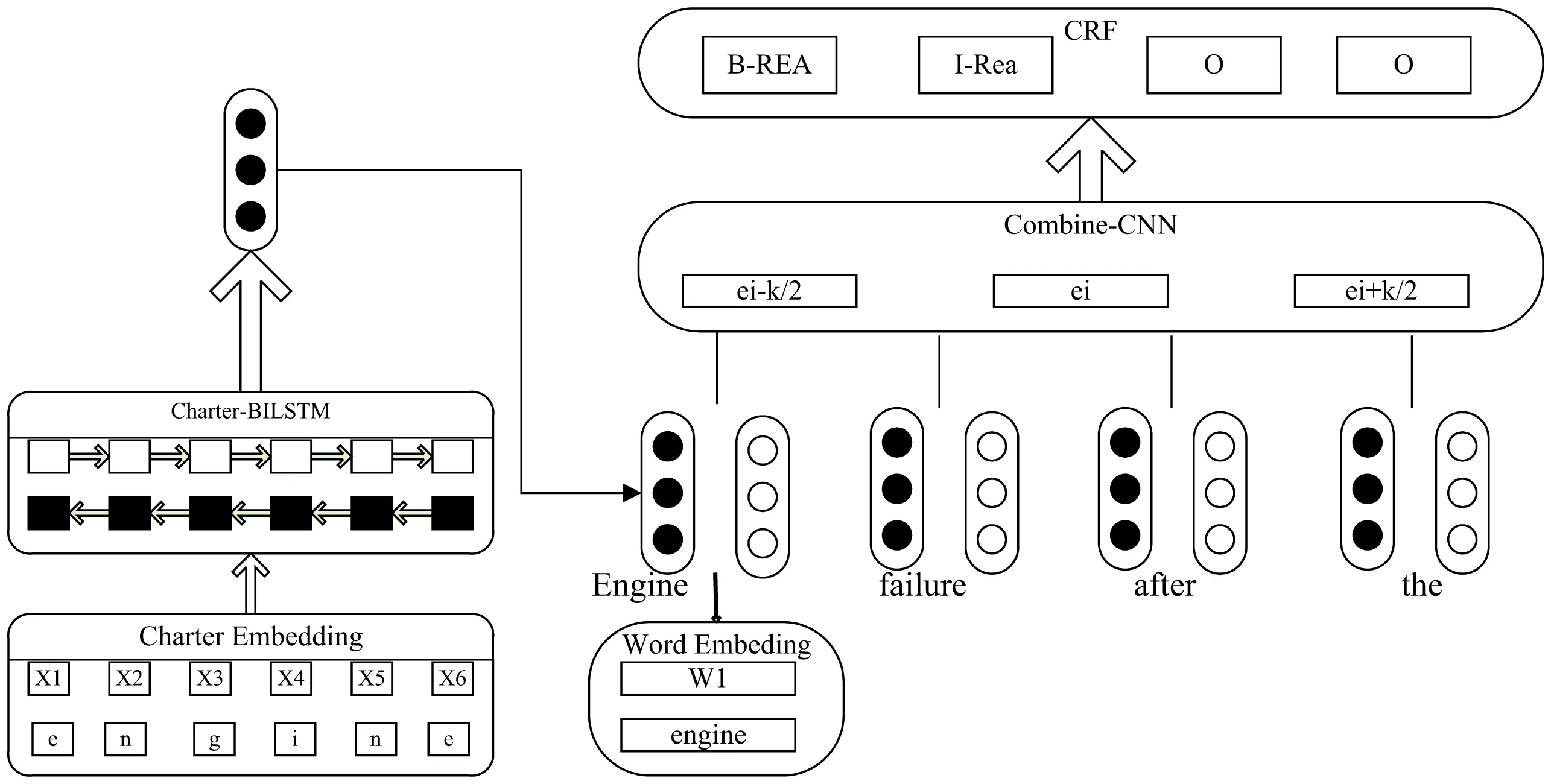
图1 模型结构
模型的理论基础是利用BILSTM对字符进行特征获取,因为BILSTM可以有效利用上下文特征的字符向量,在字符特征提取中使用BILSTM可以有效适用航空安全领域专有名词及缩写表示的情况。之后将联合单词嵌入向量放入联合特征获取层中,通过CNN卷积得到命名实体的联合特征,因为CNN可以更好地感知局部特征关系,更好适用于航空安全领域局部特征敏感的情况。之后将其放入CRF层进行序列标注。该文相较于BILSTM-CRF模型的改进在于增加字符特征解决航空安全领域专有名词及缩写表示的问题,并使用CNN获取航空安全命名实体的局部特征,提高在航空安全领域命名实体识别的效果。
首先定义一下将要使用的字符表达,设s={w1,w2,…,wn}表示一个长度为n的句子,句子第i个单词记为wi,其向量表示记为wi。wi={x1,x2,…,xk}表示字符长度为k的单词,单词中第k个字符记为xi,其向量表示记为xi。接下来将详细介绍该模型中的字符层、联合层和CRF层的内容。
2.1 字符层
字符层的主要目的在于获取字符特征,将字符通过字符嵌入得到字符的向量表示,记为xi。之后使用字符层模型得到特征表示,记为ci。字符层使用BILSTM作为特征提取方法,双向LSTM由正向LSTM和逆向LSTM组成,在结果输出时会将两个相反方向的输出结果拼接作为最终的输出结果。LSTM是一种特殊的循环神经网络(Recurrent Neural Network,RNN),不仅仅具有RNN处理序列问题的优势,还通过引入门控机制缓解了RNN梯度易爆炸或消失的问题, LSTM单元结构如图2所示。

图2 LSTM结构
LSTM中的输入xt代表t时刻的输入,即t时刻的字符向量。ht-1表示上一时刻的隐层状态,ct-1表示上一时刻的单元状态,ft表示t时刻的单元遗忘状态。LSTM由遗忘门、输入门和输出门组成。
遗忘门的目的在于决定丢弃的信息,将读取的ht-1和xt进行计算得到单元的遗忘状态ft,用于后续的状态更新。计算方式如式(1)所示:
ft=σ(Wt[ht-1,xt]+bt)
(1)
其中,σ表示激活函数,而Wt和bt则表示遗忘门参数在模型的训练过程中学习得到。

(2)
其中,Wi、bi、Wc、bc表示输入门计算参数在模型训练过程中学习得到,*表示向量点乘操作。
输出门则是决定输出的信息,单元的输出由单元状态决定,输出门首先计算单元输出状态ot,之后还要更新t时刻的单元隐层状态ht。计算方式如式(3)所示:
(3)
其中,Wo、bo表示输出门计算参数同样在训练中学习得到,*表示向量点乘操作。
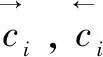
根据计算过程分析得到,字符会通过BILSTM更好地获取上下文的信息提取字符特征。对于较长的专有名词更好获取相对依赖关系,对于缩写混合情况通过字符特征也可以有效处理,这样可以很好地解决专有名词缩写混合的问题。当单词内字符通过字符特征提取后,对应单词通过单词嵌入得到单词的向量表示,并将字符特征向量ci与单词特征向量wi串联,得到最终的嵌入特征ei={ci,wi}。
2.2 联合层
联合层将字符和单词串联的特征向量ei放入CNN卷积神经网络进行特征抽取。字符与单词向量的语境特征存在很强的依赖关系,对命名实体识别任务具有很大的参考意义。特别对航空安全命名实体识别任务,因为数据的专业性和缩写的存在,句子中的依赖关系对于最终标签的预测起着更为重要的作用。同时针对航空安全数据的特点,以及数据标识类别的特点,发现航空安全数据的标注任务对于局部依赖关系特别敏感,对于全局依赖则较为迟缓。基于CNN对于局部特征提取的优势,该文在联合层使用CNN结构进行特征提取。联合层模型结构如图3所示。
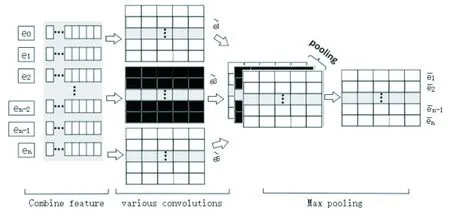
图3 联合模型结构
联合层主要将获得的联合向量ei通过卷积层进行特征提取,考虑到不同局部特征的影响,该文使用多个尺寸卷积进行局部特征提取,之后通过池化操作获得全局特征。其计算过程如式(4)所示:
(4)

(5)
2.3 CRF
对于标签依赖关系的建模在NER任务中是很重要的,因此最后使用CRF建模标签之间的依赖关系。
对一个给定的语句s={w1,w2,…,wn}和它对应的序列标签y={y1,y2,…,yn},用γ(s)标记s中的所有可能标签序列。CRF模型首先求在y给出的所有可能的标签序列上计算条件概率p(y|s),计算方式如式(6)所示:
(6)
其中,∅(yi-1,yi,s)=exp(f(si,y',y)),f是一个映射函数,主要目的是将单词映射到标签,函数的表达如式(7)所示:
f(si,y',y)=Wypi+by′,y
(7)
其中,pi是联合层输出经过非线性函数得到的最终预测特征,Wy是预测权值矩阵,by′,y是从y'到y的过渡权重。对于CRF模型而言,其损失函数的计算方式如式(8)所示:

(8)
最终的目标就是最大化式(6),即argmaxy∈γ(s)p(y|s),为了便捷和高效,将用Viterbi算法进行解码。
3 实验与结果分析
为验证该文提出模型的效果,从kaggle上获取从1908年全球飞机事故报道,进行处理后形成实验数据进行实验对比。首先将无字符特征嵌入的通用LSTM-CRF模型作为基准,以此来了解通用模型在航空安全命名实体识别任务的表现,之后又对比了使用LSTM和CNN对字符进行特征提取对结果的影响,最后对比使用不同模型在联合层对特征提取的不同影响。
3.1 数据预处理与标注
本次实验使用了从1908年到1973年之间的航空事故报道,共3 007篇,先对数据进行格式处理,并初步清理对NER任务的无效数据。例如数据中的时间、登记标号、载客数等。航空事故报道以英语为主,还包括法语、德语等其他语言,因为表达形式的原因,该文没有对语言进行详细分类,即模型本身的训练数据是由多语言集成的。对数据进行初步处理之后,使用程序对数据集中的标准格式部分进行标注处理,用人工标注的方式对其他部分进行标注。对于数据集的标注,该文参考航空事故数据特点与注意事项,并结合其他NER数据集的标注方式,将数据的标注分为八个类别,具体类别信息如表1所示。

表1 标准释义
数据标注按照标准释义表规则进行,并在标注完成后重新检查保证数据标注的质量。数据集的标注策略采用BIOS标注策略,其中B表示短语的开始部分,I表示短语的剩余部分,S表示单个词,O表示无实体含义的词。数据规模达到10万个词,数据统计如表2所示。
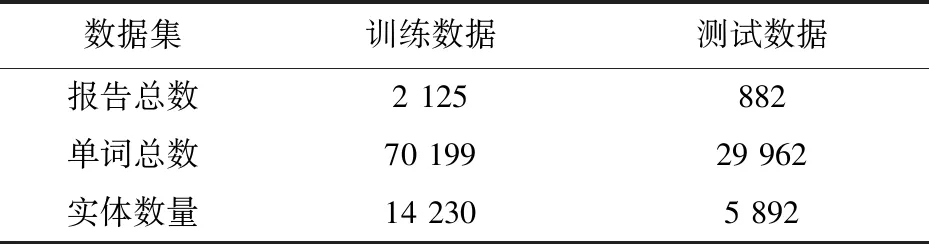
表2 数据集统计
将数据集划分为训练集和测试集两个部分,其中训练集由7万个词组成,测试集由3万个词组成。数据划分的方式在时间有序的情况下进行简单抽样处理,保证训练集与测试集数据的分布均匀。
3.2 实验设置
该模型基于Pytorch框架搭建,实验参数基于对比实验进行选择,最终实验参数设置:字符嵌入维度为30,词嵌入维度为100,双向LSTM将词嵌入维度扩展到200,卷积核尺寸分别设置为1、3、5。为防止模型过拟合,将dropout设置为0.6,数据集的batch_size设置为5,训练学习率设置为0.001,训练优化使用Adam,模型训练轮次设置为100。实验采用F1值作为模型效果评价指标,NER任务中常用的评价指标有准确率P、召回率R和F1值,计算公式如式9所示:
(9)
其中,TP表示正类预测为正类数,FP表示负类预测为正类数,FN表示正类预测为负类数。考虑到F1值是准确率和召回率的调和平均数,使用F1值作为衡量指标可以更好地兼顾准确率和召回率。
对比实验分为三个部分。第一部分是使用BILSTM-CRF作为基线方法,该方法过程为将单词通过嵌入层转化为向量表示后送入BILSTM进行特征提取,之后使用CRF解码做序列化标注。基线方法没有考虑字符特征,并且在特征提取时使用LSTM的上下文感知依赖关系。第二部分是对字符特征使用LSTM和CNN两个模型,对比不同模型提取字符特征的效果以及增加字符特征对于航空安全命名实体识别的作用。第三部分是对联合特征使用LSTM和CNN两个模型,对比联合特征提取对命名实体识别的影响,验证对航空安全命名实体识别局部敏感的处理效果。
3.3 结果分析
实验结果对比使用F1值作为标准,实验结果如表3所示。

表3 实验结果
首先将基线方法实验结果与对字符特征使用LSTM和CNN的实验结果进行对比可以发现,字符特征的加入可以提高命名实体识别任务的效果,采用LSTM和CNN在F1值上分别提升2.22和0.18,结果表明增加字符特征可以提高在航空安全领域命名实体识别的效果,并且使用LSTM可以更好地获取上下文依赖关系,在标注结果上可以更好地解决缩写混合的问题。在字符特征采用相同方法进行特征提取,对比联合特征使用LSTM和CNN的实验结果发现,使用CNN获取联合特征效果较好。在字符特征使用CNN处理时,联合特征使用CNN比LSTM效果提高0.09。在字符特征使用LSTM处理时,联合特征使用CNN比LSTM效果提高0.15。同时使用CNN的收敛速度和训练速度要优于LSTM。原因主要在于CNN模型可以更好地并行运算。
4 结束语
增加字符特征作为命名实体识别模型的特征输入,解决航空安全领域专有名词较长与缩写混合问题,使用CNN进行联合特征处理,解决航空安全领域局部敏感问题。并在1908年到1973年航空安全事故报道上进行了实验。从实验结果来看,航空安全领域命名实体识别任务因为其领域特点,字符特征的加入可以更好地提升航空安全领域命名实体识别的任务效果。在字符与单词特征联合的处理上使用CNN的效果更佳,同时CNN的训练速度与收敛速度也要优于LSTM。该方法的主要问题在于数据集标注耗时较长,考虑到航空安全领域数据标注成本较高的问题,后续的研究方向可以结合小样本学习方法减轻对于数据量的依赖情况。同时后续研究发展航空安全领域更细粒度的命名实体识别方法,获取更加详细的实体信息。考虑到注意力机制对于命名实体识别任务的提升效果,后续研究也可以使用注意力机制提高模型的效果。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
电脑报(2021年41期)2021-11-04
文萃报·周五版(2021年10期)2021-09-13
电脑知识与技术(2019年29期)2019-12-16
电脑爱好者(2019年8期)2019-10-30
人民交通(2018年6期)2018-07-31
电机与控制学报(2018年9期)2018-05-14
劳动保护(2017年5期)2017-06-12
计算机应用(2016年10期)2017-05-12
农机使用与维修(2014年10期)2014-10-23
