
基于依存感知建模的事件论元抽取方法研究
2022-09-15 14:31陈新元
无线互联科技 2022年13期
陈新元,廖 涛
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
0 引言
事件论元抽取是指从自然语言文本的事件中识别出所有论元[1],并为这些论元分配相应的角色属性,然后将其以结构化信息的形式呈现给用户。在公开数据集ACE2005中,将事件分为8个父类型和33个子类型,将论元分为35种角色。目前,研究者大多关注论元本身的语义特征,而忽略了依存关系特征、触发词和论元的位置关系特征以及触发词类型特征等隐层信息,导致论元抽取的效果不够理想。为了能更好地利用隐层信息特征,本文提出基于依存感知建模的事件论元抽取方法,有效提高了论元抽取性能。
1 模型设计
本文的模型主要分为3层:输入层、特征抽取层和输出层,具体流程如图1所示。
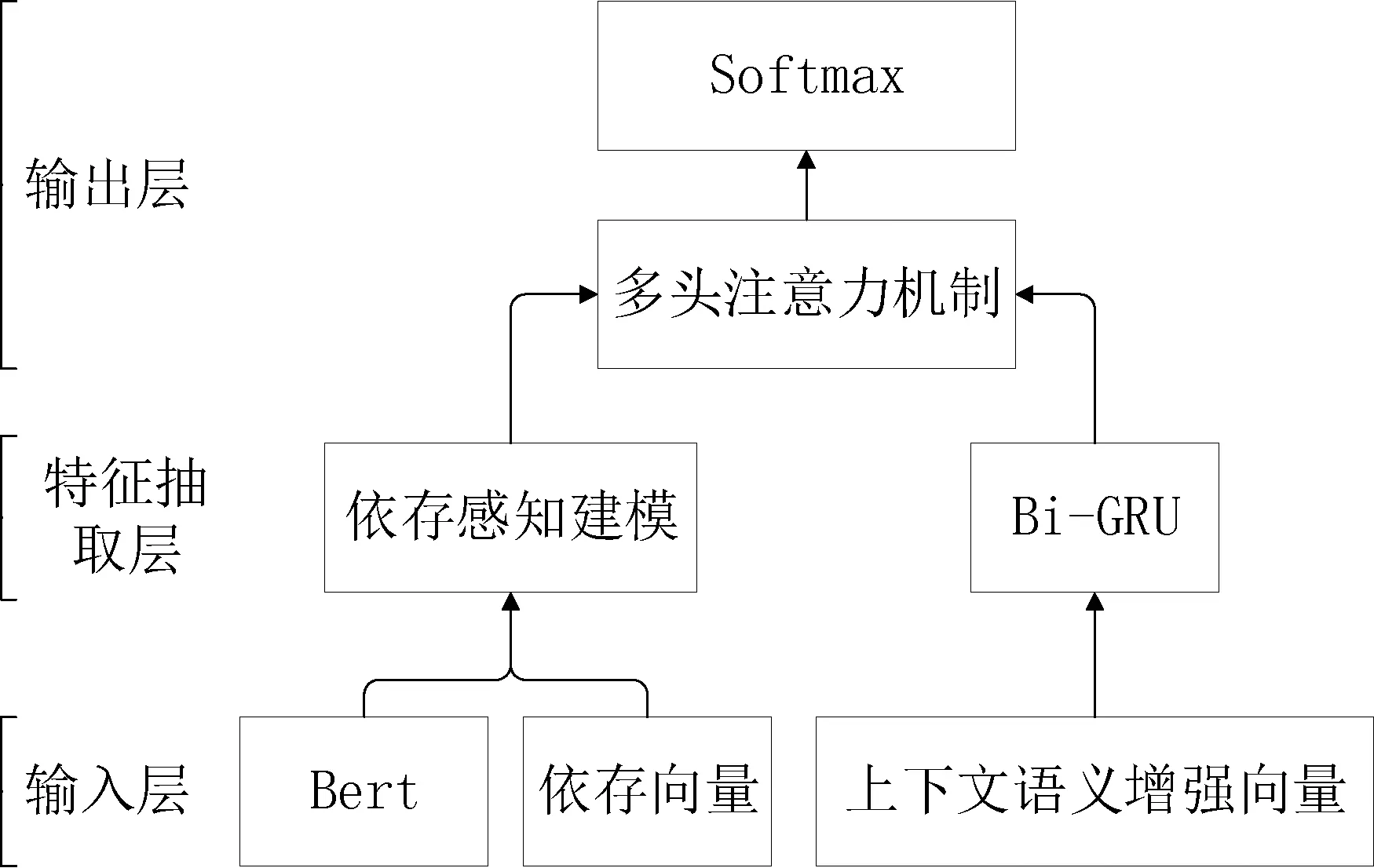
图1 事件论元抽取模型
1.1 输入层
首先,本文采用中文维基百科语料库训练Word2Vec,并通过该模型的skip-gram模式获取目标文本的词向量表示e(wori);其次,通过候选论元的空间关系构建一个10维的位置向量表示e(posi);最后,通过触发词的标注类型构建一个35维的类型向量e(typi)。因此,可得处于第i位置词语的最终上下文语义增强向量表示ei,如公式(1)所示。
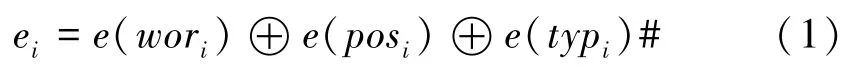
公式(1)中,⊕表示的是通过拼接的方式整合上述向量,最终得到事件句的上下文语义增强向量表示E={e1,e2,e3,……en},其中,ei代笔第i个候选论元的向量表示。
此外,句子文本在通过Bert预训练之后,每一个词都捕获了局部以及全局的语义信息。给定事件句向量X={x1,x2,x3,……xn},其中n代表事件句的长度,xi代表事件候选论元,将向量X输入到Bert中进行预训练,得到训练后的句子向量表示H={h1,h2,h3,……hn}。同时,为了获取句子中候选论元的依存关系表示,本文采用百度的自然语言处理工具DDParser进行依存句法分析,获取到词间的依存关系表示为R={r1,r2,r3,……rn}。
1.2 特征抽取层
为了让候选事件论元能够对关键的语义依存特征给予更多的关注,本层构建了依存嵌入注意力网络。依存嵌入注意力网络,即是利用候选论元之间的语义依存关系,将语义依存特征和上下文特征进行相关性计算,从而使文本中的事件论元能够具备依存嵌入注意力。依存嵌入注意力网络一共有N层,其中每一层的输出结果是下一层的输入信息,每一层网络接收到信息后与语义依存特征向量进行相关性计算。
随着依存嵌入注意力网络的训练层数逐渐加深,会面临梯度消失或梯度爆炸的风险,进而影响整体的拟合效果。本文引用残差网络(ResNet)的思想对依存嵌入注意力网络进行调整,保证信息在正向传递的过程中,经过残差网络的修正后,下一层网络蕴含的信息量多于上一层网络。残差网络基本结构由残差单元组成,残差单元由卷积层、归一化层和激活函数组成。对于给定的输入序列信息,首先残差网络将输入信息依次通过卷积层训练、ReLU激活函数激活以及BN层归一化操作,然后将得到的输出信息送入多个残差单元中,最后再通过BN层和全连接层处理得到最终结果。
本文将事件句中的每个候选词看作一个节点,将词间的依存关系看作是结点之间的边,每个节点都包含3种边:自环边、正向传播边和反向传播边,根据依存关系可以得到该事件句的依存邻接矩阵G={A,B}。为了加强捕捉依存关系的同时不错失其他关键的节点信息,本文通过依存感知建模算法对依存关系进行感知建模,具体过程如表1所示。

表1 依存感知建模算法
在另一通道中,经由输入层传来的上下文语义增强向量,将被输送到Bi-GRU中进行序列编码,该双向门控循环神经网络的具体计算过程如公式(2)和(3)所示。

公式(2)和公式(3)分别代表正向和反向的序列编码计算,通过将正向和反向的GRU编码结果进行拼接得到上下文语义增强特征表示P={p1,p2,p3,……pn}。
1.3 输出层
由前述可知,通过特征抽取层得到依存感知特征表示O={o1,o2,o3,……on}和上下文语义增强特征表示P={p1,p2,p3,……pn},本文通过多头注意力机制把两个特征进行融合。该层将含有依存感知特征的句子向量切割为三部分,分别与上下文语义增强特征表示进行注意力运算,得到最终的候选论元隐层信息表示lesn如公式(4)所示。
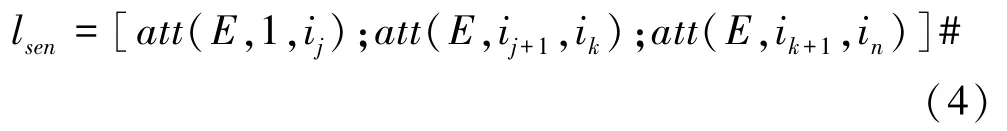
式中,att(E,m,n)表示对所有的候选论元进行线性加权操作。对于第i个候选论元wi,通过一个全连接网络为得到的每个类别进行打分,计算公式如(5)所示。

其中,W表示权重矩阵,参数b表示偏移量。得到打分之后,通过softmax函数对事件论元角色进行分类预测,如公式(6)所示。同时,本文通过自适应矩估计算法对参数进行更新,同时采用Dropout机制以防止出现过拟合现象。

2 实验分析
2.1 实验设置
本实验数据集使用的是由上海大学语义智能实验室构建的CEC2.0中午突发事件语料库。本文随机选取260篇文本作为训练集,选取37篇作为测试集,剩余35篇作为验证集。本文在实验过程中,通过验证集不间断的检测F1的分数,直至找到最大值并保留对应的实验参数,以作为最终结果。本文词向量设置为200维,事件触发词类型向量设置为35维,位置向量设置为10维,总共245维,设置防过拟合机制Dropout的实验参数为0.4。本文通过准确率P、召回率R和F1值作为实验的评估标准。
2.2 结果分析
本文与当前主流模型的实验结果对比,如表2所示。

表2 事件论元分类实验结果对比
此外,本文通过不同的依存嵌入注意力网络层数的实验结果对比,确立事件论元抽取性能最佳的网络层数,不同网络层数实验结果如表3所示。与不构建依存嵌入注意力网络相比,利用依存嵌入注意力计算能够明显提升事件论元抽取的性能。

表3 不同层数实验结果对比
因此,依据语义依存关系的影响程度不同,给予关键语义依存关系更高的注意力权重,能很好地提升模型的效果。对于使用不同依存嵌入注意力网络层数的模型,其得到的准确率P、召回率R和F1值各不相同。当模型层数为1时,模型出现欠拟合现象,随着层数的加深,准确率小幅度下降,召回率和F1逐步提升,当层数为7时F1值最大,模型达到最优效果。
3 结语
本文通过获取事件句的依存结构关系,并提出了依存感知建模算法对该关系进行建模,得到了依存感知特征;同时构建上下文语义增强向量,输入到双向门控循环神经网络中进行序列编码,得到了上下文语义增强特征;最后融合上述特征,并进行事件论元的角色分类,在CEC2.0语料库上的F1值达到了64.1%。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
传媒评论(2017年3期)2017-06-13
韶关学院学报(2017年4期)2017-04-13
海外华文教育(2016年3期)2017-01-20
河南科技(2015年8期)2015-03-11
江西师范大学学报(哲学社会科学版)(2014年1期)2014-09-05
外语学刊(2011年1期)2011-01-22
